
文章信息
- 秦伏亮, 沈明霞, 刘龙申, 孙玉文, 郑荷花, 陆鹏宇
- QIN Fuliang, SHEN Mingxia, LIU Longshen, SUN Yuwen, ZHENG Hehua, LU Pengyu
- 基于音频技术的白羽肉鸡咳嗽识别算法研究
- Study on recognition algorithm of white feather broiler cough based on audio technology
- 南京农业大学学报, 2020, 43(2): 372-378
- Journal of Nanjing Agricultural University, 2020, 43(2): 372-378.
- http://dx.doi.org/10.7685/jnau.201905056
-
文章历史
- 收稿日期: 2019-05-31




2. 新希望六合股份有限公司, 山东 青岛 266100
2. New Hope Liuhe Co., Ltd., Qingdao 266100, China
现代规模化饲养中, 肉鸡四季高发呼吸道疾病, 是制约肉鸡健康发展的重要因素[1]。在诸多种类的肉鸡呼吸道疾病中(如新城疫、传染性支气管炎等), 咳嗽是一种较为主要的临床表现[2]。目前肉鸡养殖中对于肉鸡是否感染呼吸道疾病主要依靠饲养员夜间观察, 劳动力成本高且不能保证实时性与有效性。因此, 准确实时地自动检测肉鸡咳嗽情况, 能够提升肉鸡生产效益, 提高养殖生产率[3]。
随着数字声音技术的发展, 农场动物声音的分析研究已成为研究热点[4-7]。国内外学者将声音识别技术广泛地应用到畜禽养殖生物信息监测中, 并取得了一定的成果。Silva等[8]提出一种利用不同麦克风之间声音信号到达时间的差异来定位咳嗽声的算法, 对咳嗽猪进行定位并确定危险区, 用于早期的定点治疗以减少抗生素的使用; Carpentier等[9]提出一种针对呼吸道疾病的小牛舍中咳嗽自动检测方法, 将小牛舍中牛的声音利用谱减法滤波处理后, 进行声音事件选择, 利用小牛咳嗽声和非咳嗽声信噪比的不同对小牛咳嗽进行检测识别; 黎煊等[10]提出了基于深度信念网络(DBN)的猪咳嗽声识别方法, 将短时能量和梅尔频率倒谱系数(MFCC)作为组合特征参数, 构建了一个5层深度信念网络猪咳嗽声识别模型, 在生猪养殖发生呼吸道疾病的初期, 对其进行疾病预警; 徐亚妮等[11]利用母猪咳嗽声和尖叫声的功率谱密度差异特征, 运用改进的模糊C均值聚类算法对母猪咳嗽声和尖叫声进行识别分类, 对母猪咳嗽声识别算法进行进一步研究。但国内尚无肉鸡咳嗽识别方面的研究报道。
自动语音识别(ASR)中较成功的传统建模方法是使用隐马尔可夫模型(HMM)作为子词(如音素、音节等)或全字语音单元的声学模型[12-13]。本文将高斯混合模型-隐马尔可夫模型(GMM-HMM)引入肉鸡声音识别研究, 并通过试验合理降低其计算复杂度, 旨在设计高效、精准的肉鸡咳嗽声识别算法, 为建立肉鸡早期呼吸系统疾病智能自动诊断系统提供理论与技术支持。
1 材料与方法 1.1 试验对象与音频采集肉鸡声音采集于山东潍坊新希望有限公司下属的六合新润肉鸡养殖中心。试验选择36只5周龄的白羽肉鸡, 经饲养专员诊断所选肉鸡感染呼吸道疾病, 且有明显的咳嗽症状。在试验鸡舍内建立如图 1所示的声音采集室, 四周及上、下采用透明隔音板, 尽可能减少环境噪声对采音质量的影响。在采音室内两侧安装网络拾音器, 该设备可连续录音, 录音通过TCP/IP协议传输到协议主机, 所有声音以16位、48 kHz采样率进行采集。

|
图 1 肉鸡声音采集室 Fig. 1 Chamber for broiler sounds collection |
肉鸡饲喂后, 将其放入采音室中进行肉鸡声音数据的采集。对采集的声音进行人工标记与分类, 获得目标样本(肉鸡咳嗽声)与非目标样本(如鸣叫和其他噪声)。
1.3 预处理试验中虽然做了隔音处理, 采集到的肉鸡声音仍包含有大量噪声与干扰数据, 需进行预处理, 有效提取出目标样本并减小噪声对样本特征提取的影响。本研究主要步骤有去噪和分帧加窗。
1.3.1 基于MMSE谱减法的声音增强目前在音频识别研究中, 采用声音增强算法提高声音识别系统前端预处理的抗噪声能力。为减小传统谱减法滤波后产生“音乐噪声”的影响, 本文采用利用均方误差最优选择减法参数的MMSE谱减法。谱减法的基本原理[14]为:
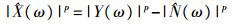
|
(1) |
