
文章信息
- 沈利言, 姜海燕, 胡滨, 谢元澄
- SHEN Liyan, JIANG Haiyan, HU Bin, XIE Yuancheng
- 水稻病虫草害与药剂实体关系联合抽取算法
- A study on joint entity recognition and relation extraction for rice diseases pests weeds and drugs
- 南京农业大学学报, 2020, 43(6): 1151-1161
- Journal of Nanjing Agricultural University, 2020, 43(6): 1151-1161.
- http://dx.doi.org/10.7685/jnau.201912024
-
文章历史
- 收稿日期: 2019-12-13




2. 南京农业大学国家信息农业工程技术中心, 江苏 南京 210095
2. National Engineering and Technology Center for Information Agriculture, Nanjing Agricultural University, Nanjing 210095, China
水稻病虫草害的防治方案大量以纯文本的形式保存在网页、书本和表格中, 如何从半结构化或非结构化文本数据中自动快速抽取病虫草害的治疗方案, 构建“水稻-病虫草害-药剂”知识库, 是作物信息服务技术发展的重要方向。
实体关系抽取是构建知识库的基础技术之一[1], 包括从文本中自动识别专有的实体名称即命名实体识别(named entity recognition, NER)[2], 对实体之间的关系进行分类(relation classification, RC)[3]。利用实体关系抽取技术可以从纯文本中自动获得结构化的三元组数据(实体1、关系、实体2), 为知识库的构建提供基础数据。按照实体识别和关系分类2个子任务完成的顺序不同, 实体关系抽取可以分为流水线法和联合抽取法。流水线法将NER和RC 2个子任务单独分开完成, 先从给定的文本中抽取出命名实体, 在此基础之上, 再对实体与实体之间的关系进行分类[4]。对于NER子任务, 传统的条件随机场模型在农业领域应用较多。王春雨等[5]、李想等[6]通过总结农业语料中词法、句法、特定限定词、特定偏旁部首等特征, 利用条件随机场模型识别农作物、病虫害等实体, 准确率达到90%左右。随着神经网络的发展, 基于深度学习的方法在命名实体识别上有了较多的应用。冯艳红等[7]通过双向长短时记忆网络提取字向量特征, 利用Softmax分类器实现每一个字符标签的分类, 在人民日报等公开语料集上对人名、地名、机构名抽取的准确率达到了90%以上。在关系分类任务上, Zhang等[8]提出双层循环神经网络模型, 利用底层循环网络自动提取原始语句中词特征、位置特征和最短依存路径特征, 再利用顶层循环网络对提取得到的特征进行解析, 进而通过注意力机制增强模型对关键词信息的提取, 在公用数据集DDI(drug-drug interactions)上, 抽取药物之间关系的准确率达到70%左右。Li等[9]提出了基于BiLSTM-RNN的关系分类模型, 该模型通过BiLSTM(bi-directional long short-term memory)对语义信息提取之后, 再通过RNN网络的解析和分类器的分类, 在公用数据集BioNLP-ST上抽取的准确率超过了60%。虽然流水线抽取方式简单易行, 但存在以下问题:将NER和RC 2个子任务单独执行, 没有考虑到2个子任务之间的互相影响关系, 无法利用其交互信息提升模型性能。RC的抽取性能依赖于NER, 命名实体识别的错误会导致关系分类也发生错误, 产生误差传播[10]。
针对流水线法的缺点, 有学者近年来提出了实体关系联合抽取法[11]。该方法在识别实体的同时抽取关系, 输出实体和关系共2种结果。Zheng等[12]提出了基于端到端的神经网络共享参数法, 以BiLSTM作为NER和RC 2个子任务的底层共享模型。通过BiLSTM自动提取原始语句的文本特征, 以此作为实体解码层LSTM(long short-term memory)的输入, 实现文本语义信息的解析, 最后利用分类器实现实体的识别。在识别的实体基础之上, 将BiLSTM提取的文本特征信息和LSTM解析的语义信息拼接得到综合语义特征, 进一步利用卷积神经网络实现实体之间的关系分类。该方法在实体识别的结果上实现关系分类, 本质上仍然相当于NER和RC子任务的单独进行。为了充分考虑NER和RC 2个子任务间的互相作用, Zheng等[13]又设计了一种同时包含实体和关系信息的新标注模式, 将实体和关系的联合抽取转化为序列标注任务, 在公用数据集NYT(New York Time)上抽取的准确率超过60%, 但是该方法的缺陷是语句中所有的实体只能有一个关系。针对该缺陷, Katiyar等[14]提出了将BiLSTM与注意力机制结合的联合抽取模型(Bi-directional long short-term memory with attention, BiLSTM-WA), 该模型以BiLSTM作为编码层提取文本的特征信息, 再以LSTM作为解码层对特征信息进行解析。以解析得到的语义信息为基础, 对字符标签分类实现实体抽取的同时, 利用注意力机制判断当前字符与之前字符是否存在关联关系, 实现关系的分类, 在公用数据集ACE05上实体关系抽取的准确率超过了55%。但在解码层中以单向LSTM作为解码网络, 当前时刻只能参考之前时刻学习到的字符特征。语义解析时, 忽略了下文信息对当前时刻语义信息提取的影响, 导致解析的语义特征并不全面, 从而影响实体和关系的抽取准确度。
