

DOI:10.11991/yykj.201505030

 , , , ,
, , , ,
, , , ,
, , , ,
关联规则是对事物之间相互依存和关联关系的一种描述[1],已经成为了数据挖掘领域的一个重要的研究课题。近几年来,随着人们对关联规则研究不断深入,关联规则已经在教育、金融、商业等各个领域取得了广泛的应用。关联规则挖掘一般可分成两个步骤:一是挖掘所有频繁模式;二是由频繁模式生成满足条件的关联规则。第一步是关联规则最主要的步骤,大多数的算法和技术主要针对频繁模式挖掘的研究,比较经典的算法有Apriori算法和FP-growth算法[2]。
Apriori算法是一种挖掘频繁模式的算法,核心思想是利用频繁项集性质的先验知识,使用逐层迭代的方法,即将K-项集用于挖掘(k+1)-项集,来挖掘数据集中的所有频繁项集[3]。Apriori算法在产生频繁模式完全集前需要对数据库多次扫描,同时产生大量的候选项集[4],使得算法时间和空间复杂度较大。针对Apriori算法在挖掘长频繁模式时时空效率低的问题,有学者提出了FP-growth算法[5]。该算法将频繁项集的数据压缩到一棵频繁模式树[6, 7](FP-tree),但是仍然保留项目集关联信息,与Apriori算法相比能明显的提高效率。
虽然FP-growth算法应用在稀疏数据库上取得了不错的性能,但是对于稠密数据库以及较低支持度时,频繁模式的数量会以指数形式增加。减少频繁模式中的冗余的最主要方法,有挖掘频繁闭项目集和最大频繁项目集(maximal frequent item set,MFI),而通过最大频繁项目集可以找到频繁闭项目集和频繁项目集,而且MFI的规模最小,所以可以把挖掘频繁项目集转换为挖掘最大频繁项目集,因此在关联规则中发现最大频繁项目集有很重要的意义。目前,最大频繁项目挖掘算法主要包括:FP-max、FPMAX*、AFOPT-tree等。Grahne等[8]在FP-growth算法基础上提出了FP-max算法,该方法通过递归构造模式树的方法产生最大频繁项集,因此需要大量的条件模式树,造成一定的时空资源浪费。Grahne 等[9]又提出了FPMAX*算法,该方法是对FP-max的一个改进,通过引入预计数技术和构造条件提升了算法在稀疏数据库中的性能,但是针对稠密数据库会有一定的限制,并且算法也未能减少潜在的冗余递归的次数。针对FP-tree存在自顶向下搜索效率低问题,在投影的超集检测算法基础上,王浩[10]提出了基于AFOPT-tree的最大频繁模式挖掘算法,通过对不同的数据项集的对比实验,验证了算法对比同类算法在超集检测优化和总体运行效率方面的优越性,但是在数据预处理阶段由于使用了基于三角矩阵的数据预处理技术,对算法的性能造成了一定的影响。
通过以上分析可知,现有的频繁模式挖掘算法时空效率有待提高。为此,文中提出基于动态结点插入技术的FP-tree构造算法,节约了数据存储空间;在改进的FP-tree的基础上又提出了一种新的最大频繁模式挖掘算法IFPmax,降低了最大频繁模式挖掘算法的时间复杂度,能够快速地挖掘出最大频繁项目集。 1 算法的基本思想
对FP-tree分析可知,FP-tree的深度和宽度决定了占用空间的大小,并且与其成正比。单个事务中所包含的项目数量的最大值是树的深度,平均每层所含的项目数量是树的宽度,因此主要从频繁模式树的宽度来进行压缩树的空间。
文中采用动态节点插入技术构建FP-tree,即improved FP-tree (IFP-tree),在该算法中,在被置换的节点的支持度相同的限定条件条件下,任何要插入IFP-tree的事物T中的节点顺序是可变的。通过概率的角度可知,支持度相同的节点出现在下一分枝中的概率是相同的,当被置换节点支持度较高时,这种做法避免了频繁置换所带来的不必要开销。通过对事物中节点顺序的动态变换,IFP-tree避免生成新的分枝,缩减了树的宽度,最终减小了树所占用的内存空间,有效地提高了树的前缀分枝的共享性,从而减少基于此结构的挖掘算法的遍历时间,提高了算法的效率。 2 算法描述
