 2014, Vol. 29
2014, Vol. 29


2. 中石化胜利油田分公司博士后工作站, 东营 257015
2. Postdoctoral Workstation of Shengli Oilfield, SINOPEC, Dongying 257015, China
地震反演问题的求解一般有两种主要的方法(Bosch et al., 2010),第一种是通过最优化目标函数(杨培杰等,2009)来求解,属于确定性反演方法;第二种是通过随机模拟的方法来实现,称为随机反演方法,或是蒙特卡洛方法,地质统计学反演(Haas and Dubrule, 1994)属于该方法.
地质统计学反演(姜岩等,2013; 王雅春等,2013)应用地质统计信息来描述解空间的先验密度函数,主要由随机模拟、对模拟结果进行优化两部分组成,它的特点是结合了随机建模和地震反演的优势,反演结果突破地震频带宽度的限制,从而可以获得高分辨率的地层波阻抗资料,并且反演结果与井可以达到最佳的吻合,同时,通过地质统计学反演还可以获得伽玛、孔隙度等非波阻抗反演结果.
传统地质统计学试图通过两点之间的空间关系来定量描述地质信息(常文渊,2004; Bohling,2005;朱守彪等,2005; 杨锴等,2012),因此又称为两点地质统计学(Two-Point Geostatistics,TPG),TPG的不足之处在于无法描述具有复杂结构地质信息的模拟,如各种河道、浊积岩、三角洲等.为了克服这些不足,多点地质统计学(Multiple-Point Geostatistics,MPG)应运而生,多点地质统计学利用空间多个点的组合模式来描述地质结构信息,因此更适合于进行具有复杂结构地质信息的模拟.最初的多点地质统计学算法是由Srivastava等(Guardiano and Srivastava, 1993)提出的,这个算法的不足之处在于随机模拟过程非常耗时,随后,Strebelle(2000,2002)提出了一种新的多点地质统计学算法(Single Normal Equation Simulation,SNESIM),通过扫描训练图像建立一个搜索数的数据结构,用来存储条件概率密度信息,SNESIM是第一个实用的多点地质统计学算法,标志着多点地质统计学一个里程碑的出现,其后,有学者对该算法进行了改进(Liu,2003).随后,Arpat(Arpat,2005; Arpat and Caers, 2007)基于模式识别和分类的思想提出了SIMPAT(Simulation of Patterns)算法,采用拼图游戏的思想,通过相似性方法对地下储集层进行恢复和再现.2006年,Zhang(Zhang et al., 2006)又提出了一种基于模式分类的FILTERSIM(Filter-Based Simulation)算法,通过对训练图像内的数据事件进行过滤和分类,识别不同数据事件所代表的地质特征,然后在对数据事件相似性判断的基础上进行多点随机模拟.
常用的地质统计学反演(Lamy et al., 1999; Hansen et al., 2010)都是基于TPG的,一般是应用序贯高斯模拟(印兴耀等,2005)和变差函数(王才经,2004)进行波阻抗的随机模拟,目前已经有很多比较成熟的方法和软件(Zawila et al., 2013),并且在实际应用中也有较好的效果.而对于多点地质统计学反演的研究非常少,在实际生产中还未得到应用,但作为地质统计学反演的发展方向,多点地质统计学反演(González et al., 2008)开始得到国内外学者们的广泛关注,相信在不久的将来,对多点地质统计学反演的深入研究必将带动该学科的深入发展.
1 地震反演理论框架将地球物理信息转化为储层信息属于反演的问题,从概率统计的角度,任何的反演问题可以看成是一种贝叶斯估计问题(Lindley,1965; Ulrych et al., 2001; Tarantola,2005),即通过根据观测数据不断的更新先验知识,从而得到问题的解,用公式描述为

其中,m 是待估计(反演)的参数空间,c是归一化的常数,σpost(m)是后验概率密度函数,pprior(m)是先验概率密度函数,pdata[ d-f(m)]是似然函数,似然函数用来测量m和观测数据的匹配程度,地震正演过程定义为

其中,d是地震数据,f(m)表示正演算子,n是噪声.
