 2018, Vol. 34
2018, Vol. 34

2. 中山大学地球环境与地球资源研究中心, 广州 510275;
3. 中山大学地球科学与工程学院, 广州 510275;
4. 中国科学院地质与地球物理研究所, 北京 100029
 , CHEN Shuo1,2,3, ZHANG Qi4, XIAO Fan1,2,3, WANG ShuGong1,2,3, LIU YanPeng1,2,3, JIAO ShouTao1,2,3
, CHEN Shuo1,2,3, ZHANG Qi4, XIAO Fan1,2,3, WANG ShuGong1,2,3, LIU YanPeng1,2,3, JIAO ShouTao1,2,3
2. Guangdong Provinical Key Laboratory of Mineral Resources and Geological Processes, Guangzhou 510275, China;
3. School of Earth Sciences & Engineering, Sun Yat-senUniversity, Guangzhou 510275, China;
4. Institute of Geology and Geophysics, China Academy of Sciences, Beijing 100029, China
中国矿物岩石地球化学学会大数据与数学地球科学专业委员由作者于2016年牵头发起成立,并于2017年4月在中山大学召开第一届全国大数据与数学地球科学学术研讨会,是《岩石学报》2018年大数据专题的直接起因。在过去的一年,作者给中山大学地球科学与工程学院研究生新开出《大数据与数学地球科学》这一课程。课程给出了一个粗略的框架,试图引导学生对大数据与数学地球科学有一个概貌性认知,并对学科前沿进展有所认识和把握,能利用所学理论和方法去解决实际的地质科学问题。
作者认为,大数据分析的基本内容应包括:数据管理、语义引擎构建、数据挖掘、预测性分析、数据可视化分析、人工智能学习等。
在大数据分析中,应有三个思考维度:一是的数据的类型。数据类型可以是结构化的,也可以是非结构-半结构化的,如图片、视频和文本等。二是数据运维,包括获取、预处理、表达、模拟、推理、可视化等。三是大数据带来的挑战性。挑战性可以是因为数据的规模、无限的数据流、不同上下文的数据意义、数据的质量、数据的不同用途等。在我国,地质大数据研究与应用的挑战还可能包括:数据来源有限(政府、机构公开数据不多)、数据来源分散(部门分割,数据封锁)、数据质量存疑(存在数据篡改、造假等现象)、数据应用工具缺乏(大数据的应用模型复杂)、缺乏最终解决方案的指引(大数据最终产品匮乏)等(严光生等,2015)。
在大数据应用中,传统的主流方法有数理统计学和数据库管理等,但随着时代的前进,特别是超算技术和能力的突破,大数据挖掘、机器学习技术逐渐成为热点(张旗和周永章,2017)。作者认为,数理统计、数据库技术、数据挖掘、机器学习互有重叠和渗透。正因为如此,大数据应用呈现一幅斑斓的世界图景。
本文重点分析大数据与数学地球科学的核心应用技术,包括高维数据降维、机器学习、图像数据处理、无限数据流挖掘、关联规则算法与推荐系统,以及人工智能地质学等。作者期望读者能从文中窥视到大数据与数学地球科学的价值,引发对大数据与数学地球科学,包括人工智能地质学发展方向的思考。
1 高维数据降维高维数据是一个普遍存在的现象。设想一个外星人莅临地球上的某所大学,看到了历届学生的名单(数量设为N)和课程目录(设数量为M)。设一名学生选修某课程记为1,否则为0。这样这位外星人看到的将是一个由1和0组成的M×N价矩阵。这就是一个M维或N维的空间。
特别是技术和社会的快速发展,使得数据收集变得越来越容易,导致数据库规模越来越大、复杂性越来越高。它们的维度(属性)通常可以达到成百上千维,甚至更高,以致出现“维数灾难”。因此,降维将数据从高维映射到低维,然后用低维数据的处理办法进行处理,是人类的正常诉求。
对高维数据的降维是一个客观需求。一个没有大学经验的人,看到由某所大学历届学生和课程目录组成的M×N价矩阵,能把该大学的院系结构或专业设置识别出来吗?
