 1994, Vol. 8
1994, Vol. 8引用本文 |

| 模糊控制及其在选矿中的应用 |
模糊数学是美国数学家Zadeh于1965年创建的一个专门描述不能准确定量变量之间的运算关系的数学分支。以后又被用于工程控制, 称之为模糊控制。我国的许多学者在模糊数学领域内都取得了成就, 因此模糊控制被各工程引进的也很快。尽管模糊控制在选矿领域中的应用, 在世界范围内还只是处于初级阶段, 但它一定会得到很快的发展。
1 什么是模糊控制模糊控制是应用模糊数学于工程控制的一种方法, 它的基础是模糊数学。在选矿操作中工人们实际上使用的绝大多数是模糊变量, 如看到矿泥含量比较多, 就多加些水玻璃, 泡沫发粘就多加些冲洗水。这里所说的'多', '粘'等都是模糊量, 因为操作工甲认为'粘', 操作工乙可能认为是'比较粘', 这样, 同样认为泡沫发粘, 但是程度不同, 所以在'粘'这个变量的领域内也可以取不同的模糊值, 如一点也不粘, 有些粘, 很粘, 非常粘, 这时它们的隶属函数, 分别表达在图 1中。曲线1, 2, 3, 4和5分别是各个模糊值的隶属函数。每两个隶属函数相交点处的隶属度可称为是该两个模糊变量的贴近度。譬如, 在图 1中, 一点不粘和有些粘之间的贴近度是0.8, 而和粘之间的贴近度则为0.4。而一点也不粘和很粘之间的贴近度是0。说明虽然这两个都是模糊变量, 但概念上绝对不会混淆。有了这样的保证可以使我们在使用模糊控制时不会出现大错误。
 |
| 1-一点也不粘; 2-有些粘; 3 -粘; 4-很枯; 5 -非常粘。 图 1 关于'粘'的模糊变量隶属度 |
我们对模糊变量有了认识之后, 就可以进一步来研究模糊控制的问题, 事实上人类在没有利用数字之前, 所有的行为都是由模糊控制来规范的。既然发展了数字, 人们在日常生活中的绝大多数思维和反应都还是遵循模糊控制的。下面我们举一个常见的例子来作为模糊控制的入门。我们要过马路, 看到有汽车驶过来, 首先我们要输入的一个模糊信息是汽车离我们有多远?是很远, 较远, 近还是很近。这时候大概没有时间和可能去估计出这个距离的精确值, 所以这时利的是模糊值。第二个要输入的模糊值是汽车目前的车速如何?是很快, 快, 较慢还是很慢。然后根据这两个模糊值来给出控制指令来指挥自己的行动。表 1给出了这个控制规律的格式。
| 表 1 过马路时的模糊关系 |
 |
| 点击放大 |
表 1内容称之为关系, 用R表示, 表中所作出的决定或输出称之为模糊响应, 用U表示.设A, B分别为车距和车速的模糊取值, 则
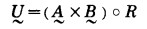
|
我们仍然以上面的例子作进一步的解释。当人们在过马路时, 会一边走一边观看开过来的汽车, 如果跑步过马路, 刚跑了一半, 觉得车还远着呢, 就会改为步行过马路, 这种对控制表示修改, 或者对输出结果进行修改的过程可称为是自适应或自学习过程。
自适应过程可以用许多方法来完成。
当控制表的输出误差是线性的, 则可采取两种方法加以修正, 一种方法是把控制表中的项目采取平移的方法, 譬如说我们对表 1的控制输出给得太保守了, 这样把表 1的模糊响应都往右平移一格如表 2所示。这时过马路的行动就要积极多了。
| 表 2 通过自适应修正的控制表 |
 |
| 点击放大 |
第二种方法和第一种方法的指导思想是一样的, 但不同的是它不修改控制表, 而是只改变控制输出模糊值量化时的比例因子。它的优点是不必去修改控制表中的大量数据, 而只去改变一个比例因子就可以了。
在输入和输出之间存在着非线性关系时, 则要看是否存在非线性模型, 如果控制表是由模型推算出来的, 则可以通过修改模型参数的方法来重新计算控制表, 不然只好逐项来修改, 这样自适应过程比较复杂。
