|
|


|
收稿日期: 2014-12-15; 修订日期: 2015-05-04;
优先数字出版日期: 2015-05-11
基金项目: 国家高技术研究发展计划(863计划) (编号: 2012AA12A304, 2013AA12A301); 中国科学院遥感与数字地球研究所“一三五”规划培育计划(编号: Y3SG1500CX)
第一作者简介: 张正(1989-), 男, 博士生, 现从遥感数据挖掘、高性能遥感数据处理系统的理论和应用研究。E-mail: zhangzheng2035@163.com
通信作者简介: 唐娉(1968-), 女, 研究员, 主要从事遥感图像处理、信息提取和数据挖掘技术研究。E-mail: tangping@radi.ac.cn
中图分类号: TP701
文献标识码: A
文章编号: 1007-4619(2016)02-0184-13
|
摘要
大数据技术中的一个难点是如何统筹多源异构的数据。在多源数据协同定量遥感产品生产系统中,不同传感器数据的协同使用为生产系统的各个环节都带来了许多的问题,例如异构数据文件的统一表示和调度,繁杂生产流程的统一抽象等。领域驱动设计是一种应对软件核心复杂性的设计方式。领域驱动是指在设计过程中经过不断的迭代,逐渐提炼出一套灵活优雅的领域模型。领域模型专注于分析问题领域本身,发掘重要的业务领域概念,并建立业务领域概念之间的关系。本文在不断实践的基础上提出了一组较成熟的领域模型,该模型用一种统一的方式解决了多源数据协同生产系统中各方面的问题,并显著地降低了系统集成的难度和工作量,且为新数据源的加入预留了灵活性。
关键词
领域驱动设计, 领域模型, 多源数据协同, 设计模式, 星机地综合, 系统集成
Abstract
Currently existing quantitative remote sensing products are mainly based on source data from the same sensor. However, the use of a single data source limits the space–time continuity and accuracy of these products. In recent years, more sensors have become available, and an increasing demand to employ multisource data emerges to generate quantitative remote sensing products. We build a multisource data synergized production system to materialize this idea. However, data from different sensors are quite heterogeneous in many aspects, such as file naming rule, data format, number of files, geometric positioning, and band setting. The heterogeneity of multisource data has many challenges in almost all parts of the production system in the process of system development and further extension. Developers have implemented and exhausted diverse logics to tackle the difference among multisource data. Therefore, we propose a set of domain models for the data from different sensors to share the same behavior when addressing, moving, and dispatching. The domain model should be sufficiently flexible to adapt new data in arbitrary form when new products are integrated in the future. Based on the unified behavior of data, all related functions in the system are also unified and can be freely used regardless of the data type. Domain-driven design is a software design philosophy that tackles core complexity in the heart of software by iteratively refining a set of core domain models. A refined domain model is valuable because of its high reusability. Domain models can ensure that all business logics have unified interfaces throughout a large system. We propose a set of domain models for each business scenarios in our system, such as data hierarchy, filename parsing, repository pattern, script building, order configuration, and job running. Based on the proposed domain model, we have built a comprehensive multisource data synergized quantitative remote sensing production system. The system is order-driven and can automatically produce the required products. Cascade production is also supported, which means that, if a high-level product requires nonexistent low-level products, then these low-level products will be spontaneously produced. The function modules include data import, order management, data search, and production. The system supports approximately 30 types of source data from almost all commonly used sensors and more than 40 types of quantitative remote sensing products. Thousands of products have been generated, and the system performs well. During system development, the number of code lines and function points are significantly reduced by using the proposed domain model. During system extension, the domain model adapts well and is completely compatible with all new types of data and products without exception and modification. The proposed domain model has shown its generality to generate multisource data with unified behavior and flexibility to adapt new data and products. The model can significantly reduce the number of code lines and function points. Thus, system development and extension have become easier and more effective. The domain model can also be referenced by other data synergized production systems. In the future, we will attempt to refine the domain model to make it more versatile and flexible.
