 2021, Vol. 42
2021, Vol. 42文章信息
- 梁洁, 和思敏, 陈淑婷, 王彤.
- Liang Jie, He Simin, Chen Shuting, Wang Tong
- 纵向研究中控制时依混杂的G方法
- G methods for handling time-varying confounding in the longitudinal study
- 中华流行病学杂志, 2021, 42(10): 1871-1875
- Chinese Journal of Epidemiology, 2021, 42(10): 1871-1875
- http://dx.doi.org/10.3760/cma.j.cn112338-20200731-01001
-
文章历史
收稿日期: 2020-07-31




在观察性研究中,估计暴露与结局间因果效应的关键是控制混杂。当暴露不随时间变化(time-fixed treatment)时,例如接种疫苗/外科手术等仅在基线发生的处理因素、基因型/性别等不随时间变化的因素、年龄等随时间有确定性变化的因素,采用匹配、分层、回归校正、倾向性评分等传统分析方法即可实现混杂的有效控制。当前,很多大型人群队列研究都试图推断基线暴露与预设的一次随访结局的关系,其中一个常被忽视的假设是基线暴露及其可能的混杂是不随时间变化的。然而在流行病学研究中,许多感兴趣的暴露是随时间变化(time-varying treatment)的,例如药物剂量、用药方案、吸烟状态、空气污染程度、社会经济状态等,此时要估计时变暴露的因果总效应,就必须考虑时依混杂的有效控制。
一、时依混杂当感兴趣的暴露随时间变化时,可能存在随时间变化的、受过去暴露水平影响并影响着后续暴露水平的混杂,即时依混杂[1]。例如,在研究抗反转录病毒治疗(anti-retroviral therapy,ART)(X=1为ART,X=0为其他治疗)对HIV感染者的CD4+T淋巴细胞(CD4)计数(Y)的影响时(例1),HIV载量(C)为时依混杂(C=1为HIV病毒载量 > 200拷贝/ml,C=0则相反)。在研究起始时受试者的基线HIV病毒载量均 > 200拷贝/ml(C0=1),而第一次随访时的HIV病毒载量(C1)会受到研究起始时治疗方案(X0)的影响,同时其又影响着该次随访时的治疗方案(X1),成为X0到Y的一条因果通路上的中介变量(图 1)。此外,当存在同时影响HIV病毒载量(C)和CD4计数(Y)的未测量协变量U0时,C1是X0、U0和Y因果通路上的对撞因子(collider)(图 1)。在这些复杂情形下,若采用传统分析方法直接控制C1,很可能产生过度校正偏倚(控制了中介变量C1)或对撞机偏倚(collider bias,控制了对撞变量C1),从而无法得到无偏因果效应估计值。

|
| 图 1 抗反转录病毒治疗与HIV感染者CD4计数的因果图 |
在临床流行病学纵向研究中,许多临床体征或生化指标不仅影响着后续的暴露水平,其本身也受过去暴露水平的影响。例如在研究哮喘抢救药物与呼气流量率峰值(peak expiratory flow rate,PEFR)的因果关系中,某阶段哮喘症状(时依混杂)出现的频率及严重程度与先前用药剂量密切相关,同时也影响着后续用药水平[2];在探索他汀类药物对冠心病一级预防效果的研究中,存在受先前是否服用他汀类药物影响的时依混杂,如血清胆固醇水平、DBP值等[3];在β受体阻滞剂与急性心梗死亡之间的因果关系研究中,血压值是受先前用药影响的时依混杂[4]。因此,纵向研究中采用有效的统计方法控制时依混杂是其因果推断的关键。
二、方法和原理目前发展了3种控制时依混杂的统计方法:参数g-formula、逆概率加权(inverse probability of weighting,IPW)和G估计,统称为G方法。不同于传统方法,G方法不会通过将混杂因素固定在某个值或某个水平而实现控制混杂的目的,因此可有效避免过度校正偏倚和对撞机偏倚,从而得到无偏因果效应估计值[5]。令X(t)为时变二分类暴露,C(t)为二分类时依混杂,假设C(t)在固定的时间点t=0,…,k处改变,,X(t)={X(0),…,X(t)}和C(t) = {C(0),…,C(t)}分别代表每次随访时的暴露状态和混杂水平。
(1) 参数g-formula参数g-formula利用了标准化的思想,在多个时间点上构建X、C和Y的联合分布,模拟受试者在暴露和非暴露情况下产生的潜在结果,并估计总体平均潜在结局

在没有未测量混杂(no unmeasured confounding)假设下,给每个观测者分配权重来重新获得一个混杂在组间均衡分布的伪人群,在该人群中拟合处理因素和结局间的边际结构模型(marginal structure models,MSMs)即可得到因果效应无偏估计值[9-10]。IPW的计算包括不稳定权重:


