|
|
|
收稿日期: 2015-01-05; 修订日期: 2015-07-08; 优先数字出版日期: 2015-07-15
基金项目: 江苏省测绘地理信息科研项目基金资助(编号:JSCHKY201412);江苏省资源环境信息工程重点实验室开发基金资助项目(编号:JS201308);中央高校基本研究业务费专项资金资助(编号:2013QNB11)
中图分类号: P237
文献标识码: A
文章编号: 1007-4619(2016)01-0114-15
|
摘要
随着遥感影像数据量以及复杂程度的日益增加,遥感图像的快速处理成为实际应用过程中亟需解决的问题。为了实现遥感影像的实时变化检测,针对基于变化矢量分析CVA的变化检测算法,设计了一种基于统一计算设备构架CUDA的并行处理模型。首先利用地理空间数据提取库GDAL实现大数据量遥感影像的分块读取、操作和保存;其次将基于变化矢量分析的变化检测过程分为变化强度检测、映射表构建和变化方向检测,并借助CUDA C将变化矢量分析算法的3个步骤嵌入到CPU和GPU组成的异构平台上进行实验;最后利用该模型对不同数据量的遥感影像进行CVA变化检测并作对比分析。实验结果表明:与CPU串行相比,基于GPU/CUDA的遥感影像CVA的变化检测速度提高了10倍左右;在一定程度上,达到了实时变化检测的效果。
关键词
遥感影像; 变化检测; 变化矢量分析; 并行计算; 统一计算设备构架
1 引 言
快速变化和高速发展的现代社会,土地利用和覆盖变化一直都是人们关注的话题。在众多的土地动态变化检测方法中,遥感技术以其经济、实用、高效的优势,在变化检测领域受到了广泛应用。然而随着遥感技术的迅速发展,遥感图像的数据量急剧增加,数据结构也逐渐复杂,在遥感图像的读取,显示和变化检测等过程中暴露出许多问题,如内存溢出、读取和存储数据耗时长等。另一方面,为了提高遥感图像变化检测的精度,各种算法层出不穷,也越来越复杂,因而计算量和计算耗时也大大增加。由于CPU受体系结构限制,大部分片上资源都用来做控制和缓存,实际的计算单元十分有限,导致基于遥感图像的变化检测效率低下。为了满足日益增长的计算需求,实时地掌握土地的变化信息,就需要一种快捷有效的图像处理方式来检测土地利用和覆盖的变化情况。
目前用于遥感图像处理的并行技术主要是基于计算机集群的并行和基于加速器的并行。基于计算机集群的并行技术有:MPI、PVM、Express等,其中最受欢迎的是基于消息传递的MPI技术,该技术需要多个计算机节点通过网络链接起来,运算时将任务分配到各个节点上运算,最终结果返回某一个节点。国内外学者对基于集群的变化检测做了一些研究:Mubasher等人(2012)将基于背景模型的变化检测嵌入到4台计算机组成的集群上进行研究,使得变化检测的效率提高了 3.4 倍;叶琛(2014)将基于PCA的变化检测嵌入到由3台VPF2组成的集群上进行并行研究,实验表明变化检测的效率提高了3.34倍;胡维(2011)分别利用1—8个节点的计算机集群对基于主成分分析的变化检测进行研究,实验表明随着节点数的增多,加速比基本上成线性增加。用于并行的加速器主要包括:DSP、FPGA、GPU、Intel MIC、APU等,借助于这些硬件设备能够很大程度上提高遥感图像处理的效率。Kockara(2009)利用GPU的并行计算能力,在一定程度上实现了医学影像和遥感影像的实时变化检测;Zhu等人(2012)利用GT630M显卡将基于KL散度的变化检测效率提高了将近20倍。Asano等人(2009)将2维滤波、立体视觉以及K均值聚类算法分别在拥有4核的CPU、FPGA和GPU上进行研究分析,实验表明:对于简单的数值计算GPU表现出良好的并行计算性能,与FPGA相当;而对于复杂的逻辑性计算,CPU和FPGA运算性能优于GPU。可见,对于需要大规模的数值计算的图像处理而言,加速器体现出无法比拟的优势。
数字图像本质上就是一个2维数组,在大多数图像处理过程中,每个像素的运算过程是相互独立而且完全一样的数字计算,这恰恰符合了GPU高性能并行运算的条件,因此,GPU在遥感图像处理领域越来越受到人们的关注。然而直接对GPU操作却非常复杂,且灵活度很差。为了克服这些缺点,NVIDIA推出统一计算设备构架CUDA(Compute Unified Device Architecture),CUDA是一种专门针对NVIDIA/GPU硬件而设计的并行运算架构,用于图像处理通用并行计算领域。CUDA的推出在学术界和产业界引起了热烈反响,尤其对于具有海量数据的遥感图像处理技术更是起到了巨大的推动作用。Yang等人(2008)将多种典型的遥感图像处理技术嵌入到GPU中研究,结果表明,图像直方图计算可以提高至少40倍,去云处理大约可以提高79倍,离散余弦变换可以提高8倍而边缘检测至少可以提高200倍;方留杨等人(2014)利用Tesla M2050 GPU将资源三号卫星影像的正射校正的效率提高了110倍;Zhang等人(2010)利用GPU分别将Sobel边缘检测以及形态学处理的运算效率提高了25倍和49倍,验证了GPU在图像处理中的可行性;肖汉和张祖勋(2010)设计了一种基于CUDA的快速影像匹配算法,相对于CPU上的串行算法提高了7倍;Hu和Yang(2013)把GPU运用到3D图像处理中,实验表明,GPU并行运算大大提高了3D图像的细化处理的效率。可见,基于GPU并行运算可以有效地提高遥感图像处理的效率。
目前基于GPU/CUDA并行技术已在遥感图像处理中得到了广泛应用,但是基于GPU/CUDA的变化检测并不多见(Zhu等,2012;Asano等,2009;Zhu和Cui等,2012)。为了可以在普通的PC机上能够实时地掌握土地利用和土地覆盖的情况,有必要把基于遥感图像的变化检测嵌入到GPU中进行进一步的研究。在众多的变化检测方法中,本文选用了基于变化矢量分析CVA(Change Vector Analysis)的遥感变化检测方法。该变化检测技术能够同时提取变化强度信息和变化方向信息。它将地物的变化表示为多光谱特征空间中像元的变化矢量,并通过图像处理和图像判读来确定地物变化的范围并进行统计分析,确定地物变化的类型信息。该方法简单、直观、易操作,大大减少了对变化区域做分类时作业人员的工作量,避免了人工操作带来的不便和误差;此外,该方法避免了分类过程引入虚假变化类型,有效的提高了检测精度。本文将CVA遥感变化检测过程嵌入到支持CUDA的NVIDIA GPU上进行研究,主要针对变化强度算子、映射表以及变化方向算子做分析,并对多组不同数据量的图像做实验。
2 CUDA构架
2.1 CUDA软件编程模型
CUDA是一种由NVIDIA推出的通用并行计算架构,通过该架构用户可以方便地对GPU进行操作。通过CUDA来操作GPU,避免了用户直接调用复杂的GPU接口函数,使用户专注于算法的研究。这种优势主要是由CUDA的软件结构决定的,该结构(如图 1所示)主要由以下3个层次组成:CUDA库函数、CUDA运行时API和CUDA驱动API。
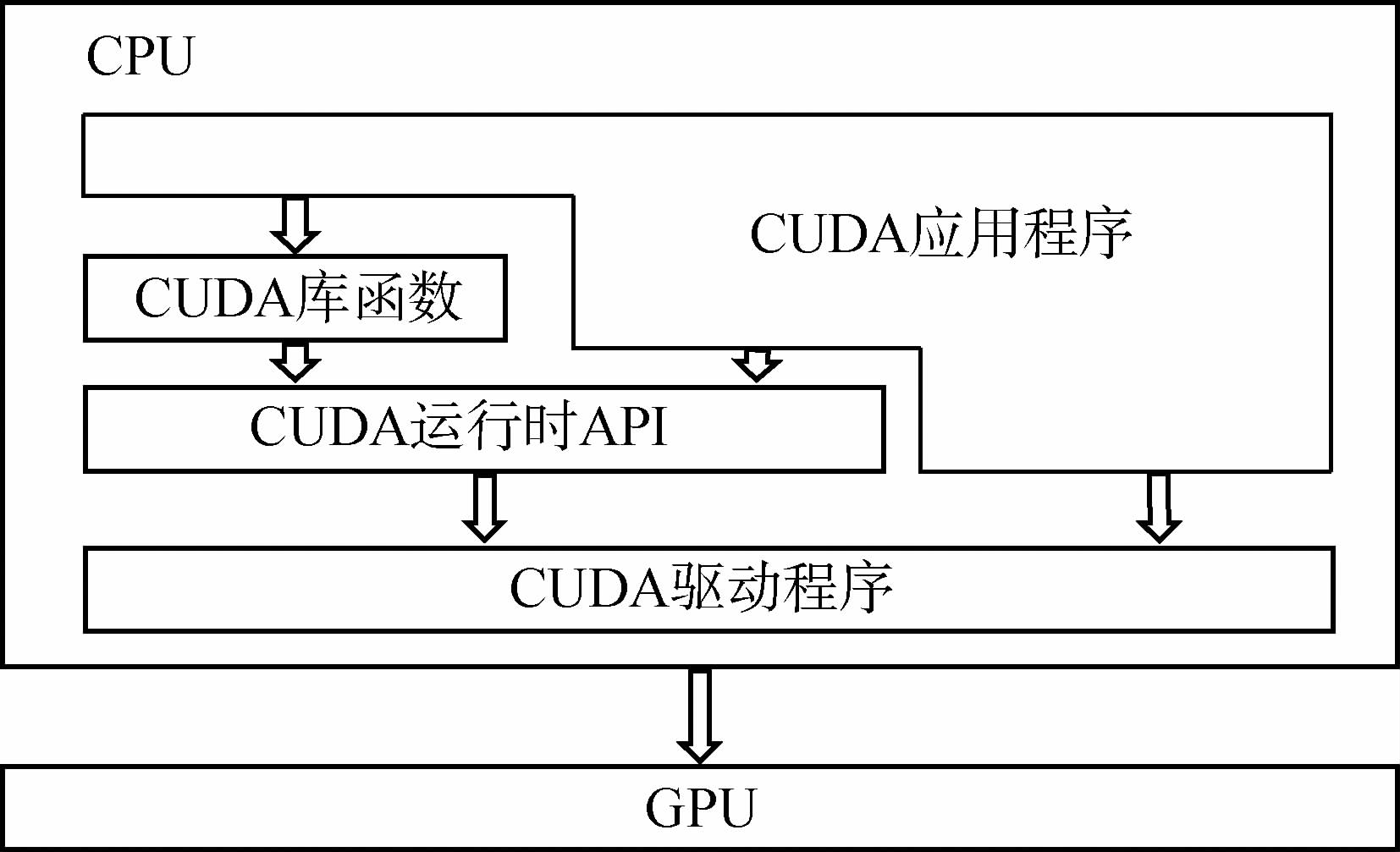
如图 1所示,在基于CUDA的编程模型中,最重要的是CUDA C语言,它包含对C语言的最小扩展集和一个运行时库。在CUDA Library中有CUFFT、CUBLAS和CUDPP 3个函数库,它们提供了一些简单高效的常用函数,方便用户调用。而CUDA运行时API和CUDA驱动API提供了设备管理、上下文管理、存储管理、代码块管理、执行控制等应用程序接口,可以访问GPU的接口函数,实现对GPU的操作。