Key words
domain-driven design, domain model, multi-source data synergy, system integration, software architecture
1 引 言
以往的定量遥感产品体系,例如MODIS产品系列和中国的FY卫星产品系列,都主要是基于单一传感器数据源,因此无法得到时空连续性强的产品体系。定量产品算法在设计时也无法充分挖掘现有的理论成果,在一定程度上限制了产品的精度和可靠性的提高,影响到了定量遥感产品在各行业的应用(历华等,2007; Soudani等,2006; Zhong等,2014)。
随着对地观测技术的日新月异,卫星传感器的种类越来越多,基于多源遥感数据协同的定量遥感产品生产越来越受到重视(Bricaud等,2002; Gao等,2013; Zhao等,2014)。大数据技术中的一个难点是如何统筹多源异构的数据。在多源数据协同定量遥感产品的生产系统中,由于不同传感器数据的存储格式,文件命名,几何定位,波段设置,辐射性能等各方面都存在一定的差异,多源遥感数据的协同应用存在许多挑战。
国家高技术研究发展计划项目“星机地综合定量遥感系统与应用示范”中提出了要率先尝试建立一套多源数据协同定量遥感产品生产系统的任务。该系统利用多源数据协同生产重点区域和全球尺度下的定量遥感产品,所支持的源数据基本涵盖了所有主要的中低分辨率传感器平台,包括MODIS,AVHRR,MERSI,VIRR,TM,ETM,GOES,MTSAT,CEBRS02B-CCD,HJ-CCD,HJ-IRS等。产品体系包含植被结构与生长状态产品,辐射收支产品,水热通量产品和冰雪变化产品4大类中的叶面积指数,植被覆盖度,净初级生产力,下行长短波辐射,净辐射,潜热通量等几十种产品。
从生产系统设计与集成的角度来看,多源异构遥感数据的协同使用带来的问题十分棘手。首先,不同传感器数据的文件存储模式大不相同,从格式到数量都有一定的区别,而且设计良好的系统还需要考虑到将来可能融入系统的未知数据形式,以避免大规模的重构。其次,多源的数据引入了冗杂的产品生产流程,各种生产算法的输入输出以及其他参数的类别和数量皆有不同。在系统集成时,这些流程如果各自实现,虽然思路上很直接,但却会产生过多的重复劳动,这就需要系统设计既能最大化的提炼不同生产流程中的一致性,也要保持生产流程的灵活性,求同存异。再次,要满足海量数据产品的快速生产,分布式高性能服务器的使用是必不可少的。然而考虑到这些高性能的设备往往都不是专用的,系统设置也会存在变动。因此对分布式系统存储和计算资源的调度逻辑需要统一抽象和封装,以隔离硬件环境对系统的影响,便于在不同硬件之间迁移。总的来看,这些都对系统的设计提出了很高的要求,对各个环节的业务逻辑既要充分的抽象,又要保持高度的灵活性,以统筹兼容各类数据和生产流程。
领域驱动设计是一种应对软件核心复杂性的良好的设计方式(Evans,2004)。领域驱动就是指经过不断的迭代,逐渐提炼出一套灵活优雅的领域模型,来抽象出核心的业务逻辑。领域模型专注于分析问题领域本身,发掘重要的业务领域概念,并建立业务领域概念之间的关系(Balasubramanian等,2006; Buschmann等,2007; Nilsson,2006)。领域模型的价值在于可复用,一旦提炼出一套成熟的领域模型,以后大多数相关的软件设计都可以遵循这一模型(Agrawal等,2003; Landre等,2007)。
