
Path Planning of Oil Spill Recovery System With Double USVs Based on Artificial Potential Field Method
https://doi.org/10.1007/s11804-024-00437-y
-
Abstract
Path planning for recovery is studied on the engineering background of double unmanned surface vehicles (USVs) towing oil booms for oil spill recovery. Given the influence of obstacles on the sea, the improved artificial potential field (APF) method is used for path planning. For addressing the two problems of unreachable target and local minimum in the APF, three improved algorithms are proposed by combining the motion performance constraints of the double USV system. These algorithms are then combined as the final APF-123 algorithm for oil spill recovery. Multiple sets of simulation tests are designed according to the flaws of the APF and the process of oil spill recovery. Results show that the proposed algorithms can ensure the system's safety in tracking oil spills in a complex environment, and the speed is increased by more than 40% compared with the APF method.Article Highlights● To ensure the safe and efficient completion of the recovery task of USVs, path planning is studied.● Three flaws of the artificial potential field method are analyzed, and three improved algorithms are proposed.● An improved artificial potential field algorithm for the oil spill recovery system with double USVs is proposed.● Simulation tests are carried out to prove that the proposed algorithm can ensure the security of the system and takes less than 60% of the time required by the APF method. -
1 Introduction
Oil spills at sea have the characteristics of long hazard time and large influence degree, causing serious harm to the marine environment and biological health. For example, oil spills cut off the contact between seawater and air, thereby reducing the oxygen content of seawater and endangering the growth of marine organisms. The cyclic aromatic hydrocarbons in oil spills increase the probability of cancer and genetic mutation in mammals. Oil spills can also hinder the heat exchange between the ocean and the atmosphere (Bucas and Saliot, 2002; Liu and Tian, 2006; Lee and Jung, 2015). Therefore, quickly and effectively dealing with an oil spill accident is of great significance. Commonly used oil spill treatment measures mainly include physical, chemical, and biological methods; among them, the physical method is the most ideal and includes the use of booms for containment and recovery and the adsorption of oleophilic materials (Zhang et al., 2020). Collecting and recovering oil spills by manned ships carrying oil booms is one of the commonly used techniques; however, it consumes substantial manpower and material resources and causes serious injuries to the staff on board unmanned surface vehicles (USVs) offer advantages such as miniaturization, autonomy, modularity, strong maneuverability, and high endurance (Manley, 2008; Liao, 2012; Liao et al., 2019). Using USVs instead of manned ships to recover oil spills at sea has many advantages, including avoiding human involvement, lowering recovery costs, improving the efficiency of task execution, and avoiding further volatilization and expansion of oil spills caused by prolonged recovery time. Hence, this approach has great practical application.
Reasonable path planning in oil spill recovery can ensure the safe and efficient completion of the task of USVs, which has great research significance and practical application. It is a system optimization problem with complex constraints (Drake et al., 2018; Yuan et al., 2019). Wang (2015) proposed a USV formation path planning algorithm based on the variable fast marching square method; it changes the anisotropy of the feasible region according to the set way so the final planned path can be balanced between the path length and safety. Considering that USVs are limited by motion constraints, Liu and Richard (2016) proposed an angle-guided fast marching square method to ensure that the generated path conforms to the dynamics and orientation constraints of the USV. For cooperative path planning considering the heterogeneity of USVs, Tan et al. (2020) established a path evaluation function based on the fast marching square method to quantify the matching degree of expected paths with different characteristics relative to the heterogeneous type of USVs. Hence, a global expected path that can unify and coordinate the characteristics of each USV in the cluster can be planned. Sang et al. (2021) proposed a hybrid path planning algorithm based on improved A* and multiple subtarget artificial potential field (APF), which can greatly reduce the probability of USVs falling into the local minimum and help the USVs escape from the local minimum by switching the target point. Aiming at the water–air cooperative operation task of unmanned aerial vehicles and USVs, Zheng et al. (2021) adopted a combination of virtual structure and APF control algorithm. The formation of vehicles is organized through the virtual structure method, and the state error of vehicles and APF function are utilized to achieve preset formation and avoid collision between unmanned aerial vehicles.
In summary, research on the cooperative path planning of multiple USVs is mainly based on the improved APF method, the improved A* algorithm, and the fast marching flat method. Traditional A* method (Hao and Agrawal, 2005), particle swarm optimization algorithm (Duan et al., 2008), genetic algorithm (Qu et al., 2013), and ant colony algorithm (Asl et al., 2013) are also used to study the cooperative path planning problem of multirobots but are rarely applied to the research on the collaborative path planning of USVs.
Compared with other path planning algorithms, the more widely used APF method has the advantages of simpler principles, faster calculation speed, and better real-time performance. Orozco-Rosas et al. (2019) combined membrane computing with a genetic algorithm and the APF method to propose a membrane evolutionary APF approach for solving the problem of mobile robot path planning. This method has shown improved performance in terms of path length and timeliness. By combining the APF method and the Deep Deterministic Policy Gradient (DDPG) algorithm, Li et al. (2023) proposed an improved algorithm APF-DDPG to improve the obstacle avoidance trajectory planning capability of mobile robotic arms in narrow passage and obstacle constraints. Compared with traditional DDPG, the improved algorithm can be trained with higher convergence efficiency to obtain a policy model with more efficient control performance. Orozco-Rosas et al. (2022) utilized the APF method to improve the classical Q-learning approach for solving the limitation of slow convergence to the optimal solution. Experiments demonstrate that in offline and online path planning modes, the Q-learning algorithm combined with the APF method algorithm successfully achieves better learning values and outperforms the classical Q-learning approach in all test environments.
The APF method also has problems, such as local minimum and unreachable targets, both of which have been studied by scholars. Jiang (2020) improved the potential function of the repulsive field to solve the local minimum problem of the APF method and applied it to the path planning of oil spill recovery systems. Experimental results show that the system can successfully avoid obstacles and finally return to the original trajectory. Sun et al. (2022) introduced the Bug algorithm to ensure the global performance of the proposed algorithm in addressing the problem of the traditional APF method easily falling into the local minimum. Test results show that the improved algorithm effectively enhances the safety of the intelligent vehicle during driving and allows the vehicle to overtake smoothly. Chu (2022) designed the expected heading compensation method to solve the large inflection point problem by smoothening the path while improving the repulsive field; however, the performance constraints of the double USV system were not considered. Current improvement methods for the traditional APF method mostly aim to improve a certain flaw of APF; this approach is not comprehensive enough and still allows room for improvement.
