 2021, Vol. 42
2021, Vol. 42文章信息
- 唐丹, 肖雄, 杨帆, 胡逸凡, 殷建忠, 赵星.
- Tang Dan, Xiao Xiong, Yang Fan, Hu Yifan, Yin Jianzhong, Zhao Xing
- 因果图模型及其在营养流行病学研究中的应用
- Causal graph model and its application in nutritional epidemiologic research
- 中华流行病学杂志, 2021, 42(10): 1882-1888
- Chinese Journal of Epidemiology, 2021, 42(10): 1882-1888
- http://dx.doi.org/10.3760/cma.j.cn112338-20200805-01025
-
文章历史
收稿日期: 2020-08-05




2. 昆明医科大学公共卫生学院 650500;
3. 保山中医药高等专科学校 678000
2. School of Public Health, Kunming Medical University, Kunming 650500, China;
3. Baoshan College of Traditional Chinese Medicine, Baoshan 678000, China
饮食因素已成为全球慢性非传染性疾病(non-communicable diseases,NCDs)和死亡最重要的可控危险因素之一,2017年全球疾病负担研究(Global Burden of Diseases,Injuries,and Risk Factors Study,GBD)表明,由不良饮食导致的死亡高于其他任何危险因素,突显了在全球、区域和国家层面改善饮食的迫切需求[1]。识别和确定具体饮食因素与健康结局间的因果关联,能指导制定针对性的营养相关政策和饮食建议并最终改善人类饮食和健康。
目前随机对照试验(randomized controlled trial,RCT)被认为是确定因果关系和估计因果效应的金标准方法,但其存在固有的局限性,如缺乏外部有效性;研究时间短、样本少、花费大;以中间事件或生物标志物替代疾病作为结局指标等[2]。此外,相较于标准药物临床试验,饮食干预的RCT研究还面临难以确定恰当的对照膳食、盲法几乎不可行、研究对象退出率高、依从性低等问题和挑战[3-4]。因此,如何充分利用观察性研究和数据开展因果推断为营养相关政策的制定和实施提供重要依据已经成为营养流行病学研究的重点和热点。上世纪末到本世纪初,有学者将有向无环图(directed acyclic graphs,DAG)与因果关系联系起来,开发了一套用图形表示因果关系的一般规则,提出因果图模型理论,为因果推断提供了一种新的思维框架和有力的方法学工具[5]。本文拟就因果图模型的因果推断框架和策略及其在营养流行病学研究中的应用进行综述,为该领域后续研究提供参考和建议。
一、因果图——因果推断的基础传统上认为,观察性研究无法测量或随机分配某些协变量,因而可能歪曲暴露-结局的真实因果关联,目前相关研究主要是根据传统混杂判别标准[6-8]来确定混杂因素并通过多元回归、分层、匹配等方法调整以消除混杂。然而,由于变量间关系十分复杂,孤立地考察各变量可能导致错判、漏判或冗余。此外,传统方法也很难解决未观测混杂的问题。而因果图模型DAG可通过直观、透明的可视化图形完整地展现因果关联系统中各变量间复杂的相互关系,并通过一定的准则判别和选择可用的混杂调整集,是识别混杂的强有力工具。此外,DAG还可提示用以估计目标因果效应的其他特殊策略和方法[9],从而巧妙避开未观测混杂的问题,是开展因果推断的基础框架。
DAG是由节点和带方向的箭头组成的无闭环图形,节点表示变量,箭头表示变量间由原因指向结果的因果关系。在DAG的因果推断框架下有1个核心概念和2个重要准则[9]:后门路径(back-door path)指从暴露到结局路径中第一个箭头指向暴露的路径。后门准则(back-door criterion)指变量集{Z}满足①阻断了暴露到结局的全部后门路径;②不包含暴露或任何中介的后代;主要用以直接识别暴露-结局间的混杂变量集并加以调整得到因果效应。前门准则(front-door criterion)指变量集{M}满足①切断了所有暴露到结局的直接路径;②暴露到{M}没有开放的后门路径且{M}到结局的后门路径都被暴露阻断;主要用以分别估计各中介路径效应最终得到总因果效应。