高维特征集合存在以下几方面问题:大量的特征;存在许多与类别仅有微弱相关度的特征;特征相互之间存在强烈的相关度;噪声数据。
降维(dimension reduction)就是要从初始高维特征集合中选出低维特征集合,以便根据一定的评估准则最优化缩小特征空间的过程。通过降维有效地消除无关和冗余特征,改善预测精确性等学习性能,增强学习结果的易理解性。
特征降维的基本思路是,从特征集T={t1, …, ts}中选择一个真子集T′={t′1, …, t′s},满足(s′<<s)。其中:s为原始特征集的大小;s′是选择后的特征集大小。特征选择不改变原始特征空间的性质,只是从原始特征空间中选择一部分重要的特征,组成一个新的低维空间。
目前,哈希算法、主成分分析、聚类分析等都是较常用的数学降维工具。
哈希(Hash)原理,就是两个集合间的映射关系函数,在集合A里的一条记录去查找集合B中的对应记录。哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。哈希函数可以将任意长度的输入经过变化以后得到固定长度的输出。哈希函数的这种单向特征和输出数据长度固定的特征使得它可以生成消息或者数据。好的哈希算法使得构造两个相互独立且具有相同哈希的输入不能通过计算方法实现(Leskovec et al., 2014)。
哈希表是根据设定的哈希函数H(key)和处理冲突方法将一组关键字映象到一个有限的地址区间上,并以关键字在地址区间中的象作为记录在表中的存储位置,这种表称为哈希表或散列,所得存储位置称为哈希地址或散列地址。作为线性数据结构与表格和队列等相比,哈希表是查找速度比较快的一种。
主成分分析(Principal components analysis, PCA)是最容易想到,也经常是最重要的降维方法之一(周永章等,2012)。
假设数据集是n维的,共有m个数据(x(1), x(2), …, x(m))。可以将这m个数据的维度从n维降到n′维,并使这m个n′维的数据集尽可能的代表原始数据集。这就是PCA的基本思想。
聚类分析(cluster analysis)的基本原理是根据样本自身的属性,用数学方法按照某种相似性或差异性指标,定量地确定样本之间的亲疏关系,并按这种亲疏关系程度对样本进行聚类。聚类分析区别于分类分析(classification analysis),后者是有监督的学习。
根据聚类变量得到的描述两个个体间(或变量间)的对应程度或联系紧密程度的度量。这种度量可以是描述个体对(变量对)之间的接近程度的指标,例如“距离”,也可以采用表示相似程度的指标,例如“相关系数”。距离越小、相关系数越大的个体(变量)间越具有相似性。标准化方法会影响到聚类模式:变量标准化倾向产生基于数量的聚类;样本标准化倾向产生基于模式的聚类。
高维数据聚类分析是聚类分析中一个非常活跃的领域,同时它也是一个具有挑战性的工作。目前,子空间聚类是实现高维数据集聚类的有效途径,它是在高维数据空间中对传统聚类算法的一种扩展,其思想是将搜索局部化在相关维中进行。
有多篇论文应用了降维技术或理念于自己的地质案例研究。左仁广(私人通讯)分析了化探弱异常识别模式,应用局部RX方法进行多变量降维和提取弱缓地球化学异常,可以取得较好效果。曹梦雪等(2018)在分析鄂尔多斯盆地北缘1:20万地球化学土壤测量数据时,将39个元素变量分解成若干独立因子向量,将最优独立因子向量作为元素组合,利用优选后的变量和样本集合分析鄂尔多斯盆地铀资源预测。
2 机器学习、深度学习和迁移学习机器学习(Machine Learning)是指用某些算法指导计算机利用已知数据得出适当的模型,并利用此模型对新的情境给出判断的过程。机器学习可以看做是生活中学习过程的一个模拟,包括输入、整合和输出三个阶段。从本质上讲,机器学习是一个源于数据的模型的训练过程,最终给出一个面向某种性能度量的决策。
根据所处理数据种类的不同,机器学习可以分为有监督学习和无监督学习。其中,监督学习就是告诉计算机某个数据样本在特定情形下的正确输出结果,希望计算机能够在面对没有见过的输入样本时也给出靠谱的输出结果,从而达到预测未知的目的。无监督学习,是指数据样本中没有给出正确的输出结果信息,希望从数据中挖掘诸如频率等有价值的信息,常见的例子有聚类、关联规则挖掘、离群点检测等等。
深度学习是的是机器学习的子集,即多层神经网络的方法。
深度学习的训练模型往往需要海量数据作为支撑。因此,近几年来,迁移学习得到研究者的高度重视,旨在解决数据不足的情况下训练深度学习模型的问题。
迁移学习的基本思路是利用预训练模型,即已经通过现成的数据集训练好的模型。开发者需要在预训练模型中找到能够输出可复用特征(feature)的层次(layer),然后利用该层次的输出作为输入特征来训练那些需要参数较少的规模更小的神经网络。由于预训练模型此前已经习得了数据的组织模式(patterns),因此这个较小规模的网络只需要学习数据中针对特定问题的特定联系就可以了。
设领域(domain)由两个部分组成:特征空间(feature space)X和特征空间的边缘分布P(x),其中,x={x1, x2…xn}属于X。如果两个领域不同,它们的特征空间或边缘概率分布不同。领域表示成D={X, P(x)}。
给定一个领域D={X, P(x)},设任务(task)为:T={Y, f(.)}。它包含两个部分:标签空间Y和一个目标预测函数f(.)。其中,目标预测函数不能被直接观测,但可以通过训练样本学习得到。从概率论角度来看,目标预测函数f(.)可以表示为P(Y|X)。任务表示成T={Y, P(Y|X)}。
一般情况下,只考虑只存在一个source domain Ds和一个target domain Dt的情况。其中,源领域Ds={(xs1, ys1), (xs2, ys2)…(xsns, ysns)},xsi属于Xs,表示源领域的观测样本,ysi属于Ys,表示源领域观测样本xsi对应的标签。目标领域Dt={(xt1, yt1), (xt2, yt2)…(xtnt, ytnt)},xti属于Xt,表示目标领域观测样本,ysi属于Yt,表示目标领域xti对应的输出。通常情况下,源领域观测样本数目ns与目标领域观测样本数目nt存在如下关系:1≤nt<<ns。