Herein, the path planning of the double USV oil spill recovery system (DUOSRS) is studied with the engineering background of oil spill recovery by double USVs towing oil booms. Figure 1 shows the whole process of the oil spill recovery of the DUOSRS, including approaching the target oil spill, rounding up the target oil spill, and consigning the target oil spill to the recovery site (Giron-Sierra et al., 2014). Considering the influence of obstacles on oil spill recovery, this research uses the improved APF method for path planning. After the three flaws of this method are analyzed, three improved algorithms are proposed by combining the motion performance constraints of the DUOSRS. The APF-123 algorithm for oil spill recovery is then established by combining these three algorithms. In consideration of the flaws of the APF and the process of oil spill recovery, multiple sets of simulation tests are designed. Results show that the proposed algorithms can ensure the safety of the system to track the oil spill in environments with numerous obstacles and increase the speed and success rate of the task.
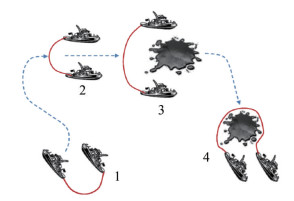 Figure 1 Diagram of double USV system for oil spill recovery
Figure 1 Diagram of double USV system for oil spill recovery2 Principles and flaws of APF
Owing to the wide area covered by the DUOSRS during sailing, the influence of obstacles in the path must be considered. Compared with other classical path planning algorithms, the APF method has the advantages of simpler principles, faster calculation speed, and better real-time performance. Hence, this work uses this method for the path planning of the double USV system.
First proposed by Khatib in 1986, the APF is a virtual force method (Khatib, 1986; Yu and Lu, 2021; Liu and Dou, 2021) for simulating natural fields. In this method, obstacles, target points, and USVs are treated as points, and the USV moves in a virtual force field composed of attractive and repulsive potential fields. The attractive potential field around the target point has an attractive effect on the USV, and the repulsive potential field around the obstacle has a repulsive effect on the USV. Figure 2 shows that under the combined force of attraction and repulsion, the USV avoids obstacles and tends to approach the target. The principle of the APF method is as follows:
$$ U=U_{\mathrm{att}}+U_{\mathrm{rep}} $$ (1) 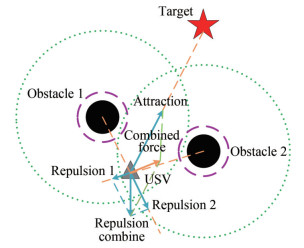 Figure 2 Force diagram of the USV
Figure 2 Force diagram of the USVwhere U is the combined potential field, Uatt is the attractive potential field, and Urep is the repulsive potential field. The directions of the negative gradient of the above three potential fields are the directions of the combined force, attractive force, and repulsive force.
1) Attraction calculation
The APF function of the target point to the USV is as follows:
$$ U_{\mathrm{att}}=\frac{1}{2} k_{\mathrm{att}}\left(X-X_t\right)^2 $$ (2) where katt is the attraction gain constant, Xt is the position of the target point, and X is the position of the USV.
The attraction direction of the target point on the USV is the direction of the negative gradient of the attractive potential field. The calculation formula for the attraction is as follows:
$$ F_{\text {att }}=-\nabla\left(U_{\text {att }}\right)=-k_{\text {att }}\left(X-X_t\right) $$ (3) 2) Repulsion calculation
The repulsive potential field function of the obstacle to the USV is as follows:
$$ U_{\text {rep }}=\left\{\begin{array}{l} \frac{1}{2} k_{\text {rep }}\left(\frac{1}{\rho_{\text {obs }}}-\frac{1}{\rho_0}\right)^2, \rho_{\text {obs }} \leqslant \rho_0 \\ 0, \rho_{\text {obs }}>\rho_0 \end{array}\right. $$ (4) where krep is the repulsion gain constant, ρobs is the distance between the USV and the obstacle, and ρ0 is the influence radius of the obstacle.When the distance between the USV and the obstacle is greater than ρ0, the USV is not subject to the repulsive force of the obstacle.
The repulsion direction of the obstacle to the USV is the negative gradient direction of the repulsive potential field. The calculation formula for the repulsion force is as follows:
$$ F_{\text {rep }}=-\nabla\left(U_{\text {rep }}\right)=\left\{\begin{array}{l} k_{\text {rep }}\left(\frac{1}{\rho_{\text {obs }}}-\frac{1}{\rho_0}\right) \frac{1}{\rho_{\text {obs }}^2} \frac{\partial \rho_{\text {obs }}}{\partial X}, \rho_{\text {obs }} \leqslant \rho_0 \\ 0, \rho_{\text {obs }}>\rho_0 \end{array}\right. $$ (5) The combined force of repulsion and attraction on the USV at its position X is as follows:
$$ F=F_{\mathrm{att}}+F_{\mathrm{rep}} $$ (6) The APF method has been widely used because of its advantages of simple calculation and easy implementation. However, this method also has certain flaws (Figure 3), which are summarized as follows:
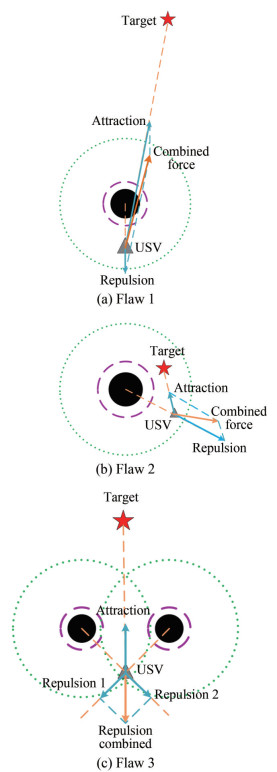 Figure 3 Diagram of the three flaws of the APF method
Figure 3 Diagram of the three flaws of the APF method1) Flaw 1: when the distance between the USV and the target is greater than the distance between the USV and the obstacle, the attractive force of the target point on the USV is greater than the repulsive force of the obstacle on the USV and the USV is very likely to collide with the obstacle;
2) Flaw 2: when the target point is within the influence distance of the obstacle and close to the obstacle, the repulsive force of the obstacle on the USV is greater than the attractive force of the target point on the USV and the USV cannot reach the target point;
3) Flaw 3: in tracking the target, the combined force of the repulsion and attraction on the USV might be zero in one position, and the USV will stop moving because it falls into the local minimum point.
Among these flaws 1 and 2 can be summarized as unreachable target problems, and 3 can be summarized as a local minima problem.
3 Improved APF algorithm for oil spill recovery
In this section, an improved algorithm APF-123 is proposed for the path planning of the system by combining the motion performance constraints of the DUOSRS with the three flaws of the APF method described in the previous section.
