

DOI:10.11991/yykj.201503013

 ,
,
,
,
抄袭是偷窃知识产权的行为,如何防范和遏制剽窃造假行为,建立一种快速、准确的论文抄袭检测模型具有现实意义,且已经成为人们的研究热点。20世纪末,随着互联网的兴起,针对文本的抄袭检测就已开始发展,至今已硕果累累[1, 2, 3, 4, 5],这些方法能够很好地完成复制检测,但却不能有效地在海量数据检测出复杂的抄袭行为,因此本文提出了基于信息检索系统和机器学习算法的抄袭检测方法,其相应的任务就是备选文档检索和基于SVM的详细比对,并同时研究了不同特征组合对实验的影响。
1 基于SVM的抄袭检测 1.1 备选文档检索
备选文档检索的任务就是从参考文档集中尽可能地检索出潜在的抄袭源文档,这些文档就叫做备选文档。备选文档检索为下一步的详细比对任务减少了工作量。
备选文档检索任务可以看作是信息检索的一个特例,在此阶段,最重要的是寻找可疑文档的最适用的关键词。在此次子任务中,本文采用Lucene进行备选文档的检索。
本文在构建查询时,采用词频-逆文本频率进行关键词的提取。词频-逆文本频率是文本分类中应用十分广泛的经典算法之一,原理是将词频(term frequency,TF)和逆文本频率(inverse document frequency,IDF)结合起来,如果某个词或短语在一篇文档中出现的次数多,并且在其他文档中出现的次数比较少,那么这个词在该文档中就具有很重要的意义。同时利用空间向量模型[6, 7](vector space model,VSM)作为计算文本相似度的模型。
备选文档检索具体做法分为分块、创建索引、文本预处理、获取查询、检索5个步骤:
1)分块。对可疑文档进行切分。对文本进行切分时,本实验采用的是把文本按固定大小(300个单词)进行切分。
2)创建索引。对于参考文档集,按照文本自然段建立索引。每篇可疑文档中的片段都有和它相对应的参考文档。
3)文本预处理。对可疑文档进行预处理,包括停用词的移除、大小写字母转化和词干提取。
4)获取查询。获取单词权重,对于可疑文档利用TF-IDF获得关键词,并排序得到相应的关键词列表。排在前n个的关键词组成一个查询,以此类推,本试验中n=5。
5)检索。在文档检索模块中,提交关键词组成的查询,调整提交查询个数的阈值、返回相关文档数的阈值等。
1.2 基于SVM的详细比对
此任务的主要目标是建立支持向量机分类模型,利用此分类模型判断一个可疑文档是否存在抄袭。SVM分类算法包括两个步骤:训练阶段和测试阶段。在训练阶段,利用训练集对分类算法进行训练,得到一个稳定的分类模型。在测试阶段,利用此分类模型对测试数据进行分类。
首先要有训练数据集。训练实例X是一个n维向量,X=(x1,x2,…,xn),其中,xi(1≤i≤n)表示特征的训练实例的值。对于每个训练实例,已经有了确定的类标号。分类器的目的就是判断可疑文档susi是否抄袭了它对应的备选文档srcj,因此,对于每次判断,都需要从一个文档对<可疑文档,备选文档>提取所需要的特征。对于特征的选取,丰富的特征则是影响机器学习算法性能的关键。经过实验验证,本实验采用了以下特征:余弦相似度、N-gram、Jaccard系数、Dice系数、Euclidean距离、Manhattan距离和Levenshtein距离等基于字符串相似度的方法提取的值作为特征值。
从PAN数据集得知,每个可疑文档都有一个相对应的标注文件,即XML文件,根据这些标注文件可以定位此文本中存在抄袭的片段及其抄袭源。得到稳定的模型后,利用测试数据对分类器进行测试,从而判断可疑文本是否是抄袭的。本实验使用的台湾大学林智仁副教授开发的LibSVM。
详细比对是本研究的重点。对于可疑文档集中的每个可疑文档,首先把文档拆分成文本块。然后,对每个文本块利用信息检索系统进行备选文档的检索,返回最有可能存在抄袭的N个备选文档。最后,使用特征提取方法,对于每个可疑文本块及其备选文本块进行提取特征,得到它们的特征向量后,就可以使用分类器进行判断了。
1.3 文本特征提取
在详细比对阶段需要对文本提取特征,进而构造特征向量用于SVM的训练和测试。
特征提取是指依照某个特征评估函数计算出每一个特征的分值,选取若干个评分值较高的特征作为特征向量。文本分类中,用于特征提取的方法有:余弦相似度(cosine similarity)、信息增益方法( IG) 、互信息方法(MI) 、χ2统计量方法(CHI) 、词性标注(part of speech)的特征选择方法等。当选定某种分类算法,特征提取在文本分类中起着至关重要的作用,优秀的特征选择方法可以有效减少特征空间的维数。
1.4 评测方法
本文采用PAN会议所定的评测方法[8],包括召回率、准确率、粒度和总体性能。精确率用来衡量检索出来的数据的准确性,召回率能衡量可以成功检索到相关文本的可能性,总体性能用来对系统的总体表现进行衡量,F1值能平衡地反映召回率与准确率。
