 2014, Vol. 34
2014, Vol. 34



水体富营养化评价是湖库、海湾水环境管理的基础和依据.目前,有关水体富营养化评价的模型与方法有很多种,较常用的主要有卡尔森营养状态指数(Yang et al., 2012)、修正的营养状态指数(段洪涛等,2006)、综合营养状态指数(王鹤扬,2012; Xu et al., 2012)、营养指数法(Liu et al., 2011)和评分法等(邓大鹏等,2006; 荆红卫等,2008).尽管这些模型和方法都已得到了不同程度的应用,但其存在的缺陷和不足仍是不可否认的,特别是在环境评价系统的不确定性方面(李如忠等,2005;徐勋等,2013).湖库水环境系统是一个充满不确定性的大系统,因此常规确定性评价方法往往难以准确反映水体富营养化的真实状况.事实上,湖库水环境系统是一个随机性、模糊性、灰性、未确知性等多种不确定性共存或交叉存在的系统,单纯考虑某一种不确定性,可能导致评价结论的片面性.为此,一些学者将未确知数学中的盲数理论(刘开第等,1999)引入水环境系统的模拟和表征(李如忠等,2005; 王宪恩等,2005; 祝慧娜等,2009),从而在一定程度上解决了上述问题.但传统盲数对模糊信息的处理似乎还较为无能为力(杨志民,2000),也还缺乏对盲数中灰区间内数据分布情况的关注.为此,李如忠等(2009a)提出了采用三角模糊数替代传统盲数中的灰区间数,构建延拓盲数,从而将盲数向模糊环境下拓展,取得了较好效果,并将其成功地应用于水环境容量计算和非点源氮磷流失量估算(李如忠等,2009a;Li,2008).但在湖库水体富营养化评价方面,如何从水环境系统多种不确定性共存或交叉存在的角度进行定量化评估,仍还缺乏必要的研究,从而影响了人们对湖库水体富营养化程度或状态的准确认识和判别.本文尝试将延拓盲数理论应用于水体富营养化评价,通过与综合营养状态指数方法和盲数可靠性原理的综合集成,构建水体富营养化评价的延拓盲数模型和营养状态等级识别模式,并以巢湖西半湖的塘西河河口为例,开展新建模型的应用研究,以期为塘西河河口乃至整个巢湖水体富营养化状况的科学评估提供技术支持.
2 延拓盲数的定义(Definition of extended blind number) 2.1 盲数的定义盲数是定义域为有理灰数集G,函数值在[0,1]上的灰函数.设 ai∈G,ωi∈[0,1],i=1,2,…,n ,则
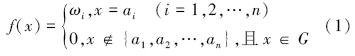
若当i≠j时, ωi≠ωj且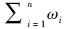 ≤1 ,则称函数f (x)是一个盲数(刘开第等,1999),f (x)的阶数为n,称 ωi 为f (x)在 ai 点的主观可信度,称 为f (x)的总可信度.
≤1 ,则称函数f (x)是一个盲数(刘开第等,1999),f (x)的阶数为n,称 ωi 为f (x)在 ai 点的主观可信度,称 为f (x)的总可信度.
一般的灰区间数虽然反映了水环境系统状态区间变化的特点,但对不同状态出现几率上的差异则还重视不够.虽然将区间细化可以在一定程度上弱化这一不足带来的影响,但这样将会带来盲数阶数的大量增加,从而导致计算量呈几何级数增大(石博强等,2003),甚至造成计算机无法正常运行.三角模糊数可以看作是一种带有隶属度的特殊的区间数.基于这一特点,李如忠等(2007)将三角模糊数替代盲数中的区间数,构建了基于三角模糊数的延拓盲数,不仅可以处理模糊不精确性,又能在一定程度上反映区间内数据出现几率上的差异.
设 Ã i 为三角模糊数,F(X)为由三角模糊数 Ã i (i=1,2, …, n)构成的模糊数集合,则 Ã i∈F(X) .设 ωi∈[0,1] ,( i=1,2,…, n), 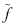 (x) 为定义在F(X)上的模糊函数,且
(x) 为定义在F(X)上的模糊函数,且
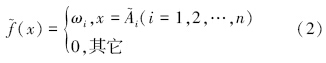
当i≠j时, à i≠à j ,且 =ω≤1 ,则函数 (x) 为盲数,将其称为延拓盲数. ωi 为 (x) 中 à i 的主观可信度,ω和n分别为 (x) 的总可信度和阶数,并将延拓盲数简记为 {[à 1,à n],(x)} .
