

DOI:10.11991/yykj.201412006

 ,
,
可用于分类的方法有:决策树、遗传算法、神经网络、朴素贝叶斯、支持向量机、基于投票的方法、KNN分类、最大熵等[1]。k-近邻分类算法(k-nearest neighbor,KNN)是Covert和Hart于1968年首次提出并应用于文本分类的非参数分类算法[2]。KNN算法原理简单易懂,不用建立复杂模型的问题,对样本集的要求低,只需要具有测试样本和训练样本集合。样本集合不需要反复训练,虽然KNN算法在分类问题上有着许多的优势,但是以下不足对KNN算法的分类精度有很大的影响。首先,当样本集大时,计算速度慢,同时在分类决策时对k个近邻样本点赋予相同的分类贡献率,这显然是不符合实际情况的。其次,在小样本的情况下容易受到局外点的干扰。针对上述不足,很多学者提出了相应的改进算法。为了提高分类速度,降低计算复杂度,Juan L[3]建立了一个有效的搜索树TKNN,提高了k-近邻的搜索速度。Weinberger等[4]从侧度学习的角度,通过学习合适的马氏距离提出了基于k-近邻分类器的大边界准则。Dudani[5]提出了距离加权的k-近邻规则,该算法对离测试样本点近的近邻点赋予大的权重,对离测试样本点远的点赋予小的权重。为了克服局外点的干扰,Zeng等[6]提出一种距离权重的局部学习的伪k-近邻算法。Yang等[7]提出一种广义的最近邻分类方法,通过计算每类训练样本集中选择出离测试样本最近的k个近邻,并求出测试样属于每一类的权值,最后把测试样本归为权值最小的所对应的类。Mitani等[8]提出一种可靠的基于局部均值的k-近邻算法。近质心近邻原则(NCN)作为近邻选择的一种有效方式,Sanchez等[9]在此原则以及k-近邻思想的基础上,提出了k-近质心近邻 (k-nearest centroid neighbor,KNCN) 分类算法并对KNCN相关算法作了详尽的概述[10]。KNCN不仅考虑近邻点应该离测试样本点尽可能的近,而且还考虑了近邻点分布在测试样本点周围的空间特性。苟建平[11]在KNCN的基础上提出了局部均值的k-近质心近邻算法。陈日新[12]在考虑测试样本对分类贡献的情况下提出半监督K近邻分类算法。虽然k-近质心近邻分类原则由于采取质心近邻选取原则,分类性能在一般情况下优于KNN算法。但也存在着一些不足:首先,在分类时不同的近质心近邻点在分类决策时具有相同的分类贡献率,这显然是不合理的;其次,在统计模式识别中,尤其在小样本的环境下,KNCN容易受到局外点的干扰。为了弥补分类贡献率和局外点干扰的不足,我们在KNCN的基础上提出一种基于局部权重K近质心近邻分类算法。
1 近质心近邻分类算法 1 近质心近邻分类算法
近质心近邻 (nearest centroid neighbor,NCN) 规则是一种有效的近邻选择方式。近质心近邻原则不但要保证测试样本点要离所选择的近邻点尽可能近,而且近邻点均匀的分布在测试样本点的周围。
1.1 近质心近邻选取原则
近质心近邻也要像近邻原则一样,考虑测试样本点与其近邻的相似性程度,但是与近邻原则不同的是,近质心近邻原则还考虑了这些近邻点在测试样本点周围的空间分布特性。对于一个测试样本点x,近质心近邻点的选取应该满足以下2个条件: 1)在距离上测试样点x要选择离x近的点质心点;2)质心近邻点要均匀的分布在测试样本点x的周围。
一组训练样本点X=x1,x2,…,xn,质心定义为
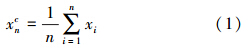
因此,在一组给定的训练样本集T=xi∈Ri=1mn上,根据近质心近邻原则待测样本点x的近质心近邻点求解过程如下,首先要满足上述2个条件,然后通过以下2步迭代得到:
1)在训练样本集上搜索测试样本点x的第一个近质心近邻点x1ncn,也就是近邻原则的最近的近邻点;
2)在训练样本集上查找测试样本点x的第i个近质心近邻点xincn(i≥/),第i个近质心近邻点的定义如下:按照质心公式计算Ti中的每个点与前面已经找到的i-1个近质心近邻点的质心,即计算Ti中每个点与x1ncn,x2ncn,…,xi-1ncn的质心点,然后计算测试样本点x到这些质心点的距离,选取离测试样本点x距离最近的质心点对应的Ti中的那个训练样本点为第i个近质心近邻点xincn。注意,在计算第i近质心点时,Ti中的所有点是剔除i-1个近质心近邻点以外的T中所有的剩余训练样本点,同时Ti中的所有点都要遍历到,以保证找到离测试样本点x最近的质心点所对应的近邻点xincn。
1.2 k-近质心近邻选取原则
在近质心近邻原则(NCN)和k-近邻思想的基础上,提出了k-近质心近邻分类算法(KNCN)。实验证明,该方法在训练样本有限的模式分类问题中取得了很好的分类效果。与k-近邻分类算法相似而又有所不同:相似之处是都要通过最大的投票原则来确定测试样本所属的类别,不同的是KNCN利用了k个近邻与测试样本点的相似性和空间分布特点。KNCN分类步骤如下:
给定m维特征空间的一组训练样本集T=xi∈Ri=1mn,该样本集T有n个训练样本,有m个类,其类别的标签为c1,…,cM。对一个测试样本点x,KNCN通过如下步骤确定x的类标签:
1)选定测试样本集合和训练样本集合;
2)确定质心近邻的个数k的初始值;
3)按照式(1)的计算方式,从T中查找测试样本点x的k个近质心近邻点,记作质心近邻点的样本集为
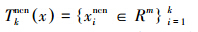