3.1 Definition of the virtual pilot
When the formation center of the double USVs in the oil spill recovery system is set as the virtual pilot (Jiang, 2020), the path planning of the DUOSRS can be simplified to that of the virtual pilot. As shown in Figure 4, USV1's coordinates are (x1, y1), its heading is ψ1, and its speed is v1. USV2's coordinates are (x2, y2), its heading is ψ2, and its speed is v2. The virtual pilot's coordinates are (xv, yv), the heading is ψv, and the speed is vv. The three relationships are as follows:
$$ \left\{\begin{array}{l} \left(x_v, y_v\right)=\left(\frac{x_1+x_2}{2}, \frac{y_1+y_2}{2}\right) \\ \psi_v=\frac{\psi_1+\psi_2}{2} \\ v_v=\frac{v_1+v_2}{2} \end{array}\right. $$ (7) 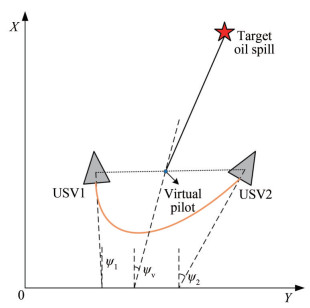 Figure 4 Diagram of the virtual pilot
Figure 4 Diagram of the virtual pilot3.2 Obstacle model of the DUOSRS
The virtual pilot is taken as the research object to simplify the calculation. However, in an actual situation, the DUOSRS covers a wide area of the sea and cannot be simplified into a single point for calculation; otherwise, a situation will arise where the virtual pilot can avoid the obstacles, but the DUOSRS will collide with the obstacles. To solve the above problems, the safety compensation radius for the formation of double USVs is added to the obstacle model of the traditional APF method. As shown in Figure 5, the actual radius of the obstacle is robs, the influence radius of the obstacle is ρ0, and the safety compensation radius is rs. In the subsequent research, the equivalent radius ro = robs + rs of the obstacle will be calculated instead of the actual radius to avoid the above situation.
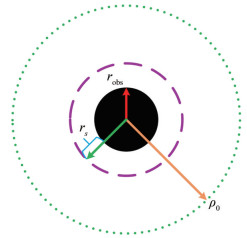 Figure 5 Diagram of the obstacle model
Figure 5 Diagram of the obstacle model3.3 Improved algorithm APF-123
Combined with the obstacle model, three algorithms, APF-1, APF-2, and APF-3, are proposed by improving the three flaws of the traditional APF method, respectively. Finally, the APF-123 algorithm is put forward by combining these three algorithms.
3.3.1 Improved algorithm for flaw 1
The improved algorithm for flaw 1 of the traditional APF method (APF-1) is shown in Figure 6, where the position of the virtual pilot is V (xv, yv), that of the obstacle is R(xobs, yobs), and that of the target point is T (xt, yt); ρobs is the distance between the virtual pilot and the obstacle; ρot is the distance between the target point and the obstacle; ρ0 is the influence radius of the obstacle; robs is the actual radius of the obstacle; ro is the equivalent radius of the obstacle; F is the combined force of attraction Fatt and repulsion Frep; l is the vertical distance of the obstacle to the line where F is located; Γ is the introduced safety compensation distance for flaw 1; S is the point obtained by extending the equivalent radius ro of the obstacle Γ along the direction l; β is the angle between the line VR and the X-axis; μ is the angle between the line VR and the direction F; θ is the angle between F and the X-axis; γ is the angle corresponding to the side RS in ΔVRS; and ε is the angle corresponding to the side VS in ΔVRS.
After calculation, the relationship between the above parameters can be obtained as follows:
$$ \left\{\begin{array}{l} \beta=\arctan \left(\frac{y_{\mathrm{obs}}-y_{\mathrm{o}}}{x_{\mathrm{obs}}-x_{\mathrm{o}}}\right) \\ \varepsilon=\frac{\pi}{2}-(\beta-\theta) \\ l=\rho_{\mathrm{obs}} \cos \varepsilon \\ \gamma=\arcsin \left(\frac{\left(r_{\mathrm{o}}+\mathit{\Gamma}\right) \sin \varepsilon}{\sqrt{\rho_{\mathrm{obs}}^2+\left(r_{\mathrm{o}}+\mathit{\Gamma}\right)^2-2 \rho_{\mathrm{obs}}\left(r_{\mathrm{o}}+\mathit{\Gamma}\right) \cos \varepsilon}}\right) \end{array}\right. $$ (8) 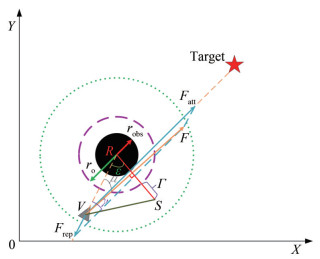 Figure 6 Diagram of the APF-1 algorithm
Figure 6 Diagram of the APF-1 algorithmThe improved part of the APF-1 algorithm is shown in the following Table 1:
Table 1 Improved part of the APF-1 algorithmImproved process for APF-1 When ρot > ρ0, μ < $\frac{\pi}{2}$ and l < robs + rs + Γ φox = β − γ Otherwise φox = θ where φox is the angle between the pilot's heading and the X-axis in Figure 6.
The introduced safety compensation distance Γ of the APF-1 algorithm is used to limit the minimum vertical distance between the obstacle and the line where F is located. According to Table 1, when ρot > ρ0, μ < $\frac{\pi}{2}$ and l < robs + rs + Γ, φox = β − γ, the virtual pilot sails away from the obstacle, effectively avoiding flaw 1.
According to Figure 6, the above discussion pertains to the case where the center point (xobs, yobs) of the obstacle is above the line between the virtual pilot and the target point. The analysis process for the other case is similar and will not be repeated.
3.3.2 Improved algorithm for flaw 2
The improved algorithm for flaw 2 of the traditional APF method (APF-2) is shown in Figure 7, where the position of the virtual pilot is V (xv, yv), that of the obstacle is R(xobs, yobs), and that of the target point is T (xt, yt); ρvt is the distance between the virtual pilot and the target point; ρobs is the distance between the virtual pilot and the obstacle; ρot is the distance between the target point and the obstacle; ρ0 is the influence radius of the obstacle; robs is the actual radius of the obstacle; ro is the equivalent radius of the obstacle; d is the vertical distance from the obstacle to the connection between the virtual pilot and the target point; Ω is the introduced safety compensation distance for flaw 2;Q is the point obtained by extending the equivalent radius ro of the obstacle Ω along the direction d; β is the angle between the line VR and the X-axis; η is the angle between the line VT and the X-axis; σ is the angle corresponding to the side VQ in ΔVRQ; γ1 is the angle corresponding to the side RQ in ΔVRQ; and λ is the angle corresponding to the side RT in ΔVRT.
