 2017, Vol. 47
2017, Vol. 47
自20世纪90年代以来, 推荐系统越来越多地得到学术界和工业界的研究关注, 取得了长足发展, 为处理信息过载问题提供了一个有效的工具。以往的研究工作大都集中在提高推荐准确度或是提升推荐效率上, 对其他方面的因素(如多样性、覆盖率、新颖性等)的研究较少。近年来, 越来越多的研究者意识到, 仅提高推荐准确度和推荐效率是远远不够的, 其他因素对于提升推荐质量和用户体验的积极作用同样不可忽视, 特别是推荐结果多样性的影响, 已在诸多研究中被强调。研究表明,推荐系统的一个重要目标是向用户提供高度个性化的产品[1-3]。
忽略推荐结果的多样性, 盲目追求推荐的准确度, 可能导致用户陷入到一个相对狭窄的推荐集里, 用户的一些潜在兴趣、需求被忽略掉, 视野变得愈发狭窄, 在一定程度上违背了个性化推荐系统的设计初衷[4]。Hu Rong等人的实证研究结果显示,推荐列表的多样性对用户感知系统的有用性和易用性有着积极和重要的影响[5]。因此, 即使推荐的结果高度准确, 但缺乏多样性的推荐结果, 不能覆盖用户的兴趣范围, 也不一定能使用户满意[6]。而向用户提供更具个性化, 即多样性的推荐结果, 有助于推荐系统为用户提供更优质的用户体验。
目前, 针对提升多样性的研究主要集中在个体多样性和整体多样性优化, 学者们提出了多种解决方案, 并从理论和实验上进行了证明[7-10]。个体多样性是指,对于某一具体用户, 在保证符合用户兴趣的同时, 尽量推荐一些彼此相似度很低的物品。提升整体多样性的目标是针对一组用户, 各自的推荐列表尽可能差异化, 避免只推荐流行物品的情况。然而, 一个具备个体多样性和整体多样性的推荐系统可能仍然无法完全满足用户对多样性的要求, 特别是音乐、电影类的推荐。在此类推荐系统中, 用户的需求是不断变化的, 用户希望每次新获得的推荐应与过去的推荐有所差异, 即推荐系统还需具备时序多样性。本文以提升时序多样性为目标, 提出了一种基于用户情境的时序多样性优化算法, 并以音乐推荐为例进行说明和实验。实验表明, 该算法能够有效提高推荐的时序多样性。
1 相关工作 1.1 协同过滤推荐算法协同过滤算法是推荐系统领域目前应用最为广泛、研究最为深入、最被业内认可的推荐方法。协同过滤算法假设同一类用户的评分信息总是十分相似的, 当预测一个用户对一个未评分项目的兴趣时, 可以将兴趣相似的用户的评价作为参考。
协同过滤推荐主要包括3个模块:①输入模块, 通常是用户-项目评分信息; ②推荐模块, 核心模块, 对应所使用的推荐算法, 主要包括用户-项目相似度计算、邻居选择、评分预测等步骤; ③输出模块, 将推荐结果以合适的方式呈现给用户, 如Top-N推荐列表。算法1描述了典型的基于项目的协同过滤算法(Item-based collaborative filtering,IBCF)。
算法1 IBCF算法
输入:用户-项目评分矩阵R、最近邻居项目数k、推荐集L,项目数N。
输出:目标用户u的top-N推荐集L。
过程:
1) 根据R, 使用合适的相似度计算方法, 计算项目之间的相似度, 得到项目相似度矩阵S;
2) 找出当前用户u的已评分项目集Iu, 对所有项目i∈Iu,从S中读取i的k最近邻居集Ni={i1, i2, …, ik}, 合并所有Ni, 同时从中删除已存在于Iu的项目, 得到候选项目集C;
3) 对所有项目j∈C, 预测用户u对其评分;
4) 将所有项目j∈C按预测评分从高到低排序,从中选择前N个项目, 形成推荐集L。
1.2 推荐结果多样性的类型推荐多样化的目标是向某一用户推荐一组彼此相似性低但符合用户兴趣的项目[11]。目前推荐系统中的多样性主要指:个体多样性、整体多样性和时序多样性[12]。
1.2.1 个体多样性个体多样性从单个用户的角度来度量推荐结果的多样性, 主要考察系统寻找用户多个兴趣领域的能力, 避推荐过于相似的物品。例如在一个电影网站上, 某一用户过去看过《饥饿游戏1》, 系统向其推荐《饥饿游戏》系列的其他电影, 可以保证推荐的准确度, 但是用户未必满意这样的推荐。如果推荐列表中能够包含一些其他生存游戏类的科幻电影, 将更有可能激发用户的观影欲, 提升用户体验。
1.2.2 整体多样性对整个推荐系统而言, 仅提升个体多样性还远远不够。例如, 向所有用户推荐相同的一组互不相似的物品, 可以实现个体多样性, 但对于系统来说, 并未实现多样性要求。此时需要从全局角度, 即整体多样性来考察。整体多样性主要强调针对不同用户的推荐应尽可能地不同。整体多样性的提升可以避免推荐结果集中于少数热门物品, 有利于冷门物品被用户发现[13]。Netflix网站就是通过向用户提供更加多样化的电影推荐, 而得到更大的收益[14]。
