

DOI: 10.11991/yykj.201506036

 ,
,
,
,
,
,
,
,
,
,
,
,
随着互联网的快速发展,微博已经成为使用最广泛的互联网应用之一[1]。微博是一个基于粉丝关注关系的信息分享、传播以及获取的社交平台,它将网民从原本单纯的信息接收者变成了接收和发布信息的完全参与者[2]。庞大的微博用户群以及产生的海量数据信息,隐藏着巨大的商业价值和社会价值[3]。分析和监测微博所包含的信息,能够了解广大网民对某产品、人物或者事件的关注程度和情感变化,为决策者提供实时科学的理论依据[4]。当前情感分析已经成为自然语言处理领域主要的分支和热点话题,而基于微博的情感分析就是其中一个研究热点。本文是对微博的倾向性进行分析,即对微博的情感倾向性进行分类。利用点互信息和微博索引系统构造了一部适用于微博情感分析的情感词典,并且选取了一组有效的特征组合,完成微博情感分析的任务。
1 相关技术介绍 1.1 情感分析情感分析是从用户发布的微博信息中识别情感信息,判断微博句子情感倾向性或得出用户表达的观点是“同意”还是“反对”。谢丽星[5]提出基于表情符号、情感词典、SVM的层次结构的多策略方法。此方法通过统计表情符号和情感词的个数计算微博的情感倾向,但是对于不明显包含情感特征的微博有一定的局限性。杜振雷等[6]提出一种基于情感词典和SVM相结合的微博情感分析的方法,该方法首先构造了一个较完整的情感词典,利用微博的语义特征和情感特征的情感强度为特征权重,借助多特征融合方法构建中文微博情感倾向性分析模型。Saif等[7]通过对英文微博的研究,提出一种新的附加语义的特征的方法,该方法对实体提取语义作为附加的特征,并计算相关的概念以及情感倾向,通过实验表明该方法能取得非常好的效果。
1.2 点互信息点互信息是信息论中的一个重要的概念,通常用来表示一个随机变量包含另一个随机变量的信息量,一般用熵来表示[8]。点互信息的表达式为
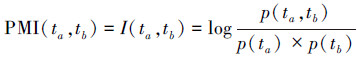 |
(1) |
式中:ta、tb分别表示2个事件,PMI(ta,tb)表示事件ta包含事件tb的信息量。
中文词语的情感倾向性值计算方法是利用点互信息计算的方法。基于点互信息的词语情感倾向性计算方法首先人工选取一定量的基准词,通过计算基准词与检索系统中词语的共现概率,来确定该词语的情感倾向性以及情感倾向值。设褒义基准词集合为C={C1,C2,…,Cn},贬义词集合为D={D1,D2,…,Dn},则对于某个单词t,基于互信息的词语的情感倾向值为
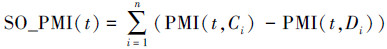 |
(2) |
点互信息PMI的计算如公式为
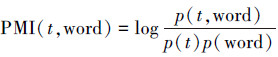 |
(3) |
式中:p(t,word)表示在语料库中单词t和基准词word共现的概率,p(t)表示单词t在语料库中出现的概率。
1.3 支持向量机支持向量机(SVM)是定义在特征空间上的函数间隔最大分类器[9],支持多分类、间隔最大化使它有别于感知机。当训练数据近似线性可分时,通过函数间隔最大化,SVM能够学习一个线性分类器,即线性可分支持向量机;当训练数据线性不可分时,所采取的方法是进行一个非线性变换,将非线性问题变换为线性问题,通过解变换后的线性问题的方法求解原来的非线性问题。支持向量机模型通过间隔最大化学习得到分离超平面,分离超平面对应公式为
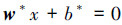 |
(4) |
相应的分类决策函数为
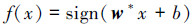 |
(5) |
式中:w表示分离超平面的法向量,b表示分离超平面的截距,可以用(w,b)表示分类决策函数。分离超平面将实例空间划分成两部分,分别是正类和负类。
1.4 评测指标采用COAE 2014评测所用的评价指标,包括召回率、精确率和F1值。召回率用来衡量成功检索到相关文本的可能性,是查询到的相关文本的数量占语料库中所有相关文本的数量的比例。精确率用来衡量检索出来的文本的准确性,是查询到的相关文本的数量占查询到的所有文本的总数的比例。而F1值是召回率和精确率的调和平均数。F1值的计算公式为
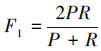 |
(6) |
式中:P是精确率,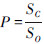
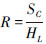
