 2010, Vol. 46
2010, Vol. 46文章信息
- 李春明, 张会儒
- Li Chunming, Zhang Huiru
- 利用非线性混合模型模拟杉木林优势木平均高
- Modeling Dominant Height for Chinese Fir Plantation Using a Nonlinear Mixed-Effects Modeling Approach
- 林业科学, 2010, 46(3): 89-95.
- Scientia Silvae Sinicae, 2010, 46(3): 89-95.
-
文章历史
- 收稿日期:2008-05-13
-
作者相关文章


在评价林分的立地质量时,由于林分平均高受抚育措施的影响较大,尤其在抚育采伐的前后,立地质量没有任何变化,但林分的平均高却有很大的增加,如果采用林分的优势木平均高就能够避免这种现象发生(孟宪宇,1994)。因此优势木平均高经常被用于鉴定不同立地质量下林分生长的对比。优势木平均高可用给定的地位指数来预测,也可以反过来利用优势木平均高和林龄关系预测林分的地位指数。另外,估计的优势木平均高可进一步来预测林分的断面积和蓄积,因此优势木平均高的准确预测对于预测木材收获具有巨大的影响。以往建立的优势木平均高与林龄关系方程,都是利用非线性最小二乘方法来估计参数; 但是,这种方法存在着一些问题。首先,这些模型在模拟时通常都是假定误差是服从独立同分布的,然而现实的观测数据很难满足这种条件,势必会对估计结果有一定的影响。其次,大多模型关心的是研究对象的确定性和平均行为,忽略了个体或群体之间存在的序列相关性及差异性。例如以往所建立的生长模型很好地反映了林分总体的平均生长变化规律,但却忽略了林木个体之间的差异。而混合效应模型方法则在很大程度上弥补了这些方面的不足,既可以反映总体的平均变化趋势,又可以提供数据方差、协方差等多种信息来反映个体之间的差异。另外在分析重复测量数据或固定样地连续观测数据及满足假设条件时体现出的灵活性,表明混合效应模型已经成为生长和收获模拟的重要工具。这一方法在最近20年内得到了快速的发展,在医学、农业、经济、林业及其他领域有了广泛的应用(Littell et al., 1996)。
作为利用混合模型研究优势木平均高的开创性研究,Lappi等(1988)建立了样地水平上Richards式非线性混合效应优势木平均高模型。之后,Hall等(2001)以美国乔治亚州的火炬松(Pinus taeda)为研究对象,考虑样地水平上的随机效应,利用多水平非线性混合模型方程组构造了Chapman-Richards形式的优势高曲线,研究结果认为与传统的模拟方法相比,多水平非线性混合模型在模型估计精度上有较大的提高。Fang等(2001)利用修改的3参数Richards生长模型为不同经营方式下(比如采伐、施肥和火烧)美国乔治亚州和佛罗里达州湿地松(Pinus elliottii)的优势高论证了非线性混合模型的一般方法论,作者考虑了经营措施的影响及样地的随机效应,认为非线性混合模型方法要比传统方法预测的精度高。Calegario等(2005)考虑样地的随机效应,为采用不同无性繁殖技术处理的杂交桉(Eucalyptus hybrid)构造了Logistic形式的优势高和林龄关系的非线性混合模型,结果表明:采用3参数Logistic函数的非线性混合模型方法描述桉树无性繁殖的优势木高度具有相当大的灵活性,产生了依赖于无性繁殖方法和周围环境的多形地位指数曲线,并且构造了样地间适宜的方差协方差矩阵。
优势木平均高会随林分密度的不同而变化(Temesgen et al., 2004)。为了比较不同初植密度林分优势木平均高与林龄关系的变化情况,本文以江西省大岗山实验局不同初植密度的人工杉木(Cunninghamia lanceolata)为研究对象,考虑初植密度的随机效应,选择常用的Richards和Logistic形式,通过变化混合模型中混合效应参数的个数来构造不同的优势木平均高和林龄关系的非线性混合效应模型, 利用SAS的NLMIXED模块对模型参数进行估计,最后采用确定系数(R2)、均方误差(MSE)和平均绝对残差(|E|)对不同模型的精度进行比较(Dorado et al., 2006)。
1 数据为了模拟不同初植密度林分优势木平均高的生长状况,选择中国林业科学研究院林业研究所设置在江西省大岗山实验局不同初植密度的人工杉木进行研究。实验地点位于114°43′ E,27°34′ N,海拔250 m,母岩、土壤等自然地理条件相同的低山地带,平均地位指数为18 m。杉木数据为5个区组,样地大小为0.06 hm2。每个区组的立地条件基本一致,采用随机区组排列,并在每个小区四周各设2行同样密度的保护带。初植密度分别为大致1 667,3 333,5 000,6 667和10 000株·hm-2,分别在林龄为5,6,7,8,9,10,11,12,14和16年时测量了样地内每木胸径和树高。选择6株优势木和亚优势木的树高进行平均,得到林分的优势木平均高。具体数据见表 1。
|
|