病虫草害防治文本存在着大量的药剂、病害、虫害、草害等实体没有明确的后缀字符即边界特征, 并且药剂与病虫草害之间存在多关系(多关系指一种药剂可以治疗多种病虫草害, 同一种病虫草害又可以由多种药剂治疗)的现象。现有的抽取算法对没有明确边界特征以及多关系共存的数据样本的应用研究有限, 本文在BiLSTM-WA算法基础之上, 在编码层和解码层均采用BiLSTM算法, 设计了双BiLSTM与注意力机制结合的水稻病虫草害与药剂实体关系联合抽取算法(joint entity recognition and relation extraction for rice diseases, pests, weeds, JE-DPW), 在解码层中, 利用BiLSTM代替单向LSTM, 从前向传播和反向传播2个角度解析文本特征, 增强算法对上下文语义特征的提取能力, 可以有效抽取出水稻病虫草害防治文本中无边界实体以及实体之间的多关系。
1 水稻病虫草害与药剂实体关系联合抽取方法(JE-DPW) 1.1 病虫草害防治文本的语料特征分析水稻病虫草害防治文本包含不同物候期发生的病虫草害名称与相应治疗试剂名称, 与传统的人民日报数据集(https://github.com/InsaneLife/ChineseNLPCorpus/tree/master/NER/renMinRiBao)、SIGHAN Bakeoff(http://sighan.cs.uchicago.edu/bakeoff2005/)等开源数据相比, 在实体边界、关系数量等方面有较大差别, 样本例句见表 1。
| 序号 Serial number | 样本例句 Sample example |
| 1 | 水稻稻棘缘蝽, 水稻灰飞虱、二化螟, 防治方法:混灭威、20%杀灭菊酪、2.5%溴氰菊酪乳油2 000倍液, 在药液中加0.2%中性洗衣粉可提高防效 |
| 2 | 使用吡蚜酮可以治疗叶枯病和灰飞虱; 预防纹枯病主要使用甲维毒 |
水稻病虫草害防治文本的语料特征主要包括:
1) 在病虫草害防治文本的大量实体没有明确的边界特征。公开数据集中人名、地名、机构名的许多实体中含有较为明显的边界特征, 如:地名中大多包含“省”“市”“县”“区”等后缀字符, 机构名中也常含有大量的特征字符, 如:“企业”“国家”“组织”等。水稻病虫草害防治文本中, 虽然有些实体包含一些特定的后缀词, 如表 1中例句1, 药剂实体“溴氰菊酪乳油”, 病害实体“叶枯病”“纹枯病”等都带有特定的后缀字符“乳油”或“病”, 但是还有大量实体并没有明显的边界特征, 如:虫害实体“稻棘缘蝽”“灰飞虱”以及药剂实体“混灭威”“杀灭菊酪”等。
针对实体的边界特征问题, JE-DPW算法对每一个字符既标注实体标签也标注关系标签, 将实体识别和关系分类同时进行, 没有割裂NER和RC 2个子任务之间互相影响的关系, 可以利用其交互信息提升模型对无边界特征实体识别和关系抽取的性能。如例句1中, 实体“稻棘缘蝽”和“混灭威”之间的关系是治疗-虫害, 记作Treate-pes, 也就是2个实体之间有关系即实体中的每个字符之间都存在Treate-pes关系。如果字符“蝽”和“混”之间抽取的关系是Treate-pes, 则2个字符的标签类型很有可能是虫害和药剂; 同理如果字符“蝽”是虫害标签, 字符“混”是药剂标签, 则二者之间的关系很有可能是Treate-pes。总之, NER和RC 2个子任务同时进行具有互相促进作用, 从而提升模型对无边界特征实体识别和关系抽取的性能。
2) 病虫草害实体与药剂实体之间含有大量多关系。如表 1的例句2, 病害、虫害实体名称为叶枯病、纹枯病和灰飞虱, 药剂的实体名称为吡蚜酮、甲维毒。吡蚜酮可以治疗叶枯病、灰飞虱; 纹枯病与甲维毒之间是治疗关系, 与吡蚜酮之间是非治疗关系。
对含有大量多关系的水稻病虫草害防治语句, 考虑上下文的信息尤为重要。例句2中“纹枯病”与该句上文中的药剂实体“吡蚜酮”以及下文的“甲维毒”实体之间都存在关系, 所以在解析纹枯病实体字符的语义信息时, 需要同时考虑上文和下文实体对当前纹枯病实体语义解析的影响。如果直接利用Katiyar等[14]设计的BiLSTM与注意力机制结合的联合抽取模型(BiLSTM-WA), 由于该模型解码层中使用的是单行LSTM网络结构, 对文本语义解析时, 当前时刻只能参考之前时刻学习的字符特征, 忽略了下文的特征信息, 降低实体和关系的抽取准确度。
1.2 病虫草害与药剂实体关系联合抽取框架JE-DPW算法主要包含3个部分:首先通过设定标注策略标注每个字符的实体标签和关系标签, 利用Word2Vec[15]实现文本向量化, 将病虫草害防治语句中的每一个字符转化为向量; 其次在编码层和解码层使用BiLSTM神经网络实现病虫草害的文本特征抽取; 最后通过Softmax分类器分类出每个字符的实体标签, 同时利用注意力机制[16]实现字符之间关系的抽取, 从而达到实体和关系同时抽取的效果。主要结构如图 1所示。

|
图 1 JE-DPW算法框架 Fig. 1 JE-DPW algorithm framework |