以一个简化的DAG说明图模型的思想和主要的因果效应估计策略。图 1(根据参考文献[9]修订)中E和O分别表示暴露和结局,C和U分别表示可观测和未观测的混杂(可以是多个因素,下述变量同理),M和N表示暴露到结局的中介因素,I和G是不由图中其他变量决定的“外生变量”,分别指向暴露和结局。该图囊括了在具体研究问题中,各变量间可能存在的主要相互关系类型,在该因果关系系统下,要估计暴露到结局的(总)因果效应有3种主要策略:①调整混杂,采用分层、匹配、回归等方法阻断“后门路径”(即非因果路径)以去除暴露结局关联中由混杂导致的非因果关联部分;②利用外生变量I,采用工具变量的方法分离暴露与结局的共(协)变异;③已知暴露-结局因果关联的全部机制和路径,通过分别估计每条路径的因果效应获得总因果效应。

|
| 图 1 包含主要关系类型的简化有向无环图模型 |
理想情况下,3种策略都能用以估计目标因果效应,且应当获得可比的结果,但实际上由于研究问题本身的特点或数据可得性的差异,不同研究的因果图结构可能大不相同,因此适合采用的估计策略也不尽相同。后文将分别详述每个策略的主要特点及其在营养流行病学中的应用。
二、因果推断的三大策略 (1) 调整混杂是因果推断最直接也最常用的策略,基于构建的DAG并借助后门准则识别最小充分混杂调整集,进而采取分层、匹配或回归分析控制可能的混杂偏倚,将为因果效应提供准确、可靠的估计。由于一般存在多个混杂因素,单纯以分层分析控制混杂的方法较少见,下文主要介绍常用多变量回归和基于倾向性得分的2类方法。
(1)常用多变量回归:多变量回归就是以混杂因素集为协变量,暴露为自变量与结局建立回归方程,常用多变量回归包括多重线性回归、多变量logistic回归、Poisson回归等。该类方法在整个流行病学研究中的应用十分广泛,但对所调整混杂的选择普遍缺乏清晰的因果图作为支撑。目前,在营养领域已有少数研究基于DAG的框架筛选混杂因素集并用于多变量回归,主要是妇幼营养相关的研究。一项基于欧美15个出生队列26 184名孕妇及其子代的汇总分析研究,利用DAGitty工具构建DAG,从大量潜在混杂因素中识别出多个最小充分调整集,并选择了信息最完整、数据质量最高的调整集以估计孕妇鱼类摄入量与子代生长过速和儿童超重肥胖间的因果关联,研究发现怀孕期间每周摄入3次以上鱼类与子代生长过速和儿童超重肥胖的风险增加有关,并且其对子代生长过速的影响在女孩中比男孩更大[10]。Busert等[11]用相似的方法研究了尼泊尔529名幼儿饮食多样性与条件生长之间的因果关联,结果表明增加儿童的饮食多样性可降低发育迟缓的风险并促进生长,但该研究在讨论部分指出,在筛选出的最小混杂调整集中,一般照料(general care)变量由于未观测而无法进行调整,因此研究结果可能仍受到该混杂变量的影响。
基于DAG筛选混杂相较于传统混杂判别标准具有以下特点和优势:①DAG筛选混杂是基于阻断“后门路径”的思想而非孤立地考虑每一个因素,因此研究者能根据研究需要和数据可得性灵活选择控制变量;②借助DAG可以确定充分调整集和最小充分调整集,既能保证消除所有可能的混杂,也尽量减少了调整的混杂因素数目,提高了统计效率;③通过DAG能够判别冲撞变量(collider,两箭头同时指向的变量,本身不能传递关联,但控制该因素会产生额外关联),合理避免了传统方法中可能存在的错误调整。但正如第二个例子所说,如果筛选出的最小混杂调整集中存在未观测变量,回归调整可能仍然是有偏倚的。
(2)基于倾向性得分的匹配、回归或加权:倾向性得分(propensity score,PS)是指在一定的协变量条件下,观察对象接受某种暴露的概率,由于在非随机研究(尤其是观察性研究)中,研究个体是否接受某种暴露E受到很多协变量C(混杂因素)的影响,C在暴露组与非暴露组分布不均衡会导致对暴露-结局效应估计的偏倚,而通过计算倾向性得分P (E = 1|C = c),并将其用以匹配、作为协变量纳入回归或进行暴露逆概率加权(尤其当效应存在个体异质性时)就能控制由C造成的混杂偏倚,得到目标效应的无偏估计。