式中: 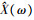
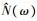
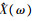
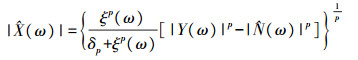
|
(2) |
式中:δp对于给定的幂指数p为常数, 当p等于1和2时, δp分别等于0.214 6和0.5;ξ(ω)是先验信噪比。为了防止对低能量声音段的过度抑制, 针对式(2)采用一个谱下限。通过对衰减后的带噪声音谱μY(ω)(0 < μ < 1)和前一帧增强且平滑后的声音谱进行平均, 可以得到平滑的频谱下限:
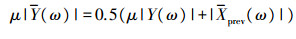
|
(3) |
式中: 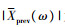

|
(4) |
式中:μ为频谱下限常数, 本研究设为0.1。
图 2所示为MMSE谱减法处理前、后的肉鸡声音样本波形图, 对比可知, 该声音增强算法去噪效果明显, 失真极小。

|
图 2 肉鸡声音样本滤波前、后对比 Fig. 2 Comparison of original broiler sounds and sounds after filtering |
动物发声是十分复杂的非平稳信号, 一般认为在10~30 ms内声音信号特性基本不变或变化缓慢[15]。本文设置分析帧长度为25 ms, 帧间重叠10 ms, 加汉明窗防止频谱泄露。汉明窗的表达式为:
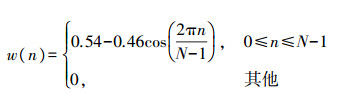
|
(5) |
式中:w(n)为窗函数; N为窗长。
1.4 肉鸡咳嗽特征参数提取声信号特征作为表征声音本质的参数, 其选取的好坏直接影响声音分类识别模型的效果。传统的声音信号频谱是采用固定窗的傅里叶变换得到, 傅里叶变换能够对窗内平稳信号提供精确的频率分量。但是声音是非平稳信号, 基于短时平稳假设的固定窗傅里叶变换将会模糊声音的细节特征, 引起信息丢失。相比傅里叶变换只能在频域对声音信号分析, 小波变换具有更加精确的局部描述及信号特征的分离[16]。本文提出一种基于小波变换的改进梅尔频率倒谱系数(MFCC)特征提取算法——WMFCC。
WMFCC特征提取与传统MFCC大致相同, 只是将正余弦函数换成了小波函数, 并且通过频率合成解决了傅里叶变换窗口固定的问题[17]。WMFCC特征参数提取流程如图 3所示。

|
图 3 基于小波变换的梅尔频率倒谱系数(WMFCC)特征提取流程 Fig. 3 Wavelet Mel frequency cepstrum coefficient(WMFCC)feature extraction process |
具体方法如下:
1) 对肉鸡声音信号进行预加重、加窗和分帧处理;
2) 将肉鸡声音样本信号用Haar小波进行小波分解。每帧2 048个样点, 帧移为1 024个样点, 进行3层小波变换, 从第1层到第3层, 信号的频段逐次升高, 得到维数分别为256、256、512、1 024的小波系数;
3) 对分层后的小波系数进行傅里叶变换, 得到不同频率段的频谱;
4) 频率合成:根据系数所属频段将FFT结果重构成一个完整的频谱, 最终得到有2 048个样点的频谱;
5) 将合成的信号输入Mel滤波器组得到Mel频率, 取对数能量并对其做DCT变换, 最终得到基于小波变换的改进MFCC特征参数。
1.5 声学建模识别在1.2节对肉鸡咳嗽声进行人工获取样本时发现, 随着肉鸡个体差异、自身活动及环境的变化, 肉鸡咳嗽的时长及波形具有一定差异性, 经过1.4节特征提取后, 每个样本的特征参数维数不同。由于神经网络、支持向量机等机器学习方法都需要固定长度的输入, 同时考虑到声音信号的时序性, 因此本文采用目前声音识别领域较为成熟的高斯混合模型-隐马尔可夫模型(GMM-HMM)作为识别肉鸡咳嗽的声学模型, 它具有强大的动态性、容错性和鲁棒性, 对不同个体的声音也能分类归并, 获得较好的识别结果[18-19]。
1.5.1 GMM-HMM模型HMM模型作为声音信号统计模型, 在音频识别领域已获得广泛应用。HMM过程是双重随机过程:具有一定状态数的隐式马尔科夫链和显式随机函数集, 这2个随机过程共同描述了声音信号, 其中声音信号瞬时特征由对应状态观测符号的随机过程描述(可观测的), 而信号随时间的变化由隐马尔可夫的状态转移概率描述(隐含的)。