首先将病虫草害与药剂之间的实体关系抽取转化为序列标注任务。病虫草害防治文本的实体主要包含病害、虫害、草害、药剂共4类, 在标注实体时标签信息主要包含实体类型和实体边界。分别使用{dis, pes, str, dru}作为病害、虫害、草害、药剂4类实体名称的类型标签。实体边界采用“BIO”标注原则, 其中B表示每个实体的初始字, Ⅰ表示实体的中间或者末尾字, 对于文本中非实体字符统一标记为O。字符标签共9种, 如表 2所示, 表中标签共有B-dru、I-dru、B-dis等8个, 第9个是非实体字符O标签。
| 实体编号 Entity number |
实体类型 Entity type |
实体开始 Entity begin |
实体内部或结尾 Inside or end of entity |
| 1 | 药剂 Drug | B-dru | I-dru |
| 2 | 病害 Disease | B-dis | I-dis |
| 3 | 虫害 Pest | B-pes | I-pes |
| 4 | 草害 Straw | B-str | I-str |
药剂与病虫草害实体之间的关系细分为6种, 分别是:治疗病害关系(Treate_dis)、不治疗病害关系(Distreate_dis)、治疗虫害关系(Treate_pes)、不治疗虫害关系(Distreate_pes)、治疗草害关系(Treate_str)、不治疗草害关系(Distreate_str)。其中Treate表示治疗, Distreate表示不治疗, 下划线“_”后面接的是治疗或者不治疗的类型。图 2为标注的例句展示。

|
图 2 病虫草害与药剂之间实体-关系标注方法示例 Fig. 2 Examples of annotation methods for entity-relationship between diseases pests and weeds and drugs |
由于自制数据集全部通过手工标注, 标注错误可能导致噪声标签的出现。对于人工标注错误的噪声标签, 本文设计了自动找错程序, 首先检测实体标签是否符合“BIO”标注规则, 即每一个实体标签都是以B开头, 中间和结尾的字符都是I标签。例如药剂实体标签的开头都是B-DRU, 那么在下一个O标签之前, 后续的实体标签一定都是I-DRU, 否则标注错误, 输出错误的位置, 然后人工修正。对于关系标签主要是通过字符串检测的方式, 来判断关系标注的准确性, 发现标注错误后, 人为修改错误的标签保证自制数据集标注的正确性。
1.4 文本向量化由于水稻病虫草害防治文本中存在大量较为偏僻的词汇, 因此采用现有的NLP(natural language processing)分词工具, 如jieba17、pynlpir[18]、NLPIR[19]并不能很好地完成分词处理。为了避免分词错误对病虫草害与药剂之间实体关系抽取结果的影响, 本文以字为基本的语义单位, 使用字向量作为联合抽取模型的输入。给定1个含有n个字的句子S, 记作S=(x1, x2, …, xn), 其中每个字xi都可以通过公式(1)被表示成为1个实值向量ei。
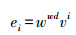
|
(1) |
式中:wwd是通word2vec得到的字向量矩阵, wwd∈Rd×|V|, R是字向量分布矩阵, d是字向量的维度, V是固定大小的字典, |V|表示字典的大小。vi表示第i个字的独热(one-hot), 其维度为|V|。最终原始语句S通过公式(1)获得字向量序列E={e1, e2, …, en}。
1.5 文本特征抽取LSTM[20]是一种能动态捕获文本序列数据信息的神经网络, 与传统神经网络相比, 它最大的特点是可以由序列的输入通过传播计算产生序列的输出, 并且每个时刻学习到的特征信息不仅取决于当前的输入, 还依赖于上一时刻的输出。它使用一种记忆细胞的结构来控制信息的保留与丢弃, 有效解决了RNN[21]存在梯度消失问题。每一个LSTM网络包含一系列的循环连接单元, 称为记忆区块。每个当前的记忆区块由“遗忘门(forget gate)”“输入门(input gate)”“记忆单元(cell)”和“输出门(output gate)”组成, 每个当前的记忆区块能够根据前一层的隐向量ht-1、前一层单元向量Ct-1以及当前的输入向量xt, 捕获到当前的隐向量。其数学模型为:
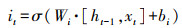
|
(2) |
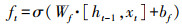
|
(3) |
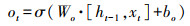
|
(4) |
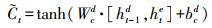
|
(5) |
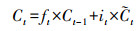
|
(6) |
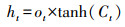
|
(7) |
式中:it、ft、ot分别表示输入门、遗忘门、输出门; 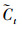
