 2013, Vol. 4
2013, Vol. 4引用本文 |

| 基于GEP的金属矿尾矿坝变形预测模型研究 |

尾矿库是指筑坝拦截谷口或围地构成的,用以堆存金属或非金属矿山矿石选别后排出的尾矿或其他工业废渣的场所,是维持矿山正常生产的必要设施.同时尾矿库是一个具有高势能的人造泥石流危险源,各种天然的和人为的不利因素威胁着它的安全[1],一旦溃坝,将严重影响下游居民生命财产安全,并对区域生态环境造成破坏.
在世界93 种事故、公害的隐患中,尾矿库事故名列第18 位[2].据国际大坝委员会统计,20 世纪全世界发生的尾矿库事故在200 例以上[3].近年来,辽宁、四川、山西、广东等地也先后发生了多起尾矿坝垮坝事故,如2007 年11 月,辽宁海城尾矿坝溃堤致使该坝下游2 km 处的多处房屋被毁,死亡10 余人;2008年5 月,受震灾影响,四川有9 座矿山尾矿库发生溃坝或导致尾矿坝不同程度的裂缝、渗漏、滑坡、护坡破坏等隐患[4];2008 年9 月,山西省襄汾县新塔矿业公司尾矿坝溃坝事故尾砂流失约20 万m3,造成270 多人遇难;2010 年9 月,广东信宜紫金矿业银岩锡矿高旗岭尾矿库发生溃坝事故,造成20 余人遇难,下游流域范围内房屋、交通、水利等设施以及农田、农作物等严重损毁.因此,加强对尾矿库的安全监测特别是对尾矿坝的变形监测,建立有效的预警机制至关重要.
传统的尾矿坝变形预测方法主要有回归分析法、时间序列分析模型、灰色模型、BP 神经网络等,但回归分析法需要大量的观测样本,时间序列分析模型往往需要考虑变形体的变形特性,灰色模型预测精度不高,BP 神经网络的预测精度依赖样本的大小和训练的次数,效率较低.以上预测模型都存在预测精度不高或适应性不强的问题,因此需要寻求一种新的尾矿坝变形预测方法,基因表达式编程具有极强的函数发现能力和很高的学习效率,能够在没有任何先验知识及不了解事物内部机制的情况下,挖掘出较为准确的公式.因此有必要开展基于基因表达式编程的尾矿坝变形预测模型的研究.
1 GEP 简介基因表达式编程是传承了遗传算法和遗传编程两者的特有优势,随之出现的一种新的进化算法,2001 年葡萄牙学者Candida Ferreira 第1 次将该算法公布于世,国际上对GEP 的研究成为热点.它能够在没有历史经验,并且不了解个体的机能、只有历史数据的前提下得出较好的表达式,凭借其特有的优势和高效性在众多范围获得了很好应用.GEP 结合了遗传编程(GP)和遗传算法(GA)的优点,可以用简单编码解决复杂问题[5].目前GEP 已在多个领域得到成功应用,例如:王卫红等[6]提出了基于克隆选择和量子进化的GEP 分类算法-ClonalQuantum-GEP; 杜冬等[7]结合空气动力学模型,将GEP 应用在四维飞行轨迹预测上;刘小生等[8]利用GEP 进行北京市PM2.5浓度预测;李世祥等[9]利用基因表达式程序设计挖掘出参考影像与退化影像的数学函数关系,然后利用该函数关系对退化影像进行恢复重建;谷琼等[10]提出一种基于主成分分析的基因表达式程序设计算法,并将其用于边坡稳定性预测.
1.1 GEP 编码方式基因表达式编程使用线性符号来编码,这些符号是具有规定长度的,基因由头部和尾部两部分组成.头部由函数操作符和终止符组成,尾部仅含有终止符这一种符号.其中函数操作符来源于函数集中的算数运算符和初等数学函数运算符,终止符是由待求问题的变量或者常量组成的,根据要求解的问题来给定头部长度h,尾部长度t 是关于h 和n 的函数表达式:
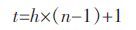
|
(1) |
式(1)中,n 为所需参数量最多的函数的运算数目,这样才能保证染色体在遗传操作过程中的合法性.
