 2017, Vol. 47
2017, Vol. 47
2. 北京师范大学 信息科学与技术学院, 北京 100875
2. School of Information Science & Technology, Beijing Normal University, Beijing 100875, China
兵马俑被称作世界第八大奇迹, 成为传播中国文化的重要渠道, 因此对兵马俑文物的保护和修复至关重要。而对兵马俑文物碎片分类问题进行研究, 将对文物碎片的自动拼接、文物的修复和数字化保护工作产生很大的促进作用。传统的手工修复方法耗时耗力, 采用计算机辅助的方式可以有效弥补手工方式的缺点, 其主要分为3个步骤, 分别是碎片分类、碎片拼接和丢失信息修补[1]。针对兵马俑的碎片分类, 需要考虑根据碎片的纹理特征和几何特征将不同部位的碎片进行分类, 从而降低碎片自动拼接和修补的工作难度。在图像特征提取方面, WANG X等[2]通过结合方向梯度直方图(HOG)特征和局部二值模式(LBP)来提取图像的纹理特征,融合的HOG和LBP特征虽然可以作为图像局部区域的有效表示,但是该特征并不具有尺度不变性;JAIN A K等[3]使用斜率直方图来表示目标物体的形状特征,首先计算每条直线段的斜率, 然后按照一定的角度划分来统计直线段的斜率直方图。在文物碎片分类方面, 康馨月等[4]通过提取碎片表面显著的几何特征, 并以这些显著几何特征为基础构建碎片特征描述符, 最后运用地球移动距离(EMD)方法进行匹配并分类, 该方法在具有显著表面特征的部分表现较好, 但在平滑碎片上分类准确率较低; 王克刚等[5]使用Gabor滤波器提取古瓷片图像表面的纹理特征, 并通过SVM对提取到的表面纹理特征进行训练, 从而实现了对古瓷片的准确自动分类; 周像金等[6]通过提取碎片图像在纹理、颜色、形状上的特征, 同时选择不同的训练器进行实验, 最终形成了基于SVM的古瓷片分类方法。由于兵马俑碎片在颜色特征上没有明显差别, 在纹理上不同部分碎片具有一定规律, 在形状特征上也存在比较大的区别, 因此本文结合已有的相关研究方法, 提出将碎片纹理特征和形状特征结合并利用SVM的方法对兵马俑碎片进行分类。
本文目的是实现兵马俑躯干、裙摆、头部、手臂、腿脚等碎片的高效分类。其中躯干碎片和裙摆碎片在几何特征上比较类似, 在纹理特征上存在明显不同:躯干相比裙摆, 多了泡钉和线条纹理; 裙摆碎片相比腿脚碎片在几何特征上有显著差异, 而在纹理特征上没有明显区别。解决这两部分碎片分类问题是提出本次方法的突破点, 也是本次研究的重点和难点。本文利用不同碎片在纹理特征和几何特征上表现的相似性和规律性, 通过对不同部位碎片图像特征进行提取, 找到相同部位碎片的共有特征, 并通过SVM进行训练, 得到相关分类模型, 从而实现兵马俑碎片的自动准确分类。
1 碎片图像预处理文中实验所用的文物碎片数据, 均为秦始皇兵马俑博物馆文物保管地实地采集所得。由于数据采集中环境的限制以及基于对文物保护方面的考虑, 本文实验所采用的文物碎片来自于Artec SpiderTM手持式3D扫描仪采集的兵马俑碎片三维模型。通过对三维模型进行截取获得二维图像, 由于截取的图像在类别和尺寸上相对比较混杂, 为了便于研究, 首先需要对图像进行统一化处理, 处理后的图像尺寸均为200*200, 同时对图片进行了筛选, 选出了具有代表性的5类兵马俑图像, 分别是头部、躯干、腿脚及踏板、手臂和裙摆部分。图 1为部分兵马俑碎片图像。

|
图 1 兵马俑各部位图像 Fig. 1 Images of various parts of Terra-Cotta Warriors |
