 2020, Vol. 37
2020, Vol. 37扩展功能
文章信息
- 郭宇奇, 查文斌, 李斌, 刘冬梅
- GUO Yu-qi, ZHA Wen-bin, LI Bin, LIU Dong-mei
- 基于春运大数据的交通运输领域词典构造及旅客情感分析
- Analysis on Transport Field Dictionary Construction and Passenger Emotion
- 公路交通科技, 2020, 37(3): 105-113
- Journal of Highway and Transportation Research and Denelopment, 2020, 37(3): 105-113
- 10.3969/j.issn.1002-0268.2020.03.013
-
文章历史
- 收稿日期: 2019-04-11


 ,
, 一般将出行者的满意度和情感倾向定义为:其在出行过程中在多大程度上对所采取的交通出行方式的服务水平持积极或者是消极态度。
春运期间,旅客出行集中,运输需求旺盛,服务保障任务繁重。为及时了解旅客的春运出行体验和服务需求,更好地掌握春运期间旅客出行规律,进一步做好春运工作,以在线问卷调查为基础,以大数据技术为支撑,认真分析广大旅客春运期间的服务体验感受与意见建议,挖掘旅客对某种交通出行方式及其配套设施、运营状态服务水平的满意度和情感倾向,客观评估政府部门春运工作服务举措的实施效果,为进一步改进和提升春运服务工作提供基础支撑。本研究通过春运期间对旅客出行体验调查问卷的开放性问题中所收集的文本数据进行深度挖掘与分析,获取了出行者的满意度和情感倾向,并进一步分析识别出了不同地域的旅客在春运期间所关注的不同热点问题。
从文本数据中获取旅客的情感倾向,目前主要有基于机器学习和基于词典两种方法。基于机器学习的方法需要从整体数据中选取部分数据进行人工标注,以得到情感倾向分别为“正向”和“负向”的标注数据作为训练集。利用机器学习算法进行情感分析常用的特征选择方法有词频过滤方法、文档频次方法、TF-IDF方法、互信息法等[1-3]。但在具体的应用中存在如下缺点:(1)由于中文语句存在结构复杂和语义多变等特点,导致在特征选择中存在词性、主题、位置、句法结构、专业词库等[4]诸多干扰因素。(2)机器学习后续模型与算法的有效性过于依赖数据集的规模,且训练模型的数据都需要人工标注。(3)在文本数据规模特别大的情况下,机器学习方法就显得有些繁琐且不能保证模型有很高的准确率。而相比较之下基于词典的情感分析方法只要能获得覆盖面广、质量高的情感词典,结合语义规则就能得到相对满意的结果。
所谓基于词典的方法,就是情感分析依赖于文本情感词典和句法规则,根据情感词的极性和权值通过加权求和的方法得出单个语句的情感值进而获得整个文本的情感值,情感词典包括基础情感词典和领域情感词典,是情感分析的基础。基于情感词典的情感分析重点在于情感词典的构建和语句分析规则的制定,国内冯超等[5]提出一种基于词向量相似度的半监督情感极性判断算法(Sentiment Orientation From Word Vector,SO-WV)作为构建领域词典的基础。孔伟俊等[6]提出基于HowNet的语义相似度计算方法,结合基准词构建领域情感词典。严仲培等[7]提出一种基于词向量的情感词典基准词集筛选方法,并利用词语互信息的SO-PMI词倾向算法构建领域情感词典。刘鑫磊等[8]针对领域情感词来源于分词后的领域文本数据,提出基于TF-IDF的方法筛选候选情感词,过滤掉分词切分出来的无效词语,得到具有很好的类别区分能力词或短语作为构建情感词典的基础。杨玉凡等[9]提出由上下文中的词语以及组成词语的字的信息、句子的情感极性信息、标记的种子词的情感极性信息3部分组成一种新词向量学习模型。李华等[10]提出基于HowNet的改进语义倾向度计算方法,算法显示具有较高的语义倾向识别准确率,但不适用于HowNet未登录词的语义倾向判别。於伟[11]提出利用BTM文本主题模型去挖掘候选情感词,利用词聚类的方法选择基准词,在此基础上利用改进的SO-PMI算法构建领域情感词典。王志涛等[12]提出了基于统计信息的情感词挖掘,满足字串频数、内部耦合度、邻字集信息熵3个统计信息阈值的词作为候选情感词,并用点互信息(Point-wise Mutual Information,PMI)对候选情感词进行情感识别进而构建领域情感词典。赵妍妍等[13]使用表情符做基准提升最终构建的领域情感词典的规模,改进了使用情感词语作为基准词来构建领域情感词典时其规模有限的不足。