三角模糊数可以借助α-截集技术(即fuzzy α-cut, α∈[0,1] )(Giachetti et al,1997),将其转化为与一定α值相对应的区间数.不难理解,如果将式(2)中的所有三角模糊数Ã i均通过α-截集转化为区间数,则延拓盲数转化为普通盲数.而且,当α=1时,延拓盲数退化为未确知有理数(刘开第等,1999).因此,经α-截集转化后的延拓盲数,可以作为普通盲数参与盲数的所有算术运算.有关盲数期望值计算公式和盲数算术运算性质,参见文献(刘开第等,1999).
3 基于延拓盲数的湖库富营养化评价模型(Eutrophication evaluation model based on extended blind number) 3.1 综合营养状态指数法综合营养状态指数法是水体富营养评价中较为常用的方法,它是以Chl-a为基准,根据各参数因子与基准参数之间的相关程度进行加权,利用加权后的综合营养状态指数判断水体富营养化状态(金相灿等,1990),数学表达式为:
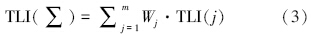
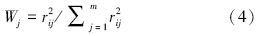
营养状态指数计算式: TLI(Chl-a)=10(2.5+ 1.086lnChl-a) 、 TLI(TP)=10(9.436+1.624lnTP) 、 TLI(TN)=10(5.453+1.694lnTN) 、 TLI(NH3)=10(7.77+1.649lnNH3) .式中,Chl-a单位为mg · m-3,其它指标单位为mg · L-1.
3.2 基于延拓盲数的水体富营养化评价模型构建水环境系统具有典型的时空不确定特征,使得各项水质指标数据呈现出一定的随机变化性(即随机性).然而由于样本数量的有限性,使得人们对于水环境质量的真实状况在主观上是不确知的(即未确知性).此外,由于采样和分析测试中误差的存在,也使得各项水质指标分析测试结果存在一定的不精确性(即模糊不精确性).而且,采样频率和水质样本的有限性,也导致水质指标状况具有部分已知部分未知的灰色特性(即灰性).对此,需要从上述多种不确定性共存或交叉存在的角度,定量刻画水体富营养化状态.
从理论上讲,可以将水质浓度参数Chl-a、TP、TN、NH3直接定义为延拓盲数.但考虑到盲数在函数运算方面还存在一定的不足,为此首先对Chl-a、TP、TN、NH3浓度值进行相应的对数运算,即lnChl-a、lnTP、lnTN、lnNH3.在此基础上,对上述函数值进一步构建相应的延拓盲数,即 {[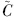 Chl-a1, Chl-am],
Chl-a1, Chl-am],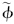 Chl-a(CChl-a)} , {[ TP1, TPl],TP(CTP)} , {[ NH31, NH3t],NH3(CNH3)} 和 {[ TN1, TNs],TN(CTN)} .然后,再将上述各参数代入相应的营养状态指数计算公式,则有:
Chl-a(CChl-a)} , {[ TP1, TPl],TP(CTP)} , {[ NH31, NH3t],NH3(CNH3)} 和 {[ TN1, TNs],TN(CTN)} .然后,再将上述各参数代入相应的营养状态指数计算公式,则有:
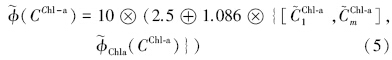
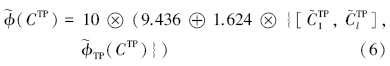
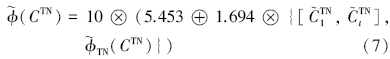
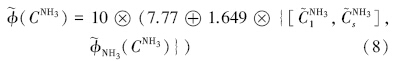
而 (CChl-a) , (CTP) , (CTN) 和 (CNH3) 分别表示各参数的营养状态指数分布密度函数.由此,得到综合营养状态指数 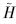 (∑) ,即
(∑) ,即
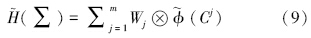
(∑) 实际上是一个延拓盲数.