基于倾向性得分的估计策略在营养领域应用广泛,主要是倾向性得分匹配或回归,加权较少见。一项基于2010-2014年韩国全国健康和营养调查9 424名健康成年人的横断面研究,将人群钠钾摄入比(Na∶K)划分为四分位数进行两两比较以探究钠钾比与高血压患病及血压水平的关联,研究将各比较组更高分位数组作为“处理组”,分别构造倾向性得分,并同时采取1∶1最近邻匹配、半径匹配和核匹配方法为“处理组”对象匹配相应的对照进而通过直接做差获得各比较组的平均处理效应(average treatment effect for the treated,ATT),3种匹配方式都显著提高了协变量在各比较组的均衡性,并得到可比的效应估计,结果表明,即使在钠钾比水平较低的情况下(较低四分位数组相比),仍然可以观察到低钠钾比与高血压及血压水平间强烈的负向关联[12];美国一项基于13 051例中老年对象的前瞻性研究,通过线性回归模型构造倾向性得分(该研究中暴露是一个连续变量)并将其作为唯一协变量纳入Cox比例风险回归进行控制,该研究同时采用了传统多变量回归方法以做比较,结果表明,在非裔美国人和白人中膳食的升糖指数(glycemic index,GI)和血糖负荷(glycemic load,GL)与冠心病风险呈正相关,两种混杂控制方法的效应估计基本一致[13];伊朗一项旨在估计青春期鱼类消费对多发性硬化症(multiple sclerosis,MS)边际因果效应的病例对照研究,通过DAG筛选混杂变量集用以构建PS,并进一步采用基于PS的逆概率加权(inverse-probability-of-treatment weighting,IPTW)方法估计了暴露对结局的因果效应,结果提示青春期食用新鲜和罐装鱼类均可降低MS的风险[14]。
此外,很多配对设计的病例对照研究会用PS作为匹配因素,此时PS模型的因变量不再是某种暴露而是结局,虽然与因果推断框架下的PS概念有所区别,但最终目的也是实现比较组间(暴露与非暴露组/病例与对照组)混杂变量的分布均衡,其相较于传统多变量回归方法具有降维效果。虽然基于PS的方法简单、有效,在营养流行病学领域的应用已很广泛,但其中仍然存在一些问题:①PS方法只能消除或控制可观测混杂导致的偏倚,仍不能解决未观测混杂的偏倚问题;②目前研究对PS模型的协变量选择存在一定的主观性,普遍缺乏清晰的因果图作为支撑,可能导致PS模型指定不恰当,不能完全控制可能的混杂偏倚。
近年来,综合上述2类调整混杂的方法又衍生出了双稳健估计(doubly robust estimation)方法,该方法在利用PS进行暴露逆概率加权的同时,又再次把所用混杂变量纳入回归模型进行双重调整,只要PS模型或回归模型至少一个正确,效应估计就是可靠的[15],基于双稳健的思想,目前还发展了其他一些具有双稳健特征的估计量,双稳健估计成为因果推断又一强有力也备受推崇的方法,但尚未找到该类方法在营养领域的应用文章。
(2) 工具变量(instrumental variable,IV)分析最初在计量经济学领域应用广泛,近年来也越来越多地用于健康领域的研究。以一个简单的DAG说明IV分析的思想,图 2(根据参考文献[16]修订)中E、O、C、U分别表示暴露、结局、可观测的混杂和未观测的混杂,根据DAG阻断所有“后门路径”的思想,同时控制C和U才能获得E到O真实的因果效应估计,但由于U无法观测,就不能基于上述调整混杂的方法产生无偏因果效应估计值。此时如果存在一个变量I满足:①与未观测的混杂U无关;②是暴露E的决定因素;③只能通过影响暴露进而对结局产生影响(而无直接或其他路径的关联),那么I就是一个有效的IV,通过I与O以及I与E之间的关联就能获得E与O之间因果关联的大小。根据“亲代等位基因随机分配给子代”的孟德尔遗传定律,基因成为潜在IV最自然和广泛的来源之一。孟德尔随机化(mendelian randomization,MR)就是以遗传变异作为IV的特殊IV分析方法。

|
| 图 2 工具变量在因果关联中的有向无环图模型 |
