 2017, Vol. 38
2017, Vol. 38文章信息
- 聂志强, 欧艳秋, 曲艳吉, 袁海云, 刘小清.
- Nie Zhiqiang, Ou Yanqiu, Qu Yanji, Yuan Haiyun, Liu Xiaoqing.
- 临床生存数据新视角:竞争风险模型
- A new perspective of survival data on clinical epidemiology:introduction of competitive risk model
- 中华流行病学杂志, 2017, 38(8): 1127-1131
- Chinese journal of Epidemiology, 2017, 38(8): 1127-1131
- http://dx.doi.org/10.3760/cma.j.issn.0254-6450.2017.08.026
-
文章历史
收稿日期: 2016-12-19




临床数据常表现为随访纵向生存资料。由于失访等原因终止时间仍未观察到终点事件,某些研究对象确切的失效时间无法获得,而只知失效事件发生在某特定时间之后的现象称为右删失。右删失数据是临床研究中最常见的生存数据类型,例如患者因术后早期死亡而观察不到远期术后并发症结果,此时若忽略死亡带来的偏倚而直接采用经典Cox分析并发症影响因素是否合理?传统生存分析回归前提是假设删失时间与失效时间独立,即结局不存在竞争风险,该结局是单一终点[1]。临床生存数据常常伴有多个结局,其间可能存在竞争关联关系,此时若使用传统生存分析可能高估累积发生率[2-3]。鉴此,适用于临床右删失数据的竞争风险模型(competing risk model)成为近期临床流行病研究热点[4-6]。本文旨在阐述临床流行病研究中竞争风险的相关概念及其程序的实现。
基本原理竞争风险是指在观察队列中,存在某种已知事件可能会影响另一种事件发生的概率或者是完全阻碍其发生,则可认为前者与后者存在竞争风险[7]。竞争风险模型适用于多个终点的生存数据[8],关心终点A与不关心终点B非相互独立且存在竞争关系,A发生导致B不会发生,例如慢性肾病患者死亡与透析[9]、心肌梗死患者导致的死亡与其他死因[10],生殖细胞癌患者死亡与继发恶性肿瘤[11],先天性心脏(先心)病患者术后死亡与随访终点肺静脉梗阻存在竞争风险[12]。临床上常见术后死亡患者无法获取关心终点,故术后死亡与关心终点存在竞争风险。竞争风险的单因素分析常为估计关心终点发生率,多因素分析常为估计预后影响因素及效应值。竞争风险模型示意如图 1。

|
| 注:λ为竞争风险函数 图 1 竞争风险模型示意图 |
1.估计粗发生率(单因素分析):
(1) Kaplan-Meier边际回归(KM)法:传统KM法只能处理右删失单一结局的资料。生存函数S(t),又称生存率,表示某个体经历时间t后尚未发生结局事件的概率,在无删失值时,S(t)=Pr(T>t),若有删失值时S(t)=P1×P2…Pi=S(ti-1)×Pi,其中T为真实失效时间,P1(i=1,2,…,i)为各时段的生存概率。累积发生函数F(t)=1-S(t)=Pr(T<t),某个体在时刻t前发生结局事件概率。KM法对应生存曲线,差异性检验对应log-rank等检验。当存在竞争风险时采用传统KM法会高估各变量的累积发生率[13]。
(2) 累积发生函数(cumulative incidence function,CIF):又称累积发生率,即,CIFk(t)=Pr(T≤t,D=k),函数CIFk(t)表示在时间t及其他类事件之前第k类事件的概率,D表示发生的事件的类型。当存在竞争风险时,结局不再仅仅是生存、死亡,此时CIF≠F(t),而CIF意为各自的关心事件累积发生函数、竞争事件累积发生函数。CIF假设事件每次发生有且仅有一种,具有期望属性,即各类别CIF之和等于复合事件CIF。CIF对应曲线Nelson-Aalen累积风险曲线,差异性检验对应Gray’s检验。当存在竞争风险时应该采用CIF估计粗发生率,因为KM法无论单独估计A、B、AB合计的事件发生率,KM法均高于CIF法(图 2)。

|
| 图 2 累积发生函数(CIF)与Kaplan-Meier边际回归(KM)法估计发生率的示意图 |
2.风险函数回归(多因素分析):风险函数[hazard function,h(t)]即t时刻存活的观察个体在t时死亡瞬时的概率强度,公式为
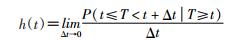
若无竞争风险,即满足假设“删失独立”的前提下,Cox比例风险模型为log[λ(t)]=log[λ0(t)]+Xβ,其中λ(t)称净危险率,λ0(t)为基线风险函数,即协变量向量为0时的风险函数,可写成λ(t)=λ0(t)exp(Xβ)。若存在竞争风险,此时“删失独立”条件不满足,存在两种模型:原因别风险函数(cause-specific hazard function,CS)、部分分布风险函数(subdistribution hazard function,SD),后者又称CIF回归模型、Fine-Gray模式[14]。
CS公式为
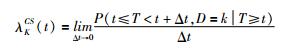
其中CS表示t时刻未发生任何事件的观察个体发生第k类事件的瞬时概率强度。
SD公式为
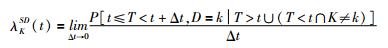
其中SD表示t时刻未发生第k类事件的观察个体发生第k类事件的瞬时概率强度。
上述两式中λk(t)称为粗危险率,存在竞争事件时粗危险率≠净危险率,故采用经典Cox分析HR值及其95%CI存在偏倚。