由于单向LSTM具有方向性[22], 在提取病虫草害防治文本语义特征时, 当前时刻只能参考之前时刻学习到的特征, 根据病虫草害与药剂之间存在多关系的特点, 无论是对文本特征提取还是特征的语义解析, 通常不仅要考虑上文信息, 也要参考下文信息。因此本文在编码层和解码层都使用双向长短期记忆网络, 该网络由2个方向相反的LSTM组成, 分别从前向和反向2个角度学习文本的特征, 再将二者拼接一起表示为整体的特征向量。如图 1在编码过程中, 对于每一个字向量et, 经过前向LSTM传播计算得到的病虫草害防治文本的特征信息记为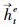
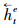
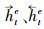
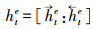
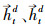
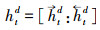
在实体识别中, 记文本序列为S=(x1, x2, …, xt, …, xn), 则对第t个字, 通过式(1)获取每一个字的向量, 表示为E={e1, e2, …, et, …, en}, 第t个字的字向量为et, 经过式(2)—(7)计算, 利用编码层前向LSTM提取到该字符的特征信息记为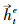
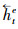
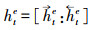
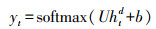
|
(8) |
式中:htd是通过双BiLSTM网络提取得到的文本特征向量; U为参数矩阵; b是偏置项。
1.6.2 关系抽取本文使用注意力机制实现病虫草害与药剂之间的关系抽取。对第t个字符抽取关系时, 以BiLSTM神经网络解码后得到htd语义向量作为注意力机制的输入, 判断t时刻与之前时刻的非O字符存在的关联关系。如图 1中, 当t=8时只需要判断当前时刻字符“叶”与“吡”“蚜”“酮”字符之间存在关系, 对于“可”“以”等非O标签不需要判断。在关系抽取中, 从式(9)得到权重矩阵u≤tt, 再通过softmax函数得到字符之间存在关联概率p≤tt, 具体计算公式如下:
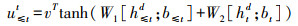
|
(9) |
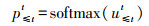
|
(10) |
式中:h≤td表示解码层中t时刻与之前所有时刻解码输出语义特征的叠加; b≤t和bt都表示偏置向量。p≤tt不仅是t时刻字符与之前字符之间存在概率的大小, 还包含关系的类型, 从而实现病虫草害与药剂之间关系标签的抽取。
1.6.3 代价函数使用JE-DPW算法训练模型时, 本文采用的代价函数为负对数似然损失函数。对于实体关系联合训练模型, 该模型有实体和关系2个目标, 因此代价函数由实体代价函数和关系代价函数2部分组成。代价函数公式如下:
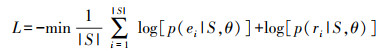
|
(11) |
式中:|S|表示句子的长度; ei、ri表示模型分类出的字符的实体标签和关系标签; θ表示模型的参数集合。在训练模型过程中, 代价函数值不断降低, 通过随机梯度下降算法不断更新2个子任务共享的双BiLSMT的参数θ, 从而使得2个子任务达到最优。
2 数据采集与模型构建 2.1 文本数据获取JE-DPW算法主要解决无边界实体和多关系的抽取, 现有研究[10-12]为基于公用数据集如ACE04、ACE05、DDI的试验, 但是开放的英文数据集很难统计实体有无边界性, 并且这种公用的英文数据集很少有多关系共存。目前较为标准的中文开放数据集如:人民日报、SIGHAN Bakeoff, 虽然明确标明了实体的类型, 但是实体与实体之间的关系没有标注, 如果要使用则需要人为规定, 缺少明确的标准。因此本文采用自制数据集。
数据来源主要分为2部分:一类是农业部提供的水稻高产栽培方案半结构化表格数据, 该半结构化表格数据包含全国不同生态区域的水稻高产创建模式信息, 本文重点抽取半结构化表格中关于病虫草害防治文本信息。该文本数据包含大量的水稻病害、虫害、草害和防治试剂的名称, 并且还包含防治试剂的用量以及防治时间。由于本文只研究实体关系的抽取, 对药剂的防治时间以及用量暂不考虑, 通过字符串匹配的方式从半结构化表格中自动抽取得到病虫草害防治语句共522条。另一类是权威网站平台上水稻病虫草害防治方案数据。研究发现农业图谱(http://tupu.zgny.com.cn/nzwbch_js_shuidao/List.shtm)、中国农资招商网(http://tupu.3456.tv/liangshizuowu/8-1)、专家在线系统(http://zjzx.cnki.net)、淘金地-农业网(http://nongye.taojindi.com/ask/list_47.html)等网站具有较为优质的水稻病虫草害防治方案, 我们从中抽取出1 071条关于水稻病虫草害防治的语句。对上述语料去重处理之后, 共得到1 581条水稻病虫草害防治语句。