3.3 基于延拓盲数的综合营养 状态指数等级识别模型
设A为延拓盲数形式的综合营养状态指数,B为营养程度等级阈值,利用盲数可靠性原理(刘开第等,1999),并参照文献(李如忠等,2007),可以定义综合营养状态指数等级识别模型.不妨将水体富营养化程度划分为5个等级,依次为贫营养、中营养、轻富营养、中富营养和重富营养,相应等级的标准阈值分别表示为B1、B2、B3、B4和B5.若令所有延拓盲数的总可信度均为ω=1,则可将评价对象隶属于各营养等级的可信度P(l)(l=1,2,…,5)分别表示为:
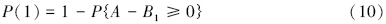
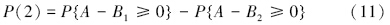
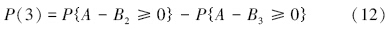
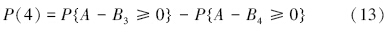
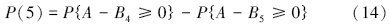
在由式(10)~(14)计算得到隶属于各营养等级的可信度后,为充分利用水质监测数据所隐含的内在信息,考虑进一步采用式(15)定量刻画水体营养程度,即
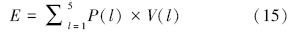
巢湖是“九五”~“十二五”期间,我国重点治理的三大湖泊之一.目前,巢湖西半湖水质常年处于Ⅳ~Ⅴ类,甚至劣Ⅴ类,夏季大部分湖面被厚厚的蓝藻覆盖,水体富营养化特征显著.塘西河位于巢湖西半湖北侧,主要接纳来自合肥市的部分生活污水和农业排水,是合肥市城市污水氮磷营养物进入巢湖的主要通道之一.同时,塘西河河口水域也是巢湖西半湖水体富营养化发生频率和严重程度最为突出的区域之一.2012年9月—2013年7月,课题组在塘西河河口水域布设了9个采样点位,通过采集水样,对包括Chl-a、TP、TN、NH3等在内的13项水质指标进行分析测试.其中,Chl-a采用冷冻浸提法(高一平等,2009)测试,TP采用过硫酸钾消解钼酸铵分光光度法测定(GB11893-89),TN采用碱性过硫酸钾消解紫外分光光度法(GB11894-89)测定,NH3则以纳氏试剂分光光度法测定(GB7479-87),相应的统计结果见表 1.采样频率每旬采样1次,共采集水样25次,因此每项指标的样本数为25×9=225个.
| 表1 水质参数统计结果 Table 1 Statistical results of water quality indexes |
为直观地展示水质分析测试数据在数值大小方面的分布情况,采用雷达图对相关数据进行描述,见图 1.图中,每个黑点分别对应于一个浓度值,圆环上的数据代表刻度值,最大刻度值对应于圆环的中心点.由图 1可以看出,绝大多数情况下水体Chl-a含量都很低,但仍有少量数据出现在10000~40000 mg · m-3数据区段内.同样,在其它3个指标中,也都出现少量数据明显偏高的现象,但在数据大小悬殊程度方面,都远逊色于Chl-a.
 |
| 图 1 各指标浓度雷达图(a. Chl-a,mg · m-3; b. NH3,mg · L-1; c. TN,mg · L-1; d. TP,mg · L-1) Fig. 1 Radar charts of index contents(a. Chl-a,mg · m-3; b. NH3,mg · L-1; c. TN,mg · L-1; d. TP,mg · L-1) |
在对各指标参数进行对数(ln)运算的基础上,对所得的计算结果按数值大小进行排序.在此基础上,根据数据波动情况,分别将各参数数据序列划分为若干个数据区段.不妨取各区段内数据子序列的最大值作为三角模糊数上限、最小值作为下限,并以平均值作为最可能值,构造各区段相应的三角模糊数.若以每个区段内数据在总数据(即225个)中所占比例作为相应区段的主观可信度,则可构造各参数对应的延拓盲数,相应的分布函数形式分别为:




对于分布函数中的三角模糊数,利用α-截集技术,将其转化为区间数.作为理论与方法上的探讨,不妨针对模糊截集α取值分别为0、0.3、0.5、0.8、1.0等几种情形,解析延拓盲数在水体富营养化评价中的应用.为简化计算,假设对延拓盲数中所有三角模糊数取相同的α-截集值.表 2展示了TN 在不同α取值时,延拓盲数中三角模糊数转化为区间数情况.同样,也可以对其它3个指标实现这一转化.显然,对于给定的模糊截集水平,延拓盲数实际上已转化为普通盲数,因此可以按一般盲数进行运算处理(李如忠等,2009a).