上述两模型都有各自独特的解释,故需要同时提供两种模型结果。Lau等[6]提出CS适合病因学研究,SD适合个人风险预测研究;Koller等[15]提出SD倾向于估计疾病风险与预后。总之,CS适合回答病因学问题,回归系数反映了协变量对无事件风险集对象中主要终点A发生率增加的相对作用;SD适合建立临床预测模型及风险评分,仅对终点A绝对发生率感兴趣。图 3为关心事件A、竞争事件B、风险集为t时未观察到事件且具有A风险的对象合集,CS与SD两模型差异在于风险集是否包含竞争事件B。例如,时间点0风险集为10个观察对象,时间点2风险集CS模型为8人=10-1A-1B,SD模型为9人=10-1A,事件A风险分别为0/9、0/8,时间点3风险集CS模型为6人=8-2B-0A,SD模型为9人=9-0A,事件A风险分别为2/9、2/6。

|
| 图 3 部分分布风险函数(SD)与原因别风险函数(CS)示意图 |
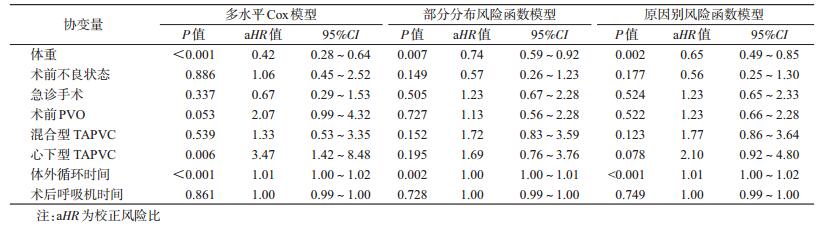
本实例选自广东省心血管病研究所等全国多中心10年连续入组先心病数据库[12],分析病种为完全肺静脉异位引流(TAPVC)。本例关心主要终点事件为远期随访的术后肺静脉狭窄或梗阻(PVO)。依临床专业角度,术后死亡患者无法获取到远期PVO数据,故二者存在竞争风险关系(图 4)。结局变量赋值为0=存活、1=术后PVO、2=死亡(竞争事件)。次要终点为不同TAPVC类型术后中远期死亡率差异,死亡无竞争事件故采用KM法即可。经过单因素(P<0.1) 及专业意义入选多因素分析,多重共线性诊断采用Belsley等[16]标准,多因素SD、CS模型最终入选协变量为体重、术前不良状态、急诊手术、术前PVO、混合型TAPVC、心下型TAPVC、体外循环时间、术后呼吸机时间。

|
| 图 4 先心病完全肺静脉异位引流术后肺静脉狭窄或梗阻(PVO)竞争风险模型 |
经CIF法估计患者术后PVO率1、6、12和24个月分别为0.95%、5.83%、7.71%和10.88%,而若用KM法则分别为1.00%、6.24%、8.28%和11.74%,均高于CIF法。图 5为两手术组的Nelson-Aalen累积风险曲线,Gray检验P=0.336,两手术组PVO发生率的差异无统计学意义。表 1为术后PVO多水平Cox分析及SD、CS风险模型,不同模型所得HR值(95%CI)不一致,且效应量SD≤CS。本例体重因素,多水平Cox模型aHR=0.42(95%CI:0.28~0.64),SD模型aHR=0.74(95%CI:0.59~0.92),CS模型aHR=0.65(95%CI:0.49~0.85),“体重”为PVO保护因素,但Cox模型高估了HR值。而心下型TAPVC因素,多水平Cox模型aHR=3.47(95%CI:1.42~8.48),SD模型aHR=1.69(95%CI:0.76~3.76),CS模型aHR=2.10(95%CI:0.92~4.80),Cox模型显示心下型为危险因素,而SD、CS模型显示该因素的差异无统计学意义。本例SD模型提示“体重”因素相应减少术后PVO发生率的26%,CS模型提示减少术后PVO原因别风险35%;“体外循环时间”因素增加术后PVO相应的发生率0.7%,增加术后PVO原因别风险0.9%;其他因素解释以此类推。

|
| 图 5 Sutureless与Conventional手术组分组Nelson-Aalen累积风险曲线 |
在生物医学研究中普遍存在生存数据竞争风险,如何正确运用竞争风险SD、CS模型解决变量的真实效应致关重要。生存数据阳性事件常见于全因死亡、原因别死亡、主要不良事件(复合终点),当探讨具体原因别风险时,全因死亡与简单合并复合终点均不能提供精准估计效应值[17]。在研究设计时需要考虑竞争风险的样本量[18],否则将导致过高估计事件发生率和错误估计HR值。竞争事件比例>10%采用传统方法可造成严重偏倚,而<10%可能出现假阳性或假阴性,本文实例中竞争事件率为7.8%故传统Cox分析各协变量HR值偏倚较大,心下型TAPVC因素甚至产生假阳性。
竞争风险模型设置关心终点为A,非关心终点为B。但有时也存在同时关心AB的复合终点事件,此时若采用KM法估计粗死亡率,将另一个事件的发生作为右删失处理,单独分析A或B会高估事件率,而若采用简单的复合终点作为结局有可能损失单项指标精确性,重要复合指标不一定存在临床意义。本文主要关心终点为PVO,死亡会影响PVO产生截尾数据即竞争风险,反之死亡为主要终点则PVO与死亡不存在竞争风险,故表 1仅提供PVO的CS及SD模型,死亡则不需要计算这两模型。但一些研究,如心血管死因及其他原因别死因均为关心终点,建议同时提供两终点对应的竞争风险模型。
竞争风险模型效应量SD≤CS。本文SD与CS的HR值95%CI接近,关联方向基本一致。但SD与CS结论亦有不一致,如Austin等[5]研究中CS模型提示肿瘤仅增加非心血管病原因别死亡风险,SD模型提示肿瘤降低心血管死亡率增加非心血管病死亡率,即肿瘤降低心血管病死亡率是由于对应的非心血管原因别风险增加所致。这也是为何强调竞争风险模型必须同时提供2个模型的意义所在[19]。CS回答上游的流行病病因学问题,SD回答下游的临床绝对发生率问题,SD模型越来越多的被用于临床预测模型和风险评分[20]。
本研究以非参数CIF及右删失半参数法CS、SD为基础,并提供了SAS 9.4分析程序,临床生存数据复杂多样,总结右删失数据竞争风险模型具有良好的临床指导意义,罕见的左删失、区间删失数据、参数法、非等比例风险数据还有待进一步研究。
附录:SAS 9.4竞争风险模型程序
