

DOI:10.11991/yykj.201503003

 ,
,
,
,
,
,
2. Technology and Engineering Center for Space Utilization, Chinese Academy of Sciences, Beijing 100094, China
在空间遥感任务中,光电探测器在工作时会产生一定的热,影响探测器的灵敏度,特别是很多红外探测器必须在低温环境下才能工作,对温度的稳定度要求很高,因此制冷机是探测器非常关键的设备[1]。斯特林制冷机具有制冷范围宽、启动时间短、可连续工作等特点,目前在工程上广泛应用。斯特林制冷机是逆向斯特林循环工作的制冷机,包括压缩机和膨胀机,制冷原理是利用膨胀缸内气体周期性膨胀和压缩来制取冷量,因此制冷过程需要一定的时间,且由于工作工程中的器件磨损等原因,总的制冷时间也是有限的。例如某型号的斯特林制冷机,设计指标为开关次数4 000次,制冷时间2 500 h,属于寿命敏感设备。
在空间遥感任务中,光电探测器在开始工作前需要制冷机先行开机制冷,制冷机能否在探测器开机工作前达到制冷目标对探测器能否顺利工作有很重要的影响。因此,如何预测制冷机的性能趋势,提出最优的使用、维修决策,提高其可用性,是制冷机非常重要的研究内容。本文通过研究表征斯特林制冷机性能的特征参数-制冷机制冷长,对其进行中长期预测研究,从而判断制冷机的工作状态及未来的可用性,为航天遥感任务安排提供有效依据。
制冷机工作在软件上定义了功率输入曲线,或称为降温曲线,以某型号的斯特林制冷机为例,在制冷机开机时电流维持在2 A左右,然后随着降温,电流缓慢爬升,达到4 A的峰值电流,当温度到达指定温度时,电流回落到稳态电流(维持控温点需要的功耗)。根据制冷机工作时的电流特性,可以从电流的变化的数据中提取出从初始温度到达目标温度所用的时间(即制冷机制冷时长)。通过对某型号的制冷机制冷时长数据的分析,其随工作时间的累积呈现出明显的时间序列数据特点[2],故对制冷机制冷时长的预测研究属时间序列的预测研究范畴。
国内外在时间序列的预测上有很多成熟的模型算法,主要分为两类:一是线性时序预测方法,典型的算法有AR模型及其改进模型ARMA、ARIMA模型[3, 4]等。另一类是非线性时序预测方法,这类方法主要包括神经网络时序预测方法、灰色预测方法、指数加权滑动平均方法[5, 6, 7]等。用于时序预测的神经网络模型(ANN模型)有径向基函数神经网络、BP神经网络、小波神经网络以及模糊神经网络等,例如Tiffany Hui-Kuang Yu[8]等应用二维模糊神经网络模型进行时序预测。适用于这2类方法的时间序列大多有一个共同的特点:时间采样周期相同或者时间采样周期对预测结果无影响。而制冷机制冷时长数据受到其间歇工作模式的影响,在采样周期上有不同于其他时间序列的特点,且对结果有着不可忽略的影响,因此,这些方法并不适合制冷机制冷时长预测。
对此本文提出了一种针对制冷机制冷时长这类采样周期不均等的数据预测的算法—改进的ARIMA-ANN算法,并以某型号的制冷机制冷时长数据为例进行了算法验证。
1 算法模型
一般地,在时间上顺序变化的一组参数数据变化规律可用如下时间序列模型描述[2]:
Pt=Tt+St+Xt (1)
式中:Pt为参数观测值,Tt为参数趋势项,St为参数周期项,Xt为参数波动项。本文研究的数据为从2011年10月到2014年6月某型号制冷机在轨工作制冷时长数据,如图 1所示。在此期间该制冷机有27个工作周期(相邻两次工作周期的时间间隔为7~20 d不等),制冷机开关机共476次(各工作周期内开关机次数10~50次不等,且相邻两次开机间隔5~24 h不等),从图 1可以看出其并没有明显的周期性。图 2是每个工作周期的第1次制冷机开机工作的制冷时长曲线,图 3是各工作周期内每次制冷机开机工作的制冷时长与该周期第1次制冷时长的差值曲线,从中可以看出数据呈现一定的波动性,因此针对制冷时长时间序列,预测模型简化为