SIFT算法是用来检测图像局部特征的算法, 该算法以检测图像特征点为基础, 通过生成特征点直方图并构建特征点描述算子来得到图像的纹理特征。通过SIFT算法可以提取到稳定的特征点, 其在旋转、缩放和亮度变化上具有很好的不变性[7], 同时在对光线和视角的改变上也具有相当高的容忍度。兵马俑文物碎片分类问题在本质上是一个相对模糊和复杂的多类别、多部位判别问题, 需要采集大量的文物碎片图像样本, 但相对于特征点维数而言, 文物碎片的样本数又是一个小样本问题。SIFT算法的多量性刚好满足研究的需求, 即使用少数的样本也可以产生出大量的SIFT特征向量。图 2所示为通过SIFT算法进行图像特征提取的步骤。

|
图 2 SIFT特征提取步骤 Fig. 2 Steps of SIFT feature extraction |
在SIFT特征提取过程中, 图片的尺寸大小对特征点检测结果会产生直接影响, 为了得到稳定的特征点, SIFT算法通过多层滤波方法建立了基于样本图像的金字塔模型, 即图像尺度空间, 以图像尺度空间来模拟图像数据的多尺度特征。金字塔模型由两部分组成(如图 3所示), 第一部分为高斯尺度空间, 每层的图像是通过高斯卷积核和上一层图像进行卷积得到, 该方法定义为
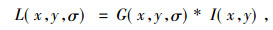
|
(1) |

|
图 3 SIFT尺度空间 Fig. 3 The scale space of SIFT |
G(x, y, σ)是尺度可变高斯函数, (x, y)为像素点坐标, σ为尺度坐标, 大的σ值对应低分辨率图像, 小的σ对应高分辨率图像, I(x, y)表示输入图像[8], 通过高斯卷积的方法可以减少图像的噪音影响, 同时提高图像在多尺度下的特征不变性; 第二部分为高斯差分尺度空间, 由于LOG可以用高斯差分算子DOG表示, 通过高斯金字塔每层内相邻两张图片相减可以得到DOG金字塔表示为
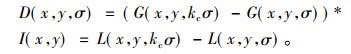
|
(2) |
其中,kc为常数乘法因子, DOG相比LOG减少了运算次数, 所以大大节省了运算时间。本文实验以原始文物碎片图像放大2倍作为第1幅实验图像, 通过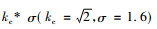
尺度空间的构造是进行SIFT特征提取的前提, 下一步以寻找邻域内的极大极小值点的方式进行关键点的粗提取, 每个像素点与其邻域8个像素点和尺度空间中相邻的2幅图像对应位置的9个像素点的像素值进行比较, 如果该点的像素值最大或最小, 则暂列为关键点。对金字塔中所有图像进行粗提取后, 进行特征点的精确定位, 主要包含3个部分:①子像素级特征点提取, 由于通过粗提取找到的极值点都落在像素点位置上, 而当用空间曲面去拟合的话, 极值点并不是都在像素点上, 因此通过泰勒展开的方法找到子像素级的极值点作为特征点; ②消除对比度差的极值点, 通过在程序中设置阈值, 将亮度比较低的极值点直接过滤掉; ③消除边界点, 去掉平坦区域上和直线边界上的点, 这些点的梯度直方图很大或者很小, 因此在图像分类中这些点是没有用的。为满足特征算子的旋转不变性, 需要为每一个关键点指定一个方向作为主方向。最后计算特征点加权梯度直方图, 构造特征点描述子, 本文实验以特征点为中心, 取邻域16*16的区域并进行4*4小区域分割, 将每个小区域分为8个方向,并计算加权梯度直方图, 产生的特征点描述子维数为4*4*8=128维。
3 词袋模型构建 3.1 K-means聚类聚类是指根据某一规则, 将数据分到不同类的过程, 使其具有极高的类内相似性和类间相异性[9], 相异度通常采用距离来度量。K-means聚类算法是基于距离的算法, 其采用距离作为数据相似性的评价标准, 是样本聚类中使用最广泛的算法之一[10], K-means算法的目的是将n个观察对象分到k个聚类中, SIFT算法为每一张训练图像提取若干个图像块的特征向量, K-means算法对得到的特征向量进行聚类, 得到k个聚类中心, 用聚类中心构建词典。
令碎片样本数据集为X={x1, x2, …,xn}, 每个xi为提取到的128维特征向量; C={C1, C2, …, Ck}表示k个类; 对象之间的欧氏距离为
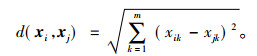