精确率和召回率都是针对特定正类或者负类进行的单一评价,无法表明在整个系统的性能。为了评价数据集上的整体指标,可以使用另外2种评价指标:宏平均和微平均。宏平均是每一个类的性能指标的算数平均值,而微平均是每一个实例的性能指标的算数平均。
2 情感词典的构建 2.1 情感词典的构建过程情感词典的构建过程如图 1所示。

|
| 图 1 情感词典的构建步骤 |
1) 合并去重。本文将基础情感词典《知网》、《学生褒贬义词典》、《ntusd情感词典》、《tsinghua褒贬义词典》组合成一部新的情感词典,并将新情感词典中重复的词条过滤。
2) 使用同义词词林扩展。利用《同义词词林》对4部基础情感词典进行扩展,得到扩展后的情感词典。
3) 微博获取及预处理。抓取的微博中包含了大量的html标记、http链接以及噪声等,微博需要一系列的预处理才能应用到建立索引的过程中去。预处理的过程包括噪声消除、标签过滤、信息提取等步骤,最终抓取的微博处理成普通的短文本形式。
4) 建立索引。传统的方法主要利用的是Google或者百度等搜索引擎,而本文构建了面向大规模微博的数据库,不仅应用简单,更符合微博语言的特点,得到更精确的统计结果。
5) 利用PMI得到词语的倾向值。对词典中的每一个词语求得褒贬基准词集合的SO_PMI值,对SO_PMI值归一化后即为该词语的倾向性值。传统的方法利用基准词和PMI计算某个词语是否是情感词语,但是本文中已经有了情感词典,只需要利用PMI求得情感倾向值。
6) 得到带情感倾向值的情感词典。将情感倾向值和情感词组合在一起,构成带情感倾向性值的情感词典。
2.2 情感词典的优化在情感词典中,有些情感词语在微博中出现的次数比较少,导致情感词语的情感倾向性有错误,因此在本节中,介绍对扩展后词典的优化方法。图 2为情感词典的优化步骤。

|
| 图 2 情感词典的优化步骤 |
1) 去除不常见的词语。在扩展后的词典中有些词语在微博中出现的次数太少,造成PMI值为0,所以在这一步中需要去除这些不常见的词语。设定一个阈值θ,利用微博检索系统,将检索后出现词频数小于阈值θ的情感词去除。
2) 去除情感倾向值在-0.1~+0.1的词语。在情感词典中,情感词语的倾向性值用来区别词语的倾向性。在本文中设定一个阈值α,对于值在-α~+α的情感倾向性值很难用来区分词语的倾向性,因此需要去除这一部分词语。
3) 将正或负词典中的倾向值为负或正的取反。在正向情感词典中倾向值为负的词语或者在负向情感词典中会有倾向值为正的词语,本文中这类词语并没有去除,只是进行倾向性值取反求得正确的倾向性值。最终的情感词语的数量如表 1所示,本文列出了部分情感词语如表 2所示。
| 部分褒义情感词典 | 部分贬义情感词语 | ||
| 词语 | 情感倾向性值 | 词语 | 情感倾向性值 |
| 爱戴 | 0.728 | 暗算 | -0.513 |
| 盎然 | 0.469 | 跋扈 | -0.526 |
| 不朽 | 0.674 | 霸占 | -0.913 |
| 灿烂 | 0.694 | 残害 | -0.636 |
| 魅力 | 0.847 | 讨厌 | -0.821 |
2.3 其他词典的构建
除了情感词典以外,对于能够影响情感分析的表情符号、连词、副词和网络用语等也分别构造了相对应的词典,4部词典分别为表情符号词典、连词词典、副词词典和网络用语词典。
3 基于SVM的微博情感分析传统的微博情感分析主要利用机器学习,采用一步三分类或者两步三分类的判定方法。一步三分类是将微博情感分析通过分类器直接把微博分成正类、负类和中性。二步三分类首先是将微博通过分类器直接分成主客观,然后在主客观分类的基础上利用另外一个分类器再将主观微博分成正类和负类。在本论文实验中,采用一步三分类的方法,利用一个分类算法进行分类,避免使用两步三分类方法繁琐的步骤以及每一步分类错误的累加,提高微博情感分析的效果。如图 3、4所示是基于SVM的微博情感分析的过程。

|
| 图 3 训练阶段过程 |

|
| 图 4 测试阶段过程 |
在训练阶段,使用训练数据,经过预处理、词性标注、特征提取后,再经过LibSVM训练,能够得到SVM模型。在测试阶段,使用测试数据,经过预处理、词性标注、特征提取以后,再经过SVM模型得到分类结果。
微博是短文本的一种形式,内容比较少。相对于长文本,特征比较稀疏并且难以提取。微博中存在各种话题,话题能够影响微博的情感分析。因此,对于微博的特征选择来说,优秀的特征能够对微博的情感分析带来巨大的影响。情感词典的规模和情感词语的倾向性能够影响情感分析的质量。通过以上分析,实验采用的特征如表 3所示。
| 序号 | 特征 | 特征描述 |
| 1 | 情感词典 | 褒义词、贬义词 |
| 2 | 网络用语词典 | 正向网络用语、负向网络用语 |
| 3 | 表情符号词典 | 正向表情符号、负向表情符号 |
