

DOI:10.3969/j.issn.1009-671X.201412002

 ,
,
,
,
,
,
,
,
2. 大连交通大学,交通运输学院,辽宁 大连 116028;
3. 日本富朗巴有限公司,日本 东京 1086021;
4. 大连中真智能科技开发有限公司,辽宁 大连 116028
2. School of Traffic and Transportation Engineering, Dalian Jiao Tong University, Dalian 116028, China;
3. FORUM8 Co., Ltd., Tokyo 1086021, Japan;
4. Dalian Zhongzhen Artificial Intelligence Technology Development Co., Ltd., Dalian 116028, China
高速动车组虚拟现实系统是虚拟现实技术在铁路机车车辆行业的工程应用,以向公众展示高新技术装备的结构组成及故障应对的科学知识为目的。为了创建一个能使操作者感受到身临其境的逼真环境,就需要创建尽可能逼真的模型和虚拟场景。但是,高速动车组结构与装配关系复杂,以时速350 km的CRH3型高速动车组转向架为例,包括一系、二系、制动、牵引电机、轮对组成、构架、辅助装置等子系统,含零部件2 000多个。如果模型和场景过于精细,数据量过于庞大,尤其是以摄像镜头的平移、旋转、推拉、摇动、变焦、及组合变换对场景和物体进行不同方位的展示时[1, 2],使所开发的系统极为复杂。所以在虚拟现实系统的建模中,有必要对同一个模型生成具有不同层次细节的多个版本,在图形绘制中依据视点选择合适的层次细节模型绘制,降低系统复杂度。
1 LOD简述
多细节层次模型,(levels of detail,LOD)技术,指根据物体模型的节点在显示环境中所处的位置和重要度,决定物体渲染的资源分配,降低非重要物体的面数和细节度,从而获得高效率的渲染运算[3]。
复杂几何模型的实时绘制是虚拟场景绘制中的重要研究课题,将LOD技术引入到复杂几何模型简化中来能够大大提高用户的实时交互性。LOD模型简化技术主要思想就是化繁为简,将原始模型通过简化算法简化成新的近似模型,即LOD模型,然后根据模型的重要度用近似模型替换原始模型,从而使场景描绘的更加快速流畅。在实际绘制过程中,再依据不同选择条件(视点、远近等条件),选择合适的LOD近似模型进行绘制。文献[4]描述了利用该技术进行场景绘制的方法,如图 1所示。
 |
| 图 1 LOD基本概念图示 |
1.1 LOD技术发展的3个阶段
LOD技术的发展大致经历了离散LOD模型、连续LOD模型和多分辨率模型3个阶段[5]。各阶段的特点如表 1。
| 发展阶段 | 主要特点 |
| 离散LOD模型 | 各层次模型已经制定,免去实时构造模型的系统开销;各层次模型简化程度已知,容易判断模型的临界使用条件。但是可供选择的细节层次数有限,模型在不同的层次变化时图像有明显的条动感 |
| 连续LOD模型 | 模型只需存储一层最高分辨率模型,节约磁盘空间;它能提供更多的细节数目,且分辨率易于调整,因而不会引起图像跳跃,更适合虚拟现实系统仿真中。但是动态模型需要额外的内存和时间开销,实现起来更为复杂 |
| 多分辨率模型 | 不同水平细节层次同时存在于模型的不同区域,没有显式的细节层次存在,在绘制过程中,由相应算法自动生成 |
1.2 LOD的生成方法
生成LOD模型的方法主要有:细分法、采样法和删减法。如表 2所示。
| LOD生成方法 | 方法概述 |
| 细分法 | 用非常简单的基模型表示初始模型,然后迭代细分基模型,每一步向模型的局部区域增加越来越多的细节,直到细节的模型满足用户定义的误差要求 |
| 采样法 | 通过随机抽取一些点来初始化多边形模型,通过较少的多边形数重建初始模型且满足采样点处的误差估计,用户可以控制采样点数,但不能控制最终近似的初始多边形模型 |
| 删减法 | 主要通过几何移去模型单元进行模型简化简化。几何移去包括:顶点删除、边折叠和面删除等。删减法应用较为广泛 |
在虚拟现实中对三维实体模型的创建普遍被简化为三角形网格,以网格自身的特性为出发点,存在着3种不同基本化简燥作,它们分别是顶点删除操作、边折叠操作和面删除操作。其中顶点删除操作是将网格上某一个顶点删除,然后对此点相邻处所形成的三角形空洞进行三角剖分补全,使整个网格的拓扑性保持一致;边折叠操作与删除顶点操作类似,它只是把某一个三角形的边进行压缩,换句话说,就是删除此边,然后将此边两端的顶点重合为1个新的点;面删除操作主要是把网格中某个三角形面压缩为一个顶点,即将某个三角形删除,然后将此三角形3个点重合为1个新的点[6]。3种基本操作方法如图 2所示。
