 2019, Vol. 36
2019, Vol. 36扩展功能
文章信息
- 杨正理, 陈海霞, 王长鹏, 徐智
- YANG Zheng-li, CHEN Hai-xia, WANG Chang-peng, XU Zhi
- 大数据背景下城市短时交通流预测
- Urban Short-term Traffic Flow Forecasting with Big Data
- 公路交通科技, 2019, 36(2): 136-143
- Journal of Highway and Transportation Research and Denelopment, 2019, 36(2): 136-143
- 10.3969/j.issn.1002-0268.2019.02.018
-
文章历史
- 收稿日期: 2018-03-26


现代城市中车辆的增长速度远远超过道路里程数的增长,由此所引发的交通拥堵、环境污染等问题已严重阻碍了城市的可持续发展。解决该问题的一个较好方法是发展城市智能交通,建立有效的交通诱导系统,提高城市道路利用率。反映城市路网状态的重要指标是交通流[1],是指单位时间内道路某一截面通过的车辆数据,有效的交通诱导系统可以预测未来短时间(10~15 min)的交通状况,及时提出合理的诱导建议。但由于城市交通流数据规模巨大,其中又包含较强噪声且呈非线性,对短时交通状况的预测一直是业界的难题。
目前,大数据技术已成为学术界和产业界共同关注的热点[2]。随着智能交通系统的发展,基于大数据技术预测城市短时交通流更成为当前重要的研究课题。例如,文献[3]根据城市某条道路实测的车流量、车流速度和道路占有率等历史数据,采用相位角方法划分交通状态,实现了城市短时交通流预测;文献[4]综合城市交通状态参数的特征,采用优化的模糊C-均值聚类算法对交通数据的真伪进行判定,实现了城市短时交通流预测;文献[5]通过车流量、车行速度和道路占有率重新组合得到交通流的特征变量,采用多层前馈神经网络模型预测了短时交通流, 文献[6]在交通信息提取基础上,通过分析区域交通流的宏观特性和路网的拓扑结构,搭建了区域交通状态预测模型;文献[7]采用动态聚类方法和投影寻踪技术构造出投影指标函数,根据交通状态和交通流参数之间的映射关系,利用混合蛙跳算法对投影指标函数进行优化,实现了交通状态的预测;文献[8]采用Hadoop技术对城市交通大数据进行挖掘和分析,提高了算法对大数据的计算和分析能力。
经过众多研究学者的努力,国内对城市短时交通流的预测技术取得了一定成果。但由于相适应的市场机制还未形成,这一技术还远未达到成熟应用的目标,更新的预测方法还需要进一步研究。本研究借助Hadoop平台,采用并行化随机森林算法预测城市短时交通流,并在不同大小数据集上对该算法进行试验,其各方面性能均优于传统预测方法。
1 城市交通大数据管理平台根据城市交通大数据的实际特征和交通流预测需求,基于Hadoop技术构建城市交通大数据管理平台框架如图 1所示[9-15]。一方面,采用Hadoop的核心组件HDFS, HBase,Hive建立大数据存储系统;另一方面,利用并行化计算框架MapReduce和内存并行化计算框架Spark构成数据计算分析系统,实现对城市交通大数据的分析与计算。框架分为数据采集系统、存储系统、挖掘分析和应用系统。

|
| 图 1 城市交通大数据管理平台 Fig. 1 Urban traffic big data management platform |
| |
1.1 数据采集系统
数据采集系统完成城市交通流原始数据采集以及数据到集群系统的数据整合。
城市交通流数据主要来自安装于城市各处的感应线圈传感器、各种物联智能设备, 摄像头、车载GPS、车辆电子标签、及其他和交通流有关的数据。这些数据由不同接口协议产生,数据口径各不相同,其模态千差万别,构成大规模异构数据。数据整合目前还没有统一方法,只能通过第三方软件,如Sqoop,Datanucleus等来完成。Sqoop能实现数据在关系型数据库和Hadoop集群之间的迁移[16]。平台采用Sqoop将各子数据库的数据抽取到Hive与HBase中;Datanucleus软件提供了标准的数据源访问接口(JDO,JPA),能够屏蔽各存储系统之间的差异[17],实现对当前众多主流存储系统的支持,如RDBMS,ODBMS,Map-based,Web-based,Documents等。平台采用Datanucleus将Hadoop平台运行过程中的中间数据写入到列数据库HBase。
1.2 数据存储系统平台中数据存储在HDFS中。列数据库Hive,HBase中数据通过MapReduce进程的Map过程并行地写入到HDFS中,实现海量数据的高效存储[18]。Hadoop集群采用经典的Master/Slave结构,其中Master为管理节点,负责集群内资源的管理、任务分配和对数据进行分块,记录与各数据块相一致的名字空间与元数据;Slave由N个数据节点组成,负责冗余地保存各数据块,执行Master分配的任务。