地震反演的结果一般是储层弹性参数(如:纵波速度、横波速度、密度等),然而,对于储层预测问题,需要将弹性参数转化为储层物性参数(如:岩性、孔隙度等).地质统计学反演方法可以实现弹性参数和物性参数的同时估计.
用 m elastic表示弹性参数,m reservoir表示物性参数,则 m=(m reservoir,m elastic),根据链式法则(Bosch,2004),式(1)可以扩展为
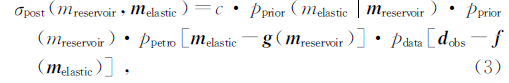
其中,ppetro[ m elastic- g(m reservoir)]表示岩石物理条件概率密度,g表示储层弹性参数和物性参数之间关系的岩石物理正演函数,式(3)就是进行地质统计学反演的通用公式,可以看出,该公式实际上就是贝叶斯公式(Ulrych et al.,2001).
反演问题的求解一般有两种主要的思路(Bosch et al., 2010):(1)通过使得后验概率密度最大化来求解;(2)通过直接对后验概率密度取样来求解.第一种方法就是通过最优化目标函数来求解,属于确定性反演方法;第二种方法被称为随机反演方法,或是蒙特卡洛方法,地质统计学反演属于该方法.确定性反演方法的求解思路主要有稀疏脉冲反演(杨培杰等,2007)和基于模型的反演(Russell and Toksz,1991),随机反演方法主要包括蒙特卡洛(Tarantola,2005)和序贯模拟(Deutsch and Journel, 1998)的方法.
2 两点与多点地质统计学 2.1 两点地质统计学上个世纪60年代,南非科学家G. Matheron发表了专著《Theory of Regionalised Variables》,内容是如何对某位置处的一个未知点进行最佳估计,也就是克里金技术(Kriging),这些理论方法在地质和采矿方面的应用促成了地质统计学的诞生.地质统计学就是以区域化变量理论为基础,以变差函数为基本工具,研究在空间分布上既有随机性,又有结构性的变量的一门学科.
2.1.1 变差函数在TPG里,变差函数是对变量的空间相关性进行定量化描述的主要工具,以概率论的表示法,变异函数定义为
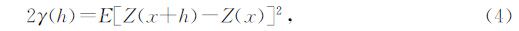
其中,Z(x)及Z(h+x)表示区域化变量,h表示这两个变量之间的距离,变差函数一般用曲线来表示,描述该曲线的主要参数有变程、块金值、基台值等,常用的理论变差函数模型有球状模型、指数模型、高斯模型等.
2.1.2 克里金估计克里金估计(印兴耀和刘永社,2002)是一种进行局部估计的方法.它所提供的是区域化变量在一个局部区域的平均值的最佳估计量,即最优(估计方差最小)、无偏(估计误差的数学期望为零)的估计.
设x1,x2,…,xn为区域上的一系列点,Z(x1),Z(x2),…,Z(xn)为相应的随机变量,x0处的随机变量Z(x0)可以采用一个线性组合来估计:
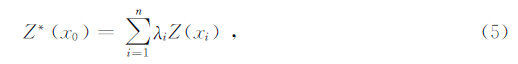
其中,Z*(x0)表示为Z(x0)的估计值,λi为权系数.从式(5)可知,求取的关键是利用统计模型确定的λi值.无偏性和估计方差最小被作为求解的标准,即:
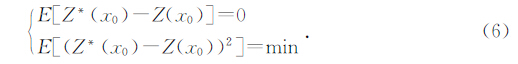
从这两个关系式可推导出求取的克里金方程组,利用拉格朗日乘数法
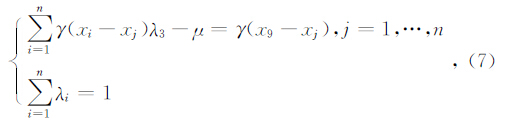
其中,γ(xi-xj)为变差函数,通过求解上述方程,得到λi的解,代入式(5)就可以进行克里金估计了.
