 2015, Vol. 31
2015, Vol. 31扩展功能
文章信息
- 潘勇, 赵佳乐, 徐志刚, 赵祥模
- PAN Yong, ZHAO Jia-le, XU Zhi-gang, ZHAO Xiang-mo
- 基于纹理特征的低照度环境下车牌定位与识别算法
- An Algorithm of License Plate Location and Recognition in Low Illuminance Environment Based on Texture Feature
- 公路交通科技, 2015, Vol. 31 (7): 140-148
- Journal of Highway and Transportation Research and Denelopment, 2015, Vol. 31 (7): 140-148
- 10.3969/j.issn.1002-0268.2015.07.022
-
文章历史
- 收稿日期:2014-3-11


2. 交通运输部公路科学研究院, 北京 100088
2. Research Institute of Highway, Ministry of Transport, Beijing 100088, China
智能交通系统(ITS)已经成为当前交通管理发展的主要方向,作为交通管理自动化的重要手段的车辆车牌识别(License Plate Recognition,LPR)技术应运而生,其任务是对汽车监控图像进行分析和处理,然后自动识别出图像中包含的汽车牌号,并进行相关数据库管理。LPR系统可以被广泛应用于各种需要车牌认证的重要场合,如电子收费站、停车场车辆管理等。
车辆车牌识别技术主要是采用计算机图像处理技术对车牌的图像进行提取,自动分割字符,进而对字符进行识别,运用图像处理、模式识别等技术,对采集的汽车图像进行预处理,从而使计算机能够快速准确地自动识别出车牌上的各种字符。但是由于现场环境的复杂性,如光照、遮挡物等造成的干扰,使得现在的系统几乎都无法有效解决复杂背景下的车牌定位与有效识别,从而对所处理的图像造成误识别。因此只有不断地创新和提高LPR系统才能满足现实需求,从而使交通系统功能越来越完善,交通将变得更加便利、通畅。
为了能更好在图像中定位车牌,国内外学者提出了许多方法,目前车牌定位的算法主要有:(1)J.Barroso提出的基于扫描行高频分析的方法[1];(2) R.Parisi等提出的基于DFT变换的频域分析方法[2];(3) Char.Coetzee提出的基于Niblack二值化算法及自适应边界搜索算法的定位方法[3];(4)J.Bulas Cruz等人曾提出基于扫描行的车牌提取方法[4];(5)自动扫描识别算法[5];(6)基于特征的车辆牌照定位算法[6];(7)基于灰度纹理分析的车牌定位算法[7]。这些算法都是基于车牌的特征来研究车牌的定位与识别,因而具有一定的针对性和局限性,比如车牌图像的倾斜、车牌表面的污秽和磨损、光线的干扰等都是影响定位准确度的潜在因素。为了解决图像恶化的问题,目前国内外采用主动红外照明摄像或使用特殊的传感器来提高图像的质量,继而提高识别率,但系统的投资成本过大,不适合普遍的推广。
本文在前人研究的基础上深入分析低照度环境下车牌图像特征的基础上,提出了一种低照度环境下的车牌识别算法。
1 基于背景差的常规定位算法本文采用背景差法进行对比试验,该算法首先对灰度图像I进行开运算,将图像上的字符及边缘等特征去除得到图像A。然后用图像I减去开运算得到的结果图像A,将得到一张对滤波不敏感的区域被剔除和高频区域(包括车牌数字)明显的图像C。在结构元素B下的开运算定义如下:
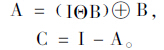
车牌图像的形态学处理效果图见图 1。

|
| 图 1 车牌图像的形态学处理结果 Fig. 1orphological processing result of license plate image |
以上处理结果显示车牌区域异常突出,然后根据字符连通域特征定位车牌区域。该方法要求字符纹理清晰,图片亮度高。对于低照度的图像该定位方法定位结果如图 2所示。