在GEP 中,一个或者若干个类似的等长基因通过连接运算符构成了染色体(Chromosome).连接运算符可以是函数集中的任意符号.GEP 的表现型用表达式树来表示,一个或多个基因可以构成染色体,基因的个数在程序运行之前已经给定.染色体中每个基因片段可以解码成一个子表达式树(Sub-ExpressionTree, Sub-ET),多个子表达式树构成了更复杂的多子树(Multi-subunit ET)表达式树[11].GEP 用线性的、定长的简单编码表示个体,易于遗传操作,并采用非线性的、不定长的树型结构来解决复杂的非线性问题,从而达到了用简单编码解决复杂问题的目的[12].
1.2 GEP 的遗传操作假设的GEP 编码和染色体结构是进行函数发现的物质基础,那么多种多样的遗传算子则是GEP 解决复杂问题的重要保证.一般来说,GEP 的遗传算子,包括选择、变异、插串和重组等[13].
(1)选择复制算子.通常是采用赌盘的方式对种群的个体进行选择.在对种群中的个体进行适应度评价以后,根据得到的结果,运用赌盘对它进行选择,确定选择复制的次数,在这个过程中,种群大小维持不变,而且优秀的个体被选择为下一代.种群中具有较高适应度的个体复制到下一代的机率更大.
(2)变异算子.对GEP 来说,变异是不受限,非常自由的,染色体的各个位置都有机会发生变异操作.如果变异发生在基因头部,最终能够变异成函数符或终止符,但是尾部只能变异成终止符,只有这样才能保证染色体的构造具有完整性.变异的种类和次数均没有限制,都可以得到一个符合规定的新生个体.
(3)插串算子.插串算子是存在于基因表达式编程中的一种特殊的算子.GEP 中用于插串的元素是随机选择的能够被激活并插到染色体别的地方的基因片段.GEP 具有3 种插串方式: IS 插串、RIS 插串和基因插串.
(4)重组算子.随着自然界的进化,每个新的个体都是由一个新的染色体产生的,而每个新的染色体的出现是由两个同源染色体通过交配、重组而生成的.重组对自然界的演化具有关键性作用.由GEP 的编码中k-表达式与数学模型的关系可知,GEP 重组方式有3 种:单点重组、两点重组、基因重组.
1.3 GEP 适应度函数适应度函数用来计算种群中染色个体适应环境的能力,并判断适应度值的优劣,从而可以根据个体的适应能力对种群的进化做出一定指导.选择一个好的适应度函数能够提高解决问题的能力,效率也更高,因此适应度函数选择的优劣直接关系到遗传的进化方向.通过GEP 进行函数挖掘,需要对种群中的各个个体进行适应度评价,即计算利用该表达式得到的模型预测值和实测值的拟合程度.对于符号回归和函数发现问题,Ferreira 用绝对误差和相对误差提出了2 种适应值函数[14]:
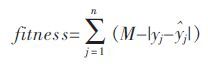
|
(2) |
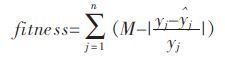
|
(3) |
元昌安等[15]利用统计残差提出了一种用于评价数据拟合程度的适应度函数,在实际应用中效果较好.
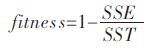
|
(4) |
其中:
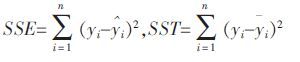
|
yi 是第i 个实测值,
对于各种实际问题来说,适应度函数的表示方式是不一样的,针对不同的问题采用不同的分析方法,适应值函数要能够完全地反映出个体的好坏.
1.4 GEP 算法流程GEP 首先设置参数,选择合适的函数符和终止符,然后用这些函数符和终止符对种群进行初始化.经过初始化的种群个体进行染色体解码,转化为表达式树形式.根据用户选定的相对误差适应度函数,来对群体中的染色个体进行适应度评价,并判断群体中的个体是否达到规定要求,如果满足,根据选出的适应度高的个体,得到尾矿坝变形预测函数关系来对测试数据进行预测,如果不满足,则通过赌盘的方式选择适应度高的个体,通过变异、插串、重组等各种遗传操作出现新的染色个体,新的群体重新产生,新产生的群体中的个体再经过上面的一系列过程,不断进化,最后结束的条件是适应度值达到最大值或进化次数达到规定值.GEP 算法的基本流程如图 1 所示.
 |
| 图 1 GEP 算法流程 |
2 尾矿坝变形预测模型
采用GEP- Deep Excavation 模型对某有色金属矿山尾矿坝变形监测数据进行处理,模拟选定监测点的位移变化轨迹,预测其变化趋势.