/*cohort为数据名,time为生存时间,结局y多类别间存在竞争风险,赋值编码0=生存、1=主要关心结局A、2=竞争风险事件B*/
/*cov1-covn为协变量名*/
ods graphics on;ods html dpi=300;
% cif(data=cohort,out=cif1_data,time=time,status=y,event=1,censored=0);/*不分组A总的CIF*/
% cif(data=cohort,out=cif1_data,time=time,status=y,event=1,censored=0,group=treat);/*手术组treat组间gray’s比较A的CIF*/
% cif(data=cohort,out=cif2_data,time=time,status=y,event=2,censored=0,group=treat);/*手术组treat组间gray’s比较B的CIF*/
/*A校正CIF,SD模型*/
proc phreg data=cohort plots(overlay=stratum)=cif;
model time*y(0)=cov1~covn /eventcode = 1 rl;run;
/*A的CS模型,y(0,2) 表示删失事件,zph为Schoenfeld残差图、assess为鞅式残差图,均可验证PH比例风险假设*/
proc phreg data=cohort zph;
model time*y(0,2)=cov1~covn /ties=efron rl;assess ph/resample seed=1234;run;
proc phreg data=cohort plots(overlay=stratum)=cif;/*B校正CIF,SD模型*/
model time*y(0)=cov1~covn /eventcode=2 rl;run;
proc phreg data=cohort zph;/*B的CS模型*/
model time*y(0,1)=cov1~covn /ties=efron rl;assess ph/resample seed=1234;run;
利益冲突: 无
| [1] | Fleming TR, Harrington DP.Counting processes and survival analysis[M]. 2nd ed. Hoboken, New Jersey: John Wiley & Sons, 2013. |
| [2] | Putter H, Fiocco M, Geskus RB. Tutorial in biostatistics:competing risks and multi-state models[J]. Stat Med, 2007, 26(11): 2389–2430. DOI:10.1002/sim.2712 |
| [3] | Berry SD, Ngo L, Samelson EJ, et al. Competing risk of death:an important consideration in studies of older adults[J]. J Am Geriatr Soc, 2010, 58(4): 783–787. DOI:10.1111/j.1532-5415.2010.02767.x |
| [4] | Andersen PK, Perme MP. Inference for outcome probabilities in multi-state models[J]. Lifetime Data Anal, 2008, 14(4): 405–431. DOI:10.1007/s10985-008-9097-x |
| [5] | Austin PC, Lee DS, Fine JP. Introduction to the analysis of survival data in the presence of competing risks[J]. Circulation, 2016, 133(6): 601–609. DOI:10.1161/CIRCULATIONAHA.115.017719 |
| [6] | Lau B, Cole SR, Gange SJ. Competing risk regression models for epidemiologic data[J]. Am J Epidemiol, 2009, 170(2): 244–256. DOI:10.1093/aje/kwp107 |
| [7] | Gooley TA, Leisenring W, Crowley J, et al. Estimation of failure probabilities in the presence of competing risks:new representations of old estimators[J]. Stat Med, 1999, 18(6): 695–706. DOI:10.1002/(SICI)1097-0258(19990330)18:6<695::AID-SIM60>3.0.CO;2-O |
| [8] | Klein JP. Competing risks[J]. WIREs Comput Stat, 2010, 2(3): 333–339. DOI:10.1002/wics.83 |