|
| 图 2 定位操作失败图 Fig. 2Failed location operation |
由于照度较低,车牌区域在二值化过程中丢失。常规算法还有基于车牌形状、颜色、边缘等特征进行提取的方法,但是当照度较低时车牌区域上述特征已经不足以区分车牌区域,故本文提出了一种基于纹理特征的低照度环境下车牌定位与识别算法。
2 基于纹理特征的车牌定位 2.1 低照度环境下车牌图像特征分析低照度环境下的车牌图像照度较低,且照度不均匀,车牌区域位于图像中照度较低的区域,通过寻找车牌的形状特征已经无法从这种图像中提取到车牌区域。
通过对大量低照度环境下车牌图像的研究发现,由于车牌内存在多个字符,基本呈水平排列,车牌内字符之间的间隔比较均匀,字符和牌照底色在灰度值上存在跳变,而字符本身与牌照底的内部都有较均匀灰度,因此车牌区域在水平方向上存在非常明显的灰度跳变特征。
实际拍摄到的汽车图像来看,图像本身也有一些特征,这些特征归纳如下:从汽车图像本身的纹理分布来看,整个图像中纹理比较密集的地方是车灯、散热器和车牌。车灯和散热器大部分是水平纹理,但是近年来随着车型的不断增加,散热器呈现垂直纹理的也很多。车牌区域则是由字符填充而成的,呈现出较为均匀的垂直纹理,并且分布较为紧凑。而车体则多呈现出水平纹理,虽然存在少数垂直纹理但其分布较为分散。
本文算法实现的流程图如图 3所示。

|
| 图 3 实现流程图 Fig. 3Flowchart of implementation |
车牌内存在多个字符,基本呈水平排列,车牌内字符之间的间隔比较均匀,字符和牌照底色在灰度值上存在跳变,利用这一特性,扫描图像的每行并标示灰度跳变密集的区域,将该区域作为车牌区域的候选区域。
以线段L作为扫描模板,设其始端点为(i,j),末端点为(i,j + n),则可以表示为Li(j,j + n)(i表示图像的行,j表示图像的列,n根据经验取值为150),选取区域的2个特征:
(1)该区域灰度跳变的频率f(Li) ,即其像素灰度值在该区域内所有像素的灰度平均值M(Li)上下波动的次数。
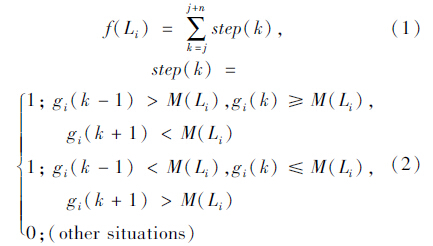
(2)区域内所有像素的灰度值与M(Li)差的绝对值之和SAD(Li)。
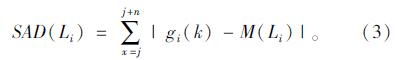
在扫描过程中标记满足SAD(Li)>500且f(Li)>15条件的最大的f(Li)为F(Li),当扫描结束后如若F(Li)不为零,则认为F(Li)对应的区域为疑似车牌区域将其标记为白色。
按照上述方法处理结束后图像中的高频区域将被标示出来,因为车牌区域属高频区域,所以车牌区域为标示线的密集区域。将密集区域提取出来作为候选区域。然后再对候选区域进行筛选,进而确定车牌区域,定位结果见图 4。伪代码如下:
设置滑块长度为150;for 图像的每一行
for 图像的宽度;滑块每次移动偏移20个像素
计算滑块内像素的灰度平均值M;
计算滑块内每一像素灰度值g与M的差的绝对值的和SAD;
计算滑块内像素值g在其灰度平均值上下波动的次数f(j);
if f(j)>15且SAD>500且f(j)>最大值F
令f(j) 为最大值F;
循环结束:if F大于0;则将F对应的区域标示为白色。

|
| 图 4 基于纹理的低照度车牌定位算法与背景差法定位结果的对比 Fig. 4Contrast of license plate location results obtained from location algorithm in low illuminance environment and background difference method based on texture feature |
图 4(d)为采用背景差法对低照度下的车牌图片进行定位的结果,从结果中可以明显看出定位失败,这是由于车牌处于图像的较暗的区域,在采用常规算法进行定位过程中,车牌区域被进一步地削弱,导致定位失败。
2.3 车牌的精确定位提取到的候选区域的面积已经很小,可以视为该图像的亮度均匀,因此可以进行形态学处理[8],采用背景差法[9]对其进行精确定位,将候选车牌区域视为基础图像对其进行定位,以进一步确定车牌区域。但是由于图像较暗,形态学处理以后噪声影响增大,有些字符出现断裂的情况,为了加强字符区域,本文采用了连通域的加强处理,即提取出图像中连通域及连通区域外接矩形,然后将每个连通域的外接矩形用白色像素填满。然后去除连通域面积较小的区域[10],进而将图像进行水平与竖直方向上的投影,由于字符区域具有规则的排列顺序,可以很容易地确定字符的区域,进而进一步缩小并确定车牌区域,处理过程的效果如图 5所示。