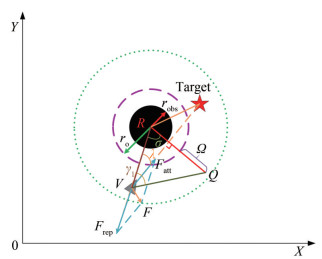 Figure 7 Diagram of the APF-2 algorithm
Figure 7 Diagram of the APF-2 algorithmAfter calculation, the relationship between the above parameters can be obtained as follows:
$$ \left\{\begin{array}{l} \lambda=\arccos \left(\frac{\rho_{\mathrm{obs}}^2+\rho_{v \mathrm{t}}^2-\rho_{\mathrm{ot}}^2}{2 \rho_{\mathrm{obs}} \rho_{v \mathrm{t}}}\right) \\ \sigma=\frac{\pi}{2}-\lambda \\ \eta=\arctan \left(\frac{y_t-y_v}{x_t-x_v}\right) \\ \gamma_1=\arcsin \left(\frac{\left(r_{\mathrm{o}}+\Omega\right) \sin \sigma}{\sqrt{\rho_{\mathrm{obs}}^2+\left(r_{\mathrm{o}}+\Omega\right)^2-2 \rho_{\mathrm{obs}}\left(r_{\mathrm{o}}+\Omega\right) \cos \sigma}}\right) \end{array}\right. $$ (9) When ρot < ρ0, the virtual navigator falls into flaw 2. The improved part of the APF-2 algorithm is shown in the following Table 2:
Table 2 Improved part of the APF-2 algorithmImproved process for APF-2 When λ ≥ $\frac{\pi}{2}$ or d ≥ robs + rs + Ω φox = η Otherwise φox = β − γ1 where φox is the angle between the pilot's heading and the X-axis in Figure 7.
The introduced safety compensation distance Ω of the APF-2 algorithm is used to limit the minimum vertical distance from the obstacle to the connection between the virtual pilot and the target point. Table 2 shows that when d ≥ robs + rs + Ω or λ ≥ $\frac{\pi}{2}$, φox = η, the virtual pilot approaches the target point directly along the line direction with the target point. Otherwise, φox = β − γ1, in which the virtual pilot approaches the target point while avoiding obstacles, effectively avoiding flaw 2.
According to Figure 7, the above discussion pertains to the case where the center point (xobs, yobs) of the obstacle is above the line between the virtual pilot and the target point. The analysis process for the other case is similar and will not be repeated.
3.3.3 Improved algorithm for flaw 3
Flaw 3 describes the situation where the virtual pilot may stop moving due to the local minimum point while tracking the target. The improved algorithm for flaw 3 of the traditional APF method (APF-3) is combined with the simulated annealing (SA) algorithm to improve the APF method and then with the motion performance constraints of the DUOSRS to screen the next position of the virtual pilot selected by the SA algorithm. This approach ensures that the path near the local minimum point will not exhibit large oscillation, and the DUOSRS can accurately track the planned path.
1) Principle of the SA algorithm
The Metropolis criterion is the basis of the SA algorithm, that is, to accept a new state with a certain probability. Assume the current state of the research object is Φ (k) and the state of the research object at the next moment is Φ (k + 1); according to the energy of gradient descent, the energy of the research object also changes from E (n) to E (n + 1). According to the Metropolis criterion, the change in the acceptance probability of the state of the research object changing from Φ (k) to Φ(k + 1) is defined as follows:
$$ P=\left\{\begin{array}{l} 1, \quad E(n+1)<E(n) \\ e^{-\frac{E(n+1)-E(n)}{T}}, \quad E(n+1) \geqslant E(n) \end{array}\right. $$ (10) where T is the temperature in the SA algorithm reduced in a certain way, as shown in the following formula:
$$ T(t)=\alpha T(t-1) $$ (11) where α is an arbitrary positive constant of the interval (0.85, 1) selected according to the actual situation, and t is the number of iterations.
Formula (11) indicates that if the energy goes down, then the acceptance probability of the state of the research object from Φ(k) to Φ(k+1) is 1; that is, it can be accepted. If the energy increases, it will be accepted with a certain probability. A random probability ξ is set. When P >ξ, accept the state of the research object from Φ (k) to Φ (k + 1); otherwise, proceed to the next step (Zang et al., 2021; Liu et al., 2021; Han, 2021).
2) APF-3 algorithm
When the local minimum point is removed by the APF method based on SA, the virtual pilot will have a relatively violent oscillation near the local minimum point, which easily causes "entanglement" and "towing separation" in the tracking of the DUOSRS and then the failure of the recovery task. Combined with the maximum heading change angle of the DUOSRS, the next position of the virtual pilot selected by the SA algorithm is screened twice to ensure that the path planning near the local minimum point is in line with the motion performance constraints of the double USV system and no large oscillation appears so that the DUOSRS can accurately track the planned path. The maximum heading change angle of the DUOSRS is calculated as follows:
$$ \varphi_m=\frac{90 \times v_v \times \Delta t}{\pi R_s} $$ (12) Here, φm is the maximum heading change angle of the DUOSRS, Rs is the turning radius of the USV located outside the DUOSRS at the current moment, Δt is the time step, and vv is the speed of the virtual pilot.
The secondary screening mechanism is shown in Table 3.
Table 3 APF-3 algorithm screening random point mechanismSecondary screening mechanism When φΔ > φm accept this random point as the next time position of the virtual pilot Otherwise reselect the random point In the table, φΔ is the absolute value of the change in the heading angle of the DUOSRS.
The specific steps for the APF-3 algorithm to escape from the local minimum point are as follows:
Step 1: Perform parameter initialization to determine the initial temperature T0, termination temperature Tf, random probability ξ, and maximum heading change angle φm of the DUOSRS.
Step 2: Select a random point X1 near the virtual pilot's current position V.
Step 3: Calculate the potential field of the position V and position X1 as U (V) and U (X1) respectively. If U (X1) − U (V) < 0, then the next position of the virtual pilot is X1. If U (X1)− U (V) ≥ 0, then the probability P of accepting X1 is calculated according to the Metropolis criterion. If P > ξ, then the next position of the virtual pilot is X1; otherwise, return to step 2 to select a random point again.
Step 4: Before accepting X1 as the next position of the virtual pilot, calculate the difference φΔ between the current and next position heading of the virtual pilot and compare it with φm. If φΔ ≤ φm, then accept the next position of the virtual pilot as X1; otherwise, return to step 2 to select a random point again.