近年来,MR在营养领域的应用显著增多,相关研究主要集中在饮酒、咖啡摄入、乳制品摄入、维生素D营养状态等有较明确关联基因的饮食因素上。一项基于丹麦2个自然人群队列93 179名参与者的研究,以咖啡因代谢相关的CYP1A1、CYP1A2和AHR基因附近5个遗传变异的等位基因得分作为IV研究咖啡摄入与肥胖、MS及2型糖尿病的因果关联,并同时重复了传统的观察性分析,结果表明,虽然观察性分析复现了以往研究发现的咖啡摄入与上述疾病的负向关联,但MR分析表明,在咖啡摄入等位基因得分的全范围内,没有发现咖啡摄入与上述疾病的因果关联,观察性研究的结果很可能是由未测量的混杂因素所致[17]。Vissers等[18]利用基于欧洲癌症与营养前瞻性调查(EPIC)的一项病例队列研究共21 820名对象的数据,采用MR探讨了乳制品摄入与2型糖尿病的因果关联,该研究在以往MR研究的基础上进一步考虑和调整了人群分层并对IV假设进行了系统的检验以最大程度降低可能的偏倚,最终采用两阶最小二乘回归得出虽然rs4988235位点基因多态性与牛奶及其饮品的摄入量有强关联,但并未发现牛奶摄入量与2型糖尿病间存在因果关联。
MR最大的优势在于能够解决残余混杂(未观测的混杂)和横断面研究中难以避免的反向因果问题,这是调整混杂策略所不能解决的,正因为如此,再加上近年来全基因组关联研究(genomic-wide association study,GWAS)在全球范围内广泛开展,相关数据库不断丰富完善,MR逐渐成为流行病学因果关联研究中的热点。但MR最关键也最困难的是识别和判定有效的IV。在IV的3个假设中,假设②最容易检验,但应当避免选择与暴露关联很弱的IV,否则可能导致IV估计的方差大,同时过度放大因IV与未测量混杂间存在微小关联而导致的弱IV偏倚(weak instrument bias)[16]。而针对假设①和③,最简单的检验方法就是在一个IV与暴露关联被打破的亚人群中考察IV与结局间是否存在关联,如果存在,说明IV可能与未测量的混杂有关或IV存在基因多效性能通过除暴露外的其他路径影响结局[16]。中国慢性病前瞻性队列就利用女性无论携带何种酒精代谢基因都几乎不饮酒的特点(即IV与暴露的关联被打破)证实了用ALDH2-rs671和ADH1B-rs1229984作为研究饮酒量与心血管疾病因果关联IV的有效性[19]。
(3) 中介分析(mediation analysis)一种更深层次的因果推断方法,当调整混杂的策略失效而又无法找到合适的IV时,如果能完整地分解暴露-结局因果关联的机制和路径,并可估计出每条路径的因果效应,就能获得总效应的无偏估计,但由于病因的复杂性,一般无法穷尽所有关联机制,因此中介分析目前主要用以确定和评价某个或某几个感兴趣的中介变量是否具有介导暴露-结局因果关联的作用及该中介作用的大小。以单一中介为例说明经典中介分析的思想,图 3(根据参考文献[20]修订)中,E、O、M分别表示暴露、结局和中介,,τ表示E对O的总效应,τ'表示E对O的直接效应,α和β分别表示E对M和M对O的效应,此时αβ的乘积就是E通过M对O的间接效应。经典中介分析的前提是线性模型且暴露和中介无交互,当存在非线性和交互时,可以采用基于反事实(counterfactual-based)的中介分析方法。

|
| 图 3 单一中介的有向无环图模型 |
目前中介分析在营养领域的应用也较多,主要关注于肥胖、血脂、血压、血糖、炎性因子等指标在饮食与疾病因果关联中的中介作用。基于澳大利亚妇女健康纵向研究,Schoenaker等[21]采用基于反事实(counterfactual-based)的中介分析因果推理框架将孕前地中海饮食模式对妊娠期糖尿病(gestational diabetes mellitus,GDM)和妊娠高血压疾病(hypertensive disorders of pregnancy,HDP)的总效应分解为自然直接效应(natural direct effect,NDE)和自然间接效应(natural indirect effect,NIE),定量估计了孕前BMI作为该因果关联中介的作用大小,结果表明,孕前BMI分别介导了32%和22%孕前地中海饮食对GDM和HDP的总效应,是重要的中介因子,提示建立最优化孕前BMI的饮食方案可降低GDM和HDP风险。Lee等[22]采用经典中介分析探究了SBP、胆固醇和FPG在水果蔬菜摄入与心血管疾病因果关联中可能的中介作用,研究者利用bootstrap重抽样10 000次的方法对各中介因子单独及联合的中介效应进行了估计和检验,结果表明,3种代谢因素的联合间接效应占总效应的21.4%,但仅SBP具有独立的中介效应,提示富含水果的饮食可通过降低SBP来降低心血管疾病的风险。