整个自适应模糊控制系统的结构见图 2。非自适应性模糊控制的结构也在图 2中的虚线框内表示出来。从以上看出自适应模糊控制较之普通模糊控制增加了自适应部分, 图 2中也给出了两种可能的自适应方法。
 |
| 图 2 模糊控制及自适应模糊控制系统结构示意图 |
3 模糊控制有什么好处
人们可能会问“既然已经有了比较精确的测定值, 为什么还要模糊化厂用模糊方法来控制呢?得到模糊的控制输出值又要量化成数值变量来控制, 这样是不是又烦琐, 更倒退了呢?下面我们要叙述一下模糊控制的优点:
第一:把量化变量模糊化了送入模糊控制器, 就不需要很精确的数学模型.很容易把人们的经验转化为控制表来实现控制, 这样简化了运算过程, 使控制动作反应迅速。而有时候对于一个复杂的过程要建立一个准确的数学模型是相当困难的。
第二:我们知道控制过程的实现是要靠执行机构来完成的, 它们可能是继电器, 也可能是调速电机等。如果应用数学模型来控制常常控制输出值总处于变化之中.这样就会引起执行机构的频繁动作, 有时候会作出很多没有必要的多余动作, 而使用模糊控制时就会使控制过程的输出平稳得多。
第三:虽然有时候我们使用了能测到精确值的仪表.但是仪表所显示的数值精确度是有限的, 譬如一个在线分析给出的铜精矿品:位为20.417%和20.179%。可能并不能真正说明精矿品位在升高, 因为其中包括的取样随机性, 样品处理过程中的误差等等。所以只根据这样的变化就进行过程的调整恐怕是不必要的。对一些测定变量, 作一些模糊化处理然后再来分析, 可能还更合理些。
第四:对于整个过程, 譬如说浮选过程, 在没有在线测试手段时, 工人几乎全是依靠模糊信息进行控制的。如把泡沫冲洗一下看看精矿品位, 得到一个精矿品位的模糊信息。用手摸摸矿浆, 得到一个磨矿细度的模糊信息, 还可以得到诸如泡沫粘不粘, 含泥量大不大等等信息。很明显模糊信息的成本要比精确信息的成本便宜得多。就是同样用仪器来测, 测一个模糊值也要比测一个精确值便宜得多, 这就是采用模糊控制的另外的一个优点。
第五:至于模糊控制是不是准确、可靠, 我们可以用过马路的例子来说明, 每天有几十万人在过马路, 但被撞被压的才占多大比例?骑自行车就是一个自适应模糊控制, 每天也有几十万人在骑车, 出事率大概也只有万分之几吧!所以说模糊控制的可靠性是毋庸置疑的。
4 模糊控制在选矿中的应用模糊控制在选矿中的应用还只是近年来的事情, 发表的文献并不很多, 下面举两个例子予以介绍, 使大家能知道如何具体的运用。
例1 模糊控制在破碎中的运用。
该模糊控制器的控制对象是一台中碎机.整个控制系统组成如图 3。
 |
| 图 3 中碎机模糊控制组成图 |
矿石经过中间矿仓由可控速给料机送往中碎机, 中碎机产品送往筛分前粉矿仓。控制系统有三个测定变量点:料位测定器测粉矿仓的料位, 破碎机驱动电流和破碎腔物料充填程度的检测。通过模糊判断和决策。扮制给料速度, 以达到充分发挥中碎机处理能办的目的。
三个测定变量的隶属函数如图 4、5和6所示。图中可看出对模糊变量的隶属函数, 没有采用简单的等分方法, 简化了一些变量的取值。
 |
| 图 4 驱动电流的隶属函数 |
 |
| 图 5 矿仓水平隶属函数 |
 |
| 图 6 给料量变化隶属函数 |
开始时规定了8条控制规律, 经过专家审理, 这此规律可表示为图 7的组合, 当然这此知识都是'专家们'的书本知识, 所以是初步的控制规则。可以在实践中加以修正。
 |
| 图 7 模糊逻辑控制系统 |
开始使用时并不顺利, 操作人员不愿意用控制系统。譬如当驱动电流到50 ~52A时, 按图 7的规则应当调整给矿量以'负大'方向, 即大大地降低给矿量。但操作人员说“在处理软矿石时50 ~52A的电流不算高。相反, 有时候驱动电流只有39~40A时, 操作人员就减少给矿量。问题是开始的专家系统没有考虑到矿石性质的变化。通过与操作人员的讨论及观察发现由腔室的充满程度来判断矿石的软硬最为有效, 因此设了一个模糊矩阵, 对驱动电流的合适标准作修正。该矩阵包括腔室充满程度的当前值和变化值。