|
| 图 5 精确定位过程 Fig. 5Accurate location process |
理想情况下希望得到的车牌图像是一个矩形,但是在实际应用中拍摄的车牌图像大都会有一定的倾斜变形,如果不进行倾斜矫正,就直接进行字符分割工作,将严重影响字符的准确分割,造成误分割和车牌识别率的下降。因此需要在字符分割之前对车牌进行倾斜校正。本文使用了一种基于 Radon 变换的车牌倾斜校正[10]的方法。
真实的车牌是矩形,镶嵌有金属边框,可认为是由4条直线围成的矩形区域。由于拍摄角度的原因,图像中的车牌会发生变形,往往不再是矩形,可能是平行四边形或者是普通的四边形。一般来说车牌的倾斜角度不大,所以车牌变形程度较小,可以看作是近似矩形。在此前提下,将原来的XY平面内的点映射到AB平面上。则原来在XY平面上的一条直线的所有的点,在AB平面上都位于同一个点。通过记录下AB平面上的点的积累厚度,可反知XY面上的一条线的存在。在新平面下得到相应的点积累的峰值,可得出原平面的显著的线集,进而确定倾斜角度。本文选取Radon 变换在θ=-90°~90°之间进行变换。分别求车牌二值图像在Y轴上的投影。然后对投影结果进行筛选,找出其中投影区域最小并且投影点最集中的结果。其对应的旋转角度则为车牌偏转角度,然后对车牌图像进行旋转。图 6为车牌图像投影的集合,竖直方向上每条支线分别代表车牌图像在该角度线的一次投影,图像中像素点灰度值越大说明此处累计的白点越多。寻找其中平均亮度最高的一个角度的投影,则认为该情况下车牌区域刚好与投影面垂直并且认为该角度为偏转角度。

|
| 图 6 Radon投影图像 Fig. 6Radon projected image |
Radon变换原车牌图像在-90°~90°之间变换时在Y轴上的投影,根据图像求得偏转角对图像进行反向旋转。结果如图 7所示。

|
| 图 7 矫正后的图像 Fig. 7Corrected image |
本文结合图像的垂直投影与车牌的先验信息对车牌图像进行字符分割[11,12,13]。

|
| 图 8 车牌图像投影 Fig. 8License plate image projection |
(1)对预处理以后的车牌图像进行垂直方向上的投影,并取出每个投影区域的起始位置将其存到容器中,同时根据车牌的比例大概计算出车牌上字符的可能宽度W。
(2)结合先验信息可知车牌上第2个字符与第3个字符之间存在一个较大的间隙,根据此能找到该间隙的具体位置,如果失败则说明该图片不是车牌图像分割失败。
(3)根据找到的第2个字符与第3个字符之间空隙的位置就能很容易进行车牌字符的分割,根据该空隙的位置首先分隔第2个字符,获取该空隙前面一个投影区域,然后将该投影区域的宽度tw与估计出来的字符宽度W进行比较:
①如果0.8W≤tw≤1.3W则说明该区域刚好符合一个字符的区域,则直接对其进行分割;
②如果1.3W<tw≤1.5W则说明该区域比一个字符区域略大,该字符被左右的连通区域干扰,然后将该区域用本文的分割函数SegmenteChar进行分割提取出其中的字符;
③如果1.5W<tw则说明该区域与第1个字符区域合并成了一个区域,则对其分割出前2个字符;
④如果tw<0.8W则说明该区域过窄,可能是字符断裂所致,将该区域向前合并一个区域然后重复如上判断,每得到一个字符,都需要对估计的字符宽度进行调整,调整公式为:
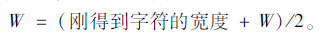
(4)根据提取第2个字符的情况与方法,很容易提取到第1字符。
(5)前2个字符提取成功以后继续对后5个字符进行提取,从第3个投影区域开始向后依次提取出5个字符然后停止,判断规则如下:
①如果tw<0.8W则说明该区域过窄,可能是字符断裂所致,然后判断该区域与后一个区域的距离小于0.5W以及后一个区域宽度也小于0.8W则说明这2个区域是同一个字符然后将其合并,进行分割;如果不是则只分割第1个区域;
②如果0.8W≤tw≤1.3W则说明该区域刚好符合一个字符的区域,则直接对其进行分割;
③如果1.3W<tw≤1.8W则说明该区域受噪声影响,导致其区域过宽,然后调用分割函数SegmenteChar进行分割并提取出其中的字符;
④如果1.8W<tw≤2.8W则说明该区域是2个字符合并为1个,然后调用分割函数SegmenteChar进行分割并提取出其中的字符;
⑤如果2.8W<tw≤4.5W则说明该区域是3个字符合并为1个,然后调用分割函数SegmenteChar进行分割并提取出其中的字符;
⑥如果4.5W<tw≤6W则说明该区域是4个字符合并为1个,然后调用分割函数SegmenteChar进行分割并提取出其中的字符;
⑦如果6W≤tw则说明该区域是5个字符合并为1个,然后调用分割函数SegmenteChar进行分割并提取出其中的字符;
分割函数SegmenteChar实现如下:在前面投影区域提取的时候本文分别采用2种不同的阈值进行提取,一种是低阈值,一种是高阈值。低阈值是为了将投影区域尽可能的提取出来,但是细微的噪声将导致投影区域连接到一起,所以这种情况出现的时候就需要通过高阈值提取的区域进行分割。
SegmenteChar (int left,int right,int point,int length,int W)。
该函数就是对存在粘连的区域将其中的字符提取出来,该函数是递归函数,当是多个字符粘连的时候,提取出一个字符以后,再次调用一次该函数进行提取直到提取完毕。该函数的主要思想是,寻找粘连区域所对应的高阈值投影区域,若存在则说明是粘连部分中的字符区域,如若不存在则说明该区域为噪声区域。若存在的高阈值投影区域刚好符合一个字符宽度则直接分割;若过宽则说明粘连比较严重,直接从该区域左边界开始截取一个字符的区域作为该字符;若过窄则对其进行合并操作,对距离其较近的区域进行合并。若不存在则该字符可能是L,J,T(由于阈值过大导致其投影区域只剩余中间的竖线),则利用竖线的位置信息来判断其具体是什么字符然后进行分割,当竖线位置偏左则为L,偏右则为J,在中间位置则为T。
以上描述为字符分割的大致步骤,效果图如图 9所示。