在实际应用过程中,用户只需要针对具体计算任务,确定程序中的并行处理部分;然后通过CUDA C在CPU中编写项目的并行程序。这些并行程序的源文件在运行过程中必须通过NVCC编译器进行编译。然而CUDA C语言编写的并行程序编译得到的只是GPU端代码,而如果需要管理GPU资源,将CUDA C编写的并行处理代码交给GPU来处理,就必须借助CUDA运行时API与CUDA驱动API来实现。需要注意的是,在一个程序中只能使用其中的一种,不能混合使用(张舒和褚艳利,2009)。GPU端的并行处理程序是以内核函数(Kernel)为单位的。然而Kernel函数并不是一个完整的程序,它只是整个CUDA程序中的一个可以被并行执行的步骤。在一个完整的CUDA程序中,除了设备端并行处理的Kernel函数以外,还有主机端的串行程序。在两个核之间运行的就是串行代码。理论上,CUDA核函数以网格(Grid)的形式执行,每个网格由若干个线程块(Block)组成,每一个线程块由若干个线程(Thread)组成。
2.2 GPU硬件模型
NVIDIA GPU可以被看作由数个多处理器SM(Streaming Multiprocessors)组成,每个多处理器包含有多个流处理器SP(Streaming Processor),SM和每个SM中SP的个数是由具体的硬件决定的(许雪贵和张清,2011)。此外,每个多处理器还具有一定数量的寄存器(Register)、共享内存(Shared Memory)以及纹理缓存(Texture Cache)和常量缓存(Constant Cache)。NVIDIA GPU的内部架构如图 2所示。
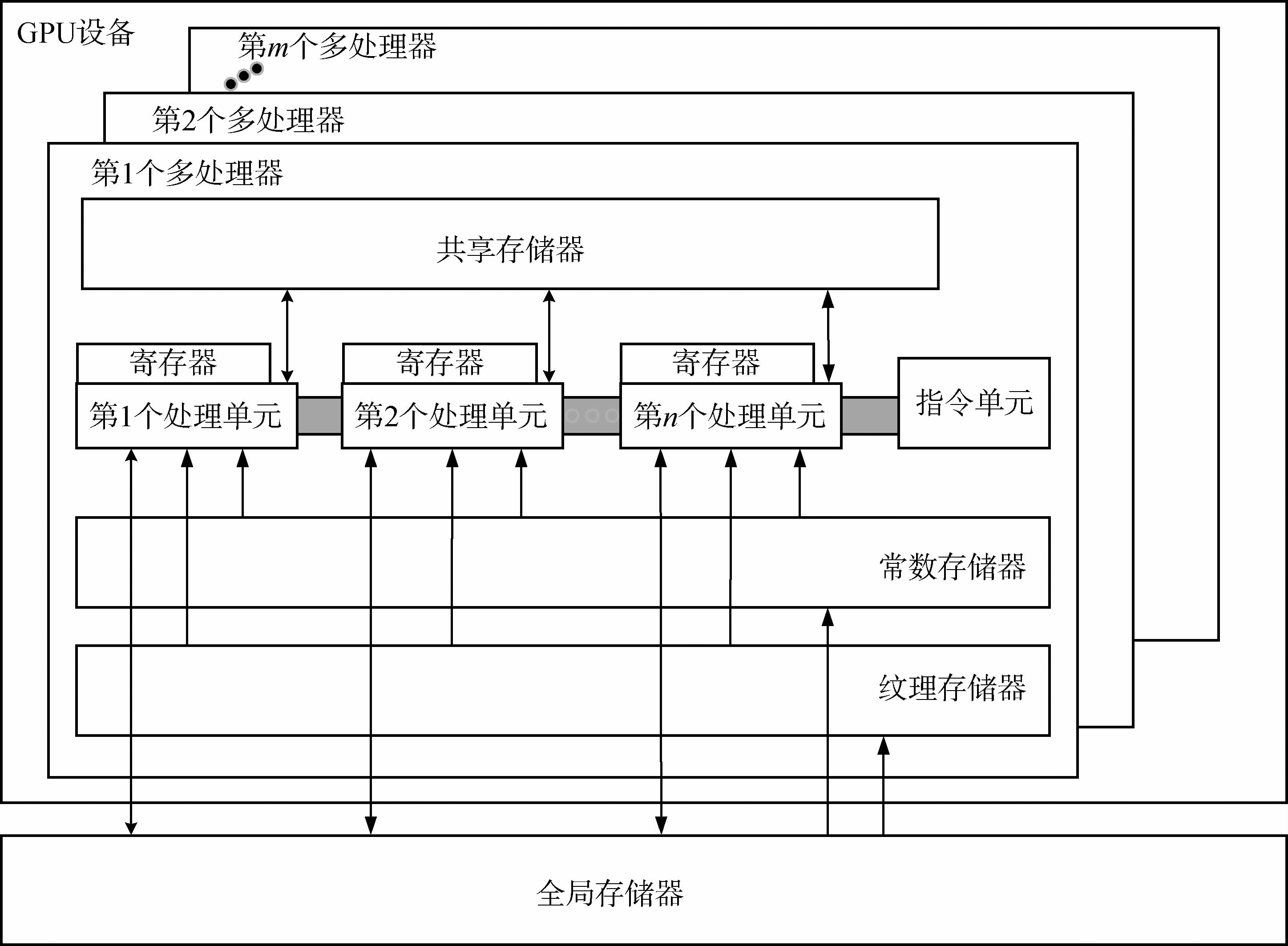
GPU最基本的处理单元是SP。虽然它们有独立的寄存器和指令指针,但没有取指、解码、分发逻辑和执行单元构成的完整前端,因此它们并不是独立的处理器核(Lindholm等,2008)。CUDA中的内核函数实际上是以Block为单位执行的,同一个Block中的线程需要共享数据,因此它们被映射到同一个SM,而Block中的每个Thread则被映射到一个SP上执行。然而为了隐藏延迟,一个多处理器同一时刻可以有多个活动的Block在等待执行。当一个Block进行同步或者异步访问显存等高延迟操作时,可以快速切换到另一个活动的Block继续运算,从而掩盖延时,提高了运算效率。
3 CVA变化检测原理
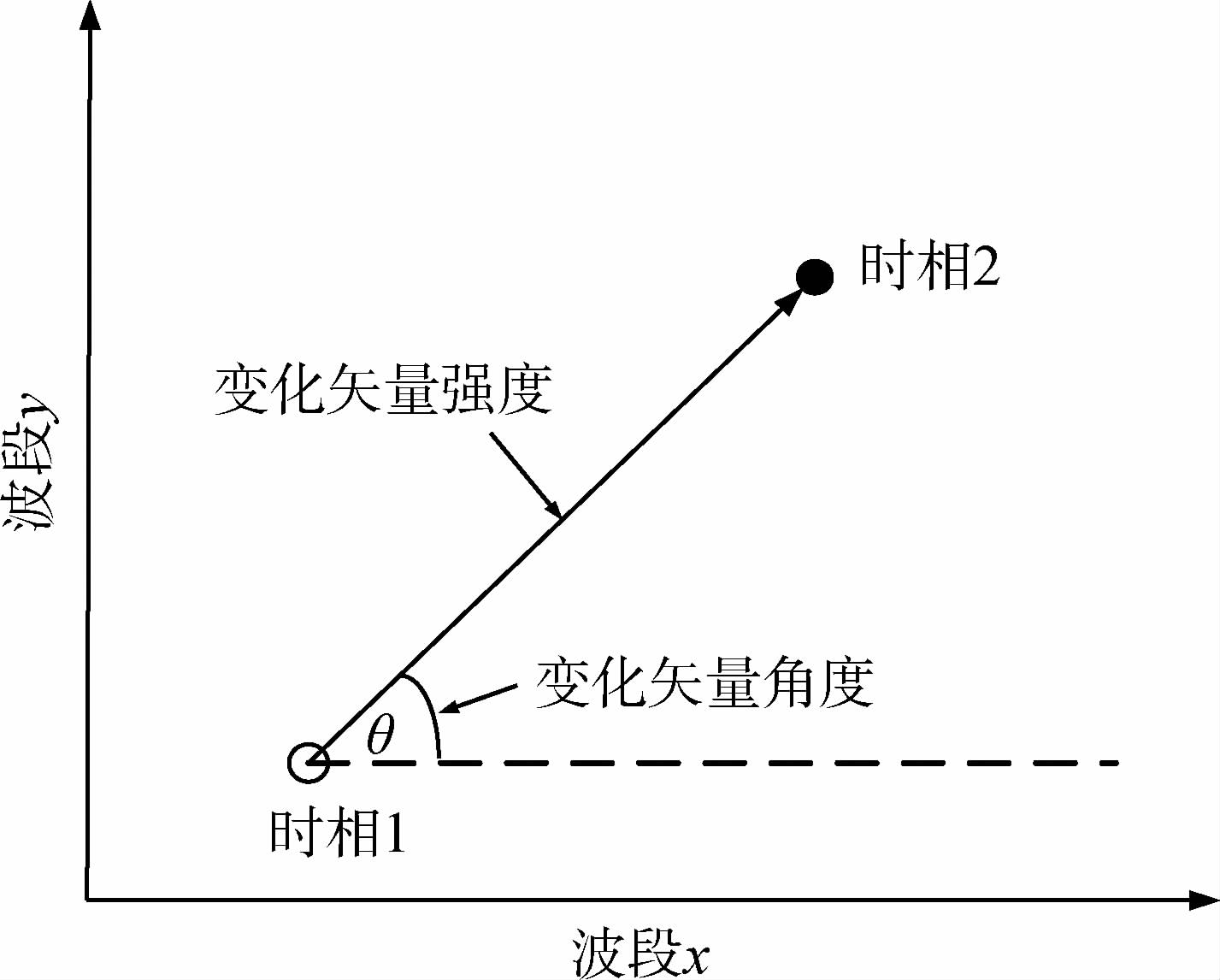
Malila(1980)最早提出了变化矢量分析法。变化矢量分析法主要是从变化的强度和变化的方向两个角度对遥感影像进行变化检测。其中,变化强度图像用于表示研究区域的变化范围;变化方向图像用于表示研究区域具体的变化类型。传统的基于CVA的变化检测方法对两个不同时相的图像做差值运算,组成一幅新的差值多光谱图像。差值图像中的每一个位置处的像元灰度值都可以组成一个矢量,如式(1)所示。
$\Delta X = \left({\begin{array}{*{20}{c}}{\Delta {x_1}}\\{\Delta {x_2}}\\ \vdots \\{\Delta {x_k}}\\ \vdots \\{\Delta {x_{b and s}}}\end{array}} \right)= \left({\begin{array}{*{20}{c}}{x_{ij}^1\left({{t_2}} \right)- x_{ij}^1\left({{t_1}} \right)}\\{x_{ij}^2\left({{t_2}} \right)- x_{ij}^2\left({{t_1}} \right)}\\ \vdots \\{x_{ij}^k\left({{t_2}} \right)- x_{ij}^k\left({{t_1}} \right)}\\ \vdots \\{x_{ij}^{b and s}\left({{t_2}} \right)- x_{ij}^{b and s}\left({{t_1}} \right)}\end{array}} \right) $ (1)
式中,xijk(t1)和xijk(t2)分别表示两个时相的图像在(i,j)位置的像元灰度值,k表示图像的波段索引(其中k=1,2,…,b and s),b and s是多光谱图像的波段数。下面以2维空间中矢量的大小和方向来说明变化矢量分析法的原理,如图 3所示。图 3中矢量的方向代表了地物的变化类型,矢量的长度代表了地物变化大小程度。
基于CVA的变化检测的强度图像是利用欧氏距离得到的,即变化强度图像的灰度值是由差值多光谱图像上对应位置的像元灰度值的平方和再开方得到的,表达式如式(2):
$ DX = \sqrt {{{\left({\Delta {x_1}} \right)}^2} + {{\left({\Delta {x_2}} \right)}^2} + \cdots + {{\left({\Delta {x_{b and s}}} \right)}^2}} $ (2)
式中,DX表示某一像元的变化强度。在实际应用中,可根据区域具体情况对变化强度设定一个阈值。若像元的变化强度在此阈值范围内,可以认为该点未发生变化;若超出此阈值范围,则认为发生了变化。通过合理的阈值分割处理,就可以有效地区分变化和未变化区域。变化矢量分析法通常是选用简单差值法(如公式1所示)来计算变化矢量以及变化模式,而变化方向图像是根据变化矢量ΔX的方向进行编码得到的。对于差值图像而言,每个像元都有b and s个不同的值,每个波段上的数值有可能为负值,有可能为零,也可能为正值。这3种可能分别对应3种编码:-1,0,1。若以3个波段为例,如表 1所示。
| 波段1 | 波段2 | 波段3 | |
| 增强 | 1 | 1 | 1 |
| 不变 | 0 | 0 | 0 |
| 减弱 | -1 | -1 | -1 |
每一位置的像元对应一个向量,向量的每一个元素是-1,0,1中的一个值。对于3个波段的图像,假设第一波段减弱,则编码为1;第二波段增强,则编码为-1;第三波段不变,则编码为0。这3个编码组成一个变化方向向量,即ΔXij=[1,-1,0],其中(i,j)为当前像元的位置。然后遍历所有情况可以得到3b and s种不同的向量,对应着3b and s种不同的变化。最后建立这些向量与1—3b and s范围上的一一映射关系,这样就实现了不同的方向矢量对应不同的灰度值。对差值图像上的每个像素进行判断,根据这种映射关系就可以得到变化方向图像。3个波段的图像对应的映射表如表 2所示。
Table 2 Mapping table between change vector and gray value of change direction image (three bands case) 下载CSV
| 序号 | 编码 | 序号 | 编码 | 序号 | 编码 | ||||||||
| 波段1 | 波段2 | 波段3 | 波段1 | 波段2 | 波段3 | 波段1 | 波段2 | 波段3 | |||||
| 1 | -1 | -1 | -1 | 10 | 0 | -1 | -1 | 19 | 1 | -1 | -1 | ||
