 2016, Vol. 31
2016, Vol. 31



2. 中国地质大学(北京)地球物理与信息技术学院, 北京 100083
2. School of Geophysics and Information Technology, China University of Geosciences (Beijing), Beijing 100083, China
油气田沉积相的主要研究目的是提高油气田采收率,传统的沉积相分析主要根据沉积和曲线特征,逐井逐段识别和划分,分析过程中研究人员的工作经验占很重要的部分,这种沉积相分析方法速度慢、效率低,无法适应油气田开发的发展速度.
随着计算机的发展,相继出现模式识别方法和地质统计学方法用于沉积相分析(王仁铎和胡光道,1988;Kosko,1996;边肇祺和张学工,2000).地质统计学方法首先由G.马特隆教授提出,其核心是克里金算法,后来由其学生Journel提出随机模拟,进一步完善地质统计学方法.地质统计学方法使用井点数据进行插值,然后根据插值后的结果结合地质人员的认识勾绘出沉积相图,在插值过程中考虑到数据的空间结构特征,但是忽略了横向上分辨率较高的地震资料,预测结果存在很大不确定性(王仁铎和胡光道,1988;王香文,2012;Vernengo et al.,2014).模式识别方法于20世纪20年代诞生,后来相继出现最近邻法、神经网络等模式识别方法,在沉积相预测过程中,该方法综合井点和地震资料建立识别模式,但是它忽略数据的空间变异性特征,预测精度不高(边肇祺和张学工,2000;沈楠等,2008;Harilal,2012).
对于一个具体的油气藏而言,地层中的流体性质、岩石性质的空间变化会引起地震反射波形、振幅、频率、能量、相位等一系列地震属性的变化,这些变化是利用地震属性预测沉积相的主要依据(王利田等,2006;王开燕等,2013).不同的地质体引起的地球物理特征不同,融入地震属性信息识别地质体可以大大提高识别的准确性,减少多解性(宋成辉等,2004;Harilal,2012;Payne et al.,2013;Agudelo et al.,2013;Rahim et al.,2015).同时鉴于某些区块的开发现状,仅利用单井信息研究沉积相的平面展布规律,预测的精度较低,必须以地震属性来辅助进行(段林娣等,2011; Anderson and Gullco,2014;Reverón and Roomer,2014).
模式识别方法和地质统计学方法用于沉积相预测的技术已经很成熟,但是如何将两者进行结合,目前尚未提出这种思想.本次研究过程中,我们综合考虑上述两种问题,将两者结合起来,以地震属性分析技术和模式识别为基础,融入序贯随机的思想,定量地用于沉积相预测(李占东等,2015).
1 序贯随机模式识别算法设计 1.1 变差函数变差函数(王仁铎和胡光道,1988;Haldorsen and Damsleth,1990;Deutsch and Journel,1992)以区域化变量为基础,描述区域化变量的空间变异性特征,反映空间变异性程度随样本点距离变化的特征.它既描述区域化变量的随机性特征,又能描述其结构性变化.其数学表达式为
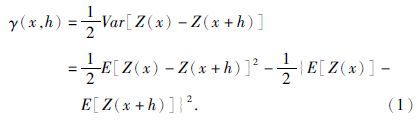
变差函数是一个描述空间数据距离的函数,它描述不同位置变量之间的相似性.变差函数的空间变异性特征包括区域化变量在空间上的连续性、空间各向异性的程度以及影响区域的大小.
1.2 基本信息描述模型构建过程中,主要使用三种数据,分别为井点信息、地震属性数据和已模拟点数据,假设:
(1) 井点数据:Wi[vi1,vi2,…,vip,Fj],其中i为井点的下标,总个数为N,p为地震属性的个数,Fj为井点处的沉积相类型,j为沉积相类型的下标,总个数为M.
(2) 地震属性数据:Si[vi1,vi2,…,vip],其中i为地震数据的下标,总个数为L,p为地震属性的个数.
(3) 已模拟点数据:ASi[vi1,vi2,…,vip,Fj],其中i为已模拟网格结点的下标值,总个数为L,每次搜索完,计数变量n加1,最终n=L,p为地震属性个数,Fj为模拟网格结点处的相类型.