令S表示语料库中抄袭片段的集合,R表示可疑文档中的抄袭片段集合,四元组s=<splg,dplg,ssrc,dsrc>,s∈S,表示文档dplg中的片段splg抄袭于文档dsrc中的ssrc片段;抄袭片段r=<rplg,dplg,rsrc,dsrc′>表示文档dplg中的片段rplg抄袭于文档dsrc′中的片段rsrc,其中r∈R。那么,精确率prec(S,R)和召回率rec(S,R)分别表示为
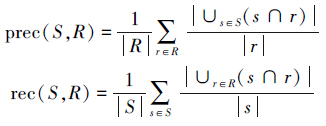
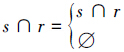 ,s∩r=s∩r表示片段r抄袭了片段s,s∩r=∅表示片段r没有抄袭片段s。
,s∩r=s∩r表示片段r抄袭了片段s,s∩r=∅表示片段r没有抄袭片段s。精确率和召回率并不能全面反应抄袭检测方法的优劣,有时候会出现一种现象:有多个片段r对应了同一个抄袭案例s,这种情况影响了召回率和精确率,进而,需要引入另外一个度量粒度:
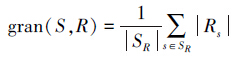

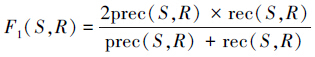 。
。
2 支持向量机
1992~1995年,Vapnik等在统计学习理论的基础上发展了支持向量机算法。它综合了结构风险最小化理论与VC维理论,充分考虑了训练误差与泛化能力,成功地解决了小样本、非线性以及高维模式识别的问题,并表现出了许多特有的优势。
2.1 算法策略
支持向量机算法是典型的监督式学习方法。首先,将向量映射到更高维的空间,在其中建立最大间隔的分离超平面,将数据分开;然后,在分离超平面两边再设立两个互相平行的超平面,分离超平面使两个平行超平面有最大的距离。支持向量机算法假定平行超平面间的距离最大时,分类器存在最小的误差率。
2.2 超平面
超平面的数学形式可以表示为
w·x-b=0
式中:x是超平面上的样本点,w是超平面上的一个垂直向量,b是截距,如图 1所示。 |
| 图 1 超平面 |
图中:①的函数为wx-b=1,②的函数为wx-b=0,③的函数为wx-b=-1。如图 1可知,平行超平面可以表示为以下2个方程:
wx-b=1
wx-b=-1
式中:w为超平面的法向量,它是一个自变量。如果是线性可分的数据,那么可以找到2个超平面,超平面之间没有分布任何一个样本点,并且这2个超平面之间有最大的距离。这2个超平面之间的距离是2/‖w‖,所以需要进行‖w‖最小化的计算。因为2个超平面之间不存在任何样本点,xi需要满足以下2个条件之一:
wxi-b≥1
wxi-b≤-1
2.3 支持向量机的特点
因为有着坚实的理论基础,支持向量机算法具有巨大的潜在研究价值和应用价值,其主要特点有:
l)支持向量机方法以统计学习理论中的结构风险最小化理论为基础,通过寻找具有最大间隔的分离超平面来控制模型的复杂度,有着最小的经验风险,可以有效地避免出现过拟合的情况。
2)针对有限样本,支持向量机算法的目的是在现有信息下得到最优解,而不单单是在样本数趋于无穷大时求解最优解。
3)支持向量机求解的本质是解决凸二次优化问题,全局最优点就是需要求解的极值点,从而避免了局部极值问题。
4)支持向量机中核函数的巧妙选择为成功地解决非线性判别问题提供有力的保障[9],通过稀疏的支持向量组合方法解决特征维数灾难问题。
3 实验结果与分析 3.1 备选文档检索
本实验采用Pan@CLEF2012的训练数据集。此数据集涵盖了抄袭的5大类型:No obfuscation、Artificial low、Artificial high、Simulated和Translation。针对每一个抄袭类型,从中随机选择20篇可疑文档,共有100篇可疑文档,与4 210篇参考文档一起作为本实验的实验数据。使用的评测方法是1.4节所述的方法。实验结果如表 1所示。
| 抄袭类型 | 精确率 | 召回率 | 总分 |
| Simulated数据集 | 0.147 | 0.168 | 0.156 |
| Translation数据集 | 0.284 | 0.171 | 0.213 |
| Artificial high数据集 | 0.432 | 0.190 | 0.264 |
| Artificial low数据集 | 0.334 | 0.451 | 0.384 |
| No obfuscation数据集 | 0.227 | 0.261 | 0.242 |
| 所有数据集 | 0.246 | 0.266 | 0.255 |
在本试验中,在所有数据集上得到的精确率、召回率和总分分别为0.246、0.266和0.256,把此数据作为Baseline,在5种抄袭类型的数据中,Artificial high数据集得到最高的精确率0.432,Artificial low数据集得到的召回率和总分最高,分别为0.451和0.384,说明使用同一个关键词提取方法,在不同的数据集上得到的效果是不一样的。文献[10]中,PAN@CLEF2012的参赛小组提交的5种备选文档检索算法中,都使用了牺牲召回率而得到高的精确率的策略,其中最好的精确率为0.556 7,而最好的召回率仅为0.069 8。经对比,本实验得到的召回率和精确率得到了一个较好的平衡,说明本实验使用的关键词提取方法能够有效地进行关键词的索引,从而得到高质量的备选文档。