| 2 | -1 | -1 | 0 | 11 | 0 | -1 | 0 | 20 | 1 | -1 | 0 | ||
| 3 | -1 | -1 | 1 | 12 | 0 | -1 | 1 | 21 | 1 | -1 | 1 | ||
| 4 | -1 | 0 | -1 | 13 | 0 | 0 | -1 | 22 | 1 | 0 | -1 | ||
| 5 | -1 | 0 | 0 | 14 | 0 | 0 | 0 | 23 | 1 | 0 | 0 | ||
| 6 | -1 | 0 | 1 | 15 | 0 | 0 | 1 | 24 | 1 | 0 | 1 | ||
| 7 | -1 | 1 | -1 | 16 | 0 | 1 | -1 | 25 | 1 | 1 | -1 | ||
| 8 | -1 | 1 | 0 | 17 | 0 | 1 | 0 | 26 | 1 | 1 | 0 | ||
| 9 | -1 | 1 | 1 | 18 | 0 | 1 | 1 | 27 | 1 | 1 | 1 | ||
对于上述得到的变化方向图像而言,各种类型的变化都是在变化强度确定的变化范围内部的,变化强度确定的未变化区域没有发生任何类型的变化。此外,变化方向图像的量化级为3b and s。理论上,如果每一种变化类型都发生,图像上应该有3b and s种不同的灰度值;但是对于某一特定的研究区域,并不是每一种变化类型都会发生。事实上,大多数的变化类型并没又发生或者变化区域很小,即变化方向图像上不同灰度值的种类远远小于其量化级。通过重新量化,变化方向图像的量化级就会大大较少,并使得每一种变化类型都有对应的变化区域。然后经过合理的伪彩色增强技术就可以把变化区域内不同类型的变化区分开来。
4 基于CUDA的CVA变化检测算法设计
4.1 基于CVA的变化检测并行处理思想
基于CVA的变化检测算法核心思想是根据变化强度图像确定变化的范围,并根据变化方向图像确定具体的变化类型。根据基于CVA的变化检测原理可知,无论是变化强度算子还是变化方向算子,计算结果的每个像元仅与输入图像的当前位置的不同波段上的值有关。此外,对于所有的像元而言,计算过程完全相同,具有良好的并行拓展性,因此适合利用GPU进行并行处理。根据CUDA编程特点,本文设计基于CVA的变化检测的并行算法模型。该模型将整个CVA变化检测并行算法划分成两部分主机端和设备端。主机端负责原始图像数据读取与变化检测结果图像的存储,设备端负责完成映射表、变化强度算子和变化方向算子的实现。基于CUDA的CVA变化检测并行运算的流程如图 4 所示。
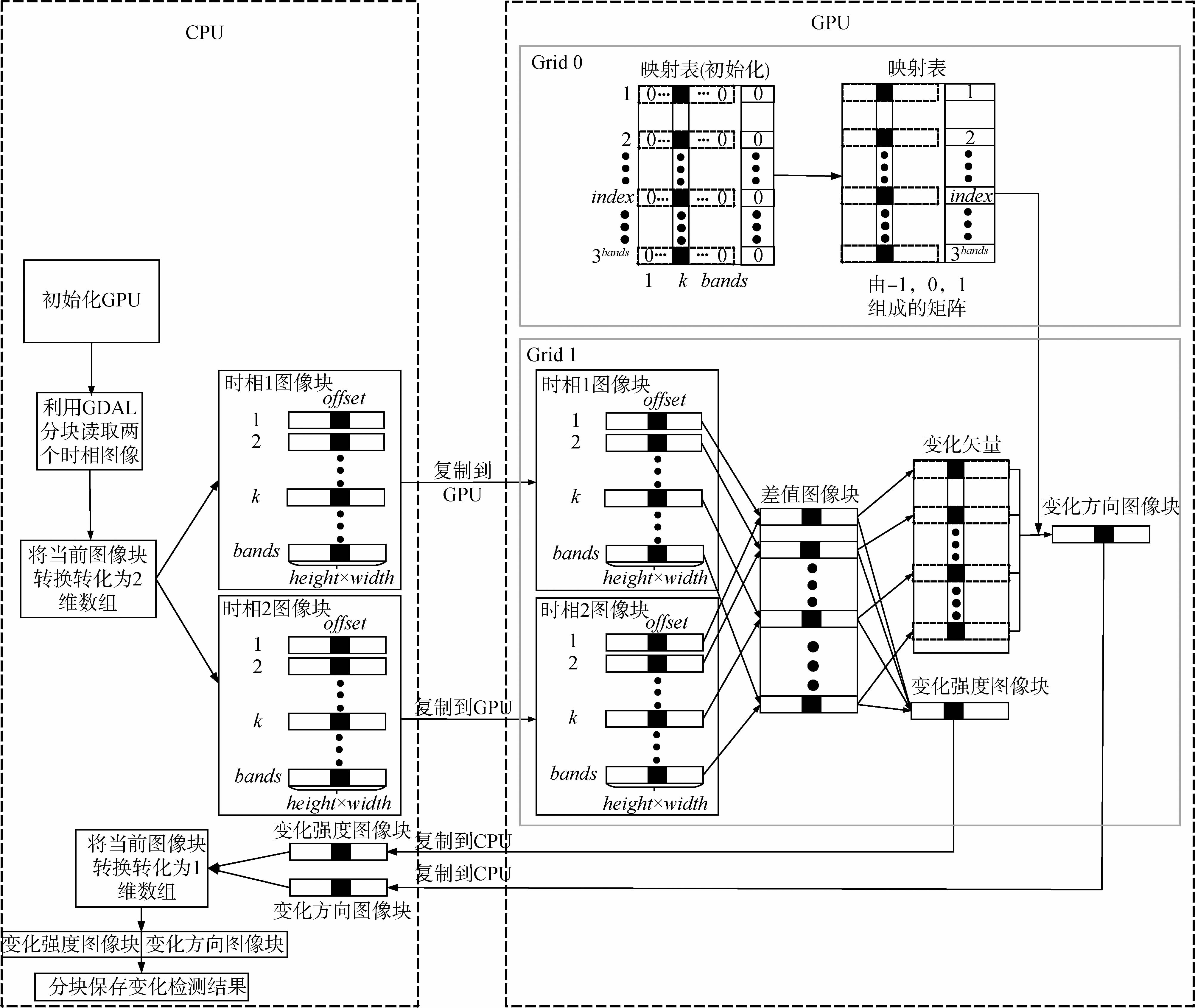
如图 4所示,在借助GPU进行变化检测前,需要对设备进行初始化工作,获取GPU硬件的相关参数信息,以便为后续的工作做准备;考虑到CPU内存和GPU显存的大小,在进行基于CUDA的CVA变化检测设计时,首先需要对遥感影像进行分块处理(图像块的行数和列数分别为height和width),并将当前的图像块读入CPU内存,接着转化为合理的存储格式。对于时相1和时相2当前图像块而言,每一行代表一个波段的图像块数据,k表示波段索引(k=1,2,…,b and s),offset表示当前线程在整个Grid中的索引号;然后将当前图像块从CPU拷贝到GPU中,并交给Kernel进行并行处理,处理结束后需要把结果从GPU拷贝到CPU中;最后在CPU中,按图像块处理顺序,逐块保存变化强度图像块和变化方向图像块。在整个过程中,最重要的就是Kernel函数的设计以及线程的分配工作。下面对基于CUDA的CVA变化检测的各个环节详细介绍。
4.2 GPU设备以及图像格式的初始化
在设计基于CVA的变化检测的并行处理模型前,首先需要对GPU进行初始化,获取必要的设备信息,为并行处理模型的设计提供必要的参数。如:GPU的个数count、以及当前GPU的索引gpu_id,一般在多GPU并行程序设计中,用于标识当前的GPU设备;Block的最大尺寸(MaxBlockX,MaxBlockY,MaxBlockZ)以及Grid的最大尺寸(MaxGridX,MaxGridY,MaxGridZ),表示GPU设备的计算能力,以限制程序设计中的Block和Grid的实际尺寸以及图像块的尺寸。GPU设备初始化的信息步骤参考附录A。
为了方便操作,在并行处理之前,本文将两个时相的遥感图像数据以BSQ的存储方式保存到2维数组中,如图 5所示。
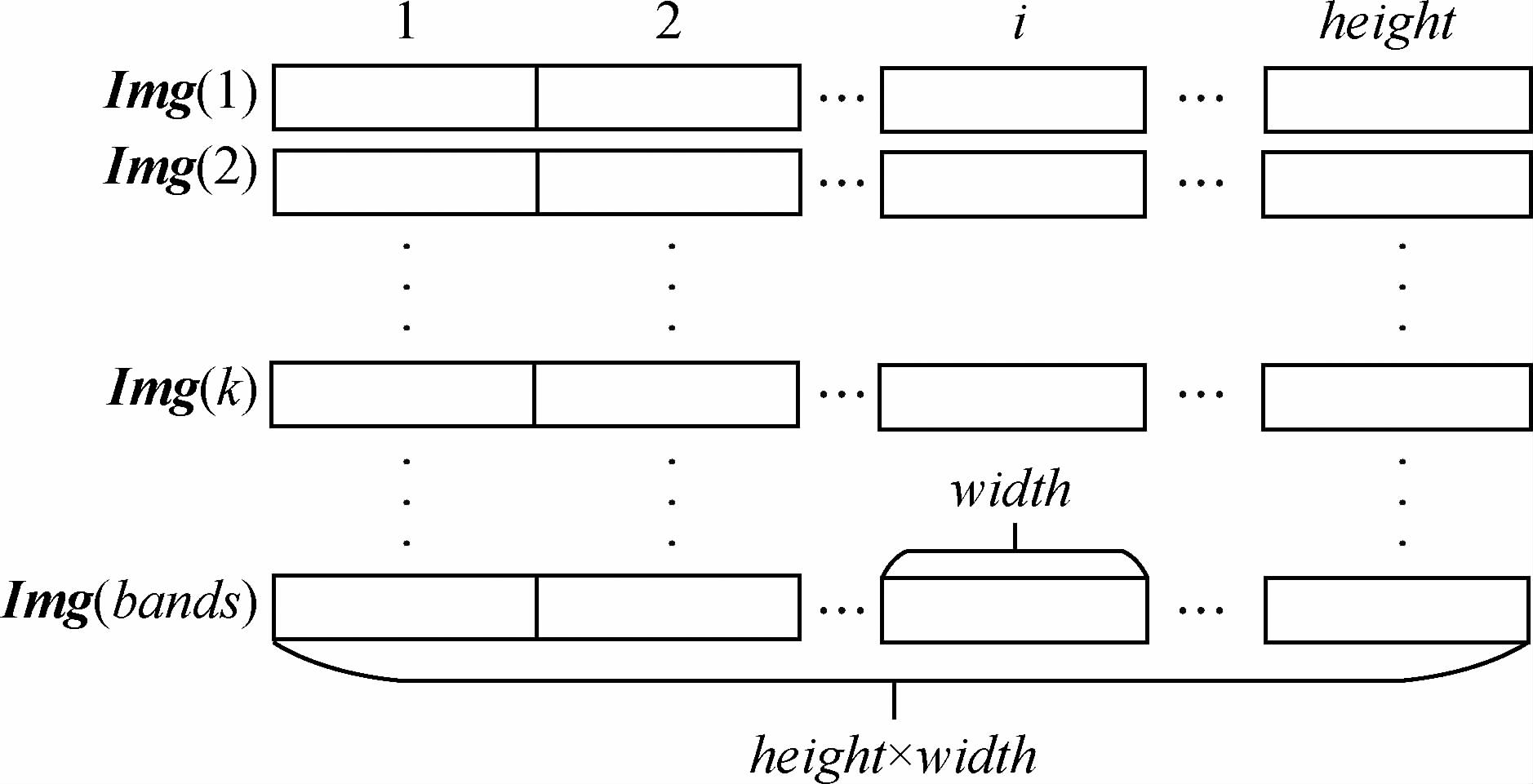
如图 5所示,假设两个时相的遥感图像各有b and s个波段,且图像有height行,width列,那么每个波段的图像的尺寸为height×width。数组中的每一行代表遥感图像上某一波段的数据,并用 Img(k)表示,其中k表示波段索引(k=1,2,…,b and s),i表示当前像元在遥感图像上的行索引(其中i=1,2,…,height)。接下来,需要将两个时相的图像数据从主机端拷贝到设备端,然后在设备端上实现变化强度算子、映射表以及变化方向算子的并行处理,最后将CVA变化检测结果从设备端拷贝到主机端并进行保存。
4.3 变化强度和变化方向算子的并行设计
下面分别针对变化强度算子、映射表以及变化方向算子的并行算法进行设计。从基于CVA的变化检测算法的原理上看出,变化强度图像和变化方向图像的像元值仅与原始图像上相同位置的像元值有关,并且每个像元值的算法是完全相同的。图像上每一个像元和每一个线程的对应关系如图 6所示。
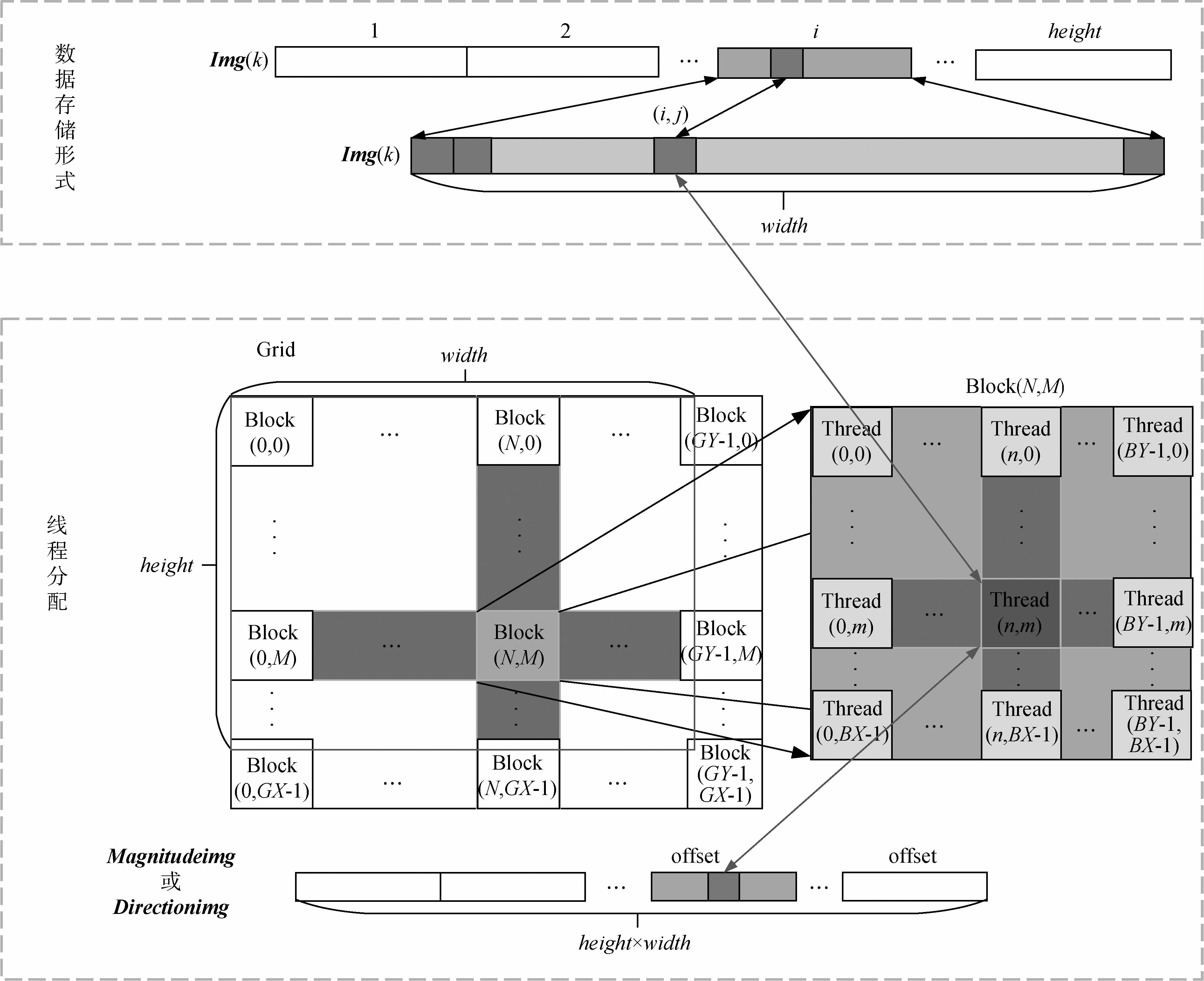
当图像的像元个数小于设备最大的并行处理能力,那么假设Grid和Block的尺寸分别为(GY,GX)和(BY,BX)(Kernel中的Grid以及Block的尺寸设计见4.4)。如图 6所示,(N,M)表示当前Block在Grid中的索引,而(n,m)表示当前Thread在当前Block中的索引,那么当前Thread在整个Grid中的索引号为(Col,Row),与之对应的像元的坐标用(i,j)表示,其中Row=M×BX+m,Col=N×BY+n。当前线程对应的变化强度和变化方向图像上的像元索引为index=i×width+j=Row×width+Col。在变化检测过程中,所有的像元同时参与运算,那么整个图像的处理耗时与一个像元的处理耗时是一样的;当图像像元个数大于等于设备最大并行计算能力时,需要对图像进行分块来实现并行处理,块与块之间的处理属于串行,因此图像变化检测的耗时是处理一个像元的耗时与分块数量的乘积。对于这两种情况而言,理论上变化检测提高的效率分别是height×width倍和(height×width)/imageblocknum倍(其中,imageblocknum表示图像分块的个数)。
4.3.1 映射表建立
在进行CVA变化检测之前,需要先建立变化方向矢量DirectionVector(index)与变化方向灰度值DirectionGrayvalue(index)的映射表,以便为不同的变化方向矢量编码不同的值,从而计算变化方向图像。其中,DirectionVector表示所有变化矢量组成的矩阵,空间大小为3b and s×b and s;DirectionGrayvalue表示与变化矢量一一对应的编码值,空间大小为3b and s×1,index对应映射表的行,k对应映射表的列。例如在表 2中,当b and s=3时,总共有27种变化方向矢量,代表变化方向图像的灰度值范围是1—27。映射表的伪代码参见附录B。