|
(3) |
其中, m为对象维度, xik为xi的第k个属性值。K-means算法的重点是要以迭代的方法将数据划分到不同类中[11], 以求得式(4)中函数的最小化。
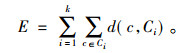
|
(4) |
从X中随机取k个元素, 作为k个类各自的中心, 分别计算剩余元素到k个类中心的相异度, 将这些元素分别划分到相异度最低的类中。根据聚类结果, 重新计算k个类各自的中心, 计算方法是取类中所用元素各自维度的算术平均数, 将X中全部元素按照新的中心重新聚类, 直到聚类结果不再变化为止。
3.2 词袋模型词袋模型(BoW)最初应用于文本的分类上, 用一组无序的单词来表达一个文档。在计算机视觉中, 图像的特征被当做单词, LI Feifei[12]提出用BoW模型来表达图像, 通过对图像特征向量聚类产生的聚类中心, 可以定义为BoW中的单词, 以图像特征向量为基础构建的直方图就是图像的BoW模型。对每张图像, 通过最近邻算法计算该图像的每个单词应该属于哪一个码本, 根据码本生成直方图, 从而得到该图片对应于该码本的BoW表示。图 4为实验碎片的BoW模型直方图, 其中码本数定为200, 由于每幅图像的图像块数量不等, 因此直方图纵坐标以频率表示, 由图 4直观地看出不同部位碎片在纹理上表现的差异。

|
图 4 碎片图像BoW直方图 Fig. 4 BoW histogram of fragment images |
词袋模型的构建是以SIFT特征点的提取为基础, 并使用K-means算法进行词汇表的构建而得到的, 因此, SIFT特征点的提取结果直接影响模型构建好坏。图 5和图 6分别为同一躯干碎片在不同边缘空白区域大小下的特征点和BoW直方图对比, 对比结果显示, 图像边缘空白区域越小, 提取到的特征点就越多, 相应的词袋模型特征也更加显著, 实验结果也说明使用较小的边缘空白图像得到的分类效果更优。因此, 为了达到更好的分类结果, 尽量选择碎片本身占比大的图像作为实验图像。

|
图 5 特征点对比 Fig. 5 Feature point contrast |

|
图 6 BoW直方图对比 Fig. 6 BoW histogram contrast |
通过SIFT特征来进行碎片分类的方法, 在表面特征比较明显的部分显示出了很好的效果。由于裙摆碎片和腿脚碎片表面没有特别明显区分的纹理特征, 仅仅通过SIFT特征进行分类训练后在这两部分上表现稍差。而裙摆碎片和腿脚碎片在几何特征上表现出了明显的区别, 因此提出将SIFT特征和形状特征结合的方法对这5部分碎片进行分类。碎片形状特征提取步骤如图 7所示。

|
图 7 形状特征提取步骤 Fig. 7 Steps of shape feature extraction |
提取图像的形状特征最重要的步骤之一就是对图像进行边缘检测。本文使用Canny算子对兵马俑碎片图像进行边缘信息获取, Canny算子是检测边缘效果最好的算法之一, 在去噪能力上也相对其他算法更强, 具有较高精准度和较低的误判率, 并且能够抑制虚假边缘[13]。图 8为利用Canny算子对文物5部分碎片图像的检测结果, 由该图可以明显看出不同部位碎片在形状上有很大区别。

|
图 8 各部分碎片边缘检测图 Fig. 8 Edge detection chart for each parts |
在Canny算子对图像进行边缘检测的过程中, 阈值的设置是边缘提取的关键。Canny算子采用双阈值的处理方法来减少伪边缘, 大于高阈值的一定是边缘点, 小于低阈值的一定不是边缘点, 介于高低阈值之间的, 如果该像素点的邻接像素有超过高阈值的边缘像素, 它就是边缘点, 否则不是边缘点[14]。因此, 阈值设置过高, 将会导致丢失太多细节并且导致边缘断裂, 从而得到不完整的碎片几何特征, 阈值设置过低, 将会出现过多的伪边缘, 甚至将图像噪声当作边缘进行提取, 与本文实验中不相关的边缘点也会随之增多。兵马俑各个部位碎片在需要完整轮廓信息的同时, 也需要部分细节信息, 因此阈值的设置对分类效果的好坏有至关重要的作用。
