 2016, Vol. 36
2016, Vol. 36



区域土壤重金属污染评价是土壤环境研究的和污染防治的重要基础(王庆仁等,2002;马成玲等,2006;Zhou et al., 2013),目前对区域土壤重金属污染程度的评价方法已有很多研究,如单因子指数法、地累积指数法、生态风险系数法等简单指数法,内梅罗指数、加权综合指数、生态风险综合系数等综合指数法,这些评价模型在土壤重金属评价领域得到了广泛应用(钟晓兰等,2007;胡春华等,2012;Krishna et al., 2013;Okedeyi et al., 2014).为了解决传统的指数法评价难以描述土壤重金属污染的不确定性问题,模糊数学方法在土壤重金属污染评价领域得到广泛的应用(朱青等,2004;Onkal-Engin et al., 2004;樊梦佳等,2010;李如忠等,2011;李飞等,2012).核密度估计法不对数据的分布形式进行预先的假设,具有更广泛的适用性(吴喜之和王兆军,1996),但目前核密度估计模型在自然科学上的应用不多,主要是集中在社会、经济以及医药等领域(杨国昌等,2011;陈璐等,2012;Yang et al., 2014).
不同评价方法各有应用特点,评价方法主要是掌握研究区域总体污染程度,但很少有学者对不同方法评价结果进行系统的总结与比较,即使有也仅仅停留在理论上的介绍,缺乏定量探讨各方法评价结果的差异(范拴喜等,2010;郭笑笑等,2011).因此,本文以经济快速发展的昆山市为例,采用简单数理统计、正态模糊数法和核密度估计法对研究区土壤重金属总体污染程度进行评价,从评价便捷性、结果的准确度与全面性方面揭示各方法的差异.
2 研究区概况(Study area)昆山市位于江苏省东南部,上海和苏州之间,地处东经120°48′21″~121°09′04″E,北纬31°06′34″~ 31°32′36″N,是上海经济圈重要的新兴工商城市,2013年人均GDP达2.89万美元,连续9年被评为全国百强县市之首.昆山市属于典型的北亚热带季风气候,年平均气温17.6 ℃,年平均降水量1200.4 mm,全市土壤分为水稻土、潮土、沼泽土、黄棕壤4个土类,水稻土在各类土壤总面积中占比最高,达93.8%.
3 数据来源和方法(Data resources and study methods) 3.1 数据来源研究数据为2 km×2 km网格的土壤采样测试数据,将研究区划分成2 km×2 km的网格,每个网格作为一个采样点,对于区域边界上的破碎网格按照四舍五入来处理,共选取232个样点.按照5点混合采样法采集0~20 cm表层土壤样品,四分法取分析样品约1.5 kg.样品经自然风干,挑除石砾和植物残体,研磨过100目筛,并充分混匀以待用.
 |
| 图1 采样点分布图 Fig.1 Spatial distribution of sampling |
本文侧重研究不同方法下土壤重金属污染程度评价结果的差异,较土壤重金属综合污染评估而言,单元素评估可以免去综合污染的加权求和,能减少不同权重对结果的干扰.已有研究表明:作为水网地区的昆山市土壤As含量相对不高,空间分异程度也较小;Cd含量相对较高,空间分异程度也较大(万红友等,2006;钟晓兰等,2008).这两种元素具有较强的代表性,能在污染评估结果中形成较为鲜明的对比,因此,本文选取As和Cd为代表元素进行研究.Cd采用分别加入浓盐酸、浓硝酸在150 ℃的有孔电热板上加热反应、再加入HF-HNO3-HClO4置于200 ℃有孔电热板上加热消解后,采用ICP-MS法测定;As采用1 ∶ 1的王水沸水浴消解后用还原气化-原子荧光光谱法进行测定.