国外Baccianella等[14-15]基于WordNet构建了其相关领域普遍认可的SentiWordNet基础情感词典,但对特定领域的情感词适应性不强。Cruz等[16]提出基于Window Size Algorithm算法对候选情感词进行筛选,即在经过TreeTagger算法处理后的语料中距离基准词K个距离的形容词/名词作为候选情感词;然后基于统计测度和概率测度的两种算法计算候选情感词的情感倾向并以此构建领域情感词典。此外,文献[17-19]在相关方面也进行了研究。综上所述,基于词典的文本情感分析主要围绕基准词的选取和在基准词的基础上构建领域情感词典开展研究,虽然构建领域情感词典的方法比较成熟,然而对基础情感词典的构建上涉及不多,所选用的基础情感词典的规模太小,或者是仅仅对现有基础情感词典做简单的整合,缺乏强有力的依据。
本研究基于情感词典的方法,在现有的研究成果和分析方法的基础上,通过基于中国知网的语义倾向计算方法整合包括大连理工大学情感本体词汇、清华大学褒贬义词典、台湾大学简体中文情感极性词典、中国知网情感词典及其他个人研究者整理发布的词典在内的资源,整合过程以情感本体词汇为基础,扩展基础情感词典,构建规模大、覆盖率高、词语倾向正确的基础情感词典,在领域情感词典的构建上,采用深度学习词向量和支持向量机结合的方法,在此基础上结合句分析规则构建旅客情感分析模型,并以春运大数据为实际对象,对旅客的情感进行分析和识别。
1 基础理论与模型建立 1.1 基础情感词典构建基础情感词典的构建基于中国知网语义体系,中国知网是揭示词语的概念以及概念所具有的属性之间的关系为基本内容的常识知识库,包括“概念”和“义原”两个内容。概念由义原组成,一个词语可由多个概念来解释。
(1) 词语相似度计算
根据相关论述,词语之间相似度的计算基于在义原层次体系树状结构中两个义原与之间的距离。对于两个孤立词语W1和W2,如果W1有n个概念:S11, S12, …, S1n,W2有m个概念:S21, S22, …, S2m;则W1和W2的相似度等于各个概念之间的相似度最大值,即:
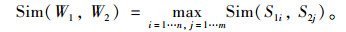
|
(1) |
概念之间的相似度由概念中的4个组成部分即第一独立义原、其他独立义原、关系义原和符号义原来计算,公式如下:
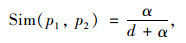
|
(2) |
式中,p1,p2分别为两个义原; d为p1和p2在义原层次体系中的距离; α为可调节参数。这样两个概念之间的整体相似度计算公式如下:
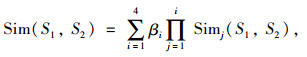
|
(3) |
式中,βi (1≤i≤4)为可以调节的参数,且有:β1+β2+β3+β4=1, β4≤β3≤β2≤β1。
Sim1 (S1, S2)为第一独立义原描述式,Sim2 (S1, S2)为其他独立义原描述式,Sim3 (S1, S2)为关系义原描述式,Sim4 (S1, S2)为符号义原描述式。
(2) 词语倾向性计算
词语的倾向性计算基于基准词和词语之间的相似度。对于要整合的词集,需要从中人工选取基准词,基准词选取的标准为词与词之间的相似度很低,同时每个词又能代表极强的情感色彩。词语褒贬倾向计算采用文献[20]提出的计算公式,如下:
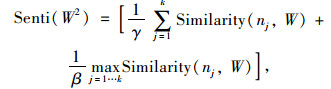
|
(4) |
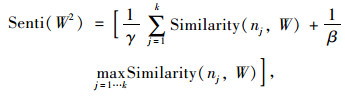
|
(5) |
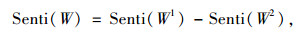
|
(6) |
式中,k为褒贬词个数,每个基准词与候选词的相似度采用公式(1)进行计算;Senti (W1)为词W与正向基准词集的相似度; Senti (W2)为词W与负向基准词集的相似度;Senti (W)为词W的情感倾向,其值表示词语的倾向强度,大于零表示词W更接近褒义倾向,小于零表示词W更接近贬义倾向,γ和β是上述词倾向计算模型的超参数,在实际应用中可通过参数寻优提高模型准确率。
(3) 整合词典
对除了大连理工大学情感本体词汇之外的包括清华大学褒贬义词典、台湾大学简体中文情感极性词典等词典求交集和并集,从交集里人工初步选取40对基准词[20]分别加入正、负基准词集,对两个基准词集分别计算词与词的相似度,剔除与其他词相似度比较大的词语,重新选择替补基准词,迭代重复直到基准词集里词与词的相似度在一定范围。接下来对并集里的未登录词做舍弃处理,根据上述词语褒贬倾向计算方法,对登录词的倾向进行计算,得到带有情感倾向的新词典。并对以上算法的准确率进行检验,不断调整参数直到符合实际应用标准为止。