1.2.3 时序多样性现实情况下, 由于消费季节的变化、新物品的发布、用户兴趣的动态迁移, 以及用户消费情境的改变, 用户偏好会在一定程度上发生变化。对于同一个用户来说, 如果每次新获得的推荐都与过去的推荐不尽相同, 用户会感知推荐列表内容在减少。尤其是在音乐、电影、书籍类的推荐系统中, 用户总希望获得不同于以往的新推荐结果。因此,近年来推荐系统中的时间感知成为一个研究热点, 有效提高个性化推荐的时序多样性也日益受到重视。
1.3 提高推荐结果多样性的方法近年来, 学者对推荐系统的多样性优化做出了诸多尝试, 并取得了一定的进展[15-16]。其中, 采用启发式的策略对传统方法得到的候选推荐列表进行二次优化的方法,因其无需对传统算法做过多改动而得到最为广泛的研究。基于推荐系统为用户生成推荐过程的两大阶段:评分预测和生成推荐,二次优化增加多样性的方法也大致分为两类, 一是通过在预测阶段增加干预来提高多样性, 即前向过滤方法, 包括用户模型分割、用户相似性幂律调节等方法; 二是在产生阶段重排推荐列表, 即后向过滤方法, 包括主题多样性、目标函数优化、推荐解释多样性等方法。
2 基于用户情境的时序多样性优化算法从用户角度分析, 用户对推荐结果多样性的要求源自用户自身需求的不断变化, 而用户需求通常是由用户所处的情境决定的。
2.1 用户情境用户情境通常可分为内部情境与外部情境。内部情境是指用户自身提供的因素, 包括诸如年龄、职业、情绪等; 外部情境信息有时间、地理位置等。同一用户在不同情境下,以及不同用户在相同情境下, 对同一推荐结果可能有不同的感受。例如对于同一个用户, 他在周内和周末希望得到的音乐推荐可能是不一样的, 心情不同时, 可能更希望得到不同的推荐结果。因此, 在推荐时, 考虑用户情境因素是非常必要的。
2.2 优化算法 2.2.1 内部信息加权用户的内部信息对推荐结果的产生有着最为直接的影响。但用户的内部信息包含很多, 部分信息是相对稳定的, 如性别、年龄、职业等; 同时还有部分信息却是不断变化的, 如用户的情绪、兴趣等。相较于稳定信息, 这部分变化信息对推荐结果多样性的影响更为直接。例如在一个音乐网站上, 某一用户过去一直喜欢听摇滚类型的音乐, 近期突然开始听民谣类型的音乐, 此时系统如果不能及时识别出该用户兴趣的变化, 继续推荐摇滚乐, 显然是不合适的。类似的, 当用户心情好时, 推荐曲风欢快的音乐显然比阴郁的音乐更加适合。对于这种情况, 系统应该重点考察用户近期的内部信息, 越近的记录, 越有参考价值, 在计算时应赋予更高的权重。为此, 本文选取指数型的时间权重对记录数据进行加权,如图 1所示。

|
图 1 指数型时间权重示意图 Fig. 1 Exponential time weights |
计算公式为
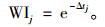
|
(1) |
其中, WIj代表歌曲j反映用户当前内部情景的能力, Δtj为用户最后一次播放歌曲j的时间与当前时间的间隔。考虑时间权重后, 歌曲之间的相似度为
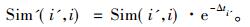
|
(2) |
除过内部信息, 外部信息对多样性也具有一定的影响。同样以音乐为例, 在不同场所、不同时间下, 用户希望得到的推荐是不尽相同的, 例如用户在睡前可能更希望听到舒缓的音乐。因此, 建立项目-情境评分矩阵, 每一项为一个项目在某一外部情境下的评分, 其值可由历史数据统计得到, 如图 2所示。

|
图 2 项目-情境评分矩阵 Fig. 2 Item-context rate matrix |
其中i1, i2, …, in代表系统中的项目,C1,C2,…,Cm代表选择的外部情境, 如时间、地点, ci1, ci2, …, cip代表不同外部情境下的细分, 如C1代表时间, 则c11, c12, …, c1p可以代表清晨、上午、中午等。
得到为用户生成的推荐候选集后, 利用项目-情境矩阵计算候选集中每个项目在用户当前情境下的评分, 计算方法为
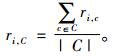
|
(3) |