3.2 研究方法 3.2.1 地累积指数法地累积指数法通常称为Muller指数,能很好地反映自然变化与人为活动因素对重金属分布带来的影响,它以研究区重金属含量背景值为标准,是评价区域重金属污染的重要污染指数.具体公式如下:

本文的重金属含量背景值采用应用广泛的《中国土壤元素背景值》(国家环境保护局和中国环境监测总站,1990)中全国各省份土壤微量金属元素背景值.
3.2.2 正态模糊数模型模糊数法是针对区域土壤重金属污染的模糊、不确定性特征所进行的评价,能更为全面地反映重金属污染程度信息,可解决传统的指数法评价难以描述土壤重金属污染的不确定性问题.模糊数模型的核心是构建隶属度函数,目前主要是采用线性形式来进行描述,例如三角与梯形模糊数法,本文采用正态模糊数评价方法,通过概率密度曲线间接反映隶属度大小(易昊旻等,2013).
设论域为R+(正实数域)上的一个模糊数,定义$\tilde{A}$的隶属函数为:μ $\tilde{A}$(x):R→$0,1],x∈R,正态模糊数隶属函数μ$\tilde{A}$(x)表示为:

$\tilde{A}$∈F(U),对于任意α∈0,],记:($\tilde{A}$)αΔ AαΔ {μ|(μ)≥a}
一般而言,α取0.9是普遍可以接受的置信度水平(李如忠,2011),根据式(2)易求得区间数Aα:

然后计算一定置信度水平下区域重金属的地累积指数区间数,对地累积指数区间数进行各污染等级的隶属度计算,根据区间数对各污染程度等级的隶属度,进行加权求和得出该区间数的重金属污染程度.对于既得的正态隶属度曲线,通过求取定积分的方式来获取研究区土壤重金属不同污染等级的面积占比.
3.2.3 核密度估计模型核密度估计作为非参数估计理论中的一个典型方法,该方法的特点在于对采样点数据的分布形式不作任何假定,仅依赖于数据本身,是完全数据驱动下的密度函数的估计.因此在土壤重金属数据的信息挖掘上有很强的适用性.
对于样本数据x1,x2...xn,核密度估计公式为:
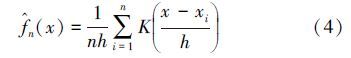
核函数为关于y轴对称并且其积分为1的概率密度函数,常用的核函数种类见表 1.根据以往学者的研究,不同核函数对结果的影响较小(郭照庄等,2008),本文选择应用较为广泛的高斯核函数进行研究.
| 表1 常见核函数类型 Table 1 Commonly used kernel functions |
窗宽对核密度估计的结果十分重要,它的值如果过大,则核密度曲线会过于平滑,反之,则曲线会出现很严重的锯齿.确定一个合理的窗宽值至关重要,最准确和科学的方法是计算核估计式关于真实概率密度函数的均方误差(MSE),但这种方法却不能在实际研究中进行应用,因为其用到了先验知识.以本文的研究为例,若研究区重金属含量的概率密度分布真实值已经掌握,就完全没有进行核估计的必要,因此,该方法仅仅具有理论上的意义.
在不需要先验知识的情况下,交叉验证法对样本数在100~1000的范围内窗宽的选取精度较高(任温军和宋向东,2009),但容易陷入局部最优化.为了避免这种影响,本文将交叉验证法所得窗宽值与实际应用中的一个经验值取平均,作为最终的窗宽值.公式(5)为交叉验证法选取窗宽的公式(吴喜之和赵博娟,2009):公式(6)为实际应用中确定窗宽的经验公式,公式(7)为最终的窗宽公式.
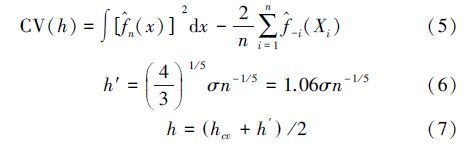
本文将采样点数据进行克里格插值后所得到的栅格数据作为参照值,虽然该参照值本质上仍旧是离散的点,其统计结果与真实值相比仍存在误差,但可以参照该值来测算各评价方法结果的偏差.