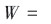
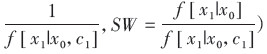
将暴露效应定义为比较同一个体或一组受试者接受暴露和非暴露的潜在结局[5, 14]。首先,在先前暴露状态和混杂水平下,第t次随访暴露与非暴露的效应估计值为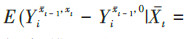
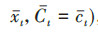
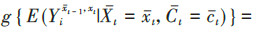
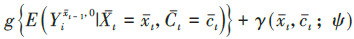
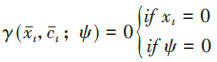
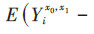

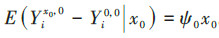
本研究将从原理、适用范围、估计的有效性和稳定性、计算复杂程度等方面比较3种方法的差异,并用表 1简要概括了3种方法的优缺点。

参数g-formula可以看作标准化方法在多个随访时间点的拓展,通过预测缺失的反事实结局,比较在不同的假设干预下人群的结局是否存在差异;IPW通过对调查人群加权,获得一个不受混杂因素影响的、伪随机化的人群[1, 18]。这2种方法是直观的,相对于G估计更好理解,但是通过G估计得到的因果效应结论更容易外推到其他人群中[18]。
(2) 零悖论因果推断的零假设为暴露和结局间不存在因果关联,当零假设为真时错误地拒绝零假设被称为零悖论[19]。参数g-formula需要估计给定协变量和处理因素的平均结局效应E [Y|X = x,C = c],和给定历史协变量和处理因素时该次随访协变量的分布布f[(Ct = ct|Xt- 1 = xt- 1,Ct- 1 = ct- 1)。。当先前的暴露对之后的混杂有非零影响时,基于参数g-formula得到的结论会与零假设不一致,即产生了零悖论[1, 18]。而其他2种估计方法不存在零悖论,零假设对IPW而言,意味着加权后的MSMs中估计的暴露系数为0;零假设在G估计中,对应着波动函数的有限维参数ψ = 0[18]。因此零悖论也被称为g-null悖论,其只会发生在控制时依混杂的因果推断中。避免零悖论的方法是仅考虑已知对结局有影响的暴露,或基于零假设不成立的先验信息[20]。
(3) 估计的有效性和稳定性参数g-formula估计的有效性和稳定性主要依赖于模型是否被正确设定,尤其是在不能排除零假设的前提下,而一旦结局模型(以结局为预测变量建模)和混杂模型(以混杂为预测变量建模)均被正确设定,参数g-formula的效率和稳定性都很高[18]。基于IPW加权建立伪人群方法的效率和稳定性都低于模型正确设定时的参数g-formula,且随着混杂维数的增加,IPW的变异性增加,会给数据集中少数受试者非常大的权重,导致其低效和不稳定性进一步增加[18, 21]。G估计的效率和稳定性通常介于参数g-formula和IPW之间,与MSMs相比,SNMs可以纳入暴露和混杂的交互项,这可能是G估计的效率高于IPW的原因[18]。
(4) 适用范围参数g-formula可用于估计较复杂的联合暴露(例如吸烟和每日≥30 min的体育锻炼对健康的联合效应),但当暴露是连续变量/具有多个水平的分类变量/具有多个随访时间点的二分类变量,且无感兴趣的暴露水平时,参数g-formula要估计每一种可能处理组合的平均结局,当有太多可能的假设处理水平可供比较时,计算量很大,模型解释变得很困难,同时也会增加模型误设的概率[1, 18]。当某一混杂水平下所有受试者均为暴露或均为非暴露,即违背了正性假设(给定的混杂水平下,没有接受某个处理水平概率为零的受试者)时,不能用IPW方法[1];IPW难以处理连续性暴露,且由于MSMs是边际的,因此无法纳入暴露和混杂的交互项。G估计可以纳入暴露和混杂的交互项[1, 19]。参数g-formula和IPW均可以用于连续性、分类的结局变量以及生存分析中;G估计在生存分析中采用的模型为基于SNMs的结构嵌套累计失效时间模型[22]。
上述G方法对随访次数均不做限制,但随着随访次数增加,失访比例可能增大。虽然G方法能够将失访视为另一种可能的治疗方式,从而通过二次加权均衡失访偏倚,但其需要假设失访是完全随机发生的。而在实际研究中,失访常与暴露或结局存在一定关联,因此在设计阶段采取一系列措施提高随访率是十分必要的,例如纳入主动性较高更易跟踪随访的受试者、设计的问卷尽可能易于理解和完成、确保在所有研究小组中保持高水平的随访等。此外,研究者应结合临床实际、文献报道、或进行预调查,判断研究纳入的暴露和协变量是否随时间变化,即判断是否存在需要控制的时依混杂,虽然在理论上G方法可以估计不随时间变化的暴露因素与结局间的因果效应,但其复杂程度要远高于传统的匹配、分层、倾向性评分等方法。本研究仅讨论了包含单个随访时间点结局事件(即随访终点结局事件Y)的因果效应估计,但研究者可根据实际研究问题将G方法拓展到包含了多个随访时间点结局事件(Yi)的因果效应估计中[23]。
(5) 计算和程序实现参数g-formula计算较复杂,因为涉及了蒙特卡洛模拟和bootstrap,可用Stata软件中的“gformula”命令或R软件中的“gformula”软件包实现;IPW可在大多数统计软件中轻松实现,可参考R软件包“ipw”;G估计计算较复杂,可通过Stata软件中的“stgest”命令、SAS软件中的“SURV”宏程序或R软件中的“DTRreg”软件包实现。
四、实例分析以2016年Naimi等[5]的研究报告中关于ART治疗对HIV感染者CD4计数影响的前瞻性研究数据为例,比较传统回归分析方法与3种G方法估计效应的准确性(表 2)。该研究调查了基线(t0)和第一次随访(t1)时的ART状态,分别用X0、X1表示(Xi=1为接受ART、Xi=0为未接受ART);基线的HIV病毒载量(C0)均 > 200拷贝/ml,在第一次随访时第二次治疗前测得的HIV病毒载量(C1)为时依混杂(C1=0表示≤200拷贝/ml,C1=1则相反),随访结束时测得的CD4计数(个/μl)为结局Y(因果图可参考图 1)。分别用传统线性回归方法,包括只考虑基线治疗状态X0和同时考虑两次治疗状态X0和X1的校正了C1的线性回归模型,以及3种可以控制时依混杂C1的G方法,估计ART与CD4计数间的因果关系。表 2中β0、β1分别代表X0、X1的回归系数,Δŷmean代表基线和第一次随访时均接受ART(X0=1且X1=1)与均未接受ART(X0=0且X1=0)分别对应的Y均值的差异。表 2中显示,G方法估计的β0和β1很接近,即在t0和t1时的ART对CD4计数的影响效应相同,而传统回归方法估计的β0和β1有较大差异;且G方法估计的Δŷmean均为50.0个/μl,即两次均接受ART的患者CD4计数平均增加50.0个/μl。传统回归方法则低估了ART与CD4计数间的因果效应,尤其是在只关注基线暴露对结局的影响效应时。