基于以上的符号定义,迁移学习可以定义为:在给定源领域Ds和源领域学习任务Ts、目标领域Dt和目标领域任务Tt的情况,且Ds不等于Dt或Ts不等于Tt,情况下;迁移学习使用源领域Ds和Ts中的知识提升或优化目标领域Dt中目标预测函数ft(.)的学习效果。
基于迁移学习的定义中源领域和目标领域D和任务T的不同,迁移学习可以分成三类:
(1) 推导迁移学习(inductive transfer learning)表示:给定源领域Ds和源领域学习任务Ts、目标领域Dt和目标领域任务Tt的情况,且Ts不等于Tt,情况下;推导迁移学习使用源领域Ds和Ts中的知识提升或优化目标领域Dt中目标预测函数ft(.)的学习效果。
(2) 转导迁移学习(tranductive transfer learning)表示:给定源领域Ds和源领域学习任务Ts、目标领域Dt和目标领域任务Tt的情况,且Ts等于Tt、Ds不等于Dt,情况下;转导迁移学习使用源领域Ds和Ts中的知识提升或优化目标领域Dt中目标预测函数ft(.)的学习效果。此外,模型训练时,目标领域Dt中必须提供一些无标记的数据。
(3) 无监督迁移学习(unsupervised transfer learning)表示:给定源领域Ds和源领域学习任务Ts、目标领域Dt和目标领域任务Tt的情况,且Ts不等于Tt、标签空间Yt和Ys不可观测,情况下;转导迁移学习使用源领域Ds和Ts中的知识提升或优化目标领域Dt中目标预测函数ft(.)的学习效果。在无监督迁移学习中,目标任务与源任务不同但却相关。无监督迁移学习主要解决目标领域中的无监督学习问题,类似于传统的聚类、降维和密度估计等。
目前,市场提供有NanoNets工具,可以用于基于云端实现的迁移学习。它的内部包含了一组已经实现好的预训练模型,每个模型有数百万个训练好的参数。用户可以自己上传或通过网络搜索得到数据,NanoNets将自动根据待解问题选择最佳的预训练模型,并根据该模型建立一个NanoNets(纳米网络),并将之适配到用户的数据。
机器学习被认为是人工智能的核心,是使计算机具有智能的根本途径。目前,机器学习与人工智能各种基础问题的统一性观点正在形成。机器学习也是当前大数据与数学地球科学研究的热点之一。
在本期论文中,张野等(2018)运用迁移学习方法实现了岩石岩性的自动识别与分类,为岩石岩性自动分类提供了一种新的手段。作者在实验中用到的岩石图像样本是通过照片、岩石数据库和网络搜索等不同手段采集得到,主要选取了花岗岩、千枚岩、角砾岩三种岩石图像来进行测试识别分析。岩石类型主要由实验室岩石标本、现场岩石标本及现场大范围岩石三种图像组成。为了使整个过程更加智能化,对于岩石图像的缩放、裁剪的处理均在训练中自动完成,输入的图像只保证固定的格式,对于图像大小,尺寸和像素均无具体要求。该文建立了基于Inception-v3的岩石图像深度学习迁移模型,对花岗岩、千枚岩和角砾岩三种岩石的自动识别率可以达到80%以上,部分结果甚至可以达到95%以上。训练过程对于岩石图像的大小、成像距离及光照强度要求低,充分证明了其鲁棒性和泛化能力。
张雪英等(2018)研究了一种面向文本数据的地质实体识别方法。地质实体信息中包含了基本概念、空间分布、属性信息及其相互关系的表达,其要素组成可以按照对象、特征和关系三个层次进行划分。作者将深度学习理念应用到地质实体文本信息识别中,制定了面向自然语言的地质实体信息标注规范和语料库,并基于深度信念网络构建了地质实体信息识别模型。论文利用的实验数据来源于中国地质调查局全国地质资料馆网站,以矿产资源地质调查报告为主,共标注1166个地质实体。研究结果表明,深度信念网络模型可以在目前较小规模语料库的情况下,有效识别地质调查文本中包含的相关地质实体信息。
王成彬等(2018)在论文中提到基于地学数据特征设计的地学空间大数据智慧化方法。该方法利用地学本体和词典的知识库,结合现有的W3C和OGC数据标准将地学大数据变为智慧数据服务。
3 图形数据处理、数据可视化与虚拟现实技术图形数据是以图形为对象形式的表示,在大数据中广泛存在。图形对象是指图元(primitive)和图段(segment)。其中,图元有点、线、面、字符、符号、像元阵列等;图段是由图元组成,例如地质图的地层、断裂和矿体等。每个图元的几何形状可用坐标位置,字符编码及字高、方位,字符的纵横比,像元阵列及其参考位置,相关的颜色属性加以描述。
图形数据结构分析主要研究形状和图形数据元素之间的关系,它主要谈论几何形体在计算机内部的表示以及期间进行运算的基本方法。
图像的模式识别(Pattern Recognition)是大数据挖掘的重要技术,它是一种从大量信息和数据出发,利用计算机和数学推理的方法对形状、模式、曲线、数字、字符格式和图形自动完成识别、评价的过程,一般包括两个阶段,即学习阶段和实现阶段,前者是对样本进行特征选择,寻找分类的规律,后者是根据分类规律对未知样本集进行分类和识别。
Herbert Simon提出复杂系统具有模块结构特性是一个有重要意义的发现(转刘旭,2012)。社区结构在各种复杂网络中存在具有相当普遍性,事实上,社区发现已经在多个领域发挥着作用。从理论上上讲,社区发现可以地质网络分析、古生物演化、特殊地质现象识别、矿床预测、地震预报等研究方面找到用武之地。
网络中的社区结构识别对理解整个网络的结构和功能有重要价值,可帮助分析、预测网络各元素间的交互关系。
基于社区结构度模块度(Modularity)的优化算法的提出,使非重叠社区社区发现问题转化为一个优化问题,进而去寻找一个目标函数的最优解(Newman, 2004)。近几年来,重叠社区发现算法得到迅速发展和应用。
在信息检索领域,基于图的拓扑结构信息来衡量任意两个对象间相似程度的SimRank算法(Jeh and Widom, 2002),引起广泛关注,并成功应用于网络图聚类、孤立点检测、网页排名、协同过滤等。SimRank结构相似度(Structural Similarity)是一种通过网络图的拓扑结构信息来衡量对象间相似程度的普适模型。由于它完全基于网络图的拓扑结构,因此可以捕捉到图结构的整体信息。
