
文章信息
- 戚超, 徐佳琪, 刘超, 吴明清, 陈坤杰
- QI Chao, XU Jiaqi, LIU Chao, WU Mingqing, CHEN Kunjie
- 基于机器视觉和机器学习技术的鸡胴体质量自动分级方法
- Automatic classification of chicken carcass weight based on machine vision and machine learning technology
- 南京农业大学学报, 2019, 42(3): 551-558
- Journal of Nanjing Agricultural University, 2019, 42(3): 551-558.
- http://dx.doi.org/10.7685/jnau.201808013
-
文章历史
- 收稿日期: 2018-08-12




目前, 关于鸡胴体的质量分级, 国外已普遍使用在线自动称量系统, 而国内除了极少数大型家禽屠宰企业引进国外此类设备实现在线自动称量分级外, 大多数中小型企业均采用人工台秤称量分级的方法, 不仅效率低、差错多, 还造成了鸡胴体的二次污染[1]。鸡胴体加工过程中的各类接触面是生产过程中的潜在污染源[2], 不仅会给生产者带来巨大的经济损失, 而且还可能引起消费者的健康问题[3]。因此, 采用基于悬挂输送的质量分级方法可以有效减少家禽胴体加工过程中的二次污染问题。近20年, 机器视觉技术在农产品品质检测与分级中已广泛应用[4-5]。李俊伟等[6]通过提取分割后的葡萄穗面积、周长、长轴及短轴长度等特征参数, 建立葡萄穗质量分级的偏最小二乘回归模型, 实现对无核白鲜葡萄质量的预测。陈坤杰等[7]搭建了一个基于机器视觉技术的鸡胴体质量分级平台, 通过提取鸡胴体的图像特征参数建立鸡胴体质量与特征参数线性模型的方式, 实现了鸡胴体在悬挂输送过程中的非接触自动质量分级, 显示基于机器视觉技术的鸡胴体质量自动分级方法, 不仅效率高, 而且可以在很大程度上减少鸡胴体的二次污染, 是一种较为理想的鸡胴体质量在线分级方法。然而, 不足的是, 尽管鸡胴体的图像特征参数与鸡胴体等级之间呈现一定的线性关系, 但利用所建立的线性模型对鸡胴体质量进行分级时, 模型的预测精度并不高, 存在较大的预测误差。因此, 本文在上述研究的基础上, 利用鸡胴体的图像特征参数及多种非线性建模技术, 建立鸡胴体质量和等级的非线性预测模型, 提高这种基于机器视觉技术的鸡胴体质量预测集分级方法的预测精度, 为该方法和技术的实际应用打下良好的技术基础。
1 材料与方法 1.1 试验材料本试验材料取自六合集团肉鸡屠宰厂, 随机选取预冷环节之后、分割包装环节之前共250个鸡胴体作为试验样本, 其中150个鸡胴体为训练集, 其余100个鸡胴体为验证集。
1.2 试验仪器及设备佳能5D Mark Ⅳ数码相机(佳能公司(中国)), Benro三脚架(广东百诺影像科技工业有限公司), 黑色背景布(娇颖布艺公司), YH/JTS-CW型号电子秤(青岛钰恒称重设备有限公司)。
1.3 样本图像采集为了模拟鸡胴体在悬挂输送线悬挂的状态并获取图像, 按生产实际所用悬挂输送线, 搭建了鸡胴体图像获取平台, 如图 1所示。数码相机固定在三脚架上, 使相机镜头距离地面120 cm, 在输送线后设置1个黑色背景布, 将鸡胴体挂在输送线的挂架上, 由于挂架定向结构, 可使鸡胴体的胸部或脊背部朝向相机方向, 本试验使鸡胸朝向相机。另外, 由于重力作用, 悬挂的鸡胴体会自然下垂, 因此, 鸡胸将垂直于相机光轴。在输送线上安装1个光电传感器, 当鸡胴体到达相机光轴位置时, 给相机1个触发信号, 相机自动采集1幅该鸡胴体图像, 图像采集完后, 立即将鸡胴体从输送线上取下称量, 记录下样本的质量, 对所有样本进行统计分析。结果如表 1所示。

|
图 1 平台硬件架构图 Fig. 1 Platform hardware architecture diagram |
| 数量Number | 最小值/gMinimum | 最大值/gMaximum | 均值/gMean value | 方差Variance | |
| 训练集Training set | 150 | 1 256 | 2 523 | 1 853.68 | 85 364.92 |
| 验证集Validation set | 100 | 1 238 | 2 496 | 1 896.83 | 76 263.43 |
| 样本总量Sample size | 250 | 1 238 | 2 523 | 1 870.23 | 82 373.68 |
采集得到的鸡胴体样本原始图像如图 2所示。为消除所采集鸡胴体图像中无关的信息, 增强有关信息的可检测性和最大限度地简化数据, 必须对原始图像进行去燥、分割等预处理。

