

DOI:10.11991/yykj.201505017

 , , ,
, ,
, , ,
, ,
随着互联网的发展,大量有价值的学术论文以及资料被发布在网络上,随之也就出现了文本抄袭的现象。文本抄袭是指抄袭者将他人的作品没有修改或者做出少量修改后使用而不做引用说明的行为[1]。为了遏制这种抄袭行为,抄袭检测技术也逐渐受到了相关研究人员的重视。抄袭检测是指人们利用计算机各方面的研究技术,检测数字产品是否复制其他数字产品的过程[2]。当前的抄袭检测系统存在的问题是对于在线的抄袭检测系统,无法快速地获得处理结果。针对以上问题,本文提出了基于图论的片段合并算法,并将片断合并算法与MapReduce[3]计算框架相结合,使片段合并算法在分布式集群中并行执行,缩短了抄袭检测的时间。
1 合并方法相关技术介绍 1.1 Hadoop简介Hadoop[4]是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统[5]和MapReduce为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。Apache Hadoop的流行与大数据处理的兴起关系密切。现代社会的信息量增长速度极快,这些信息里又积累着大量的数据,其中包括个人数据和工业数据。预计到2020年,每年产生的数字信息将会有超过1/3的内容驻留在云平台中或借助云平台处理。人们需要对这些数据进行分析和处理,以获取更多有价值的信息。那么为了高效地存储、管理和分析这些数据,这时可以选用Hadoop系统,它在处理这类问题时,采用了分布式存储方式,提高了读写速度,并扩大了存储容量。采用MapReduce来整合分布式文件系统上的数据,可保证分析和处理数据的高效。与此同时,Hadoop还采用存储冗余数据的方式保证了数据的安全性。
1.2 实验评测方法在本论文中所使用的评价函数是Pan@CLEF2012会议中规定的评价函数[6],分别是精确率(precision),召回率 (recall)、粒度 (granularity)、总体性能 (plagdet score)。精确率是用来衡量检索出来的数据的准确性。召回率是用来衡量可以成功检索到相关文本的可能性。粒度用来确定2个或者多个剽窃的文本片段组合在一起的段落是否连续。总体性能反映精确率、召回率以及粒度的之间关系,是文本对齐阶段的最重要的评价指标
2 文本对齐模块研究Pan@CLEF2012将抄袭检测可以分为源检索和文本对齐2个子任务[6]。文本对齐任务又可以分为种子搜索和片段合并2个子阶段。种子搜索阶段是指将每个备选文档集中的文档与可疑文本一一进行对比,并提取2个文档间高度相似的所有文本片段对,即种子片段。片段合并阶段是指将所获得的种子片段进行合并,形成抄袭片段对,最后以可以显现的形式展现出具体的抄袭片段对。
抄袭检测系统通过文本对齐模块展示结果,文本对齐模块片段合并算法直接影响着整个系统和该模块的时间效率。特别是在大规模数据集下,算法的性能有着更为重要的意义。本文针对Pan@CLEF2012文本对齐模块的片段合并算法提出改进策略。
在Pan@CLEF2012,第一名[7]采用的是在双侧位置上的双向交替合并算法。整个过程是在“片段位置”级别而非“字符位置”级别上的最大公共子序列[8]算法,通过设定片段间隔阈值,将相邻片段合并;同时,为了保证每次划分出的可疑片段与参考片段的两侧位置都相邻,则每次提取出片段后都对其两侧位置进行排序,然后再次划分,直到可疑片段与参考片段彼此都满足位置相邻阈值条件时合并。为了提高效率,在算法实现的过程中可以进行适当的剪枝操作,以达到降低时间复杂度的目的,具体可以在如下操作剪枝:
1)在每次划分处理之前,依据片段的特征单元个数阈值,将特征单元数大于该设定阈值的划分进入下一次的处理,否则将当前可疑片段忽略。
2)在每次处理的最初阶段,首先根据片段链表的节点个数与首尾片段的位置跨度的关系判断能否在O(1)的时间复杂度内完成合并,即判断是否满足如下关系如下:
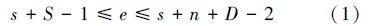