4.3.2 变化强度算子和变化方向算子
在基于CUDA的CVA变化检测过程中,最主要的就是设计变化强度算子和变化方向算子的Kernel函数。为了减少数据在CPU和GPU之间的数据传输,提高变化检测的效率,本文将这两个算子融合在同一个Grid中,以完成变化检测,即计算变化强度图像Magnitudeimg和变化方向图像Direction-img。这两个变量都是1维的指针变量,它们的空间大小都是[1,height×width]。另外为了计算变化方向图像,本文为差值图像Differimg的各个波段设置阈值threshold,其中,Differimg的空间大小为[b and s,height×width],threshold(k)表示第k个波段的正数阈值,用于判断每个波段的反射率变化情况。当Differimg[k][offset] < threshold[k]时,表示反射率减少,将Differimg[k][offset]值更新为-1;当-threshold[k]≤Differimg[k][offset] < hreshold[k]时,表示反射率不变,将Differimg[k][offset]的值更新为0;当Differimg[k][offset]≥threshold[k]时,表示反射率增加,将Differimg[k][offset]的值更新为1。最终将Differimg的每一列与DirectionVector中的每一行进行比较,完全匹配时,将对应的编码值赋给变化方向图像的当前像元,以确定变化的类型。变化强度算子和变化方向算子的具体实现,参考附录C。
4.4 线程分配
执行并行运算的关键是Block、Thread大小的设定以及设备端并行化指令的设计。设定合理的Block、Thread大小是保证并行化指令高速执行获得较高计算效率的前提条件(陶伟东等,2013)。由于GPU中的多流处理器(SM)再取指和发射指令时,是以warp为单位并交给流处理单元(SP)执行的,而本文中用的GPU中的warp是32个线程。为了有效利用执行SP,每个Block中线程数目须为32的倍数。当每个Block中线程数目不是32倍数时就会造成SP的浪费,从而降低并行计算的效率,因此本次实验中Block的尺寸设置为:dim3 dimBlock(16,16),dim3为数据类型。对于Grid而言,理论上Grid越大越好。而实际处理过程中,Grid尺寸的选择与图像的大小有关,如下图 7所示。
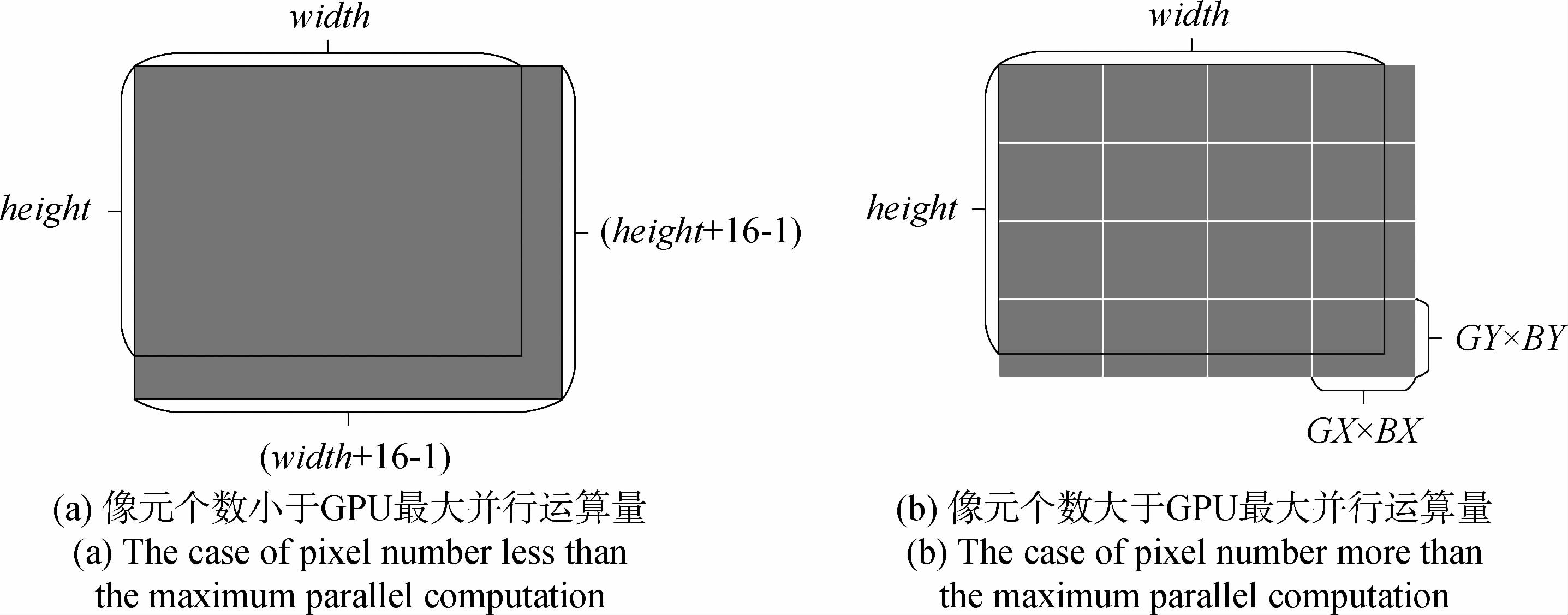
如图 7所示,其中height和width分别表示图像的行数和列数。如图 7(a)所示,当图像的像元个数小于设备最大可以并行的运算量时,即height×width < 56×MaxGridX×MaxGridY,Grid大小为((width+16-1)/16,(height+16-1)/16),处理过程中只需要一次并行运算就可以完成变化检测;如图 7(b)所示,当图像的像元的个数大于设备的最大并行计算量时,即height×width≥256×MaxGridX×MaxGridY,Grid就选取设备支持的最大尺寸dim3 dimGrid(MaxGridY,MaxGridX),这种情况下,一次并行运算并不能完成图像的运算,因此需要对图像进行分块处理,需要分(INT(height/MaxGridY)+1,INT(width/MaxGridX)+1)块,才可以将变化检测算法处理完。
5 基于CUDA的CVA变化检测实验
5.1 实验环境
本文的实验主机平台是 Intel(R)Core(TM)i5-3470 CPU,主频率为3.2 GHz,系统内存为4 G,CPU有4个核;显卡采用的NVIDIA GeForce GT 610,GPU型号是GF119,属于Fermi构架。GPU的核心频率为1.62 GHz,显卡内存为1 G,GPU运算核为48个。操作系统为Microsoft Window 8.1 64位,开发环境为Microsoft Visual Studio 2010,整个实验基于GDAL- 1.9.2 、GeForce 340.52 Driver和CUDA6.0 包括:CUDA Toolkit 6.0和CUDA Samples 6.0。
5.2 CVA变化检测实验
本文选取江苏和山东交界处徐州-枣庄一带的2000年4月的L and sat 5 TM图像和2013年4月的L and sat 8 OLI图像作为实验数据。首先分别对两个时相的遥感图像做辐射定标,并进行FLAASH大气校正;接着以2013年4月的L and sat 8 OLI图像为基准,对2000年4月的L and sat 5 TM图像做几何校正及配准处理,使得两幅影像在空间方位和尺度上保持一致。图 8为研究区域的两个时相图像的短波红外、近红外、红色波段的组合,图像大小为5120×5120。本文利用基于CVA的变化检测方法对研究区域进行变化检测分析,变化强度图像和变化方向图像的结果如图 9所示。


如图 9所示,变化强度图像表示所有波段变化的共性,其纹理结构比较清晰,几何信息比较强,变化的范围更加准确;变化方向图像表示波段与波段变化的个性,体现了光谱变化的差别,突出了变化的类型。为了体现出变化检测的效果,本文分别选取了两个样区进行了分析,如图 10所示。

图 10(a)、(b)分别表示两个样区的两时相的原始图像和变化强度图像。根据CVA变化检测原理可知,变化区域在变化检测强度图中为亮色调,为变化区域为暗色调。图 10(a)中变化强度图像的白色部分表示骆马湖扩大的区域,图 10(b)变化强度图像中间亮色调部分表示废黄河沿岸的裸地变化为植被。通过对比分析可知,原始图像中有变化的区域与变化强度图像上亮色调部分一一对应,验证了基于CVA变化检测的可行性。
为了比较不同数据量对处理效率的影响,本文将配准好的影像分别裁剪为不同大小的子影像,包括:256×256,256×512,512×512,512×1024,1024×1024,1024×2048,2048×2048,2048×4096,4096×4096,5120×5120等。然后分别对这几组数据做实验并进行分析,利用这几组数据分别采用CPU单线程运算、OpenMP多线程运算以及GPU/CUDA并行运算,变化检测耗时和加速比结果如表 3所示。
| 序号 | 图像大小 | CPU单线程耗时/s | OpenMP多线程耗时/s | OpenMP/CPU | GPU端耗时/s | GPU/CPU |
| 1 | 256×256 | 0.757 | 0.242 | 3.128 | 0.233 | 3.249 |
| 2 | 256×512 | 1.507 | 0.522 | 2.887 | 0.267 | 5.644 |
| 3 | 512×512 | 2.978 | 0.974 | 3.058 | 0.430 | 6.926 |
| 3 | 512×1024 | 6.205 | 1.807 | 3.434 | 0.501 | 12.385 |
| 4 | 1024×1024 | 11.942 | 3.503 | 3.409 | 1.141 | 10.466 |
| 5 | 1024×2048 | 23.783 | 7.290 | 3.262 | 3.282 | 7.247 |
