 2018, Vol. 36
2018, Vol. 36 

2. 中国计量大学 经济与管理学院, 杭州 310018;
3. 国网浙江省电力有限公司电力科学研究院, 杭州 310014;
4. 国网浙江海盐县供电有限公司, 浙江 海盐 314300;
5. 浙江华云信息科技有限公司, 杭州 310007
2. China Jiliang University, Hangzhou 310018, China;
3. State Grid Zhejiang Electric Power Research Institute, Hangzhou 310014, China;
4. State Grid Zhejiang Haiyan Supply Company, Haiyan 314300, China;
5. Zhejiang Huayun Information Technology Co. Ltd., Hangzhou 310007, China
用电量的识别对地方经济发展和配电公司改善电力系统用电管理起着非常重要的作用。现有文献对用电量的分析大都集中在异常用电量的识别、正常用电量的影响因素分析以及预测方面。
(1)在异常用电量识别方面,田力、向敏提出1种基于密度聚类技术的电力系统用电量异常分析算法[1]。
(2)在用电量的影响因素分析方面,有学者提出产业结构升级对用电的影响问题,分析了用电量与三大产业之间的关联关系[2]。有的学者从产业结构调整、节能减排等政策方面提出1种基于改进灰色关联度的电力负荷影响因素量化分析模型[3]。也有学者基于格氏因果关系及误差修正模型,对10个主要工业部门用电量与GDP增长的双向关系进行了初步分析,发掘了它们之间的互为影响关系[4]。
(3)在用电量预测方面,有学者对原始用电量数据进行平滑预处理,并考虑了影响园区用电量的主要因素,将其进行模糊化处理,借助分段模糊拟合预测方法进行拟合预测[5]。有些学者对比了工作日、休息日、固定假日和非固定假日用电量的差异,针对不同情况获得了虚拟化变量的系数,在此基础上建立了短期用电量预测模型[5]。
尽管已经存在各类用电量分析文献,但是这些文献在分析用电量的时候很少考虑空间要素,而区域之间的空间关系会影响到用电行业的用电情况。分析不同用电行业在不同区域之间分布呈现的聚集或离散情况,能够对配电企业在安排用电时起到辅助决策作用。
1.2 本文的研究方法一个区域的用电情况并非是单一行业决定的,决定区域经济发展的用电行业是多种多样的,基本构成的八大用电行业(代码)分别是:
(1)农、林、牧、渔业(A000);
(2)工业(GG00);
(3)建筑业(E000);
(4)交通运输、仓储和邮政业(F000);
(5)信息传输、计算机服务和软件业(G000);
(6)商业、住宿和餐饮业(H000);
(7)金融、房地产、商务及居民服务业(J000);
(8)公共事业及管理组织(M000)。
这些用电行业的共同作用决定着所在区域的经济发展状况。这些区域在多种用电行业作用下是否呈现集聚效应,哪些区域属于用电热点区域或冷点区域,均需要进行测度。本研究以浙江省的八大用电行业为研究对象,将传统的多变量同这些变量的空间测度结合起来,自动聚类那些既具有多变量属性又涉及连续性空间单元的用电行业,识别出用电行业区域内的热点区域与冷点区域。
常用的多变量聚类算法可以归纳为分割聚类方法、层次聚类方法、基于密度的聚类方法和基于网格的聚类方法,其中最流行和常用的聚类方法是k-means聚类[6-10]。为了考虑属性的空间关系,聚类算法将空间因素纳入到这些传统聚类算法之中[11]。本研究创新地提出了1种非空间—空间组合在一起的多元聚类方法,该方法通过将Getis-Ord Gi*统计和k-means多元聚类方法结合在一起,分析用电行业数据在区域空间中的集聚情况,探测多种用电行业作用下各个城市用电的冷、热点情况。
2 数据选择及权重设定数据来源于浙江省上述8大行业用电数据,分布在浙江省的11个地区。为了进行空间探测,需要构建空间权重矩阵,进行空间数据分析的1个重要环节是生成空间权重文件,选取空间计量软件GeoDa进行权重的设计。根据判断邻居关系规则的不同,GeoDa中主要有3种产生空间权重的方式:
(1)有公共边界或顶点即为相邻的queen和rook权重设置;