但该算法采用的是一种递归回溯合并策略,不断对可疑文本的片段号和参考文本的片段号进行交替排序与比对,即使在搜索过程中已对算法进行了剪枝操作,但其合并过程中使用该算法的整个过程的时间复杂度还是很高,如何减少不断进行的重复计算所消耗的时间,仍值得进一步研究。
经过文本对齐模块的种子搜索阶段,得到的相似片段对过于零碎,文本合并阶段的任务是尽可能全面地将抄袭片段合并为较大的抄袭片段对。如图 1所示,将可疑文本种子片段和参考文本种子片段合并成较大片断的过程。
 |
| 图 1 片段合并过程 |
本文综合分析片段合并后的形式,结合图论[9]的思想,实现了一种寻找图的连通分支[10]的优化合并算法。
2.1 抄袭片段的合并规则经过初步种子搜索后,句子sus和src种子的抄袭关系如图 2所示。
 |
| 图 2 sus句子和src句子抄袭关系表示 |
在图 2中,列标号代表sus的种子编号,行标号代表src的种子编号;行列所交叉的一个方格代表两个句子之间的对应关系,如果有颜色则表示对应的sus句子和src句子之间存在潜在抄袭,否则不存在。
对于可疑文本或参考文本的种子,含有如下的属性特征:
int sus_start ;//可疑片段的起始位置
int sus_end ; //可疑片段的结束位置
int src_start ;//参考片段的起始位置
int src_end ;//参考片段的结束位置
本文定义的合并规则是sus句子之间和src句子之间的相隔距离同时满足距离阈值d时,才可以将2个抄袭片段对合并。但对于可疑文本或参考文本间的种子是否可以合并的情况,可以根据如下公式来判断,s1与s2的满足下面的公式值为1时,则可以合并,否则不可以合并。对于2个可疑文本和参考文本来说,可疑文本与参考文本要同时满足下述公式,才可以合并。如式(2)所示:
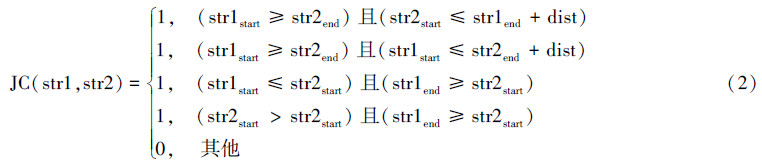
对于2个种子(抄袭片段对)SP1(sus1,src1)和SP2(sus2,src2)满足公式(3)才可以进行合并。
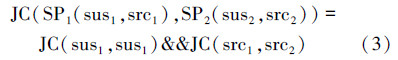
经过种子搜索阶段,文本对齐模块会得到许多抄袭片段对。在本算法中规定每个抄袭对是图论中的一个节点,如果2个抄袭对符合合并条件,就可以合并成一个较大的抄袭片段,则2个节点之间就会有连线,称作图的边。在本文中规定:把每个抄袭对看作是最小的抄袭片段。如图 2所示,假定每种颜色标记的方块是最终合并的抄袭片段,可以得到结论:对于已合并的片段中的每个抄袭对,在合并的片段中至少存在一个抄袭对能够跟此抄袭对进行合并。
通过上述分析,文本对齐模块的抄袭片段合并问题可以转化为求图论的联通分支的问题,抄袭对之间的合并关系就是2个节点之间的边,最终合并的抄袭片段就是图中的每个连通分支。对于某个连通分支,其中的任一节点在连通分支中都至少有一个节点与其相连。为了准确地表示抄袭片段,一种常用的方法是为每个抄袭片段选定一个固定的抄袭对,本文称为“代表”,用来代表整个抄袭片段。为了方便的处理抄袭对,定义2个操作:联合(Union)、查找(Find)。
在2个操作之前需要初始化一个抄袭片段,算法如下:

Find操作:确定抄袭对属于哪一个抄袭片段和判定2个抄袭对是否存在于同一个抄袭片段。查找1个抄袭对所属的抄袭片段,其关键是找到这个抄袭对所在的抄袭片段的祖先,这才是判断合并抄袭片段的依据。查找算法是根据其父节点的引用向根节点行进直到抵达根节点,这是一个递归的过程。算法如下:

Union操作:将2个较小的抄袭片段合并成更大的抄袭片段。利用Find找到其中2个抄袭片段的祖先,将一个抄袭片段的祖先指向另一个抄袭片段的祖先即可。算法如下:

如图 3所示,如果抄袭对e和抄袭对g具有合并关系,那么它们所在抄袭片段也是可以合并的,只需要把它们所在的抄袭片段的祖先节点c、f连接。由于寻找祖先节点采用递归算法,某个抄袭片段由许多元素构成,每次Find操作都会使用O(n)的复杂度。为了避免过高的复杂度,本文采用路径压缩和按秩合并策略。
 |
| 图 3 Union操作过程 |
路径压缩是在执行Find操作时构造扁平化树结构的算法,关键在于路径点上的每个节点都可以直接连接到根节点上。Find操作递归的访问树的节点,将每个节点的引用连接到根节点。每次递归调用后,得到的结果将使路径更加扁平化,加快直接或者间接访问节点的操作速度。算法如下:
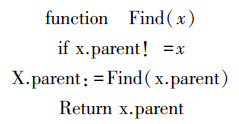
如图 4所示,已知h和g符合合并规则,需要回溯整条路径找到g节点的根节点f,将遍历路径中的所有节点一律指向根节点f。如果再有新的节点需要与此片段某节点符合合并规则时,很快就能找到此片段的根节点。
 |
| 图 4 路径压缩过程 |
把即将合并的抄袭片段的深度称为秩,按照秩合并策略即总是将秩更小的抄袭片段链接到有更大秩的抄袭片段上。影响运行时间的是抄袭片段中抄袭对的深度,有更小秩的抄袭片段添加到有更大秩的抄袭片段的根节点后,新片段的秩将不会增加。单个抄袭对组成的抄袭片段的秩定义为0,当2个秩同为r的抄袭片段合并时,组成新片段的秩为r+1。算法如下:

其中,算法中新增加了一个记录抄袭片断的秩的变量rank。经过以上步骤,会得到所有的连通分支。
假设现在已经生成的某一连通分支中,可疑文本片段集合为S= {s1,s2,…,sm},参考文本片段集合为R={r1,r2,…,rn},他们的抄袭对关系集合RS={rsi,j= <si,rj> | si∈S,rj∈R,m≥i≥0,n≥j≥0},那么合并结果为A={<si-sj,rp-rq> | si,sj∈S;rp,rq∈R}。当向这个连通分支中新加入一个抄袭对,只需更改片断合并结果的范围。
在文本对齐模块中基于图论的片段合并算法的并行处理是指把片段合并算法作为一个独立的处理单元,整合到MapReduce框架中,利用Hadoop平台调度执行的过程。本实验与MapReduce计算框架结合,利用Map范式和Reduce范式实现在Hadoop分布式集群行的并行执行。片段合并算法在Hadoop平台上的并行处理如图 5所示。
 |
| 图 5 片断合并算法并行执行的数据流 |
本文的实验中,用Baseline表示基于双向交替排序的合并算法、Graph表示基于图论的片断合并算法的实验结果。表 1为Baseline和Graph在各个数据集的性能对比结果。本实验中采用的评测指标是Pan@CLEF 2012在文本对齐模块的评测指标。实验所用的数据集是6种不同的数据集,分别是数据集1(no obfuscation)、数据集2(artificial low)、数据集3(artificial high)、数据集4(simulated paraphrase)、数据集5(translation)、以及将前5个数据集合并后的总的数据集6(all data)。
| 指标 | 数据1 | 数据2 | 数据3 | 数据4 | 数据5 | 数据6 | ||||||
| Baseline | Graph | Baseline | Graph | Baseline | Graph | Baseline | Graph | Baseline | Graph | Baseline | Graph | |
| 总分 | 0.720 8 | 0.723 6 | 0.724 6 | 0.724 9 | 0.715 3 | 0.718 3 | 0.715 3 | 0.718 3 | 0.715 3 | 0.718 3 | 0.715 3 | 0.718 3 |
| 召回率 | 0.750 5 | 0.723 6 | 0.747 5 | 0.743 5 | 0.746 1 | 0.738 9 | 0.746 1 | 0.738 9 | 0.746 1 | 0.738 9 | 0.746 1 | 0.738 9 |
| 精确率 | 0.695 5 | 0.711 4 | 0.704 6 | 0.718 3 | 0.689 4 | 0.703 1 | 0.689 4 | 0.703 1 | 0.689 4 | 0.703 1 | 0.689 4 | 0.703 1 |
| 粒度 | 1.002 1 | 1.007 4 | 1.001 5 | 1.011 1 | 1.002 5 | 1.004 4 | 1.002 5 | 1.004 4 | 1.002 5 | 1.004 4 | 1.002 5 | 1.004 4 |