最后以大连理工大学情感词汇本体为基础,对于新的词典里的每一个词,如果这个词在情感词汇本体中出现,则舍弃;否则就加入情感词汇本体,最后生成一个覆盖面较全的基础情感词典。
1.2 领域词典的构建领域情感词来源于实际的文本数据,本研究根据结合词性和TF-IDF算法进行情感词的提取,其中多数情感词属于中国知网语义情感词体系中的未登录词,如果采用构建基础情感词典的方法构建领域情感词典,词典的准确率和覆盖率难以满足实际需求。基于此,本研究提出结合深度学习词向量和支持向量机的方法构建领域情感词典。
(1) 深度学习词向量
在词语是未登录词的情况下,一种有效的词语特征信息表示方法是采用词向量,词向量技术将词转化成为向量。目前主要有两种词向量方法,一种是词的离散表示,包括独热编码表示、词袋表示等,另一种是词的分布式表示,其基本内涵体现为一个词语的语义基于它的上下文,上下文相似的词语,其语义信息也相似。
词向量用来描述词语特征时,分布式表示方法相比之下更能保存词语本身的信息,具有代表性的分布式词向量学习方法NNLM、CBOW、Skip-Gram,其中Skip-Gram根据目标单词预测上下文,CBOW根据上下文预测目标单词。本研究采用基于Hierarchical Softmax的CBOW模型训练词向量,如图 1所示。与传统的神经网络语言模型相比,采用了霍夫曼树来替代从隐藏层到输出softmax层的映射,霍夫曼树的所有内部节点就类似之前神经网络隐藏层的神经元。其中,根节点的词向量对应我们的投影后的词向量,而所有叶子节点就类似于softmax输出层的神经元,叶子节点的个数就是词的个数,具体训练过程如下。

|
| 图 1 基于Hierarchical Softmax的CBOW Fig. 1 CBOW based on Hierarchical Softmax |
| |
输入层为Context(w)中2c个词的词向量,最开始初始化的输入层数据可以是词的独热编码形式,投影层将输入层的2c个词向量做求和取平均,即
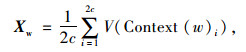
|
(7) |
式中,c为计算窗口,即某个词与上下文相关的个数,在训练开始时人为指定,2c定义为特定词前后各c个词。
输出层对应一棵以词频为权重构造出来的Huffman树,以词库中的词作为叶子节点,如果词库中有D个词,则有D个叶子节点。对于词库中任意一个词,Huffman树必存在且唯一存在一条从根节点到词w对应节点的路径,路径上存在分支,每个分支看做是一次二分类,分到树的左边定义为负类,分到右边定义为正类,根据逻辑回归模型易知一个节点被分到正类的概率如下:
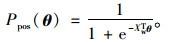
|
(8) |
被分为负类的概率就等于1-Ppos (θ),θ是一个向量,对应每个非叶子节点的待定参数,每一次分类就产生一个概率,将这些概率连乘,就可以得到在上下文2c个词的情况下,得到特定词w的概率P (W|Context (w)),如下:
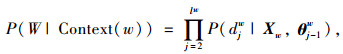
|
(9) |
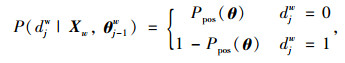
|
(10) |
式中,lw为Huffman树中从根节点到叶子节点的路径所包含的节点个数; θwj-1为路径中非叶子节点对应的参数; djw为路径中第j个节点对应的编码(0或1)。词向量训练的目标就是找到合适的所有节点的词向量和所有内部节点参数θwj-1,使训练样本达到最大似然。对此,对公式(9)求对数似然函数,如下:
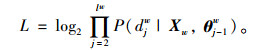
|
(11) |
函数(11)使用随机梯度上升法迭代求解,求解过程中并没有把所有样本的似然乘起来得到真正的训练集最大似然,仅仅每次只用一个样本更新梯度,这样做的目的是减少梯度计算量,其参数梯度如下:
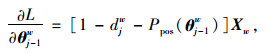
|
(12) |
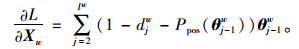
|
(13) |
参数更新机制如下:
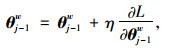