对栅格图进行数据统计分析,可以得到表 2的数据作为评价的参照值.从表 2可以看出,参与统计的栅格图像元值达到了50741个,数据量扩大了218倍.统计分析可知,研究区As、Cd的平均地累积指数参照值分别为-0.56、0.26,总体污染程度分别是清洁和轻度污染.
| 表2 研究区土壤重金属地累积指数参照值 Table 2 Reference values about soil heavy metals in the study area |
采用地累积指数法,通过取平均值计算区域总体污染程度,再按照各个样点的污染程度等级进行简单统计,得到各级别污染区域的面积占比.具体评价结果见表 3.从表 3结果可以看出,运用单纯地累积指数进行评价偏差会较大,区域平均地累积指数相对于参照值的偏差分别为14.3%、19.2%.As在整个研究区的平均污染程度较低,总体污染程度评价结果偏低,各污染等级面积占比的偏差不大;各污染区域面积占比的偏差在Cd中体现较为明显,重金属污染评价结果偏高.总体上来看,运用简单统计所得到的结果偏差比较大,如何在评价模型上进行一些改进以减少这种偏差很有必要.
| 表3 基于简单地累积统计法的研究区土壤As、Cd污染程度评价结果 Table 3 Assessment based on geo-accumulation index for the contamination level of soil As and Cd |
研究区重金属的正态或对数正态分布特征是运用正态模糊数法评价的前提条件和基础,进行K-S检验,得到Cd的sig值为0.062,通过对As进行两次对数转换,其sig值为0.107,Cd、As在0.05的显著水平下分别服从正态、对数正态分布,即可对研究区进行基于正态模糊数模型的As、Cd污染评价.
| 表4 基于正态模糊数的研究区土壤As、Cd污染程度评价结果 Table 4 Assessment for the contamination level of soil As and Cd based on normal fuzzy numbers |
Cd计算得到标准化后清洁、轻度和中度污染面积占比分别是23.02%、71.96%、5.02%,偏差为+5.10%、-4.20%、-0.90%.与参照值相比,清洁区域面积占比有所提高,而轻度和中度污染的区域面积占比有不同幅度的下降,总体评价结果有一定程度偏低.As计算结果为归一化后清洁、轻度和中度污染面积占比分别为99.81%、0.19%、0,清洁、清度污染的偏差分别为+0.11%、-0.11%.结合表 3的结果,该占比结果更加接近于参照值,说明对于占比十分微小的轻度污染面积占比,正态模糊数模型仍有一定的识别功能.
4.3.2 与传统的线性模型评价结果的定量比较基于模糊数模型的土壤重金属污染程度评价,更多学者选择的是线性模糊数,其中的典型代表是三角模糊数,本文运用三角模糊数进行研究区污染程度评价,并将其评价结果与正态模糊数的结果进行定量比较.三角模糊数的原理、公式可参见相关文献(李飞等,2012),截集α仍选择0.9,计算结果见表 5.
| 表5 基于三角模糊数的研究区土壤As、Cd污染程度评价结果 Table 5 Assessment for the contamination level of soil As and Cd based on triangular fuzzy number |
从表 5可以看出,与正态型模糊数相比,三角模糊数的模糊地累积指数区间发生了正向偏移,使得评价地累积指数大于正态模型.结合参照值可知,这种正向偏移使As的偏差减小到10.54%,但使Cd的偏差大幅增加到52.42%,显示出线性模糊数的评价结果具有较强的波动性.同时,从各等级污染区域占比看出,三角模糊数会使区间值范围有所缩小.与参照值的各等级污染面积占比相比,As的轻度污染区域占比减小,而清洁区域占比增大;Cd的清洁区域和中度污染区域占比进一步减小,而轻度污染区域占比增大,从而使其污染比重有所提高.因此,三角模糊数的评价结果较差.