其中,ri, C是项目i在情境C下的评分, C是目标用户当前所处的外部情境集合, ri, c是项目i在C中的每一具体情境下的评分。以ri, C的值为依据对候选集重新排列, 选取评分最高的前N个项目组成最终的推荐列表。
2.2.3 算法描述将用户内部情境和外部情境引入到IBCF算法的不同阶段, 可以得到基于用户情境的协同过滤推荐结果时序多样性优化算法(UCBCF), 算法描述如下:
算法2 UCBCF算法
输入:用户u的历史行为记录集R, 用户u当前的情境C。
输出:用户u在当前情境C下的top-N推荐列表L。
过程:
1) 使用传统协同过滤算法得到用户u的推荐候选集LC;
2) 使用式(1)对项目评分进行加权,传统基于用户的协同过滤算法得到用户u在当前情境s下的推荐候选集LC;
3) 使用式(2)对候选集LC中项目的评分进行加权;
4) 将评分较高的N个项目组成集合L推荐给用户u。
3 实验 3.1 数据集本文使用阿里音乐流行趋势预测大赛提供的数据集作为实验数据, 该数据集提供了440 000多名阿里音乐用户连续6个月的历史数据,总记录数超过1 400万条。
3.2 评估方法本文实验采用4个评估标准, 分别是F-measure,Intra-list similarity(ILS),Hamming distance(HD),Self-system diversity(SSD),4个标准分别定义如下:
1) F-measure

|
其中,PredictionSet为算法预测的数据集合, ReferenceSet为真实的数据集合。Precision衡量了正确预测结果占整体预测结果的比例, 其值越高, 算法的精确度越高。Recall描述了正确预测结果占真实结果的比例, 其值越高, 算法的召回率越高。
由于Precision和Recall很难同步提高, 因此, 一般使用F-measure计算二者的调和平均值, F-measure的值越大, 预测效果越好。本文中取a=1, 即F= 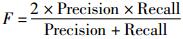
2) ILS
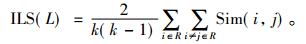
|
ILS主要指针对单个用户, 一般来说, ILS值越大, 推荐个体多样性效果越差。其中, i和j是同一推荐列表中的两个项目, k是推荐项目的个数。Sim(i, j)是i和j的相似度。
3) HD
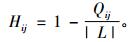
|
海明距离主要度量整体多样性。其中, L为推荐列表的长度, Qij为系统推荐给用户i和j的两个推荐列表中相同物品的个数。推荐列表的多样性就是Hij的平均值, 其值越大, 整体多样性程度越高。
4) SSD
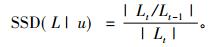
|
SSD指推荐项目没有被包括在以前的推荐列表中的比例, 主要考察推荐结果的时序多样性。其中, Lt-1是Lt的上一次推荐, Lt/Lt-1={r∈Lt|r∉Lt-1}。SSD值越小, 推荐列表的时序多样性越好。
3.3 实验结果本文实现了一种基于用户情境的多样性优化算法, 并与传统基于项目的IBCF算法、文献[10]提出的多样性增强推荐算法DIV、文献[17]提出的基于推荐期望的top-N推荐方法EBCF进行了比较。为了更好地验证本文所提算法的有效性,共进行了10组独立的实验, 对于每组实验, 首先从原数据集中随机选取10 000名用户的播放记录组成新的数据集, 然后利用新数据集在不同时刻共进行多次推荐, 将每个推荐时间点之前的播放记录组成训练集, 之后3小时内的播放记录组成测试集。每组数据分别利用上述4种算法进行了实验, 得到结果如图 3所示。

|
图 3 4种算法推荐结果准确率比较 Fig. 3 Comparison of accuracy of four algorithms |
由图 3(a)和图 3(b)可以看出, 本文提出的UCBCF算法在推荐结果准确度方面略低于传统IBCF算法, 但优于DIV算法和EBCF算法。综合4种算法分析可以发现, 多样性优化算法的推荐结果准确度普遍会略有降低, 这是由于为了获得更好的多样性, 优化算法可能会推荐一些评分较低的项目。值得强调的是, 日期靠后的推荐, 虽然有更多的历史数据作为参考, 但推荐结果的准确度并没有提升, 这说明过于久远的历史数据对于未来的预测贡献较低, 甚至会有负面影响,也从另一角度验证了本文根据用户内部情境提高近期历史数据权重的合理性。