| [9] | Beydoun MA, Beydoun HA, Mode N, et al. Racial disparities in adult all-cause and cause-specific mortality among us adults:mediating and moderating factors[J]. BMC Public Health, 2016, 16: 1113. DOI:10.1186/s12889-016-3744-z |
| [10] | Puddu PE, Piras P, Menotti A. Lifetime competing risks between coronary heart disease mortality and other causes of death during 50 years of follow-up[J]. Int J Cardiol, 2017, 228: 359–363. DOI:10.1016/j.ijcard.2016.11.157 |
| [11] | Kier MG, Hansen MK, Lauritsen J, et al. Second malignant neoplasms and cause of death in patients with germ cell cancer:a danish nationwide cohort study[J]. JAMA Oncol, 2016, 2(12): 1624–1627. DOI:10.1001/jamaoncol.2016.3651 |
| [12] | Shi GC, Zhu ZQ, Chen JM, et al. Total anomalous pulmonary venous connection:the current management strategies in a pediatric cohort of 768 patients[J]. Circulation, 2017, 135(1): 48–58. DOI:10.1161/CIRCULATIONAHA.116.023889 |
| [13] | Varadhan R, Weiss CO, Segal JB, et al. Evaluating health outcomes in the presence of competing risks:a review of statistical methods and clinical applications[J]. Med Care, 2010, 48(6 Suppl): S96–105. DOI:10.1097/MLR.0b013e3181d99107 |
| [14] | Fine JP, Gray RJ. A proportional hazards model for the subdistribution of a competing risk[J]. J Am Stat Assoc, 1999, 94(446): 496–509. DOI:10.1080/01621459.1999.10474144 |
| [15] | Koller MT, Raatz H, Steyerberg EW, et al. Competing risks and the clinical community:irrelevance or ignorance?[J]. Stat Med, 2012, 31(11/12): 1089–1097. DOI:10.1002/sim.4384 |
| [16] | Belsley DA, Kuh E, Welsch RE.Regression diagnostics:identifying influential data and sources of collinearity[M]. Hoboken, New Jersey: John Wiley & Sons, 2005. |
| [17] | Mell LK, Jeong JH. Pitfalls of using composite primary end points in the presence of competing risks[J]. J Clin Oncol, 2010, 28(28): 4297–4299. DOI:10.1200/JCO.2010.30.2802 |
| [18] | Pintilie M. Dealing with competing risks:testing covariates and calculating sample size[J]. Stat Med, 2002, 21(22): 3317–3324. DOI:10.1002/sim.1271 |
| [19] | Latouche A, Allignol A, Beyersmann J, et al. A competing risks analysis should report results on all cause-specific hazards and cumulative incidence functions[J]. J Clin Epidemiol, 2013, 66(6): 648–653. DOI:10.1016/j.jclinepi.2012.09.017 |
| [20] | Wolbers M, Koller MT, Witteman JCM, et al. Prognostic models with competing risks:methods and application to coronary risk prediction[J]. Epidemiology, 2009, 20(4): 555–561. DOI:10.1097/EDE.0b013e3181a39056 |