| 6 | 2048×2048 | 46.317 | 14.121 | 3.280 | 4.902 | 9.449 |
| 7 | 2048×4096 | 94.474 | 28.049 | 3.368 | 10.778 | 8.765 |
| 8 | 4096×4096 | 188.718 | 54.382 | 3.470 | 22.069 | 8.551 |
| 9 | 4096×5120 | 236.938 | 67.344 | 3.518 | 24.949 | 9.497 |
| 10 | 5120×5120 | 298.491 | 83.478 | 2.857 | 29.759 | 10.030 |
从表 3中可以看出,对于CPU上的串行处理而言,随着实验的图像的数据量的增加,变化检测耗时呈线性增加,因为在CPU上的串行运算是逐个像元进行处理的,所以随着图像数据量的增加,变化检测耗时逐渐变长。为了对比分析CVA变化检测在GPU上的并行运算的优势,本文利用OpenMP共享式并行处理技术将变化检测任务分配到CPU的多核上进行处理,理论上利用OpenMP技术进行并行处理,变化检测的效率提高的最大倍数等于CPU的运算核数,然而从表 3中可以看出,变化检测在CPU上的并行加速的倍数稍低于CPU的核数,这是由于计算机本身运行以及其他必要的程序或软件运行会占用一定的进程所致。对于GPU上的CVA变化检测,考虑到数据在CPU和GPU间的传输耗,变化检测的效率是CPU串行处理的10倍左右,在一定程度上实现了实时变化检测。利用CPU串行、OpenMP并行以及GPU/CUDA 3种方法对不同数据量的遥感影像进行变化检测处理的效率对比也可以表示为如图 11所示。
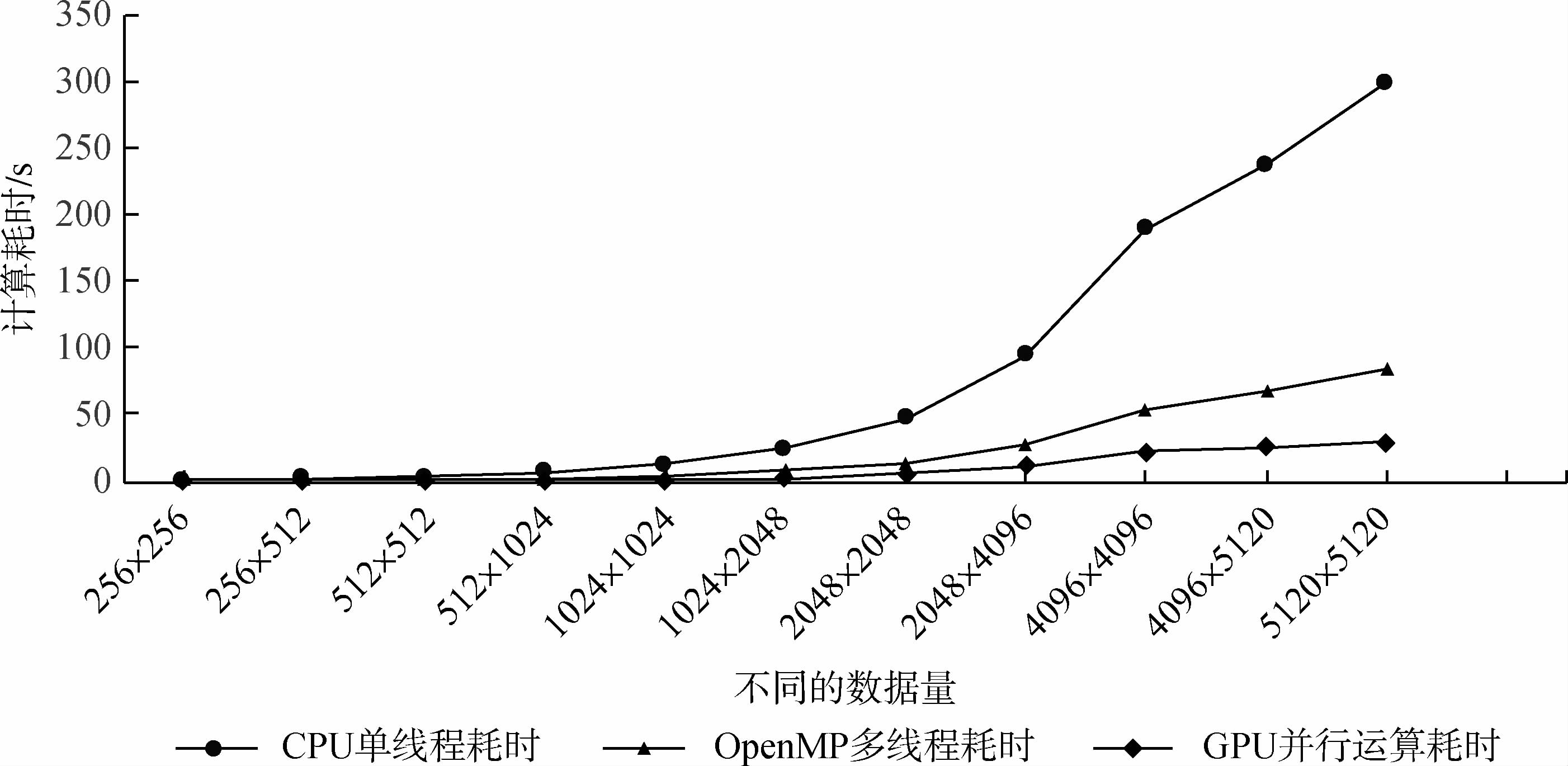
如图 11所示,在GPU中进行并行变化检测时,当前处理的图像块的所有像元同时进行运算,如果不考虑数据传输的情况,GPU上每一块图像的变化检测耗时与CPU上处理每一个像元所需要的时间相当;而在CPU上的串行变化检测耗时会随着数据量的增加逐步增加,因此这种情况下的加速比与图像分块的个数成反比,与整幅图像的数据量成正比。如果考虑到数据在CPU和GPU之间的传输,GPU上的并行变化检测效率除了与分块的个数、整幅图像的数据量有关外,还受到任务分配方法、数据存储类型,数据传输速度等因素的影响。因此,实际情况下,利用GPU/CUDA进行CVA变化检测时需要注意一下几点:对于Kernel中常有的只读性变量最好保存在常数存储内,如图像的波段数,映射表的索引范围等;对于整个程序中常用函数变量最好在循环外定义和初始化,在循环内调用,如设备端的映射表;尽量减少Kernel函数的个数,以减少数据在各种存储器间的传输次数,内核函数中尽量减少for,while等循环类语句的出现。此外,合理的将共享存储器和纹理存储器等具有高速缓存的存储器与全局存储器相结合,可以实现数据的快速拷贝,从而提高数据处理的速度。
考虑到CPU内存和GPU显存的限制,对于大数据量的遥感影像进行变化检测时,还需要对图像进行分块处理,而不同尺寸的分块对变化检测的效率有很大影响。因此,本文以数据量为5120×5120的遥感图像进行CVA变化检测,并分别用200×200、400×400、…、4000×4000的图像块进行运算,以分析图像的分块尺寸对以上3种条件下的CVA变化检测的影响。实验结果如图 12所示。

从图 12可以看出来,在CPU串行和OpenMP并行运算的条件下,CVA变化检测耗时基本上保持不变,且分别在285S和85S左右波动。这是由于图像块与图像块之间的处理属于串行,当图像分块增大时,虽然块数少了,但是单块图像处理的耗时增加,因此总的CVA变化检测耗时基本上保持稳定不变;而在GPU并行条件下,随着分块尺寸的增大,CVA变化检测耗时逐渐减少。这是因为分块越大,每次传输的数据量增加,而数据在CPU和GPU之间的传输的次数减少所致。因此,在对大数据做CVA变化检测时,如果CPU内存和GPU显存没有溢出,可以适当的增大图像分块的尺寸,以提高图像处理的效率。从基于像素的CVA变化检测的原理以及实验的结果分析,以上3种变化检测方法的准确度不会受到分块大小的影响。无论怎么分块,每个像元的变化检测结果都只是与当前位置上的像元灰度值有关,而与周围的像元无关,因此不同的分块并不会影响变化检测的准确度。
6 结 论
为了实现对土地利用和覆盖变化的实时监测、对海量遥感数据的快速处理,本文结合CUDA编程模型,针对基于CVA的变化检测算法设计了一种并行处理模型。该模型将CVA变化检测中的变化强度检测、映射表构建和变化方向检测3个过程嵌入到GPU中进行研究。本文利用CPU串行、OpenMP并行以及GPU/CUDA并行3种方法对不同数据量遥感进行CVA变化检测实验。结果表明,与另外两种方法相比,基于CUDA C的CVA变化检测效率有明显提高。当图像的数据量相对较小时,结合CUDA的CVA变化检测耗时等于在CPU上对一个像元计算的耗时,一般不会随着数据量的增加而增加,从而大大地提高了变化检测的运算速度;当图像数据量比较大时,就需要对图像进行分块并行处理,运算耗时与分块的个数成正比例关系。根据图 12中GPU耗时随着图像分块大小的变化,可知对于大数据量的遥感影像变化检测而言,在内存和显存不溢出的前提下,增加分块的尺寸,可以减少分块的数量,从而提高变化检测的效率。
总之,在实际处理过程中,针对不同的数据,需要充分地运用全局存储器和各种具有高缓存的存储器来提高数据的调用和传输效率,减少Kernel的个数和图像分块的个数以减少数据在不同设备间传输的次数,并调节Grid和Block的大小以便为并行任务合理地分配处理单元,从而充分利用GPU的并行运算能力,提高遥感图像处理的效率,以满足各种领域对数字图像的处理要求。
附录
在利用GPU设备进行并行变化检测之前,首先需要获取GPU设备的基本信息,包括GPU个数、每个GPU设备的名称等信息、Block的最大尺寸以及Grid的最大尺寸等信息。GPU设备初始化伪代码如下:
_host_ bool InitCUDA()
Dim count, gpu_id As Integar
cudaGetDeviceCount(&count);
For gpu_id =0 To count
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, gpu_id);
//Block的最大尺寸
MaxBlockX=prop.maxThreadsDim[0];
MaxBlockY=prop.maxThreadsDim[1];
MaxBlockZ=prop.maxThreadsDim[2];
//Grid的最大尺寸
MaxGridX=prop.maxGridSize[0];
MaxGridY=prop.maxGridSize[1];
MaxGridZ=prop.maxGridSize[2];
……………………
EndFor
End InitCUDA
附录B在进行CVA变化检测之前,我们需要构造映射表,用于对变化矢量进行编码,用于计算变化方向图像。构造映射表的伪代码如下所示:
_global_ void MappingTable_Kernel (Input bands; Output DirectionVector, DirectionGrayvalue )Dim index, k, index_k As Integer