4.4 基于核密度估计法的区域土壤重金属污染程度评价对核估计式绘图得到As、Cd含量的概率密度曲线(图 2),从曲线形状可知,As含量的概率密度确实呈现一定程度的正偏态,概率最高值出现在7.2 mg · kg-1,在其右侧的最大值达到了12 mg · kg-1左右,而左侧在5.5 mg · kg-1之下就出现几率基本为0.计算后得到研究区As地累积指数平均值为-0.62,地累积指数的方差为0.24,说明核密度估计法能对区域As总体污染程度的准确度评估方面有一定提高,并且运用核密度估计后的数据的标准差也与参照值一致,反映了评估结果较为稳定可靠.接下来再根据核密度估计曲线对As各个污染程度的面积比重进行计算.计算结果为:清洁区域污染比重为99.87%,轻度污染区域的比重是0.13%.各级污染区域比重与模糊数法相比类似,而核估计法轻度污染区域的评估比重稍低,但也能较敏感的显示占比很小的轻度污染区域.
 |
| 图2 As、Cd含量核密度估计曲线 Fig.2 Density function curve about As and Cd′s content |
Cd也存在一定程度的正偏态,含量值绝大部分分布在0.1~0.25 mg · kg-1,其中概率密度最高的值在1.8 mg · kg-1左右.相较于As,Cd元素的曲线峰度也很大,含量值在0.01 mg · kg-1之前出现频率基本为0,从0.1~0.2迅速上升至最高点,再从0.2~0.26骤降至很低的概率密度值,这和As元素的阶梯式下降有所不同.0.3~0.5 mg · kg-1高含量值区间有严重拖尾现象,该区间概率密度值均很低,这有可能是部分区域的人为污染造成.对Cd的总体污染水平进行计算,得到研究区Cd地累积指数平均值为0.30,地累积指数的方差为0.36.最后对各个污染级别的面积占比进行统计,清洁区域占比18.40%,轻度污染区域占比为70.96%,中度污染区域占比10.64%.与参照值相比,轻度与中度污染区域面积有5%左右的偏差,这可以解释为核估计模型对稀少值的一种敏感性,即Cd曲线中区间$0.3~0.5]的点位稀少,通过评估,每个点位的出现都会使其附近值的出现几率增加,反映在概率密度曲线上,就是连续不间断的拖尾现象.
4.5 不同评价方法下区域土壤重金属污染程度的综合比较本文采用不同方法对研究区As、Cd两种土壤重金属元素的污染程度进行了污染评价.以地累积指数为污染指数,分别采用了简单数理统计、模糊数法以及核密度估计方法进行了评价.3种方法从评价便捷性上是由易到难的,但运用更为复杂的模型会提高评价结果的准确度或全面性.相关评价结果见图 3.
 |
| 图3 As、Cd不同评价方法结果的综合比较 Fig.3 Integrated comparison of As and Cd with different assessment methods |
从简单数理统计上来说,评估的结果较为良好,准确度和参照值相差不大,但是对各污染等级面积占比的测度不够准确,会遗漏研究区域分布极少的污染等级面积占比,这种情况在对As元素各污染级别的面积比重测算中有所体现,即遗漏了面积占比极少量的轻度污染区域.而运用模糊数与核估计模型进行评估就能在一定程度上避免了这个问题.
模糊数模型与简单数理统计的结果一致,原因在于模型的两个重要参数——均值与标准差就是基于样本数据,故不能提高对总体污染程度评估的准确度.但运用正态模糊数法仍然有两个优点:①通过隶属度曲线能对各污染等级面积占比有比较准确的测度,能较为敏感地统计出研究区域分布极少的污染等级面积占比;②也能在一定置信水平下用一个区间数来表征区域土壤重金属总体污染程度,能更为全面地反映区域土壤重金属污染程度,评价结果所涵盖的信息更加全面.