数据可视化是一个极为活跃的研究和应用领域。它利用图形、图像处理、计算机视觉以及用户界面,通过表达、建模以及对立体、表面、属性以及动画的显示,对数据加以可视化解释。它需要对多维数据进行切片、块、旋转等动作剖析数据,从多角度多侧面观察数据,然后将大型数据集中的数据以图形图像形式表示出来。目前,数据可视化包括基于几何的技术、面向像素技术、基于图标的技术、基于层次的技术、基于图像的技术和分布式技术等。
当存在多个指标时,挖掘指标之间的关系,将指标关系图形化,可提升图表的可视化深度。目前,大数据可视化软件有如Tableau、Qlik、Chart和D3等,它们可将数据转化为条形图、图谱、HMTL表格等格式等。至今,国内外学者对地质数据可视化开展了许多研究,包括重点成矿带3D地质模型的构建(陈建平, 2014; Weihed, 2015; Díez-Montes et al., 2015)。
虚拟现实技术(Virtual Reality)是实现大数据可视化的重要方向,对具有多元、异构、时空性、非线性、多尺度地质矿产勘查数据的展示要求有特别的价值。VR提供了动态处理数据的能力,使人可以触摸数据,让大数据成为一种触觉体验,使得数据更容易理解和操纵(Sciglar, 2017)。
进入21世纪后,VR技术以及应用进入一个高速发展时期(Goran, 2016)。在水文地质领域,研究者利用虚拟现实技术沉浸感、与计算机的交互功能和实时表现功能,建立相关的地质、水文地质模型和专业模型,进而实现对含水层结构、地下水流、地下水质和环境地质问题的虚拟表达。在石油开发领域,运用三维虚拟技术创建了具有高度沉浸感的三维虚拟环境,满足企业对石油矿井等高要求、高难度职位的培训要求。交互式地形可视化技术在2010海地地震快速科学响应中的应用表明(Cowgill et al., 2012),基于虚拟现实的数据可视化有可能通过虚拟实地研究和大规模地形数据集的实时交互分析来改变快速的科学反应。
VR让用户以更自然和直观方式将自己沉浸在数据中,可提高在特定时间内处理的数据量;以不同的角度查看数据,可从数据发现不同内容。因此,引入VR技术进行矿产地质大数据的可视化,可实现大数据时代的矿产勘查数据认知的问题。目前,虚拟现实引擎日益成熟,较为通用的仿真软件包括VRP、Quest 3D、Patchwork3D、EON Reality等。
在本期论文中,王彦飞和邹安祺(2018)应用图像分割算法对页岩CT图像数据进行处理,获得了页岩体三维结构特征及空间分布。
郭艳军(私人通讯)应用三维的虚拟仿真建模技术,建立了成矿带、地层、矿体、矿物和晶体等多分辨率的3D模型,运用光学追踪技术和图形图像渲染技术搭建了3D沉浸式交互平台,将复杂的矿产资源勘查数据系统的显示在3D沉浸式交互环境中。第鹏飞等(2018)采用全球全体扩张中心数据,使用稀土元素La、Ce、Pr、Sm和其他高场强元素Nb、Zr、Hf、Y之间的比值关系,得出具有较好直观效果的判断图,进而替代传统的Pearce判别图,较好地识别了N-MORB与E-MORB。
4 无限数据流挖掘算法无限数据流(infinite data stream)是一种重要的数据类型,在地质、地球化学、地球物理、气象等监测中,大量存在,甚至可以持续自动产生。这类数据经常与地理信息有一定关联,并因为地理信息的维度较大,容易产生这类大量的细节数据。时空序列是最常见的数据流(Zhou, 1999;李勇等,2010;陈飞香等,2013)。
数据流可以形式化地描述为:考虑向量α,其属性的域为[1…n](秩为n),而且向量α在时间t的状态:
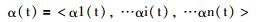
|
对数据流数据的计算包括对点查询、范围查询、内积查询、分位数计算、频繁项计算等。在进行数据流计算时,可有数据流模型(data stream model)、滑动窗口模型(sliding window model)和n-of-N模型等。其中,数据流模型要求,从某个特定时间开始至今的所有数据都要被纳入计算范围。滑动窗口模型要求计算最近的N个数据。
对分位数的计算其实是一个复杂的计算,学者提出有对分位数进行一遍扫描进行近似估计的框架结构。频繁项(Frequent items)计算,要求找出头k个最频繁出现的项,因而也是找出所有出现频率大于1/k的项。对数据流数据进行挖掘涉及更复杂的计算,如多维分析、分类分析、聚类分析等。
数据流处理过程中的主要难点在于如何将存储数据所花费的空间控制在一定范围之内。为此,传统数据库用到的略图(Sketch)、直方图(histogram)和小波(wavelet)等方法得到应用,但要将它们应用于数据流的特殊环境。这些方法的思路是,构造一个小的、能提供近似结果的数据结构存放压缩的数据流数据,这个结构能存放在存储器中。
5 关联规则和推荐系统算法关联规则(Association Rules)算法是大数据挖掘中的一类重要算法。频繁项集(Frequent Itemset)是一个关键概念。
在数学表达中,设I={i1, i2, …, im}为项(Item)的集合,D={T1, T2, …, Tn},i∈[1, n]为事务数据集(Transaction Data Itemsets),事务Ti由I中若干项组成。设S为由项组成的一个集合,S={i|i∈I},简称项集(Itemset)。包含k个项的项集称为k-项集。
定义S为频繁项集(Frequent Itemset),如果S的支持度≥给定最小支持度阈值。其中,S的支持度sup(S)=(项集S的事务数量/D中总的事务数量)×100%。t为一条事务,如果S⊆t,则称事务t包含S。
关联规则形如XY的逻辑蕴含关系。对于关联规则XY,存在支持度和信任度。支持度是指规则中所出现模式的频率,如果事务数据库有s%的事务包含XY,则称关联规则XY在D中的支持度为s%,可以表示为概率P(XY),即support(XY)=P(XY)。信任度是指蕴含的强度,即事务D中c%的包含X的交易同时包含XY。若X的支持度是support(X),规则的信任度为即为:support(XY)/support(X),这是一个条件概率P(Y|X),即confidence(XY)=P(Y|X)。