(4) 研究区域共有M个沉积相类型,Fj为沉积相类型.
1.3 基本原理 1.3.1 序贯随机思想首先将所研究的区域进行网格化,生成nx×ny个网格.为了表征模拟结果的不确定特征,本文通过随机数产生一个随机路径(Haldorsen and Damsleth,1990),随机地遍历每一个网格结点.在模拟网格结点时不仅考虑周围的井点数据,还要考虑到已模拟点的网格结点数据(地震数据).
序贯原理(张春雷等,2001)简单的可理解为(图 1):假设在预测结点A时,我们搜索周围的三个B数据,用搜索到B数据预测A点的值,然后在预测结点C时,这时不仅考虑考虑到周围搜索到的B数据,还要考虑到上一步模拟出的A结点的值,用这四个值去模拟结点C的值,以此类推.

|
图 1 序贯随机思想模拟图 Fig. 1 Simulation diagram of sequential random thoughts |
模式构建过程中,随着搜索数据量的增加,计算时间也会增加,同时距离较远的点对模拟点的影响也越来越小,所以算法实现过程中主要考虑邻域内有限数据.考虑到地质数据自身具有空间变异性特征,所以模型构建过程中引入变差函数表征该特征.首先通过包含空间位置信息的井数据建立模糊规则.假设搜索到的数据包括井点数据和已模拟点数据,个数分别为NW和NS.总个数为N,即N=NW+NS.建立的规则采用椭球形规则,即每条规则都有p个地震属性的均值和方差,第j条规则为
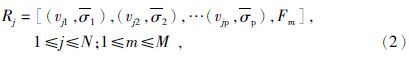
其中,vjk表示每个井点数据自身的地震属性值,σp为搜索到的井点数据和地震数据的每种地震属性的标准方差(Lipschutz and Schiller,2011),Fm为沉积相的类型.表达式为
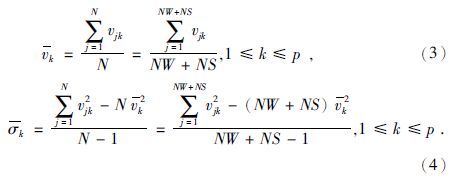
为了在模型识别过程中融入数据的空间变异性特征,在隶属度函数计算中加入变差函数的权重为
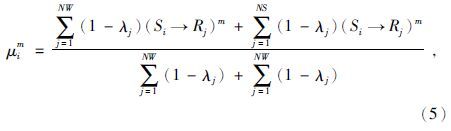
(1) μim为第i个网格结点隶属于第m种相的隶属度,1≤i≤L,1≤m≤M;
(2) NW为搜索到的井点数据个数,NS为已模拟点数据个数,即第i个网格结点周围的模糊规则个数;
(3) →表示样本地震数据Si隶属于模糊规则Rj(搜索到的井点数据和已模拟点数据)的隶属度,隶属度计算主要使用高斯隶属度函数(Kosko,1996;沈楠等,2008),表达式为
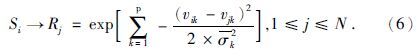
(4) λj为样本Si与Rj的变差函数值.对于搜索到的不同数据使用不同的变差函数,搜索到的井点数据使用井点变差函数,搜索到的已模拟点使用地震变差函数.
1.3.3 样本判别过程以第Si(vi1,vi2,…,vip)个网格结点为例说明识别的过程.
(1) 在地震网格结点Si周围分别搜索到NW个井点数据和NS个已模拟点数据,求取每个网格结点隶属于每种相的隶属度μim后,接着求取第i个网格结点隶属于每种相的权重Pij,其计算公式为
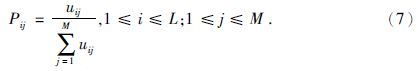
(2) 根据求得的网格结点隶属于每种相的概率,然后求取累积概率值,建立累积概率分布函数,假设第i个网格结点对应的累计概率分布函数值分别为:P1,P2,…,Pj-1,Pj,Pj+1,…,PM-1,1,根据离散型变量随机抽样理论,将分为μ个区间:[0,P1],(P1,P2],…,(Pj-1,Pj],(Pj,Pj+1],…,(PM-1,1].