Step 5: After the virtual pilot reaches the position X1, determine whether the combined force of attraction and repulsion on the virtual pilot's position is 0. If the combined force is not 0, then the virtual pilot eliminates the local minimum point and keeps tracking the target point; otherwise, return to step 2 to select a random point again.
The flow chart of the APF-3 algorithm out of the local minimum point is shown in Figure 8.
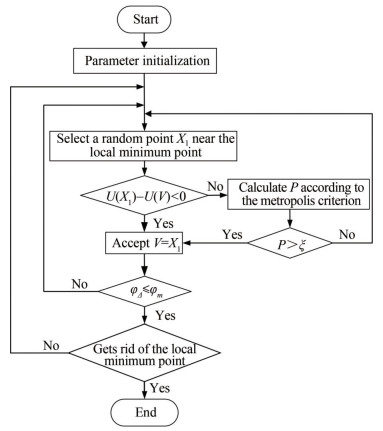 Figure 8 Flow chart of the APF-3 algorithm
Figure 8 Flow chart of the APF-3 algorithmThe APF-123 algorithm for oil spill recovery is obtained by combining the above three algorithms, and its flow chart is shown in Figure 9.
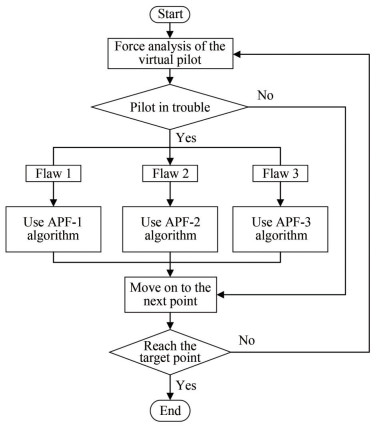 Figure 9 Flow chart of the APF-123 algorithm
Figure 9 Flow chart of the APF-123 algorithm4 Simulation tests and results
Simulation tests are designed and carried out in the following four parts to verify the effectiveness and feasibility of the improved algorithms:
1) The APF-1 algorithm and APF method are compared under the condition of flaw 1 to verify the effectiveness of the APF-1 algorithm;
2) The APF-2 algorithm and APF method are compared under the condition of flaw 2 to verify the effectiveness of the APF-2 algorithm;
3) The APF-3 algorithm, APF method, and APF algorithm based on SA are compared under the condition of defect 3 to verify the effectiveness of the APF-3 algorithm;
4) The APF-123 algorithm is used for the tracking and obstacle avoidance tests of dynamic targets to verify its feasibility and effectiveness when applied to the oil spill recovery system.
4.1 Simulation comparison test under the condition of flaw 1
The starting position of the virtual pilot is (0, 0), the position of the target point is (350, 350), the position of the obstacle is (50, 50), the actual radius of the obstacle robs = 15 m, the safety compensation radius rs = 5 m, the influence radius of the obstacle ρ0 = 30 m, the attraction gain constant katt = 10, the repulsion gain constant krep = 5 × 105, and the safety compensation distance Γ = 6 m in the APF-1 algorithm. The simulation result is shown in Figure 10.
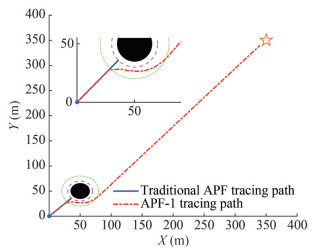 Figure 10 APF and APF-1 tracking paths under the condition of flaw 1
Figure 10 APF and APF-1 tracking paths under the condition of flaw 1Figure 10 shows that under the condition of flaw 1, the tracking path planned by the APF method crashes into the equivalent radius of the obstacle, resulting in the failure of the tracking task of the virtual pilot. By contrast, the tracking path planned by the APF-1 algorithm always maintains a safe distance of no less than 6 m from the equivalent radius of the obstacle. In addition, the virtual pilot is still able to track the target point under the condition of flaw 1, ensuring the successful completion of the oil spill recovery task.
4.2 Simulation comparison test under the condition of flaw 2
The starting position of the virtual pilot is (0, 0), the position of the target point is (200, 200), the position of the obstacle is (175, 200), the actual radius of the obstacle robs = 10 m, the safety compensation radius rs = 5 m, the influence radius of the obstacle ρ0 = 45 m, the attraction gain constant katt = 10, the repulsion gain constant krep = 4 × 106, and the safety compensation distance Ω = 8 m in the APF-2 algorithm. The simulation result is shown in Figure 11(a).
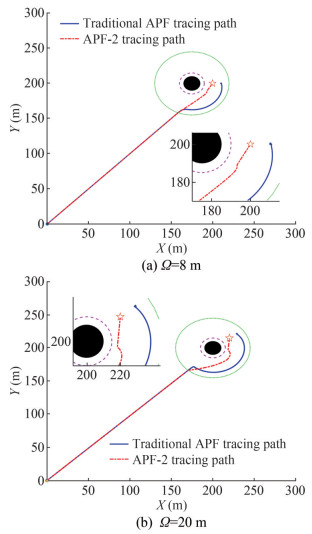 Figure 11 APF and APF-2 tracking paths under the condition of flaw 2
Figure 11 APF and APF-2 tracking paths under the condition of flaw 2In the above simulation conditions, the position of the target point is changed to (220, 215), that of the obstacle is changed to (200, 200), and the safety compensation distance is Ω = 20 m in the APF-2 algorithm. The simulation comparison test is conducted, and the result is shown in Figure 11(b).
Figure 11 shows that when the target point is located within the influence distance of the obstacle and relatively close to the equivalent radius of the obstacle, the path planned by the APF method causes the "unreachable target" phenomenon. When the repulsive force received by the virtual pilot is greater than the attractive force, the virtual pilot oscillates irregularly in a small area when it is still a distance away from the target point, leading to the failure of the tracking task. The APF-2 algorithm allows the virtual pilot to track the target point while maintaining a certain safe distance from the equivalent radius of the obstacle, ensuring the success of the oil spill recovery task. In addition, the planned paths are shortened, which reduces energy consumption. Compared with the APF method, the APF-2 algorithm has better practicality.
4.3 Simulation comparison test under the condition of flaw 3
The starting position of the virtual pilot is (0, 0); the position of the target point is (240, 240); the positions of the obstacles are (40, 40), (120, 60), (60, 120), (100, 100), and (180, 180); the actual radius of the obstacle robs = 5 m; the safety compensation radius rs = 5 m; the influence radius of the obstacle ρ0 = 25 m; the attraction gain constant katt = 10; the repulsion gain constant krep = 5 × 105, the initial temperature of the APF-3 algorithm and APF algorithm based on SA is 10; the termination temperature is 0.1; and the random probability is ξ = 0.9. The simulation result is shown in Figure 12.