中介分析不仅考虑了暴露-结局的总因果关联,还进一步揭示了该因果关联的内在机制及作用大小,这对营养流行病学研究有两方面的重要意义:①研究结果最终要转化为具体、定量的饮食指南以指导人们日常饮食的选择,如果能确定饮食到疾病的因果关联路径,明确主要的中介因素,就能以最优化该中介因素为导向,形成针对性、可操作性强的饮食推荐;②饮食习惯是受社会、文化、经济等因素深刻影响形成的一种复杂长期的生活行为方式,改变人群的饮食习惯往往很困难,如果通过中介分析能明确重要的中介因子,而该中介因子比饮食更容易改变和调控,就能结合其他干预方式直接优化中介因子达到相同或更好的疾病防治效果。
目前国内中介分析研究大多仅针对单一中介,即使面临多中介问题,也简化为多个单一中介处理,而忽略了中介因素间的复杂相互关联及序次关系。针对此类多重中介或多水平中介问题,van der Weele[23]总结了基于回归和基于加权的两大类方法。多重中介问题在营养领域是非常突出的,因为饮食往往可通过同时影响多种体格测量或生化代谢指标进而影响疾病,而各指标间又存在复杂的相互关联和顺序关系,因此要想正确分解和准确估计各中介因子的效应就需要用到多重中介分析方法。
三、总结和讨论目前,因果推断的理论和方法研究在流行病学中发展迅速,为提高观察性研究的因果证据强度提供了有力的工具和支撑。其中因果图模型作为一种新的思维体系和框架,为合理选择因果推断策略并系统估计因果效应大小提供了基础和依据。相较于传统因果推断方法,DAG通过将复杂的因果关系系统可视化,为目标因果效应的估计提供了更直观和更丰富的可选策略与手段,就混杂控制而言,DAG能通过调整更少的混杂数目充分地消除混杂,同时对混杂调整集的选择具有高度的灵活性,既能避免传统混杂选择的错判、漏判和冗余,也能合理避开某些未观测或难以测量的变量信息。但通过DAG有效揭示真实因果关联的前提是所构建的因果图即对各变量间因果关联的假设是正确的,这也正是DAG方法最突出的挑战和局限,一方面,构建DAG需要基于大量的先验知识,系统全面的文献梳理工作量巨大;另一方面,由于病因研究的复杂性,很多因果关系假设仍然是不确定或者双向的,研究者需要做出合理且有依据的决策甚至需要同时构建多个DAG分别分析和解释[24-25]。因此,正确构建DAG是因果图模型框架下开展因果推断的关键,Ferguson等[26]提出了一种基于证据综合构建DAG的系统方法和框架,强调其系统性和透明性,对如何构建DAG具有很好的指导意义。
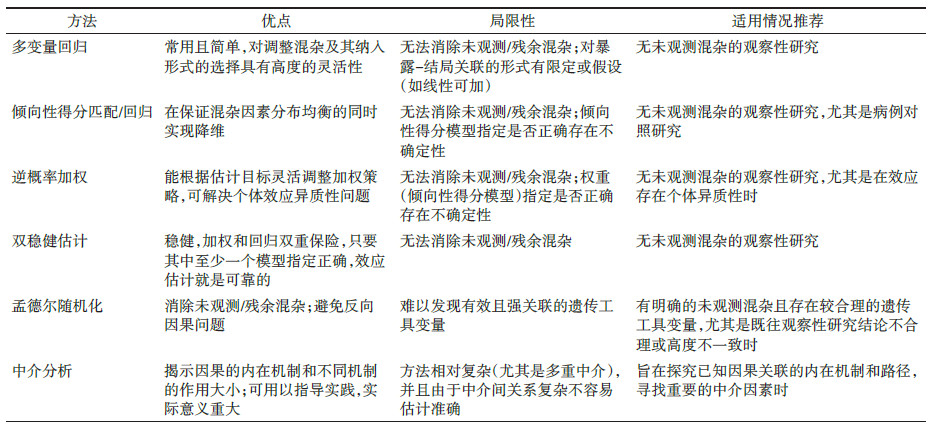
一旦DAG构建完成,研究者可根据DAG的结构特点和数据可得性科学选择因果推断策略,主要有调整混杂、IV和中介分析策略,这些策略在营养流行病学研究中都得到了广泛应用,其中以调整混杂最为常见。各分析策略和方法的适用情况和主要优缺点见表 1,就目前而言,如果不存在明确的未观测混杂因素,较推荐采用双稳健估计方法,该方法结合了逆概率加权和回归调整的双重优势,最大程度保证了效应估计的可靠性,是一种普适性的方法,但目前尚未找到该方法在营养流行病学研究中的应用,部分原因可能是该方法相较于多变量回归等传统混杂调整方法更复杂多变,相对缺乏成熟配套的软件和程序实现。此外,由于营养研究本身的复杂性,时常存在未观测或难以观测的混杂,此时双稳健方法可能并不适用,但如果研究者在研究开始或数据收集前就完成DAG构建,进而根据需要进行研究设计和数据收集,可在很大程度上解决上述问题。实际上,目前已有一些软件包和程序可用于双稳健估计[27-28],相关应用研究也在逐渐增多,因此,基于DAG结合双稳健估计开展营养流行病学因果推断是一种可靠也可实现的方法,未来可能被广泛应用。
综上所述,DAG为因果推断提供了新的思维体系和基础框架,但要有效利用DAG揭示真实的因果关联,研究者则必须更深入和系统地了解所研究的问题,理清相互关系,并具体化研究问题和假设,构建出合理、正确的因果图,这不仅能增强研究本身的科学性与合理性,更能促进学界透明、公开的相互交流、监督和发展,因此DAG应当成为观察性研究开展因果推断的常规实践。
利益冲突 所有作者均声明不存在利益冲突
| [1] |
Afshin A, Sur PJ, Fay KA, et al. Health effects of dietary risks in 195 countries, 1990-2017:a systematic analysis for the Global Burden of Disease Study 2017[J]. Lancet, 2019, 393(10184): 1958-1972. DOI:10.1016/s0140-6736(19)30041-8 |