设事物数据库D是一个由事物T组成的集合,其中每个事务T是项的集合,I={i1,i2,…,im}是D中全体项目组成的集合,在本文中一个项对应一个URL,且满足T⊂I。每一个事务有一个标识符,称作TID。设A是一个项集,事务T包含A当且仅当A⊂T。
一个关联规则是形如A⇒B形式的一种蕴涵式,其中A⊂I,B⊂I,A∩B=∅。
定义1 关联规则A⇒B在事务数据库D中的支持度(support)是事务数据库D中包含A和B的事物个数与所有事物个数的比值,如式(1)所示。
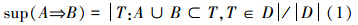
定义2 关联规则A⇒B在事务数据库D中的置信度(confidence)是指事务数据库D中,包含A和B的事务个数与包含A的事务个数的比值,如式(2)所示。
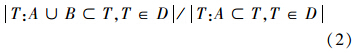
定义3 对于频繁模式p,如果不存在频繁模式q,使得q 包含p,则p是最大频繁模式MFP(maximal frequent pattern)。
定义4 有向树型数据结构IFP-tree满足如下定义:
1)它包含根结点null、子女结点(项的前缀子树的集合)以及一个频繁项目头表。
2)前缀子树的每个节点包含3个域:item-name、count和node-link,其中:item-name表示节点所代表的项目名称;count记录到达该节点的子路径上节点出现的次数;node-link用于连接树中下一个具有相同名称的节点,如果节点不存在则值为空。
3)频繁项目的头表包括项目名称item-name、项目频度item-count和结点链头head of node-link。
定义5 IFP-tree是一棵有向树,树中的分枝可以看成是由节点构成的序列,2个分枝中存在的最大公共前缀称为共享前缀,共享前缀所包含的节点数称为共享前缀的长度,共享前缀中的节点的支持度最小值称为共享度。
IFP-tree的构造主要包括2个步骤:
1)扫描事务数据库D一次,产生频繁1-项集,并得到它们的支持度计数,按递减顺序对频繁项的集合进行排序,用L表示。
2)创建IFP-tree的根结点,标记为“null”。对于D中的每个事务,执行以下操作:选择事务中的频繁项,并按L中的次序排序。设排序后的频繁项表为[p|P],其中p是第一个元素,而P是剩余元素的表。调用insert_tree([p|P],T),该过程的执行情况如下:
a)若T有子女N,使得N.item-name=p.item-name,那么,N的计数增加1;
b)否则找到p后面节点s判断 N.item-name =s.item-name;
c)若相等且满足s. count≤p.count,N.count++,则p与s交换;
d)否则创建一个新节点N,将其计数置为1,链接到它的父结点T,并通过节点链结构将其链接到具有相同item-name的节点。若p非空,递归地调用insert_tree([p|P],N)。
通过节点支持度的比较,改进后的算法实现了节点的动态插入,最大限度地避免了新节点的生成,压缩了模式树的宽度。 3 实例说明
为了更加直观地描述IFP-tree,以事物数据库D为例进行说明,事务数据库D如表 1。
| TID | 项的列表 |
| T1 | c,e,b,a |
| T2 | b,f,c,e,a,l |
| T3 | e,d,h |
| T4 | e,g,d,m |
| T5 | h,d,m |
| T6 | c,e,b,g,a |
| T7 | b,f,c |
| T8 | b,f,c,g |
| T9 | b,f,c,e,a |
表 1包含9个事务T1~T9,设该事务数据库最小支持度为2,计算数据库各项的支持度,并删除支持度小于最小支持度的不频繁项,按照支持度降序重新排列事务数据库D,如表 2。
| TID | 项的列表 |
| T1 | c,e,b,a |
| T2 | c,e,b,f,a |
| T3 | e,d,h |
| T4 | e,g,d,m |
| T5 | d,h,m |
| T6 | c,e,b,g,a |
| T7 | c,b,f |
| T8 | c,b,g,f |
| T9 | c,e,b,f,a |
创建以根节点标记为null,对于数据库中的第一个事务T1(c,e,b,a),插入树中,构造第1个分枝