1.3 数据挖掘分析系统平台利用并行化计算模型MapReduce对大数据进行挖掘分析,采用基于内存的并行化计算模型Spark完成对密集型数据进行迭代式计算[19]。MapReduce作业类通过Map过程将一个key/value键值对生成多个key/value中间键值对,Reduce过程则负责获取这些key/value中间键值对,将有相同key的value合并起来,完成统计结果。Spark运算框架与MapReduce相似,具有MapReduce算法的所有优点[20]。与MapReduce算法不同的是,Spark运算过程的中间数据保存在内存中,不需要频繁地读写HDFS,提高MapReduce算法的迭代过程。
1.4 数据应用系统根据云服务中应用即服务的理念,数据应用系统直接面向城市交通行业用户,向城市管理者、城市交通参与者、城市交通相关部门提供方便、具体的应用服务。例如以文件形式向用户提供实时交通预测、路网规划、交通管理等可视化服务。另外,数据应用系统提供数据接口、数据资源等,以方便与其他系统进行数据交换和服务接口操作。
2 并行随机森林算法预测短时交通流 2.1 随机森林算法原理目前,应用于城市短时交通流状态预测的学习算法主要有极限学习、贝叶斯算法、支持向量机和决策树等。决策树算法以其简单易用且能处理多输出问题的优势得到广泛的研究和应用。
决策树预测方法虽然应用广泛,但由于其自身原因,仍存在一些不足,主要表现在:
(1) 分类规则复杂,在学习过程中需要大量内存支持,使算法对大数据的处理能力不足。
(2) 算法在属性选择时不进行回归运算,其分类结果只能收敛于局部最优解,从而使决策树算法的预测精度降低,且泛化能力差。
(3) 学习者可以创建复杂的树,但其推广依据不足,即训练过程中容易出现过拟合现象,导致树的结构变得过于复杂。复杂的决策树对训练样本的分类效果良好,但对新数据的分类效果则明显不佳。
随机森林是集成了多个决策树的学习方法。当输入训练样本后,每个决策树都会输出一个决策结果,而随机森林的最终结果由多个决策树输出结果的平均值或投票得到。随机森林算法克服了决策树的一些不足,且能够实现并行化,具有较强的数据处理能力,使其预测精度得到了明显提高。
2.2 随机森林算法的并行化随机森林由多棵决策树组成是其实现并行化的基本条件;而其能够实现并行化的理论条件则依赖于Bagging和随机子空间算法[21-22],其原理如下:
Bagging算法是一种根据概率分布原理从数据集中有放回的抽样技术。每轮抽样时,数据集中约有36.8%的样本不能被抽中,没有被抽中的样本不参加训练,但可以用来检测模型的泛化能力。Bagging算法使得每个学习单元的训练样本互不相同,但每个训练样本都包含了原始数据集的知识规模,从而使随机森林中的决策树可以并行完成训练,提高了算法的效率,使其具备处理大规模数据能力。
随机子空间算法是指单棵决策树通过在属性集中随机抽取属性样本,并按分支准则进行内部分支的方法。该方法一方面避免了决策树在生成过程中容易过拟合的缺点;另一方面每棵决策树随机抽取属性集,能够实现各决策树的并行生成。
根据上面描述,随机森林的并行化增强了数据分析和处理效率,提高了大数据处理能力。因此,本研究提出了基于MapReduce的并行化随机森林算法(Map Reduce-Paralleled random forests,MR-PRF)进行城市短时交通流预测方法。
2.3 城市短时交通流预测流程采用3个MapReduce作业类完成城市短时交通流预测模型的训练过程。每一个MapReduce作业类的输出作为下一个MapReduce作业类的输入,训练完成后的随机森林模型保存在Hadoop集群中。这3个MapReduce作业类分别用来生成数据字典、生成决策树和完成随机森林模型。
生成数据字典是用文件形式描述参于训练的样本数据,包括样本的条件属性、决策属性和模型的类型(回归/分类),该过程由第1个MapReduce作业类来完成。在Map过程读取城市交通大数据集的一部分样本数据,并用文件形式描述样本数据的属性类型和属性值,得到的描述文件保存在模型的HDFS中,并作为第2个MapReduce作业类的输入。
生成决策树是预测过程的核心步骤,主要包括:
(1) 采用Bagging算法从原始数据集有放回的抽取k个大小相同的训练样本数据集TSi(i=1, 2, …, k)。因为是有放回的抽取,所以k个样本可以同时抽取;
(2) 根据样本数据集中M个属性为每个决策树节点随机抽取m个分支属性集,并根据每个属性集所包含的信息,选择最佳的属性进行分支;
(3) 以递归方法建立节点并生成决策树。
随机森林中的每棵决策树的生成是并行进行的,每个Map过程生成一棵决策树,由第2个MapReduce作业类完成。
生成随机森林就是对每棵决策树结果进行统计,通过对每棵决策树结果进行投票或求平均值得到随机森林的最终结果,由第3个MapReduce作业类完成。