3.2 详细比对
本文实验采用PAN@CLEF2012的实验数据集,数据集包括了不同的子数据集,分别为:Real cases(数据集1)、Simulated(数据集2)、Translation(数据集3)、Artificial high(数据集4)、Artificial low(数据集5)、No obfuscation(数据集6)。使用的评测方法是1.4节所述的方法。
在对比结果的时候,本论文选取了PAN@CLEF 2012排名前三的方法,分别是Kong[11]、Suchomel[12]和Grozea[13]提出的方法。在详细比对阶段,为了找出与可疑文档对应的源文档,Kong提出了一种基于语义相似度和结构相似度的方法。Suchomel使用文本对的特征并计算特征之间的距离。Grozea的目的是得到一个高召回率,他使用N-gram进行文本块的匹配,并利用启发式聚类算法得到抄袭文档及其抄袭源。对比结果如表 2所示。
| 抄袭类型 | 总分 | 精确率 | 召回率 | 粒度 |
| 数据集1 | 0.725 | 0.776 | 0.680 | 1.000 |
| 数据集2 | 0.705 | 0.911 | 0.575 | 1.000 |
| 数据集3 | 0.721 | 0.839 | 0.633 | 1.000 |
| 数据集4 | 0.335 | 0.823 | 0.211 | 1.020 |
| 数据集5 | 0.748 | 0.930 | 0.638 | 1.100 |
| 数据集6 | 0.872 | 0.817 | 0.934 | 1.000 |
如表 2所示,本论文的方法在各个数据集中粒度指标与其他3种方法相差无几,在数据集5中却优于其他3种方法。在精确率指标上,对于数据集4,本论文的方法优于其他3种方法,但是在召回率和总分指标上却要明显低于其他3种方法,可能的原因就是在实验中选取的特征的代表性不高,使用SVM判断区别度不高的2个文本片段的效果不是很好。本文提出的方法在总分指标上总是低于Kong提出的方法,但是对于数据集1和2,本文的方法明显的要好于Suchomel和Grozea所提出的方法。在子数据集1中,本文得到的召回率明显优于其他3种方法,而在其他指标上劣于其他3种方法。
对比表 2可知,本文所提出的方法在各个子数据集上表现的结果在总体上略逊于Kong提出的方法,但是明显优于其他2种方法,因此文中提出的基于SVM的抄袭检测的方法具有一定的可行性。
如表 3所示,在总数据集中各项指标对比中,本论文提出的方法的召回率比其他3种方法要高,但是精确率和总分却介于Kong和Suchomel之间。因此,基于SVM的抄袭检测系统在PAN@CLEF2012数据集上能够表现出良好的性能。同时也说明,本论文提出的基于信息检索系统和支持向量机的抄袭检测方法能够处理互联网上海量的文本,并取得了较好的成绩。
| 指标 | 本文方法 | Kong | Suchomel | Grozea |
| 总分 | 0.708 | 0.738 | 0.682 | 0.678 |
| 精确率 | 0.745 | 0.824 | 0.893 | 0.774 |
| 召回率 | 0.692 | 0.678 | 0.552 | 0.635 |
| 粒度 | 1.000 | 1.010 | 1.000 | 1.030 |
4 结束语
经过实验证明,本文提出的基于信息检索和支持向量机的抄袭检测方法是可行的,无论是高模糊度抄袭还是逐字抄袭,精确率和召回率都得到了一定的提高,且取得了不错的性能,无论是在实践中还是在理论上都是有一定价值的。但是,由于精力的限制,本研究还是存在着很多不足,需要做进一步的改进。最显著的是,因为SVM的空间复杂度比较大,在进行训练和测试时,实验花费了大量的时间,这也限制了SVM在文本抄袭检测演技的扩展和推广。机器学习算法多种多样,因此,下一步的研究工作是,探索和选择更适合文本抄袭检测研究的分类器。
| [1] | SCHLEIMER S, WILKERSON D S, AIKEN A. Winnowing: local algorithms for document fingerprinting[C]//Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data. New York, USA, 2003: 76-85. |
| [2] | POTTHAST M, BARRÓN-CEDEÑO A, EISELT A, et al. Overview of the 2nd International Competition on Plagiarism Detection[C]// BRASCHLER M, HARMAN D eds. Notebook Papers of CLEF 2010 Labs and Workshops. Padua, Italy, 2010. |