模型中的状态Y与肉鸡咳嗽的音素或音节等声音单位对应, 表示为{y1, y2, …, yi}, 其中yi∈Y, 代表时刻i的状态。而把声音单位的声音信号特征作为对应声音单元的观测量, 表示为{x1, x2, …, xi}, xi∈X代表时刻i的观察值。通常设yi的可能取值个数为N, 定义xi的取值范围为{o1, o2, …, om}。
HMM模型通常采用λ=[A, B, π]来表示[20]。其各自含义如下:
1) A=[aij]N×N, 表示隐状态之间转移概率矩阵, aij为yi, yj状态之间的转移概率;
2) B=[bij]N×M, 表示观测状态概率矩阵, bij为状态yi生成观测值oj的概率;
3) π=[πi]N, 表示隐藏状态起始概率矩阵, πi为隐状态初始为yi的概率。
混合高斯模型(GMM)是一种将多个高斯分布进行混合的统计模型, 在GMM-HMM中GMM用于拟合HMM模型中的参数观测矩阵B。
1.5.2 识别方法将肉鸡咳嗽和鸣叫2种声音样本特征用混合高斯模型(GMM)去模拟, 其均值和方差生成观测值序列输入到HMM中, 训练估计参数λ=[A, B, π], 分别建立1个HMMλ; 对每一个要识别的发声段提取其特征, 经过GMM生成观测矢量序列O={O1, O2, …, OM}; 求O在每个HMMλ模型下的概率P(O/λ), 选择得分最高的模型对应的声音作为识别结果。
2 结果与分析 2.1 特征对比分析本文选取肉鸡发声活动中较为常见的鸣叫声和咳嗽声进行对比识别分类。从图 4-a可以看出, 肉鸡咳嗽声和鸣叫声的主要频率范围都在5 000 Hz以下, 其中肉鸡鸣叫声频段主要在1 000 Hz以下, 而咳嗽声频段主要集中在500~3 000 Hz, 两者之间有小部分重叠。从图 4-b频谱图可以看出, 肉鸡咳嗽声频谱较强且逐渐减弱, 类似一个脉冲; 而在肉鸡鸣叫声整个发声段内其频谱近乎保持稳定。此外, 图 4-c显示了在低于5 000 Hz的部分, 咳嗽声的功率谱密度比鸣叫声的功率谱密度波动性更大。

|
图 4 肉鸡咳嗽声与鸣叫声的频域、频谱、功率谱密度及WMFCC特征图 Fig. 4 Frequency domain, spectrogram, power spectrum density and WMFCC feature map of broiler ' s cough and chirping |
图 4-d为肉鸡咳嗽声及鸣叫声的基于小波变换的WMFCC特征图, 2种声音之间的WMFCC特征存在明显差异, 这是我们进行分类识别的有效基础。本文以WMFCC特征参数为基础, 构建并训练GMM-HMM声学识别模型。
2.2 分类识别结果 2.2.1 MFCC与WMFCC特征的识别效果对比试验组选取30只鸡, 共获取500对样本数据(1个咳嗽声和1个鸣叫声为1对), 分别提取样本MFCC及改进的WMFCC特征, 训练GMM-HMM模型。表 1中, 13维特征参数为每个特征提取器设定参数个数, 26维特征参数包含13维特征参数本身及其一阶差分, 39维特征参数包含13维特征参数本身、其一阶差分及其二阶差分。由表 1可见:与MFCC相比, 利用WMFCC特征进行咳嗽识别平均识别率提高了2%, 在任一特征维度上WMFCC都有更好的表现。而且, 无论利用哪种特征, 当每帧特征参数维数适当增加后, 识别率都有一定的提升, 取26维特征参数时识别效果最优。
| 特征类型 Feature type |
不同特征维度Different feature dimensions | ||
| 13 | 26 | 39 | |
| MFCC | 94.7 | 96.4 | 96.1 |
| WMFCC | 97.5 | 98.7 | 97.6 |
以每帧26维特征参数个数提取肉鸡声音样本特征, 进行GMM-HMM模型训练并对参数调优(主要改变隐状态数n与混合高斯元个数m), 测试得到最终各自的识别正确率(表 2)。
| 混合高斯数(m) Gaussian mixture number |
隐状态数(n)Number of hidden states | |||||
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 1 | 87.7 | 92.7 | 96.3 | 96.3 | 95.2 | 94.0 |
| 2 | 87.9 | 88.9 | 96.4 | 96.3 | 96.3 | 93.0 |
| 3 | 92.7 | 92.7 | 98.7 | 96.5 | 95.2 | 94.0 |