采用并行化随机森林算法实现城市短时交通流状态预测的流程如图 2所示。预测模型基于分布式Hadoop集群建立,并采用MapReduce实现随机森林算法的并行化。依托Hadoop集群强大的存储和计算能力,实现了城市交通大数据的挖掘和分析处理,有效地提高了算法的分析效率和对大数据的处理能力。

|
| 图 2 城市短时交通流状态预测流程图 Fig. 2 Flowchart of predicting urban short-term traffic flow state |
| |
3 城市短时交通流预测模型和试验分析 3.1 城市交通大数据试验平台
课题组在实验室用38台PC机搭建了一个城市交通大数据试验平台。其中一台PC机作为平台的主节点,负责完成平台内资源分配和任务调度,也是平台内整个文件系统的管理节点;其他PC机作为数据节点,完成集群内数据的存储和任务的执行。主节点将数据集进行分块并以文件形式记录各分块文件的名字空间和元数据,并将各数据块冗余地保存在各数据节点。
当MapReduce作业提交至主节点时,主节点按照任务所需要的资源,依据各数据节点所能提供的资源分配任务量,并负责监控MapReduce作业的执行过程。试验平台的拓扑结构如图 3所示。

|
| 图 3 试验平台拓扑结构 Fig. 3 Topology structure of experimental platform |
| |
图 3中,原始交通流大数据以关系型数据库方式保存,平台采用DataNucleus完成数据库到Hadoop集群的数据整合。DataNucleus软件操作容易,但其灵活性及速度均不高。试验中,将约20万条测试数据整合到HBase列式数据库中,大约需要3 min时间。
3.2 基于Hadoop的城市短时交通流预测原型系统在3.1节所述试验平台上实现基于Hadoop的城市短时交通流状态预测的原型系统如图 4所示。

|
| 图 4 基于Hadoop的城市短时交通流预测原型系统 Fig. 4 Urban short-term traffic flow forecasting prototype system based on Hadoop |
| |
城市短时交通流预测原型系统包括Hadoop集群管理、交通数据管理、Hadoop文件管理、序列文件管理、预测分析算法以及预测结果展示等功能。Hadoop集群管理用来向集群注册用户,注册后的用户才能获取集群的管理权限;Hadoop文件管理用来实现HDFS系统的文件上传、下载、编辑及在线查看;交通数据管理主要实现原始交通数据库到Hadoop集群的整合;序列文件管理主要实现对MapReduce作业的中间数据和集群内小文件的管理。一方面提高了小文件的存储效率;另一方面可以更好地监督MapReduce的执行过程;预测分析算法中包括了决策树、随机森林、贝叶斯、K均值等多种预测分类算法;预测结果通过图表等工具进行展示,提高了数据的可视化程度。文中的所有试验均在此原型系统中进行。
3.3 试验数据、属性值、试验评价指标选取试验数据来自某城市一条繁华街道2016年5~8月的交通流信息,包括268个预测结点,数据按15 min一次进行采集,并包含有时间和天气等相关信息。已有的数据量远没有达到大数据规模,但完全可以用来验证算法的正确性。通过人为的扩充数据,使试验数据达到大数据规模,可用来验证算法处理数据的效率、算法的预测性能等。
根据文献[23-24]的研究成果确定城市交通流的样本属性为:星期、预测时间、车行方向(0表示正向,1表示反向)、天气状况(0表示良好天气,1表示高温、高寒、暴风雨等恶劣天气)、周围是否有大型活动(0表示没有,1表示有)、车辆平均速度、车流量、车道占有率、上周同时间交通状态、昨天同时间交通状态、相临时间段交通状态、未来15 min的交通状态。交通状态用1表示畅通,2表示缓行,3表示拥堵。训练样本的部分属性如表 1所示。
| 样本属性 | 属性值 |
| 星期 | 星期一 |
| 预测时间 | 15:30 |
| 车行方向 | 0 |
| 天气状况 | 0 |
| 周围是否有大型活动 | 0 |
| 车辆平均速度/(km·h-1) | 51 |
| 车流量/(veh·min-1) | 14 |
| 车道占有率 | 5.9 |
| 上周同时间交通状态 | 0 |
| 昨天同时间交通状态 | 1 |
| 相临时间段交通状态 | 2 |
| 未来15 min的交通状态 | 1 |
算法预测精度评价指标采用常用的平均绝对百分比误差(mean absolute percentage error,MAPE),MAPE的计算公式为:
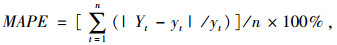
|
(1) |
式中,Yt为算法的预测值;yt为真实值;n为预测个数;MAPE值越小,算法的预测精度越高。
算法的并行化性能评价指标采用通用的加速比,加速比的计算公式为:
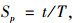
|
(2) |
式中,t为单台PC机的运行时间;T为集群模型的运行时间。
3.4 短时交通流预测试验分析试验1:比较MR-PRF与传统预测算法的预测精度。以2016年5月6日至2016年5月27日的历史数据为输入样本数据集(文件大小102 MB,共1.3×106组数据),分别采用MR-PRF(集成决策树数量k=240)、传统预测算法对2017年5月28日该路段15: 30—15: 45时段的交通状态进行预测。试验结果如表 2所示。
| 预测算法 | MAPE值/% |
| MR-PRF算法 | 1.43 |
| 决策树算法 | 2.24 |
| 贝叶斯算法 | 2.49 |
| K均值算法 | 3.78 |
由表 2可见MR-PRF的预测精度较其他算法高。这是因为MR-PRF集成了多个决策树,保留了决策树优点的同时克服了决策树的一些缺点,从而使MR-PRF表现出更好的预测性能。
试验2:MR-PRF预测精度受决策树数量的影响。当MR-PRF集成的决策树数量k取不同值时,采用同一样本数据集进行多次试验,试验结果如表 3所示。
| 决策树数量 | MAPE值/% | 运行时间/s |
| 120 | 2.01 | 2.8 |
| 180 | 1.87 | 3.4 |
| 240 | 1.59 | 4.5 |
| 300 | 1.56 | 6.2 |
| 360 | 1.57 | 8.0 |
由表 3可见,当MR-PRF集成决策树数量k取值较小时,MAPE值较大。这是因为k值较小时,不能体现随机森林的优势,因而预测精度不高。k值过大时,算法的复杂程度加大,运行时间加长。当k值达到一定数量时,MAPE值变化不大,说明合适的k值是保证MR-PRF预测精度的重要参数。
试验3:MR-PRF预测性能受原始数据集大小的影响。人为对原始数据集进行补充,生成不同大小的原始数据集,选择算法集成决策树数量k=240进行试验,得到MR-PRF性能值如表 4所示。
| 文件大小(MB)/元组数 | MAPE值/% | 运行时间/s |
| 380/4.2×106 | 1.72 | 37 |
| 760/8.4×106 | 1.71 | 87 |
| 1 140/12.6×106 | 1.76 | 131 |
| 1 520/16.8×106 | 1.75 | 184 |
| 1 950/20.5×106 | 1.68 | 233 |
由表 4可见,MR-PRF预测精度受原始数据集大小的影响不大,没有明显的变化规律。但随着数据量的增加,算法的运行时间明显加长。这说明MR-PRF具有较强的大数据处理能力。但是,在实际应用中,应选择合适的原始数据集大小。
试验4:MR-PRF的加速比,即并行性能测试。人为将原始数据集文件补充至3.8,13.8,138 G,选择算法集成决策树数量k=240,分别运行在由1,5,15,25,35台PC机组成的集群进行试验,其运行结果如图 5所示。

|
| 图 5 MR-PRF加速比 Fig. 5 Speedup ratio of MR-PRF |
| |
由图 5可以看出,MR-PRF在相同大小集群上,原始数据量越大,加速比越大;在相同的原始数据集上,加速比随集群的增大而增大,当集群数量达到一定程度时,加速比的增大趋势减小。
4 结论从试验结果来看,针对海量的城市道路交通流量数据,利用Hadoop环境下的并行化随机森林算法模型进行数据存储和处理,实现城市短时交通流预测是合理、可行、高效的,并较其他常用的预测算法具有更快的数据处理效率、更高的预测精度以及更强的大数据处理能力。
受试验条件限制,试验中所应用的原始数据集远没有达到大数据的规模。但通过人为的数据补充,已从不同角度模拟了数据集的增加,试验过程接近实际情况,因而试验结果具有较强的可参考性。
| [1] |
程政, 陈贤富. 基于随机森林模型的短时交通流预测方法[J]. 微型机与应用, 2016, 35(10): 46-49. CHENG Zheng, CHEN Xian-fu. The Model of Short Term Traffic Flow Prediction Based on the Random Forest[J]. Microcomputers and Its Applications, 2016, 35(10): 46-49. |
| [2] |
RUSITSCHKA S, EGER K, GERDES C.Smart Grid Data Cloud: A Model for Utilizing Cloud Computing in the Smart Grid Domain[C]//First IEEE International Conference on Smart Grid Communications.Gaithersburg, USA: IEEE, 2010: 483-488. https://www.researchgate.net/publication/224189801_Smart_Grid_Data_Cloud_A_Model_for_Utilizing_Cloud_Computing_in_the_Smart_Grid_Domain
