 2021, Vol. 38
2021, Vol. 38扩展功能
文章信息
- 李炳林
- LI Bing-lin
- 基于深度学习的应急装备物资车辆检测跟踪算法研究
- Study on Emergency Vehicle Detection and Tracking Algorithm Based on Deep Learning
- 公路交通科技, 2021, 38(11): 142-149
- Journal of Highway and Transportation Research and Denelopment, 2021, 38(11): 142-149
- 10.3969/j.issn.1002-0268.2021.11.017
-
文章历史
- 收稿日期: 2021-05-21


车辆的实时轨迹跟踪研究是智能交通领域的热点问题。目前,众多学者对车辆跟踪任务展开了深入的研究,然而针对应急装备车辆的跟踪研究较为缺乏。应急装备物资车辆为公路突发事件应急救援等场景提供重要的装备物资保障,扮演着重要的角色。作为公路交通应急处置的关键要素,应急装备物资车辆的实时轨迹跟踪对保障公路应急装备物资及时到位,及时恢复公路交通正常运行具有重要意义。
对于目标追踪任务而言,目前主流的方法一般先采用目标检测算法,检测出目标,然后利用追踪算法对目标进行跟踪。
对车辆进行有效检测是车辆跟踪的基础,传统的目标检测方法有背景差分法、帧差法和光流法[1]。背景差分法是将当前帧图像与背景帧或者是背景更新模型进行做差来得到提取前景对象的方法。但是在实际应用当中,很难获取到背景帧图像,所以出现了许多基于背景更新算法的背景差分法。帧差法对连续两帧或是连续多帧视频序列做差,根据做差之后得到的图像的灰度值来得到运动目标。光流法通过视频图像相邻帧中各个像素点的亮度值,利用灰度的变化信息和变化程度得到光流场,从而得到目标的运动场。光流法[2]利用的是图像中像素强度数据的时域变化和相关性,来进一步确定各个像素点的运动。与背景差分法和帧差法不同,光流法不仅展现灰度在时间上的变化,还可以展示目标的外形,结构与运动状态的关系,但计算困难,耗时较长。传统的目标检测算法,在检测时间和精度上均有较大的不知之处。
近年来,基于深度学习的目标检测算法受到了越来越多学者的关注,该算法可以分为一阶段(One-stage)和两阶段(Two-stage)检测算法2类,Two-stage算法以Fast-RCNN[3]、Faster-RCNN[4]为代表,该类算法分为2个部分,先通过算法生成一系列的候选框,然后再进行分类任务。而One-stage算法不需要生成候选框,可以直接得出检测目标的位置和类别信息,代表算法有YOLO[5]系列、SSD[6]等。因此相较于Two-stage算法而言,One-stage算法检测速度,实时性高,更适合本文的研究对象。
利用视频对道路上的应急装备车辆进行跟踪对实时性要求较高,而目标跟踪算法的速度在很大程度上取决于检测算法的性能,基于深度学习的单阶段目标检测算法YOLO系列速度精度权衡最好,学者对该系列算法的改进也有很多,吕石磊等人[7]使用轻量级骨干网络MobileNet-v2对YOLOv3进行改进,提高模型在CPU端推理速度,但是模型的识别精度略有下降;李继辉[8]将CBAM注意力机制引入YOLOv3网络中,同时使用剪枝量化手段使算法在嵌入式开发板NVIDIA TX2上达到了24FPS接近实时的处理速度;周方禹[9]将SE注意力机制和双向金字塔特征融合机制引入目标检测网络,在PASCAL VOC 2007/2012等公开数据集和安全帽私有数据集验证了改进模型的有效性。刘学平[10]结合K-means聚类与粒子群优化算法进行锚框计算, 在YOLOV3网络shortcut层嵌入SENet结构, 得到SE-YOLOV3网络,用于算法训练和测试。试验结果表明,SE-YOLOV3能有效减少假正例数量。许小伟[11]提出了一种小型化的改进YOLOv3深度卷积网络的实时车辆检测及跟踪算法,研究表明该小型化网络检测跟踪算法在复杂道路环境中有较强的鲁棒性,可以满足实际智能驾驶过程中对车辆检测跟踪的精度、速度的要求。
在目标跟踪算法方面,Alex Bewley等人[12]简单结合了卡尔曼滤波和匈牙利算法实现了实时性好,精度高的SORT在线追踪算法,相比同时期SOTA追踪器(MDP[13]、MHT-DAM[14])快20倍左右,缺点是ID切换比较严重;在SORT基础上提出的DEEP SORT算法[15],将重识别模型融入外观特征,增加级联匹配机制,改进算法能够克服跟踪过程中更长的时间的遮挡,有效地减少ID切换的数量[16]。王春艳[17]提出引用深度外观特征的在线分层数据关联跟踪算法;刘沛鑫[18]提出网络流数据关联求解算法,将长短时记忆网络和条件随机场引入数据关联模型,有效关联跨视角行人跟踪轨迹片段。
本文的研究对象为应急装备物资车辆,除带有明显的标志(如红十字)外,和普通货车没有较大的区别。为了更好地明确应急装备物资车辆,本研究主要在以下2个场景进行应急装备物资车辆的识别研究:(1)应急区域;(2)根据应急车辆的北斗数据,协调调度途经道路的摄像机,然后利用采集来的视频图像进行识别和跟踪应急车辆。
基于以上分析,本研究主要针对应急装备物资车辆检测跟踪进行方法探究,利用道路监控视频和航拍视频制作应急装备物资车辆图像样本库,并制作训练数据集。采用YOLOv3算法检测运动的应急装备物资车辆,通过增加网络的检测层,改进网络结构,提高模型的检测性能,使用Deep Sort跟踪方法进行车辆跟踪,在图像上画出跟踪车辆的运动轨迹,并对车辆进行计数,实现了对应急装备物资车辆的检测跟踪。
1 基于改进YOLOv3算法的应急装备物资车辆检测研究 1.1 检测流程与传统的图像识别方法相比,深度学习的网络模型能够自动地从原始图像中学习到检测对象的图像特征信息,进而完成后续的分类和识别任务,相比于传统的图像识别方法有更好的表现。基于深度学习的应急装备物资车辆的检测流程如图 1所示。