4)根据得到k个近质心近邻点,计算每个类别所包含的近邻质心近邻点的个数,将含有最大近质心近邻点个数的类别标签分配给待测样本点。
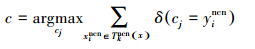
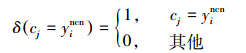
通过以上描述,KNCN和KNN都是通过投票原则,从训练样本集中查找待测样本点的k个近邻,但是确定k个近邻的方法是截然不同的过程,这k个近邻点也不完全相同。KNN算法通过距离确定训练样本和测试样本的相似性,而KNCN不仅通过距离衡量2个样本的相似性而且还强调选取的k个近邻点应尽可能地分布在测试样本点的周围。
2 基于局部权重的KNCN算法
KNCN提供了一种有效的近邻选取原则,但是在模式分类中仍然存在一些问题。主要体现在容易受局外点的干扰和在分类决策时认为所有的近邻点具有相同的分类贡献率。针对上述不足,在KNCN的基础上提出一种基于局部权重的k-近质心近邻分类算法,在每类中查找k个近邻质心点,有效地克服了局外点的干扰,同时它给不同近邻质心点在分类过程中赋予不同的权重。
2.1 局部权重k-质心近邻的基本思想
基于局部的权重的k-近质心近邻(k-nearest neighbor algorithm of near centroid based on local weight ,LWKNCN)的思想如下:根据NCN近邻原则确定测试样本在每一类k个质心点,也就是对于m个类,n1,n2,…,nM是属于1,2,…,M类样本的个数,x1jncn,x2jncn,…,xkjncn定义为属于测试样本x在第j∈1,2,…,M类的k个近邻质心点,d1jncn,d2jncn,…,dkjncn为测试样本x到这k个质心点的距离,并且是按照递增的顺序排列。由广义k-近邻规则的启发,不同的质心到测试样本的距离不同,对分类做出的贡献也不同,离测试样本近的质心对分类结果的贡献应该大于离测试样本远的质心所做的贡献。因此,应对离测试样近的质心距离赋予大的权重,对离测试样本远的质心距离赋予较小的权重,我们按照如下定义的权重系数公式对k质心距离进行权重分配。ωji为测试样本在第j类里到第i个近邻质心的权重,ωji定义为
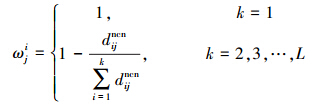
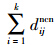 代表测试样本点到j类里k个近邻质心点的距离的总和。注意,如果k=1时,其权重分配为1;当k≠1是时根据其距离动态的分配权重。很明显,对离测试样本点近的质心能分配一个大的权重,离测试样本远的质心点分配小的权重。让sj为测试样本点在第j类里到k个近邻质心的距离权重和,sj的定义形式为
代表测试样本点到j类里k个近邻质心点的距离的总和。注意,如果k=1时,其权重分配为1;当k≠1是时根据其距离动态的分配权重。很明显,对离测试样本点近的质心能分配一个大的权重,离测试样本远的质心点分配小的权重。让sj为测试样本点在第j类里到k个近邻质心的距离权重和,sj的定义形式为
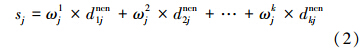
根据式(2)计算测试样本x到每一类的sjj=1,2,…,M,然后将具有最小权重距离的sj所对应的类别分配给测试样本x,测试样本类别判别函数如为
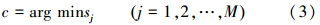
值得注意的是,当且仅当近邻个数k=1时,LWKNCN等同于最近邻(1-NN)分类算法,并且这k个质心点都是通过训练样按照质心公式计算出来,并不一定是原训练样本中的点。
2.2 局部权重k-近质心近邻算法基本流程
1)构建训练样本集合和测试样本集合,确定特征向量空间;
2)确定k的初始值;
3)应用式(1)从T中查找测试样本点x在第j∈1,2,…,M类的k个近邻质心点x1jncn,x2jncn,…,xkjncn,并求出测试样本x到这k个质心点的距离d1jncn,d2jncn,…,dkjncn,并按照递增的顺序进行排列。
4)根据式(2)计算出测试样本点在j∈1,2,…,M里的距离权重的和sj。
5)根据式(3)将具有最小距离权重的和sj所对应的类别分配给测试样本x。
3 仿真实验及分析
在模式分类问题中分类精度是评价算法性能重要指标之一,为了验证LWKNCN算法的分类效果,在分类精度的基础上,本文在5组UCI数据集进行随机选择测试样本来验证算法分类的有效性,并把我们所提出的算法同经典KNN算法和KNCN算法进行了对比实验。3种算法都采用欧式距离来计算测试样本和训练样本的相似度。
5组数据集都是来自用于机器学习的UCI数据库,主要信息包括:特征维数、样本数、测试样本数和类别数。表 1给出了5组数据集的基本信息。这些数据集中包括2个二分类问题和3个多分类问题,样本的属性都是实数便于计算相似度。
|
数据集 名称 | 特征 维数 | 样本 个数 | 测试样 本个数 | 类别 个数 |
| Iris | 4 | 150 | 48 | 3 |
| Pima-India diabetes | 8 | 768 | 268 | 2 |
| Thyroid disease | 21 | 7 200 | 3 428 | 3 |
| Ionosphere | 34 | 351 | 117 | 2 |
| Wave | 21 | 5 000 | 1 666 | 3 |