2.2 数据集划分水稻病虫草害防治语句中含有大量的病虫草害实体及其相应的防治关系, 对于1 581条水稻病虫草害防治语句, 其中实体共有9 286个, 关系共有10 748个, 可以满足深度学习网络对特征学习样本数据的需求。按照1.3节标注策略对原始病虫草害防治文本标注, 采用8:2的比例随机划分训练集和测试集, 再对训练集按照8:2比例随机划分得到新的训练集和验证集, 数据集的实体和关系分布见表 3。
| 抽取目标 Extraction target | 元素 Element | 训练集 Training set | 验证集 Validation set | 测试集 Test set |
| 实体 Entity |
有边界实体 Bordered entity | 3 999 | 927 | 1 252 |
| 无边界实体 Borderless entity | 1 928 | 526 | 654 | |
| 总计 Total | 5 927 | 1 453 | 1 906 | |
| 关系 Relation |
1~4 | 2 766 | 666 | 814 |
| >4~8 | 2 009 | 502 | 649 | |
| >8 | 2 111 | 551 | 680 | |
| 总体 Total | 6 886 | 1 719 | 2 143 |
为了分析不同方法对实体边界抽取的效果, 对原始病虫草害防治文本数据的实体进行分类。若实体中包含“乳油”“病”“试剂”“草”等边界字符则该实体为有边界实体, 否则为无边界实体。为了分析每一条语句所包含的关系数, 按照语句中包含的关系数范围在1~4、>4~8和>8 3种情况对训练集、验证集和测试集进行分类。
2.3 JE-DPW模型构建与参数设置本文的试验处理平台为Super Sever服务器, 处理器为Inter(R)Xeon(R)CPU E5-2670 v3, 主频为2.3 GHz, 内存为512 GB, 硬盘为10 TB, 显卡型号NVIDIA Quadro K5200。运行环境:Windows Server 2012, Pytorch-0.4.1, Python3.6。
模型参数设置如表 4所示。本文使用word2vec生成字向量, 根据Lin等[23]的研究, 语句中每个字对应的向量维度的范围可选{50, 60, …, 300}, 由于本文语句的平均长度为92.7个字符, 因此文本设置字向量维度(embedding_size)为100。模型中的学习速率(learning rate)范围为{0.01, 0.001, 0.000 1}, 本文为0.001。为防止神经网络模型过拟合, 设置丢弃率为0.5[11]。试验中使用小批量随机梯度下降法进行反向梯度传递, 在批处理时, 每一批处理64条病虫草害防治语句, 即batch_size为64[24]。编码层和解码层中LSTM的隐藏层单元数分别记为LSTMe_hidden_units、LSTMd_hidden_units, 隐藏单元数根据Zheng等[13]经验以及试验结果设置为150。
| 参数 Parameter |
参数值 Parameter value |
| 字向量维度 Embedding size | 100 |
| 学习速率 Learning rate | 0.001 |
| 丢弃率 Dropout rate | 0.5 |
| 批处理大小 Batch size | 64 |
| 隐藏层大小 Hidden units size | 150 |
为了验证JE-DPW算法训练的模型在实体识别和关系抽取上的性能, 本文设置的对比试验如下:以BiLSTM作为实体识别网络[25], 利用表 3中训练集和验证集共7 380个实体进行训练和调参, 并且将该试验得到的模型记为E-BiLSTM模型。使用6 886个关系作为数据集, 以RNN和LSTM作为关系分类网络[26], 将RNN、LSTM网络训练的关系抽取模型分别记为R-RNN模型、R-LSTM模型。对原始联合抽取算法, 通过训练集和验证集的训练和调参之后得到的模型记为BiLSTM-WA模型。
2.5 模型评价指标实体关系抽取领域主要有3项基本的评价指标:准确率(precision, P)、召回率(recall, R)和准确率与召回率的调和平均值(F1)[22]。准确率和召回率分别从查准率和查全率2种不同的角度对实体关系抽取效果进行评估。对于实体关系抽取任务来说, 准确率和召回率是相互影响的, 二者存在互补关系, 因此F1值综合考虑了准确率和召回率的信息。具体计算公式如下:
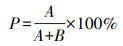
|
(12) |
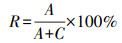
|
(13) |
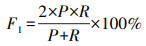
|
(14) |
式中:A表示正确识别的实体关系数; B表示错误识别的实体关系数; C表示没有识别出来的实体关系数。
3 试验结果与分析 3.1 实体识别对比试验为了验证JE-DPW模型对病虫草害防治文本中无边界实体识别的优越性, 使用包含315条病虫草害防治语句的测试集对JE-DPW模型、BiLSTM-WA模型以及E-BiLSTM模型进行测试, 表 5为3种模型对实体识别结果的评价表。
| 场景 Scenes |
模型 Model |
准确率/% Precision |
召回率/% Recall |