由于两点地质统计学中的变差函数只能描述两点之间的统计特性,因此,两点地质统计学插值和模拟方法难于表征具有复杂空间结构和几何形态的地质体.
2.2 多点地质统计学MPG利用空间多个点的组合模式进行地质体的描述,MPG用训练图像(Training Images,TI)(Arpat,2005; 尹艳树等,2011)代替变差函数来描述地质体结构信息,因而可克服TPG不能再现目标几何形态的不足.
MPG通过用定义好的数据模板(Template)对训练图像进行扫描,进而获得多点的数据事件(Data Events)和模式(Patterns),并用这些统计信息和模式进行随机模拟.在MPG随机建模时,对每一个未知点,估计其数据事件出现的概率,随后通过概率抽样获得未知点处数值,即完成单次MPG模拟,然后循环随机模拟完成所有的未知点.首先给出MPG的几个基本概念,然后简要介绍两种目前最常用的MPG算法.
2.2.1 几个基本概念(1)训练图像
训练图像是待研究工区主要地质特征的一种描述和抽象,包含有先验的地质认识,一个11×11网格的训练图像如图 1所示,其中褐色表示河道砂岩,白色表示泥岩.
 | 图 1 训练图像 Fig. 1 Training image |
(2)模板
模板用来扫描训练图像,生成许多的数据事件,用向量来表示一个模板 T,T={u+h1,u+h2,…,u+h nT},u表示模板的中心位置,h1=0,nT表示该模板的节点数,一个3×3模板如图 2所示,几个不同大小的模板如图 3所示,其中不同的灰度值表示模板的访问训练图像的顺序.
 | 图 2 3×3模板 Fig. 2 A templates(3×3) |
 | 图 3 不同大小的模板 Fig. 3 Templates with different sizes |
(3)数据事件
数据事件即是由个数据值和它们的几何结构组成的,定义为:devT(u)={ devT(u+h 1),devT(u+h 2),…,devT(u+h nT)},可以看出,数据事件和模板的几何形态是完全相同的,需要注意的是,在不同的MPG算法中有时将数据事件成为模式(Arpat,2005),而将数据事件定义为用模板对待模拟的图像(数据)进行模拟时获得的一个模式,其中包括了尚未模拟的节点.
用模板T扫描训练图像,获得数据事件,并将这些数据事件进行存储,用一个3×3模板扫描训练图像并获得该图像所有数据事件的示意图如图 4所示.
 | 图 4 3×3模板扫描训练图像并获得数据事件(a)训练图像;(b)训练图像中所有的数据事件. Fig. 4 Scanning the training image to obtain data events using a 3×3 template |
SNESIM(Single Normal Equation Simulation)是第一个实用的MPG算法,是由Stanford大学的Strebelle于2000年提出的.在平稳假设的前提下,一个数据事件在训练图像中的重复数与训练图像大小的比值,相当于该数据事件出现的概率.
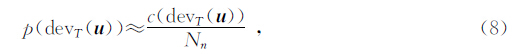
其中,c(dev T(u))表示数据事件重复的次数,Nn表示训练图像的大小.
假设某工区沉积相可取m个状态,{sk,k=1,2,…,m},例如s1=砂岩,s2=泥岩,根据贝叶斯条件概率公式,在给定某一数据事件,状态sk发生的概率为
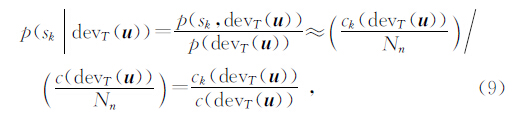
其中,ck(dev T(u))表示c(dev T(u))个重复中sk状态发生的数量.因此,通过扫描训练图像可获取未取样点处的条件概率密度函数.通过该条件概率密度函数进行待模拟点的随机模拟,直到循环随机模拟完成所有的待模拟点.