在纵向研究中,常常存在受过去暴露影响的时依混杂,但在实践中,通常被忽略或者直接使用传统方法进行调整,得到有偏因果效应估计值。G方法是在对暴露和混杂进行重复测量的纵向数据中,调整受过去暴露影响的时依混杂的方法。在一项关于2000-2016年控制时依混杂的相关研究文献的系统回顾中,使用G方法的文献虽然在逐年增加,但也仅占总文献量的20%,且其中有60.9%集中在HIV、心肺疾病、肾病或精神健康领域,80.3%采用的方法是IPW[24]。因此,本研究可为不同领域的研究人员在处理纵向数据的因果推断实践中提供参考,由于G方法包括的3种方法的适用范围、估计的有效性和稳定性有差异,研究者应根据实际情况,选择适合的G方法控制时依混杂,从而获得无偏因果效应估计值。
利益冲突 所有作者均声明不存在利益冲突
| [1] |
Mansournia MA, Etminan M, Danaei G, et al. Handling time varying confounding in observational research[J]. BMJ, 2017, 359: j4587. DOI:10.1136/bmj.j4587 |
| [2] |
Mortimer KM, Neugebauer R, van der Laan M, et al. An application of model-fitting procedures for marginal structural models[J]. Am J Epidemiol, 2005, 162(4): 382-388. DOI:10.1093/aje/kwi208 |
| [3] |
Danaei G, Rodríguez LAG, Cantero OF, et al. Observational data for comparative effectiveness research: an emulation of randomised trials of statins and primary prevention of coronary heart disease[J]. Stat Methods Med Res, 2011, 22(1): 70-96. DOI:10.1177/0962280211403603 |
| [4] |
Williamson T, Ravani P. Marginal structural models in clinical research: when and how to use them?[J]. Nephrol Dial Transplant, 2017, 32(Suppl 2): ii84-90. DOI:10.1093/ndt/gfw341 |
| [5] |
Naimi AI, Cole SR, Kennedy EH. An introduction to G methods[J]. Int J Epidemiol, 2016, 46(2): 756-762. DOI:10.1093/ije/dyw323 |
| [6] |
Robins JM. A new approach to causal inference in mortality studies with a sustained exposure period-application to control of the healthy worker survivor effect[J]. Math Model, 1986, 7(9/12): 1393-1512. DOI:10.1016/0270-0255(86)90088-6 |
| [7] |
Westreich D, Cole SR, Young JG, et al. The parametric g-formula to estimate the effect of highly active antiretroviral therapy on incident AIDS or death[J]. Stat Med, 2012, 31(18): 2000-2009. DOI:10.1002/sim.5316 |
| [8] |
吴诗蓝, 周价, 李逊, 等. Parametric g-formula方法在因果分析中的应用[J]. 中华流行病学杂志, 2019, 40(10): 1310-1313. Wu SL, Zhou J, Li X, et al. Application of parametric g-formula in causal analysis[J]. Chin J Epidemiol, 2019, 40(10): 1310-1313. DOI:10.3760/cma.j.issn.0254-6450.2019.10.025 |
| [9] |
Robins JM, Hernán MÁ, Brumback B. Marginal structural models and causal inference in epidemiology[J]. Epidemiology, 2000, 11(5): 550-560. DOI:10.1097/00001648-200009000-00011 |
| [10] |
Imai K, Ratkovic M. Robust estimation of inverse probability weights for marginal structural models[J]. J Am Stat Assoc, 2015, 110(511): 1013-1023. DOI:10.1080/01621459.2014.956872 |
| [11] |
郭威. 基于统计学习的逆概率加权方法研究及其在医学中的应用[D]. 上海: 中国人民解放军海军军医大学, 2018. DOI: CNKI:CDMD:1.1018.084023. Guo W. Research and application in medical studies of inverse probability weighting based on statistical learning[D]. Shanghai: Naval Medical University, 2018. DOI: CNKI:CDMD:1.1018.084023. |
| [12] |