Pt=Tt+Xt (2)
 |
| 图 1 全周期制冷机制冷时长曲线 |
 |
| 图 2 各周期第1次开机工作制冷时长曲线 |
 |
| 图 3 各周期内开机工作制冷时长与该周期第1次制冷时长的差值曲线 |
式(2)将斯特林制冷时长的预测分为趋势项Tt预测与波动项Xt预测,其中,趋势项为各工作周期第1次开机工作的制冷时长,波动项为各工作周期内每次制冷机开机工作的制冷时长与该周期的第1次制冷时长的差值。
1.1 趋势项预测模型
在时间序列预测中,基于平稳过程的时间序列模型是一类基本模型,其中,自回归滑动平均模型(auto-regressive and moving average model,ARMA 模型),由于其综合考虑了自身回归项及模型误差而成为一种标准方法。ARMA模型由自回归模型(简称AR模型)与滑动平均模型(简称MA模型)构成。ARMA的基本模型如下:
Yt=β1Yt-1+β2Yt-2+…+βtYt-p+Zt (3)
式中:Yt为预测对象的观测值,βt为自回归系数,Zt为Yt的误差项。ARMA模型假设时间序列为平稳过程[9],但图 1中制冷时长数据具有明显的上升趋势,因此ARMA模型并不适合制冷时长数据。对此,自回归积分滑动平均(autoregressive integrated moving average model,ARIMA)模型在ARMA模型的基础上建立了新的时间序列模型,它解决时间序列本身不具有平稳性,但是在d阶差分之后,所得的新时间序列具有平稳性的问题。图 4显示了制冷时长序列一阶差分数据。
 |
| 图 4 全周期制冷机制冷时长一阶差分曲线 |
由图 4可以看出,差分数据显示出了较明显的平稳特征,即制冷机制冷时长数据的一阶差分为平稳时间序列,符合ARIMA模型的假设,因此采用ARIMA模型进行制冷机数据的趋势项预测。
ARIMA的基本模型为
Yt=β1Yt-1+β2Yt-2+…+βtYt-p+Zt (4)
式中:Yt为预测对象的d阶差分,βt为自回归系数,Zt为Yt的误差项。制冷时长的长期趋势预测中,首先分析可能影响长期趋势预测的因素。由图 1可知,随着制冷机累计工作时间的增加,制冷机冷时长整体上呈现出增长趋势,这是由于制冷机性能的退化导致。因此制冷机的累计开机工作时间是影响制冷机制冷时长的一个重要因素,预测模型应对其进行建模。
图 5给出了周期间时间间隔与制冷时长之间的关系。
 |
| 图 5 相邻2次工作周期的时间间隔和对应制冷时长一阶差分散点图 |
由图可知,当2次工作周期的间隔大于1 500 000 s(约17 d)时,制冷时长较上一工作周期的最后一次有所下降;而当工作周期间隔小于1 500 000 s时则制冷时才有较大波动。因此,相邻2次的工作周期的时间间隔对各工作周期的第1次开机制冷时长有很大影响,即工作周期的时间间隔在进行趋势项预测时也是必须要考虑的因素。
在利用ARIMA模型(4)进行趋势预测时,误差项Zt本质上是进行波动项预测,而波动项预测将在下面的小节中进行建模,因此在制冷时长的趋势项预测中去除了Zt项。
综上所述,在原始ARIMA模型的基础上,通过分析制冷机制冷时长数据的特性,提出了如下改进的ARIMA模型进行制冷时长趋势项的预测:
Yt=β1Yt-1+β2Yt-2+…+βpYt-p+α1T1+α2T2 (5)
式中:Yt代表工作周期第1次开机制冷时长差分值,Yt-1、Yt-2、…、Y、代表与之相邻的前p次制冷机开机制冷时长差分值,T1代表制冷机累计开机工作时间,T2代表相邻工作周期时间间隔。式(5)为关于参数β1,β2,…,βp,α1,α2的线性方程,因此其求解可以看做线性方程组的求解问题,采用最小二乘法进行求解。
1.2 波动项预测模型
上面对各周期第1次开机工作的制冷时长进行了预测,本节将对各周期内其他各次开机工作的制冷时长进行预测。周期内其他开机制冷时长与第1次开机制冷时长的差值呈现出随机波动性,如图 3所示。这些随机波动具有非线性,而神经网络具有非线性映射的能力,因此,采用神经网络进行波动项的预测。