通过对驱动电流值模糊处理后, 碎矿机的破碎效率提高了, 但是仍然存在着要改变给矿量时, 反应较慢, 于是又改变了控制器输出的量化比例因子, 进一步提高其灵敏度。然而仍没有解决由于腔室过满而必须停止给料的问题。后来又加了防止给料中断的措施, 使模糊控制更臻完善。
逐步完善了模糊控制的指标及改进的结果见表 3。
| 表 3 中碎过程模糊控制后改善结果的情况 |
 |
| 点击放大 |
从表中可看出:使用了模糊控制后中碎机的破碎效率大大提高了。
在这个例子中可以看到一个模糊值的测试器, 破碎腔位测定器, 对过程控制起着非常重要的作用。
例2 浮选柱自适应模糊控制模拟器
本例模拟器是用来模拟浮选柱的泡沫层, 模拟器所采用的数学模型是一个能描述多种可浮矿物在浮选柱中富集的模型, 因此它能反映不同泡沫层高度上各种有用成分的含量和回收率的分布。模拟器通过假随机数发生器对给料的有用成分的品位和它们的可浮性产生扰动, 然后利用测得浮出产品的品位和回收率, 通过自适应模糊控制系统去控制充气量或者是液面, 以保证精矿合格并得到最高的回收率。
模拟器运行的一个例子是含方解石的萤石矿的浮选。原矿品位含CaF2 3 %, 含CaCO3 0.6 %, CaF2的浮选速率常数为0.9 min-1, CaCO3为0.6 min-1, 浮选中取精矿CaF2含量, 精矿CaF2含量的变化率; 精矿CaCO3的含量, CaCO3的品位变化率以及CaF2回收率。CaF2回收率的变化率, CaCO3的回收率和CaCO3回收率的变化率等八个测定值作为模糊输入量。自学习控制主要修正输出变量, 充气量, 在量化时的比例因子。在判断控制效果时使用了三个达标参数, 一是当前的控制水平(不考虑方向), 二是控制后接近日标的速度, 三是达标的方向。如果达标的方向反了(负数), 则说明控制太过头引起了大振荡。通过对这三项参数的检验确定对童化比例因子增加或是减少以及确定变化的幅度。
使用该自适应模糊控制器对模拟器所作的控制运行得到了比较满意的结果。
表 4给出了在不同控制策略下精矿的合格率(CaF2 > 96%)和平均回收率。
| 表 4 浮选柱浮选萤石时的模糊控制模拟运行结果 |
 |
| 点击放大 |
试验类别:
第一类是没有使用模糊控制时的结果。
第二类是使用模糊控制, 但是一次性给定比例因子, 没有自适应过程。
第三类是使用自适应模糊控制时的结果。在使用自学习模糊控制时, 表中所列的比例因子是其起始值。
从表中可以看出采用了自适应控制后使产品的合格率大大地提高。
图 8表达了在不同量化比例因子的起始条件下, 如何随着比例因子在自适应过程中调整, 改善了过程控制的稳定性, 从图 8中可以看出不论比例因子的起始值选在-0.0150还是-0.005, 最后通过自适应调整后, 都达到-0.0013-0.0014之间, 只有这时控制的效果最好, 而且在500轮运行以后, 比例因子值基本上固定不再作大的调整了。
 |
| 图 8 浮选柱使用自学习模糊控制时的动态反应过程。 |
从图 8中可以看出, 不合格产品均产生在自适应过程中, 一旦'学成'之后, 精矿合格率还会大大的提高。模糊控制的优点从这里也可以看到。
5 结语模糊控制是近十年来新兴的一个控制领域, 随着计算机的日益普及, 模糊控制将愈来愈受到人们的青睐。
尽管选矿自动化已经有了20多年的历史, 但是在线分析仪器的价格仍然居高不卜, 使选矿自动化的进展受到影响。模糊控制的发展, 将给简化测试手段提供一种机会, 即用模糊的测试值来进行控制。这样有可能大大降低选矿厂自动化控制的费用。
我国是一个发展中的国家, 对大规模地使用各种在线测试手段, 在短期内难以实现, 笔者认为发展模糊性试验工具, 发展模糊控制, 应当是近期内发展选矿自动化的一个方向。