而在IFP-tree中,若节点f与a不同,再判断事务T2(c,e,b,f,a)中节点f的后继节点与a是否相同,若相同再判断是否符合交换节点条件f.count=a.count ,满足条件则交换节点f和a,插入T2后如图 3所示,这样避免了冗余分枝的生成,同时,共享前缀由{<c:2><e:2><b:2>}变为{<c:2> 图 4所示为最终全部9个事务插入后的频繁模式树,生成的IFP-tree宽度为5。若按照原算法,如图 5所示,生成的FP-tree宽度为6。文中分别在
FP-tree和IPF-tree上进行对比试验,设最小支持度计数是2,从前向后依次扫描事务数据库中的每一个项,得到每一项的条件模式基、条件FP-tree和产生的频繁模式。实验结果如表 3和表 4。
由此可以看出,生成的IFP-tree有效避免了1个冗余分枝,生成IFP-tree的宽度小于FP-tree的宽度,宽度压缩率为20%,在树的深度即网站拓扑结构不变的情况下,构造IFP-tree所占的内存空间要小于FP-tree,特别是在数据库容量较大或者是支持度设置较低时可以解决FP-tree占用内存过大以至于挖掘算法无法实现的问题。同时,由于节点间顺序的灵活变换使生成的IFP树中的3个分支的共享前缀分别增加了1个节点,使模式树的分支共享性增强,提高了基于此结构的挖掘算法的效率。
由表 3、4可知,FP-tree和IFP-tree算法生成的条件模式基和条件树不尽相同,但是最后产生的频繁模式都是一样的,这证明了文中提出的算法的可靠性。还可以发现,虽然生成IFP-tree的过程中增加了事务节点支持度的比较和交换,算法复杂度和时间损耗上要高于FP-tree,但是生成IFP-tree的时间代价可以在挖掘算法的执行过程中得到补偿。因为IFP-tree的宽度减少了,所以在挖掘过程中,遍历整个树的节点时间节约了,再加上较高的前缀分枝的共享性,使挖掘算法更有效率,特别是在挖掘较大型的数据库或支持度阈值设定较小时,挖掘算法的时间效率的提高将会更加明显。
5 最大频繁模式挖掘
最大频繁模式具有如下性质[11]:
性质1 最大频繁模式的任何超集都不是频繁的。
性质2 最大频繁模式的任何子集都是频繁的。
由以上性质可知,频繁模式与非频繁模式的分界线是最大频繁模式,在最大频繁模式集以下的都是频繁模式,而在最大频繁模式以上的都是非频繁模式。因此,为了得到所有的频繁模式,只要找到所有最大频繁模式就可以了。
在算法IFP-tree中,父结点的支持度必然大于等于子结点的支持度。当遍历IFP-tree中某一分枝上的子女节点,而且经过子集检测被存入最大频繁模式树时,该节点的父节点必定已经包含在当前的最大频繁模式集中,因此可以不再遍历此父节点。通过以上分析,文中提出了一种基于IFP-tree的最大频繁模式挖掘算法IFPmax(improved FPmax),对Fpmax算法进行改进,减少了子集检测时所遍历的节点数目以及时间消耗,提高了整个系统的效率。
下面在给出新算法IFPmax之前,首先对IFP-tree结构做一下说明:IFP-tree中的每个节点有5个域,其中的3个域item-name、count、 node-link的定义与FP-tree相同,每个节点新增加了2个域level和flag ,其中 level表示节点的秩,结点的秩最小为0,从上往下,每增加一层节点的秩就加1。flag 表示节点是否已被遍历过,flag=1代表该节点已经被遍历过,flag=0代表该节点没有被遍历过。IFP-tree结构结点如图 6所示。
对于IFP-tree中的一条路径β=i1,i2,…,ik,如果是一个最大频繁模式,根据性质1和2可知,则它的任何子集都不是最大频繁模式,即这条路径上节点的其他任何组合都不是最大频繁模式,那么该路径上的i1,i2,…,ik-1都没必要为了生成最大频繁模式再进行遍历。这时就可以修改i1,i2,…,ik-1的flag标记,使该条路径上的其余节点不再重复遍历,这样就减少了k-1次节点遍历的时间。
IFPmax算法执行过程如下:
输入 IFP-tree Tα,min_sup
输出 MFS
MFS为最大频繁模式集,初值为空;所有结点flag=0
if (Tα是只有1个分支的树)