在多源数据协同定量遥感产品生产系统的设计过程中,经过不断地迭代与重构,提出了一套较成熟的领域模型,用一种统一的方式解决了多源数据协同生产中各环节的问题。基于该领域模型实现的生产系统,成功地支持了数十种源数据的协同使用以及数十种不同层级定量产品的生产。并显著地降低了系统集成的难度和工作量,且为将来未知的新数据源的加入预留了灵活性。
2 业务场景与领域模型
2.1 系统业务场景总览
本系统是围绕着多源数据协同定量遥感产品的按需生产而展开的,将其涉及的业务分解为如下图 1所示的几个场景。图 1同时也简单描述了这些业务之间的关联。后续的小节会详细地讨论针对各个业务场景而设计的领域模型。
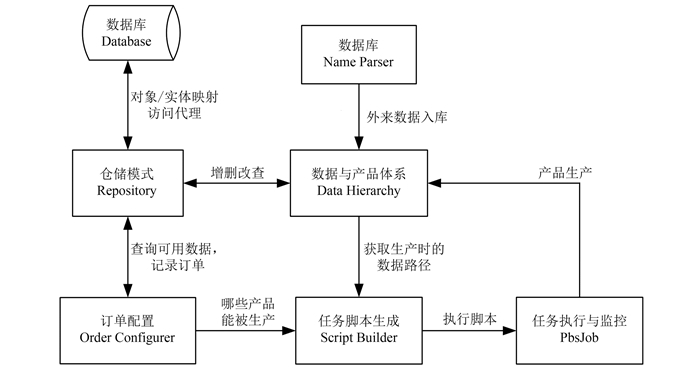

2.2 数据与产品体系
作为一个定量遥感产品生产系统,一个完备且具有统一行为模式的数据与产品体系是系统设计的基础。以本系统为例,涉及的数据一共分为4大类,分别为原始数据(raw data),标准产品(standard product),定量产品(quantitative product)和辅助数据(auxiliary data)。面对多样的数据和产品(统称为数据),最佳实践是能够用一致的方式对其进行操作(包括移动、备份、寻址、相应数据库记录的增删改查、元数据描述)。实际上,虽然这些数据的文件格式、文件数量与命名规范都不尽相同,但是归根结底他们都对应着存在于磁盘上的文件实体,这就成为了对其进行统一操作的出发点。本文将所有数据都抽象为数据实体(DataEntity),其中标准产品,定量产品和辅助数据根据不同的类别又被派生为具体的子类。在共同的基类DataEntity中定义数据操作公用的接口,并且把所有通用的操作统一实现,而特定类别的数据所独有的操作方式则在各自的子类中个别定义。图 2展示了数据体系的继承关系。
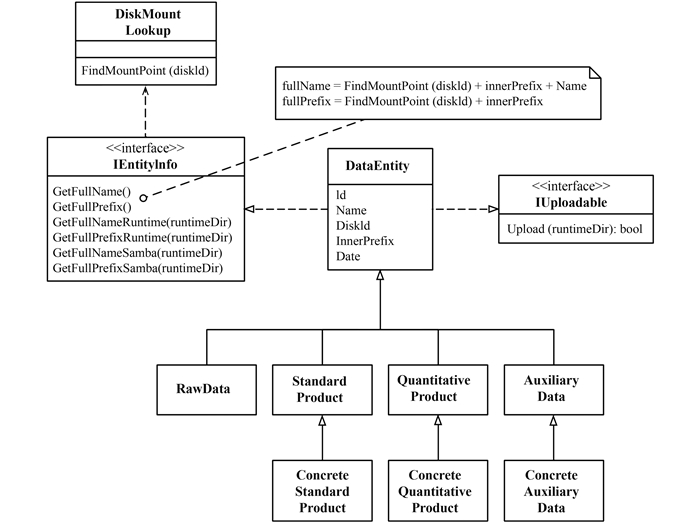
海量定量遥感产品生产所涉及的数据规模一般都很大,例如本系统运行期间每天都可能产出TB级的数据,长期运行就会累积PB级的数据。因此如下3个问题必须被考虑:(1)数据会散布在不同磁盘上,磁盘随时可能增减;(2)计算平台和数据存储分离,数据要先从各自所在的磁盘上传到计算平台才能参与计算。(3)产品计算完成后要回传到指定的磁盘归档。这些都要求数据路径和磁盘的映射关系要足够灵活且动态更新。
为了应对这一需求,提炼出了两个重要的接口IEntityInfo和IUploadable. IUploadable接口定义了数据上传的方法,遵循了设计模式中的组合模式(Composite,Gamma等,1994),继承自DataEntity 的单个数据实体天然地继承了基类的Upload方法,产品生产过程中涉及的各种数据原料的集合(ConcretePlan类)也要实现IUploadable接口,其Upload方法内部调用了每一个所属的DataEntity的Upload方法,使得个体与集合都遵循相同的行为模式,便于开发人员无差别地调用。
IEntityInfo接口定义了每一个数据实体的3种动态路径,所谓动态表示该路径不是固定的,会根据磁盘挂载点和其他相关配置文件的变化而做出相应的变化。
第1个路径是数据在存储平台的本地路径,该路径由3部分连接而成:所在磁盘当前的挂载目录(可变),系统内部的存储目录(InnerPrefix),数据文件名或文件夹名(一个数据包含多个子文件)。在每一块磁盘上的系统内部存储目录结构都是统一的,它是按照数据类型和数据日期逐级组织的,具体到天为止。InnerPrefix是根据数据类型和日期自动生成的,作为属性记录在DataEntity对象和数据库中。