|
(14) |
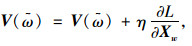
|
(15) |
式中,η为学习率;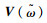
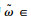
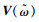
(2) 领域情感词典构建
在经过评估校验得到比较准确的词向量模型后,以领域情感词的词向量和情感倾向为基础,结合SVM支持向量机构建词分类器,分类结果为正向和负向,分类器构建流程如图 2所示。在训练过程中,取领域情感词与情感词汇本体的交集作为词分类器的训练数据,剩余领域词集作为待分类词集。在构建完词分类器后,对分类词集里的每一个词,依据其词向量输入到分类器,得到词的情感倾向,最后将正向词和负向词合并即得到领域情感词典,词的强度采用公式(1)计算。

|
| 图 2 词分类器训练过程 Fig. 2 Training process of words classifier |
| |
1.3 句分析规则
在具备了比较完整的情感词典之后,结合词语和分句搭配规则就可以对文本的情感倾向进行分析。按照词组成短语,短语组成句子,句子组成文本的原理,按标点符号对文本进行分句处理,每条语句的情感倾向由分句的情感倾向组成,分句的情感倾向由被修饰的情感词、句型、词语组合等关系决定。
(1) 词修饰规则
定义程度词的权值为D,情感词的情感值为W,否定词的权值采用否定词的权值相乘,记为N,经过修饰后的情感词的情感值记为E (W)。当程度词修饰情感词时,情感词的倾向E (W)=D×W。当否定词修饰情感词时,情感词的倾向E (W)=N×W。当程度词和否定词同时修饰情感词而且程度词出现在否定词之前时,情感词倾向E (W)=N×D×W。当程度词和否定词同时修饰情感词而且程度词出现在否定词之后时,情感词倾向E (W)=0.5N×W。
(2) 句型规则
句子是陈述句,则句子倾向不改变,如果句子中同时出现反问号和反问词,则句子倾向发生改变,如果句子是感叹句,则句子情感增强,倾向不改变。
(3) 句间规则
句与句之间的关系可依照表 1进行分析,以连词为分界点,分为连词前的分句和连词后的分句,按连词出现的情况赋予不同的权值,比如在转折关系中,如果句子中只出现转折后接词,则连词前权值为0,连词后权值为1,反之亦然。
| 类型 | 连词前分句权值 | 连词后分句权值 | 词语 |
| 转折连词 | 0或1 | 1或0 | 却,但是,然而, … |
| 递进连词 | 1 | 1.5 | 并,并且,而且, … |
| 假设连词 | 1或-1 | 0.5或-0.5 | 那么,要是,若是, … |
| 因果连词 | 1 | 1 | 因此,所以,以致, … |
2 文本情感分析 2.1 基础情感词典
本研究采用常规的人工选取方法对基准词进行选取,所选取的基准词满足词间相似度不大,但又极具情感色彩,选取结果如表 2所示,在此基础上,利用公式(1)计算词的情感倾向并构建基础情感词典如表 3所示。公式(1)中的最优参数组合通过迭代搜索查找,经过验证,公式(1)的算法准确率达了81.4%。
| 类型 | 基准词 | 基准词 | 相似度 |
| 正向 | 昌盛 | 新颖 | 0.04 |
| 正向 | 发达 | 投身 | 0.04 |
| 正向 | 榜样 | 大公无私 | 0.05 |
| 负向 | 扒窃 | 失职 | 0.06 |
| 负向 | 败类 | 勾结 | 0.04 |
| 负向 | 诓骗 | 徇私 | 0.12 |
| 词语 | 情感倾向 | 情感强度 |
| 脏乱 | 负向 | 7 |
| 难上难 | 负向 | 5 |
| 嘈杂 | 负向 | 1 |
| 发展 | 正向 | 5 |
| 繁盛 | 正向 | 5 |
| 实惠 | 正向 | 7 |
2.2 领域情感词典
(1) 词向量模型训练
用google的word2vec词向量工具构建词向量模型,输入数据为经过清洗整理和分词后的文本语料,每个旅客的数据存储在一个列表中,所有旅客的数据组成二维列表。词向量结果好坏直接影响后续的文本情感分析,对此需要有衡量措施来把握词向量的质量,目前常用的衡量措施主要有word analogy和document classification两类,但不局限与此,实际上,应该以所得的词向量对于实际任务的收益和效果为评价标准。对此,针对不同参数组合的词向量模型,取文本语料与情感词汇本体的交集一共561个词作为评价词向量模型好坏的依据,把该交集按词性分为正向词集和负向词集,对正向词集里的每一个词,分别计算其与正向词集和负向词集里每个词的余弦相似度,然后求和取平均值分别作为该词与正向词集和负向词集的相似度指标,对负向词集里的每一个词做同样的运算。