(3) 从区间(0,1)均匀分布中抽取一随机点,从累计概率分布中判断该随机数属于哪个区间,比如在(Pj-1,Pj],则该网格结点的相值即为j,也即Si∈Fj.
2 实际应用及效果分析 2.1 研究概况研究工区源自苏里格气田西北部的苏10区块,研究目的层位为盒8下段.2006年区内完成17条二维地震测线,主测线9条,联络测线8条,测线总长239公里.二维地震测线的目的层在1.8~2.0 s附近,主频率在35 Hz左右,分辨率较高,剖面极性为负极性,近于零相位.区内有钻井236口,其中测线上的钻井174口,测线交点共72个(图 2).

|
图 2 研究区沉积相图(红色为地震测线,黑色为井点) Fig. 2 Sedimentary facies in study area(red refers to seismic lines,black refers to well point) |
根据苏10区块的岩心资料以及钻井资料,结合前人研究,认为苏10区块整体属于河流-三角洲相沉积,盒8段为辫状河三角洲平原沉积,山1段属于曲流河三角洲平原沉积(徐蒙等,2013).物源方向为北向南方向,本次研究层段为盒8下段,主要发育主分流河道、河道及分流间湾三种微相(图 2).辫状河三角洲河道连片性发育,主河道成交叉条带状,摆动频繁.
2.2 地震属性提取地震属性是那些由叠前或叠后地震数据经过数学变换而导出的有关几何的、运动学的、动力学或统计特征的物理量.地震属性分析就是将地球物理的含义与地质含义关联的过程,其目的就是把地震属性转换为物性、岩性、构造或油藏参数相关的信息,从地震资料中提取隐藏其中的多种有用信息,为油气勘探与开发提供丰富的宝贵资料(何碧竹等,2003;杜世通,2004;陈建阳等,2011).
目前地震属性的分类方法很多,国内外仍然没有一个公认的地震属性分类,也很难建立一个完整的地震属性列表.本文主要参考Landmark软件的地震属性分类方法,将其分为五大类:振幅统计类、复数道统计类、频谱统计类、序列统计类及相关统计类(王利田等,2006).
研究过程中,完成目的层段地震属性的提取,主要提取均方根振幅、反射强度、波阻抗、平均瞬时频率、有效带宽和吸收衰减等地震属性.通过对这些数据进行插值,获的地震属性平面图,后面的研究工作主要根据网格化的地震属性(图 3,以均方根振幅为例)(李丙喜,2014;吴海波等,2015).

|
图 3 地震属性:均方根振幅 Fig. 3 Seismic attribute: RMS amplitude |
地震波的传播与沉积相有关,不同的沉积相体现在砂体厚度和砂地比的不同,不同的砂体厚度及砂地比会引起地震波在波形、振幅强度、反射强度、相位等方面上的变化,这些变化最终反映到地震剖面在反射特征上的变化(陈建阳等,2011).首先提取井点位置处的地震属性值,通过地震属性与砂地比的交会图,分析井点处地震属性与砂地比的关系.图 4显示砂地比与地震属性的关系比较一致,与均方根振幅、反射强度和波阻抗成线性正相关关系,与平均瞬时频率、有效带宽和吸收衰减成线性负相关关系.

|
图 4 砂地比和地震属性交会图 Fig. 4 Cross plot of SDB and seismic attributes |
通过分析砂地比与提取的地震属性的关系,表明沉积相与地震属性之间也存在着一定的关系,不同的沉积相有着不同的地震属性分布特征.通过图 5分析多属性与沉积相的关系显示,主体河道具有均方根振幅高、反射强度高、平均瞬时频率低、有效带宽低的特征,河道和分流间湾交叉的部分较多,但是从有效带宽、反射强度上也是可以区分开的.所以基于地震属性的沉积相预测方案是可行的.

|
图 5 地震属性和沉积相关系图 Fig. 5 Diagram of seismic attributes and sedimentary facies |
根据算法理论阐述部分,序贯随机模式识别方法首先对定义的网格区域产生315×205个随机数,然后遍历每一个网格.针对某一个特定的网格u,搜索该点周围的井点数据和已模拟点数据.根据公式求出搜索到的每个数据和要模拟的网格结点的变差函数值,将该值作为权值参与到下步计算中.