研究林分优势木平均高生长的模型种类很多,例如Logistic方程、Mitscherlich方程、Gompertz方程、Richards方程和Korf方程等。从众多研究者提出或应用的优势木平均高模型来看,普遍用到的模型的形式有2类,即Richards和Logistic型。大量研究表明Richards适应性强、准确性高,其方程中的参数有一定的生物学意义,在国内外生长收获预估中得到广泛应用(章允清,2006)。Logistic方程不仅具有良好的生物学理论基础,而且具有良好的解析性能和预测性能以及广泛的适应性,同时预测精度也高。本文采用这2种方程进行模拟研究。
2.1 基础模型 2.1.1 Richards形式在研究优势木平均高模型时,通常用到的Richards形式包括3个参数,具体形式如(1)式:
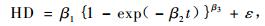
|
(1) |
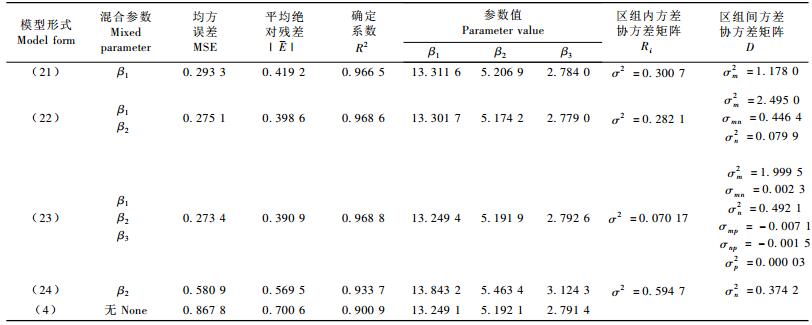
式中:HD指优势木平均高,β1为优势高渐近参数,β2为尺度参数,β3为形状参数,t为林龄,ε为随机误差。
Fang等(2001)在估计优势木平均高时,认为(1)式的β1是最不稳定的参数,所以为了避免优势高和地位指数之间的不相容性,对(1)式进行了修改。具体形式如下:
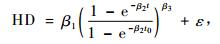
|
(2) |
式中:HD指优势木平均高,β1为林分标准林龄时的优势高,β2为尺度参数,β3为形状参数,t为林龄,t0为标准林龄(本文取20年),ε为随机误差。
2.1.2 Logistic形式Logistic形式(李永慈等,2004)也是目前林业上常用的估计林分优势木平均高与林龄关系的模型,最常用的2种变化形式如(3)和(4)式:
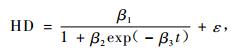
|
(3) |
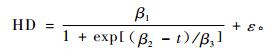
|
(4) |
式中:HD为样地的优势木平均高,t为林龄,βi为参数,ε为随机误差。
2.2 非线性混合效应模型 2.2.1 基本形式非线性混合效应模型是通过考虑回归函数依赖于固定和随机效应的非线性关系而建立的。其主要特征是参数向量随样地的不同而变化,参数被分成固定效应和随机效应2部分。此类模型可被看成是在数据分析中忽略群体性的简单非线性模型和缺乏描述种群平均趋势的非线性模型的一种折中(Pinheiro et al., 2000)。
一般来说,单水平非线性混合效应模型的形式如(5)式:
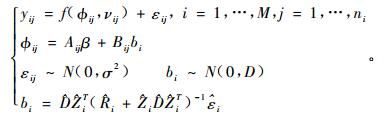
|
(5) |
式中:yij是第i个区组中第j个样地观测的因变量值,本文指预测的样地林分优势木平均高。M是区组数,ni是第i个区组内观测的样地数。f是真实值,是一个研究对象中具体参数向量φij和变值向量νij的可微函数,本文指测量的样地林分优势木平均高。εij是服从正态分布的误差项。β是(p×1)维固定效应向量,bi是带有方差协方差矩阵D的(q×1)维随机效应向量,Aij和Bij是相应的设计矩阵。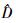

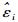
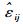
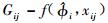
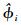
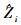