index = threadIdx.x+blockIdx.x*blockDim.x;
k = threadIdx.y+blockIdx.y*blockDim.y;
index_k=pow(3.0,(bands-k));
①//反射率减少
If ((index+1)%index_k≤(index_k/3)
AND
(index+1)%index_k !=0)
Then DirectionVector[index][k]=-1
②//反射率不变
Else
If((index_k/3≤(index+1)%index_k≤2*index_k/3))
Then DirectionVector[index][k]=0
③//反射率增加
Else
If (index+1)%index_k>2×index_k/3 or
(index+1)%index_k=0
Then DirectionVector[index][k]=1
Eendif
//与DirectionVector的行一一对应的编码值
DirectionGrayvalue[index]=index+1
End MappingTable_Kernel
其中,DirectionVector表示所有变化矢量组成的矩阵,空间大小为[3bands,bands];DirectionGrayvalue表示与变化矢量一一对应的灰度值,空间大小为[3bands,1],index对应映射表的行,k对应映射表的列。 附录C在基于CVA变化检测的程序设计中,最重要的就是结合像元与线程的对应关系,设计变化强度算子和变化方向算子,其对应的Kernel函数的如下所示:
_global_ void ChangeDetection Kerenl ( Input Inputimg1, Inputimg2, DirectionVector, DirectionGrayvalue, height, width, bands; Output Magnitudeimg, Directionimg ) Dim Row, Col, offset As Integer Row = threadIdx.y+blockIdx.y×blockDim.y; Col = threadIdx.x+blockIdx.x×blockDim.x; offset = Col+Row×width; GrayScale_Direction=pow(3.0, bands);①//变化强度算子
For k= 0 To bands
Magnitudeimg[offset]+=pow((Inputimg2[k][offset]-Inputimg1[k][offset]),2);
EndFor
Magnitudeimg[offset]=sqrt(Magnitudeimg[offset]);
②//变化方向算子
For k= 0 To bands
Differimg[k][offset]=Inputimg2[k][offset]-Inputimg1[k][offset];
Dim threshold [bands] As Integer
//反射率减少
If Differimg ≤ -threshold(k)
Then Differimg[k][offset]=-1
//反射率不变
Else
If -threshold(k) ≤ Differimg[k][offset] ≤ threshold(k)Then Differimg[k][offset]=0
//反射率增强
Else If Differimg[k][offset] ≥ threshold(k)Then Differimg[k][offset]=1;
Endif
//根据当前像素的变化矢量查询对应的编码值
For index=0 To GrayScale_Direction Dim index_XY As Integer index_XY=0; //判断DirectionVector的第index行的每个值与当前像素的矢量的每个值是否相等 For k=0 To bandsIf DirectionVector[index][k]=Differimg[k][offset]
Then index_XY++;
Endif
EndFor //如果当前像素的变化矢量与DirectionVector的第index行相等,则将对应的DirectionGrayvalue的index值赋给变化方向图像的对应当前像素 If index_XY=bands Then Directionimg[offset]=DirectionGrayvalue[index] Endif
EndFor
EndFor
End ChangeDetection Kerenl
其中,Magnitudeimg和Directionimg分别表示变化强度图像指针和变化方向图像指针,它们的空间大小都是[1,height×width];Differimg表示差值图像指针;Inputimg1和Inputimg2分别表示时相1和时相2图像的指针,空间大小为[bands,height×width],bands为图像的波段数,height表示图像的行数,width表示图像的列数;GrayScale_Direction表示变化方向图像中最大的理论值,即3bands;threshold表示各个波段的阈值,threshold[k]为第k个波段的阈值,用于判断每个波段的反射率是否减少、不变或增加。参考文献
- Asano S, Maruyama T and Yamaguchi Y. 2009. Performance comparison of FPGA, GPU and CPU in image processing. IEEE International Conference on Field Programmable Logic and Applications. Prague:IEEE:126-131[DOI:10.1109/FPL.2009.5272532]
- Fang L Y, Wang M and Li D R. 2014. A CPU-GPU co-processing orthographic rectification approach for optical satellite imagery. Acta Geodaetica et Cartographica Sinica, 42(5):668-675 (方留杨, 王密, 李德仁. 2014.基于CPU和GPU协同处理的光学卫星遥感影像正射校正方法. 测绘学报, 42(5):668-675)