|
| 图 9 字符分割图像 Fig. 9Images of segmented characters |
当分割完毕后根据得到的W将同一张车牌上的字符调整到同一宽度方便于后边的字符识别,调整方法为:如果分割的图像宽度大于W则对其进行裁剪,如果小于W则扩张图像宽度,扩张的部分用黑色像素填充。效果如图 10所示。

|
| 图 10 调整字符图像大小 Fig. 10Image size adjustment |
本文主要采用模版匹配[14]的方法进行识别,将预先设计好的标准字符模板存储在计算机中,然后用待识别字符与标准模板进行逻辑‘异或’运算,但由于汉字的结构复杂,单纯地使用模板匹配的方法识别结果较差,所以本文在模板匹配的基础上结合使用连通域特征对该方法进行了改进。
3.1 汉字的识别基于字符连通域特征的汉字识别[15],主要利用字符图像的连通域特征进行识别。设有r×q的待识别字符矩阵X和标准字符模板 A,X和A的背景色像素值均为0,前景色像素值为均1。对X和A作数量乘法(X和A的对应元素相乘),得到数字点阵I,即I=X*A。这样做的实质上是得到了2个汉字字符重叠的部分。统计I中白色像素点的个数n1 和八连通域的个数d1。再统计A中白色像素点的个数n2的八连通域的个数d2,计算I和A的连通域数目的绝对值d及I和A的白色像素点的比值μ(相似度),如公式(4):
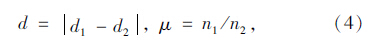