在构建一个混合模型之前,需要确定以下3个结构(Fang et al.,2001):
1) 混合效应参数 在模型中,哪个参数为固定效应哪个为混合效应一般依赖于所研究的数据。如果没有关于随机效应方差协方差结构的先验知识并且满足收敛条件,Pinheiro等(2000)建议模型中所有的参数首先应全部看成是混合的,然后再分别进行参数拟合,最后选择模拟精度较高的形式来估计优势木高度。本文按照此方法进行参数选择和模拟。
2) 区组内方差协方差结构(Ri) 为了确定区组内的方差协方差结构,必须解决异方差和自相关结构2方面的问题。本文所使用的数据没有包括观测对象的空间相关性,而仅仅考虑了残差的方差结构,因此区组内的方差协方差结构具体表达式为:
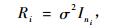
|
(6) |
式中:σ2指某一区组内观测对象的残差方差值,Ini为描述变化方差的ni×ni维单位矩阵。
3) 区组间方差协方差结构(D) 区组间的方差协方差结构反映了样地之间的变化性。本研究中所用的方差协方差结构有3种,其中m为参数β1的随机效应参数,n为参数β2的随机效应参数,p参数β3的随机效应参数,以同时包括3个随机参数(m, n, p)的方差协方差结构为例,结构如(7)式:

|
(7) |
式中:σm2为随机参数m的方差,σn2为随机参数n的方差,σp2为随机参数p的方差,σmn=σnm为随机参数m和n的协方差值,σmp=σpm为随机参数m和p的协方差值,σnp=σpn为随机参数n和p的协方差值。
2.3 模型精度比较利用SAS软件的NLMIXED模块对模型的参数进行估计,然后采用确定系数(R2)、均方误差(MSE)和平均绝对残差(|E|)3个模型精度评价指标对模拟结果进行效果评价。其中这3个评价指标的结果利用EXCELL软件进行计算,(MSE)和(|E|)值越小而(R2)值越大说明模型的模拟精度越高(Dorado et al., 2006)。
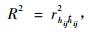
|
(8) |