Agrawal et al. (1993)首次提出挖掘顾客交易数据中项目集间的关联规则问题,继而1994年提出Apriori算法(Agrawal, 1994),1995年提出序列模式挖掘(Agrawal and Srikant, 1995)。Koperski和Han (1995)将关联规则应用到空间数据挖掘。
推荐系统(Recommender systems)也是大数据挖掘的重要算法之一。目前应用的主要推荐方法包括:基于关联规则推荐、基于知识推荐、基于内容推荐、协同过滤推荐、基于效用推荐和组合推荐等。
其中,基于关联规则的推荐(Association Rule-based Recommendation)是以关联规则为基础的推荐数字。基于知识的推荐(Knowledge-based Recommendation)在某种程度是可以看成是一种推理技术,它不是建立在用户需要和偏好基础上推荐的,可以是用户已经规范化的查询。基于内容的推荐(Content-based Recommendation)是信息过滤技术的延续与发展,它是建立在项目的内容信息上作出推荐的,而不需要依据用户对项目的评价意见,更多地需要用机器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。项目或对象是通过相关的特征的属性来定义,系统基于用户评价对象的特征,学习用户的兴趣,考察用户资料与待预测项目的相匹配程度。
在本期论文中,常力恒等(2018)以全国矿产地数据库中的热液型金矿数据和潜力评价数据为研究对象,应用关联规则算法挖掘与金矿相关的侵入岩、火山岩、变质岩建造及区域构造地质大数据的关联性,进而发现地质要素之间的共生组合规律。作者首先通过空间位置建立不同类型数据之间的联系,形成金矿属性数据库,然后基于Apriori算法提取了大地构造环境与变质作用的频繁项集,挖掘矿产资源信息与其它信息的关联规则,发现古裂谷相、古弧盆相分别受区域动力热流变质作用和区域中高温变质作用控制明显。张宝一等(2018)对地球化学场的分析认为,地球化学场的空间相关模式包括单个地球化学指标在区域上的空间自相关性,以及多个地球化学指标之间的空间互相关性。空间自相关的度量可以写成属性自相似性集合与位置自相似性集合的叉乘形式的交叉积统计指标,提出挖掘多元地学数据之间的隐形联系,分析其与成矿过程的关联性,可以为地下成矿物质的分布和演化以及隐伏矿体三维预测提供依据。
6 贝叶斯原理与智能地质学贝叶斯原理的数学表达是(周永章等, 2012):
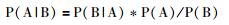
|
该公式中,P(A)是先验概率,P(A|B)是后验概率,表示在以后B事件发生的条件下A事件发生的条件概率。
贝叶斯公式,虽然看起来很简单、有些不起眼,但有着丰富、透彻的内涵。当存在着大量数据,但数据又可能有各种各样的错误和遗漏的时候,它可以从中找到真实的规律。
贝叶斯公式有被称为贝叶斯-拉普拉斯方法。它认为,可以根据先验知识进行的主观判断,即在人类认识事物不全面的情况下,可以利用已有经验帮助做出大致合理的判断、决策,以后如有客观的新信息、新数据更新最初关于某个事物的信念后,就会得到一个新的、改进了的信念。这就是说,当一个人不能准确知悉一个事物的本质时,他可以依靠与事物特定本质相关的事件出现的多少去判断其本质属性的概率。用数学语言表达就是:支持某项属性的事件发生得愈多,则该属性成立的可能性就愈大。与经典统计统计学方法不同,贝叶斯-拉普拉斯方法建立在主观判断的基础上,先估计一个值,然后根据客观事实不断修正。
贝叶斯-拉普拉斯公式隐含下列思想:“大胆假设,小心求证”,“不断试错,快速迭代”。先验概率(初始状态)的重要性已经不是最重要,即使最初选择不理想,只要根据新情况不断进行调整,仍然可以取得成功。一个人完全可以按照自己的想法弄个粗放的原型出来,然后充分利用大数据和互联网的力量,让新数据加入进来帮助它快速迭代,逐渐使模型变得越来越完善。大数据时代获得信息的成本越来越低,社会也变得更加开放和包容,因此贝叶斯-拉普拉斯方法的很有力量的,只需要一个人对新鲜事物保持开放的心态,愿意根据新信息对自己的策略和行为进行调整。
二十世纪八十年代以来,贝叶斯原理在自然语言处理领域的成功应用,开辟了一条全新的问题解决路径:原来看起来非常复杂的问题可以用贝叶斯公式转化为简单的数学问题;可以把贝叶斯公式和马尔科夫链结合以简化问题,使计算机能够方便求解,从实践看来它非常有效;将大量观测数据输入模型进行迭代—也就是对模型进行训练,就可以得到希望的结果(Lake et al., 2015)。随着计算能力的不断提高、大数据技术的发展,原来手工条件下看起来不可思议的进行模型训练的巨大工作量变得很容易实现,它们使贝叶斯公式巨大的实用价值体现出来。
语音和语言处理研究者认为,语音识别就是根据接收到的一个信号序列推测说话人实际发出的信号序列(说的话)和要表达的意思,因此可以把语音识别问题转化为一个通信问题,进而可以简化为用贝叶斯公式处理的数学问题。一般情况下,一个句子中的每个字符都跟它前面的所有字符相关。为了简化问题,可以简化假设:说话人说的句子是一个马尔科夫链,句子中的每个字符都只由它前一个字符决定;独立输入假设,就是每个接受的字符信号只由对应的发送字符决定。将大量观测数据输入模型进行迭代—也就是对模型进行训练,就可以得到希望的结果。
这样的简化看起来有点简单粗暴,但事实证明,这个基于贝叶斯公式的统计语言模型在解决问题时相当有效。八十年代微软公司用这个模型成功开发出第一个大词汇量连续语音识别系统。该语音识别系统不但能够识别静态的词库,而且对词汇的动态变化具有很好的适应性,即使是新出现的词汇,只要这个词已经被大家高频使用,用于训练的数据量足够多,系统就能正确地识别。这反映出贝叶斯公式对新增加知识(数据)变化的高度敏感,对增量信息有非常好的适应能力。
马尔可夫链可以进一步推广为贝叶斯网络,以给复杂问题提供一个普适性的解决框架。与马尔可夫链类似的是,贝叶斯网络中每个节点的状态值取决于其前面的有限个状态,不同的是,贝叶斯网络不受马尔可夫链的链状结构的约束,因此可以更准确地描述事件之间的相关性。为了确定各个节点之间的相关性,需要用已知数据对贝叶斯网络进行迭代和训练。美国数学家朱迪亚·珀尔证明,贝叶斯网络可以用来有效揭示复杂现象背后的成因,把错综复杂的事件梳理清楚。
