 2011, Vol. 47
2011, Vol. 47文章信息
- 曾伟生, 唐守正
- Zeng Weisheng, Tang Shouzheng
- 立木生物量方程的优度评价和精度分析
- Goodness Evaluation and Precision Analysis of Tree Biomass Equations
- 林业科学, 2011, 47(11): 106-113.
- Scientia Silvae Sinicae, 2011, 47(11): 106-113.
-
文章历史
- 收稿日期:2010-04-26
- 修回日期:2010-06-09
-
作者相关文章



森林在应对全球气候变化中发挥着不可替代的作用,世界各国越来越重视对森林碳储量和固碳能力的监测,而森林生物量估计是监测和评价森林碳储量的基础。估计森林生物量最常用的方法是回归估计(Parresol,1999),即通过收集一定数量的林木,确定每株林木干物质质量或生物量,并通过回归建立与一个或多个林木因子的关系。建立立木生物量回归模型,一般包括建模样本采集、模型结构确定、模型参数求解和模型检验评价等环节(曾伟生等,2001),而对所建模型进行全面评价是建模工作的最后一个环节,也可能是最重要的一个环节(Kozak et al., 2003)。根据文献统计,全世界已经建立的生物量(包括总量和各分量)模型超过2 300个,涉及的树种在100个以上(Chojnacky,2002); 但是,很多模型对建模样本数据的基本信息描述不详或没有描述,也缺乏对所建模型进行检验评价和精度分析。如在Zianis等(2005)汇编的欧洲39个树种的607个生物量方程中,就有172个方程建模样本数量不详、169个方程没有提供建模样本的直径分布范围,所有方程只提供了R2(确定系数)这一项评价指标。
回归方程的统计指标很多,但模型的评价到底应该采用哪些基本指标,目前尚未达成共识,因而各种文献中所采用的指标差异很大(Parresol,1999; 曾伟生等,1999; 唐守正等,2002; Kozak et al., 2003; 段晓君等,2003; Zianis et al., 2004; Zabek et al., 2006; Harmel et al., 2007; Case et al., 2008)。除了常规的统计指标之外,模型的预估精度分析已经逐渐得到重视。如Bi等(2001)在建立澳大利亚桉树(Eucalyptus)和金合欢(Acacia farnesiana)的可加性生物量方程系统时,利用树干材积预估中的误差分布特性参与方程系统的随机模拟,确定了生物量估计值的置信区间; 王仲锋等(2005)根据立木生物量模型参数的方差与协方差以及胸径和树高的测量误差,对样地林木生物量计算的精度进行了估计。
另外,是否需要对所建模型进行适用性检验(或交叉检验),也是一个存在争议的问题。很多人认为仅利用建模样本计算的统计指标来评价模型的预估能力难以令人信服,必须利用检验样本进行适用性检验(Berk, 1984; Shao, 1993); 我国关于林业数表编制的技术也明确规定要利用检验样本进行适用性检验(中华人民共和国林业部,1990)。但也有人对这一做法持不同观点,如Picard等(1984)对样本分组的理论和方法学基础提出置疑,认为交叉检验存在2个明显不足:首先涉及到信息量的损失,因为被检验的模型基于较少的样本,第二是检验估计值的稳定性较差,因为检验样本的预估误差也是基于较少的样本; 曾伟生等(1999)认为整个适用性检验行为并不能提出一个反映所建回归模型预估精度的指标值,应该将检验样本和建模样本合并起来建模,从而更充分地利用样本信息; Kozak等(2003)利用蒙特卡罗(Monte Carlo)模拟也得出了类似的结论,认为将整个样本分成建模样本和检验样本进行建模的做法并不能对回归模型的评价提供额外的信息。
本文结合建立东北落叶松(Larix)和南方马尾松(Pinus massoniana)立木生物量的实际需要,从以下3个方面进行研究: 1)提出立木生物量模型的基本评价指标,并通过实例对其实用性进行检验; 2)对非线性立木生物量模型的预估精度进行分析,为在实际应用中评定森林生物量估计误差提供依据; 3)通过利用蒙特卡罗模拟进行随机再抽样试验,对模型适用性检验方法的必要性再做探讨。