Rubin DB. On principles for modeling propensity scores in medical research[J]. Pharmacoepidemiol Drug Safe, 2004, 13(12): 855-857. DOI:10.1002/pds.968 |
| [13] |
Taylor F, Huffman MD, Macedo AF, et al. Statins for the primary prevention of cardiovascular disease in the Elderly[J]. Cochrane Database Syst Rev, 2013, 2013:CD004816. DOI:10.1002/14651858.CD004816.pub5 |
| [14] |
Picciotto S, Neophytou AM. G-estimation of structural nested models: recent applications in two subfields of epidemiology[J]. Curr Epidemiol Rep, 2016, 3(3): 242-251. DOI:10.1007/s40471-016-0081-9 |
| [15] |
Robins JM. The analysis of randomized and non-randomized AIDS treatment trials using a new approach to causal inference in longitudinal studies[M]//Sechrest L, Freeman H, Mulley A. Health service research methodology: a focus on AIDS. Washington: U.S. Public Health Service, National Center for Health Services Research, 1989: 113-159.
|
| [16] |
Hernán MA, Cole SR, Margolick J, et al. Structural accelerated failure time models for survival analysis in studies with time-varying treatments[J]. Pharmacoepidemiol Drug Saf, 2005, 14(7): 477-491. DOI:10.1002/pds.1064 |
| [17] |
Shakiba M, Mansournia MA, Salari A, et al. Accounting for time-varying confounding in the relationship between obesity and coronary heart disease: analysis with G-estimation: the ARIC study[J]. Am J Epidemiol, 2018, 187(6): 1319-1326. DOI:10.1093/aje/kwx360 |
| [18] |
Daniel RM, Cousens SN, de Stavola BL, et al. Methods for dealing with time-dependent confounding[J]. Stats Med, 2013, 32(9): 1584-1618. DOI:10.1002/sim.5686 |
| [19] |
Robins JM, Hernán MA. Estimation of the causal effects of time-varying exposures[M]//Fitzmaurice G, Davidian M, Verbeke G, et al. Longitudinal Data Analysis. New York: Chapman and Hall/CRC Press, 2009: 553-599. DOI: 10.1201/9781420011579.ch23.
|
| [20] |
Wilsgaard T, Vangen-Lø nne AM, Mathiesen E, et al. Hypothetical interventions and risk of myocardial infarction in a general population: application of the parametric g-formula in a longitudinal cohort study-the Tromsø Study[J]. BMJ Open, 2020, 10(5): e035584. DOI:10.1136/bmjopen-2019-035584 |
| [21] |
Kang JDY, Schafer JL. Demystifying double robustness: a comparison of alternative strategies for estimating a population mean from incomplete data (with discussion and rejoinder)[J]. Stat Sci, 2007, 22(4): 523-539. DOI:10.1214/07-STS227 |
| [22] |
Vansteelandt S, Joffe M. Structural nested models and g-estimation: the partially realized promise[J]. Stat Sci, 2014, 29(4): 707-731. DOI:10.1214/14-STS493 |
| [23] |
Clare PJ, Dobbins TA, Mattick RP. Causal models adjusting for time-varying confounding-a systematic review of the literature[J]. Int J Epidemiol, 2019, 48(1): 254-265. DOI:10.1093/ije/dyy218 |