|
| 图 1 检测流程 Fig. 1 Detection process |
| |
1.2 改进的YOLOv3算法
YOLO(You Only Look Once)是一种基于深度神经网络的一阶段目标检测算法,其最大的特点是在保证较高精度的同时,检测速度很快,可以用于实时系统。该算法在检测过程中将图像分为S×S个格子(本文S×S为13×13、26×26、52×52这3种尺度),每个单元格负责检测中心点落于此单元格的对象,每个单元格需要预测出3个边界框,每个边界框会预测出5个结果(x,y,w,h,conf)。x,y分别为目标框中心坐标值,w,h表示边界框的长和宽,conf表示框中含有目标的置信度。YOLOv3采用残差网络结构,在原有YOLOv2[19]主干特征提取网络Darknet19的基础上,通过添加3×3和1×1的卷积和残差构成了一个有53个卷积层特征提取网络。算法在骨干特征提取网络后面添加FPN[20]网络(Feature Pyramid Networks),对输入图像进行多尺度的检测,输出3个不同的尺度的特征图,这使得YOLOv3算法相较于前2个版本的检测效果有了显著的提升。
由于本研究的研究对象为视频中的应急装备物资车辆,该车辆在视频中多为小目标,为了提高YOLOv3目标检测网络对于小目标的检测能力,本研究在YOLOv3网络原有的3个检测层基础上,增加第4个检测层,用来提高模型对小目标的检测性能。
随着网络深度的增加,模型可以提取更多图像的全局信息,但是这样会导致小目标物体的语义信息丢失,对小目标检测精度会下降。原始的YOLOv3网络采用特征金字塔结构,融合不同尺度大小的特征图。
在原有的检测层基础上,对52×52的输出特征图进行上采样,并与骨干特征提取网络Darknet53中104×104的特征图进行融合,作为第4个检测层。改进后的YOLOv3网络结构如图 2所示,图 2中实线部分为原始的网络结构,虚线为新添加的检测层。