|
图 2 鸡胴体原始图像 Fig. 2 Original photo of chicken carcass sample |
简化图像的信息量, 对采集的彩色图像进行灰度化处理, 即将3色图像处理成单色图像, 将RGB模型转换成灰度级L模型, 采用matlab的rgb2gray函数将样本原始彩色图像进行灰度变换。为了尽可能保留图像的细节特征和边缘信息, 通常要利用滤波来抑制脉冲噪声, 脉冲噪声经常以亮点的形式出现在处理过的图像中, 二值化处理易将部分图像中的亮点与鸡胴体的像素点进行混淆。本文利用matlab的medfilt2方法对灰度化后的图像进行中值滤波, 以消除样本图像因拍摄、光照、阴影等产生的脉冲噪声。经过灰度化及中值滤波处理后的图像样本如图 3所示。

|
图 3 灰度化及中值滤波处理后的图像 Fig. 3 Images after grayscale and median filtering |
为便于后续对样本图像进行特征参数的提取, 需要对样本图像进行背景去除和二值化处理。阈值分割是为了让图像像素分为0和255这2种灰度值, Otus法是按照2种像素的个数比例和灰度级中占比来计算类间方差, 类间方差最大时, 表明2种像素错分的概率最小, 阈值最佳。一般来说, Otsu法丢失的细节越少, 分割效果越好, 因此使用该算法进行图像二值化。本文采取调用matlab的graythresh函数的方法对经过灰度化和中值滤波处理后的图像样本采用Otsu方法进行背景分割和二值化处理。graythresh是用大津法求灰度图像的二值化阈值, 是一种自适应的求阈值方法。具体原理是:记T为前景与背景的分割阈值, 前景点数占图像比例为w0, 平均灰度为u0; 背景点数占图像比例为w1, 平均灰度为u1, 图像的总平均灰度为u, 则u=w0*u0+w1*u1, 建立目标函数g(t)=w0*(u0-u)2+w1*(u1-u)2, g(t)是当分割阈值为t时的类间方差表达式。OTSU算法使g(t)取得全局最大值, 当g(t)为最大时所对应的t称为最佳阈值, 因此, OTSU算法也被称为最大类间方差法, 即求出最优的阈值T, 使得目标函数g(t)的值最大。结果如图 4及图 5所示。

|
图 4 滤波后的图像 Fig. 4 Image after filterin |

|
图 5 阈值分割后的图像 Fig. 5 Image after threshold segmentation |
由于鸡胴体表面的血迹、反光等影响, 二值化处理后的样本图像会出现少量的黑色斑点, 类似于孔洞, 会影响后续特征参数提取的精度。为了寻找孔洞, 首先需要遍历鸡胴体所有外轮廓, 在每一个外轮廓里面遍历所有内轮廓, 将检测到的孔洞绘制成白色, 完成空洞填充。本文采用imfill函数对经过背景分割和二值化后样本图像中的孔洞进行填充处理, 结果如图 6所示。

|
图 6 孔洞填充后的图像 Fig. 6 Image after hole filling |
体长定义为垂直状态下, 鸡胴体最高点与最低点的距离。对于经过预处理的样本图像, 就是鸡胴体轮廓上任意2点的最远长度。通过扫描鸡胴体轮廓上的白色像素点坐标值, 依次存入集合中, 根据坐标值(x, y), 代入式(1)计算任意2个坐标点的距离, 最大值即为鸡胴体的体长。
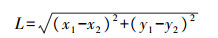
|
(1) |
鸡胴体投影面积定义为经过图像预处理后, 图像白色区域的面积。扫描鸡胴体样本的二值化图像, 图像中所有白色像素点的总个数计为A, A即表示以像素点个数为单位的鸡胴体投影面积。
1.5.3 周长(C)鸡胴体周长定义为鸡胴体图像边界所连接的最大周长。扫描鸡胴体图像的边界, 轮廓中的白色像素点的个数即为鸡胴体样本图像的周长(C)。
1.5.4 鸡胸长度和宽度1) 利用matlab中的edge函数检测鸡酮体的边缘, 得到二值化的边缘轮廓图, 将边缘图上的点坐标存入数组M; 2)对图像上的每一点, 计算与上一步所得的数组M中的距离, 得到每一点和数组点之间的最大最小距离, 即遍历二值图像中所有像素值为1的点, 计算该点到边缘矩阵M所有的距离, 记录最小距离和最大距离, 最大距离对应的坐标点即为椭圆中心(x, y), 通过不同的长、短轴长度进行椭圆方程的测算, 得到椭圆的圆心坐标和长、短轴半径; 3)一个椭圆需要5个参数, a, b为椭圆的长、短轴半径, (P, Q)为椭圆中心坐标, θ为椭圆的旋转角度; 将2)中的最大阈值对应的椭圆圆心坐标和长、短轴半径代入椭圆方程公式(2)。
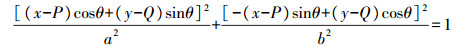
|
(2) |
4) 在参数空间中统计b和θ参数阈值, 得到峰值超过2)最大阈值的一组参数即为椭圆。定义椭圆的长轴为鸡胸长度La, 短轴为鸡胸宽度Lb。如图 7所示, 红色曲线即为理想的拟合椭圆。