|
| [3] |
BHASKAR A, TSUBOTA T, KIEU L M, et al. Urban Traffic State Estimation:Fusing Point and Zone Based Data[J]. Transportation Record Part C:Emerging Technologies, 2014, 48(295): 120-142. |
| [4] |
商强, 杨兆升, 张伟, 等. 基于奇异谱分析和CKF-LSSVM的短时交通流量预测[J]. 吉林大学学报:工学版, 2016, 46(6): 1792-1798. SHANG Qiang, YANG Zhao-sheng, ZHANG Wei, et al. Short-term Traffic Flow Prediction Based on Singular Spectrum Analysis and CKF-LSSVM[J]. Journal of Jilin University:Engineering and Technology Edition, 2016, 46(6): 1792-1798. |
| [5] |
邴其春, 龚勃文, 林赐云, 等. 基于粒子群优化投影寻踪回归模型的短时交通流预测[J]. 中南大学学报:自然科学版, 2016, 47(12): 4277-4282. BING Qi-chun, GONG Bo-wen, LIN Ci-yun, et al. Short-term Traffic Flow Prediction Method Based on Particle Swarm Optimization Projection Pursuit Regression Model[J]. Journal of Central South University:Science and Technology Edition, 2016, 47(12): 4277-4282. |
| [6] |
SUN Y, FANG J, HAN Y.A Distributed Real-time Storage Method for Stream Data[C]//201310th Web Information System and Application Conference.Yangzhou: IEEE, 2013: 314-317. http://en.cnki.com.cn/Article_en/CJFDTotal-DNZS201519004.htm
|
| [7] |
NISHIMURA S, DAS S, AGRAWAL D. MD-HBase:Design and Implementation of an Elastic Data Infrastructure for Cloud Scale Location Services[J]. Distributed and Parallel Databases, 2013, 31(2): 289-319. |
| [8] |
邴其春, 龚勃文, 杨兆升, 等. 基于投影寻踪动态聚类的快速路交通状态判别[J]. 西南交通大学学报, 2015, 50(6): 1164-1169. BING Qi-chun, GONG Bo-wen, YANG Zhao-sheng, et al. Traffic State Identification for Urban Expressway Based on Projection Pursuit Dynamic Cluster Model[J]. Journal of Southwest Jiaotong University, 2015, 50(6): 1164-1169. |
| [9] |
李成兵, 魏磊, 李奉孝, 等. 基于攻击策略的城市群复合交通网络脆弱性研究[J]. 公路交通科技, 2017, 34(3): 101-109. LI Cheng-bing, WEI Lei, LI Feng-xiao, et al. Study on Vulnerability of City Agglomeration Compound Traffic Network Based on Attack Strategy[J]. Journal of Highway and Transportation Research and Development, 2017, 34(3): 101-109. |
| [10] |