|
| 图 2 改进后的YOLOv3网络结构图 Fig. 2 Improved network structure diagram of YOLOv3 |
| |
1.3 试验结果
将改进前后的网络进行在相同的数据集情况下,进行对比试验,试验的对比结果如表 1所示,表中的mAP为目标检测任务中常用的评价指标,表示模型的检测精度,mAP越大代表模型整体检测精度高。通过表 1可以发现通过在原网络结构中添加第4个小目标检测层,有效地提高了模型对小目标的检测性能,检测精度得到提升,相比于基础的YOLOv3网络mAP增加了3.81%。
2 基于Deep Sort的应急装备物资车辆跟踪算法
(1) 目标的特征提取
在实现目标跟踪之前,一般分为3步:首先需要识别目标,即在跟踪初始化界面中的第1帧图像里找到要跟踪的前景对象,提取其特征。目标描述的方法直接决定了目标跟踪的准确性和实时性,而在做分类的时候,需要从特征入手,将目标提取后,检测其相似度。一个好的目标描述方法可以剔除噪声干扰,当车辆发生运动速度变化或者自身形态变化时,或者环境和光照发生变化时,数据属性的相关性由相关系数来描述,数据对象的相似保证即可,依然能够依据车辆目标的特征,准确的识别目标;最后一步才是特征的匹配跟踪。
(2) 特征点匹配策略
基于特征点的目标跟踪是在相邻帧之间进行特征点集的关联,特征点是由其本身以及周围邻域像素共同表征的灰度信息集合,并以此为依据,进行特征点的匹配。匹配过程的关键就是确定相似性度量准则。
目前,常用的相似性度量准则有很多,例如像素灰度绝对值差和(Sum of Absolute Differences,SAD)、归一化交叉相关(Normalized Cross Correlation,NCC)和像素灰度差平方和(Sum of Squared Differences,SSD)等。特征点匹配根据关联方式的不同,可分为确定性方法和基于统计的方法。最常用的是相似性度量,即评定样本特征与检测特征之间的关系,以及从图像中选取某些特征点并对图像进行局部分析。确定性方法先采用运动约束对目标和目标观测间的关联定义代价函数;还有距离度量,比如,马氏距离,以及欧式距离。
(3) Deep Sort跟踪算法原理
Deep Sort全称是Simple Online and Realtime Tracking。Deep SORT算法在实际应用中使用较为广泛,核心就是2个算法:卡尔曼滤波和匈牙利算法。在实现上较为简单,常用于先检测,后跟踪的结合。
卡尔曼滤波器在Deep SORT中的作用是进行前景对象状态的估计预测。状态指的是bbox(bbox存在待检测的目标对象)的相关参数,包括中心的位置、高度、纵横比等。卡尔曼滤波器可以预测更新轨迹。
Deep SORT在更新轨迹状态的时候还用到了马氏距离,计算公式是:
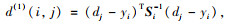
|
(1) |
式中, d(1)(i, j)为第i个目标预测框和第j个目标检测框匹配结果;Si表示轨迹由卡尔曼滤波器计算预测得到在当前帧观测得到的协方差矩阵; yi是轨迹在当前帧,或者说是当前时刻的预测量; dj是第j个detection的状态。这个detection的状态是由之前的检测算法得到的检测框。
匈牙利算法的作用是为了进行数据之间的关联,数据关联也是匹配的一个关键步骤。这里匈牙利算法使用cost矩阵进行detection之间的匹配。基于检测框位置和IOU的匈牙利算法,使得Deep Sort相对于Sort算法,在效率方面得到了进一步的加强。图 3为Deep Sort的算法流程。

|
| 图 3 Deep Sort算法流程图 Fig. 3 Flowchart of Deep Sort algorithm |
| |
图 3中的IOU称为交并比,是用来衡量模型检测出来的预测框和真实框之间的位置关系,表征检测物体位置的准确性。其计算公式如式2所示,它是预测框与真实框的交集和并集的比值。交集和并集如图 4所示,虚线表示预测框,实现表示真实框:

|
| 图 4 交/并集示意图 Fig. 4 Schematic diagram of intersection and union |
| |

|
(2) |
式中, S交指预测框与真实框交集的部分;S并指预测框与真实框并集的部分。
3 试验结果 3.1 试验环境搭建本研究中程序算法采用python3.6.7语言进行实现,在Visual Studio 2015开发平台上进行开发,试验环境为Tensorflow1.4.0,Opencv,Keras,sklearn等,Win8系统在CPU上进行试验。
3.2 模型训练(1) 图像库建立
为了增加跟踪模型的泛化能力,在建立图像库时,采用不同拍摄角度的视频,得到不同角度的应急物资装备车辆图像,提高了模型的检测性能。数据采集来源于青海省应急装备物资储备中心辐射区域相关路段的视频序列,隔帧抽取出5 293张图像作为图形样本库,用于训练应急装备物资车辆检测模型。标注方式如图 5所示,将目标车辆的位置和类别存储在文本文件中。

|
| 图 5 图像标注 Fig. 5 Image annotation |
| |
(2) 训练结果
采用SGD优化器,初始学习率设置为0.1,训练300轮结果如图 6所示。图 6(a)为模型训练过程中的损失曲线,loss代表模型训练的损失值,图 6(b)mAP、图 6(c)Precision和图 6(d)Recall分别代表模型随着迭代次数增加在测试集上的平均准确率、精度和召回率。