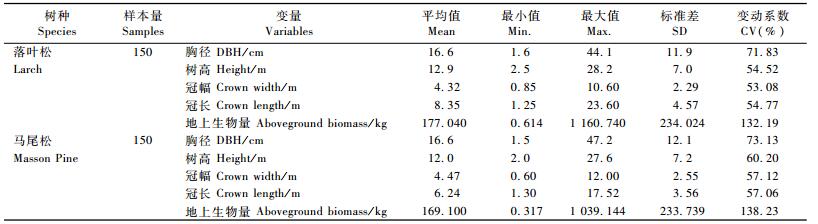
1 数据所用数据为我国东北落叶松和南方马尾松的地上生物量实测数据,每个树种各150株样木,其中东北落叶松的采集地点涉及内蒙古、黑龙江、吉林、辽宁4省区,南方马尾松的采集地点涉及江苏、浙江、安徽、?ā⒔鳌⒑稀⒐愣⒐阄鳌⒐笾?省区。样本单元数按各省资源多少分配,并兼顾天然和人工起源。每个树种的样木按2,4,6,8,12,16,20,26,32,38 cm以上10个径阶均匀分布,每个径阶的样木按树高级也接近均匀分布,在大尺度范围内具有广泛的代表性。全部样木都用钢围尺准确测量胸径,将样木伐倒后,用皮尺测量树干长度(树高)和活树冠长度(冠长),分干材、干皮、树枝、树叶称鲜质量,并分别抽取样品带回实验室,在85 ℃恒温下烘干至恒重,根据样品鲜质量和干质量分别推算样木各部分干质量并汇总得到地上部分干质量。样木基本情况见表 1。
|
|
本文以建立如下形式的二元立木生物量模型为例:
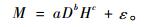
|
(1) |
式中: M为立木地上生物量(kg),D为胸径(cm),H为树高(m),a, b, c为参数,ε为误差。
立木生物量模型的检验评价指标很多。Parresol(1999)列出了7项评价模型拟合优度的统计指标:确定系数(R2)、估计值的标准差(SEE)、变动系数(CV)、Furnival指数、平均百分标准误差(MPSE)、百分误差(PE)以及建立预估置信区间所需的信息; 曾伟生等(1999)提出对用于预测目的的回归模型,除了常用统计指标之外,还要考虑总相对误差、总系统误差(或平均系统误差)、平均相对误差绝对值和预估精度(或预估误差)4项指标; Kozak等(2003)利用蒙特卡罗模拟进行交叉检验时,除采用R2和SEE指标外,还采用了残差平方和(RSS)、均方差(RMS)、平均偏差(MB)和平均绝对偏差(MAB)指标; Zianis等(2004)在比较不同预估方程时,提出了相对差异指标; Zabek等(2006)在建立加拿大BC省沿海地区杂交杨生物量方程时,除采用SEE指标外,也采用了MB和MAB指标; Harmel等(2007)在评价水文和水质模型时,除用到平均绝对误差(MAE)和均方根误差(RMSE)外,还提出采用效率系数(coefficient of efficiency)和一致指数(index of agreement); Case等(2008)在建立加拿大中西部地区北方森林通用性立木生物量方程时,采用了平均误差和均方根误差指标。此外,模型的评价指标还有参数稳定性、残差随机性、AIC准则和BIC准则等(曾伟生等,1999; 唐守正等,2002; 段晓君等,2003)。
2.1 基本评价指标在上述众多评价指标中,有些指标是针对某种特定情况提出的,如Furnival指数就是针对不同因变量形式的模型比较而提出的,对相同因变量形式的模型没有意义; AIC准则和BIC准则主要是为了对模型的拟合度和复杂性进行折中而提出的指标,对于建立一元或二元立木生物量模型而言意义不大。有些指标计算公式相同但叫法不同,如平均百分标准误差和平均相对误差绝对值的内涵就完全一样; 而且对于“误差”和“偏差”也经常混用,如上述平均误差和平均偏差就是同一指标。作为模型拟合优度的评价指标,一般叫误差比较合适; 只有当误差系统偏大或偏小时,才称模型存在偏差。综合考虑各种因素,在立木生物量模型评价和比较时,将确定系数(R2)、估计值的标准差(SEE)、总相对误差(TRE)、平均系统误差(MSE)、平均预估误差(MPE)和平均百分标准误差(MPSE)6项指标作为基本评价指标:
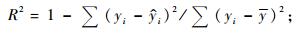
|
(2) |
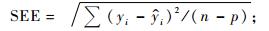
|
(3) |