平均值 F1 measure |
| 无边界实体 Borderless entity |
E-BiLSTM | 79.8 | 78.7 | 79.2 |
| BiLSTM-WA | 85.2 | 82.8 | 84.0 | |
| JE-DPW | 88.1 | 86.1 | 87.0 | |
| 有边界实体 Boundary entity |
E-BiLSTM | 84.4 | 82.7 | 83.7 |
| BiLSTM-WA | 91.3 | 89.0 | 90.1 | |
| JE-DPW | 92.9 | 91.0 | 91.9 | |
| 全部语料 All corpus |
E-BiLSTM | 82.3 | 80.7 | 81.5 |
| BiLSTM-WA | 89.2 | 86.9 | 88.0 | |
| JE-DPW | 91.3 | 89.4 | 90.3 |
对于无边界实体, 实体关系联合抽取的JE-DPW模型和BiLSTM-WA模型的准确率分别为88.1%和85.2%, 比E-BiLSTM流水线模型分别提高8.3%和5.4%。分析原因是联合抽取方法可以充分利用实体识别和关系分类2个子任务的互相影响, 在输出字符实体标签的同时也输出关系标签, 利用其交互信息提升模型的性能。对全部语料的实体识别, JE-DPW联合抽取算法训练的模型F1值为90.3%, 比原始BiLSTM-WA模型提高2.3%, 说明相比于单行LSTM解码网络, BiLSTM利用上下文的语义信息增强了模型对语义特征提取的能力, 因此改进后模型实体识别效果提升。3种模型JE-DPW、BiLSTM-WA、E-BiLSTM对有边界实体识别的精度分别达到92.9%、91.3%、84.4%, 均高于无边界实体, 说明带有特殊边界的实体其字符语义信息更强, 识别的精度更高。
图 3为不同方法识别的实体数情况。从图 3-a可以看出:JE-DPW模型、BiLSTM-WA模型、E-BiLSTM模型识别的实体数相差不大, 分别为1 865、1 856、1 868;JE-DPW模型正确识别的实体数是1 703, 比BiLSTM-WA和E-BiLSTM分别多46和165, 错误识别的实体数为162, 分别比BiLSTM-WA模型和E-BiLSTM模型少37和168, 说明JE-DPW模型抽取效果更优。

|
图 3 利用不同模型识别实体的统计图 Fig. 3 The statistical charts for entities recognition using different models |
实体识别错误主要分为3种情形:类型错误、歧义错误、边界错误。类型错误指实体边界正确, 但是类型错误, 如表 6中E-BiLSTM模型将草害实体“千金子”错误地识别为药剂类型实体。歧义错误指该实体表示的意思有多种, 如虫害实体“二化螟”包含“一代二化螟”“二代二化螟”“三代二化螟”等。边界错误指实体类型识别正确但是边界发生错误, 如表 6中对药剂实体“吡嘧磺隆”3种模型都把该实体识别为药剂类型(DRU), 但是识别的实体名称为“吡嘧磺”, 缺少了边界字符。从图 3-b可以看出:JE-DPW、BiLSTM-WA、E-BiLSTM发生实体边界错误数分别为147、176和295, 边界错误占总错误数的比例分别为88.3%、88.4%、89.4%, 因此实体边界错误是实体识别的主要错误。从图 3-c可见:E-BiLSTM模型在抽取实体时, 边界错误的实体中有155个属于无边界实体, 而JE-DPW模型中, 边界错误的实体仅有76个属于无边界实体, 比E-BiLSTM模型少79个; 在无边界实体识别上, JE-DPW模型的抽取效果明显优于E-BiLSTM模型。JE-DPW模型比BiLSTM-WA模型对无边界实体识别的错误数少18个, 表明在解码层使用BiLSTM网络对文本特征提取的能力强于使用单向LSTM网络, 在实体抽取上所得到的语义信息更充分。
| 元素 Element |
语句:秧田播种后3~10 d, 稗草1.5叶期之前, 可以使用吡嘧磺隆、水星、一克净来防治。选用安全性丙草胺或易抛乐或农思它等药剂, 防治水稻千金子。 | |
| 原始标注 Original callout |
str:[稗草, 千金子] dru:[吡嘧磺隆, 水星, 一克净, 丙草胺, 易抛乐, 农思它] |
|
| 模型Model | E-BiLSTM | str:[稗草] dru:[吡嘧磺, 水星, 一克净, 安全性丙草胺, 易抛乐, 农思它, 千金子] |
| BiLSTM-WA | str:[稗草, 千金子] dru:[吡嘧磺, 水星, 一克净, 丙草胺, 易抛乐, 农思它] |
|
| JE-DPW | str:[稗草, 千金子] dru:[吡嘧磺, 水星, 一克净, 丙草胺, 易抛乐, 农思它] |
|
为了验证JE-DPW模型对药剂与病虫草害之间多关系抽取的适用性和稳定性, 使用包含315条语句的测试集对JE-DPW模型、E-RNN模型、R-LSMT模型进行测试。使用表 3中不同关系条数的测试集对上述3种模型分别测试, 得到不同模型抽取的准确率、召回率的F1值变化情况(图 4)。

|
图 4 利用不同模型识别关系的统计图 Fig. 4 The statistical charts for relation recognition using different models |