| 4 | 90.3 | 96.3 | 98.7 | 97.5 | 97.5 | 97.5 |
| 5 | 91.5 | 96.3 | 97.5 | 96.3 | 94.0 | 96.3 |
| 6 | 92.7 | 94.0 | 95.2 | 94.0 | 94.0 | 94.0 |
由表 2可得, 在隐状态数为3, 每个状态对应3个混合高斯分量时, GMM-HMM模型达到最优识别率, 为98.7%。一般HMM状态输出由3个单高斯密度分布加权混合构成, 数目越多识别率越高, 隐状态数也是如此(传统HMM模型每个音节分配6个状态数)。但在本研究肉鸡咳嗽识别中, 隐状态数3以上, 模型正识率不再提高, 高斯分量个数的增加也对识别效果影响甚微, 此种情况下, 我们选择隐状态数为3, 高斯元个数为3, 不仅得到系统最优的识别性能, 同时大大减少不必要的运算量, 提高了该模型识别效率。
2.3 试验验证选取6只肉鸡作为测试组。每只肉鸡进行4次试验, 每次试验采集肉鸡30 min发声数据, 为验证本文算法实用性, 经人工分类后选取每只肉鸡200次咳嗽数据, 将其输入到本文模型中。试验结果(表 3)表明:本文模型判断肉鸡咳嗽的平均准确率为95%;准确率最高的为5号肉鸡(准确率达98%)。本文提出的肉鸡咳嗽算法模型能较好地检测肉鸡咳嗽。
| 肉鸡编号 Broiler No. |
模型检出咳嗽声次数 The cough times of the model outputs |
模型检出鸣叫声次数 The chirping times of the model outputs |
准确率/% Precision rate |
| 1 | 193 | 7 | 96.5 |
| 2 | 182 | 18 | 91.0 |
| 3 | 185 | 15 | 92.5 |
| 4 | 189 | 11 | 94.5 |
| 5 | 196 | 2 | 98.0 |
| 6 | 195 | 5 | 97.5 |
1) 本文提出了一种基于音频技术的肉鸡咳嗽识别方法, 在广泛研究肉鸡声音特点与GMM-HMM不同参数选择对模型的影响作用后, 试验得到了一个最优的肉鸡咳嗽识别模型。测试结果表明, 其平均正确率达95%, 表明该方法可作为肉鸡呼吸系统疾病早期自动诊断的手段之一。
2) 利用小波变换的特点对声音识别传统的MFCC特征进行改进, 试验结果表明利用改进后的WMFCC特征, 系统的识别正确率有了较大提升。
3) 本文试验环境较为单一, 对于多噪声大群体复杂情况下肉鸡咳嗽的识别效果有待验证, 这也是后期算法进一步研究的方向。
| [1] |
张海燕. 鸡呼吸道疾病发病特点及防治[J]. 畜牧兽医科技信息, 2016(7): 103-104. Zhang H Y. Characteristics and prevention of respiratory diseases in chickens[J]. Journal of Animal Husbandry and Veterinary Medicine, 2016(7): 103-104 (in Chinese). |
| [2] |
钟扬万. 肉鸡呼吸道疾病特点及综合防治[J]. 畜禽业, 2016(5): 78. Zhong Y W. Characteristics and comprehensive prevention of respiratory diseases in broiler chickens[J]. Livestock & Poultry Industry, 2016(5): 78 (in Chinese). |
| [3] |
汪开英, 赵晓洋, 何勇. 畜禽行为及生理信息的无损监测技术研究进展[J]. 农业工程学报, 2017, 33(20): 197-209. Wang K Y, Zhao X Y, He Y. Review on noninvasive monitoring technology of poultry behavior and physiological information[J]. Transactions of the Chinese Society of Agricultural Engineering, 2017, 33(20): 197-209 (in Chinese with English abstract). |
| [4] |
Xie L, Lee T, Mak M-W. Guest editorial:advances in deep learning for speech processing[J]. Journal of Signal Processing Systems, 2018, 90(7): 959-961. |