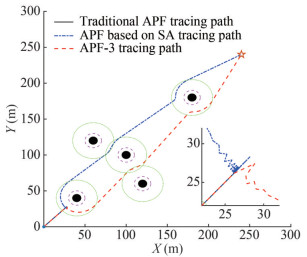 Figure 12 Tracking paths of APF, APF based on SA, and APF-3 under the condition of flaw 3
Figure 12 Tracking paths of APF, APF based on SA, and APF-3 under the condition of flaw 3Figure 12 shows that the path planned by the APF method causes the virtual pilot to fall into the local minimum point and stop moving, resulting in task failure. Meanwhile, the path planned by the APF algorithm based on SA oscillates violently near the local minimum point, leading to "entanglement" and "towing separation" in the tracking of the DUOSRS and, consequently, the failure of the recovery task. The path planned by the APF-3 algorithm is relatively stable and has less oscillation near the local minimum point, meeting the motion performance constraints of the system and ensuring the success of the task. The effectiveness of the APF-3 algorithm in the oil spill recovery task of double USVs is verified by comparing the result with the tracking paths planned by the APF method and APF algorithm based on SA.
4.4 Dynamic target tracking and obstacle avoidance test
Oil spills in the ocean drift and expand due to the influence of the environment. Given that the virtual pilot is tracking the centroid of the oil spill coverage area and the expansion and drift of the oil spill causes the movement of the centroid, studying the static target tracking is not enough. The following is the dynamic target tracking simulation test.
4.4.1 Target tracking test in a static obstacle environment
The starting position of the virtual pilot is (0, 0), and that of the dynamic target point is (220, 220); the positions of the obstacles are (30, 40), (60, 80), (120, 40), (190, 180), (150, 125), (115, 90), (75, 150), (120, 160), (210, 110), (175, 50), and (150, 200); the actual radius of the obstacle robs = 5 m; the safety compensation radius rs = 5 m; the influence radius of the obstacle ρ0 = 25 m; the attraction gain constant katt = 10; the repulsion gain constant krep = 5 × 105; the initial temperature of APF-123 algorithm is 10; the termination temperature is 0.1; and the random probability ξ=0.9.
1) Simulation test of regular motion of the target
The speed of the target is set as vt = 0.2 m/s, the heading of the target is set as φt = 120°, i.e. moving at an angle of 120° to the X-axis, and the speed of the virtual pilot vv = 1.0m/s. The result is shown in Figure 13(a).
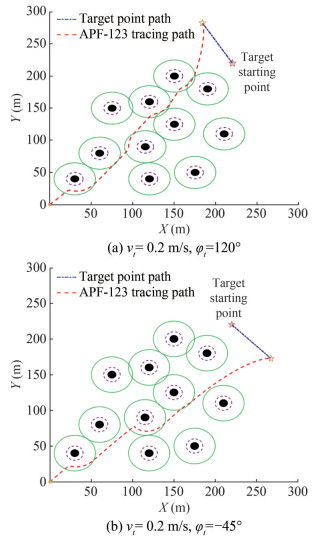 Figure 13 APF-123 tracks regularly moving targets in an environment with static obstacles
Figure 13 APF-123 tracks regularly moving targets in an environment with static obstaclesWith the other conditions unchanged, the heading of the target is set as φt= −45°. The result is shown in Figure 13(b).
Figure 13 shows that the path planned by the APF-123 algorithm allows the virtual pilot to successfully track the regular motion dynamic target under the influence of multiple static obstacles, ensuring the success of the recovery task.
2) Simulation test of the irregular motion of the target Owing to the expansion and drift of the oil spill, the centroid of the oil spill on the sea surface changes irregularly. Hence, a simulation test of the irregular motion of the target point must be carried out. The basic parameters in the simulation are consistent with those for the regularly moving target point described above, with only the speed and direction of the target point being changed. The target is set to move irregularly with a speed vt = 0.5 × rand (1) m/s along an angle of 270° × rand (1) with the X-axis. The result is shown in Figure 14(a).
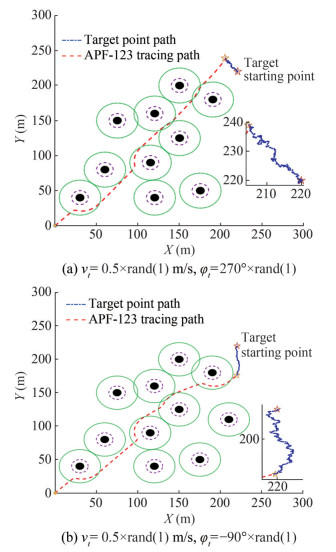 Figure 14 APF-123 tracks irregularly moving targets in an environment with static obstacles
Figure 14 APF-123 tracks irregularly moving targets in an environment with static obstaclesWith the other conditions unchanged, the target is set to move irregularly along an angle of − 90° × rand (1) with the X-axis. The result is shown in Figure 14(b).
Figure 14 shows that the path planned by the APF-123 algorithm allows the virtual pilot to successfully track the irregularly moving dynamic target under the influence of multiple static obstacles, ensuring the success of the recovery task.
4.4.2 Target tracking test in a dynamic obstacle environment
Owing to the presence of other moving objects in the environment and the fact that some marine debris can drift on the surface of the sea under the action of wind and waves, simulation tests in the dynamic obstacle environment must be carried out.
The positions of the three static obstacles are set as (70, 130), (200, 220), and (250, 200), and the initial position of the five dynamic obstacles as (40, 20), (60, 80), (120, 40), (210, 170), and (150, 125). They make uniform linear motion along the angles of 120°, 0°, 60°, −135°, and 90° to the X-axis, respectively, and the speed is 0.2m/s. The starting point of the dynamic target is (220, 220), and it moves irregularly along an angle of − 120° × rand (1) with the X-axis at the speed of vt = 0.4 × rand(1) m/s. The virtual pilot speed is vv = 1 m/s. The rest of the parameters are the same as those in 4.4.1. The paths planned using the APF method and APF-123 algorithm are shown in Figures 15(a) and 15(b), respectively.