|
| 图 6 训练结果图 Fig. 6 Graphs of training result |
| |
由图 6(a)可以发现,模型在前20轮训练中,损失值下降较为迅速,模型在快速进行拟合,从第20到200轮,损失值下降在慢慢减缓,在训练迭代200后,损失值趋于稳定状态。准确率也在0.9以上,该模型达到了很好的检测效果。
3.3 试验验证(1) 场景选取
本次研究采用青海省应急装备物资储备中心辐射区域路段上应急装备物资车辆行驶场景的视频序列,进行视频检测,视频格式为MP4,帧速率为29帧/s,帧宽度为640,帧高度为368,试验场景如图 7所示。

|
| 图 7 试验环境 Fig. 7 Experimental environment |
| |
(2) 试验结果
① 应急装备物资车辆轨迹检测结果
通过YOLOv3算法对路段多个角度视频片段检测效果如图 6所示,结果显示,YOLOv3速度快,精度高,相对于传统的经典目标检测算法有很大的优势。
可以看到,在图 8(f)角度6中,由于车辆密集排布,可能出现漏检的情况。在其他角度检测结果都较好。

|
| 图 8 检测效果 Fig. 8 Test effect |
| |
② 车辆轨迹跟踪结果
在试验环境下验证跟踪情况,如图 9所示,用矩形框标记出被检测出的车辆,并进行持续的跟踪,本研究提出的模型可以实现多辆应急装备物资车辆跟踪并统计数量。

|
| 图 9 跟踪情况 Fig. 9 Target tracking |
| |
本研究选取4个路段各10 min视频,采用人工计数与算法跟踪结果进行对比,结果如表 2所示。
| 路段 | 人工统计 | 算法跟踪统计 | 误差/% |
| 路段1 | 1 042 | 1 091 | 4.70 |
| 路段2 | 973 | 1 021 | 4.93 |
| 路段3 | 1 326 | 1 340 | 1.06 |
| 路段4 | 539 | 553 | 2.60 |
对比试验结果可以看出,基于YOLOv3检测的Deep Sort算法跟踪精度高,计数统计误差在5%以内。误差产生原因是YOLOv3检测算法有可能将较大的普通车辆识别为应急车辆。
③ 轨迹提取
在Deep Sort的基础上进行应急装备物资车辆轨迹的提取,在图像中实现自动绘制出轨迹图像,结果如图 10所示。从基于检测的跟踪实验结果来看,在速度较快,光照变化较明显的情况下,YOLOv3与Deep Sort算法的结合在精度和速度上都达到了不错的效果。一般情况下,在车辆进出视频的时刻,框的大小会发生变化,形成轨迹误差。