核密度估计则突破了模糊数对分布条件的限制,对任何分布形式的数据均能统计出所有可能值的概率密度,并通过一定的公式转化求得该重金属的区域总体污染程度以及各污染级别面积占比.从图 3的结果可知,评价结果的准确度能在前两种方法基础上有一定提高,且从标准差上可以看出,很好的保持了样本数据的稳定性,因此,核估计的评价结果能更准确地反映研究区土壤重金属污染实际,但它有两个缺点:一是计算量比较大,手动计算起来很繁琐,通常需要通过程序来支持运算,可考虑借助软件编程来实现;二是窗宽值的大小对核估计的效果起着决定性作用,但是窗宽的合理估计值往往是较难确定的.核密度估计方法的模型架构较为灵活多变,同时由于估计式可以依赖代码程序实现,允许它的估计过程更为复杂,故有着很大的改造空间.比如王金然等(2005)运用迭代算法对核函数模型进行优化,通过对核密度函数进行迭代,进一步提高区域土壤重金属污染程度评价的准确度,鉴于其运算量在核密度估计的基础上又有了数量级的增加,在较多指标与样本数的情况下评价效率会比较低,如何在保证准确度的同时,提高核估计迭代式的评价效率是值得进一步研究的问题.
5 结论(Conclusions)区域土壤重金属污染不同评价方法的结果有所不同,各方法在评价便捷性、结果的准确度和包含信息的全面性方面也有所差异:
1)简单数理统计评价便捷性最高,但结果准确度较低,对各污染等级面积占比的测度不够准确,会遗漏研究区内分布极少的污染等级面积占比,并且只能得出唯一值,结果所包含信息较少.
2)应用正态模糊数法评价能通过隶属度曲线能对各污染等级面积占比有比较准确的测度,此外也能在一定置信水平下用一个区间数来表征区域土壤重金属总体污染程度,评价结果所涵盖的信息更加全面,结果所包含信息最多,但基于正态模糊数法与简单数理统计的总体污染程度评价结果偏差一致,结果准确度较低,并且正态模糊数法采用较为复杂的数学模型,评价便捷性远低于简单数理统计.与正态模糊数法相比,三角模糊数法评价结果具有较强的波动性,评价结果较差.
3)核密度估计结果准确度最高,该方法下研究区As和Cd总体污染评价的平均地累积指数相对于参照值的偏差仅分别为10.7%和15.4%,但是核密度估计模型计算最为复杂,需要通过程序来支持运算,评价便捷性最差,并且只能得出唯一值,结果所包含信息较少.同时对核密度估计效果起着决定性作用的窗宽合理估计值往往是较难确定的,但由于其灵活多变模型架构和计算可以依赖代码程序实现的特点,核密度方法有着很大的改造空间.
| [1] | 陈璐, 傅志柯, 韩冰. 2012. 基于核密度法的城乡居民收入分布状况分析-以四川省为例[J]. 经营管理者, 06: 13-16 |
| [2] | 樊梦佳, 袁兴中, 祝慧娜, 等. 2010. 基于三角模糊数的河流沉积物中重金属污染评价模型[J]. 环境科学学报, 30(8): 1700-1706 |
| [3] | 范拴喜, 甘卓亭, 李美娟. 2010. 土壤重金属污染评价方法进展[J]. 中国农学通报, 26(17): 310-315 |
| [4] | 国家环境保护局, 中国环境监测总站. 1990. 中国土壤元素背景值[M]. 北京市:中国环境科学出版社 |
| [5] | 郭笑笑, 刘丛强, 朱兆洲, 等. 2011. 土壤重金属污染评价方法[J]. 生态学杂志, 30(5): 889-896 |
| [6] | 郭照庄, 霍东升, 孙月芳. 2008. 密度核估计中窗宽选择的一种新方法[J]. 佳木斯大学学报: 自然科学版, 26(3): 401-403 |
| [7] | 胡春华, 蒋建华, 周文斌. 2012. 环鄱阳湖区农家菜地土壤重金属风险评价及来源分析[J]. 地理科学, 32(6): 771-776 |
| [8] | Krishna A K, Mohan K R, Murthy N N, et al. 2013. Assessment of heavy metal contamination in soils around chromite mining areas, Nuggihalli, Karnataka, India[J]. Environmental earth sciences, 70(2): 699-708 |
| [9] | 李飞, 黄瑾辉, 曾光明, 等. 2012. 基于三角模糊数和重金属化学形态的土壤重金属污染综合评价模型[J]. 环境科学学报, 32(2): 432-439 |
| [10] | 李如忠, 童芳, 周爱佳, 等. 2011. 基于梯形模糊数的地表灰尘重金属污染健康风险评价模型[J]. 环境科学学报, 31(08):1790-1798 |