图 6a、6b是通过随机数产生的两个不同路径,得到的两个不同的模拟结果.为了进行对比分析,采用模式识别中的最近邻法和地质统计学中的序贯指示模拟算法,对应的结果见图 6c、6d所示.

|
图 6 不同方法预测结果 Fig. 6 Prediction results of different methods |
为了对比三种方法预测沉积相的结果,本文采用交叉检验的方式检验预测的精度(如表 1).交叉检验是从条件数据中抽掉一部分数据,用剩余数据建立识别模型,然后用识别的模型识别抽掉的数据.针对本次方法,条件数据采用井点数据,对于任意一口井,用其他井点数据预测该井的沉积相类型,使用该方法用于表征算法预测沉积相的精度.
|
|
表 1 交叉检验统计表 Table 1 Table of Cross Validation |
(1) 传统方法:最近邻法预测的准确率为62%,通过选择井点数据中地震属性相近的井点沉积相类型作为识别的结果,该方法以地震属性为基础,地震属性变化对该方法影响较大,且无法表征空间数据的空间结构特征,对河道的模拟效果较差,不能再现河道整体形态.序贯指示模拟方法预测的准确率为78%,该方法以井点数据为基础,忽略横向上分辨率较高的地震数据,对于井点较少的区域预测的精度很低.
(2) 序贯随机模式识别方法与上述两种方法相比,综合井点数据和地震数据,同时又将数据的空间结构特征融入到模式建立过程中,其预测的准确率为86%,同时对各个沉积相类型的识别准确率较为平衡,基本上都在80%以上.预测结果与手工沉积相对比,很好的展示河道的整体形态,大大提高预测的结果.
3 结 论通过本文的研究可以得出以下结论和认识:
(1) 研究过程中,分析提取的地震属性与沉积相的关系,优选出与沉积相较为敏感的地震属性,主要有均方根振幅、反射强度、波阻抗、瞬时频率、有效带宽和吸收频率.其中均方根振幅、反射强度、波阻抗与砂岩厚度存在较高的正相关关系,平均瞬时频率、有效带宽和吸收频率与砂岩厚度存在较高的负相关关系.
(2) 本次研究引入变差函数,用来表征空间数据的变异性特征.在识别过程中,不仅考虑数据的空间距离影响,同时融入井点信息和地震属性的空间变化特征,能够提高沉积相预测的精度.
(3) 序贯随机模式识别方法综合多变量因素(井点数据和地震数据)和空间结构特征,用于沉积相的预测,相比最近邻法和序贯指示模拟,预测精度较高,它能够为沉积相分布研究提供一种重要的技术手段.
总之,地震信息和空间结构特征的综合考虑为储层预测提供一种新的思路和方法.
致 谢 感谢审稿专家提出的修改意见和编辑部的大力支持!
| [1] | Agudelo W, Pineda E, Gómez R, et al. 2013. Using converted-wave seismic data for lithology discrimination in a complex fluvial setting: Tenerife oil field, Middle Magdalena Valley, Colombia[J]. The Leading Edge, 32(1): 72-78. |
| [2] | Anderson M, Gullco R. 2014. On discriminating sand from shale using prestack inversion without wells: A proof of concept using well data as a surrogate for seismic amplitudes[J]. The Leading Edge, 33(3): 256-258, 260-264. |
| [3] | BIAN Zhao-Qi,ZHANG Xue-Gong.2000. Pattern Recognition(Second Edition)[M].TSINGHUA UNIVERSITY PRESS. |
| [4] | CHEN Jian-Yang, TIAN Chang-Bing, ZHOU Xin-MAO, et al. 2011. Sedimentary microfacies studies and reservoir modeling by integration of multiple seismic attributes[J]. Oil Geophysical Prospecting (in Chinese), 46(1): 98-102. |
| [5] | Deutsch C V, Journel A G. 1992. GSLIB: Geostatistical Software Library and User's Guide[M]. New York, Oxford: Oxford University Press. |
| [6] | DU Shi-Tong. 2004. Seismic attribute analysis[J]. Petroleum Geophysics (in Chinese), 2(4): 19-30. |
| [7] | DUAN Lin-Di, ZHAO Zhan-Liang, HUI Yi. 2011. 2D seismic facies analysis constrained by multi-source information[J]. Journal of Oil and Gas Technology (J. JPI) (in Chinese), 33(4): 66-71. |
| [8] | Haldorsen H H, Damsleth E. 1990. Stochastic modeling[J]. Journal of Petroleum Technology, 42(4): 404-412. |