//bi是分支上的最后1个节点,β是bi的条件IFP-tree
{对Tα调用MINE-MAX(β,bi,MFS)
Else //Tα有多个分支
{对项头表的每一个节点ai(i=n,n-1,……,1)
Do
{if (flag(ai)==0 并且ai的count大于当前最大频繁模式集MFS中ai的count值的和))
//即该节点没有被遍历过而且以该节点为叶子节点的所有分支不全是已有MFS中最大频繁模式的子集
{构造ai的条件IFP-tree,得到tree-R
If(tree-R仍然有多个路径)
{对每一个分支分别调用
MINE-MAX(β,bi,MFS)。
Else {
// ri 是tree-R的最后一个节点。
对tree-R调用MINE-MAX(R,ri ,MFS)
}
}
}
}
//下面是MINE-MAX(bi的条件IFP树β,最后节点bi,最大频繁模式集MFS)的实现过程。
MINE-MAX(β,bi,MFS)
{ If(Tα是空的)则生成最大频繁模式候选项Cmax=bi
Else Cmax=β∪bi,
//Cmax支持度是bi节点的支持度
If (原来的MFS中不包含bi,或者候选频繁模式中bi的秩大于等于MFS中bi的秩)
//说明Cmax不是MFS中已有的最大频繁模式的子集
{ MFS=MFS∪Cmax,删除MFS中Cmax的所有子集,修改β中所有节点的flag值使之为1,更新β中所有节点的count值,使之等于包含bi的IFP树所有分支的对应节点的count值的和。
}
}
下面以表 2所示的数据库为例,设最小支持度为2,说明使用上述算法进行最大频繁模式挖掘过程。首先生成相应的IFP树,如图 4所示。因为是多分支树,所以需要按照图 4中的项目头表中从下往上的顺序,构造节点的条件IFP树,并采用MINE-Max算法,得到最大频繁模式集。首先构造m节点的条件IFP树,是<g:2>,所以生成最大频繁模式候选项Cmaxm={(g,2,2,1,1)(m,2,2,1)},每一项中的第2个参数表示频繁度计数,第3个参数表示的秩,第4个参数表示flag标志。此时的MFS是空的,所以可以g,m加到MFS中,得到MFS={<(g,2,1,1),(m,2,1,1)>}。然后继续对后面的节点进行同样的处理。对h进行处理,因为h的条件IFP树是空的,所以处理后后得到的MFS={<(g,2,1,1),(m,2,2,1) >,<(h,2,1,1) > } ;同样对d,d的条件IFP树是<e:2>,进行处理后MFS={<(g,2,1,1),(m,2,2,1)> ,<(h,2,1,1)> ,<(e,2,1,1),(d,2,2,1)> } ;然后对a进行处理,得到的最大频繁模式候选项Cmaxa={(a,4,4,1),(b,4,,3,1),(e,4,2,1),(c,6,1,1)}。把a的Cmaxa添加到MFS中,并且修改e的秩,更新后MFS={<(g,2,2,1,1),(m,2,2,1)> ,<(h,2,1,1)> ,<(e,2,1,1),(d,2,2,1)> ,<( a,4,4,1),(b,4,3,1),(e,4,2,1),(c,6,1,1)> } ;对f进行处理,得到的得到的f的最大频繁模式候选项Cmaxf={(f,4,5,1),(a,4,4,1),(b,6,3,1),(e,4,2,1),(c,6,1,1)},加到MFS中,而且因为原来MFS中的项<(a,4,4,1),(b,4,3,1),(e,4,2,1),(c,6,1,1)>是f的最大频繁模式候选项的子集,所以把<(a,4,4,1),(b,4,3,1),(e,4,2,1),(c,6,1,1)>从MFS中删除,更新MFS={<(g,2,1,1),(m,2,2,1)> ,<(h,2,1,1)> ,<(e,2,1,1),(d,2,2,1)>,<(f,4,5,1),(a,4,4,1),(b,6,3,1),(e,4,2,1),(c,6,1,1)>} 。接下来对g节点进行处理,g节点虽然flag=1,但是不满足count条件,构造条件IFP树{<c:2,b:2,e:1>,<e:1>},它有2个分支,按照上述算法对每一个分支分别进行处理,当以g为后缀的频繁模式检测完毕之后,按照项目头表,接下来要按顺序对b、e、c节点进行检测,因为这些节点的flag标志此时已经等于1,而且满足count条件所以放弃对这几个节点的遍历,因为MFS一定包含这4个节点为后缀的分枝。从以上检测过程可以看出,IFPmax算法中需要遍历的节点数目明显少于FPmax算法,IFPmax算法的时间性能高于FPmax算法,而且数据库越大,优势越明显。