|
图 7 鸡胸拟合椭圆示意图 Fig. 7 Chicken breast fitting ellipse diagram |
鸡胸面积可用拟合椭圆面积来表示, 可以通过式(3)计算得到。
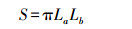
|
(3) |
式中:La表示鸡胸长度的像素个数; Lb表示鸡胸宽度的像素个数。
1.6 特征参数的标定上述特征参数A、L、C、La、Lb、S均以像素个数为单位, 为得到鸡胴体特征参数的实际值, 参照文献[7]所述图像标定方法, 对所采集样本图像进行标定, 得到在本试验条件下, 1 mm=13像素。因此, 鸡胴体的实际特征参数如下:
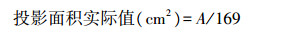
|
(4) |

|
(5) |

|
(6) |

|
(7) |
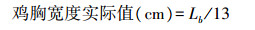
|
(8) |

|
(9) |
由于线性模型只能够解决有限的问题, 用基于图像参数建立的线性模型对鸡胴体质量等级进行预测存在较大的误差[7]。相对于线性模型, 非线性模型不仅能够拟合非线性可分的数据, 而且还能更加灵活处理复杂变量之间的关系, 用于基于多变量预测鸡胴体质量等级这类问题, 可能会获得更好的效果。本文采用的方法属于机器学习算法中的监督学习问题, 从概率角度来看, 该类问题的过程可以看作:假设X和Y满足同一个联合概率分布P(X, Y), 其中X是特征也就是自变量, Y是被预测的目标值也就是因变量, 而各类机器学习算法判别模型则会自动学习数据中的条件概率P(Y|X), 条件概率分布P(Y|X)本质上描述的就是Y与X之间的映射关系。
本文主要选用的假设类3种集成算法主要包括随机森林(random forest, RF)算法[8-9]、自适应提升(Adaboost, AB)算法[10-11]和梯度提升(gradient boosting, GB)算法[12-13]。大多数机器学习算法都是依靠类似随机梯度下降(stochastic gradient descent, SGD)[14-15]这类优化器去优化算法的损失函数, 从而使算法得到关于特征和预测目标之间的最优映射模型, 而梯度提升算法在自适应提升算法中则是直接将优化的目标作用在梯度上, 即梯度变化的残差。本文选择使用上述这3类基于决策树的集成算法作为建模假设类。
1.7.1 随机森林算法随机森林算法是1个包含多个决策树的集成算法, 本质上将多个决策树的预测结果综合加权后得到1个综合的预测结果, 具有方便调参、适合并行且效率高的特点。随机森林算法以及后面的其他集成算法的回归预测均使用CART算法(classification and regression tree)作为决策树的生成和剪枝算法, 即3类回归的集成模型的基回归器都是CART树。而在整个随机森林算法的过程中, 有2个随机过程, 第1个过程是输入数据, 随机地从整体的训练数据中选取一部分作为1棵决策树的构建, 该选取是有放回的选取; 第2个过程是从整体的特征集随机选取每棵决策树构建所需的特征, 这2个随机过程使随机森林算法很大程度上避免了过拟合现象的出现。
本文随机森林模型的建模主要参数:
1) 决策树的数量150棵。
2) 损失函数为mean squared error函数, 即模型学习的目标是使数据中的均方误差最小化。
3) 单棵决策树生成过程中的样本最小数为2, 即在回归过程中, 当某个叶节点之后的样本只有2个时, 则该方向的决策树停止继续生成。
4) 每个决策树随机抽取的特征数量为0.9, 即每棵决策树随机使用90%的特征数量进行决策树的生成, 这主要是为了让随机森林里的决策树更加多样化, 从而保证模型的泛化能力。
1.7.2 自适应提升算法自适应提升算法其本质是一种迭代算法, 提升方法(boosting)就是从弱学习器算法(决策树)出发反复学习, 每一轮学习后, 提高那些被前一轮错误预测误差大的样本的权重值, 而降低那些被前一轮错误预测误差小的样本的权重值。因而与随机森林算法类似, 都可以看作是m个决策树的线性组合, 公式如式(10):
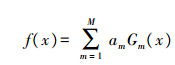
|
(10) |
式中:am表示弱学习器的系数; Gm表示弱学习器。
从依赖性和独立性角度来看:boosting中参与训练的基础学习器按照顺序生成, 序列方法的原理是利用基础学习器之间的依赖关系, 对之前训练中错误标记的样本赋值较高的权重, 以提高整体的预测效果。而另一类集成算法bagging中参与训练的基础学习器并行生成, 利用基础学习器之间的独立性, 可以显著降低错误。
本文AB算法的主要参数:
1) 决策树数量150棵, 这也代表Adaboost会迭代100次。
2) 学习率(learning rate)设置为1.0, 该值指的是每棵决策树贡献的衰减率, 当值为1时, 表示第1棵决策树的结果和第100棵决策树的结果是等权重的。
3) 损失函数使用线性函数, 该函数指的是每次迭代更新样本权重时的函数, 线性函数表示该权重的更新速度以固定的速率来更新, 该参数同样可以根据情况选择平方函数或者指数函数, 以加快权重更新。
1.7.3 梯度提升算法梯度提升算法(gradient boosting, GB)是boosting算法的一种改进, 原始的boosting算法是在算法开始时, 为每1个样本赋上1个相等的权重值, 并更新该权重。GB与传统的boosting有着很大的区别, 它的每一次计算都是为了减少上一次的残差, 而为了减少这些残差, 可以在残差减少的梯度方向上建立1个新模型。所以说, 在GB中, 每个新模型的建立是为了使得先前模型残差往梯度方向减少, 与传统的boosting算法对正确、错误的样本进行加权有着极大的区别。
本文GB算法的主要参数:
1) 决策树数量150棵, 即迭代次数为100次。
2) 学习率设置为0.1, 即每次迭代后, 下一棵决策树对预测结果的贡献仅为上一棵树的10%。
3) 损失函数使用最小二乘法, 即梯度残差矩阵的投影矩阵计算方式使用最小二乘法计算。
4) 决策树分裂度量使用的是Friedman改进均方误差。
5) 每棵树的最大树深度限定为3层。
1.8 数据处理及模型评估利用SPSS Statistics 17软件进行数据处理及建模。考虑到7个特征参数不在一个数量级且量纲不同, 为了使神经网络便于训练和收敛, 参照Z-SCORE标准化[14]的方式对数据进行无量纲化处理。对所建模型的性能, 分别采用判定系数, 即R-squared(R2)[15]和均方根误差(RMSE)[16-17]进行评价。
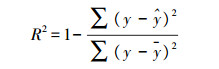
|
(11) |
式中:y表示拟合数据; y表示原始数据均值; 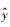
利用数据拟合模型一定会存在误差, 回归方程对观测值拟合的程度就是拟合优度。上式中1减去y对回归方程的方差和y的总方差的比值, y减去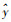
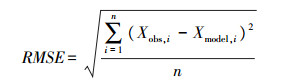
|
(12) |
式中:RMSE是观测值与真值偏差的平方与观测次数n比值的平方根; Xobs代表观测值; Xmodel代表真值, 真值用最佳值来替代; n代表实际观测次数, 且是有限的。由于方根误差对测量中特别大或者特别小的误差反应很敏感, 所以均方根误差可以很好地反映测量精密度。在统计学和机器学习回归问题中, 使用拟合优度R-squared和RMSE来判定模型性能是通用和标准的。
2 结果与分析 2.1 鸡胴体质量预测和等级判定的非线性模型及其比较分析首先按1.7节所述方法建立鸡胴体质量预测和等级判定的非线性模型, 然后对训练集样本和验证集鸡胴体样本的质量进行预测, 结果如表 2所示。
| 模型 Model |
训练集样本Training set samples | 验证集样本Validation set samples | |||
| R2 | RMSE/g | R2 | RMSE/g | ||
| 随机森林Random forest | 0.969 4 | 1.330 9 | 0.948 4 | 1.437 0 | |
| 自适应提升Adaboost | 0.937 4 | 0.580 2 | 0.939 2 | 0.682 4 | |
| 梯度提升Gradient boosting | 0.996 0 | 0.039 0 | 0.996 0 | 0.067 0 | |
由表 2可知, 在所建立的3个非线性模型中, 均属于基于树的集成模型, 3个模型的基本模型规模相等, 在3个树的集成模型中, 不论是对训练集还是对验证集, 均是梯度提升模型的判定系数最大而均方根误差最小。根据参考文献[7]所述方法, 建立鸡胴体质量等级判定的一元和多元线性模型并利用其对训练集样本和验证集样本进行判定。结果显示:在所有一元模型中, 最高的判定系数仅有0.832 3, 而RMSE则高达80.68;即便多元线性模型表现较好, R2=0.941 0, RMSE=60.32。说明线性模型无法提供足够的复杂度去更好地拟合本研究的这类数据。