|
(4) |

|
(5) |
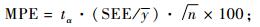
|
(6) |
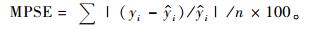
|
(7) |
式中: yi为实际观测值,
在前述6项基本评价指标中,MPE是反映回归模型预估精度大小的一项重要指标。另外,还进一步分析非线性生物量模型用于预估时的置信区间。
根据线性模型的回归估计理论,对于一元线性模型:
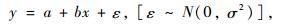
|
(8) |
对应于新的自变量x0,其条件均值的置信区间为(李松岗,2002):
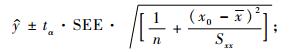
|
(9) |
单一观测值的置信区间为(李松岗,2002; 胡健颖等,2002):
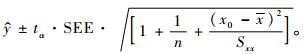
|
(10) |
式中:SEE根据式(3)计算,为σ的估计值。如果令式(1)中的DbHc=x,M=y,则式(1)就变成了类似式(8)一样的线性形式(截距参数为0):
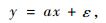
|
(11) |
但它并不满足等方差条件。根据有关研究结论(胥辉,1999; 曾伟生等,1999; 张会儒等,1999),误差项ε的方差与y的预估值的平方成正比,即SEE与y的预估值成正比,相当于生物量的相对误差项满足等方差条件。依据加权回归估计的基本原理,若式(11)两边同时除以ax,则新方程:
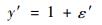
|
(12) |
的误差项ε′满足等方差条件。式(12)中y′相当于生物量的实测值与预估值之比。用新方程(12)进行拟合,用其SEE估计值乘以y的预估值代替式(9),(10)中的SEE,就可以对立木生物量平均预估值和单株预估值的置信区间进行估计。
2.3 随机再抽样检验关于林业数表的编制,按照有关技术规定的要求,“要同时收集编表和检验2套样本,用编表样本编表,用检验样本检验所编数表的精度”(中华人民共和国林业部,1990)。按照适用精度的检验方法,最终判定模型适用的条件,根据检验样本计算的“系统误差”(TRE)应满足:

|
(13) |
式中: n和n′分别为建模样本和检验样本的样木株数,tα和t′α分别为其对应的置信水平为α的t分布值。
关于这一做法,曾伟生等(1999)提出不同观点,认为整个适用性检验行为并不能提出一个反映所建回归模型预估精度的指标值,而只能做出一个可否接受模型的判定,但做出否决模型的判定只是一个小概率事件; 即使出现此种情况,也只能按要求去完善样本资料,重新建模。因此,应该将检验样本和建模样本合并起来建模,从而更充分地利用样本信息,因为真正体现回归模型预测精度的统计指标是式(6)的平均预估误差(MPE)。Kozak等(2003)利用不同样本单元数的7组数据,通过蒙特卡罗模拟对2个立木材积方程和1个树高-直径方程进行建模研究,也得出了类似的结论。本研究利用蒙特卡罗模拟(又称刀切法,Jack-knife)进行随机再抽样试验(唐守正等,2002; 胥辉等,2002; Kozak et al., 2003),即以全部150株样木为基础,将其随机分成建模样本(n1=100)和检验样本(n2=50)2部分,用建模样本建立生物量模型,再用检验样本进行按式(13)进行适用性检验。一共抽样100次,相当于每次用其中的100株样木建立生物量模型,用另外的50株样木相应进行适用性检验,最后再根据这100次随机再抽样的检验结果,验证上述观点是否正确,并在此基础上提出反映模型适用性的评价指标。
3 结果 3.1 生物量模型的基本评价利用全部150株样木,按式(1)分别2个树种采用加权回归拟合地上生物量模型,并按式(2)~(7)计算各项统计指标,结果见表 2。
|
|

从表 2的各项统计指标可以看出: 2个树种的R2都超过0.96,说明用D, H 2项因子已经解释了立木生物量变动的96%以上; SEE分别为42.15和43.84 kg,它们是计算预估误差的基础信息; TRE和MSE基本在±3%以内,表明模型拟合效果良好; MPE基本在4%左右,说明生物量模型的平均预估精度达到约96%;MPSE达到将近20%,该指标反映的是单株生物量估计误差的平均水平。从参数估计值可以看出: 2个树种的相应参数也比较接近,说明模型(1)的稳定性好; 各参数的t值都大于2,均达到显著或极显著水平。
从残差分布图(图 1)可以看出:各个径阶的残差和相对残差近似随机,但小径阶林木存在较大的系统偏差。分析其主要原因是:当式(1)中的D或H为0时,得到的生物量估计值就为0;而根据专业知识,只要树高低于1.3 m,胸径D就为0,但树高低于1.3 m的林木无疑具有一定的生物量。正是这一因素的影响,导致用式(1)得到的生物量估计值对小径阶林木会产生显著偏差。