贝叶斯网络操作思路如下(Lake et al., 2015):如果一个人不清楚一个现象的成因,那首先可以根据他认为最有可能的原因来建立一个模型,然后把每个可能的原因作为网络中的节点连接起来,根据已有的知识、他的预判或者专家意见给每个连接分配一个概率值(先验概率)。接下来只需要向这个模型代入观测数据,通过网络节点间的贝叶斯公式重新计算出概率值。为每个新数据、每个连接重复这种计算,直到形成一个网络图,任意两个原因之间的连接都得到精确的概率值为止。即使实验数据存在空白或者充斥噪声和干扰信息,不懈追寻各种现象发生原因的贝叶斯网络依然能够构建出各种复杂现象的模型。
贝叶斯网络是成因建模的一个革命性工具。贝叶斯公式的价值在于,当观测数据不充分时,它可以将专家意见和原始数据进行综合,以弥补测量中的不足。人类的认知缺陷越大,贝叶斯公式的价值就越大。
贝叶斯原理在大数据时代有独特的价值。有科学家认为,人类的大脑结构就是一个贝叶斯网络,贝叶斯公式是人类在没有充分或准确信息时最优的推理结构,为了提高生存效率,进化会向这个模式演进。一种基于贝叶斯公式的方法—贝叶斯程序学习(Bayesian Program Learning),可以即时认识来自陌生文字系统的字符。人们只需向这个系统展示一个来自陌生文字系统的字符,它就能很快学到精髓,像人一样写出来,甚至还能写出其他类似的文字—更有甚者,它还通过了图灵测试,人们很难区分下图中的字符是人类还是机器的作品。
智能地质-矿床研究刚刚起步。它可以设想为以地质-矿床大数据平台为依托,利用大数据挖掘技术与高性能计算能力,建立智能地质-矿床模型。贝叶斯原理在其中具有十分基础的地位。
构建大数据-智能矿床成因模型与找矿模型是智能地质-矿床研究的重要内容。
科学家依托贝叶斯原理开发的语音识别系统对智能地质的发展有很强的启迪意义。周永章等(2017)认为,贝叶斯网络可以用来揭示矿床的成因机制及它们背后的规律,用来构建大数据-智能矿床成矿与找矿模型,它展示了构建大数据-智能矿床成矿与找矿模型值得努力的方向。来自地质调查、监测数据获得的与“矿”有关的大数据,包括在一定的地质历史时期或构造运动阶段,在一定的地质构造单元及构造部位,与一定的地质成矿作用有关的时间、空间、成因及矿床产状的数据,还包括庞大的成矿温度、成矿压力、流体包裹体、同位素、微量元素等矿床地球化学数据等,都可以利用来迭代计算出贝叶斯成因网络,完善所建立的矿床模型,并且通过互联网、云计算技术,使得世界各地的矿床研究团队共同参与,引发矿床模型研究方式的变革。
在本期论文中,李景哲等(2018)以珠江口盆地惠州凹陷南部为例,在分析K系列地层沉积时期的相对海平面变化后,探讨了应用大数据贝叶斯-拉普拉斯方法,实现海平面变化从深度域的刻画到时间域的刻画,包括在年代资料比较离散和稀疏的地区。可以说,这是一项很有价值的挑战。
该文作者认为,贝叶斯-拉普拉斯方法为这项挑战的解决提供了基于大数据的新思路。开始时,可以利用地层的层序结构、分形特性以及离散的地层年龄等数据建立初始的较粗糙的年代关系,随着实测年龄数据的增加,新信息、新数据不断更新,这些年代信息不断细化,进而可以实现相对海平面在时间域的高精度刻画。具体流程是,首先通过现代沉积相分析获得一个定量化的分型模型(针对实际年龄)。在实际测井剖面中,可以获得层序地层和系列年龄测定(离散数据)。然后利用离散的年龄数据和层序地层,依据定量化的分型模型预测剖面上任意一个点的年龄值。最后利用后续不断获得的实测年龄新数据迭代给出更新结果。这样,可以实现相对海平面在时间域的高精度刻画,不但可以使得沉积过程“源到汇”的完整再现成为可能,还可以为地下沉积体的精确推断与表征提供重要依据。
致谢 本专题得以出版源于翟明国院士对新学科生长点敏锐的认知以及鼎力支持。毛先成、路来君、陈建国、成秋明、郭艳军、左仁广、梁元、刘刚、刘洁、马小刚、张宝一、张雪英、张野、朱月琴等给予赐稿或荐稿支持。余先川、夏庆霖、周可法、路来君、毛先成、张生元、刘刚、朱月琴、谢淑云、杨永国、郭艳军、王永志、王正海、刘玉葆等参与了稿件的评审,对论文的完善提出非常有价值的改进意见。整个过程得到参加首届中国大数据与数学地球科学学术讨论会的中国矿物岩石地球化学学会大数据与数学地球科学专业委员会委员以及中山大学选修《大数据与数学地球科学》研究生的支持和帮助。
Agrawal R, Imielinski T and Swami A. 1993. Mining association rules between sets of items in large databases. In: Proceedings of the ACM SIGMOD Conference on Management of Data. Washington, D. C
|
Agrawal R. 1994. Fast Algorithms for Mining Association Rules. In: Proceedings of the 20th VLDB Conference. Santiago: 487-499
|
Agrawal R and Srikant R. 1995. Mining sequential pattern. In:Proceedings of the 11th International Conference on Data Engineering. Taipei:ICDE, 3. |
Cao MX, Lu LJ, Lü Y and Xin S. 2018. Samples optimum analysis of geochemical big data in the northern margin of Ordos Basin. Acta Petrologica Sinica, 34(2): 363-371. |
Chang LH, Zhu YQ, Zhang GY, Zhang X and Hu BR. 2018. Spatial correlation analysis of mineral resources information. Acta Petrologica Sinica, 34(2): 314-318. |