| [5] |
曹晏飞, 余礼根, 滕光辉, 等. 蛋鸡发声与机械噪声特征提取及分类识别[J]. 农业工程学报, 2014, 30(18): 190-197. Cao Y F, Yu L G, Teng G H, et al. Feature extraction and classification of laying hens' vocalization and mechanical noise[J]. Transactions of the Chinese Society of Agricultural Engineering, 2014, 30(18): 190-197 (in Chinese with English abstract). |
| [6] |
Aydin A, Bahr C, Viazzi S, et al. A novel method to automatically measure the feed intake of broiler chickens by sound technology[J]. Computers and Electronics in Agriculture, 2014, 101: 17-23. |
| [7] |
闫丽, 邵庆, 吴晓梅, 等. 基于偏度聚类的哺乳期母猪声音特征提取与分类识别[J]. 农业机械学报, 2016, 47(5): 300-306. Yan L, Shao Q, Wu X M, et al. Feature extraction and classification based on skewness clustering algorithm for lactating sow[J]. Transactions of the Chinese Society for Agricultural Machinery, 2016, 47(5): 300-306 (in Chinese with English abstract). |
| [8] |
Silva M, Ferrari S, Costa A, et al. Cough localization for the detection of respiratory diseases in pig houses[J]. Computers and Electronics in Agriculture, 2008, 64(2): 286-292. |
| [9] |
Carpentier L, Berckmans D, Youssef A, et al. Automatic cough detection for bovine respiratory disease in a calf house[J]. Biosystems Engineering, 2018, 173: 45-56. |
| [10] |
黎煊, 赵建, 高云, 等. 基于深度信念网络的猪咳嗽声识别[J]. 农业机械学报, 2018, 49(3): 179-186. Li X, Zhao J, Gao Y, et al. Recognition of pig cough sound based on deep belief nets[J]. Transactions of the Chinese Society for Agricultural Machinery, 2018, 49(3): 179-186 (in Chinese with English abstract). |
| [11] |
徐亚妮, 沈明霞, 闫丽, 等. 待产梅山母猪咳嗽声识别算法的研究[J]. 南京农业大学学报, 2016, 39(4): 681-687. Xu Y N, Shen M X, Yan L, et al. Research of predelivery Meishan sow cough recognition algorithm[J]. Journal of Nanjing Agricultural University, 2016, 39(4): 681-687 (in Chinese with English abstract). DOI:10.7685/jnau.201510035 |
| [12] |