2.2.3 SIMPAT算法SIMPAT算法(Simulation of Patterns)是由Stanford大学的Arpat在2003年设计的多点地质统计学随机建模方法,SIMPAT算法采用相似性方法对地下储集层进行图像恢复和再现.
定义“模式”的概念,通过扫描图像获取模式,通过聚类的方法将模式进行聚类分析,从而得到若干个模式“集合”,这种集合里包含有很多相近的模式,将“原型”定义为集合内模式的平均,可以认为是这个集合的代表.
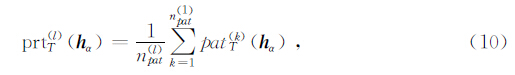
其中,prt<sup>(l)T(h α)代表模式,prt<sup>(l)T(h α)代表原型,n(l)pat是集合内所有模式的数量.
定义距离函数d〈 x,y 〉来表征数据事件之间的相似性,其中向量 x,y 可以是模式、原型或是数据事件,常用的距离函数是明科斯基距离(Minkowski).
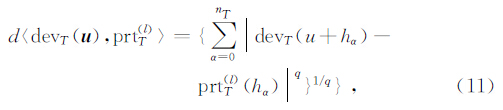
其中,当q=1时是曼哈顿距离(Manhattan),当q=2时是欧几里德距离(Euclidean).
通过定义的摸板拾取出待模拟点的一个数据事件,并通过式(11)寻找与之最接近的原型,该原型中点的值就是待模拟点的条件概率密度函数,通过该条件概率密度函数进行待模拟点的随机模拟,直到循环随机模拟完成所有的待模拟点.
3 地质统计学反演——从两点到多点地质统计学反演方法是一种将随机模拟理论与地震反演相结合的反演方法,主要由两部分组成:(1)随机模拟过程;(2)对模拟结果进行优化.其特点是整合了地震反演和随机建模的优势,如图 5所示,充分利用地震数据横向密集和测井数据垂向密集的特点,求取多个等概率的反演结果,这些反演结果在井点上与测井数据计算的波阻抗一致,在井间符合地震数据和已知数据的地质统计学特征.
 | 图 5 地质统计学反演模式 Fig. 5 Geostatistics inversion pattern |
地质统计学反演是由Haas(Haas and Dubrule, 1994)提出的,后来的很多国内外学者也开始进行这方面的研究(Lamy et al., 1999; 孙思敏等,2007; 王家华等,2011; 尹艳树等,2011).目前的地质统计学反演方法多是基于序贯高斯模拟的地质统计学反演方法,也就是说,其随机模拟过程是通过序贯高斯模拟来实现的.
两点地质统计学反演的一般模式为:
(1)通过变差函数来描述空间数据的相关性,利用井数据求取垂向变差函数,以及统计参数的先验信息(均值、方差);利用地震数据或是稀疏脉冲反演数据计算横向变差函数,发挥测井资料在纵向上分辨率高以及地震数据在横向上密集的优势.
(2)定义模拟的一个随机路径,在每个随机位置处通过序贯高斯模拟来生成若干波阻抗数据,并计算其反射系数序列.
(3)与一个已知的子波进行褶积,得到合成地震道,并与实际的地震道进行比较,按照一定的准则接受一个最佳的波阻抗数据作为该随机位置处的反演结果.
(4)循环步骤(2)、(3),知道反演完成所有的地震道.
到目前为止,基于两点地质统计学反演的方法和软件已经比较成熟,并且在实际应用中也有较好的效果,如Jason储层预测软件的StatMod MC和RockMod模块(Zawila et al., 2013).
3.2 多点地质统计学反演MPG反演与TPG反演的不同之处主要在于随机模拟过程,MPG用训练图像代替变差函数来描述地质体空间结构信息,通过用定义好的数据模板对训练图像进行扫描,进而获得多点的数据事件和模式,并用这些统计信息和模式进行随机模拟.