| 表2 不同模糊截集水平下TN中三角模糊数对应的区间数 Table 2 Interval values corresponding to different fuzzy-cuts for extended blind number of TN index |
针对采样得到的水质监测数据信息,采用SPSS17.0软件,以Chl-a为基准(即r=1),分别对Chl-a-TN、Chl-a-TP、Chla-NH3做相关性分析,得到塘西河河口水域各参数因子与Chl-a的相关系数,结果分别为 rChl-a=1 , rTN=0.854 , rTP=0.888 , rNH3=0.890 .由式(4)计算出各参数因子的权重,即WChl-a=0.302,WTN=0.221,WTP=0.238,WNH3=0.239.
4.4 营养状态指数计算限于篇幅,这里仅就α = 0.8为例,说明延拓盲数在塘西河口水体富营养化评价中的应用.将已转化为一般盲数的各参数值分别代入式(5)~(8),得到各参数相应的营养状态指数(略).在此基础上,再对各营养状态指数分别乘以参数相应的权重,得到如下结果:



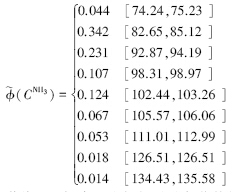
若将上述耦合了指标权重的各营养状态指数再代入式(9),从理论上讲,可以计算得到综合营养状态指数值 (∑) .这里,盲数 (CChl-a)、(CTP)、(CTN)和(CNH3) 的阶数均为9阶.根据盲数运算性质,计算结果 (∑) 将是阶数为9×9×9×9=6561的盲数.依照盲数运算规则,利用Matlab工具软件编制计算程序,求得 (∑) 值(限于篇幅,此处略去).在此基础上,由盲数期望值计算式(刘开第等,1999),进一步计算得到 (∑) 的期望值为79.34.
值得一提的是,在盲数 (∑) 所包含的6561个区间数中,几乎所有区间都存在不同程度的重叠或交叉问题,从而给 (∑) 的实际应用带来很大不便.为此,笔者按照盲数运算中有关降阶或区间合并处理的思想与技术方法(刘开第等,1999;李如忠等,2009b),对互相交叉或重叠的可能值区间进行简化处理,即将其转化为一系列不相重叠(边缘除外)的区间值,并对相应的可信度进行累加.在此基础上,考虑对整个可能值区间进行等分化,从而得到除边缘处可能重叠外,不再存在区间交叉的一系列区间数(李如忠和石勇,2009).特别地,等分化的区间数数目可以根据决策者对 (∑) 值刻画精细程度的要求设定,从而更好地提高评价结果的模拟效果.图 2是在截集水平α =0.8情形下,当等分化的区间数数目分别为n=80、160和320时,综合营养状态指数 (∑) 的可能值\可信度分布曲线和可能值\累积可信度关系曲线模拟情况.
 |
| 图 2 综合营养状态指数可能值-可信度分布与累积分布曲线 Fig. 2 Distribution density and cumulative distribution curves of comprehensive trophic state index |
不难看出,塘西河口综合营养状态指数值是一个在一定区间范围内变化的区间数,而且随着对 (∑) 值等分化区间数数目的增大,对于综合营养状态指数可能值与可信度关系曲线的刻画也越来越精细.从图 2的 (∑) 可能值\可信度分布曲线看,在70~90范围内,综合营养状态指数可能值具有相对较高的可信度,特别是在80附近,可信度水平达到最高.从可能值\累积可信度关系曲线上看,在70~90范围内,累积频率曲线对应的曲线斜率相对较大,且相应的累积可信度水平也由0.14迅速上升到0.93.由3.2节对于延拓盲数可信度的定义可知,该区段涵盖了绝大部分的样本数据信息.毫无疑问,上述针对 (∑) 可能值与可信度关系的直观、系统的展示,是确定性评价方法所无法实现的.