| [9] | Harilal. 2012. Integration of well logs for seismic-guided sand mapping in the Barail coal-shale sequence of Geleki Field[J]. The Leading Edge, 31(1): 18-22. |
| [10] | HE Bi-Zhu, ZHOU Jie, WANG Gong-Huai. 2003. Using multivariate seismic reservoir information[J]. Oil Geophysical Prospecting (in Chinese), 38(3): 358-262. |
| [11] | Kosko B. 1996. Fuzzy Engineering[M]. Upper Saddle River, NJ: Prentice Hall. |
| [12] | Kosko B. 1999. Fuzzy Engineering[M]. Xi'an: Xi'an Jiaotong University Press. |
| [13] | LI Bing-Xi, LI Shu-Heng, WANG Yong-Hong, et al. 2014. Processing and Applications of standardization of 2-D seismic attributes—Chang 81 formation of Liumaoyuan area of Ordos basin as a example[J]. Progress in Geophysics (in Chinese), 29(4): 1672-1677, doi: 10.6038/pg20140424. |
| [14] | LI Zhan-Dong,LIU Yi-Kun,Li Yang,et al.2015. Well-seismic combination multidisciplinary reservoir technology and the application in Daqing Changyuan oilfield[J]. Progress in Geophysics (in Chinese), 30(1): 242-248, doi: 10.6038/pg20150135. |
| [15] | Lipschutz S, Schiller J J. 2011. Schaum's Outline of Introduction to Probability and Statistics[M]. New York: McGraw-Hill Education. |
| [16] | Payne M A, Liu E R, Bandyopadhyay K. 2013. Uncertainty in discriminating lithology in different data domains[J]. The Leading Edge, 32(9): 1140-1142. |
| [17] | Rahim S, Li Z K, Trivedi J. 2015. Reservoir geological uncertainty reduction: An optimization-based method using multiple static measures[J]. Mathematical Geosciences, 47(4): 373-396. |
| [18] | Reverón J, Roomer J. 2014. Probabilistic facies discrimination from simultaneous seismic-inversion results in clastic reservoirs in southwestern Venezuela[J]. The Leading Edge, 33(7): 784-786, 788-790. |
| [19] | SHEN Nan, ZHANG Chun-Lei, QIN Xu-Sheng. 2008. Application of fuzzy system to reservoir modeling[J]. Xinjiang Petroleum Geology (in Chinese), 29(1): 94-97. |
| [20] | SONG Cheng-Hui, WANG Zhi-Zhang, QI Jia-Fu, et al. 2004. Multi-parameter comprehensively identifying sedimentary facies[J]. Journal of Xi'an Shiyou University (Natural Science Edition) (in Chinese), 19(6): 10-14, 22. |
| [21] | Vernengo L, Czeplowodzki R, Trinchero E, et al. 2014. Improvement of the reservoir characterization of fluvial sandstones with geostatistical inversion in Golfo San Jorge Basin, Argentina[J]. The Leading Edge, 33(5): 508-510, 512, 514, 516, 518. |
| [22] | Wang K Y, Xu Q Y, Zhang G F, et al. 2013. Summary of seismic attribute analysis[J]. Progress in Geophysics (in Chinese), 28(2): 815-823, doi: 10.6038/pg20130231. |