3.2.1 多点地质统计学反演模式下面介绍一种多点地质统计反演方法,该方法主要包括预处理过程和反演过程两步.
1)预处理过程
预处理的目的要是为了产生用于反演过程的信息.
(1)定义组和条件岩石物理
根据需要定义若干个组,组是一种分类变量,如定义泥岩和砂岩两个组(mgShale和mgS and ),令泥岩=0,砂岩=1,另外,定义每个组的物理性质的一个多变量的条件分布,即:γM(me mg).以波阻抗反演为例,只需要两个物理参数(速度和密度),因此,对于每个组,需要定义二维变量的条件分布: γM(mVp,mρ mgShale) 和γM(mVp,mρ mgS and ).这种条件概率分布一般假设为高斯分布,当然,也可以是其他的分布形式,它可以通过对测井数据进行统计而得到,然后再通过岩石物理来验证和理解测井数据.
(2)建立模式数据库
通过统计的方法建立先验信息(或是模式),通过用预先定义的模板扫描训练图像,来建立模式数据库.
2)反演过程
反演是一种迭代的过程,最终获得反演的解.
(1)(伪)随机路径定义
定义地震剖面的随机访问路径,最终依次访问完所有的地震道,随机访问路径可以提高反演的效果.
(2)多点地质统计学模拟
产生待反演的时间段内的伪组测井数据,对于每个通过SIMPAT模拟的伪组测井,先定义一个需要的伪物理量测井数量,伪物理量测井通过对条件概率密度抽样来获得.
(3)正演模拟
通过将由伪物理量测井所获得的伪物理量测井进行正演,计算合成地震记录,选择与地震数据最佳匹配的由SIMPAT所获得的伪物理量测井数据,为此,对于每一个SIMPAT的实现,定义为
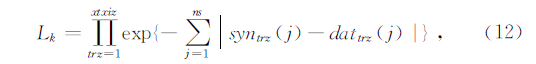
其中,xtxiz是模板的水平长度,k表示某个x处SIMPAT模拟的总数量,然后在Lk里选择最大的一个作为速度和密度反演的结果,该反演结果主要用于计算似然函数γD[f(mg,me)].
到目前为止,基于多点地质统计学的反演文献非常少,在实际生产中还未得到应用,但作为地质统计学反演的发展方向,目前以及开始得到国内外学者们的广泛关注,对多点地质统计学反演的深入研究必将带动该学科的深入发展.
3.2.2 一种基于SIMPAT算法的MPG反演简介文献(González et al., 2008)提出里一种基于SIMPAT算法的多点地质统计学反演方法,该反演采用SIMPAT算法进行多点随机模拟,将岩石物理与多点地质统计学进行有效的结合,岩石物理关系可通过测井和岩芯数据进行统计,也可以通过经验公式获取.
多点地质统计学反演需要准备的数据主要有:测井数据、地震数据和训练图像.本次反演实际应用定义了三个组:砂岩、漫滩、泥岩.图 6的两口测井包括GR曲线、速度曲线、密度曲线,这些井曲线用来计算不同的组所对应的物理量(速度和密度)二维分布的均值、方差、协方差.
 | 图 6 两口井的测井曲线 Fig. 6 Wells logging curves |
图 7是三维地质模型,训练图像从该模型中获得,模型在x、y方向分别有150、130个单元格,每个单元格大小为100×100 m,在Z方向有20个单元格,深112 m(采样间隔112/20=5.6 m),伪组测井曲线由SIMPAT来完成,需要特别注意的是,伪组测井曲线的单元格垂向的大小要与训练图像相同,而伪物理量测井的单元格垂向的大小不必要与训练图像相同,但是要求伪物理量测井与伪组测井曲线垂向单元格的比应该是个常数.
 | 图 7 用于多点地质统计学反演的训练图像 Fig. 7 Training images for multipli-point geostatistics inversion |
建立模式数据库,用5×5的模板在三个网格的基础上扫描训练图像,第一网格模式的数量是11733,第二网格模式的数量是16044,第三网格模式的数量是6816,对于模式数据库中的每个模式,一个相应的关联模式也被保留.