|
(9) |
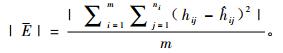
|
(10) |
式中: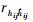
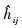
为了解决本研究数据样本量少的问题,首先从第Ⅰ区组到第Ⅳ区组随机去掉1块样地,第Ⅴ区组随机去掉2块样地,剩下的10块样地作为模拟数据。每个方程每一次分别随机选择10块样地模拟1次,共模拟20次,然后把模拟的20次的参数结果分成2组,利用F检验来对参数的差异性进行检验。模拟检验结果为这4个方程的参数的F值均小于3.18(F临界值),说明对不同样地进行参数模拟,参数值无显著性差异,因此可以认为这4个方程完全实用于模拟本研究所使用的数据。在利用这4个方程构建混合模型时,分别确定4个模型的混合效应参数、区组内方差协方差结构以及区组间方差协方差结构,然后利用SAS软件的NLMIXED模块对其中10块模拟样地数据进行参数的模拟,把能够收敛的模型作为模拟结果。利用全部的16块样地作为检验数据并计算3个精度评价指标。
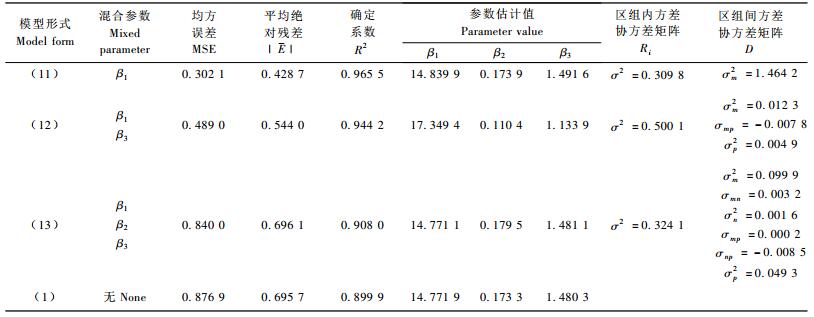
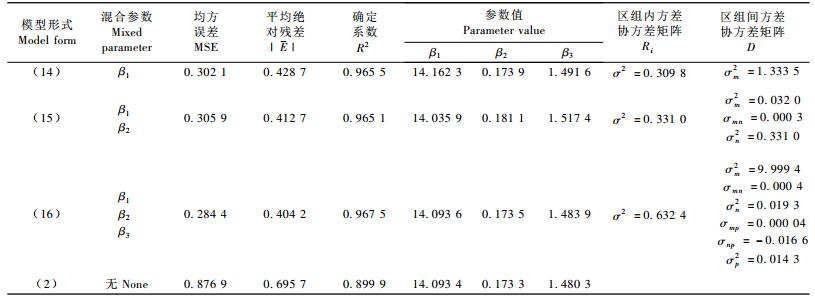
3.1 Richards形式拟合结果 3.1.1 以(1)式为基础的非线性混合效应模型最后收敛的模型形式如(11),(12)和(13)式。模型的固定参数、区组内方差协方差矩阵Ri、区组间方差协方差矩阵D及均方误差(MSE)、平均绝对残差(|E|)及确定系数(R2)的拟合结果如表 2。
|
|
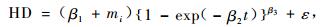
|
(11) |
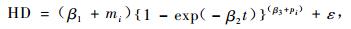
|
(12) |
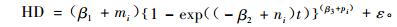
|
(13) |
从表 2的结果来看,带有混合效应参数的(11~13)式最后计算的MSE和|E|都比传统的模型值要小,而且R2值比传统的大,从而充分说明混合效应模型比传统模型精度高。但(13)式的精度比(11)和(12)式明显降低,并不随着混合效应参数的增加而精度提高,这与Budhathoki等(2005)的研究结论并不一致。造成这种情况一方面的原因是由于增加了混合参数个数就增加了计算难度可能造成精度降低,另一方面跟软件本身的算法也有一定的关系。这方面有待进一步进行研究。
3.1.2 以(2)式为基础的非线性混合效应模型(14~16)式为收敛的模型,表 3为模型的拟合结果。
|
|
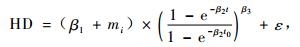
|
(14) |
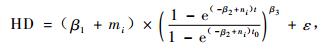
|
(15) |
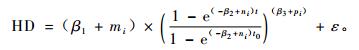
|
(16) |
从表 3的结果来看,带有混合效应参数的(14~16)式MSE和|E|都比传统的模型值小而R2值大,与表 2的结果一致。以(2)式为基础的这几个模型的模拟精度都随着混合效应参数个数的增加而提高了精度。与(1)式相比,当3个参数都为混合参数时,(2)式的MSE和|E|明显要小,这说明当考虑林分的标准年龄的优势高时避免了β1的不稳定性,因此提高了估计优势木平均高的准确性。这与Fang等(2001)的结论一致。
3.2 Logistic形式拟合结果 3.2.1 以(3)式为基础的非线性混合效应模型经过SAS软件的模拟,最终收敛的结果见(17~20)式。表 4为以(3)式为基础的模拟计算结果。
|
|
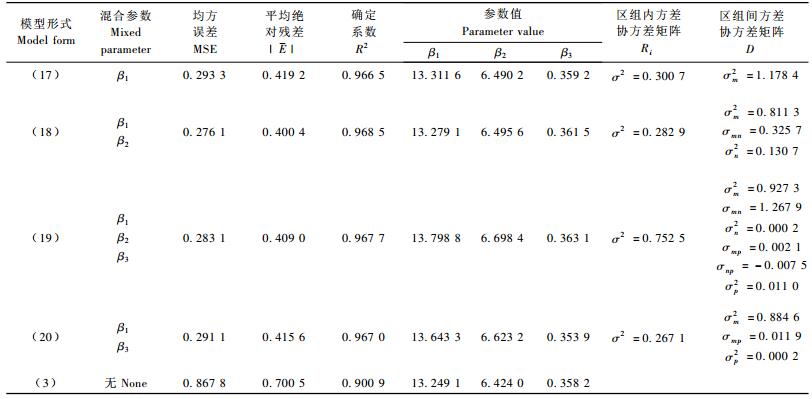
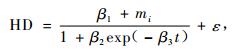
|
(17) |
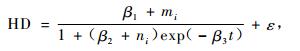
|
(18) |
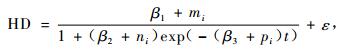
|
(19) |

|
(20) |
从表 4的结果来看,带有混合效应参数的(17~20)式的MSE和|E|都比传统的模型值小而R2值大,充分说明混合效应模型比传统模型精度高。但(19)式的精度比(18)式要低但是比(17)和(20)式要高,并不完全随着混合效应参数个数的增加而精度提高,这与3.1.1的模拟结果一致。
3.2.2 以(4)式为基础的非线性混合效应模型利用SAS软件的进行模型拟合,最后确定的模拟收敛的模型形式如(21~24)式,模型拟合结果如表 5。
|
|
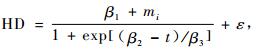
|
(21) |