Jiang H. Discriminative training of HMMs for automatic speech recognition:a survey[J]. Computer Speech and Language, 2010, 24(4): 589-608. |
| [13] |
王海坤, 潘嘉, 刘聪. 语音识别技术的研究进展与展望[J]. 电信科学, 2018, 34(2): 1-11. Wang H K, Pan J, Liu C. Research development and forecast of automatic speech recognition technologies[J]. Telecommunications Science, 2018, 34(2): 1-11 (in Chinese with English abstract). |
| [14] |
Loizou P C. Speech Enhancement:Theory and Practice[M]. Boca Raton: CRC Press, 2007: 75-101.
|
| [15] |
曹晏飞, 陈红茜, 滕光辉, 等. 基于功率谱密度的蛋鸡声音检测方法[J]. 农业机械学报, 2015, 46(2): 276-280, 300. Cao Y F, Chen H Q, Teng G H, et al. Detection of laying hens' vocalization based on power spectral density[J]. Transactions of the Chinese Society for Agricultural Machinery, 2015, 46(2): 276-280, 300 (in Chinese with English abstract). |
| [16] |
檀蕊莲, 柏鹏, 李哲, 等. 基于小波变换的说话人识别技术[J]. 空军工程大学学报(自然科学版), 2013, 14(1): 85-89. Tan R L, Bai P, Li Z, et al. Research on speaker recognition based on wavelet transform[J]. Journal of Air Force Engineering University(Natural Science Edition), 2013, 14(1): 85-89 (in Chinese with English abstract). |
| [17] |
薛凌云, 夏国荣. 基于小波变换的语音特征参数提取[J]. 电子世界, 2014(2): 99-100. Xue L Y, Xia G R. Speech feature extraction based on wavelet MFCC[J]. Electronics World, 2014(2): 99-100 (in Chinese with English abstract). |
| [18] |
Cho J W, Park H M. Independent vector analysis followed by HMM-based feature enhancement for robust speech recognition[J]. Signal Processing, 2016, 120: 200-208. |
| [19] |
Cai J, Bouselmi G, Laprie Y, et al. Efficient likelihood evaluation and dynamic Gaussian selection for HMM-based speech recognition[J]. Computer Speech & Language, 2009, 23(2): 147-164. |
| [20] |
洪淑月, 施晓钟, 徐皓. 改进的小波变换HMM语音识别算法[J]. 浙江师范大学学报(自然科学版), 2011, 34(4): 398-403. Hong S Y, Shi X Z, Xu H. Speech recognition algorithm based on wavelet transform and improved HMM[J]. Journal of Zhejiang Normal University(Natural Science Edition), 2011, 34(4): 398-403 (in Chinese with English abstract). |