| [2] |
Frieden TR. Evidence for health decision making-beyond randomized, controlled trials[J]. N Engl J Med, 2017, 377(5): 465-475. DOI:10.1056/NEJMra1614394 |
| [3] |
Schulze MB, Martínez-González MA, Fung TT, et al. Food based dietary patterns and chronic disease prevention[J]. BMJ, 2018, 361:k2396. DOI:10.1136/bmj.k2396 |
| [4] |
Staudacher HM, Irving PM, Lomer MCE, et al. The challenges of control groups, placebos and blinding in clinical trials of dietary interventions[J]. Proc Nutr Soc, 2017, 76(3): 203-212. DOI:10.1017/S0029665117000350 |
| [5] |
Pearl J. Causality: Models, Reasoning, and Inference[M]. Cambridge: Cambridge University Press, 2009.
|
| [6] |
Weinberg CR. Toward a clearer definition of confounding[J]. Am J Epidemiol, 1993, 137(1): 1-8. DOI:10.1093/oxfordjournals.aje.a116591 |
| [7] |
Geng Z, Guo JH, Fung WK. Criteria for confounders in epidemiological studies[J]. J Roy Stat Soc: Ser B (Stat Methodol), 2002, 64(1): 3-15. DOI:10.1111/1467-9868.00321 |
| [8] |
Greenland S, Morgenstern H. Confounding in health research[J]. Annu Rev Public Health, 2001, 22: 189-212. DOI:10.1146/annurev.publhealth.22.1.189 |
| [9] |
Morgan SL, Winship C. Counterfactuals and Causal Inference[M]. Cambridge: Cambridge University Press, 2015.
|
| [10] |
Stratakis N, Roumeliotaki T, Oken E, et al. Fish intake in pregnancy and child growth: a pooled analysis of 15 European and US birth cohorts[J]. JAMA Pediatr, 2016, 170(4): 381-390. DOI:10.1001/jamapediatrics.2015.4430 |
| [11] |
Busert LK, Neuman M, Rehfuess EA, et al. Dietary diversity is positively associated with deviation from expected height in rural Nepal[J]. J Nutr, 2016, 146(7): 1387-1393. DOI:10.3945/jn.115.220137 |
| [12] |