Chen FX, Cheng JC, Hu YM, Zhou YZ, Zhao Y and Yi JC. 2013. Spatial prediction of soil properties by RBF neural network. Scientia Geographica Sinica, 33(1): 69-74. |
Chen FX. 2014. Study on spatial prediction, simulation and uncertainty assessment of farmland soil properties at county-scale. Ph. D. Dissertation. Guangzhou: Sun Yat-sen University: 1-183.
|
Chen JP, Yu M, Yu PP, Shang BC, Zheng X and Wang LM. 2014. Method and practice of 3D geological modeling at key metallogenic belt with large and medium scale. Acta Geologica Sinica, 88(6): 1187-1195. |
Cowgill E, Bernardin TS, Oskin ME, Bowles C, Yikilmaz MB, Kreylos O, Elliott AJ, Bishop S, Gold RD, Morelan A, Bawden GW, Hamann B and Kellogg L. 2012. Interactive terrain visualization enables virtual field work during rapid scientific response to the 2010 Haiti earthquake. Geosphere, 8(4): 787-804. DOI:10.1130/GES00687.1 |
Di PF, Chen WF, Zhang Q, Wang JR, Tang QY and Jiao ST. 2018. Comparison of global N-MORB and E-MORB classification schemes. Acta Petrologica Sinica, 34(2): 264-274. |
GORAN. 2016. Virtual reality: A brief history. http://www.useoftechnology.com/virtual-reality-history/
|
Jeh G and Widom J. 2002. SimRank:A measure of structural-context similarity. In:Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Edmonton, Alberta, Canada:ACM. DOI:10.1145/775047.775126 |
Koperski K and Han JW. 1995. Discovery of spatial association rules in geographic information databases. In: Egenhofer MJ and Herring JR (eds. ). Advances in Spatial Databases. Berlin, Heidelberg: Springer, 951: 47-66
|
Lake BM, Salakhutdinov R and Tenenbaum JB. 2015. Human-level concept learning through probabilistic program induction. Science, 350(6266): 1332-1338. DOI:10.1126/science.aab3050 |
Leskovec J, Rajaraman A and Ullman JD. 2014. Mining of Massive Datasets. Palo Alto. CA: Stanford University.
|
Li JZ, Zhang JL, Zhou YZ, Wang SG and Ding L. 2018. Eustatic fluctuations of the Neogene K successions of Huizhou Sag:High resolution quantitative analysis and application of Bayes-Laplace principlewith big data. Acta Petrologica Sinica, 34(2): 371-382. |
Li Y, Zhou YZ, Zhang CB, Dou L, Du HY, Lin XM, Fan R, Du M and He X. 2010. Application of local Moran's I and GIS to identify hotspots of Ni, Cr of vegetable soils in high-incidence area of liver cancer from the Pearl River Delta, South China. Environmental Science, 31(6): 1617-1623. |
Liu X. 2012. Community structure detection in complex networks via objective function optimization. Ph. D. Dissertation. Changsha: China National University of Defense Technology: 1-197.