如果基于树的模型, 在树的生成过程中利用梯度提升模型对各个特征参数在回归过程中的相对重要度进行计算, 结果如表 3所示。在6个特征中, 最重要的是投影面积, 其次是体长, 最不重要的是鸡胸宽度。其中前3个特征参数的相对重要度加和占比超过65%, 说明这3个特征可以解释质量变异性的65%。如果去掉鸡胸宽度, 仅测量和计算剩下5个特征, 模型仍能够解释质量变异性的95%。因此, 如果特征数据的获取成本较高, 可以考虑去掉参数鸡胸宽度。
| 序号 | 特征参数Characteristic parameters | 相对重要度Relative importance |
| 1 | 投影面积Area | 0.259 271 |
| 2 | 体长Height | 0.216 999 |
| 3 | 周长Contour | 0.175 908 |
| 4 | 鸡胸长度Chicken breast length | 0.102 392 |
| 5 | 鸡胸宽度Chicken breast width | 0.042 657 |
| 6 | 鸡胸面积Chicken breast area | 0.135 449 |
采用称量法, 将250个鸡胴体按照质量分为5个等级[7], 1级:1 000~1 300 g, 2级:1 300~1 600 g, 3级:1 600~1 900 g, 4级:1 900~2 200 g, 5级:2200~2 500。随机选取150个样本作为训练集进行建模, 另外100个样本作为验证集对模型进行验证, 如果模型判定的等级与实际称量分级一致, 即认为模型等级判定正确, 反之则判定失败。用等级判断正确的样本个数占样本总数的百分比, 即判定正确率对模型进行评价。结果(表 4)显示:在对鸡胴体质量等级进行判定时, 梯度提升模型的判定正确率最高, 为96%。
| 模型 Model |
训练集Training set | 验证集Validation set | |||
| 样本数量Sample size | 判定正确率/%Determining the weight level | 样本数量Sample size | 判定正确率/%Determining the weight level | ||
| 随机森林Random forest | 150 | 96 | 100 | 92 | |
| 自适应提升Adaboost | 150 | 93 | 100 | 90 | |
| 梯度提升Gradient boosting | 150 | 99 | 100 | 96 | |
本文是在食品加工领域内, 首次使用梯度提升模型进行非线性建模。为了改善鸡胴体加工过程中的二次污染问题, 提出一种基于机器视觉和机器学习技术的鸡胴体质量自动分级方法, 运用图像处理技术, 提取出与鸡胴体大小相关的6个特征量, 进行非线性建模, 最后利用梯度提升模型对鸡胴体质量进行分级。综合试验结果可知, 梯度提升模型的R-squared值为0.996 0, RMSE值为0.039 0, 利用梯度提升模型进行的质量分级的成功率达到96%, 预测模型明显优于其他模型, 可以为鸡胴体在线质量分级提供技术支持。
| [1] |
陈坤杰, 杨凯, 康睿, 等. 基于机器视觉的鸡胴体表面污染物在线检测技术[J]. 农业机械学报, 2015, 46(9): 228-232. Chen K J, Yang K, Kang R, et al. Online detection technology for contaminants on chicken carcass surface based on machine vision[J]. Transactions of the Chinese Society for Agricultural Machinery, 2015, 46(9): 228-232 (in Chinese with English abstract). |
| [2] |
章彬.冷鲜鸡加工及贮藏过程中的微生物调查及气调保鲜技术应用研究[D].扬州: 扬州大学, 2017. Zhang B.Microbial survey and application of modified atmosphere preservation technology in chicken processing and storage[D]. Yangzhou: Yangzhou University, 2017(in Chinese with English abstract). http://cdmd.cnki.com.cn/Article/CDMD-11117-1017238778.htm |
| [3] |
Duan D B, Wang H H, Xue S W, et al. Application of disinfectant sprays after chilling to reduce the initial microbial load and extend the shelf-life of chilled chicken carcasses[J]. Food Control, 2017, 75: 70-77. DOI:10.1016/j.foodcont.2016.12.017 |