目前,对于水体富营养化,国内外也都还没有一套权威的、统一的评价标准.本文考虑采用中国环境监测总站推荐的湖泊营养状态5级划分标准(王翠明等,2002),即0≤TLI(∑)<30,贫营养;30≤TLI(∑)<50,中营养;50≤TLI(∑)<60,轻富营养;60≤TLI(∑)<70,中富营养;70≤TLI(∑)≤100,重富营养.显然,当以式(10)~式(14)进行营养等级评估时,相应的评价标准等级阈值B1、B2、B3、B4和B5分别对应于30、50、60、70和100.于是,根据上述计算得到的综合营养状态指数 (∑) 相应的可能值与可信度对应关系(模糊截集水平α =0.8),可以对塘西河河口水域营养状况进行定量化评估,结果见表 3.显然,该河口水域属于重富营养等级的可信度高达0.90,属于中富营养的可信度仅为0.10,而属于其它等级的可信度则为0.按最大隶属原则,可以判别该水体当为重富营养状态.
| 表3 河口水域隶属于各营养等级的可信度(α =0.8) Table 3 Credibility subordinating to nutrient levels under the fuzzy-cut of α =0.8 of estuary |
同理,可以计算得到模糊截集α = 0、0.3、0.5和1.0时,塘西河河口水域水体营养状况判别结果,见表 4.不难看出,在α = 0、0.3、0.5、0.8和1.0时,该河口水体对于重富营养等级的隶属度都是最大的,且均显著高于对其它等级的隶属度.综合营养状态指数 (∑) 在α = 0、0.3、0.5、0.8和1.0时,相应的期望值见表 4.显然,期望值均超过重富营养等级阈值(即70),对照湖泊营养状态5级划分标准,即便按期望值,也可以判定相应水体属于重富营养等级.
| 表4 综合营养状态指数隶属于各营养等级的可信度 Table 4 Credibility subordinating to different nutrient levels of TLI under various fuzzy-cuts |
根据表 4,再利用式(15)可以进一步计算得到不同α-截集水平下,塘西河河口水域水体营养程度状态E.这里,针对不同营养等级赋值V(l)和水体营养程度指数E,不妨约定:(1)贫营养等级V(l)赋值为1,中营养为2,轻富营养为3,中富营养为4,重富营养为5;(2)当1≤ E<1.5时,营养程度判为贫营养;当1.5≤ E<2.5时,判为中营养;当2.5≤ E<3.5时,判为轻富营养;当3.5≤ E<4.5时,判为中富营养;当4.5≤ E≤ 5时,判为重富营养.
根据上述约定,可以计算得到α = 0、0.3、0.5、0.8和1.0时,塘西河河口水体营养程度指数及其等级判别结果,见表 5.显然,在α = 0、0.3、0.5、0.8和1.0时,该河口水体都最终判为重富营养等级.概括地,无论是从最大隶属度、期望值,还是从水体营养程度指数层面,都将塘西河口水体判别为重富营养水平.
| 表5 塘西河河口水体富营养化状态 Table 5 Eutrophication status levels for Tangxihe River mouth under different fuzzy-cuts |
若以常规的确定性评价方法判别塘西河河口区水体营养状况,只需将Chl-a、TN、TP和NH3浓度平均值代入各参数因子的营养状态指数计算公式,即可得到水体综合营养状态指数值,即TLI(∑)=93.50.尽管据此也可以将塘西河河口区水体富营养状态判定为重富营养,但与延拓盲数评价结果相比,确定性评价方法所能提供的信息也仅限于此,对于该河口在不同水文条件下出现的富营养化状态差异缺乏一定的量化和表征.而且,从计算结果看,确定性方法得到的水体综合营养状态指数值(93.50)明显高于延拓盲数方法所得的期望值.究其原因,这与简单的平均化方法,容易扩大极端值对整体水平的影响,从而掩盖数据真实的分布特征有关.由图 1可以看出,Chl-a出现了几次极高浓度,简单的算术平均无疑显著抬高了Chl-a平均浓度水平.