|
| 图 11 字符重叠的部分 Fig. 11Characters overlap |
以“宁”字为待识别字符为例:“云”字的连通域数目为2,“辽”字的连通域数目为3,“宁”、“云”的重叠部分的连通域是3个,“宁”、“辽”的重叠部分的连通域是8个,“云”字的白色像素点共有2 760个,“辽”字的白色像素点共有3 382个,“宁”、“云”的重叠部分共有白色像素点404个,“宁”、“辽”的重叠部分共有白色像素点861个。由此可得“宁”相对于“云”的连通域特征:
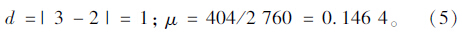
同理可得“宁”相对于“辽”的连通域特征d=5,相似度特征μ=0.254 6,分析一下在何种情况下能使得d取得最小值且μ取得最大值。很容易可以知道,若X中包含的汉字字符恰好是A中的汉字字符的话,则d 和μ必定能同时取得最小值和最大值,且有d= 0,μ= 1。由此,可以做出如下2个假设:
(1)在标准汉字字符模板列表L中,若L中的某个元素A为待识别字符X的正确识别,则d取得最小值;
(2)在标准汉字字符模板列表L中,若L中的某个元素A为待识别字符X的正确识别,则μ取得最大值;
综上所述,若将假设(1)和假设(2)结合起来,将待识别字符矩阵X和标准汉字字符列表L中的各个标准汉字字符矩阵进行比较,则有很大几率能找到X代表的汉字所对应的标准汉字字符矩阵L(i)。这实际上也就完成了对X的识别。应用上述原理识别汉字字符X算法如下:
(1)作标准汉字字符模板列表L,计算X相对于L(1)的连通域特征值D0和相似度特征值U0,既:D0=D[X,L(1)],U0=U[X,L(1)],i=1, 字符识别结果char为L(1)所代表的汉字;
(2)i增加1;
(3)计算X相对于L(i)的连通域特征值和相似度特征值:
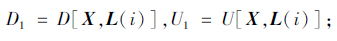
(4)若D1<D0,则令U0=U1,D0=D1,并取char为L(i)所代表的汉字;
(5)若D1=D0并且U1=U0,则令U0=U1,并取char为L(i)所代表的汉字;
(6)判断 L(i)是否为列表L的最后一个元素。若是,结束识别过程,否则,转到2。
识别结果见表 1。
| 待识别字符/个 | 正确识别/个 | 错误识别/个 | 正确率/% | 错误率/% |
| 148 | 142 | 6 | 95.93 | 4.07 |
该部分中主要利用模板匹配的方法对字母以及数字字符图像进行识别[16]。在字符二值图像中,白色部分的标识为1,黑色部分的标识为0。即字符笔画所在位置的标识为1。逻辑“异或”运算的规则为:
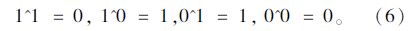
将其转变为图像颜色的关系即为:

而字符图像中白色位置正好是字符笔画所在的位置。因此,待识别的字符图像与标准字符模板图像差异越小,进行“异或”运算以后得到的图像中白色像素点的个数就会越少;而待识别的字符图像与标准字符模板图像差异越大,进行“异或”运算以后得到的图像中白色像素点的个数就会越多。因此将待识别字符图像与每一副标准字符模板图像进行“异或”运算,并计算其得到的图像中白色像素点的个数,取其中白色像素点最少的模板图像,说明待识别字符图像与其最为相似,则认为该模板为识别结果。这一过程的对比图像如图 12所示。

|
| 图 12 字符图像进行逻辑运算(异或)的效果 Fig. 12Effect of logic operation (xor) for character images |
其中,图a~图f这6幅图像中最左侧为待识别字符图像,中间为标准字符模板图像,右侧为进行逻辑‘异或’运算后得到的图像。通过上图中图像的对比,可以很直观的看出文中模板匹配的原理。测试匹配结果见表 2。
| 待识别字符/个 | 正确识别/个 | 错误识别/个 | 正确率/ % | 错误率/ % |
| 902 | 843 | 59 | 93.39 | 6.61 |
为了确定算法的准确性以及鲁棒性,本文随机采取了157张道路车辆图片对本文算法进行测试,经过测试发现本文的算法定位的准确性为97.46%。测试图像中大部分的图像都得到了准确的定位结果,说明本文算法确实可行并准确度较高。其中4张图像由于亮度极低,导致纹理不够清晰所以定位失败,本算法有待提高,将在后续的研究中进行进一步的完善与改进。定位成功率见表 3,图 13为本文算法与背景差法对比测试结果。