|
| 图 10 轨迹提取效果 Fig. 10 Trajectory extraction effect |
| |
4 结论
本研究主要针对车辆检测和车辆跟踪2个部分进行了研究,在此基础上进行轨迹提取。主要工作如下:(1)增加YOLOv3算法的检测层,提高算法对小目标的检测性能。(2)通过对YOLO检测和Deep Sort进行了验证,确定了YOLOv3+Deep Sort结合的检测跟踪算法,在跟踪的基础上实现了绘制出车辆轨迹,并实现自动计数功能。(3)在VS2015集成开发环境下,主要采用Opencv库,基于Tensorflow和Keras框架用Python语言进行项目开发,完成了基于视频的应急装备物资车辆检测与跟踪系统,并在试验环境下进行测试,结果显示可以有效地检测与跟踪应急装备物资车辆,有一定的实用价值。
本研究收集到的图像数据有限,对实际应用场景有一定限制,后续将继续扩充图像库,进一步提升检测跟踪模型的精度和泛化能力。
| [1] |
梁娟. 视频序列中运动目标检测与跟踪算法研究[D]. 武汉: 中南民族大学, 2012. LIANG Juan. Research on Moving Object Detection and Tracking Algorithm in Video Sequence[D]. Wuhan: South-Central University for Nationalities, 2012. |
| [2] |
吴进, 董国豪, 李乔深. 基于区域卷积神经网络和光流法的目标跟踪[J]. 电讯技术, 2018, 58(1): 6-12. WU Jin, DONG Guo-hao, LI Qiao-shen. Object Tracking Based on Region Convolution Neural Network and Optical Flow Method[J]. Telecommunication Technology, 2018, 58(1): 6-12. |
| [3] |
GIRSHICK R. Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision (ICCV). Santiago: IEEE, 2015: 1440-1448.
|
| [4] |
REN S Q, HE K M, GIRSHICK R. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(6): 1137-1149. |
| [5] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: Unified, Real-time Object Detection: Computer Vision & Pattern Recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788.
|
| [6] |
LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single Shot MultiBox Detector[C]//European Conference on Computer Vision. Amsterdam: Springer, 2016: 21-37.
|
| [7] |
吕石磊, 卢思华, 李震, 等. 基于改进YOLOv3-LITE轻量级神经网络的柑橘识别方法[J]. 农业工程学报, 2019, 35(17): 205-214. LÜ Shi-lei, LU Si-hua, LI Zhen, et al. Orange Recognition Method Using Improved YOLOv3-LITE Lightweight Neural Network[J]. Transactions of the Chinese Society of Agricultural Engineering, 2019, 35(17): 205-214. |
| [8] |
李继辉. 多旋翼无人机的目标检测与自主避障研究[D]. 长春: 中国科学院大学(中国科学院长春光学精密机械与物理研究所), 2020. LI Ji-hui. Research on Target Detection and Autonomous Obstacle Avoidance of Multi-rotor UAV[D]. Changchun: University of Chinese Academy of Sciences (Changchun Institute of Optics, Fine Mechanics and Physics), 2020. |
| [9] |
周方禹. 基于改进的端到端卷积神经网络的目标检测算法研究[D]. 武汉: 湖北工业大学, 2020. ZHOU Fang-yu. Research on Target Detection Algorithm Based on Improved End-to-end Convolutional Neural Network[D]. Wuhan: Hubei University of Technology, 2020. |
| [10] |
刘学平, 李玙乾, 刘励, 等. 嵌入SENet结构的改进YOLOV3目标识别算法[J]. 计算机工程, 2019, 45(11): 243-248. LIU Xue-ping, LI Yu-qian, LIU Li, et al. Improved YOLOV3 Target Recognition Algorithm with Embedded SENet Structure[J]. Computer Engineering, 2019, 45(11): 243-248. |
| [11] |
许小伟, 陈乾坤, 钱枫, 等. 基于小型化YOLOv3的实时车辆检测及跟踪算法[J]. 公路交通科技, 2020, 37(8): 149-158. XU Xiao-wei, CHEN Qian-kun, QIAN Feng, et al. REAL-time Vehicle Detection and Tracking Based on Miniaturized YOLOv3[J]. Journal of Highway and Transportation Research and Development, 2020, 37(8): 149-158. |
| [12] |
BEWLEY A, GE Z, OTT L, et al. Simple Online and Realtime Tracking[C]//2016 IEEE International Conference on Image Processing (ICIP). Phoenix: IEEE, 2016: 3464-3468.
|
| [13] |
XIANG Y, ALAHI A, SAVARESE S. Learning to Track: Online Multi-object Tracking by Decision Making[C]//2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 4705-4713.
|
| [14] |
KIM C, LI F, CIPTADI A, et al. Multiple Hypothesis Tracking Revisited[C]//2015 IEEE International Conference on Computer Vision, Santiage: IEEE, 2015: 4696-4704.
|
| [15] |
WOJKE N, BEWLEY A, PAULUS D. Simple Online and Realtime Tracking with a Deep Association Metric[C]//2017 IEEE International Conference on Image Processing (ICIP). Beijing: IEEE, 2017: 3645-3649.
|
| [16] |
ZHANG X, HAO X Y, LIU S L, et al. Multi-target Tracking of Surveillance Video with Differential YOLO and Deep Sort[C]//11th Eleventh International Conference on Digital Image Processing (ICDIP 2019). Guangzhou: [s. n. ], 2019.
|
| [17] |
王春艳, 刘正熙. 结合深度学习的多目标跟踪算法[J]. 现代计算机, 2019(6): 55-59. WANG Chun-yan, LIU Zheng-xi. Online Multiple Object Tracking with Deep Learning[J]. Modern Computer, 2019(6): 55-59. |
| [18] |
刘沛鑫. 基于数据关联的视频多目标跟踪关键技术研究[D]. 成都: 电子科技大学, 2020. LIU Pei-xin. Research on Key Technologies of Video Multi-target Tracking Based on Data Association[D]. Chengdu: University of Electronic Science and Technology of China, 2020. |
| [19] |
REDMON J, FARHADI A. YOLO9000: Better, Faster, Stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu: IEEE, 2017: 6517-6525.
|
| [20] |
LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature Pyramid Networks for Object Detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu: IEEE, 2017.
|