- Hu B F and Yang X. 2013. GPU-accelerated parallel 3D image thinning. 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing (HPCC_EUC). Zhangjiajie:IEEE:149-152[DOI:10.1109/HPCC.and.EUC.2013.30]Kockara S, Halic T, Bayrak C. 2009. Real-time minute change detection on GPU for cellular and remote sensor imaging. Advanced Information Networking and Applications Workshops, 2009. WAINA'09. International Conference. Bradford:IEEE:13-18[DOI:10.1109/WAINA.2009.202]Lindholm E, Nickolls J, Oberman S and Montrym J. 2008. NVIDIA Tesla:a unified graphics and computing architecture. IEEE Micro, 28(2):39-55[DOI:10.1109/MM.2008.31]Malila W A. 1980. Change vector analysis:an approach for detecting forest changes with Landsat//Burroff P G and Morrison D B, eds. Laboratory for Applications of Remote Sensing Symposia. West Lafayette, Indiana:Purdue University:326-335Mubasher M M, Farid M S, Khaliq A and Yousaf M M. 2012. A parallel algorithm for change detection. IEEE 2012 15th International Multitopic Conference. Islamabad:IEEE:201-208[DOI:10.1109/INMIC.2012.6511449]Tao W D, Huang H, Yuan Z Y, Yang L and Wang J C. 2013. Edge detection of remote sensing image based on GPU parallel. Geography and Geo-Information Science, 29(1):8-11 (陶伟东, 黄昊, 苑振宇, 杨柳, 王结臣. 2013. 基于GPU并行的遥感影像边缘检测算法. 地理与地理信息科学, 29(1):8-11)[DOI:10.7702/dlydlxxkx20130102]Wei H. 2011. Design and Realization of Multi-temporal Remote Sensing Image Change Detection System. Wuhan:Huazhong University of Science and Technology(胡维. 2011. 多时相遥感影像变化检测并行系统设计与实现. 武汉:华中科技大学)Xiao H and Zhang Z X. 2010. Parallel image matching algorithm based on GPGPU. Acta Geodaetica et Cartographica Sinica, 39(1):46-51 (肖汉, 张祖勋. 2010. 基于GPGPU的并行影像匹配算法. 测绘学报, 39(1):46-51)Xu X G and Zhang Q. 2011. High performance parallel remote sensing image processing based on CUDA. Geospatial Information, 9(6):47-54 (许雪贵, 张清. 2011. 基于CUDA的高效并行遥感影像处理. 地理空间信息, 9(6):47-54)Yang Z Y, Zhu Y T and Pu Y. 2008. Parallel image processing based on CUDA. Proceedings of the 2008 International Conference on Computer Science and Software Engineering. Wuhan, Hubei:IEEE:198-201[DOI:10.1109/CSSE.2008.1448]Ye C. 2014. Research on Parallel Processing of SAR Image Change Detection. Hangzhou:Hangzhou Electronic Science and Technology University (叶琛. 2014. SAR图像变化检测并行处理研究. 杭州:杭州电子科技大学)Zhang N, Chen Y S and Wang J L. 2010. Image parallel processing based on GPU. 2010 2nd International Conference on Advanced Computer Control (ICACC). Shenyang:IEEE:367-370[DOI:10.1109/ICACC.2010.5486836]Zhang S and Zhu Y L. 2009. CUDA GPU High-Performance Computing. Beijing:China Water Conservancy and Hydropower Press:36-37 (张舒, 褚艳利. 2009.GPU高性能运算之CUDA. 北京:中国水利水电出版社:36-37)Zhu H M, Cao Y, Zhou Z Q and Gong M G. 2012. Parallel multi-temporal remote sensing image change detection on GPU. IEEE 26th International Parallel and Distributed Processing Symposium Workshops & PhD Forum (IPDPSW). Shanghai:IEEE:1898-1904[DOI:10.1109/IPDPSW.2012.234]Zhu K and Cui S Y. 2012. Near real-time SAR change detection using CUDA. IEEE International Geoscience and Remote Sensing Symposium (IGARSS). Munich:IEEE:2004-2007[DOI:10.1109/IGARSS.2012.6351107]The dense feature-weighted object tracking
 CHANG Fangzheng1
,
ZHAO Yindi1
,
LIU Shanlei2
1. School of Environment Science & Spatial Informatics, China University of Mining and Technology, Jiangsu Xuzhou 221116, China;2. Basic geographic information center of Jiangsu, Jiangsu Nanjing, 210013, China
CHANG Fangzheng1
,