2.1 研究对象概况该尾矿坝为碾压混凝土重力坝,最大坝高18.26 m, 坝顶长约310 m.在进行变形监测时,在大坝两侧距离大坝较远的稳定的基岩上各布设了2 个GPS 基准点,在大坝背水坡面上建立A、B、C 3排监测点,同排监测点之间水平距离约30 m 左右,监测点布设情况见图 2 所示.
 |
| 图 2 尾矿坝监测点分布图 |
该尾矿坝监测点自布设以来,每2 个月进行一次变形监测,汛期增加观测次数,共获得36 期观测数据,为了研究该坝监测点的位移规律,预测其位移变化趋势,选取B5 监测点的水平位移数据,将前29 期作为训练样本,后7 期作为测试样本,以Eclipse 为开发工具,通过选择函数集和终止符集、种群初始化、染色体解码、适应度评估、遗传操作等过程,开发了基于GEP- Deep Excavation 的尾矿坝变形预测程序.
2.2 用GEP 对监测点水平位移进行建模的参数设置用GEP 对监测点B5 水平位移进行变形预测,其参数设置见表 1,首先要定义基因和适应度函数,该尾矿坝监测点B5 水平位移预测模型中的基因和适应度函数分别如下:
基因:该模型中所采用的函数集为F={+,-,*,/,~},变量集为T={d1,d2,d3,d4,d5,d6}.
| 表1 监测点B5 水平位移的GEP 参数设置 |
 |
| 点击放大 |
适应度函数: 该模型采用相对误差适应度函数.令T 是训练数据集合,包含m 组数据,Tj 表示训练数据中第j 组数据的输入,yj 表示对应于Tj 的观测数据,yj 表示利用表达式由Tj 计算得到的的估计值,M是一个常数,则个体j 的适应度函数fitness, 其值由式(5)给出:
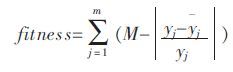
|
(5) |
根据上述分析,基于GEP 的尾矿坝监测点的水平位移变形预测模型的输入数据、输出函数和建立过程如下:
(1)输入数据.包括监测点水平位移训练数据,监测点水平位移测试数据,监测点水平位移历史数据期数n, 种群大小,基因头部长度,基因尾部长度,基因个数,变异率,插串(IS 插串,RIS 插串,基因插串)率,重组(单点重组,两点重组,基因重组)率.
(2)输出函数.最优染色体对应的监测点水平位移时间序列模型(函数表达式).
(3)模型建立过程.步骤如下:
第1 步: 根据n 的值将原始数据转化为有n + 1列的时间序列数据;
第2 步: 根据Deep Excavation-Gene 的结构对种群进行初始化;
第3 步: 计算每个个体的Deep Excavation-Fitness.依据适应度函数挑选出最好个体,即适应度高的个体被选择到下一代的可能性更大;
第4 步: 判断种群中的个体是否满足终止条件(达到最大适应度或最大迭代次数),如果满足,则转第7 步,否则从第5 步继续向下运行;
第5 步:遗传进化产生下一代.①选择操作(Select);②复制(Replication);③变异(Mutation);④IS 插串(IS_Transposition);⑤RIS插串(RIS_Transposition);⑥Gene 插串(Gene_Transposition);⑦单点重组(OnePoint_Recombination); ⑧两点重组(TwoPoint_Recombination);⑨基因重组(Gene_Recombination);
第6 步:转到第3 步继续运行;
第7 步:根据选择的种群中的适应度最高的个体得到监测点水平位移变形预测函数关系,从而可以对测试数据进行预测.
2.4 基于GEP-Deep Excavation 模型的监测点水平位移变形预测时间序列分析尾矿坝监测点监测数据是按照一定的时间间隔进行观测的,不论时间间隔的长短,这些数据都是按照时间顺序排列的.基于GEP-Deep Excavation 模型的变形预测模型涉及到2 个重要的参数:嵌入维数和时间延迟.嵌入维数的数量代表利用的观测数据的个数,嵌入维数越多,说明利用的观测数据越多.时间延迟表示数据可以是间隔一段时间的,也可以是连续的.本实例中嵌入维数取6,时间延迟为1.进化后得到的预测模型如式(6)所示.
