

DOI:10.11991/yykj.201505004

 ,
,
,
,
2. Remote Sensing Technology Center, Heilongjiang Academy of agricultural science, Harbin 150001, China
聚类是根据数据集合中各个数据点之间相似性的度量将其划分为若干个不同类别的过程,通过聚类分析,同一个类中的数据具有较高的相似性,而不同类别的数据具有较大的差异性。目前,数据聚类已经在数据挖掘、机器学习、生物信息以及图像处理等方面有了广泛的应用,包括。随着聚类技术的不断发展,许多研究人员开始将群体智能优化算法引入聚类方法中,通过并行搜索的方式解决初始聚类中心敏感问题。这一类新聚类算法的根本策略是将数据聚类问题归结为一个优化问题,模拟自然界的某些群体智能行为进行启发式搜索,通过了解种群的演变,寻找具有最优目标函数值的聚类划分[1]。目前,具有代表性的算法有,基于粒子群(PSO)的聚类算法[2],基于人工鱼群(AFSA)的聚类算法[3]、基于蚁群(ACO)的聚类算法[4]等。PSO算法由于粒子间的信息交流,收敛速度较快,但粒子都向最优方向移动而趋向同一化,容易引起早熟现象。AFSA虽然全局搜索性能好,但是收敛速度过慢。ACO的收敛性好,但也有收敛时间长、容易停滞,易于陷入局部最优的问题。烟花算法(FA)是一种相对较新的群体智能优化算法,是解决复杂的无约束优化问题的一种新型算法,该算法的思想简单、参数较少、求解速度快、具有大范围快速全局搜索能力。2010年,Tan等[5]最初提出的一种相对较新的全局优化算法,该算法在搜索空间选择一定数量的烟花弹,每个烟花弹爆炸产生一组火花。然后从中选择高质量的火花进行下一次迭代,直到满足停止条件。2013年,基于标准的FA算法,Tan等[6]对FA算法进行了改进,主要是对产生火花的算法、对超出搜索空间的火花进行新的映射策略以及新的产生下一次迭代烟花弹的方法的改进。但是,由于没有利用种群内其他的解的信息,群体间信息没有交互。为了避免局部最优,2015年,ZHENG等[7]提出了FA与差分进化(DE)相结合的算法。基于同样的烟花爆炸思路,曹炬等[8]提出了一种烟花爆炸优化算法(FEO),该算法主要思想是通过烟花爆炸产生火花,但是爆炸半径的控制,爆炸产生火花的方法以及选取下一代烟花弹的方法都独树一帜。本文采用基于聚类中心的二进制编码原则,根据文献[5, 8]、对烟花算法的描述,为了解决离散空间聚类优化问题,提出一种基于二进制编码的烟花优化聚类算法。
1 基于二进制编码的烟花算法 1.1 烟花算法根据文献[8]的描述,烟花算法(FA)是在搜索空间生成一定数目的烟花弹,对每个烟花弹进行爆炸操作,使得爆炸产生的大量火花形成在原烟花弹的一定邻域范围内,并采用局部保优的策略逐代控制进行爆炸的烟花弹数。同时,通过调整烟花弹爆炸的最大半径,可以均衡算法的全局搜索和局部搜索能力。由此可知,烟花爆炸产生火花需要火花数和爆炸半径2个参数控制。
根据文献[5],每个烟花弹Xi产生火花的数量为
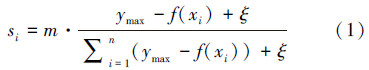

根据文献[8]中,采用如下方式计算爆炸半径:

一般而言,二进制编码比实数编码的搜索能力强,操作简单,由于烟花算法的烟花弹位置被定义为二进制串,所以首先是对位置的变换进行定义。
基于二进制编码烟花算法(BFA)中,设烟花弹是长度为m的二进制码,如图 1所示,根据爆炸半径r,控制烟花弹Xi的爆炸范围,即在1~r更新二进制位。半径r是随着迭代次数非线性递减的。Xi的每一位二进制位可以通过变异bk的对应位得到,bk可以由概率p得到,表达式为
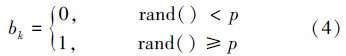
 |
| 图 1 烟花位置更新图解 |
位置在更新时,随机产生一个[0, 1]的随机数rand(),如果rand()
根据上述对二进制烟花算法的设计和定义,BFA算法的步骤可描述如下:
1)初始化N个烟花的位置,即随机产生Xi。
2)根据式(2)计算火花数s,根据式(3)确定爆炸半径r。
3)根据位置更新式(4),爆炸产生火花Xe。
4)将爆炸产生的火花和原烟花解码并评价其适应度值f(Xi)(或f(Xe))。
5)选出N/2个质量最好的火花(烟花),再从剩余的火花(烟花)中随机选择N/2个,作为下一次迭代的烟花。