如果词向量模型精度足够应用于实际任务中,那么每个词对于其原生词集相似度指标必然大于其对应于词性对立词集的相似度指标。事实上,本研究经过训练的词性量效果完全能满足实际应用。其中,正向词向量模型精度检验如图 3所示;负向词向量模型精度检验如图 4所示。

|
| 图 3 正向词向量模型精度检验 Fig. 3 Accuracy test of positive word vector model |
| |

|
| 图 4 负向词向量模型精度检验 Fig. 4 Accuracy test of negative word vector model |
| |
(2) SVM词分类器训练
词分类器训练数据采用文本语料与情感词汇本体的交集,针对训练过程中出现的数据集类别不均衡,数据集数量不充足的问题,本研究采用SMOTE算法进行处理,在此基础上进行模型的训练,模型的输入为每个词的词向量,输出标签为1和-1,分别代表“正向”和“负向”,如表 4所示。SVM的词分类器参数寻优过程如图 5和图 6所示,最后确定参数值C=355,gamma=1,核函数=“rbf”,经过验证,SVM分类器精度高达90.7%。

|
| 图 5 词分类器超参数寻优 Fig. 5 Hyper parameter optimization of word classifier |
| |

|
| 图 6 词分类器核函数选择 Fig. 6 Kernel function selection of word classifier |
| |
| 词语 | 词向量(输入) | 强度 |
| 保障 | [1.48, 1.53, 2.41, 0.03, 0.50, 0.83, 1.42, 1.59, 1.45, 1.33, 0.8,1.43,……] | 7 |
| 快捷 | [-0.95, -0.93, -1.45, -0.83, 2.04, -0.57, 2.78, 1.66, 1.43, 1.53, ……] | 5 |
| 延误 | [-0.61, 2.18, 0.16, -0.31, 0.81, -0.89, 0.81, 1.53, -0.02, 1.43, 0.24, ……] | 5 |
| 缺失 | [-0.20, -0.44, -0.38, -0.11, 0.23, 0.02, 0.02, 0.14, 0.26, 0.27, 0.06, ……] | 3 |
3 文本情感分析及其应用
为了更好地了解春运期间旅客的需求,以便为旅客提供更好地服务、提高服务质量与水平。2018年春运大数据调查问卷设置了开放性试题,其题目为:“您对春运服务还有哪些建议?”;旅客可以结合自己的实际情况进行留言,最终共收集到20余万条旅客建议。
针对收集到的旅客建议,通过整合基础情感词典和领域情感词典,结合句法分析规则,对2018年春运期间旅客的出行服务体验调查文本数据进行倾向性分析。其中,“1”表示积极倾向,“-1”表示消极倾向。在测试模型精度上,人工选取并标注测试集,输入模型,最后经过3次重采样自助法验证得出本研究提出的模型平均准确率达82%,模型预测结果示例如表 5所示。在实际应用中,对春运期间旅客的投诉、建议、看法的情感倾向挖掘可从一定角度客观地反映出各省份、省各地区交通运输管理组织工作开展的质量和服务水平,结合LDA文本主题模型,还可挖掘分析出春运期间旅客关注的热点问题和运输组织工作不足的地方,本研究选取2018年全国春运客流量前十位的省市为例,对春运期间旅客对春运工作的“正面情感”和“负面情感”进行深度挖掘和分析,绘制出了如图 7所示的旅客情感占比图。
| 问卷数据 | 预测标签 |
| “大家共勉,共创辉煌。” | 1 |
| “特别乱涨价、乱收费、超载超速、随意甩客、欺诈、服务态度恶劣,大骂乘客。” | -1 |
| “买火车票难” | -1 |
| “希望加强对黑车的管控。” | -1 |
| “无,希望继续努力。” | 1 |
| “继续努力,满足群众出行!” | 1 |
| “主要是黄牛倒票” | -1 |

|
| 图 7 重点省份的春运旅客情感占比分析 Fig. 7 Analysis of proportion of passengers' emotion in Spring Festival transport in different provinces |