|
| 图 13 本文算法与背景差法对比测试结果 Fig. 13Comparative test result of proposed algorithm and background difference method |
(1)本文提出的基于纹理的车牌定位算法,在低照度环境下,其定位准确率要明显优于传统的背景差法。
(2)根据图像垂直投影特征以及车牌的先验信息可对车牌的字符进行精确的分割。
(3)根据汉字和数字字母各自的特点选择不同的模板进行匹配,可以提高字符识别率。
(4)本文对157张低照度条件下的车牌抓拍图像进行了算法测试,车牌定位准确率达97.46%,字符分割准确率达97.10%,字符识别准确率达94.71%,能满足实际工程需求。
| [1] | BARROSO J, DAGLESS E L, RAFAEL A, et al. Number Plate Reading Using Computer Vision[C]// Proceedings of the IEEE International Symposium on Industrial Electronics, 1997. ISIE'97. Guimaraes: IEEE, 1997:761-766. |
| [2] | PARISI R, DI CLAUDIO E D, LUCARELLI G, et al. Car Plate Recognition by Neural Networks and Image Processing[C] // Proceedings of the 1998 IEEE International Symposium on Circuits and Systems, 1998. ISCAS'98. Monterey, CA: IEEE, 1998:195-198. |
| [3] | COETZEE C, BOTHA C, WEBER D. PC Based Number Plate Recognition System[C]// Proceedings of IEEE International Symposium on Industrial Electronics, 1998, ISIE'98. Pretoria: IEEE, 1998:605-610. |
| [4] | BARROSO J,BULAS-CRUZ J,DAGLESS E L.Real-time Number Plate Reading[C] //4th IFAC Workshop on Algorithms and Architectures for Real-time Control. Vilamoura, Portugal: AARTC,1997:70-73. |
| [5] | 刘效静,成瑜.汽车牌照自动识别技术研究[J].南京航空航天大学学报,1998,30(5):573-577. LIU Xiao-jing,CHENG Yu. Research on Automatic Recognition of Car License Plate[J]. Journal of Nanjing University of Aeronautics & Astronautics, 1998,30(5):573-577. |
| [6] | 牛欣,沈兰荪.基于特征的车辆牌照定位算法[J].交通与计算机,2000,18(1):31-33. NIU Xin,SHEN Lan-sun. A Method of Car License Plate Location Based on Feature [J].Computer And Communications,2000,18(1):31-33. |
| [7] | 刘智勇,刘迎建.车牌识别(LPR)中的图像提取及分割[J].中文信息学报,2000,14(4):29-34. LIU Zhi-yong, LIU Ying-jian. Image Extraction and Segmentation in License Plate Recognition [J].Journal of Chinese Information Processing,2000,14(4):29-34. |
| [8] | 周律,汪亮,周昱明,等.基于固定颜色搭配搜索和形态学的车牌定位[J].公路交通科技,2013,30(5):118-125. ZHOU Lü, WANG Liang, ZHOU Yu-ming,et al. License Plate Location Based on Fixed Color Assortment Search and Morphology[J].Journal of Highway and Transportation Research and Development, 2013,30(5):118-125. |
| [9] | FRANCESCA O. Experiments on a License Plate Recognition System,DISI-TR-06-17[R]. Genoa: University of Genova, 2007. |
| [10] | 蒋治华,陈继荣,王卫.一种非传统车牌倾斜矫正方法[J].计算机应用研究, 2006,23(3):175-177. JIANG Zhi-hua, CHEN Ji-rong, WANG Wei. A Non-traditional Deflection-rectify Algorithm for LPR[J].Application Research of Computers, 2006,23(3):175-177. |
| [11] | 翟伟芳.具有倾斜矫正功能的车牌定位和字符分割算法研究[D].天津:河北工业大学,2007. ZHAI Wei-fang. Research on Car License Location and Character Division Which Has Adjustment Function for Inclines[D]. Tianjin: Hebei University of Technology, 2007. |
| [12] | 谢伟生.车牌定位及字符分割算法的研究与实现[D].成都:西南交通大学,2010. XIE Wei-sheng. Research and Implementation on Algorithms of License Plate Location and Character Segmentation [D].Chengdu: Southwest Jiaotong University, 2010. |
| [13] | 贾震斌.基于图像分析的汽车牌照定位和字符分割算法研究与实现[D].苏州:苏州大学,2006. JIA Zhen-bin. Research and Implementation of Vehicle License Plate Positioning & Characters Segmentation Algorithm Based on Image Analysis [D].Suzhou: Soochow University, 2006. |
| [14] | 谷秋頔.基于模板匹配的车牌字符识别及其判别函数的研究[D].太原:中北大学,2012. GU Qiu-di. Research of License Plate Character Recognition and Discriminant Function Based on Template Matching[D]. Taiyuan: North University of China, 2012. |
| [15] | 孟庆远.车牌识别系统中字符识别技术研究[D].太原:中北大学,2011. MENG Qing-yuan. Research on Character Recognition Technology in Vehicle License Plate Recognition System [D]. Taiyuan: North University of China, 2011. |
| [16] | 邢博,梁德群,李文举.一种新的车牌数字及字母字符识别方法[J].辽宁师范大学学报:自然科学版,2005,28(1):55-58. XING Bo, LIANG De-qun, LI Wen-ju. A New Method for Number and Letter Character Recognition of License Plate [J]. Journal of Liaoning Normal University:Natural Science Edition, 2005,28(1):56-58. |