(2)在一定距离阈值范围内相邻的权重设置;
(3)将距离最近的k个单元设为相邻的权重设置。
3种方式生成的空间权重矩阵均为0~1矩阵,本研究选择rook模式。因为舟山在地图呈现中与其他各个城市没有共同边界,因此其单元的邻居数为0,这样会出现舟山的行权重无法参与到空间计算的情况,导致计算错误。本文的解决方法是将宁波分配给舟山作为邻居,同时宁波的邻居数中同样对称性地增加了舟山。
3 基于局部指数Gi*的多变量非空间—空间组合聚类方法 3.1 多变量空间聚类的研究框架为了检测多种用电行业的空间集聚情况,需要考察每个用电行业的空间依赖。空间依赖的测度一般有2种方式,即全局空间相关性测度及局部空间相关性测度。
全局空间相关性测度强调的是整个区域的均值空间依赖。如果潜在的空间过程不稳定,则全局测度可能不具有代表性;局部空间相关性测度旨在识别研究区域内的每个变量值的空间依赖模式,其满足2个条件:
(1)为变量的每个位置标示重要的空间聚类内容;
(2)局部统计的总数与全局空间相关指数成正比。
局部空间统计经常使用的方法是Gi*统计、局部moran指数,在空间集聚探测方面,Gi*统计要优于局部moran指数。原因是局部moran指数只对统计有效性检验的数据点有效,而Gi*统计可以针对所有的数据点进行分析[11],使多变量的数据转换为多变量的空间数据成为可能。为了实现不同行业用电量的多变量空间聚类,需要将每1个多变量转换为具有空间特征的变量,而这个转换工作恰好可以通过Gi*统计来完成。转换完毕后形成多变量空间矩阵,就可以采用k-means来完成聚类。聚类时通过轮廓线系数方法确定最优聚类数。
为了比较多变量空间聚类和普通聚类的优劣,通过拟合优度方法对两者进行了比较,并对两种方法产生的结果进行地图可视化。研究方案框架见图 1。

|
图 1 基于局部指数Gi*的多变量空间聚类研究方案框架 |
Getis和Ord提出2种局部计算指标Gi*(Gi),Gi*统计中要素j中包含i,而Gi统计要素中j中不包含i[12-14]。由于要探测每1个变量的空间聚集程度,所以选择Gi*比较合适,计算如公式(1):
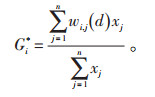
|
(1) |
其中,xj是要素j的属性值,wi, j(d)是要素i和j之间的空间权重,是空间权重矩阵W的n×p元素,n为要素总数。矩阵W从xi和xj之间的门槛距离d导出[15]。门槛距离d的定义规则为:凡是在这个距离范围内的元素都被称作为邻居,且在矩阵W中这些要素间权重取值为1,不在这个距离范围内的要素在矩阵W中取值为0。为了计算的统一,将相邻规则形成的空间权重转换为距离权重参与Gi*测度,Gi*测度计算的是以第i个位置为中心,其值等于其邻居的值与空间权重的乘积之和,与所有数据值总和的比值。为了提高统计检验精度,Ord和Getis发展了1种将Gi*做最小化估计的z转换形式,见公式(2):
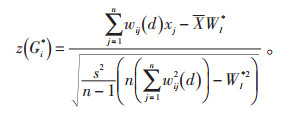
|
(2) |
其中,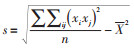
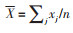
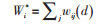
后续计算以z(Gi*)统计为主。对于具有显著统计学意义的正的z得分来说,z得分越高,高值(热点)的聚类就越紧密;对于具有显著统计学意义的负z得分,z得分越低,低值(冷点)的聚类就越紧密。
3.3 非空间—空间组合数据聚类 3.3.1 聚类结果依照图 1的框架逻辑,需要将标准化的Gi*加入到多变量的属性数据中,构造新的n×p列联表结构,然后对这个列联表采用k-means来聚类,寻找其最优的聚类数,聚类过程如下:
(1)给定1个空间权重W,设为每个变量计算标准的局部Getis-Ord统计指数。通过公式(2)计算第i个单元(i=1,…,n)中第j个变量(j=1,…,p)的值z(Gj*(xi))。将这些值组合成(n×p)维度的矩阵Z,其中Z的每个列代表其中1个变量的局部空间自相关模式,Z的每一行描述了每1个局部单元的聚类属性构成。