| [4] |
申爱敏, 霍晓静, 王文娣, 等. 基于机器视觉的核桃仁大小自动分级技术[J]. 江苏农业科学, 2016, 44(9): 383-385. Shen A M, Huo X J, Wang W D, et al. Automatic size classification technology of walnut kernel based on machine vision[J]. Jiangsu Agricultural Sciences, 2016, 44(9): 383-385 (in Chinese). |
| [5] |
王伟.基于机器视觉的农产品物料分级检测系统关键技术研究[D].合肥: 合肥工业大学, 2012. Wang W.Based on machine vision inspection of agricultural materials classification system key technology[D]. Hefei: Hefei University of Technology, 2012(in Chinese with English abstract). http://cdmd.cnki.com.cn/Article/CDMD-10359-1012521031.htm |
| [6] |
李俊伟, 郭俊先, 张学军, 等. 无核白鲜葡萄机器视觉质量预测研究[J]. 农机化研究, 2014, 36(7): 57-61, 66. Li J W, Guo J X, Zhang X J, et al. Prediction of the weight of Xinjiang grape by machine vision techniques[J]. Journal of Agricultural Mechanization Research, 2014, 36(7): 57-61, 66 (in Chinese with English abstract). DOI:10.3969/j.issn.1003-188X.2014.07.014 |
| [7] |
陈坤杰, 李航, 于镇伟, 等. 基于机器视觉的鸡胴体质量分级方法[J]. 农业机械学报, 2017, 48(6): 290-295, 372. Chen K J, Li H, Yu Z W, et al. Grading of chicken carcass weight based on machine vision[J]. Transactions of the Chinese Society for Agricultural Machinery, 2017, 48(6): 290-295, 372 (in Chinese with English abstract). |
| [8] |
Wang X J. Ladle furnace temperature prediction model based on large-scale data with random forest[J]. IEEE/CAA Journal of Automatica Sinica, 2017, 4(4): 770-774. DOI:10.1109/JAS.2016.7510247 |
| [9] |
张乾.基于随机森林的视觉数据分类关键技术研究[D].广州: 华南理工大学, 2016. Zhang Q.Visual data classification based on random forests[D]. Guangzhou: South China University of Technology, 2016(in Chinese with English abstract). http://cdmd.cnki.com.cn/Article/CDMD-10561-1017805865.htm |
| [10] |
Xu J S, Wu Q, Zhang J, et al. Exploiting Universum data in Adaboost using gradient descent[J]. Image and Vision Computing, 2014, 32(8): 550-557. DOI:10.1016/j.imavis.2014.04.009 |
| [11] |