从图 4-a可见:JE-DPW模型的准确率为76.8%, 比单独抽取关系的R-RNN模型和R-LSTM模型分别高出了22.6%和19.7%。JE-DPW模型的准确率、召回率、F1值比原始BiLSTM-WA模型分别高出5.6%、4.6%、5.0%, 主要的原因是JE-DPW模型中以BiLSTM作为解码网络, BiLSTM从前向传播和反向传播2个方向解析特征, 充分考虑上下文的语义信息, 抽取得到的病虫草害防治文本的特征信息更丰富, 增强了模型的关系抽取能力。
从图 4-b可见:随着语句关系对个数的增加, JE-DPW模型的F1值由70.1%降至61.5%。主要的原因是, 当关系数在1~4范围内时, 语义信息较为简单, 利用注意力机制判断当前字符与之前非O字符之间是否存在关系时, 噪声较少。而当关系对个数增多时, 则需要判断实体对之间是否存在关系的次数增多, 出错率也增加, 并且由于文本中含有较多对药剂的使用说明以及病虫草害发病时间的说明信息, 当关系增多时实体数量在增多, 与关系抽取无关的说明信息也在增多, 关系抽取的性能下降。虽然JE-DPW模型抽取的F1值逐渐下降, 但是在不同关系对场景下比BiLSTM-WA、R-RNN、R-LSTM模型至少高出3.11%、13.1%、17.4%, 因此本文设计的JE-DPW模型关系抽取的整体鲁棒性更好。
从表 7可以看出, JE-DPW模型正确识别的关系数为1 746, 比BiLSTM-WA模型、R-LSTM模型和R-RNN模型分别多381、632和723, 错误识别的关系数为445, 比上述3种模型分别少108、392和419。因此本文提出的算法所训练的模型更适用于病虫草害与药剂之间的关系抽取。
| 模型 Model |
总关系数 Total relation number |
识别数 Identify number |
识别正确数 Identify right number |
识别错误数 Identify wrong number |
| R-RNN | 2 396 | 1 887 | 1 023 | 864 |
| R-LSRM | 2 396 | 1 951 | 1 114 | 837 |
| BiLSTM-WA | 2 396 | 1 918 | 1 365 | 553 |
| JE-DPW | 2 396 | 1 921 | 1 746 | 445 |
水稻病虫草害防治文本中含有大量无边界实体, 具有多关系特点, 本文利用实体-关系同时标注的方式, 在解码层设计了一种双向BiLSTM算法, 并在分类器上结合注意力机制实现了水稻病虫草害与药剂实体关系联合抽取(JE-DPW)。对包含7 380个实体、8 605个关系的病虫草害防治文本训练实体关系联合抽取模型并测试, 获得如下结论:
1) 利用JE-DPW算法训练的模型对全部语料的实体识别测试, 准确率达到91.3%, 比BiLSTM-WA模型和流水线E-BiLSTM模型分别提高2.1%和9.0%。在关系抽取上准确率和F1值分别为76.8%和68.3%。
2) JE-DPW模型可以有效识别无边界实体。将实体-关系抽取问题转变为多标记分类问题, JE-DPW模型利用实体-关系之间的交互信息提升算法对无边界实体识别能力, 准确率为88.1%, 比BiLSTM-WA和E-BiLSTM分别高出2.9%和8.3%;JE-DPW模型识别出边界错误的实体为76个, 均为无边界实体, 比BiLSTM-WA和E-BiLSTM少18和79个。
3) JE-DPW模型可以抽取文本语料中病虫草害与药剂之间的多关系。该模型在多关系抽取上的准确率比BiLSTM-WA模型、R-RNN模型、R-LSTM模型分别高出5.6%、22.6%、19.7%。JE-DPW模型正确识别的关系数为1 746, 比BiLSTM-WA、R-RNN、R-LSTM 3种对比模型分别多390、632、723个; 错误识别数为445个, 比上述3种模型分别少108、392、419个。随着关系数量的增加, 虽然JE-DPW模型的抽取准确率有所下降, 但是各类评价指标均优于BiLSTM-WA模型。相比于R-RNN、R-LSTM模型, 其关系抽取的F1值可保持17.4%~20.1%的优势。
| [1] |
漆桂林, 高桓, 吴天星. 知识图谱研究进展[J]. 情报工程, 2017, 3(1): 4-25. Qi G L, Gao H, Wu T X. The research advances of knowledge graph[J]. Technology Intelligence Engineering, 2017, 3(1): 4-25 (in Chinese with English abstract). |
| [2] |
Marrero M, Urbano J, Sánchez-Cuadrado S, et al. Named entity recognition:fallacies, challenges and opportunities[J]. Computer Standards & Interfaces, 2013, 35(5): 482-489. |
| [3] |
Kumar S. A survey of deep learning methods for relation extraction[EB/OL]. (2017-08-13)[2018-06-12]. https://arxiv.org/pdf/1705.03645.pdf.