ZHAO Yindi1
,
LIU Shanlei2
1. School of Environment Science & Spatial Informatics, China University of Mining and Technology, Jiangsu Xuzhou 221116, China;2. Basic geographic information center of Jiangsu, Jiangsu Nanjing, 210013, ChinaAbstract
With the rapidly developing society, land use or cover change has gained considerable attention. Highly economic, practical, and efficient remote sensing technology has been used in various methods of land dynamic change detection. However, rapid image processing has become a problem with the increase in data volume and complexity in remote sensing. New complex algorithms that increase both computation volume and time have been proposed to achieve a high precision of change detection. Moreover, the Central Processing Unit (CPU) computing cells are limited and cannot meet real-time requirements. To achieve real-time change detection using remote sensing image, this paper designs a parallel processing model based on Compute Unified Device Architecture (CUDA), in reference to the CVA-based change detection algorithm.The model can be divided into the following steps. To make the general PC without the large cache process data, the model first uses Geospatial Data Abstraction Library to determine image block reading, block operation, and block saving. Second, CVA change detection is paralleled through three sub-processes:changing the magnitude detection, designing the index table, and changing the direction of detection. Then, the three sub-processes are embedded in CPU and Graphic Process Unit (GPU) through CUDA C. Finally, different sizes of multi-group images are studied with the same model to execute CVA change detection in consideration of the effect of image data volume and block size on the change detection efficiency. For comparison, the same group image data are also processed using OpenMP on multi-core systems.In consideration of image data volume, the change detection speedup remains unchanged if the data volume is less than the total PC cache. Executing image block is already unnecessary. However, if the data volume is larger than the total PC cache, image block processing is needed to ensure that the cache is not out. Larger image block means more efficient change detection. The efficiency of the parallel computing of CVA-based change detection is increased 10 times in GPU than serial processing in CPU. However, OpenMP is only about three times faster than serial processing in CPU. GPU is more capable in digital image processing than CPU.Change detection processing is serial between the block and image block, and processing is parallel in each image block. With enough cache, larger image block means higher degree of parallelization and change detection efficiency. Parallel operation integrated with CUDA effectively improves change detection based on CVA. To some extent, this operation reaches the effect of the real-time change detection.
Key words
remote sensing imagery; change detection; change vector analysis; parallel computing; compute unified device architecture
- 目录 目录
- 文章信息 文章信息
- 引用格式 引用格式
- 地图 地图
- 评论 评论
- 图 图
- 表 表
- 二维码 二维码
- 参考文献 参考文献