神经网络模型的示意图如图 6所示,它包含输入层、若干隐含层及输出层。给定神经网络的结构,即输入层结点个数、隐含层层数、隐含层各层结点个数、传递函数。通过BP算法,利用实际输出与期望输出之差对网络的各层连接权值由后向前进行逐层校正就可进行神经网络模型的训练。理论上,只包含1个隐层的三层神经网络就能够以任意精度逼近任何非线性连续函数[10]。
 |
| 图 6 神经网络模型 |
在建立神经网络模型之前,首先分析可能引起数据波动的因素。在图 3中,随着开关机次数的增加,制冷时长的波动幅度越来越大,由此可知:制冷机在轨运行的总时长T对数据的波动有影响,而总时长T包括总开机工作时间T3与总待机时间T4。
图 7给出了周期内累积工作时间对制冷时长的影响,其横坐标是某型号制冷机的第20个工作周期制冷机开关机次数,纵坐标是该周期内31次开机工作制冷时长与第1次制冷时长的差值曲线,可以看出随着周期内相对于第1次开机的累积开机工作时间T5增加,制冷时长有所增加。
 |
| 图 7 周期内累积工作时间对制冷时长的影响 |
图 8给出了周期内相邻2次工作间隔对制冷时长的影响。从图中的散点分布可以看出当间隔大于18 000 s(约等于5 h)时,制冷时长较上次会有所减少或保持不变,而当间隔小于18 000 s时则有较大波动,因此,相邻两次开机工作的间隔时长T6对数据的波动有影响。
 |
| 图 8 第2个工作周期内相邻2次的开机工作间隔与相邻2次的制冷时长差值关系散点图 |
除以上因素外,上一次制冷机开机工作时长T7会影响制冷机的工作性能,从而也会影响下次制冷机制冷时长。为了在神经网络的周期内波动项预测中综合考虑以上各因素,神经网络模型的结构确定为:输入层节点个数5个,分别为制冷机总开机工作时间、制冷机总待机时间、制冷机周期内第1次工作之后的累计工作时间、制冷机相邻2次开机时间间隔、制冷机上一次开机工作时长;中间隐层为一层,节点个数为8个;输出层为一个输出节点,为周期内当前开机制冷时长与周期内第1次工作制冷时长的差值。
波动项预测的神经网络模型如下:
Xt=f(T3,T4,T5,T6,T7) (6)
式中:Xt周期内当前开机制冷时长与周期内第1次工作制冷时长的差值,(T3,T4,T5,T6,T7)分别为制冷机的总开机工作时间、总待机时间、相对于周期内第1次的累计工作时间、相邻一次开机时间间隔、上一次开机工作时长。给定神经网络,通过BP算法进行训练得到神经网络的参数,从而就可以进行周期内波动项的预测。给定趋势项得到的周期第1次工作的制冷时长及周期内的波动项预测结果,通过式(2)就可以进行制冷时长的预测。
2 实验结果及分析
实验中,为了对本文提出的ARIMA-ANN模型的有效性进行验证,其将与ARIMA模型、ANN模型进行比较,数据选取了某型号斯特林制冷机第20个工作周期的15次开机制冷时长的中期预测。
2.1 自回归积分滑动平均模型预测(ARIMA模型)
ARIMA模型利用第20个工作周期以前的制冷时长数据进行建模。一般的ARIMA模型为ARIMA(p,d,q),其中3个超参数p为自回归变量个数,d为差分阶数,q为误差项变量个数。在进行预测之前,首先对ARIMA模型进行模型选择,模型选择以最小信息准则[11](Akaike information criterion,AIC)的值为准,不同ARIMA模型的AIC值如表 1所示。
| ARIMA模型 | AIC值 | ARIMA模型 | AIC值 | |
| (3,1,2) | 3.403 4 | (4,1,4) | 3.419 3 | |
| (3,1,3) | 3.392 5 | (5,1,2) | 3.402 5 | |
| (3,1,4) | 3.394 9 | (5,1,3) | 3.414 7 | |
| (4,1,2) | 3.373 3 | (5,1,4) | 3.416 3 | |