|
Newman MEJ. 2004. Fast algorithm for detecting community structure in networks. Physical Review, 69(6): 066133. |
Wang CB, Ma XG and Chen JG. 2018. The application of data pre-processing technology in the geoscience big data. Acta Petrologica Sinica, 34(2): 303-313. |
Wang YF and Zou AQ. 2018. Regularization and optimization methods for micro pore structure analysis of shale based on neural networks. Acta Petrologica Sinica, 34(2): 281-288. |
Wu CL and Liu G. 2015. Current situation, existent problems, trend and strategy of the construction of "Glass Earth". Geological Bulletin of China, 34(7): 1280-1287. |
Yan GS, Xue QW, Xiao KY, Chen JP, Miao JL and Yu HL. 2015. An analysis of major problems in geological survey big data. Geological Bulletin of China, 34(7): 1273-1279. |
Zhang BY, Chen YR, Huang AS, Lu H and Cheng QM. 2018. Geochemical field and its roles on the 3D prediction of concealed ore-bodies. Acta Petrologica Sinica, 34(2): 352-362. |
Zhang Q and Zhou YZ. 2017. Big data will lead to a profound revolution in the field of geological science. Chinese Journal of Geology, 52(3): 637-648. |
Zhang XY, Ye P, Wang S and Du M. 2018. Geological entity recognition method based on Deep Belief Networks. Acta Petrologica Sinica, 34(2): 343-351. |
Zhang Y, Li MC and Han S. 2018. Automatic identification and classification in lithology based on deep learning in rock images. Acta Petrologica Sinica, 34(2): 333-342. |
Zhao PD. 2015. Digital mineral exploration and quantitative evaluation in the big data age. Geological Bulletin of China, 34(7): 1255-1259. |
Zhou YZ. 1999. Reconstruction of nonlinear geochemical dynamics of elemental sedimentation based on power spectral analysis of time sequence. Mathematical Geology, 31(6): 723-742. DOI:10.1023/A:1007584511667 |
Zhou YZ, Wang ZH and Hou WS. 2012. Mathematical Geoscience. Guangzhou: Sun Yat-Sen University Press: 1-247.
|
Zhou YZ, Li PX, Wang SG, Xiao F and Li JZ and Gao L. 2017. Research progress on big data and intelligent modelling of mineral deposits. Bulletin of Mineralogy, Petrology and Geochemistry, 36(2): 327-331, 344. |
曹梦雪, 路来君, 吕岩, 辛双. 2018. 鄂尔多斯盆地北缘地球化学大数据样本优选分析. 岩石学报, 34(2): 363-371. |
常力恒, 朱月琴, 张戈一, 张旋, 胡博然. 2018. 面向矿产资源信息的空间关联性分析. 岩石学报, 34(2): 314-318. |
陈飞香, 程家昌, 胡月明, 周永章, 赵元, 蚁佳纯. 2013. 基于RBF神经网络的土壤铬含量空间预测. 地理科学, 33(1): 69-74. |
陈建平, 于淼, 于萍萍, 尚北川, 郑啸, 王丽梅. 2014. 重点成矿带大中比例尺三维地质建模方法与实践. 地质学报, (6): 1187-1195. |
第鹏飞, 陈万峰, 张旗, 王金荣, 汤庆艳, 焦守涛. 2018. 全球N-MORB和E-MORB分类方案对比. 岩石学报, 34(2): 264-274. |
李景哲, 周永章, 张金亮, 王树功, 丁琳. 2018. 惠州凹陷新近系K系列海平面变化定量分析及大数据应用展望. 岩石学报, 34(2): 371-382. |
李勇, 周永章, 张澄博, 窦磊, 杜海燕, 林小明, 范瑞, 杜敏, 何翔. 2010. 基于局部Moran's I和GIS的珠江三角洲肝癌高发区蔬菜土壤中Ni、Cr的空间热点分析. 环境科学, 31(6): 1617-1623. |
刘旭. 2012. 基于目标函数优化的复杂网络社区结构发现. 博士学位论文. 长沙: 国防科学技术大学, 1-197
|
王成彬, 马小刚, 陈建国. 2018. 数据预处理技术在地学大数据中应用. 岩石学报, 34(2): 303-313. |
王彦飞, 邹安祺. 2018. 基于神经网络的页岩微纳米孔隙微结构分析的正则化和最优化方法. 岩石学报, 34(2): 281-288. |
严光生, 薛群威, 肖克炎, 陈建平, 缪谨励, 余海龙. 2015. 地质调查大数据研究的主要问题分析. 地质通报, 34(7): 1273-1279. |
张宝一, 陈伊如, 黄岸烁, 陆浩, 成秋明. 2018. 地球化学场及其在隐伏矿体三维预测中的作用. 岩石学报, 34(2): 352-362. |
张旗, 周永章. 2017. 大数据正在引发地球科学领域一场深刻的革命—《地质科学》2017年大数据专题代序. 地质科学, 52(3): 637-648. DOI:10.12017/dzkx.2017.041 |
张雪英, 叶鹏, 王曙, 杜咪. 2018. 基于深度信念网络的地质实体识别方法. 岩石学报, 34(2): 343-351. |
张野, 李明超, 韩帅. 2018. 基于岩石图像深度学习的岩性自动识别与分类方法. 岩石学报, 34(2): 333-342. |
周永章, 王正海, 侯卫生. 2012. 数学地球科学. 广州: 中山大学出版社: 1-247.
|
周永章, 黎培兴, 王树功, 肖凡, 李景哲, 高乐. 2017. 矿床大数据及智能矿床模型研究背景与进展. 矿物岩石地球化学通报, 36(2): 327-331, 344. |