| [3] | MAURER H, KAPPE F, ZAKA B. Plagiarism-a survey[J]. Journal of Universal Computer Sciences, 2006, 12(8): 1050-1084. |
| [4] | 李旭东. 计算机程序抄袭检测系统的设计方案[J]. 电脑知识与技术, 2012, 8(4): 799-800. |
| [5] | WISE M J. YAP3: improved detection of similarities in computer program and other texts [C]//Proceedings of the 27th SIGCSE Technical Symposium on Computer Science Education. New York, USA, 1996: 130-134. |
| [6] | SALTON G, WONG A, YANG C S. A vector space model for automatic indexing[J]. Communications of the ACM, 1975, 18(11): 613-620. |
| [7] | JIFFRIYA M, JAHAN M A, RAGEL R G. Plagiarism detection on electronic text based assignments using vector space model[C]// /The 7th International Conference on Information and Automation for Sustainability (ICIAfS). Colombo, Sri Lanka, 2014. |
| [8] | POTTHAST M, STEIN B, EISELT A, et al. Overview of the 1st International Competition on Plagiarism Detection[C]//STEIN B, ROSSO P, STAMATATOS E, et al. eds. EPLN 2009 Workshop on Uncovering Plagiarism, Authorship, and Social Software Misuse (PAN 09), 2009: 1-9. |
| [9] | JUAN D U, ZHANG W L, XIE M M. Research of a new SVM kernel function[J]. Applied Mechanics & Materials, 2014(543-547): 1659-1665. |
| [10] | POTTHAST M, GOLLUB T, HAGEN M, et al. Overview of the 4th International Competition on Plagiarism Detection[C]//CLEF (Online Working Notes/Labs/Workshop). 2012. |
| [11] | KONG Leilei, QI Haoliang, DU Suhong, et al. Approaches for candidate document retrieval and detailed comparison of plagiarism detection[C]// CLEF 2012 Conference and Labs of the Evaluation Forum. Rome, Italy, 2012. |
| [12] | SUCHOMEL Š, KASPRZAK J, BRANDEJS M. Three way search engine queries with multi-feature document comparison for plagiarism detection[C]// CLEF 2012 Conference and Labs of the Evaluation Forum. Rome, Italy, 2012. |
| [13] | GROZEA C, POPESCU M. Encoplot - Tuned for High Recall (also proposing a new plagiarism detection score) [C]// CLEF 2012 Conference and Labs of the Evaluation Forum. Rome, Italy, 2012. |