(2)将k均值聚类算法应用于这组空间结构化的变量矩阵Z。k均值聚类是将1组数据划分为预先设定好的k个簇,簇的质心是k均值聚类的关键。基本思想是利用迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。对于选择好k个质心后,接着将数据中的每个点与距离其最近的质心联系起来,如果已无数据点与质心相连,则第1步结束;然后将第1步生成的围绕质心的样本点求均值后作为新的质心,再计算与其最近样本点的聚集情况,以此类推迭代,直到质心点不再发生变动为止。对于所有k个聚类的模式遵循准则函数J的值为最小的原则,从而计算出k个聚类的质心点。见公式(3):
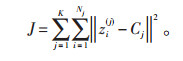
|
(3) |
其中,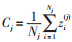
(3)确定最优主题数。k均值聚类的目标是最小化每一个类内部的差异,最大化类之间的差异。由于聚类采用的是无监督方法,聚类最优数目需要提前确定。聚类最优数目确定有多种手段,如KL方法、Scott方法、Marriot方法、Ball方法、silhouette方法,Gap方法等。轮廓线系数(silhouette coefficient)表达了所聚类的内部要素是紧密联系的,而该类之外的元素与其内部元素是分离的观念,与k均值聚类特别契合而且表现稳定[17]。因此本次聚类采用silhouette方法来完成最优聚类数目的寻找。轮廓线系数s(i)的计算公式如式(4):
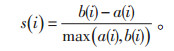
|
(4) |
其中,a(i)为实体i与和它属于同一个聚类中其他实体的平均距离,b(i)是实体i与其他聚类中所有实体平均距离的最小值。轮廓线系数的取值-1~1,值越大表示聚类效果越好,最大值对应的聚类数目即为最佳聚类数目[7]。如果某实体的轮廓线系数为0,则表明该实体可能已经被分配到了其他类别中;如果轮廓线系数接近于-1,则意味着这个实体被错误分类了。如果所有的轮廓线系数都接近于1,那么意味着全部实体都得到很好地聚类。为了避免局部最优解,令聚类数目k取值2—8,在每个k值上重复运行30次k-means,并计算当前k的平均轮廓线系数,最后选取轮廓线系数最大的值对应的k作为最终的聚类数目。使用轮廓线系数对k-means处理的多变量空间矩阵进行聚类最优数量寻找。计算结果见图 2。

|
图 2 轮廓系数确定最优主题数 |
(4)方差拟合优度(GVF)测度及热点冷点检测。为了比较非空间—空间结合的k-means聚类和非空间聚类的优劣,选择k=3聚类数目分别对带空间依赖的8个用电行业和不带空间依赖的8个用电行业进行k-means聚类。为了评测空间聚类方法的有效性,遵循聚类内部要素应越具相似性且聚类之间应越具差异性的原则,选择方差拟合优度(GVF)来测度它的有效性,并将其与非空间的k-means聚类进行比较。方差拟合优度是评价聚类精度的有效方法[18],见公式(5):
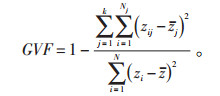
|
(5) |
其中,zj(i=1,...,N,N为区域总数目,就当前研究内容来说指国内31个省市自治区)为观察值,k为聚类数目,zj是聚类j中的观察值的均值,Nj是聚类j中的区域数目。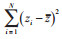
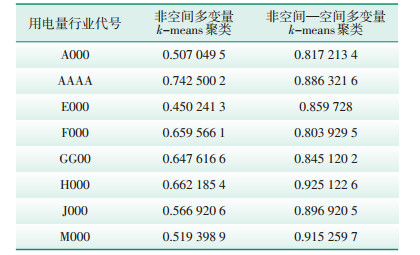
表 1比较了未考虑空间要素的多变量k-means聚类和考虑了空间要素的多变量聚类的情况,发现在考虑空间要素时,各个类别用电量观察值的GVF都有所提升,说明空间聚类较好地改善了非空间聚类。
| 表 1 非空间聚类与空间聚类的GVF比较 |
多变量非空间k-means的聚类结果和多变量非空间—空间k-means聚类结果见图 3所示。从地图效果上看,右侧的多变量非空间—空间结合的k-means聚类明显比左侧的多变量非空间k-means聚类有规则,聚类效果更好,这一点在方差拟合优度中也得到了说明。说明论文所提供的多变量非空间—空间聚类方法可行。

|
图 3 两种k-means的聚类比较 |