反演有两个输出:(1)直接输出岩性、物性等反演结果,如图 8所示,图中三种不同的灰度表示了三个不同的“组”.其中的每个都是通过所提出的反演方法七次迭代所获得的;(2)基于贝叶斯公式,通过抽样的方法输出概率的反演结果,如图 9所示,图中给出了砂岩、漫滩、泥岩的概率反演剖面,数值范围是[0~1],其中,上图的概率反演结果表明了是砂岩的概率,中间图的概率反演结果表明了是漫滩的概率,下图的概率反演结果表明了是泥岩的概率.
 | 图 8 反演的四个解 Fig. 8 Four solutions of inversion |
 | 图 9 砂岩、漫滩、泥岩的概率反演剖面 Fig. 9 Probability inversion profiles of s and ,overbank and shale |
在以上研究和总结的基础上,设计了多点地质统计学反演流程图,如图 10所示,该流程也设计了两种不同反演数据的输出,即直接输出岩性、物性等反演结果以及输出概率的反演结果,下一步的研究是基于该流程,将多点随机模拟和反演有效结合,开发多点地质统计学反演新方法.
 | 图 10 多点地质统计学反演流程图 Fig. 10 MPG inversion flow |
4.1 地质统计学反演方法是一种将随机模拟理论与地震反演相结合的反演方法,结合了地震反演和随机建模的优势,能够充分利用地震数据横向密集和测井数据垂向密集的特点,求取多个等概率的反演结果.
4.2 两点地质统计学反演方法多是基于序贯高斯模拟的地质统计学反演方法,目前已经比较成熟,并且在实际应用中也有较好的效果,但是还存在一定的问题.
4.3 多点地质统计学反演用训练图像代替两点地质统计学的变差函数来描述地质体空间结构信息,通过用定义好的数据模板对训练图像进行扫描,进而获得多点的数据事件和模式,并用这些统计信息和模式进行随机模拟和反演.
4.4 到目前为止,针对多点地质统计学反演的研究非常少,在实际生产中还未得到应用,但作为地质统计学反演的发展方向,目前以及开始得到国内外学者们的广泛关注,对多点地质统计学反演的深入研究必将带动该学科的深入发展.
致 谢 感谢审稿专家及编辑部的支持和帮助.| [1] | Arpat G B. 2005. Sequential simulation with patterns [Doctoral Dissertation]. Stanford: Stanford University. |
| [2] | Arpat G B, Caers J. 2007. Conditional simulation with patterns [J]. Mathematical Geology, 39(2): 177-203. |
| [3] | Bohling G. 2005. Introduction to Geostatistics and Variograms Analysis [R/OL]. http://people.ku.edu/-gbohling/cpe940. |
| [4] | Bosch M. 2004. The optimization approach to lithological tomography: Combining seismic data and petrophysics for porosity prediction [J]. Geophysics, 69(5): 1272-1282. |
| [5] | Bosch M, Mukerji T, González E F. 2010. Seismic inversion for reservoir properties combining statistical rock physics and geostatistics: A review [J]. Geophysics, 75(5): 75A165-75A176. |
| [6] | Chang W Y. 2004. A case study of geoestatistical interpolation to meteorological fields [J]. Chinese J. Geophys. (in Chinese), 47(6): 982-990. |
| [7] | Deutsch C V, Journel A G. 1998. GSLIB: Geostatistical Software Library and User's Guide [M]. 2nd ed. Oxford: Oxford University Press. |
| [8] | González E F, Mukerji T, Mavko G. 2008. Seismic inversion combining rock physics and multiple-point geostatistics [J]. Geophysics, 73(1): R11-R21. |
| [9] | Guardiano F B, Srivastava R M. 1993. Multivariate geostatistics: Beyond bivariate moments [M]. // Soares A ed. Geostatistics-Troia. Kluwer Academic Publications, 113-114. |
| [10] | Haas A, Dubrule O. 1994. Geostatical inversion — a sequential method of stochastic reservoir modelling constrined by seismic data [J]. First Break, 12(11): 561-569. |
| [11] | Hansen T M, Journel A G, Tarantola A, et al. 2010. Linear inverse Gaussian theory and geostatistics [J]. Geophysics, 71(6): R101-R111. |