| [11] | 马成玲, 周健民, 王火焰, 等. 2006. 农田土壤重金属污染评价方法研究-以长江三角洲典型县级市常熟市为例[J]. 生态与农村环境学报, 22(1): 48-53 |
| [12] | Onkal-Engin G, Demir I, Hiz H. 2004. Assessment of urban air quality in Istanbul using fuzzy synthetic evaluation[J]. Atmospheric Environment, 38(23): 3809-3815 |
| [13] | Okedeyi O O, Dube S, Awofolu O R, et al. 2014. Assessing the enrichment of heavy metals in surface soil and plant (Digitaria eriantha) around coal-fired power plants in South Africa[J]. Environmental Science and Pollution Research, 21(6): 4686-4696 |
| [14] | Pan N F. 2008. Fuzzy AHP approach for selecting the suitable bridge construction method[J]. Automation in construction, 17(8): 958-965. |
| [15] | 任文军, 宋向东. 2009. 核密度估计中递归方法选择窗宽及其应用[J]. 长春大学学报, 19(2): 23-26 |
| [16] | 万红友, 周生路, 赵其国. 2006. 苏南典型区土壤基本性质的时空变化-以昆山市为例[J]. 地理研究, 25(2): 303-310 |
| [17] | 王金然. 2005. 密度核估计中核函数的迭代算法及对最优窗宽的研究[D]. 北京: 燕山大学 |
| [18] | 王庆仁, 刘秀梅, 崔岩山, 等. 2002. 我国几个工矿与污灌区土壤重金属污染状况及原因探讨[J]. 环境科学学报, 22(3): 354-358 |
| [19] | 吴喜之, 王兆军. 1996. 非参数统计方法[M]. 北京: 高等教育出版社 |
| [20] | 吴喜之, 赵博娟. 2009. 非参数统计(第4版)[M]. 北京:中国统计出版社 |
| [21] | 杨国昌, 杨明华, 张玲, 等. 2011. 核密度估计在大口径机枪加速寿命研究中的应用[J]. 科学技术与工程, 11(9): 1967-1970 |
| [22] | Yang S, Zheng F, Luo X, et al. 2014. Effective dysphonia detection using feature dimension reduction and kernel density estimation for patients with Parkinson's disease[J]. PloS one, 9(2): e88825 |
| [23] | 易昊旻, 周生路, 吴绍华, 等. 2013. 基于正态模糊数的区域土壤重金属污染综合评价[J]. 环境科学学报, 33(4):1127-1134 |
| [24] | 钟晓兰, 周生路, 赵其国. 2007. 长江三角洲地区土壤重金属污染特征及潜在生态风险评价-以江苏太仓市为例[J]. 地理科学, 27(3): 395-400 |
| [25] | 钟晓兰, 周生路, 李江涛, 等. 2008. 长江三角洲地区土壤重金属生物有效性的研究-以江苏昆山市为例[J]. 土壤学报, 45(02):240-248 |
| [26] | Zhou H, Zeng M, Zhou X, et al. 2013. Assessment of heavy metal contamination and bioaccumulation in soybean plants from mining and smelting areas of southern Hunan Province, China[J]. Environmental Toxicology and Chemistry, 32(12): 2719-2727 |
| [27] | 朱青, 周生路, 孙兆金, 等. 2004. 两种模糊数学模型在土壤重金属综合污染评价中的应用与比较[J]. 环境保护科学, 30(3): 53-57 |