本文通过将延拓盲数与富营养化评价模型的综合集成,构造了基于延拓盲数的富营养化评价方法,从而将水质监测数据的离散性与水质时空分布的连续性较好的结合起来(石勇等,2009),充分挖掘了已有数据信息,进而更加真实、客观地反映水体富营养化状况.与确定性评价模型相比,该方法不仅能在一定程度上反映参数时空变化出现几率的差异,而且可以通过综合营养状态指数的等级识别模型得到各区间相应的主观可信度水平,计算相应的评价等级的可信度.特别是,将综合营养状态指数 (∑) 采用可能值\可信度分布曲线、可能值\累积可信度关系曲线进行定量化模拟刻画,可以非常直观地展示水质营养状态,从而提高了决策管理的科学性和可操作性,这是常规确定性方法所无法比拟的.模型定量化计算是延拓盲数评价模型使用的关键,从模型推广应用的角度看,还需要对编制的计算程序作进一步的优化升级,以提高评价模型的通用性和操作的便捷性.本文虽然选择河口水域为具体实例对象,但延拓盲数模型对于湖库、海湾等水体富营养化评价的适用性是显然的.随着这类水体水质监测数据信息的日益丰富,以及人们对湖库水体富营养化等级识别精细程度要求的不断提高,延拓盲数评价模型将有着广泛的应用前景.
与现有的传统盲数相比,延拓盲数借用三角模糊数进一步刻画灰区间内数据的分布特征,因此,从理论上讲,这较传统盲数显得更为科学、合理.利用α-截集技术将三角模糊数转化为与某一特定模糊截集水平相应的区间值,进而将延拓盲数转化为一般盲数,并通过对不同模糊截集水平下水体富营养化状况的评价,既可以避免因区间划分过多给盲数计算带来的困难,也有效地提高了评价结果的科学性和灵活性.本文在对 (∑) 可能值\可信度分布曲线和可能值\累积可信度关系曲线进行定量化模拟时(α=0.8),将 (∑) 分别按阶数n=80、160和320等3种情形进行等分化处理.从模拟效果看,阶数越大,模拟曲线越光滑.在实际应用中,可以根据具体情况,选取合适的阶数模拟和表征水体富营养化状态.
1)基于湖库水环境系统随机性、模糊性、灰性、未确知性等多种不确定性共存或交叉存在的特点,将延拓盲数引入水体富营养化评价,并通过与综合营养状态指数方法的耦合,构建湖库水体富营养化评价延拓盲数模型和等级识别判别模式,不仅可以判别水体富营养状态等级,也可以得到相应的主观可信度,既有效弥补了传统确定性方法对于湖库水环境系统不确定性考虑不足的缺陷,也提高了评价结果的直观展示效果,从而提高了评价结论的科学性和合理性.
2)采用三角模糊数描述灰区间内数据的分布特征,较好地反映了数据区段内监测数据出现几率上的差异,避免了以传统盲数来精细刻画数据分布情况时,因盲数阶数过高而影响计算速度等缺陷,提高了模型的实用性.但在三角模糊数的构造过程中,如何确定三角模糊数上、下限,特别是最可能值的选取,仍还需要进一步研究.
3)根据延拓盲数模型和等级识别判别模式评价结果,巢湖北岸塘西河河口区水体当属严重富营养化等级,相应的主观可信度高达0.86(即86%)以上,需要引起相关部门的高度重视.