| [12] | Jiang Y, Xv L H, Zhang X L, et al. 2013. Prestack geostatistical inversion method and its application on the reservoir prediction of Changyuan oil field [J]. Progress in Geophysics (in Chinese), 28(5): 2579-2586, doi: 10.6038/pg20130537. |
| [13] | Lamy P, Swaby P A, Rowbotham P S, et al. 1999. From seismic to reservoir properties with geostatistical inversion [C]. SPE Reservoir Evaluation & Engineering. |
| [14] | Lindley D V. 1965. Introduction to probability and statistics from bayesian viewpoint [M]. London: Cambridge University Press. |
| [15] | Li F M, Ji Z F, Zhao G L, et al. 2007. Methodology and application of stochastic seismic inversion: A case from P Oilfield, M Basin, Sudan [J]. Petroleum Exploration and Development (in Chinese), 34(4): 451-455. |
| [16] | Liu Y H. 2003. Downscaling seismic data into a geologically sound numerical model [Ph. D. thesis]. Stanford: Stanford University. |
| [17] | Russell B, Toksöz M N. 1991. Comparison of poststack seismic inversion methods [C]. SEG Annual Meeting Expanded Abstracts, 876-878. |
| [18] | Strebelle S. 2000. Sequential simulation drawing structures from training images [Ph. D. thesis]. Stanford: Stanford University. |
| [19] | Strebelle S. 2002. Conditional simulation of complex geological structures using multiple-point statistics [J]. Mathematical Geology, 34(1): 1-21. |
| [20] | Sun S M, Peng S M. 2007. Inversion of geostatistics based on simulated annealing algorithm [J]. Oil Geophysical Prospecting (in Chinese), 42(1): 38-43. |
| [21] | Tarantola A. 2005. Inverse Problem Theory and Methods for Model Parameter Estimation [M]. Philadelphia: Society for Industrial and Applied Mathematics. |
| [22] | Ulrych T J, Sacchi M D, Woodbury A. 2001. A Bayes tour of inversion: A tutorial [J]. Geophysics, 66(1): 55-69. |
| [23] | Wang C J. 2004. Modern applied mathematics (in Chinese)[M]. Dongying: University of Petroleum Press. |
| [24] | Wang J H, Wang J H, Mei M H. 2011. Study on application of geostatistic inversion [J]. Tuha Oil & Gas (in Chinese), 16(3): 201-204. |
| [25] | Wang Y C, Wang L. 2013. Application of geostatistical inversion to reservoir prediction in the Western Slope of the northern Xingshugang oil field [J]. Progress in Geophysics (in Chinese), 28(5): 2554-2560, doi: 10.6038/pg20130534. |
| [26] | Yin X Y, He W S, Huang X R. 2005. Bayesian sequential Gaussian simulation method [J]. Journal of the University of Petroleum (in Chinese), 29(5): 28-32. |
| [27] | Yang P J, Yin X Y, Zhang G Z. 2007. Trispectrum mixed-phase wavelet estimation and maximum posteriori deconvolution [J]. Oil Geophysical Prospecting (in Chinese), 42(4): 396-401. |