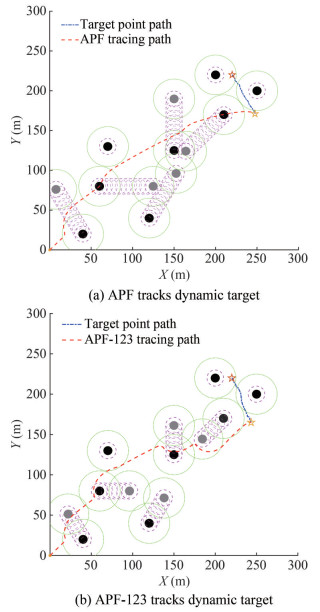 Figure 15 APF and APF-123 track dynamic targets in an environment with regular motion obstacles
Figure 15 APF and APF-123 track dynamic targets in an environment with regular motion obstaclesThe black circle in the figure indicates the starting position of the obstacle, and the gray circle indicates the position of the obstacle when the virtual pilot tracks the target. In this test, the number of iterative steps to track the target is set to 325 for the APF method and 181 for the APF-123 algorithm, and the efficiency increases by 44.3%.
The dynamic target is set to move irregularly along an angle of 60° × rand (1) with the X-axis, and the dynamic obstacles are set to move along the angles of 180° × rand (1), 0°, 60°, 45° × rand (1), 90° to the X-axis. The rest of the conditions remain unchanged. The paths planned using the APF method and APF-123 algorithm are shown in Figures 16(a) and 16(b), respectively.
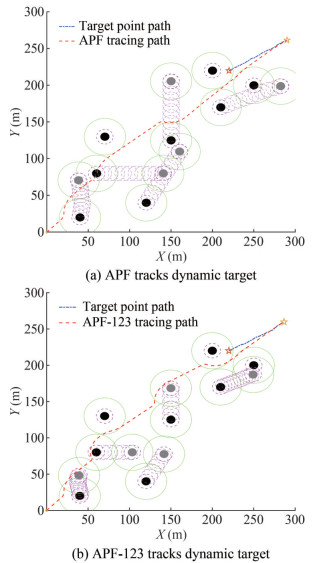 Figure 16 APF and APF-123 track dynamic targets in an environment with irregular motion obstacles
Figure 16 APF and APF-123 track dynamic targets in an environment with irregular motion obstaclesIn this test, the number of iterative steps to track the target is set to 404 for the APF method and 217 for the APF-123 algorithm, and the efficiency increases by 46.3%.
Figures 15 and 16 show that although the path planned by the APF-123 algorithm is not as smooth as that planned by the APF method, the number of iterative steps produced by the APF-123 algorithm is less than 60% that produced by the APF method. In the oil spill recovery task, quickly completing the tracking and reducing the spread of the oil spill are necessary to avoid great pollution, so the APF-123 algorithm with faster speed has better practicality than the APF method.
In summary, comparison tests are set up in sections 4.1– 4.3 for each of the three flaws of the APF method. The results prove that the three improved algorithms can effectively prevent the USVs from falling into the flaws of the APF method and failing the task and improve the success rate of the task, implying their feasibility and practicability. In section 4.4, the dynamic target tracking and obstacle avoidance tests are carried out. The results show that the virtual pilot can track the dynamic oil spill in a complex environment, and the speed is increased by more than 40% compared with that using the APF method. This finding verifies the feasibility and superiority of the APF-123 algorithm for the oil spill recovery system.
5 Conclusions
Against the engineering background of oil spill recovery by double USVs towing oil booms, the path planning of the double USV system for oil spill recovery is studied using the improved APF method. First, the three flaws of the APF method are analyzed in principle, and three improved algorithms are proposed by combining them with the motion performance constraints of the DUOSRS. Second, the APF-123 algorithm for the oil spill recovery system is proposed by combining the three algorithms. Finally, in consideration of the flaws of the APF method and the process of oil spill recovery, several sets of simulation tests under different scenarios are conducted. The results show that the proposed algorithm allows the virtual pilot to safely track the dynamic motion target in a short time, making it a feasible and superior approach.
Although the simulations have successfully accomplished the tracking task, the following are suggested as areas for continued development:
1) Oil spills drift and expand irregularly on the sea surface, and their shape changes irregularly. Hence, tracking the centroid of the oil spill without considering the boundary condition is insufficient. The drift and expansion models of the real oil spill must be considered in subsequent research to achieve high tracking accuracy.
2) In the simulation tests, the position, moving speed, and direction of the obstacle are assumed to be known. In a real marine environment, these parameters may not be accurately measured. Therefore, real ship experiments are warranted to further verify the effectiveness of the proposed algorithm.
Competing interest Yulei Liao is an editorial board member for the Journal of Marine Science and Application and was not involved in the editorial review, or the decision to publish this article. All authors declare that there are no other competing interests. -
Figure 1 Diagram of double USV system for oil spill recovery
Figure 2 Force diagram of the USV
Figure 3 Diagram of the three flaws of the APF method
Figure 4 Diagram of the virtual pilot
Figure 5 Diagram of the obstacle model
Figure 6 Diagram of the APF-1 algorithm
Figure 7 Diagram of the APF-2 algorithm
Figure 8 Flow chart of the APF-3 algorithm
Figure 9 Flow chart of the APF-123 algorithm
Figure 10 APF and APF-1 tracking paths under the condition of flaw 1
Figure 11 APF and APF-2 tracking paths under the condition of flaw 2
Figure 12 Tracking paths of APF, APF based on SA, and APF-3 under the condition of flaw 3
Figure 13 APF-123 tracks regularly moving targets in an environment with static obstacles
Figure 14 APF-123 tracks irregularly moving targets in an environment with static obstacles
Figure 15 APF and APF-123 track dynamic targets in an environment with regular motion obstacles
Figure 16 APF and APF-123 track dynamic targets in an environment with irregular motion obstacles
Table 1 Improved part of the APF-1 algorithm
Improved process for APF-1 When ρot > ρ0, μ < $\frac{\pi}{2}$ and l < robs + rs + Γ φox = β − γ Otherwise φox = θ Table 2 Improved part of the APF-2 algorithm
Improved process for APF-2 When λ ≥ $\frac{\pi}{2}$ or d ≥ robs + rs + Ω φox = η Otherwise φox = β − γ1 Table 3 APF-3 algorithm screening random point mechanism
Secondary screening mechanism When φΔ > φm accept this random point as the next time position of the virtual pilot Otherwise reselect the random point -