6 实验结果及性能分析
文中在内存大小为2 GB,操作系统为Windows 7,利用Visual C++6.0的编译环境下实现了IFPmax算法。实验数据从网络日志文件数据库中截取了2个事务数据库(包含15 000和2 000个事物数据库的记录),分别基于FP-tree和IFP-tree挖掘频繁模式,得到在不同的支持度下的挖掘时间,如表 5、6。
挖掘算法 挖掘算法
挖掘算法
挖掘算法 由表 5、6可知,当设置支持度为50%时,文中算法消耗时间略高于FP-tree算法。文中算法需要对插入树中的节点进行支持度比较和动态排序,因此IFP-tree算法的复杂性比FP-tree高。当支持度设置较高时,IPF-tree算法得到的频繁项集数量较少,空间压缩率较小,使得IFP-tree构造算法性能下降。在表 5中,当最小支持度为0.1%时,FP-tree算法无法挖掘最大频繁模式,而在IFP-tree上可以挖掘成功,说明对同样大小的事务数据库生成IFP-tree所占用的内存空间要小于FP-tree,体现了IFP-tree构造算法压缩内存空间的性能。同时由表 6可知,在数据库比较大或者支持度较小,时IFP-tree算法的运行时间更少,说明使用的动态节点插入技术提高了IFP-tree构建算法中树的前缀分枝的共享性,减少了挖掘算法需要遍历的分枝数目,因此,在频繁项集较大时,IFP-tree比FP-tree具有更好的适应性。FPmax和IFPmax的算法性能比较如图 7。
实验数据表明,在相同大小的事务数据库上(20 000),IFPmax算法在各个支持度上的运行时间都要少于FPmax算法,特别在支持度较小时IFPmax算法优越性更加明显。
7 结束语
文中深入研究了频繁模式算法和FP-tree,并提出了IFP-tree结构,构造频繁模式树时采用了动态节点插入技术,有效地压缩了数据空间。同时,在IFP-tree结构的基础上,进一步优化最大频繁模式挖掘算法FPmax,提出了IFPmax算法,利用节点的秩进行子集检测前的预判断,根据最大频繁模式的性质对已经存在的节点进行标记,有效地避免了节点的冗余遍历,使最大频繁模式挖掘算法效率更高。

图 1 插入第1个分支构造FP-tree 
图 2 插入第2个分支构造FP-tree 
图 3 插入第2个分支构造FP-tree 
图 4 生成的IFP-tree 
图 5 生成的FP-tree
项目
条件模式基
条件FP-tree
产生的频繁模式
h
<(e,d:1)>,<(g:1)>
null
null
m
<(e,g,d:1)>,
<(g,h:1)>
<g:2>
gm:2
d
<(e:1)>,<(e,g:1)>
<e:2>
ed:2
a
<(c,e,b:1)>,
<(c,e,b,f:2)>,
<(c,e,b,g:1)>
<c:4,e:4,b:4,
f:2>
ca:4,ea:4,ba:4,cea:4,cba:4,eba:4,ceba:4,
fa:2,cfa:2,efa:2,
bfa:2,cefa:2,cbfa:2,
befa:2,cebfa:2
f
<(c,e,b:2)>,
<(c,b,g:1)>,
<(c,b:1)>
<c:4,b:4,e:2>
cf:4,bf:4,ef:2,cbf:4,
cef:2,
bef:2,cbef:2
g
<(c,e,b:1)>,<(c,b:1)>
<(e:1)>
<c:2,b:2,e:1>,<e:1>
cg:2,eg:2,bg:2,
cbg:2
b
<(c,e:4)>,<(c:2)>
<c:6,e:4>
cb:6,eb:4,ceb:4
e
<(c:4)>
ce:4
项目
条件模式基
条件FP-tree
产生的频繁模式
h
<(e,d:1)>,<(g:1)>
null
Null
m
<(e,g,d:1)>,
<(g,h:1)>
<g:2>