Park J, Kwock CK, Yang YJ. The effect of the sodium to potassium ratio on hypertension prevalence: a propensity score matching approach[J]. Nutrients, 2016, 8(8): 482. DOI:10.3390/nu8080482 |
| [13] |
Hardy DS, Hoelscher DM, Aragaki C, et al. Association of glycemic index and glycemic load with risk of incident coronary heart disease among Whites and African Americans with and without type 2 diabetes: the Atherosclerosis risk in Communities study[J]. Ann Epidemiol, 2010, 20(8): 610-616. DOI:10.1016/j.annepidem.2010.05.008 |
| [14] |
Abdollahpour I, Nedjat S, Mansournia MA, et al. Estimating the marginal causal effect of fish consumption during adolescence on multiple sclerosis: a population-based incident case-control study[J]. Neuroepidemiology, 2018, 50(3/4): 111-118. DOI:10.1159/000487640 |
| [15] |
Funk MJ, Westreich D, Wiesen C, et al. Doubly robust estimation of causal effects[J]. Am J Epidemiol, 2011, 173(7): 761-767. DOI:10.1093/aje/kwq439 |
| [16] |
Baiocchi M, Cheng J, Small DS. Instrumental variable methods for causal inference[J]. Stat Med, 2014, 33(13): 2297-2340. DOI:10.1002/sim.6128 |
| [17] |
Nordestgaard AT, Thomsen M, Nordestgaard BG. Coffee intake and risk of obesity, metabolic syndrome and type 2 diabetes: a Mendelian randomization study[J]. Int J Epidemiol, 2015, 44(2): 551-565. DOI:10.1093/ije/dyv083 |
| [18] |
Vissers LET, Sluijs I, van der Schouw YT, et al. Dairy product intake and risk of type 2 diabetes in EPIC-InterAct: a Mendelian randomization study[J]. Diabetes Care, 2019, 42(4): 568-575. DOI:10.2337/dc18-2034 |
| [19] |
Millwood IY, Walters RG, Mei XW, et al. Conventional and genetic evidence on alcohol and vascular disease aetiology: a prospective study of 500 000 men and women in China[J]. Lancet, 2019, 393(10183): 1831-1842. DOI:10.1016/s0140-6736(18)31772-0 |
| [20] |