| (4,1,3) | 3.374 8 |
由表 1可知,ARIMA(4,1,2)模型的AIC值最小,因此利用此模型进行预测。ARIMA模型的预测结果如图 9所示,与真实结果的误差曲线如图 10所示。
 |
| 图 9 ARIMA模型预测结果拟合曲线 |
 |
| 图 10 ARIMA模型预测结果误差曲线 |
从中可以看出,ARIMA模型的预测误差较大。计算得出ARIMA模型的预测结果与真实结果之间的均方误差为
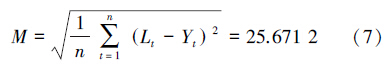
ARIMA模型的预测误差较大,其主要原因为在制冷机制冷时长时间序列中存在2种不同的随机序列,分别为周期间的随机序列与周期内的时间序列。由于周期间的随机序列的时间间隔较周期内的时间间隔要大很多,因此这2种随机序列用统一的ARIMA模型进行建模时会存在误差,特别是当进行中长期预测时,误差会更大。
2.2 神经网络模型预测
根据波动项预测的分析,在神经网络模型中,制冷机的总开机工作时间、总待机时间、相邻2次开机时间间隔、上一次开机工作时长会对预测结果有不同程度的影响,因此设定神经网络模型的输入层为4个神经元。隐含层根据经验公式m+n+a,其中m、n分别是输入层和输出层的神经元个数,a是0~10之间的常整数。经过多次试验,令隐含层的神经元数为6个。神经网络的输出为预测的制冷时长。给定神经网络结构,利用MATLAB自带的BP算法进行神经网络模型的训练,BP算法参数设定如下:
1)传递函数为sigmoid函数,即

2)学习参数δ=0.4;
3)用梯度下降法,动量因子α=0.4;
4)训练精度为0.000 1。
以2013年7月24日之前的数据作为训练数据进行神经网络的训练,得到预测曲线及误差曲线如图 11、12所示,并计算得到其预测结果的均方误差为31.923 3。
 |
| 图 11 ANN模型预测结果拟合曲线 |
 |
| 图 12 ANN模型预测结果误差曲线 |
由图 11可见,ANN在对数据的波动预测结果很好,但总体预测误差较大,其主要原因与ARIMA模型误差较大原因类似,制冷机制冷时长时间序列中存在2种不同的随机序列,而在此ANN模型中将其统一为相邻2次开机时间间隔作为输入,并没有体现出2种随机序列的区别,在预测周期第1次工作制冷时长时产生了较大误差,而在长期预测中误差会传递到后面几次制冷时长的预测中,因此,中长期预测中整体误差偏大。
2.3 自回归积分滑动平均-BP神经网络模型预测
自回归积分滑动平均-BP神经网络(ARIMA-ANN)模型分为2部分预测,一是改进的ARIMA模型进行工作周期的第1次开机工作制冷时长的预测,二是ANN模型进行工作周期内的制冷时长相对于第1次数据的波动预测,最后进行两者的加和得到最终的预测结果。
在趋势项预测中,在预测第20个工作周期的第1次制冷时长时,由于ARIMA模型预测中分析得到ARIMA(4,1,2)模型的AIC值最小,因此采用此模型,利用2~19次工作周期的数据建立了18个方程,采用最小二乘法计算出趋势项预测模型的参数,并预测第20次工作周期第1次加电制冷时长。
在进行周期内数据相对于第1次数据的波动预测时,将制冷机的总开机工作时间、总待机时间、相对于周期内第1次的累计工作时间、相邻一次开机时间间隔、上一次开机工作时长作为5个输入层,输出为一个神经元,令隐含层的神经元数为8个,并用MATLAB自带的BP算法进行实现,BP算法的参数与2.2节中BP参数的设定一样。
神经网络模型以2013年7月24日之前的数据作为训练数据进行训练得到模型的参数。
通过把神经网络得到的预测结果与趋势项预测的第1次工作制冷时长进行相加,最后得到的预测结果和误差如图 13、14所示,预测结果的均方误差为10.060。
 |
| 图 13 ARIMA-ANN模型预测结果拟合曲线 |
 |
| 图 14 ARIMA-ANN模型预测结果误差曲线 |