Asl NA, Menhaj BM, Sajedin A (2013) Control of leader-follower formation and path planning of mobile robots using Asexual Reproduction Optimization (ARO). Applied Soft Computing Journal 14: 563–576. DOI: 10.1016/j.asoc.2013.07.030 Bucas G, Saliot A (2002) Sea transport of animal and vegetable oils and its environmental consequences. Marine Pollution Bulletin 44(12): 1388–1396. DOI: 10.1016/S0025-326X(02)00303-X Chu Y (2022) Research on the formation control method of dual unmanned surface vehicle for oil spill containment. Master thesis, Harbin Engineering University, Harbin Drake D, Koziol S, Chabot E (2018) Mobile robot path planning with a moving goal. IEEE Access 6: 12800–12814. DOI: 10.1109/access.2018.2797070 Duan H, Ma G, Luo D (2008) Optimal formation reconfiguration control of multiple UCAVs using improved particle swarm optimization. Journal of Bionic Engineering 5(4): 340–347. DOI: 10.1016/S1672-6529(08)60179-1 Giron-Sierra JM, Gheorghita AT, Angulo G, Jimenez JF (2014) Preparing the automatic spill recovery by two unmanned boats towing a boom: Development with scale experiments. Ocean Engineering 95(1): 23–33. DOI: 10.1016/j.oceaneng.2014.11.034 Han L (2021) Multiphase sequence search based on simulated annealing algorithm. Yangtze River Information and Communication 34(2): 52–55. DOI: 10.3969/j.issn.1673-1131.2021.02.017 Hao Y, Agrawal K (2005) Planning and control of UGV formations in a dynamic environment: A practical framework with experiments. Robotics and Autonomous Systems 51(2–3): 101–110. DOI: 10.1016/j.robot.2005.01.001 Jiang W (2020) Research on cooperative planning and control method of double unmanned surface vehicle for oil spill roundup. Master thesis, Harbin Engineering University, Harbin Khatib O (1986) Real-time obstacle avoidance for manipulators and mobile robots. The International Journal of Robotics Research 5(1): 90–98. DOI: 10.1177/027836498600500106 Lee M, Jung J (2015) Pollution risk assessment of oil spill accidents in Garorim Bay of Korea. Marine Pollution Bulletin 100(1): 297–303. DOI: 10.1016/j.marpolbul.2015.08.037 Li Y, Zhang S, Chai L (2023) Cooperative obstacle avoidance trajectory planning for mobile robotic arm based on artificial potential field DDPG algorithm. Computer Integrated Manufacturing Systems: 1–15 Liao Y (2012) Research on nonlinear motion control method of unmanned vehicle. PhD thesis, Harbin Engineering University, Harbin Liao Y, Jiang Q, Du T, Jiang W (2019) Redefined output model-free adaptive control method and unmanned surface vehicle heading control. IEEE Journal of Oceanic Engineering 45(3): 714–723. DOI: 10.1109/joe.2019.2896397 Liu N, Tan Y, Mo W, Han H, Li L (2021) Optimization design of halbach linear generator based on simulated annealing algorithm. Transactions of China Electrotechnical Society 36(6): 1210–1218. DOI: 10.19595/j.cnki.1000-6753.tces.200442 Liu T, Tian S (2006) Treatment of oil spill at sea and future development trend. China Water Transportation (Theoretical Edition) 4(11): 27–29 Liu X, Dou Y (2021) Research on obstacle avoidance of small cruise vehicle based on improved artificial potential field method. Journal of Physics: Conference Series 1965(1): 12–24. DOI: 10.1088/1742-6596/1965/1/012036 Liu Y, Richard B (2016) The angle guidance path planning algorithms for unmanned surface vehicle formations by using the fast marching method. Applied Ocean Research 59: 327–344. DOI: 10.1016/j.apor.2016.06.013 Manley JE (2008) Unmanned surface vehicles, 15 years of development. OCEANS MTS/IEEE, Quebec City, Canada, 1–4. DOI: 10.1109/OCEANS.2008.5152052 Orozco-Rosas U, Montiel O, Sepúlveda R (2019) Mobile robot path planning using membrane evolutionary artificial potential field. Applied Soft Computing Journal 77: 236–251. DOI: 10.1016/j.asoc.2019.01.036 Orozco-Rosas U, Picos K, Pantrigo JJ, Montemayor AS, Cuesta-Infante A (2022) Mobile robot path planning using a QAPF learning algorithm for known and unknown environments. IEEE Access 10: 84648–84663. DOI: 10.1109/ACCESS.2022.3197628 Qu H, Xing K, Alexander T (2013) An improved genetic algorithm with co-evolutionary strategy for global path planning of multiple mobile robots. Neurocomputing 120: 509–517. DOI: 10.1016/j.neucom.2013.04.020 Sang H, You Y, Sun X, Zhou Y, Liu F (2021) The hybrid path planning algorithm based on improved A* and artificial potential field for unmanned surface vehicle formations. Ocean Engineering 223: 108709. DOI: 10.1016/j.oceaneng.2021.108709 Sun L, Fu Z, Tao F, Si P, Song S (2022) Research on obstacle avoidance algorithm for intelligent vehicles with improved artificial potential field. Journal of Henan University of Science & Technology (Natural Science) 43(5): 28–34+41+5-6. DOI: 10.15926/j.cnki.issn1672-6871.2022.05.005 Tan G, Zou J, Zhuang J, Wan L, Sun H, Sun Z (2020) Fast marching square method based intelligent navigation of the unmanned surface vehicle swarm in restricted waters. Applied Ocean Research 95: 102018. DOI: 10.1016/j.apor.2019.102018 Wang Y (2015) Research on path planning technology of unmanned boat formation based on fast marching method. Master thesis, Harbin Engineering University, Harbin Yu WQ, Lu YG (2021) UAV 3D environment obstacle avoidance trajectory planning based on improved artificial potential field method. Journal of Physics: Conference Series 1885(2): 20–22. DOI: 10.1088/1742-6596/1885/2/022020 Yuan C, Weng S, He Y, Shen J, He L, Wang T (2019) Research on integrated path planning decision algorithm based on improved artificial potential field method. Transactions of the Chinese Society for Agricultural Machinery 50(9): 394–403. DOI: 10.6041/j.issn.1000-1298.2019.09.046 Zang Y, Xu Z, Huang A, Ai S, Xia H, Kan R (2021) Reconstruction of heterogeneous combustion field distribution based on improved simulated annealing algorithm. Acta Physica Sinica 70(13): 229–240. DOI: 10.7498/aps.70.20202124 Zhang M, Zhang Q, Wang Y, Ding Z (2020) A review of research on waterborne oil spill recovery ship. Journal of Qingdao Ocean Shipping Mariners College 41(1): 35–41. DOI: 10.3969/j.issn.2095-3747.2020.01.008 Zheng H, Long M, Su H, Wang H (2021) Cooperative formation of aircraft and boats Combined with Virtual Structure and Artificial Potential Field. Proceedings of the 40th Chinese Control Conference, Shanghai 15: 634–639. DOI: 10.26914/c.cnkihy.2021.029286