由于局部Gi*指数能够对聚类变量进行热点、冷点探测,因此可以将其应用于观察多变量空间聚类的热点监测情况,从而判高值聚类与低值聚类。参照单变量Gi*统计的要求,观察各变量在不同聚类中的Z得分情况,选取每个空间聚类中的Z得分均值来判断多变量空间聚类的热点、冷点以及无空间相关性的分布。Z均值大于1.65的为高值聚类且为热点聚类,介于1.2~1.65的为一般程度的高质聚类,介于-1.65~1.65的则无空间相关性(空间分布呈现随机性),而小于-1.65的为低值聚类且为冷点聚类。
从图 3(b)可知,绍兴、嘉兴、湖州属于第一聚类,查找其Z得分的均值为2.281 107 4;衢州、金华、宁波、杭州、台州属于第二聚类,查找其Z得分的均值为1.225 094 4;温州、丽水、舟山属于第三聚类,查找其Z得分的均值为-0.920 843 5。根据Z得分情况说明绍兴、嘉兴、湖州属于热点区域, 这3个区域的经济发展迅猛,八大行业的用电量在这几个城市呈现需求增长趋势。而衢州、金华、宁波、杭州、台州属于一般热点聚类。由于温州、丽水、舟山的Z得分均值为-0.920 843 5,可能属于随机分布状态,这说明了八大行业在这几个城市的发展并不均衡,有些产业的发展比较迅猛,有些产业的发展则比较迟缓。
3.3.2 结论本文将Gi*空间统计与k-means相结合进行用电量的区域集聚研究,是空间多变量聚类的尝试性研究,尚有一些问题有待进一步讨论。
(1)在做空间组合的多元聚类过程中,由于要将每个变量的具体值都转换为带有空间关系的变量形式,利用全局空间moran指数是不合适的(因其处理的内容是变量的均值效应)。局部Geary C和局部moran′s I也不合适,一方面它们对通过统计检验的变量值检查准确,而对未经过统计检验的变量值则表现一般;另一方面它们没有考虑待分析变量的特征值,只处理该变量的邻居值,这就造成了k均值聚类中数据的缺失。而Gi*统计既能考虑邻居值也能考虑自身值,因此适合发现区域的同质性聚类效应。由于Gi*统计可以为每个数据点做空间统计转化,擅长分析空间数据的热点趋势, 因此在做k均值聚类时,引入Gi*统计转化数据更合适。
(2)传统的k-means聚类根据数据距离测度(本论文选择欧式距离)完成类属划分,对聚类中的高值聚类与低值聚类无法做出区分。而空间多元聚类方法由于加入了Gi*统计因素,能够观察各变量在不同聚类中的Z得分情况,进而通过Z得分均值来判断多变量空间聚类的热点、冷点以及无空间相关性的分布情况,从而使得产生的聚类结果更具指导性。
(3)空间—非空间组合方法为用电量区域集聚分析提供了1种尝试,但这种方法是基于截面数据的。如何通过面板数据扑捉用电量热点、冷点随时间的演变过程,观察区域之间在生产和生活用电方面的接近程度,以便于帮助配电企业和政府对相近的区域进行政策指导,这些问题需要继续开展研究工作。
4 结语城市用电并不局限于某1个行业,往往是多个行业同时并存,本文讨论的这些行业在不同的城市基本都存在。传统的k-means聚类没有考虑到不同城市之间因为空间关系导致的依赖效应,因此在城市用电聚类方面精确度不高。当在城市之间引入空间依赖后,不仅城市用电的聚类效果得到很大提升,而且能够测度出哪些城市属于热点、冷点聚类,可为用电企业对这些城市的配电管理提供科学依据。通过比较不同城市在用电方面的相似程度和用电量聚集情况,可以帮助配电企业根据城市用电热点和冷点来进行用电供给,实现资源的最佳配置,提升城市的经济发展水平。
| [1] | 田力, 向敏. 基于密度聚类技术的电力系统用电量异常分析算法[J]. 电力系统自动化, 2017, 41(5): 64–70. DOI:10.7500/AEPS20160510003 |
| [2] | 杨方圆, 史宇超, 侯玉琤. 考虑产业结构调整的用电量指标关联分析及负荷预测[J]. 电气技术, 2017, 18(5): 19–23. |
| [3] | 王雁凌, 吴梦凯, 周子青, 等. 基于改进灰色关联度的电力负荷影响因素量化分析模型[J]. 电网技术, 2017, 41(6): 1772–1778. |
| [4] | 何永秀, 赵四化, 李莹, 等. 中国工业用电量与经济增长的关系研究[J]. 工业技术经济, 2006, 25(1): 78–82. |