ARIMA-ANN模型得到更小预测误差的主要原因有2个:1)ARIMA-ANN模型对周期间的第1次制冷时长随机序列进行建模,而ANN模型对周期内的制冷时长随机序列进行建模,这种分别对不同的随机序列进行分别建模更符合制冷机制冷时长序列的特性。2)在模型中,综合考虑了周期间相邻2次工作时间间隔、制冷机累积工作时间、制冷机总待机时间等影响制冷机性能从而进一步影响制冷机制冷时长的因素,因此,本文提出的方法得到了更准确的预测结果。
3 结束语
提出了一种新的空间任务中具有间歇工作模式的斯特林制冷机制冷时长预测模型。该模型将斯特林制冷机制冷时长时间序列预测模型分解为趋势项与波动项预测2部分,然后,结合制冷机工作时间及间歇时间等信息利用改进的ARIMA模型进行趋势项预测,利用神经网络模型进行波动项预测。本文提出的模型与ARIMA模型及神经网络模型进行了中长期预测比较,实验结果验证了提出模型的有效性。
| [1] | 陆永达, 朱魁章, 杨坤, 等. 大冷量长寿命斯特林制冷机热环境适应性试验研究[J]. 低温与超导, 2012, 40(4): 5-8. |
| [2] | 刘祥明, 石为人, 范敏. 一种时间序列连续分段多项式模式表示方法[J]. 仪器仪表学报, 2014, 35(5): 1052-1056. |
| [3] | OWEN J S, ECCLES B J, CHOO B S, et al. The application of auto-regressive time series modelling for the time-frequency analysis of civil engineering structures[J]. Engineering Structures, 2001, 23(5): 521-536. |
| [4] | LIU Hui, TIAN Hongqi, LI Yanfei. Comparison of two new ARIMA-ANN and ARIMA-Kalman hybrid methods for wind speed prediction[J]. Applied Energy, 2012, 98: 415-424. |
| [5] | 冯志鹏, 宋希庚, 薛冬新, 等. 基于广义回归神经网络的时间序列预测研究[J]. 振动、测试与诊断, 2003, 23(2): 105-109. |
| [6] | 张大海, 江世芳, 史开泉. 灰色预测公式的理论缺陷及改进[J]. 系统工程理论与实践, 2002, 22(8): 140-142. |
| [7] | 张东, 安玉娥, 傅娟. 一种改进的基于指数平滑神经网络模型的时间序列预测方法[J]. 数学的实践与认识, 2013, 43(5): 20-28. |
| [8] | YU T H K, HUARNG K H. A bivariate fuzzy time series model to forecast the TAIEX[J]. Expert Systems with Applications, 2008, 34(4): 2945-2952. |
| [9] | 李庆雷, 马楠, 付遵涛. 时间序列非平稳检测方法的对比分析[J]. 北京大学学报: 自然科学版, 2013, 49(2): 252-260. |
| [10] | 钟诗胜, 朴树学, 丁刚. 改进BP算法在过程神经网络中的应用[J]. 哈尔滨工业大学学报, 2006, 38(6): 840-842. |
| [11] | AKAIKE H. Information theory and an extension of the maximum likelihood principle[C]// 2nd International Symposium on Information Theory, Tsaghkadzor, 1971: 267-281. |