利用上述预测模型对后7 期变形数据进行预测,并与测试样本进行对比分析,结果如表 2 所示.
| 表2 尾矿坝监测点水平位移实际值和预测值 |
 |
| 点击放大 |
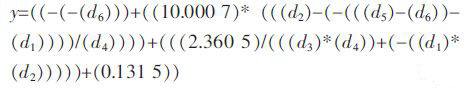
|
(6) |
同时采用灰色GM(1,1)和BP 神经网络及GEP编程算法3 种模型对监测点B5 的变形数据进行预测,其预测值与相对误差如表 3 所示.
| 表3 3 种预测模型对监测点水平位移的预测精度分析 |
 |
| 点击放大 |
3种预测模型的预测值与真实值的对比图如图 3所示.
 |
| 图 3 3 种预测模型对监测点水平位移的预测值与真实值对比图 |
通过表 3 和图 3 可知:灰色GM(1,1)、BP 神经网络和基因表达式编程模型对监测点水平位移进行预测的平均相对误差分别是2.373 9 %、1.718 3 %和0.580 9 %,相比较其它两种模型来说,基因表达式编程模型的精度得到明显提高,平均相对误差小,监测点水平位移的预测值与真实值的拟合程度高.
4 结束语尾矿坝变形产生的原因复杂,且各影响因子间函数关系无法准确表达,而基因表达式编程无需知道自变量与因变量间的关系即可较准确地挖掘函数,省去了建模和确定众多参数的过程,论文分析了基于GEP 的尾矿坝变形预测的方法和流程,以某金属矿山尾矿坝变形预测为例,选择了函数集和终止符集,进行了种群初始化、染色体解码、适应度评估和遗传操作等,并开发了基于GEP-Deep Excavation 的尾矿坝变形预测模型,对该金属矿山尾矿坝监测点位移数据进行了预测.经实验对比分析,基于GEP 的金属矿山尾矿坝变形预测模型在预测值的平均相对误差和与真实值的拟合度方面均优于灰色GM(1,1)模型和BP 神经网络模型,证实了基于GEP 的尾矿坝变形预测模型的可靠性,同时为金属矿山尾矿坝的变形预测提供了一种新方法.
| [1] | 彭康, 李夕兵, 王世鸣. 基于未确知测度模型的尾矿库溃坝风险评价[J]. 中南大学学报: 自然科学版, 2012, 43(4): 1147–1152. |
| [2] | 张力霆. 尾矿库溃坝研究综述[J]. 水利学报, 2013, 44(5): 594–600. |
| [3] | 魏勇, 许开立, 郑欣. 浅析国内外尾矿坝事故及原因[J]. 金属矿山, 2009(7): 139–142. |
| [4] | 蔡嗣经, 张栋, 何理. 地震中尾矿库液化失稳机理及数值模拟研究[J]. 有色金属科学与工程, 2011, 2(2): 1–6. |
| [5] | 元昌安, 彭昱忠, 覃晓, 等. 基因表达式编程算法原理与应用[M]. 北京: 科学出版社 , 2010. |
| [6] | 王卫红, 杜燕烨, 李曲. 基于克隆选择和量子进化的GEP分类算法[J]. 计算机科学, 2011, 38(10): 236–239. |
| [7] | 杜冬, 麦海波. 基于GEP的四维飞行轨迹预测模型[J]. 四川大学学报: 自然科学版, 2013(4): 749–752. |
| [8] | 刘小生, 李胜, 赵相博. 基于基因表达式编程的PM2.5浓度预测模型研究[J]. 江西理工大学学报, 2013, 34(5): 1–5. |
| [9] | 李世祥, 樊红, 王玉莉. 基因表达式程序设计的卫星遥感影像恢复[J]. 武汉大学学报: 信息科学版, 2010, 35(7): 877–881. |
| [10] | 谷琼, 蔡之华, 朱莉. 基于PCA-GEP算法的边坡稳定性预测[J]. 岩土力学, 2009, 30(3): 757–768. |
| [11] |
Candida Ferreira. Gene expression programming: A new adaptive algorithm for solving problems[J].
Complex Systems, 2001, 13(2): 87–129. |
| [12] | 唐常杰, 张天庆, 左劼, 等. 基于基因表达式编程的知识发现——沿革、成果和发展方向[J]. 计算机应用, 2004, 24(10): 7–10. |
| [13] | Ferreira C. Gene expression programming: Mathematical modeling by an artificial intelligence[M]. 2nd ed. Berlin: Springer-Verlag , 2006. |
| [14] | Ferreira C. Gene expression programming: A new adaptive algorithm for solving problems[M]. Berlin: Springer , 2002. |
| [15] | 元昌安, 唐常杰, 左劼, 等. 基于基因表达式编程的函数挖掘-收敛性分析与残差制导进化算法[J]. 四川大学学报: 工程科学版, 2004, 36(6): 100–105. |