徐艳艳, 李国柱, 徐喆, 等. 北京市交通环境承载力动态评价及障碍因子诊断[J]. 公路交通科技, 2017, 34(6): 122-128. XU Yan-yan, LI Guo-zhu, XU Zhe, et al. Dynamic Evaluation of Traffic Environment Bearing Capacity of Beijing and Diagnosis of Obstacle Factor[J]. Journal of Highway and Transportation Research and Development, 2017, 34(6): 122-128. |
| [11] |
苏刚, 王坚, 凌卫青. 基于大数据的智能交通分析系统的设计与实现[J]. 电脑知识与技术, 2015, 11(36): 44-46. SU Gang, WANG Jian, LING Wei-qing. Design and Implementation of Intelligent Transportation Analysis System Based on Big Data[J]. Computer Knowledge and Technology, 2015, 11(36): 44-46. |
| [12] |
韩伟, 张学庆, 陈旸. 基于MapReduce的图像分类方法[J]. 计算机应用, 2014, 34(6): 1600-1603. HAN Wei, ZHANG Xue-qing, CHEN Yang. MapReduce Based Image Classification Approach[J]. Journal of Computer Applications, 2014, 34(6): 1600-1603. |
| [13] |
陈娇杨, 宋国华, 于雷. 面向城市群交通规划的道路碳排测算与分析方法[J]. 公路交通科技, 2018, 35(2): 122-128, 136. CHEN Jiao-yang, SONG Guo-hua, YU Lei. An Estimation and Analysis Method for Road Carbon Emissions in Urban Agglomeration Transport Planning[J]. Journal of Highway and Transportation Research and Development, 2018, 35(2): 122-128, 136. |
| [14] |
姚庆华, 和永军, 缪应锋. 面向综合智能交通系统的多源异构数据集成框架研究[J]. 云南大学学报:自然科学版, 2017(增1): 41-45. YAO Qing-hua, HE Yong-jun, MIAO Ying-feng. Study on the Integration Framework of Multi-source Heterogeneous Transportation Data[J]. Journal of Yunnan University:Natural Sciences Edition, 2017(S1): 41-45. |
| [15] |
陆婷, 房俊, 乔彦克. 基于HBase的交通流数据实时存储系统[J]. 计算机应用, 2015, 35(1): 103-107, 135. LU Ting, FANG Jun, QIAO Yan-ke. HBase-based Real-time Storage System for Traffic Stream Data[J]. Journal of Computer Applications, 2015, 35(1): 103-107, 135. |
| [16] |
施俊庆, 程琳, 褚昭明, 等. 城市路网交通流元胞自动机模型研究[J]. 公路交通科技, 2015, 32(4): 143-149. SHI Jun-qing, CHENG Lin, CHU Zhao-ming, et al. Cellular Automata Model of Urban Road Network Traffic Flow[J]. Journal of Highway and Transportation Research and Development, 2015, 32(4): 143-149. |
| [17] |
牛海玲, 鲁慧民, 刘振杰. 基于Spark的Apriori算法的改进[J]. 东北师大学报:自然科学版, 2016, 48(1): 84-89. NIU Hai-ling, LU Hui-min, LIU Zhen-jie. The Improvement and Research of Apriori Algorithm Based on Spark[J]. Journal of Northeast Normal University:Natural Science Edition, 2016, 48(1): 84-89. |