图 9通过Matlab软件, 显示了手部碎片在不同阈值(图中设置的阈值为高阈值, 对应的低阈值为高阈值*0.4)下的Canny边缘检测结果, 经过反复多次实验, 以分类结果好坏为选择依据, 确定了针对不同部位碎片的最佳阈值。

|
图 9 边缘检测图对比 Fig. 9 Edge detection chart contrast |
同SIFT特征提取一样, 碎片的形状特征提取也需要满足旋转、平移及缩放的不变性。Hu.M.K[15]在1962年证明了Hu不变矩具有旋转、缩放和平移不变性, 结合其在形状特征上的良好表现, 本文采用Hu不变矩作为碎片形状特征提取的方法。
式(5)为图像的p+q阶几何矩定义, 其中f(x, y)为图像函数; 式(6)为图像的p+q阶中心矩定义, 其中x和y为图像的重心, 定义为式(7);式(8)为图像的归一化中心矩定义。Hu不变矩实质上是利用二阶和三阶归一化中心矩构造的7个不变矩, 如式(9)所示, M1~M7为构造的7个不变矩。
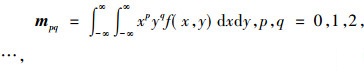
|
(5) |
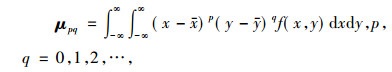
|
(6) |
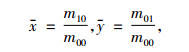
|
(7) |
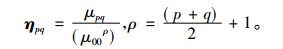
|
(8) |
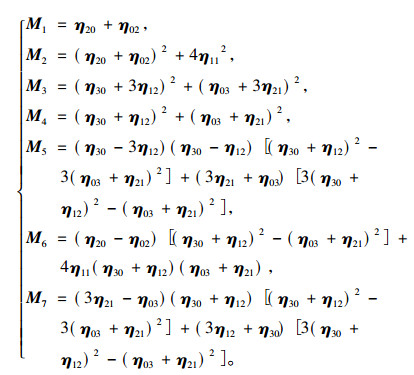
|
(9) |
SVM是一个有监督的学习模型, 其广泛应用于模式识别中, 提供了一个独特的全局超平面将数据集分为不同类, 同时采用结构风险最小化原理来降低训练阶段的风险[16]。与其他分类器相比, SVM在解决小样本、非线性和高维度模式识别上具有明显的优势[17]。用于训练分类模型的兵马俑碎片图像数据集属于小样本数据集, 因此本文采用SVM作为实验的分类器。图 10为通过SVM训练分类的步骤。

|
图 10 兵马俑碎片分类步骤 Fig. 10 Steps of Terra-Cotta Warriors fragments classification |
在图像特征结合应用方面, 毕学慧等[18]将28个形状特征和7个颜色特征合并作为SVM分类器的特征输入。本文结合其研究方法, 将兵马俑碎片图像的纹理特征和形状特征合并作为训练碎片分类的SVM分类器输入。
影响SVM分类效果的因素除了特征选择和训练样本选择外, 最重要的就是核函数的选择, 核函数的目的是通过将输入空间内线性不可分的数据映射到一个高维的特征空间内,使得数据在特征空间内变成可分的。如何选择最优的核函数,对图像分类中SVM的性能表现至关重要, 因此本文实验采用以下两种核函数进行实验比较:
1) 径向基核函数(RBF)
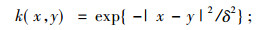
|
(10) |
2) 直方图交叉核函数(HIK)
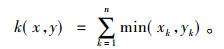
|
(11) |
径向基函数在SVM训练上具有很强的局部性, 在小样本数据上能表现出很好的性能, 基于文物碎片的特征数量小原因, 选择了以径向基函数作为实验所用的核函数之一。
文献[19]最早提出直方图交叉核函数, 是一种基于隐式对应关系的内核函数, 其通过将特征集映射到多分辨率超平面上, 并对超平面进行比较。针对本文, 多分辨率超平面即是由原始BoW直方图根据灰度值的不同间隔转化的多层次直方图, 即不同分辨率直方图。实验证明, 直方图交叉核函数在文物碎片分类上具有很大优势。