| |
同时选取具有典型代表的北京、河南、江苏、广东、山东、四川等省份,分别对6个省份旅客在2018年春运期间出行期间关注的热点问题进行挖掘分析,具体结果如表 6所示;从分析结果可以看出,旅客的关注度主要集中在“购票问题”、“安全和服务”、“高速公路管理”、“行业监管”等方面;其中不同地域、不同省份的旅客所关注的内容有所差别;比如:北京的旅客在枢纽的换乘便利性、购票问题、运力供需方面以及春运期间的安全和服务关注度表较高。相比之下,广东省的旅客广为关注春运期间相关部门的监管力度、购票问题、高速公路管理以及安全和服务等问题。
| 省份 | 热点内容 | 占比/% | 省份 | 热点内容 | 占比/% |
| 北京 | 购票问题 | 31.03 | 广东 | 购票问题 | 32.1 |
| 换乘便利性 | 26.66 | 安全和服务 | 24 | ||
| 安全和服务 | 22.16 | 高速公路管理 | 23.34 | ||
| 运力供需问题 | 20.16 | 行业监管力度 | 20.56 | ||
| 河南 | 安全、服务和监管 | 33.54 | 山东 | 安全和服务 | 35.6 |
| 运力供需问题 | 34.68 | 运力供需问题 | 33.38 | ||
| 购票问题 | 31.78 | 购票问题 | 31.02 | ||
| 江苏 | 购票问题 | 35.38 | 四川 | 购票问题 | 29.03 |
| 监管力度 | 26.44 | 行业监管力度 | 25.38 | ||
| 运力供需问题 | 19.52 | 安全和服务 | 24.36 | ||
| 安全和服务 | 18.66 | 运力供需问题 | 21.23 |
上述分析结果基本符合2018年春运期间的实际情况。
4 结论本研究结合自然语言处理、数据挖掘和机器学习等技术,基于春运期间旅客出行服务体验调查大数据,构建了旅客情感分析模型并设计了相应的模型算法。通过对2018年实际春运大数据的测试分析结果可以看出本研究提出的模型能够应用于实际的春运工作中,可有效挖掘和识别旅客的情感倾向以及关注的热点,其结果能够为客观评估相关部门在春运的服务工作提供重要依据,更为进一步提升和改进来年春运期间旅客出行服务工作提供基础支撑。
| [1] |
张志飞, 苗夺谦, 岳晓冬, 等. 强语义模糊性词语的情感分析[J]. 中文信息学报, 2015, 29(2): 68-78. ZHANG Zhi-fei, MIAO Duo-qian, YUE Xiao-dong, et al. Sentiment Analysis with Words of Strong Semantic Fuzziness[J]. Chinese Journal of Information Science, 2015, 29(2): 68-78. |
| [2] |
王祖辉, 姜维, 李一军. 在线评论情感分析中固定搭配特征提取方法研究[J]. 管理工程学报, 2014, 28(4): 180-186. WANG Zu-hui, JIANG Wei, LI Yi-jun. Regular Collocation Features Extraction Method in Online Reviews Sentiment Analysis[J]. Journal of Industrial Engineering and Engineering Management, 2014, 28(4): 180-186. |
| [3] |
曾永明.基于χ2统计的文本分类特征选择方法研究[D].广州: 华南理工大学, 2012. ZENG Yong-ming. Text Categorization Feature Selection Method Based on χ2 Statistics[D]. Guangzhou: South China University of Technology, 2012. http://cdmd.cnki.com.cn/Article/CDMD-10561-1013151315.htm |
| [4] |
孔杏, 林庆. 主观性文本情感分类研究综述[J]. 信息技术, 2018, 42(8): 126-130, 134. KONG Xing, LIN Qing. Survey on Subjective Text Sentiment Classification[J]. Information Technology, 2018, 42(8): 126-130, 134. |