吴俊利, 张步涵, 王魁. 基于Adaboost的BP神经网络改进算法在短期风速预测中的应用[J]. 电网技术, 2012, 36(9): 221-225. Wu J L, Zhang B H, Wang K. Application of Adaboost-based BP neural network for short-term wind speed forecast[J]. Power System Technology, 2012, 36(9): 221-225 (in Chinese with English abstract). |
| [12] |
邓仙荣.基于梯度提升回归算法的O2O推荐模型研究[D].淮南: 安徽理工大学, 2016. Deng X R.Research of O2O e-commerce recommendation model on gradient boosting regression trees[D]. Huainan: Anhui Univeersity of Science and Technology, 2016(in Chinese with English abstract). http://cdmd.cnki.com.cn/Article/CDMD-10361-1016185765.htm |
| [13] |
龚越, 罗小芹, 王殿海, 等. 基于梯度提升回归树的城市道路行程时间预测[J]. 浙江大学学报(工学版), 2018, 52(3): 453-460. Gong Y, Luo X Q, Wang D H, et al. Urban traver time prediction based on gradient boosting regression tress[J]. Journal of Zhejiang University(Engineering Science), 2018, 52(3): 453-460 (in Chinese with English abstract). |
| [14] |
俞艺涵, 付钰, 吴晓平. MapReduce框架下支持差分隐私保护的随机梯度下降算法[J]. 通信学报, 2018, 39(1): 70-77. Yu Y H, Fu Y, Wu X P. Stochastic gradient descent algorithm preserving differential privacy in MapReduce framework[J]. Journal on Communications, 2018, 39(1): 70-77 (in Chinese with English abstract). |
| [15] |
艾玲梅, 叶雪娜. 基于循环卷积神经网络的目标检测与分类[J]. 计算机技术与发展, 2018, 28(2): 31-35. Ai L M, Ye X N. Object detection and classification of circular convonlutional neural network[J]. Computer Technology and Development, 2018, 28(2): 31-35 (in Chinese with English abstract). DOI:10.3969/j.issn.1673-629X.2018.02.008 |
| [16] |
马玉良, 许明珍, 佘青山, 等. 基于自适应阈值的脑电信号去噪方法[J]. 传感技术学报, 2014, 27(10): 1368-1372. Ma Y L, Xu M Z, She Q S, et al. De-noising method of the EEG based on adaptive threshold[J]. Chinese Journal of Sensors and Actuators, 2014, 27(10): 1368-1372 (in Chinese with English abstract). DOI:10.3969/j.issn.1004-1699.2014.10.012 |
| [17] |
王丽爱.小麦主要生育期苗情诊断关键参数遥感监测算法优化研究[D].扬州: 扬州大学, 2016. Wang L A.Study of the optimization algorithms for remote sensing monitoring key growth diagnosis parameters of winter wheat at main growth stages[D]. Yangzhou: Yangzhuo University, 2016(in Chinese with English abstract). http://cdmd.cnki.com.cn/Article/CDMD-11117-1016287910.htm |