杨春艳, 侯艳, 李康. 中介分析方法及其在医学研究中的应用[J]. 中国卫生统计, 2017, 34(1): 159-162. Yang CY, Hou Y, Li K. Mediating analysis method and its application in medical research[J]. Chin J Health Stat, 2017, 34(1): 159-162. |
| [21] |
Schoenaker DA, Soedamah-Muthu SS, Mishra GD. Quantifying the mediating effect of body mass index on the relation between a Mediterranean diet and development of maternal pregnancy complications: the Australian Longitudinal Study on Women's Health[J]. Am J Clin Nutr, 2016, 104(3): 638-645. DOI:10.3945/ajcn.116.133884 |
| [22] |
Lee HA, Lim D, Oh K, et al. Mediating effects of metabolic factors on the association between fruit or vegetable intake and cardiovascular disease: the Korean National Health and Nutrition Examination Survey[J]. BMJ Open, 2018, 8(2): e019620. DOI:10.1136/bmjopen-2017-019620 |
| [23] |
van der Weele TJ. Explanation in causal inference: methods for mediation and interaction[M]. Oxford: Oxford University Press, 2015.
|
| [24] |
向韧, 戴文杰, 熊元, 等. 有向无环图在因果推断控制混杂因素中的应用[J]. 中华流行病学杂志, 2016, 37(7): 1035-1038. Xiang R, Dai WJ, Xiong Y, et al. Application of directed acyclic graphs in control of confounding[J]. Chin J Epidemiol, 2016, 37(7): 1035-1038. DOI:10.3760/cma.j.issn.0254-6450.2016.07.025 |
| [25] |
Shrier I, Platt RW. Reducing bias through directed acyclic graphs[J]. BMC Med Res Methodol, 2008, 8: 70. DOI:10.1186/1471-2288-8-70 |
| [26] |
Ferguson KD, Mccann M, Katikireddi SV, et al. Evidence synthesis for constructing directed acyclic graphs (ESC-DAGs): a novel and systematic method for building directed acyclic graphs[J]. Int J Epidemiol, 2020, 49(1): 322-329. DOI:10.1093/ije/dyz150 |
| [27] |
Zetterqvist J, Sjölander A. Doubly robust estimation with the R package drgee[J]. Epidemiologic Methods, 2015, 4(1). DOI:10.1515/em-2014-0021 |
| [28] |
Benkeser D. drtmle: Doubly-Robust Inference in R[EB/OL]. [2020-07-31]. https://cran.r-project.org/web/packages/drtmle/vignettes/using_drtmle.html.
|