gm:2
d
<(e:2)>
<e:2>
ed:2
a
<(c,e,b,:4)>
<c:4,e:4,b:4>
ca:4,ea:4,ba:4,,cea:4,cb a:4,eba:4,ceba:4
f
<(c,e,b,a:2)>,
<(c,b:2)>
<c:4,b:4,e:2,
a:2>
cf:4,bf:4,ef:2,cbf:4,
cef:2,bef:2,cbef:2,
fa:2,cfa:2,efa:2,bfa:2,cefa:2,cbfa:2,befa:2,cebfa:2
g
<(c,e,b,a:1)>,
<(c,b,f:1)>
<(e,d:1)>
<c:2,b:2,e:1>,
<e:1>
cg:2,eg:2,bg:2,cbg:,
b
<(c,e:4)>,<(c:2)>
<c:6,e:4>
cb:6,eb:4,ceb:4
e
<(c:4)>
<c:4>
ce:4 
图 6 生成的FP-tree
支持度/%
基于FP-
tree的
基于IFP-
tree的
0.1
—
10 260
0.5
730
478
1
128
105
10
9.7
9.4
50
3.1
3.3 s
支持度/%
基于FP-tree的
基于IFP-tree的
0.1
—
—
0.5
—
609
1
40.6
30.5
10
13.7
11.6
50
3.6
4.1 
图 7 FPmax和IFPmax的算法性能比较
| [1] | 秦亮曦, 史忠植. SFP-Max——基于排序FP-树的最大频繁模式挖掘算法[J]. 计算机研究与发展, 2005, 42(2):217-223. |
| [2] | 晏杰, 亓文娟. 基于Aprior&FP-growth算法的研究[J]. 计算机系统应用, 2013, 22(5):122-125. |
| [3] | GU D, XIA L. A novel and improved apriori algorithm[J]. Vehicle mechanical & electrical engineering, 2015, 721. |
| [4] | 王乐, 冯林, 王水. 不产生候选项集的TOP-K高效用模式挖掘算法[J]. 计算机研究与发展, 2015, 52(2):445-455. |
| [5] | BORGELT C. An implementation of the Fp-growth algorithm[C]//Osdm Proceedings of International Workshop on Open Source Data Mining Frequent Pattern, 2005. |
| [6] | 宋余庆, 朱玉全, 孙志挥,等. 基于FP-Tree的最大频繁项目集挖掘及更新算法[J]. 软件学报, 2003, 14(9):1586-1592. |
| [7] | 朱玉全, 孙志挥, 季小俊. 基于频繁模式树的关联规则增量式更新算法[J]. 计算机学报, 2003, 26(1):91-96. |
| [8] | GRAHNE G., ZHU J. High performance mining of maximal frequent itemsets[C]//Proceedings of the 6th International Workshop on High Performance Data Mining, 2003:1-10. |
| [9] | GRAHNE G, ZHU J. Efficiently using prefix-trees in mining frequent itemsets[C]//Proceedings of the Third FIMI Workshop on Frequent Itemset Mining Implementations. 2003:123-132. |
| [10] | 王浩. 基于AFOPT-tree的最大频繁项集挖掘[D]. 合肥:安徽大学, 2014:3-22. |
| [11] | 牛新征, 佘堃. 基于FPMAX的最大频繁项目集挖掘改进算法[J]. 计算机科学, 2013, 40(12):223-228. |