|
(22) |
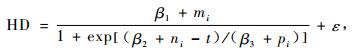
|
(23) |

|
(24) |
表 5中带有混合效应参数的(21~24)式MSE和|E|都比传统的模型值小而R2值大,并且很明显,说明混合效应模型比传统模型精度高,这与前面3个结论一致。模拟精度随着混合效应参数的增加而精度提高。但是同样含有一个混合效应参数的(21)式与(24)式相比,精度要高的多,这说明混合效应参数不同,对模拟的结果有很大的影响。精度高的原因是β1是渐近参数,其值变化很大,这也充分印证了Fang等(2001)的结论。另外对这4个模型总体进行评价发现(23)式中3个参数都作为混合模型的模拟精度最高。
4 结论与讨论1) 无论是Richards形式还是Logistic形式的优势木平均高与林龄关系的非线性混合效应模型的估计精度都比传统的回归模型估计精度明显提高。
2) 虽然非线性混合效应模型的估计精度比传统的回归模型精度明显提高,但是增加随机效应参数个数并不一定绝对增加模型的估计精度,相反估计精度有可能下降。造成这种情况的原因可能是由于增加了混合参数个数就增加了计算难度,因此造成了精度降低。
3) 通过Richards方程的2种形式的精度比较,可看出当考虑林分的标准年龄的优势高时避免了β1的不稳定性,因此提高了优势木平均高估计的准确性。本研究所选择的模型参数中,β1是最灵活、变化最不稳定的参数,在估计时最能够体现优势高的变化,因此在拟合时应首先考虑其作为混合参数。
4) 本研究中,以(4)式为基础的Logistic方程中,3个参数都作为混合模型的模拟精度最高。在生产实践中可把此模型作为首选模型。
5) 目前只有在S-PLUS软件的NLME模块和SAS软件的NLMIEXD模块中实现了非线性混合效应模型的计算,并且只能够利用限制极大似然法进行参数估计,给利用混合效应模型进行研究带来一定的限制。相信随着计算机软件的发展,混合效应模型在林业研究中的应用前景会更加广泛。
6) 由于非线性混合效应模型参数拟合方法的限制,本次研究只考虑了区组间的随机效应而没有考虑区组内样地的随机效应,因此,还需进一步对样地效应进行研究。
李永慈, 唐守正. 2004. 用Mixed和Nlmixed过程建立混合生长模型[J]. 林业科学研究, 17(3): 279-283. |
孟宪宇. 1994. 测树学[M]. 2版. 北京: 中国林业出版社.
|
章允清. 2006. 卫闽林场杉木人工林经验收获表的研制[J]. 福建林业科技, 33(3): 47-51. |
Budhathoki C B, Lynch T B, Guldin J M.2005.Individual tree growth models for natural even-aged Shortleaf Pine(Pinus echinata Mill.). Proc eedings of the 13th Biennial Southern Silvicultural Conference, Memphis, TN.
|
Calegario N, Daniels R F, Maestri R, et al. 2005. Modeling dominant height growth based on nonlinear mixed-effects model: a clonal eucalyptus plantation case study[J]. Forest Ecology and Management, 204: 11-21. DOI:10.1016/j.foreco.2004.07.051 |
Dorado F C, Ulises D A, Marcos B A, et al. 2006. A generalized height-diameter model including random components for radiata pine plantations in northwestern Spain[J]. Forest Ecology and Management, 229: 202-213. DOI:10.1016/j.foreco.2006.04.028 |
Fang Z, Bailey R L. 2001. Nonlinear mixed effects modeling for slash pine dominant height growth following intensive silvicultural treatments[J]. Forest Science, 47: 287-300. |
Hall D B, Bailey R L. 2001. Modeling and prediction of forest growth variables based on multilevel nonlinear mixed models[J]. Forest Science, 47: 311-321. |
Lappi J, Bailey R L. 1988. A height prediction model with random stand and tree parameters: an alternative to traditional site methods[J]. Forest Science, 34: 907-927. |
Littell R C, Milliken G A, Stroup W W, et al. 1996.SAS system for mixed models. SAS institute Inc, Cary, NC.
|
Pinheiro J C, Bates D M.2000. Mixed effects models in S and S-plus. Springer Verlag, Newyork.
|
Temesgen H, Von Gadow K. 2004. Generalized height-diameter models for major tree species in complex stands of interior British Columbia[J]. Europe Journal of Forest Research, 123: 45-51. DOI:10.1007/s10342-004-0020-z |