6)记录全局最好位置G以及其适应度函数。
7)重复执行步骤2)~6),直到满足迭代终止条件。
2 基于BFA的聚类算法 2.1 BFA算法的编码本文的BFA聚类算法中,采用的是基于聚类中心的二进制编码方式。已知数据集包括M个数据点,每个数据点是一个包含D个属性特征的模式向量。设{A1,A2,…,AM}代表 1~M个数据点标号的二进制编码,长度为m。烟花的位置Xi是从M个数据点中选择K个作为聚类中心,如图 2所示。烟花弹由{C1,C2,…,Ck}组成,它的位置由K个二进制编码串组成。其中Ci表示聚类中心的二进制串,这样烟花弹的的位置是K×m的二维矩阵。
 |
| 图 2 烟花的编码结构 |
针对传统的聚类算法初始聚类中心敏感、容易陷入局部误区问题,本文采取群体智能优化算法的并行式搜索方式解决,在搜索空间内随机初始化种群规模为N的群体。为了提高初始聚类中心选取的有效性,在迭代开始前,需要控制种群规模N来避免初始点敏感问题,若N值较小或大多数初始值的选取偏离最优,也会造成初始点敏感,或陷入局部最优的情况;若N值较大,可能会造成初始解随机性降低,造成运算复杂。
虽然并行式搜索方式能够提高初始解的多样性,但随机产生的解还是会造成搜索空间内采样空白,造成搜索过程中偏离最优解,所以,在烟花算法迭代过程中,会抛弃一定数量超出搜索空间外的解,并在搜索空间内产生新的解,从而有效的避免采样空白的产生。
2.3 适应度函数群体智能优化算法的聚类分析往往使用Merwe等[9]提出的聚类误差方程作为适应度函数,Esmin等[10]改进了Merwe提出的适应度函数,他发现了不足,并提出了解决方案。此外,文献[11]中使用的k均值适应度函数,文献[12]中使用了FCM适应度函数,还有再此基础上提出的KFCM适应度函数[13]。
本文根据Esmin[10]提出的改进的聚类误差方程来计算适应度函数,当聚类中心确定时,按照下列方法确定适应度值。
1)算法使用欧式距离作为相似性度量,将该数据集合划分到制定的K类。
2)根据聚类划分,按照式(5)~(8)计算Jc:
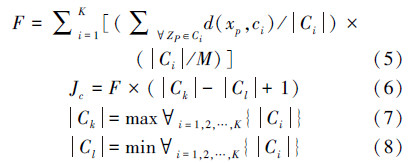
3)每个烟花弹的适应度值按照式(9)计算:

式中k为常数。如果Jc越小,个体适应度值越大,聚类效果越好。
2.4 基于BFA的聚类算法步骤BFA聚类算法首先定义基于聚类中心的二进制编码规则,每一次迭代都在当前烟花弹的基础上进行爆炸操作,通过适应度函数F评价烟花的适应度值,从中选取质量较好的火花(烟花)作为新一代的烟花。找出聚类问题的当前最优解,直到满足终止条件。具体步骤如下:
1)初始化种群规模为N的种群。
2)根据式(1)~(3)计算火花数和爆炸半径。
3)每个烟花Xi爆炸产生火花Xe。
4)对烟花和火花的集合R,根据式(5)~(9)计算每个个体的适应度值F,将最大F的个体定义为gbest。
5)选取集合R中适应度值最大的N/2个个体,在剩下的个体中随机选取N/2个,将此作为新一代的烟花。
6)重复执行步骤2)~5),直到满足迭代终止条件。
3 实验与分析 3.1 实验数据实验采用Indian Pine 数据集中的数据对本文算法进行性能评估。数据集是在1992年6月的印第安纳州西北的Indian Pine试验场,通过可见光红外成像仪(AVIRIS)成像得到的,图像数据由145 pix×145 pix的20 m空间分辨率220波段数组成,并且通过去噪得到200波段,如表 1所示,其中每种类别数据点是100个。测试数据取自UCI机器学习数据库,选取2组测试数据集Iris和Wine,如表 2所示。
| 数据名称 | 样本类别 | 类别数 |
| 数据集1 | 大豆1,2,3 | 3 |
| 数据集2 | 牧场,灌木,干草 | 3 |
| 数据集3 | 玉米1,牧场,灌木,乔木,大豆 | 5 |
| 数据集4 | 玉米2,灌木,大豆1,小麦,乔木 | 5 |
| 数据集5 | 玉米2,牧场,灌木,干草,大豆1,大豆3,小麦,乔木 | 8 |
精度评价是指比较实际数据和分类结果,以确定分类过程的准确度。最常用的精度评价方法是总体分类精度以及Kappa系数,其中总体分类精度定义为 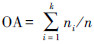 [14],其中ni为第i类正确分类的样本个数,n为样本的总个数。Kappa系数是另一种计算分类精度的方法,公式如下[14, 15]:
[14],其中ni为第i类正确分类的样本个数,n为样本的总个数。Kappa系数是另一种计算分类精度的方法,公式如下[14, 15]:
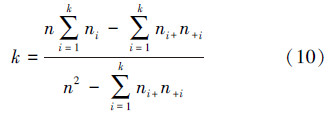
在实验中,设置烟花弹个数N,聚类数目k,控制产生火花总数的参数m,最大迭代次数T,数据集初始爆炸半径rinit和最后一次爆炸半径rend,如表 3所示。实验结果是各聚类算法在所有数据集上独立运行10次之后进行统计平均得到的,如表 4所示。
| 数据 | N | m | T | rinit | rend |
| 数据集1 | 50 | 300 | 100 | 8 | 4 |
| 数据集2 | 20 | 300 | 100 | 8 | 2 |
| 数据集3 | 20 | 300 | 100 | 9 | 4 |
| 数据集4 | 50 | 300 | 100 | 9 | 5 |
| 数据集5 | 20 | 300 | 100 | 8 | 2 |
| iris | 50 | 600 | 100 | 7 | 4 |
| wine | 50 | 600 | 100 | 7 | 6 |
| 算法 | 数据集1 | 数据集2 | 数据集3 | 数据集4 | 数据集5 | iris | wine | |||||||
| 总体精度/% | Kappa系数 | 总体精度/% | Kappa系数 | 总体精度/% | Kappa系数 | 总体精度/% | Kappa系数 | 总体精度/% | Kappa系数 | 总体精度/% | Kappa系数 | 总体精度/% | Kappa系数 | |
| k均值 | 74.73 | 0.621 0 | 89.37 | 0.840 5 | 66.76 | 0.584 5 | 71.88 | 0.648 5 | 64.53 | 0.594 6 | 78.13 | 0.672 | 69.33 | 0.537 1 |
| PSO | 73.67 | 0.605 0 | 93.40 | 0.901 0 | 68.28 | 0.603 5 | 75.14 | 0.689 3 | 66.35 | 0.615 4 | 90.4 | 0.856 | 71.24 | 0.567 3 |
| 本文算法 | 75.97 | 0.639 5 | 95.33 | 0.930 0 | 80.32 | 0.754 0 | 80.56 | 0.757 0 | 72.80 | 0.689 1 | 92.8 | 0.892 | 71.91 | 0.578 9 |
由表 3、4分析可知,相比较k均值和PSO算法,本文算法具有较高的总体精度和Kappa系数,性能较优。极大的改善了K-means聚类算法受初始聚类中心影响大的缺点。特别是类别数较多的情况,由表 4可知,数据集3和4包含5种类别的地物,分别较PSO算法精度提高了12.04%和5.42%。数据集5包含8中类别的地物,较PSO算法精度提高了6.45%,说明类别数较多的情况下,性能更优。
4 结束语本文提出了一种基于二进制编码的烟花聚类算法,该算法有效地利用了爆炸半径对搜索范围的控制,深度优化了全局搜索能力,从而提高了烟花算法鲁棒性。实验结果表明,本文算法不仅弥补了聚类算法的缺点,而且经过与k均值和PSO聚类算法的比较,总体分类精度和Kappa系数都有明显提高。优化精度和稳定性都明显高于PSO算法。因此,BFA在数据聚类相关领域有着良好的应用前景。
| [1] | 陈伟,傅毅,孙俊,等.一种改进二进制编码量子行为粒子群优化聚类算法[J].控制与决策,2011,26(10):1463-1468. |
| [2] | 李峻金,向阳,芦英明,等.粒子群聚类算法综述[J].计算机应用研究,2009,26(12):4423-4427. |
| [3] | CHENG Yongming,JIANG Mingyan,YUAN Dongfeng.Novel clustering algorithms based on improved artificial fish swarm algorithm[C]//Proceedings of the 6th International Conference on Fuzzy Systems and Knowledge Discovery.Tianjin,China,2009:141-145. |