|
图 1 马尾松生物量模型(1)的相对残差分布 Figure 1 Distribution of relative residual errors of biomass model (1) for Masson Pine |
基于这一考虑,在非线性模型(1)的基础上加上一个截距常数a0,变为以下形式:

|
(14) |
则应该会改进拟合效果。表 3为2个树种按式(14)计算的拟合结果。
|
|

从表 3与表 2的对比不难看出,模型(14)的各项统计指标都要好于模型(1),表明在模型(1)基础上增加截距常数a0后的新模型(14)达到了预期目标,它不仅使小径阶林木估计有偏的问题得到了明显改善(图 2),而且在一定程度上改进了整个模型的预估效果,如TRE和MSE已基本控制在±1%以内。需要指出的是,因为参数a0的估计值较小,在统计上与0无显著差异(t值小于2);但是因为其结果符合预期,具有生物学意义(意味着胸径刚好为0、树高1.3 m的落叶松和马尾松林木,其生物量平均约为0.3 kg),所以该参数是不宜减去的。

|
图 2 马尾松生物量模型(14)的相对残差分布 Figure 2 Distribution of relative residual errors of biomass model (14) for Masson Pine |
对于表 3中的生物量模型,转化为具有齐性方差的新模型(12)后,落叶松和马尾松2个树种的SEE值分别为0.230 0和0.249 1,将该值与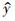

|
图 3 落叶松立木生物量预估值的置信区间 Figure 3 The confidence intervals of tree biomass estimates for larch |

|
图 4 马尾松立木生物量预估值的置信区间 Figure 4 The confidence intervals of tree biomass estimates for Masson Pine |

|
图 5 落叶松立木生物量预估值的相对置信区间 Figure 5 The relative confidence intervals of tree biomass estimates for larch |