| [18] |
张毅, 张丽, 万丽娟, 等. 基于机动车政策的城市交通可持续发展建模研究[J]. 公路交通科技, 2015, 32(6): 142-147, 153. ZHANG Yi, ZHANG Li, WAN Li-juan, et al. Modelling of Sustainable Development of Urban Traffic Based on Vehicle Policy[J]. Journal of Highway and Transportation Research and Development, 2015, 32(6): 142-147, 153. |
| [19] |
曹杰, 邵笑笑. 基于信息增益和Bagging集成学习算法的个人信用评估模型研究[J]. 数学的实践与认识, 2016, 46(8): 90-98. CAO Jie, SHAO Xiao-xiao. Analysis of Personal Credit Evaluation Method Based on Information Gain and Bagging Integration Learning Algorithm[J]. Mathematics in Practice and Theory, 2016, 46(8): 90-98. |
| [20] |
孙波军, 尹伟石. 改进的灰色模型及在短时交通流中的应用[J]. 数学的实践与认识, 2016, 46(23): 201-206. SUN Bo-jun, YIN Wei-shi. A Modified Grey Model and Its Application in Short Time Traffic Flow[J]. Mathematics in Practice and Theory, 2016, 46(23): 201-206. |
| [21] |
田保慧, 郭彬. 基于时空特征分析的短时交通流预测模型[J]. 重庆交通大学学报:自然科学版, 2016, 35(3): 105-109. TIAN Bao-hui, GUO Bin. A Short-term Traffic Flow Prediction Model Based on Spatio-temporal Characteristics Analysis[J]. Journal of Chongqing Jiaotong University:Natural Science Edition, 2016, 35(3): 105-109. |
| [22] |
韦凌翔, 陈红, 王永岗, 等. 基于RVM和ARIMA的短时交通流量预测方法研究[J]. 武汉理工大学学报:交通科学与工程版, 2017, 41(2): 349-354. WEI Ling-xiang, CHEN Hong, WANG Yong-gang, et al. Study on the Methods of Short-term Traffic Flow Forecasting Based on RVM and ARIMA[J]. Journal of Wuhan University of Technology:Transportation Science & Engineering, 2017, 41(2): 349-354. |
| [23] |
罗向龙, 张生瑞, 牛力瑶. 基于检测器优化选择的短时交通流预测[J]. 计算机工程与应用, 2017, 53(8): 199-202. LUO Xiang-long, ZHANG Sheng-rui, NIU Li-yao. Short-term Traffic Flow Prediction Based on Detector Optimal Selection[J]. Computer Engineering and Applications, 2017, 53(8): 199-202. |
| [24] |
张军, 王远强, 朱新山. 改进PSO优化神经网络的短时交通流预测[J]. 计算机工程与应用, 2017, 53(14): 227-231. ZHANG Jun, WANG Yuan-qiang, ZHU Xin-shan. Short-term Prediction of Traffic Flow Based on Neural Network Optimized Improved Particle Swarm Optimization[J]. Computer Engineering and Applications, 2017, 53(14): 227-231. |