 |
| 图 2 层次细节模型简化的基本操作 |
采用以上方法进行操作时,需要将每个步骤所造成的误差记录下来,然后对原始模型采用误差代价计算方法来计算每个步骤对每一个网格所造成的误差,此误差即为权值,最后将此数值按照一定的顺序组成一个队列,而后开始循环进行网格基本化操作。每当循环一次操作时,都从中选取误差权值最小的作为操作对象,然后更新整个网格,重新计算各个网格误差权值,再进行误差权值的排序,这样就完成一次循环。当循环进行到最小的误差权值低于用户设定的一个临界值时,此循环结束,这样也就满足了用户的需求。按照此方法进行循环,当我们根据原始模型建立的多个不同层次细节相似模型后,这些类似模型的误差值是逐渐递增的[7],为此这种具有层次化的模型能够更好地应用到虚拟现实系统中。
2 边折叠算法
考虑到动车组虚拟场景中所需模型量大、种类多、模型更新速度快等特点,结合LOD模型的生成方法,本文选择了基于边折叠的网格简化算法。基于边折叠的网格简化从多方面考虑模型,例如从模型纹理,模型色泽,模型光线和表面法向量等,此方法方便快捷,能够更有效地实现不同LOD模型实时性转换。
2.1 边折叠算法的基本思想
边折叠算法的基本思想是将一条边的2个顶点折叠到边的某一点上,然后删去相邻的三角形,边折叠算法要解决的关键问题是如何判断一条边是否要删去[8]。
本文介绍的是一种基于误差分析的边折叠算法[9],即分别计算删除每条边所对整体网格影响的误差大小,然后从中选取误差值最小的边进行删除,以此类推;当最小误差的边删除后,重新对各个边的误差进行分析,在从剩余的边中选取误差最小的边再进行删除。整体思路如图 3所示。
 |
| 图 3 边折叠算法 |
边折叠算法用公式表示为(s1,s2)→s,其步骤可以表示为:
1)将所有顶点s1、s2移到s;
2)把所有s2出现的地方都用s1替换;
3)删去s2和相关的三角形。
2.2 边折叠算法的误差评估
误差评估的主要目的是为了在LOD模型生成过程中(即采取折叠算法中),尽量将简化后的模型的误差降到最低,在不改变原始模型特性的前提下,实现图像的实时性。此评估方法的主要思路为:分析整个模型的网格,将网格中的每个节点与其周围的所有的平面作为研究对象,然后求出此节点到周围各个平面的距离的平方值,最终累加在一起作为此节点的误差值。当进行变折叠算法时,某个边被删除后,此边的2个节点会被重合于1个新的节点,这个新的节点周围形成新的平面组是原始2个节点平面组的合并。其中每个新形成的平面都可以用以下方程表示:
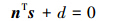
那么,点s到该平面距离的平方为

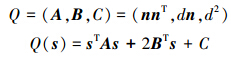
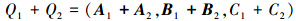
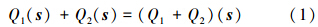
因此累加每个点到周围各个平面的距离的平方,列出一个方程式。2个顶点压缩为1个顶点后,相应的二次式也是原来2个点的二次式的和。可以用
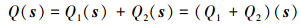
2.3 压缩后目标点的位置
如果想将2个顶点压缩为1个顶点,则需要考虑压缩后的目标点将位于何处。这里有2个方法可以选择:
1)一般的边折叠算法。
此方法思路非常的简单,不用费时费力的选取新节点的具体位置,而是将此边两端的节点之一作为新的节点,即将其中的一个节点挪到另一个节点上,使2个节点重合为新的节点。然而如何选取这2个节点哪个作为新的节点的方法,主要是分别计算出移动2个节点的误差值,即Q1(s)、Q2(s),选取误差值最大的为新的节点,即不被移动的节点。
2)推广的边折叠算法。
为了获得更好的效果,一般的边折叠算法是不够的,通过下面的计算可以找出最优的位置。
由式(1),通过Q(s)取得最小值从而确定新的节点s。当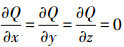 时,进行求偏导,可以计算出Q(s)的最小值。
时,进行求偏导,可以计算出Q(s)的最小值。
计算Q(s)为最小值时,s=-A-1B,因此所计算出来的误差最小值为

然而一些情况下矩阵A是不可逆矩阵,即计算过程中无法求出A-1,在此情况下只能采取方法1)来判断新节点s的位置,即一般的折叠算法。根据实际应用采取不同的算法对模型进行简化,推广的边折叠算法简化出的模型与原始模型更为接近,三角网格的大小和形状也非常均匀平滑。但是对于一些对简单的模型,对虚拟环境要求不高的情况下,就没有必要采用推广的边折叠算法,可以采取一般的边折叠算法,这样不仅能快速的完成建模,也不需要太高的硬件水平。
但是由于绘制原理的约束,即使应用了LOD进行模型简化,仍无法回避如下问题:
1)场景复杂的情况下,需要大量的时间建模,浪费人力资源和计算机资源;
2)建模数量多引起计算量巨大,保障虚拟环境质量下,影响系统实时响应或需要庞大的硬件开销;
3)虚拟场景是由三维模型创建的,虚拟场景的颜色是由软件制作出来的,与现实场景一定会存在色差,因此在真实感方面会有欠缺。
3 分步模式的模型简化算法流程及实验结果综上所述,论文提出了一种分步模式的模型简化算法:先通过简化的边折叠方法进行预处理,再运用基于包围盒的约束算法进一步简化,并通过引入阈值来控制生成不同精度的模型[10]。具体实现步骤为:导入零件模型数据→对模型进行边折叠预处理→遍历场景图、进行包围盒计算→基于AABB盒的约束方法简化模型→导出简化后的模型数据到场景图结构文件。
本文以动车组车体的简化为例,对所提出的算法进行编程验证。距离用户距离越近,视点越好,车体的细节显示也越细;反之,距离用户距离远、视点不好的位置车体显示粗略,甚至某些细节全部省略,例如车窗雨刷等[11]。图 4给出了三维模型在距离观测者远近不同位置的简化结果(即图 4中Ⅰ、Ⅱ、Ⅲ、Ⅳ所示)。
 |
| 图 4 动车模型LOD简化效果 |
表 3为同一模型以2种不同文件格式进行简化时的文件大小变化(在进行边折叠时,给定的代价值是E=4.0;在基于AABB盒的模型简化时,阈值分别为M=0.01,H=10,N=0.1)。由表 3可以看出,2种格式的文件经过边折叠后,简化率分别达到47.03%和48.45%。经过边折叠后的模型再经过AABB盒的模型简化后,简化率分别达到了65.34%和66.68%。计算结果表明:文中提出的算法是可行的。根据图 4的模型简化效果可以看出:模型简化的结果能很好地保持原始模型的可视效果,而且具有较高的文件简化率。
| 文件格式 | 原始模型大小/KB | 边折叠后大小/KB | 简化后大小/KB | 简化率/% |
| OSG | 4 295 | 2 275 | 1 377 | 65.34 |
| IVE | 1 032 | 532 | 320 | 66.68 |
4 结论
由于动车组零件众多,造成虚拟现实系统模型在细节部分比较复杂,渲染过程会出现明显迟缓的现象。研究者通过在软件系统中引入LOD技术有效地解决了这一问题,同时得到下面的结论:
1)目前LOD的简化算法研究主要集中于低层次的网格简化(如地形信息,可视计算等),针对复杂产品的高层次的模型简化算法的研究相对匮乏。研究者结合所处理的模型结构的特点,在吸收了连续性LOD的部分思想,提出了一种基于AABB盒的模型简化算法,系统实践证明了该算法有良好的简化效果。
2)为提高简化算法的适用性,研究者又根据视点到模型的距离,提出了使用AABB盒与边折叠的分步的模型简化方法。经过编程实践,对动车组模型的简化率达到了68.99%;该分步算法还可以通过相应的阈值,动态控制输出模型的大小,生成不同精度的模型。
| [1] | 郭阳明, 翟正军, 陆艳红. 虚拟场景生成中的LOD技术综述[J]. 计算机仿真, 2005, 22(12): 180-183. |
| [2] | 罗陆锋, 邹湘军, 刘天湖, 等. 大数据量虚拟景观的三维模型优化与漫游[J]. 系统仿真学报, 2008, 21(6): 1655-1657. |
| [3] | 毕振波, 郑爱勤. 当前地下水流有限元系统关键问题的探讨[J]. 浙江海洋学院学报, 2011, 30(1): 77-82. |
| [4] | 孙豪阳. 动车组检修/维修虚拟装配系统LOD技术研究[D]. 大连: 大连交通大学, 2009: 15-17. |
| [5] | 于一. 虚拟场景实时真实绘制技术和分形理论的研究及其应用[D]. 太原: 中北大学, 2008: 15-16. |
| [6] | 张昌明, 张虹. 一种基于边折叠的LOD自动生成算法[J]. 计算机工程与设计, 2005, 26(11): 3109-3111. |
| [7] | 冯良波, 罗大庸. 3D多层次模型简化算法的研究[J]. 计算机技术与发展, 2010, 20(4): 97-100. |
| [8] | 朱萧峰. 虚拟现实场景中多细节层次模型及其显示的研究[D]. 上海:同济大学, 2004: 19-20. |
| [9] | 郝筱松. 虚拟现实中的三维模型简化技术[D]. 西安: 西安电子科技大学, 2007: 22-23. |
| [10] | 吕广宪, 潘懋, 吴焕萍, 等. 面向真三维地学建模的海量虚拟八叉树模型研究[J]. 北京大学学报: 自然科学版, 2007, 2(1): 1-6. |
| [11] | 赵争鸣, 顾耀林. 基于三角形折叠的视相关多层次细节模型[J]. 计算机工程, 2007, 3(4): 278-279. |