| [4] | TIWARI R,HUSAIN M,GUPTA S,et al.Improving ant colony optimization algorithm for data clustering[C]//Proceedings of the 10th International Conference and Workshop on Emerging Trends in Technology.New York,USA,2010:529-534. |
| [5] | TAN Ying,ZHU Yuhui,TAN K C.Fireworks algorithm for optimization[C]//Proceedings of the 1st International Conference.Beijing,China,2010:355-364. |
| [6] | ZHENG Shaoqiu,JANECEK A,TAN Ying.Enhanced fireworks algorithm[C]//Proceedings of IEEE Congress on Evolutionary Computation.Cancun,Mexico,2013:2069-2077. |
| [7] | ZHENG Yujun,XU Xinli,LING Haifeng,et al.A hybrid fireworks optimization method with differential evolution operators[J].Neurocomputing,2015,148:75-82. |
| [8] | 曹炬,贾红,李婷婷.烟花爆炸优化算法[J].计算机工程与科学,2011,33(1):138-142. |
| [9] | VAN DER MERWE D W,ENGELBRECHT A P.Data clustering using particle swarm optimization[C]//Proceedings of the 2003 Congress on Evolutionary Computation.Canberra,Australia,2003:215-220. |
| [10] | ESMIN A A A,PEREIRA D L,DE ARAUJO F.Study of different approach to clustering data by using the particle swarm optimization algorithm[C]//Proceedings of IEEE World Congress on Computational Intelligence.Hong Kong,China,2008:1817-1822. |
| [11] | 刘靖明,韩丽川,侯立文.基于粒子群的K均值聚类算法[J].系统工程理论与实践,2005(6):54-58. |
| [12] | TOREINI E,MEHRNEJAD M.Clustering data with particle swarm optimization using a new fitness[C]//Proceedings of the 3rd Conference on Data Mining and Optimization.Putrajaya,Malysia,2011:266-270. |
| [13] | NIAZMARDI S,NAEINI A A,HOMAYOUNI S,et al.Particle swarm optimization of kernel-based fuzzy c-means for hyperspectral data clustering[J].Journal of applied remote sensing,2012,6(1):063601. |
| [14] | 孙家抦.遥感原理与应用[M].2版.武汉:武汉大学出版社,2009:215-216. |
| [15] | 王立国,魏芳洁.结合APO算法的高光谱图像波段选择[J].哈尔滨工业大学学报,2013,45(9):100-106. |