|
图 6 马尾松立木生物量预估值的相对置信区间 Figure 6 The relative confidence intervals of tree biomass estimatas for Masson Pine |
从图 3~6可以看出:落叶松的置信区间比马尾松要稍窄一些,说明其预估精度比马尾松要略高; 单一预估值的相对置信区间基本不随x变化,这是由生物量的相对误差项近似满足等方差条件所决定的(事实上小径阶林木的相对误差项的方差要偏大一些,这一点可以参见图 1, 2)。落叶松建模样本的自变量平均值x=2 806(位于20 cm径阶),此时其条件均值的相对置信区间为±3.68%,单一预估值的相对置信区间为±45.23%;当x0从20 cm径阶逐渐减少到2 cm径阶时,条件均值的相对置信区间逐渐增加到约±4.63%;当x0从20 cm径阶逐渐增加到40 cm径阶时,条件均值的相对置信区间逐渐增加到超过±10%。类似地,马尾松建模样本的自变量平均值x=2 926(位于20 cm径阶),此时其条件均值的相对置信区间为±3.99%,单一预估值的相对置信区间为±48.99%;当x0从20 cm径阶逐渐减少到2 cm径阶时,条件均值的相对置信区间逐渐增加到约±4.95%;当x0从20 cm径阶逐渐增加到40 cm径阶时,条件均值的相对置信区间逐渐增加到约±11%。因此,大径阶林木的生物量预估精度相对较低。
3.3 随机再抽样的检验结果由于进行随机再抽样的计算工作量较大,本文只利用马尾松生物量数据进行检验。模型选用式(1),并且为了提高数据处理的效率,在采用加权回归估计时,权函数的选择没有针对每个模型通过残差方差再去拟合最合适的方程,而是全部采用通用权函数W=1/f(x)2进行加权回归(曾伟生等,1999)。表 4为100次随机再抽样、每次抽取100株样木的拟合结果。
|
|
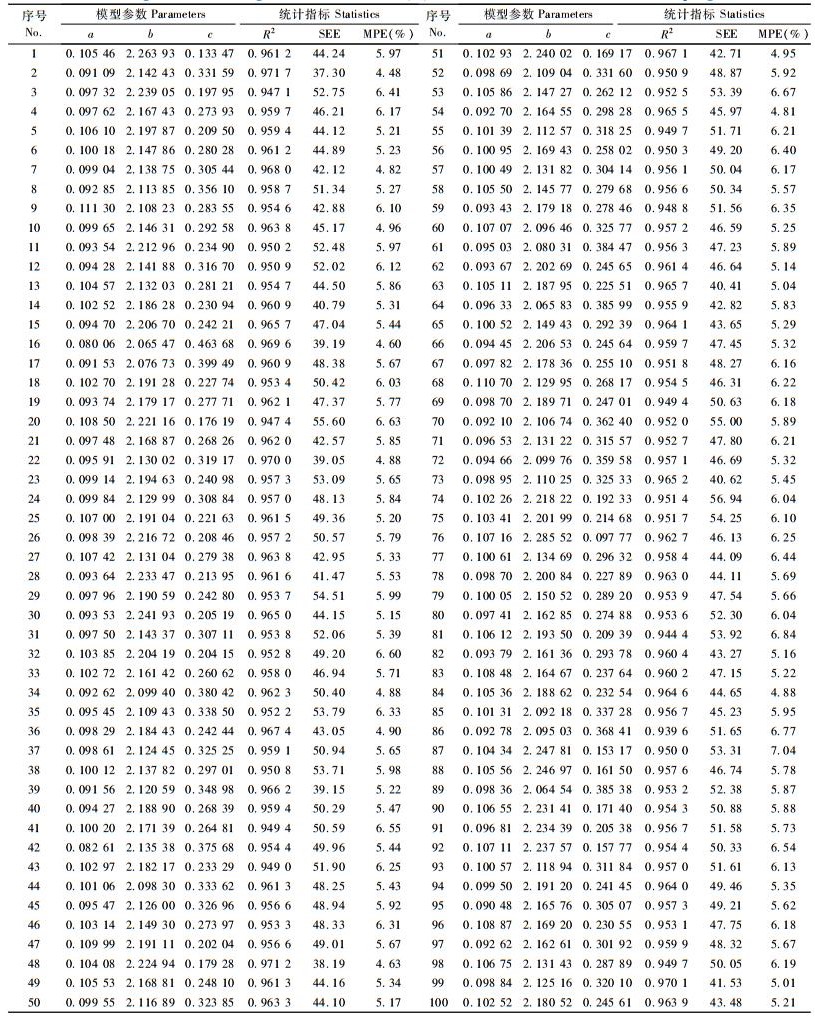
然后,针对每个建立的模型,用相应的检验样本按式(4)计算TRE,再按式(13)来判定所建模型是否适用。根据检验结果,通过随机再抽样所建立的100个模型,有98个模型经判定是适用的,只有2个模型(34号和36号)用检验样本计算的总相对误差超过了临界值。经分析,这2个模型的建模样本和检验样本明显出现偏离,34号是建模样本偏大,检验样本偏小; 36号是建模样本偏小,检验样本偏大。因此,通过随机再抽样检验,印证了“利用适用性检验做出否决模型的判定只是一个小概率事件”的观点是正确的。
通过随机再抽样方法所建立的100个模型中,有98个都通过了检验,从统计上讲,应该是取98个或100个模型的平均值最好。作为对比,利用全部150株样木按同样的通用权函数进行加权回归估计,其结果见表 5。
|
|