| [5] |
冯超, 梁循, 李亚平, 等. 基于词向量的跨领域中文情感词典构建方法[J]. 数据采集与处理, 2017, 32(3): 579-587. FENG Chao, LIANG Xun, LI Ya-ping, et al. Construction Method of Chinese Cross-domain Sentiment Lexicon Based on Word Vector[J]. Journal of Data Acquisition and Processing, 2017, 32(3): 579-587. |
| [6] |
孔伟俊, 胡广朋. 基于领域词典的网络商品评论情感分析[J]. 计算机与数字工程, 2018, 46(1): 155-159. KONG Wei-jun, HU Guang-peng. Analysis of Internet Product Reviews Which Based on Field of Emotional Dictionary[J]. Computer and Digital Engineering, 2018, 46(1): 155-159. |
| [7] |
严仲培, 陆文星, 束柬, 等. 面向旅游在线评论情感词典构建方法[J]. 计算机应用研究, 2019(6): 1-3. YAN Zhong-pei, LU Wen-xing, SHU Jian, et al. Construction Method of Sentiment Lexicon for Online Travel Reviews[J]. Application Research of Computers, 2019(6): 1-3. |
| [8] |
刘鑫磊, 张备, 沈建京, 等. 用于涉军网络舆情情感分析的情感词典构建[J]. 信息系统工程, 2016(3): 32-34. LIU Xin-lei, ZHANG Bei, SHEN Jian-jing, et al. Emotional Dictionary Construction for Emotional Analysis of Army-related Network Public Opinion[J]. China CIO News, 2016(3): 32-34. |
| [9] |
杨玉凡.中文情感词典构建中词向量学习技术的研究与应用[D].南京: 南京大学, 2018. YANG Yu-fan.Research and Application of Word Vector Learning Technology in the Construction of Chinese Emotional Dictionary[D]. Nanjing: Nanjing University, 2018. |
| [10] |
李华, 储荷兰, 高旻. 中文网络评论观点词汇语义褒贬倾向性判断[J]. 计算机应用, 2012, 32(11): 3023-3025, 3033. LI Hua, CHU He-lan, GAO Min. Semantic Orientation Study on Chinese Network Comments[J]. Journal of Computer Applications, 2012, 32(11): 3023-3025, 3033. |
| [11] |
於伟.中文微博情感词典的构建研究与应用[D].上海: 上海师范大学, 2017. YU Wei. Research and Application on Construction of Chinese Weibo Emotional Dictionary[D]. Shanghai: Shanghai Normal University, 2017. |
| [12] |
王志涛, 於志文, 郭斌, 等. 基于词典和规则集的中文微博情感分析[J]. 计算机工程与应用, 2015, 51(8): 218-225. WANG Zhi-tao, YU Zhi-wei, GUO Bin, et al. Sentiment Analysis of Chinese Micro Blog Based on Lexicon and Rule Set[J]. Computer Engineering and Applications, 2015, 51(8): 218-225. |