| [28] | Yin X Y, Liu Y S. 2002. Methods and development of integrating seismic data in reservoir model-building [J]. Oil Geophysical Prospecting (in Chinese), 37(4): 423-430. |
| [29] | Yin Y S, Zhang C M, Li J Y, et al. 2011. Progress and prospect of multiple-point geostatistics [J]. Journal of Palaeogeography (in Chinese), 13(2): 245-252. |
| [30] | Yang P J, Mu X, Yin X Y. 2009. Prestack three-term simultaneous inversion method and its application [J]. Acta Petrolei Sinica (in Chinese), 30(2): 232-236. |
| [31] | Yang K, Ai D F, Geng J H. 2012. A new geostatistical inversion and reservoir modeling technique constrained by well-log, crosshole and surface seismic data[J]. Chinese J. Geophys. (in Chinese), 55(8): 2695-2704, doi: 10. 6038/j. issn. 0001-5733. 2012. 08.022. |
| [32] | Zhang T F, Switzer P, Journel A G. 2006. Filter-based classification of training image patterns for spatial simulation [J]. Mathematical Geology, 38(1): 63-80. |
| [33] | Zawila J, Pendrel J, Valdez A. 2013. A case study for detecting thin Upper Morrow fluvial sands in the United States Mid-continent from geostatistical simultaneous AVO inversion [R/OL]. http://www.fugro-jason.com/readingroom/techpapers. |
| [34] | Zhu S B, Cai Y E, Shi Y L. 2005. Computation of the present-day strain rate field of the Qinghai-Tibetan plateau and its geodynamic implications [J]. Chinese J. Geophys. (in Chinese), 48(5): 1053-1061. |
| [35] | 常文渊. 2004. 地质统计学在气象要素场插值的实例研究[J]. 地球物理学报, 47(6): 982-990. |
| [36] | 姜岩, 徐立恒, 张秀丽,等. 2013. 叠前地质统计学反演方法在长垣油田储层预测中的应用[J]. 地球物理学进展, 28(5): 2579-2586, doi: 10.6038/pg20130537. |
| [37] | 李方明, 计智锋, 赵国良,等. 2007. 地质统计反演之随机地震反演方法——以苏丹M盆地P油田为例[J]. 石油勘探与开发, 34(4): 451-455. |
| [38] | 孙思敏, 彭仕宓. 2007. 基于模拟退火算法的地质统计学反演方法[J]. 石油地球物理勘探, 42(1): 38-43. |
| [39] | 王才经. 2004. 现代应用数学[M]. 东营: 石油大学出版社. |
| [40] | 王家华, 王镜惠, 梅明华. 2011. 地质统计学反演的应用研究[J]. 吐哈油气, 16(3): 201-204. |
| [41] | 王雅春, 王璐. 2013. 地质统计学反演在杏北西斜坡区储层预测中的应用[J]. 地球物理学进展, 28(5): 2554-2560, doi: 10.6038/pg20130534. |
| [42] | 印兴耀, 贺维胜, 黄旭日. 2005. 贝叶斯—序贯高斯模拟方法[J]. 石油大学学报(自然科学版), 29(5): 28-32. |
| [43] | 杨培杰, 印兴耀, 张广智. 2007. 三谱混合相位子波估计与最大后验反褶积[J]. 石油地球物理勘探, 42(4): 396-401. |
| [44] | 印兴耀, 刘永社. 2002. 储层建模中地质统计学整合地震数据的方法及研究进展[J]. 石油地球物理勘探, 37(4): 423-430. |
| [45] | 尹艳树, 张昌民, 李玖勇,等. 2011. 多点地质统计学研究进展与展望[J]. 古地理学报, 13(2): 245-252. |
| [46] | 杨培杰, 穆星, 印兴耀. 2009. 叠前三参数同步反演方法及其应用[J]. 石油学报, 30(2): 232-236. |
| [47] | 杨锴, 艾迪飞, 耿建华. 2012. 测井、井间地震与地面地震数据联合约束下的地质统计学随机建模方法研究[J]. 地球物理学报, 55(8):2695-2704,doi:10.6038/j.issn.0001-5733.2012.08.022. |
| [48] | 朱守彪, 蔡永恩, 石耀霖. 2005. 青藏高原及邻区现今地应变率场的计算及其结果的地球动力学意义[J]. 地球物理学报, 48(5): 1053-1061. |