6 实验结果与分析本文以兵马俑碎片图像作为实验对象, 共使用采集的兵马俑碎片图像527幅, 其中350幅图像用作SVM的训练样本集, 另外177幅图像作为分类模型的验证样本集。实验根据分类需求将所采集的兵马俑碎片图像分为5大类, 分别是:W1类, 表示兵马俑头部; W2类, 表示兵马俑躯干部分; W3类, 表示兵马俑裙摆部分; W4类, 表示兵马俑腿脚和踏板部分; W5类, 表示兵马俑手臂部分。
结合所采集的兵马俑三维模型和二维图像, 并利用Matlab软件及LibSVM工具包对基于显著几何特征的方法和本文所提出的方法进行实验。表 1显示的是本次实验所用各类碎片图像数量, 其中碎片三维模型数量和碎片图像数量相等。
|
|
表 1 兵马俑碎片图像数量统计 Tab. 1 Image statistics of Terra-Cotta Warriors fragments |
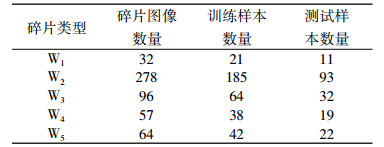
表 2为基于SIFT特征和形状特征使用两种不同核函数的SVM分类器对兵马俑碎片各个部分的识别结果。由表中不同部位文物碎片的识别率可以看出, 在文物碎片分类方面, HIK核函数的表现要比RBF核函数好, 针对各个部位识别率都较RBF核函数高。同时, 通过表 2可以看出, 在对不同碎片不同部位的识别结果中, 头部的识别率最好, 躯干部分和裙摆部分的识别率相对较低, 分析主要原因是头部的轮廓和纹理比较明显, 而躯干和裙摆的碎片形状类似, 纹理方面除了躯干碎片有独特的泡钉和线条以外, 其余纹理和裙摆碎片都比较相似, 因此分类的准确率稍微偏低。
|
|
表 2 不同核函数的分类结果对比 Tab. 2 Comparison of classification results based on different kernel functions |
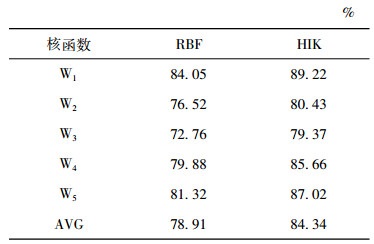
表 3显示了单独通过SIFT特征或形状特征结合SVM进行参考实验的实验结果, 并且与本文方法和基于显著几何特征的分类方法进行了对比。
|
|
表 3 不同方法的分类结果对比 Tab. 3 Comparison of classification results of different methods |
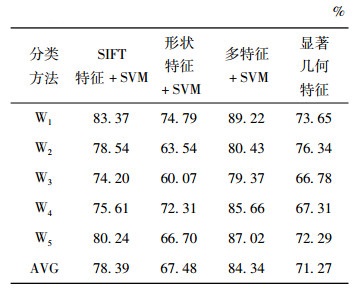
从表 3中可以看到基于SIFT特征和SVM的分类方法在裙摆和腿脚及踏板部分的识别率相对较低; 基于形状特征和SVM的分类方法在躯干和裙摆部分的识别率相对较低; 使用基于多特征和SVM的分类方法的识别率相比前两种方法都高, 同时也比基于显著几何特征的分类方法识别率高。通过对本文方法和基于显著几何特征在腿脚、裙摆部分识别结果进行对比可知, 本文方法显著改善了基于显著几何特征方法在识别表面平滑碎片上的缺点, 并且在其他部位的识别中表现也均优于该方法。
7 结语本文提出的文物碎片分类方法, 在对几何特征和纹理特征有一定区别的兵马俑碎片分类上, 取得了很好的效果。在对特征不明显以及特征交叉的兵马俑碎片分类上还需结合考古专家以往经验以及实际情况进行手动分类和校准, 由于选择样本上存在的缺陷和参数选择的影响, 本文方法只是对部分文物碎片进行了仿真实验, 在实际应用中还需考虑缺失纹理、严重损坏等诸多因素。如何更加准确、高效地分类所有情况下的碎片, 还需要作进一步研究。
| [1] |
杨承磊, 张宗霞, 潘荣江, 等. 计算机辅助文物修复系统架构及关键技术研究[J]. 系统仿真学报, 2006, 18(7): 2003-2006. DOI:10.3969/j.issn.1004-731X.2006.07.066 |
| [2] |
WANG X, HAN T X, YAN S. An HOG-LBP human detector with partial occlusion handling[C]//IEEE International Conference on Computer Vision.IEEE, 2010: 32-39.