| [1] | 邓大鹏, 刘刚, 李学德, 等. 2006. 湖泊富营养化综合评价的坡度加权评分法[J]. 环境科学学报, 26(8): 1386-1392 |
| [2] | 段洪涛, 于磊, 张柏, 等. 2006. 查干湖富营养化状况高光谱遥感评价研究[J]. 环境科学学报, 26(7): 1219-1226 |
| [3] | 高一平, 陈肖建. 2009. 地表水中叶绿色a的测定[J]. 福建分析测试, 18(3): 17-19 |
| [4] | Giachetti R E, Young R E. 1997. Analysis of the error in the standard approximation used for multiplication of triangular and trapezoidal fuzzy numbers and the development of a new approximation [J]. Fuzzy Sets and Systems, 91(1): 1-13 |
| [5] | 金相灿, 刘鸿亮, 屠瑛清, 等. 1990. 中国湖泊富营养化[M]. 北京: 中国环境科学出版社 |
| [6] | 荆红卫, 华 蕾, 孙成华, 等. 2008. 北京城市湖泊富营养化评价与分析[J]. 湖泊科学, 20(3): 357-363 |
| [7] | Kwiesielewicz M. 1998. A note on the fuzzy extension of Saaty's priority theory[J]. Fuzzy Sets and Systems, 95(2): 161-172 |
| [8] | 李如忠, 洪天求. 2005. 盲数理论在湖泊水环境容量计算中的应用[J]. 水利学报, 36(7): 765-771 |
| [9] | 李如忠. 2007. 基于不确定信息的城市水源水环境健康风险评价[J]. 水利学报, 38(8): 895-900 |
| [10] | 李如忠, 洪天求, 贾志海, 等. 2007. 基于盲数的水体沉积物潜在生态风险评价方法[J]. 生态环境, 16(5): 1346-1352 |
| [11] | Li R Z. 2008. Estimation of non-point source pollution loads under uncertain information[J]. Chinese Geographical Science, 18(4): 348-355 |
| [12] | 李如忠, 范传勇. 2009a. 基于盲数理论的河流水环境容量计算[J]. 哈尔滨工业大学学报, 41(10): 233-235 |
| [13] | 李如忠, 石勇. 2009b. 巢湖塘西河河口湿地重金属污染风险不确定性评价[J]. 环境科学研究, 22(10): 1156-1163 |
| [14] | 刘开第, 吴和琴, 庞彦军, 等. 1999. 不确定性信息数学处理与应用[M]. 北京: 科学出版社. 5-90 |
| [15] | Liu S G, Lou S, Kuang C P, et al. 2011. Water quality assessment by pollution-index method in the coastal waters of Hebei Province in western Bohai Sea, China [J]. Marine Pollution Bulletin, 62(10): 2220-2229 |
| [16] | 毛劲乔, 陈永灿, 刘昭伟, 等. 2006. 基于地理分区的湖泊水库富营养化判别标准[J]. 人民黄河, 28(10): 43-45 |
| [17] | Mehran H. 2004. Bridging the gap between probabilistic and fuzzy-parameter EOQ[J]. International Journal of Production Economics, 91(3): 215-221 |
| [18] | 石勇, 李如忠, 熊鸿斌, 等. 2009. 基于未确知数的湖泊富营养化评价模式[J]. 合肥工业大学学报(自然科学版), 32(2): 150-154 |
| [19] | 石博强, 肖成勇. 2003. 基于盲数的螺旋弹簧可靠性计算[J]. 农业机械学报, 34(4): 98-99, 104 |
| [20] | 王翠明, 刘雪芹, 张建辉. 2002. 湖泊富营养化评价方法及分级标准[J]. 中国环境监测, 18(5): 47-49 |
| [21] | 王鹤扬. 2012. 综合营养状态指数法在陶然亭湖富营养化评价中的应用[J]. 环境科学与管理, 37(9): 188-194 |
| [22] | 王宪恩, 张海亮, 李杰, 等. 2005. 不确定性条件下的湖泊总磷允许输入量分析[J]. 吉林大学学报(理学版), 43(3): 384-387 |
| [23] | 徐勋, 梁婕, 曾光明, 等. 2013. 基于三角模糊数的贝叶斯水质评价模型[J]. 环境科学学报, 33(3): 904-909 |
| [24] | Xu M J, Yu L, Zhao Y W, et al. 2012. The simulation of shallow reservoir eutrophication based on MIKE21: a case study of douhe reservoir in north China[J]. Procedia Environmental Sciences, 13: 1975-1988 |
| [25] | Yang J, Yu X Q, Liu L M, et al. 2012. Algae community and trophic state of subtropical reservoirs in southeast Fujian, China[J]. Environmental Science and Pollution Research, 19(5): 1432-1442 |
| [26] | 杨志民. 2000. 专著<不确定性信息数学处理及应用>的评介[J]. 科学通报, 45(16): 1790-1791 |
| [27] | 曾庆飞, 谷孝鸿, 毛志刚, 等. 2012. 固城湖及上下游河道富营养化和浮游藻类现状[J]. 中国环境科学, 32(8): 1487-1494 |
| [28] | 祝慧娜, 黄兴中, 曾光明, 等. 2009. 基于区间数的河流水环境健康风险模糊综合评价模型[J]. 环境科学学报, 29(7): 1527-1533 |