| [13] |
赵妍妍, 秦兵, 石秋慧, 等. 大规模情感词典的构建及其在情感分类中的应用[J]. 中文信息学报, 2017, 31(2): 187-193. ZHAO Yan-yan, QIN Bing, SHI Qiu-hui, et al. Large-scale Sentiment Lexicon Collection and Its Application in Sentiment Classification[J]. Journal of Chinese Information Processing, 2017, 31(2): 187-193. |
| [14] |
BACCIANELLA S, ESULI A, SEBASTIANI F. SentiWordNet 3[J]. 0:An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining[C]//Proceedings of International Conference on Language Resources and Evaluation, Mauritius:International Book Market Service, 2010, 83-90. |
| [15] |
BACCIANELLA S, ESULI A, SEBASTIANI F. Feature Selection for Ordinal Text Classification[J]. Neural Computation, 2014, 26(3): 557-591. |
| [16] |
CRUZ L, OCHOA J, ROCHE M, et al. Dictionary-based Sentiment Analysis Applied to a Specific Domain[C]//Annual International Symposium on Information Management and Big Data. Berlin: Springer-Verlag, 2017: 57-68.
|
| [17] |
金盛, 沈莉潇, 贺正冰. 基于多源数据融合的城市道路网络宏观基本图模型[J]. 交通运输系统工程与信息, 2018, 18(2): 108-115, 127. JIN Sheng, SHEN Li-xiao, HE Zheng-bing. Macroscopic Fundamental Diagram Model of Urban Network Based on Multi-source Data Fusion[J]. Journal of Transportation Systems Engineering and Information Technology, 2018, 18(2): 108-115, 127. |
| [18] |
HE Z B, LÜ Y, LU L L, et al. Constructing Spatiotemporal Speed Contour Diagrams:Using Rectangular or Non-rectangular Parallelogram Cells?[J]. Transportmetrica B:Transport Dynamics, 2019, 7(1): 44-60. |
| [19] |
HE Z B, ZHENG L, CHEN P, et al. Mapping to Cells:A Simple Method to Extract Traffic Dynamics from Probe Vehicle Data[J]. Computer-Aided Civil and Infrastructure Engineering, 2017, 32(3): 252-267. |
| [20] |
杨昱昺, 吴贤伟. 改进的基于知网词汇语义褒贬倾向性计算[J]. 计算机工程与应用, 2009, 45(21): 91-93, 108. YANG Yu-bing, WU Xian-wei. Improved Lexical Semantic Tendentiousness Recognition Computing[J]. Computer Engineering and Applications, 2009, 45(21): 91-93, 108. |