在表 1中,Baseline是基于双向交替排序的片段合并算法的实验结果,Graph是基于图论的片段合并算法的实验结果。由表 1可知,Baseline中使用的方法和Graph使用的方法在Plagdet Score指标的得分几乎一样,对其他指标也无较大的影响,因此本论文提出的基于图论的片段合并算法是有效的,能够处理抄袭检测中片段合并的问题。
表 2为Baseline和Graph的抄袭检测系统运行时间对比结果。实验的数据集包括6组数据集,前5组数据集中每组有1 000对测试数据,第6组数据集综合前5组数据集组合成1个新的数据集。按照实验要求,分别统计Baseline和Graph方法在抄袭检测系统中运行总时间和文本对齐模块运行的时间。
| 数据集 | Baseline | Graph | ||
| 抄袭检测系统 | 文本对齐模块 | 抄袭检测系统 | 文本对齐模块 | |
| 数据1 | 87 | 39 | 76 | 22 |
| 数据2 | 134 | 51 | 116 | 35 |
| 数据3 | 129 | 48 | 105 | 29 |
| 数据4 | 220 | 83 | 195 | 61 |
| 数据5 | 164 | 65 | 143 | 44 |
| 数据6 | 804 | 316 | 688 | 223 |
如表 2所示,在各个数据集上基于图论的片段合并算法在整个抄袭系统以及文本对齐模块上的时间都优于Baseline中提出的基于双向交替排序的合并算法。从实验数据可以看出,文本对齐模块的时间开销占整个抄袭检测系统开销的一小部分,但是却能明显影响整个数据集在抄袭检测中的总运行时间。综上所述,在时间性能上,基于图论的片段合并算法优于基于双向交替排序的片段合并算法。
表 3为Baseline和Graph使用的方法在不同规模的数据集上分别对抄袭检测系统运行的总时间和文本对其模块运行时间的对比结果。本实验所用数据集规模如下表所示,数据集规模依次为0.98、10.23、40.07、100.01、200.15、300.01 GB,实验都是运行在基于单机的服务器上。
| 数据集 | Baseline | Graph | ||
| 抄袭检测系统 | 文本对齐模块 | 抄袭检测系统 | 文本对齐模块 | |
| 数据1 | 182 | 71 | 146 | 49 |
| 数据2 | 386 | 116 | 337 | 84 |
| 数据3 | 973 | 329 | 899 | 256 |
| 数据4 | 1 764 | 497 | 1 613 | 427 |
| 数据5 | 2 679 | 846 | 2 342 | 761 |
| 数据6 | 3 125 | 1 034 | 2 847 | 915 |
由表 3可知,随着数据规模的增大,基于图论的片段合并算法和基于双向交替排序的片段合并算法在抄袭检测系统的总运行时间和文本对齐模块的时间都增大。在抄袭检测系统和文本对齐模块上的运行时间,基于图论的片段合并算法优于基于双向交替的片段合并算法。综上所述,在不同规模的数据集上,基于图论的片段合并算法在时间性能上优于基于双向交替排序的片段合并算法。
表 4为Baseline和Graph并行执行的时间性能实验对比结果。本次实验使用上一实验中的数据集。本次实验将基于图论的片段合并算法和基于双向交替排序的片段合并算法分别部署到Hadoop分布式集群中,统计在分布式集群下使用2种片段合并算法在不同规模数据集的实验开销。分布式集群采用Hadoop平台,集群的规模分别为4、5、6台服务器,可疑文本数量为1 000篇。
| 数据集 | 抄袭检测系统 | 文本对齐模块 | ||||||||||
| 4台服务器 | 6台服务器 | 5台服务器 | 4台服务器 | 6台服务器 | 5台服务器 | |||||||
| Baseline | Graph | Baseline | Graph | Baseline | Graph | Baseline | Graph | Baseline | Graph | Baseline | Graph | |
| 数据1 | 165 | 137 | 158 | 109 | 141 | 93 | 43 | 35 | 37 | 26 | 23 | 10 |
| 数据2 | 253 | 231 | 224 | 211 | 206 | 182 | 82 | 63 | 65 | 44 | 49 | 35 |