为了说明k值对分类精度造成的影响,本文选取不同的k值时,在5组UCI数据集上进行测试,得到分类精度随k值变化曲线图,如图 1所示。
 |
| 图 1 5个UCI数据集上分类精度随k值变化曲线 |
通过3种分类方法随近邻个数k变化的分类精度曲线图可知,与其他2种方法相比,LWKNCN在不同的k值的情况下,取得了良好的分类结果,在各个数据集上的分类精度明显高于KNN和KNCN算法。同时,KNN和KNCN是相对整个数据集寻找k个近邻点,而LWKNCN是在每类训练样本子集来寻找k个近邻质心点。
4 结束语
本文提出了一种新颖的近邻选取的分类算法,有效地克服了KNN和KNCN算法上的不足,通过仿真实验验证所提出的算法在模式分类问题中的有效性,通过观察分类精度曲线图可知,在个别的k值情况下LWKNCN与KNN和KNCN相当,在通常情况下分类精度明显高于KNCN和KNN算法,LWKNCN在近邻选取上不同于KNN和KNCN,该算法不仅考虑了近邻点应该尽可能靠近测试点并均匀地分布在测试样本点周围,而且还克服了局外点的影响以及对不同的近邻点赋予不同的分类权重,这更符合实际分类情况。本文提出的算法在实际中更具可操作性,易于应用到实际的分类问题。下一步应该研究如何进一步提高算法的执行效率。
| [1] | 奉国和. 自动文本分类技术研究[J]. 情报杂志, 2007, 26(12): 108-111. |
| [2] | COVER T, HART P. Nearest neighbor pattern classification[J]. IEEE Transactions on Information Theory, 1967, 13(1): 21-27. |
| [3] | LI Juan. TKNN: an improved KNN algorithm based on tree structure[C]//2011 Seventh International Conference on Computational Intelligence and Security (CIS). Sanya, China, 2011: 1390-1394. |
| [4] | WEINBERGER K Q, SAUL L K. Distance metric learning for large margin nearest neighbor classification[J]. The Journal of Machine Learning Research, 2009 (10): 207-244. |
| [5] | DUDANI S A. The distance-weighted k-nearest-neighbor rule[J]. IEEE Transactions on Systems, Man, and Cybernetics, 1976, SMC-6(4): 325-327. |
| [6] | ZENG Yong, YANG Yupu, ZHAO Liang. Pseudo nearest neighbor rule for pattern classification[J]. Expert Systems with Applications, 2009, 36(2): 3587-3595. |
| [7] | WANG B, ZENG Yong, YANG Yupu. Generalized nearest neighbor rule for pattern classification[C]// 7th World Congress on Intelligent Control and Automation. Chongqing, China, 2008: 8465-8470. |
| [8] | MITANI Y, HAMAMOTO Y. A local mean-based nonparametric classifier[J]. Pattern Recognition Letters, 2006, 27(10): 1151-1159. |
| [9] | SÁNCHEZ J S, PLA F, FERRI F J. On the use of neighbourhood-based non-parametric classifiers[J]. Pattern Recognition Letters, 1997, 18(11/12/13): 1179-1186. |
| [10] | SÁNCHEZ J S, MARQUÉS A I. Enhanced neighbourhood specifications for pattern classification[M]// Chen Dechang, Cheng Xiuzhen. Pattern recognition and String Matching. : Springer-Verlag US, 2002: 673-702. |
| [11] | GOU Jianping, YI Zhang, DU Lan, et al. A local mean-based k-nearest centroid neighbor classifier[J]. The Computer Journal, 2012, 55(9): 1058-1071. |
| [12] | 陈日新, 朱明旱. 半监督k近邻分类方法[J]. 中国图象图形学报, 2013, 18(2): 195-200. |