图 4是4种算法推荐结果个体多样性的比较。图 4(a)和图 4(b)的结果显示, UCBCF算法在推荐结果个体多样性方面仅次于EBCF算法。这是由于EBCF算法调整了候选项目被推荐的概率, 使每个项目被推荐的可能性尽量一致, 以此大大提升了推荐结果的个体多样性,但这样做的负面影响也是显而易见的。图 5是4种算法推荐结果整体多样性的比较,从图 5(a)和图 5(b)可以看出, EBCF算法的整体多样性表现较差, 而本文的UCBCF算法在此方面的结果尚可接受。

|
图 4 4种算法推荐结果个体多样性比较 Fig. 4 Comparison of individual diversity of four algorithms |

|
图 5 4种算法推荐结果整体多样性比较 Fig. 5 Comparison of aggregate diversity |
随着推荐列表长度的变化,4种算法推荐结果个体多样性和整体多样性均会出现相应的变化。这是因为, 推荐列表长度增加, 更多相似度较低的项目会出现在同一推荐列表中, 个体多样性因此提高。同时, 同一商品出现在不同推荐列表中的概率增大, 整体多样性因此降低。
综合图 3、图 4、图 5的结果, 本文提出的UCBCF算法在推荐结果的准确度、个体多样性和整体多样性方面都有较好的表现。
图 6是4种算法推荐结果时序多样性的比较,图 6的结果显示, 本文提出的UCBCF算法在推荐结果的时序多样性方面远远优于传统IBCF算法、DIV算法和EBCF算法。因为在生成推荐列表时, UCBCF算法考虑了用户当时所处的内部情境和外部情境, 动态为用户历史记录和候选推荐项目赋予权值, 在评分预测阶段和推荐生成阶段进行干预。正如本文第二节分析, 用户情境是变化的, 基于用户情境得到的推荐结果具有了更好的时序多样性。而IBCF算法、DIV算法和EBCF算法生成的推荐列表相对静态, 变化较小, 因此时序多样性较差。

|
图 6 4种算法推荐结果时序多样性比较 Fig. 6 Comparison of timing diversity of four algorithms |
本文提出了一种基于用户情境的协同过滤推荐结果时序多样性优化算法, 目标是增强推荐系统的时序多样性, 使用户每次可以获得不同的推荐列表, 而且推荐结果符合用户所处情境。本文的算法以传统基于项目的算法为基础, 在评分预测阶段考虑用户的内部情境, 对评分进行加权, 之后在推荐前参考用户所处外部情境, 对推荐列表进行重排。在真实阿里音乐流行趋势预测数据集上的实验结果表明, 本文的算法在保证推荐准确率的条件下, 能够大大提高推荐的时序多样性, 同时还具有理想的整体多样性和个体多样性。该算法适用于音乐、电影、新闻、书籍等类型项目的推荐, 尤其是移动端的推荐。
| [1] |
ADOMAVICIUS G, KWON Y O. Improving aggregate recommendation diversity using ranking-based techniques[J]. IEEE Transactions on Knowledge & Data Engineering, 2012, 24(5): 896-911. |
| [2] |
WU H, CUI X, HE J, et al. On improving aggregate recommendation diversity and novelty in folksonomy-based social systems[J]. Personal & Ubiquitous Computing, 2014, 18(8): 1855-1869. |
| [3] |
LIU H, BAI X, YANG Z, et al. Trust-aware recommendation for improving aggregate diversity[J]. New Review in Hypermedia & Multimedia, 2015, 21(3): 242-258. |
| [4] |
MCNEE S M, RIEDL J, KONSTAN J A. Being accurate is not enough: How accuracy metrics have hurt recommender systems[C]//CHI 06 Extended Abstracts on Human Factors in Computing Systems. ACM, 2006: 1097-1101. http://dl.acm.org/citation.cfm?id=1125659