| [23] | WANG Li-Tian, SU Xiao-Jun, GUAN Ren-Shun, et al. 2006. The application of seismic attribute analyses in predicating reservoir of cai 16 area[J]. Progress in Geophysics (in Chinese), 21(3): 922-925, doi: 10.3969/j.issn.1004-2903.2006.03.034. |
| [24] | Wang Ren-Duo, Hu Guang-Dao.1988.Linear Geostatistics[M].Beijing:Geological Publishing House. |
| [25] | Wang X W, Liu H, Teng B B, et al. 2012. Application of geostatistical inversion to thin reservoir prediction[J]. Oil & Gas Geology (in Chinese), 33(5): 730-735. |
| [26] | WU Hai-Bo, DONG Shou-Hua, HUANG Ya-Ping, et al. 2015. Prediction of coal seam igneous intrusion based on seismic attribute[J]. Progress in Geophysics (in Chinese), 30(3): 1376-1381, doi: 10.6038/pg20150350. |
| [27] | Xu M, Wang J H, Xu D H, et al. 2013. The sandbody evolution of shallow-water braided river deltas in the Eighth member of Shihezi formation in block Su120, Sulige Gas Field[J]. Acta Sedimentologica Sinica (in Chinese), 31(2): 340-349. |
| [28] | ZHANG Chun-Lei, XIONG Qi-Hua, ZHANG Yi-Wei. 2001. Application of stochastic simulation to reservoir characterization in the exploration stage of oilfield[J]. Journal of the University of Petroleum, China (in Chinese), 25(1): 59-62. |
| [29] | 边肇祺,张学工.2000.模式识别(第2版)[M].北京:清华大学出版社. |
| [30] | 陈建阳, 田昌炳, 周新茂,等. 2011. 融合多种地震属性的沉积微相研究与储层建模[J]. 石油地球物理勘探, 46(1): 98-102. |
| [31] | 杜世通. 2004. 地震属性分析[J]. 油气地球物理, 2(4): 19-30. |
| [32] | 段林娣, 赵占良, 惠毅. 2011. 多信息约束下的二维地震相分析[J]. 石油天然气学报(江汉石油学院学报), 33(4): 66-71. |
| [33] | 何碧竹, 周杰, 汪功怀. 2003. 利用多元地震属性预测储层信息[J]. 石油地球物理勘探, 38(3): 358-262. |
| [34] | 李丙喜, 李书恒, 王永红,等. 2014. 二维地震属性标准化处理及应用——以鄂尔多斯盆地刘峁塬地区长81段为例[J]. 地球物理学进展, 29(4): 1672-1677, doi: 10.6038/pg20140424. |
| [35] | 李占东, 刘义坤, 李阳,等. 2015. 井震联合多学科油藏技术及在大庆长垣油田中的应用[J]. 地球物理学进展, 30(1): 242-248, doi: 10.6038/pg20150135. |
| [36] | 沈楠, 张春雷, 秦旭升. 2008. 模糊系统在储集层建模中的应用[J]. 新疆石油地质, 29(1): 94-97. |
| [37] | 宋成辉, 王志章, 漆家福,等. 2004. 多参数综合方法判别沉积微相[J]. 西安石油大学学报(自然科学版), 19(6): 10-14, 22. |
| [38] | 王开燕, 徐清彦, 张桂芳,等. 2013. 地震属性分析技术综述[J]. 地球物理学进展, 28(2): 815-823, doi: 10.6038/pg20130231. |
| [39] | 王利田, 苏小军, 管仁顺,等. 2006. 地震属性分析在彩16井区储层预测中的应用[J]. 地球物理学进展, 21(3): 922-925, doi: 10.3969/j.issn.1004-2903.2006.03.034. |
| [40] | 王仁铎, 胡光道. 1988. 线性地质统计学[M]. 北京: 地质出版社. |
| [41] | 王香文, 刘红, 滕彬彬,等. 2012. 地质统计学反演技术在薄储层预测中的应用[J]. 石油与天然气地质, 33(5): 730-735. |
| [42] | 吴海波, 董守华, 黄亚平,等. 2015. 基于地震属性的煤层火成岩侵入预测[J]. 地球物理学进展, 30(3): 1376-1381, doi: 10.6038/pg20150350. |
| [43] | 徐蒙, 王家豪, 徐东浩,等. 2013. 苏里格气田苏120区块盒8段浅水辫状河三角洲砂体演化规律[J]. 沉积学报, 31(2): 340-349. |
| [44] | 张春雷, 熊琦华, 张一伟. 2001. 随机模拟技术在油田勘探阶段油藏描述中的应用[J]. 石油大学学报(自然科学版), 25(1): 59-62. |