| 数据3 | 754 | 697 | 693 | 609 | 622 | 537 | 238 | 192 | 201 | 161 | 176 | 138 |
| 数据4 | 1 485 | 1 168 | 1 299 | 948 | 936 | 729 | 337 | 268 | 254 | 212 | 199 | 173 |
| 数据5 | 2 196 | 1 966 | 1 833 | 1 693 | 1 543 | 1 477 | 543 | 441 | 410 | 317 | 299 | 210 |
| 数据6 | 2 604 | 2 497 | 2 341 | 2 103 | 2 019 | 1 712 | 816 | 749 | 664 | 571 | 403 | 318 |
由表 4可知,在数据规模相同的情况下,随着Hadoop分布式集群规模的扩大,在抄袭检测系统运行总时间和在文本对齐模块运行的时间都有明显的减少。同时,时间开销并不和服务器的数量成比例。对比表 4,在数据规模相同的情况下,在分布式集群中基于单机的抄袭检测系统抄袭检测总运行时间和文本对齐模块有明显的减少。
综上所述,基于图论的片断合并算法在分布式集群上的时间性能优于基于双向交替排序的片断合并算法。随着数据集规模的扩大以及分布式集群的规模越大,抄袭检测系统和文本对齐模块的时间消耗越小。
4 结束语针对文本对齐模块的片断合并算法中得到的片段过于零碎的问题,本文提出了基于图论的片断合并算法。该方法计算抄袭对形成的图中的连通分支,减少了重复计算,通过实验证明了本文提出的算法能有效地提高效率。本文将片段合并算法与Hadoop的MapReduce计算框架结合,使片断合并算法在集群中并行的执行,减少了文本对齐模块与整个系统的运行时间,提高了片段合并算法的时间性能,从而能够快速的处理大规模的文本数据。
| [1] | 史彦军,滕弘飞,金博.抄袭论文识别研究与进展[J].大连理工大学学报,2005,45(1):50-57. |
| [2] | 鲍军鹏,沈钧毅,刘晓东,等.自然语言文档复制检测研究综述[J].软件学报,2003,14(10):1753-1760. |
| [3] | LI Feng,OOI B C,ÖZSU M T,et al.Distributed data management using MapReduce[J].ACM computing surveys,2014,46(3):31. |
| [4] | Welcome to ApacheTM Hadoop[EB/OL].[2013-2-27].http://hadoop.apache.org/. |
| [5] | 王雪涛,刘伟杰.分布式文件系统[J].科技信息,2006(11):406-407. |
| [6] | POTTHAST M,GOLLUB T,HAGEN M,et al.Overview of the 4th international competition on plagiarism detection[C]//CLEF 2012 Evaluation Labs and Workshop-Working Notes Papers.Rome,Italy,2012:1-9. |
| [7] | KONG Leilei,QI Haoliang.WANG Shuai,et al.Approaches for candidate document retrieval and detailed comparison of plagiarism detection[C]//CLEF 2012 Conference and Labs of the Evaluation Form.Rome,Italy,2012:1-8. |
| [8] | 李欣,舒风笛.最长公共子序列问题的改进快速算法[J].计算机应用研究,2000,17(2):28-30. |
| [9] | 陈国良,梁维发,沈鸿.并行图论算法研究进展[J].计算机研究与发展,1995,32(9):1-16. |
| [10] | 韩逢庆,李红梅,纪纲.图的连通分支遍历算法在材料信息处理中的应用[J].计算机工程与应用,2002,38(9):215-217. |