|
| [5] |
HU R, PU P. Helping users perceive recommendation diversity[C]//Proceedings of the Workshop on Novelty and Diversity in Recommender Systems. New York: ACM, 2011: 43-50.
|
| [6] |
ZHOU T, KUSCSIK Z, LIU J G, et al. Solving the apparent diversity-accuracy dilemma of recommender systems[J]. Proceedings of the National Academy of Sciences, 2010, 107(10): 4511. DOI:10.1073/pnas.1000488107 |
| [7] |
叶锡君, 龚玥. 基于项目类别的协同过滤推荐算法多样性研究[J]. 计算机工程, 2015, 41(10): 42-46. |
| [8] |
ADOMAVICIUS G, KWON Y O. Optimization-based approaches for maximizing aggregate recommendation diversity[J]. Informs Journal on Computing, 2014, 26(2): 351-369. DOI:10.1287/ijoc.2013.0570 |
| [9] |
WU H, CUI X, HE J, et al. On improving aggregate recommendation diversity and novelty in folksonomy-based social systems[J]. Personal & Ubiquitous Computing, 2014, 18(8): 1855-1869. |
| [10] |
王森. 一种基于整体多样性增强的推荐算法[J]. 计算机工程与科学, 2016, 38(1): 183-187. DOI:10.3969/j.issn.1007-130X.2016.01.030 |
| [11] |
ZIEGLER C N, LAUSEN G. Making product recommendations more diverse[J]. Bulletin of the Technical Committee on Data Engineering, 2009, 32(4): 23-32. |
| [12] |
安维, 刘启华, 张李义. 个性化推荐系统的多样性研究进展[J]. 图书情报工作, 2013, 57(20): 127-135. DOI:10.7536/j.issn.0252-3116.2013.20.022 |
| [13] |
安德森. 长尾理论[M]. 北京: 中信出版社, 2012.
|
| [14] |
ADOMAVICIUS G, KWON Y O. Maximizing aggregate recommendation diversity: A graph-theoretic approach[C]//Proceedings of the Workshop on Novelty and Diversity in Recommender Systems. New York: ACM, 2011: 3-10.
|
| [15] |
ZHANG Y C, MEDO M, REN J, et al. Recommendation model based on opinion diffusion[J]. Epl, 2007, 80(6): 417-429. |
| [16] |
张富国, 徐升华. 基于信任的电子商务推荐多样性研究[J]. 情报学报, 2010, 29(2): 350-355. DOI:10.3772/j.issn.1000-0135.2010.02.021 |
| [17] |
刘慧婷, 岳可诚. 可提高多样性的基于推荐期望的top-N推荐方法[J]. 计算机科学, 2014, 41(7): 270-274. |