| 4 | 连词词典 | 连词 |
| 5 | 副词词典 | 副词 |
| 6 | 标点符号 | !、! |
| 7 | 标点符号 | ?、? |
| 8 | 标点符号 | “…”、”…” |
| 9 | 上下文 | 动词 |
| 10 | 上下文 | 形容词 |
| 11 | 链接 | http://、网页链接 |
| 12 | @ | @+微博用户名 |
| 13 | // | 评论+// |
| 14 | # | #话题# |
4 实验结果及分析 4.1 特征选择对比实验
传统的特征选择方法固定地选择某些特征组合,但是有一些特征对情感分析的效果不明显,因此本文利用不同的特征组合对比实验进行特征的选择。本实验采用2折交叉验证,实验数据为COAE 2014微博标注数据集。实验结果用精确率、召回率和F1值表示。表 4列出了精确率、召回率和F1值较好的几种组合。
| 序号组合 | 褒义 | 褒义 | ||||
| P | R | F1 | P | R | F1 | |
| 1~7、13 | 0.810 | 0.726 | 0.767 | 0.784 | 0.732 | 0.757 |
| 1~8、13 | 0.811 | 0.712 | 0.758 | 0.796 | 0.817 | 0.752 |
| 1~10、13 | 0.790 | 0.735 | 0.761 | 0.782 | 0.715 | 0.747 |
| 1~13 | 0.754 | 0.690 | 0.721 | 0.731 | 0.707 | 0.719 |
由表 4可知,当特征组合为情感词典、网络用语词典、表情符号词典、连词词典、副词词典、“?”、“!”“//”时,SVM算法得到了最好的F1值,比其他特征组合的F1值略高,说明这组特征组合是有效的,因此采用该特征组合为实验的特征。链接特征只是引用了一组链接,没有明显的提供可区别的情感分类的有效信息。“@”符号后面跟着用户名,因此也没有提供分类的信息。虽然双引号的特征能够表明用户的态度,但是由于在微博中出现的次数极少,因此无法提供过多的分类信息。“#”代表了话题,但是话题一般是客观公正的,也无法进行情感分类。由于情感词典中的情感词大多数为动词和形容词,但是动词和形容词不一定都是情感词,因此动词和形容词作为特征也无法进行情感分类。经过以上的分析可知,本实验中选择的特征组合有效,可以用在微博的情感分类任务中。
4.2 情感词典对比实验为了验证构建的情感词典的有效性,本实验利用4部基础情感词典、合并去重词典、扩展词典以及优化后词典等7部情感词典做对比实验。实验数据为COAE 2014微博标注数据集,采用2折交叉验证,实验结果用精确率、召回率和F1值,如表 5所示。
| 情感词典编号 | 褒义 | 贬义 | ||||
| P | R | F1 | P | R | F1 | |
| 1 | 0.735 | 0.686 | 0.710 | 0.726 | 0.654 | 0.688 |
| 2 | 0.683 | 0.701 | 0.692 | 0.679 | 0.698 | 0.688 |
| 3 | 0.745 | 0.723 | 0.734 | 0.745 | 0.700 | 0.721 |
| 4 | 0.692 | 0.614 | 0.651 | 0.753 | 0.715 | 0.734 |
| 5 | 0.748 | 0.734 | 0.741 | 0.756 | 0.723 | 0.739 |
| 6 | 0.652 | 0.612 | 0.631 | 0.634 | 0.656 | 0.645 |
| 7 | 0.783 | 0.742 | 0.762 | 0.776 | 0.743 | 0.759 |
由表 5可知,在对比实验中,优化后的情感词典的F1值高于合并词典、扩展后的情感词典以及4部基础情感词典。4部基础情感词典由于包含的情感词语很少,在微博情感分类的时候无法覆盖整个微博数据集,导致F1值较低。扩展后的情感词典中的许多情感词语的情感倾向性值与实际值相反,因此F1值也很低。而合并词典在SVM分类算法中和优化后情感词典中情感词语的数量比较多,F1值也相对较高,但是词典中情感词语的数量仍然太少,在处理大规模微博时,合并词典仍旧无法处理情感分析的任务。通过以上的实验结果及分析,文中构建的情感词典有效,并且能够处理情感分析的任务。
4.3 不同算法的对比实验为了验证本文中构建的情感词典以及选择的特征组合有效,本论文选取了COAE 2014任务四中排名前二的方法作为baseline,2种方法具体的实现系统为:MI&TLAB和hit[10]。使用4.1节中选择出的特征组合,使用LibSVM进行褒贬分类。