|
| [3] |
JAIN A K, VAILAYA A. Image retrieval using color and shape[J]. Pattern Recognition, 1996, 29(8): 1233-1244. DOI:10.1016/0031-3203(95)00160-3 |
| [4] |
康馨月, 周明全, 耿国华. 基于显著几何特征的文物碎片分类[J]. 图学学报, 2015, 36(4): 551-556. DOI:10.3969/j.issn.2095-302X.2015.04.010 |
| [5] |
耿国华, 王克刚, 李康. 基于色彩纹理特征的图像分类及应用[J]. 西北大学学报(自然科学版), 2010, 40(1): 53-56. |
| [6] |
周像金, 耿国华, 周明全, 等.基于BP神经网络和支持向量机的文物分类研究[C]//计算机技术与应用进展——全国计算机科学与技术应用学术会议论文集.合肥: 中国科学技术大学出版社, 2006: 446-449.
|
| [7] |
SUN Y, ZHAO L, HUANG S, et al. L2-SIFT: SIFT feature extraction and matching for large images in large-scale aerial photogrammetry[J]. Isprs Journal of Photogrammetry & Remote Sensing, 2014, 91: 1-16. |
| [8] |
LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110. DOI:10.1023/B:VISI.0000029664.99615.94 |
| [9] |
HAN J W, KAMBER M.数据挖掘概念与技术[M].范明, 孟小峰, 译.北京: 机械工业出版社, 2001.
|
| [10] |
韩凌波. 一种新的K-means最佳聚类数确定方法[J]. 现代计算机, 2013(30): 12-15. |
| [11] |
尹成祥, 张宏军, 张睿, 等. 一种改进的K-Means算法[J]. 计算机技术与发展, 2014(10): 30-33. |
| [12] |
LI F F, PERONA P. A bayesian hierarchical model for learning natural scene categories[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE Computer Socienty, 2005: 524-531.
|
| [13] |
王智文. 几种边缘检测算子的性能比较研究[J]. 制造业自动化, 2012, 34(11): 14-16. DOI:10.3969/j.issn.1009-0134.2012.6(s).05 |
| [14] |
CANNY J. A computational approach to edge detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 1986, 8(6): 679. |
| [15] |
HU M K. Visual pattern recognition by moment invariants[J]. Information Theory Ire Transactions on, 1962, 8(2): 179-187. DOI:10.1109/TIT.1962.1057692 |
| [16] |
ABDIANSAH A, WARDOYO R. Time complexity analysis of support vector machines (SVM) in LibSVM[J]. International Journal of Computer Applications, 2015, 128(3): 975. |
| [17] |
CHEN Q.The application of problems concerning the imbalanced data classification by means of support vector machines[C]//International Symposium on Knowledge Acquisition & Modeling.IEEE Computer Society, 2011: 291-295.
|
| [18] |
毕学慧, 刘华明, 倪扬眉, 等. 基于SVM的多特征唐卡头饰分类[J]. 阜阳师范学院学报(自然科学版), 2016, 33(2): 55-60. |
| [19] |
GRAUMAN K, DARRELL T.The pyramid match kernel: Discriminative classification with sets of image features[C]//Tenth IEEE International Conference on Computer Vision.IEEE Computer Society, 2005, 2: 1458-1465.
|