|
| [4] |
鄂海红, 张文静, 肖思琪, 等. 深度学习实体关系抽取研究综述[J]. 软件学报, 2019, 30(6): 1793-1818. E H H, Zhang W J, Xiao S Q, et al. Survey of entity relationship extraction based on deep learning[J]. Journal of Software, 2019, 30(6): 1793-1818 (in Chinese with English abstract). |
| [5] |
王春雨, 王芳. 基于条件随机场的农业命名实体识别研究[J]. 河北农业大学学报, 2014, 37(1): 132-135. Wang C Y, Wang F. Study on recognition of Chinese agricultural named entity with conditional random fields[J]. Journal of Hebei Agricultural University, 2014, 37(1): 132-135 (in Chinese with English abstract). |
| [6] |
李想, 魏小红, 贾璐, 等. 基于条件随机场的农作物病虫害及农药命名实体识别[J]. 农业机械学报, 2017, 48(S1): 178-185. Li X, Wei X H, Jia L, et al. Recognition of crops, diseases and pesticides named entities in Chinese based on conditional random fields[J]. Transactions of the Chinese Society for Agricultural Machinery, 2017, 48(S1): 178-185 (in Chinese with English abstract). |
| [7] |
冯艳红, 于红, 孙庚, 等. 基于BLSTM的命名实体识别方法[J]. 计算机科学, 2018, 45(2): 261-268. Feng Y H, Yu H, Sun G, et al. Named entity recognition method based on BLSTM[J]. Computer Science, 2018, 45(2): 261-268 (in Chinese with English abstract). |
| [8] |
Zhang Y J, Zheng W, Lin H F, et al. Drug-drug interaction extraction via hierarchical RNNs on sequence and shortest dependency paths[J]. Bioinformatics, 2018, 34(5): 828-835. DOI:10.1093/bioinformatics/btx659 |
| [9] |
Li F, Zhang M, Fu G, et al. A Bi-LSTM-RNN model for relation classification using low-cost sequence features[EB/OL]. (2016-08-27)[2018-07-01]. https://arxiv.org/pdf/1608.07720.pdf.
|
| [10] |
Miwa M, Bansal M. End-to-end relation extraction using LSTMs on sequences and tree structures[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: Association for Computational Linguistics, 2016: 1105-1116.
|
| [11] |
Feng Y T, Zhang H J, Hao W N, et al. Joint extraction of entities and relations using reinforcement learning and deep learning[J]. Computational Intelligence and Neuroscience, 2017, 2017: 1-11. |
| [12] |
Zheng S C, Hao Y X, Lu D Y, et al. Joint entity and relation extraction based on a hybrid neural network[J]. Neurocomputing, 2017, 257: 59-66. DOI:10.1016/j.neucom.2016.12.075 |
| [13] |
Zheng S, Wang F, Bao H, et al. Joint extraction of entities and relations based on a novel tagging scheme[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada, July 30-August 4, 2017: 1227-1236.
|
| [14] |
Katiyar A, Cardie C. Going out on a limb: joint extraction of entity mentions and relations without dependency trees[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics.Vancouver, Canada, July 30-August 4, 2017: 917-928.
|
| [15] |
Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2014-04-20)[2018-12-13]. http://arxiv.org/pdf/1301.3781.pdf.
|
| [16] |
Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[EB/OL]. (2016-05-19)[2019-03-02]. https://arxiv.org/pdf/1409.0473.pdf.
|
| [17] |
Sun Junyi.结巴中文分词[EB/OL]. (2014-02-01)[2018-12-19]. https://github.com/fxsjy/jieba.
|
| [18] |
Thomas Roten. A Python wrapper around the NLPIR/ICTCLASchinese segmentation software[EB/OL]. (2015-08-07)[2019-03-14]. https://github.com/tsroten/pynlpir.
|
| [19] |
Zhou L N, Zhang D S. NLPIR:a theoretical framework for applying natural language processing to information retrieval[J]. Journal of the American Society for Information Science and Technology, 2003, 54(2): 115-123. |
| [20] |
Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. DOI:10.1162/neco.1997.9.8.1735 |
| [21] |
Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003, 3(6): 1137-1155. |
| [22] |
曹明宇, 杨志豪, 罗凌, 等. 基于神经网络的药物实体与关系联合抽取[J]. 计算机研究与发展, 2019, 56(7): 1432-1440. Cao M Y, Yang Z H, Luo L, et al. Joint extraction of drug entities and relationships based on neural networks[J]. Journal of Computer Research and Development, 2019, 56(7): 1432-1440 (in Chinese with English abstract). |
| [23] |
Lin Y, Shen S, Liu Z, et al. Neural relation extraction with selective attention over instances[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany, 2016: 2124-2133.
|
| [24] |
夏天赐, 孙媛. 基于联合模型的藏文实体关系抽取方法研究[J]. 中文信息学报, 2018, 32(12): 76-83. Xia T C, Sun Y. Tibetan entity relation extraction based on joint model[J]. Journal of Chinese Information Processing, 2018, 32(12): 76-83 (in Chinese with English abstract). |
| [25] |
Wang D X, Liu X, Luo H Z, et al. A novel framework for semantic entity identification and relationship integration in large scale text data[J]. Future Generation Computer Systems, 2016, 64: 198-210. DOI:10.1016/j.future.2015.08.003 |
| [26] |
Ebrahimi J, Dou D. Chain based RNN for relation classification[C]//Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Denver, Colorado, May 31-June 5, 2015: 1244-1249.
|