MI&TLAB在任务四中排名第一,有5项指标获得第一名。该系统首先构造了包含16 702个词语的情感词典;然后,根据情感词典筛选出带有情感词语的微博句子,并且将筛选出的句子组合成具有情感倾向的候选集;最后,针对候选集中的每一个微博句子判断情感倾向性,计算出概率,按照概率大小得到最终的结果;在实验阶段,选取词、词性、情感词典作为分类的特征,采用SVM_Multi进行分类。
hit在任务四中排名第二。该系统提出一个主客观分类和褒贬分类融合的评估情感倾向性的模型。首先,使用改进的LR模型构建一个能够判别主客观的分类模型,并结合情感词典构建褒贬模型;然后将主客观模型和褒贬模型进行融合,构建情感倾向性强度模型选出较强情感微博;最后使用褒贬分类模型判断微博最终的倾向性。
由表 6可知,对于情感倾向为正的分类,基于SVM的方法在精确率和F1值略高于第二名而低于第一名,但是召回率却比第一名和第二名都低;对于情感倾向为负的分类,基于SVM的方法在精确率上比第一二名略高,但是召回率和F1值较低。对于宏平均和微平均,基于SVM的方法在精确率上低于第一名高于第二名,由于较低的召回率,导致微平均的F1值略低,但是宏平均的F1值高于第二名。本论文提出的方法获得较高的精确率,能够完成微博情感分析的任务,但是召回率较低,对整体指标F1值造成了一定的影响。
| 指标 | MI&TLAB算法 | hit算法 | SVM算法 | ||||||
| P | R | F1 | P | R | F1 | P | R | F1 | |
| 褒义 | 0.918 | 0.586 | 0.715 | 0.873 | 0.574 | 0.692 | 0.899 | 0.570 | 0.698 |
| 贬义 | 0.886 | 0.500 | 0.639 | 0.887 | 0.500 | 0.640 | 0.901 | 0.485 | 0.631 |
| 宏平均 | 0.902 | 0.543 | 0.678 | 0.880 | 0.537 | 0.667 | 0.900 | 0.535 | 0.672 |
| 微平均 | 0.904 | 0.547 | 0.681 | 0.879 | 0.540 | 0.669 | 0.881 | 0.530 | 0.661 |
5 结束语
本论文利用同义词词林对4 部基础情感词典进行扩展形成一部情感词典,通过对比实验,证明本论文构造的情感词典有效。针对情感分析中特征选择的问题,利用不同的特征组合通过对比实验选取了有效的特征组合。经实验证明,选取的特征组合有效,能够有效提高微博情感分析的质量。
| [1] | 牛耘, 潘明慧, 魏欧, 等. 基于词典的中文微博情绪识别[J]. 计算机科学,2014, 41 (9) : 253 –258. |
| [2] | 王媛媛, 冯世朋. 信息传播过程中微博用户心理需求研究[J]. 兰台世界,2013 (9) : 105 –106. |
| [3] | 陈晓东. 基于情感词典的中文微博情感倾向分析研究[D]. 武汉:华中科技大学, 2012. |
| [4] | 宋静静. 中文短文本情感倾向性分析研究[D]. 重庆:重庆理工大学, 2013. |
| [5] | 谢丽星, 周明, 孙茂松. 基于层次结构的多策略中文微博情感分析和特征抽取[J]. 中文信息学报,2012, 26 (1) : 73 –83. |
| [6] | 杜振雷. 面向微博短文本的情感分析研究[D]. 北京:北京信息科技大学, 2013. |
| [7] | SAIF H, HE Yulan, ALANI H. Semantic sentiment analysis of twitter[C]//Proceedings of the 11th International Semantic Web Conference. Berlin:Springer, 2012. |
| [8] | 王振宇, 吴泽衡, 胡方涛. 基于HowNet和PMI的词语情感计算[J]. 计算机工程,2012, 38 (15) : 187 –189. |
| [9] | MORAES R, VALIATI J F, NETO W P G. Document-level sentiment classification:an empirical comparison between SVM and ANN[J]. Expert systems with applications,2013, 40 (2) : 621 –633. |
| [10] | 韩中元, 杨沐昀, 李生, 等. 一个面向微博的情感倾向性分析模型[J]. 智能计算机与应用,2014, 4 (6) : 57 –60. |