从表 5可知:不管是100个还是98个模型的平均值,其参数估计值及统计指标R2,SEE与利用全部150株样木建立的模型相比差异很小,但MPE因为样本单元数的差异而相差1%。根据中心极限定理,随着再抽样次数m的进一步增多,由m个模型得到的参数平均值的数学期望值应该等于利用全部150株样木所建模型的参数值。因此,最终确定的模型既不是通过适用性检验的98个模型中的任何一个(常规做法相当于取其中的某一个模型),也不是采用其平均值,而是利用全部样本(不分建模样本和检验样本)建立的模型。它一方面使所有样本信息得到了充分利用; 另一方面建模样本单元数达到最大,从而使MPE最小。
4 结论本文以建立东北落叶松和南方马尾松的立木生物量模型为例,提出了立木生物量模型的基本评价指标,并重点对模型预估精度进行分析,给出了立木生物量模型用于预估的置信区间; 并通过利用蒙特卡罗模拟进行随机再抽样检验,对模型适用性检验方法的必要性进行了探讨。
1) 模型的评价指标很多,但每项指标各有其用途。综合考虑各种因素,对于一元或二元立木生物量模型的评价和比较,R2,SEE,TRE,MSE,MPE和MPSE 6项指标应该作为基本评价指标,另外再考虑参数的稳定性和残差的随机性。
2) 基于线性回归估计中模型预估值置信区间的计算公式,通过模型变换和消除异方差措施,提出了适合非线性立木生物量模型预估的条件均值置信区间和单一预估值置信区间的估计方法,并确定了2个树种生物量模型的置信区间。林木的大小不同,其预估值的置信区间就不同,平均直径以上的林木,随着林木直径和树高的增加,林木生物量的预估误差越来越大。
3) 通过蒙特卡罗模拟进行随机再抽样检验,印证了“利用适用性检验做出否决模型的判定只是一个小概率事件”的观点是正确的,单独采集一套检验样本进行适用性检验的做法不可取; 应该利用全部样本(不分建模样本和检验样本)来建立模型,它能充分利用样本信息,使模型的预估误差达到最小; MPE是反映模型预估精度的重要评价指标。
段晓君, 王正明. 2003. 基于选择准则的参数模型评价方法[J]. 国防科技大学学报, 25(3): 62-65. |
胡健颖, 冯泰. 2002. 实用统计学[M]. 北京: 北京大学出版社.
|
李松岗. 2002. 实用生物统计[M]. 北京: 北京大学出版社.
|
唐守正, 李勇. 2002. 生物数学模型的统计学基础[M]. 北京: 科学出版社.
|
王仲锋, 冯仲科. 2005. 样地林木生物量精度评定的研究[J]. 北京林业大学学报, 27(增): 173-176. |
胥辉. 1999. 生物量模型方差非齐性研究[J]. 西北林学院学报, 19(2): 73-77. |
胥辉, 张会儒. 2002. 林木生物量模型研究[M]. 昆明: 云南科技出版社.
|
曾伟生, 骆期邦. 2001. 论林业数表模型的研建方法[J]. 中南林业调查规划, 20(2): 1-4. |
曾伟生, 骆期邦, 贺东北. 1999. 论加权回归与建模[J]. 林业科学, 35(5): 5-11. |
张会儒, 唐守正, 胥辉. 1999. 关于生物量模型中的异方差问题[J]. 林业资源管理, (1): 46-49. |
中华人民共和国林业部. 1990. 林业专业调查主要技术规定[M]. 北京: 中国林业出版社.
|
Berk K N. 1984. Validating regression procedures with new data[J]. Technometrics, 26(4): 331-338. DOI:10.1080/00401706.1984.10487985 |
Bi H, Birk E, Turner J, et al. 2001. Converting stem volume to biomass with additivity, bias correction, and confidence bands for two Australian tree species[J]. New Zealand Journal of Forestry Science, 31(3): 298-319. |
Case B, Hall R J. 2008. Assessing prediction errors of generalized tree biomass and volume equations for the boreal forest region of west-central Canada[J]. Can J For Res, 38(4): 878-889. DOI:10.1139/x07-212 |
Chojnacky D C. 2002. Allometric scaling theory applied to FIA biomass estimation: GTR NC-230. North Central Research Station, Forest Service USDA, 96-102.
|
Harmel R D, Smith P K. 2007. Consideration of measurement uncertainty in the evaluation of goodness-of-fit in hydrologic and water quality modeling[J]. Journal of Hydrology, 337(3/4): 326-336. |
Kozak A, Kozak R. 2003. Does cross validation provide additional information in the evaluation of regression models?[J]. Can J For Res, 33(6): 976-987. DOI:10.1139/x03-022 |
Parresol B R. 1999. Assessing tree and stand biomass: a review with examples and critical comparisons[J]. For Sci, 45(4): 573-593. |
Picard R R, Cook R D. 1984. Cross-validation of regression models[J]. J Am Stat Assoc, 79(387): 575-583. DOI:10.1080/01621459.1984.10478083 |
Shao J. 1993. Linear model selection by cross-validation[J]. J Am Stat Assoc, 88(422): 486-494. DOI:10.1080/01621459.1993.10476299 |
Ter-Mikaelian M T, Korzukhin M D. 1997. Biomass equations for sixty-five North American tree species[J]. Forest Ecology and Management, 97(1): 1-24. DOI:10.1016/S0378-1127(97)00019-4 |
Zabek L M, Prescott C E. 2006. Biomass equations and carbon content of aboveground leafless biomass of hybrid poplar in Coastal British Columbia[J]. Forest Ecology and Management, 223(1/3): 291-302. |
Zianis D, Mencuccini M. 2004. On simplifying allometric analyses of forest biomass[J]. Forest Ecology and Management, 187(2/3): 311-332. |
Zianis D, Muukkonen P, Mäkipää R, et al. 2005. Biomass and stem volume equations for tree species in Europe[J]. Silva Fennica Monographs, 4(4): 1-63. |