| [5] | 刘晓娟, 龚毅豪. 基于分段模糊拟合方法的用电量预测研究[J]. 上海电力学院学报, 2017, 33(2): 206–209. |
| [6] | 李凯, 赵滨滨, 曹占峰, 等. 基于回归分析和虚拟变量的短期用电量预测管理模型[J]. 电气应用, 2017(2): 59–65. |
| [7] | 朱连江, 马炳先, 赵学泉. 基于轮廓系数的聚类有效性分析[J]. 计算机应用, 2010(S2): 139–141. |
| [8] | 张松林, 张昆. 局部空间自相关指标对比研究[J]. 统计研究, 2007, 24(7): 65–67. |
| [9] | Jain A K. Data clustering:50 years beyond k-means, European[J]. Pattern Recognition Letters, 2010, 31(8): 651–666. DOI:10.1016/j.patrec.2009.09.011 |
| [10] | Theodoridis S, Pikrakis A, Koutroumbas K, et al. Introduction to Pattern Recognition[M]. Amsterdam: Academic Press, 2010. |
| [11] | Cressie N, Wikle C K. Statistics for Spatio-temporal Data[M]. New Jersey: John Willey & Sons Inc, 2011. |
| [12] | Lloyd C D. Spatial Data Analysis[M]. New York: Oxford University Press Inc, 2010. |
| [13] | Córdoba M, Bruno C, Costa J, et al. Subfield manage ment class delineation using cluster analysis from spatial principal components of soil variables[J]. Comput Electron Agric, 2013(97): 6–14. |
| [14] | Getis A, Ord J K. The analysis of spatial association by use of distance statistics[J]. Geogr Anal, 1992, 24(3): 189–206. |
| [15] | Ord J K, Getis A. Local spatial autocorrelation statistics:distributional issues and an application[J]. Geogr Anal, 1995, 27(4): 286–306. |
| [16] | Mitchell A. The ESRI guide to GIS analysis in Spatial Measurements & Statistics[M]. Redlands: ESRI Press, 2005. |
| [17] | Charrad M, Niknafs A, Ghazzali N, et al. NbClust:An R Package for Determining the Relevant Number of Clusters in a Data Set[J]. Journal of Statistical Software, 2014, 61(6): 30–36. |
| [18] | Armstrong P, Ningchuan X, David A. Bennett. Using Genetic Algorithms to Create Multicriteria Class Intervals for Choropleth Maps[J]. Annals of the Association of American Geographers, 2003, 93(3): 595–623. DOI:10.1111/1467-8306.9303005 |