第2个路径是数据上传之后在计算平台的本地路径,这一路径是从计算节点来看数据所在的路径,是将要被写入生产脚本中的路径。每一个订单都会在计算平台上开辟一个独立的运行时间文件夹(RuntimeDir),订单相关的所有数据原料都会被拷贝到此文件夹下,因此该路径是由运行时间文件夹的路径加上数据文件名组成的。
第3个路径是从存储平台来看数据在计算平台上的远程路径,这个路径和第2个路径实际上指向的是同一个位置,只不过是从存储平台来看的远程路径,而非计算平台本地路径。根据远程链接方式的不同,该路径的具体组成也不相同,但大致上都是由以下3部分组成:计算节点的IP地址,运行时文件夹路径,数据文件名。该路径是数据上传下载时使用的路径。
实现IEntityInfo接口意味着提供了组合出这3种动态路径的方法。
DiskMountLookup:磁盘挂载点查询服务类,根据磁盘固定编号即时查找磁盘当前挂载目录。在存储平台上,每一块磁盘都有一个挂载点,即磁盘所对应的目录,考虑到磁盘的挂载点是允许即时变化的,所以系统提供了挂载点查询服务。DataEntity中只记录了数据所在磁盘的固定编号而不是磁盘所在的目录,因为无论磁盘是怎么挂载的,数据位于某一特定磁盘上的地址是不会改变的。
以上关于数据体系的领域模型确保了不同类型的数据所有相关操作的一致性,接口统一。
2.3 文件名解析
遥感定量产品都是具有时效性的,每一个数据文件在进入系统之前,都需要从文件名或者是文件的内容中解析出数据的日期(图 3)。从外部进入系统的数据可能是各类传感器的原始数据,各种辅助数据或者外来产品。一般来说从文件名中基本都可以获得数据的日期,但文件名中的日期信息可能不够精确,例如环境星原始数据的文件名中日期只精确到分钟,如果要获得精确到秒的日期则需要解压数据并读取其中的XML元数据文件。如果要从文件名中解析出日期信息,那么文件名的命名必须是标准的,满足一定规律的。各类原始数据和外来产品的文件名本身都满足一定的命名规范,但是为了排除一些意外的文件名,同时能够让系统更加智能地在纷繁的目录中识别出那些需要的文件,需要对文件名进行筛查,以保证文件名的规范性同时剔除同一目录下不相关的文件。
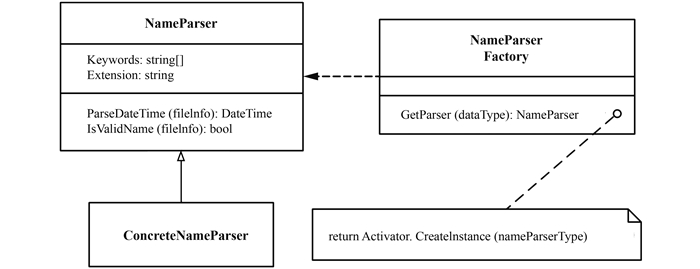
要进入系统的数据总共可能有几十上百种,每种数据文件的命名规则和内容结构一般都是不同的,因此每一类数据都需要专门的业务逻辑来完成其日期解析和文件名检查工作。既然已经抽象出了日期解析和文件名检查这两个共有的功能需求,很自然地将共有的方法提炼至基类,对于每一类具体的数据都派生出一个子类,重写覆盖基类的方法以实现专门的业务逻辑。这里采用基类而没有使用接口的原因是基类对于文件名检查提供了一个共用的实现,即通过检查关键词和文件后缀的方式来对文件名进行简单的验证。在创建子类对象的过程中,选择了简单工厂模式加反射的机制,这样可以避免过多的判断语句同时将选择生成哪一种子类的工作集中到一处。
NameParser:作为基类定义了日期解析和文件名检查两个功能函数的统一接口,并且为文件名检查提供了共用的简单实现版本。
ConcreteNameParser:针对某一类数据的具体文件名解析器类。每一类要进入系统的数据都要实现自己的文件名解析器类,提供专门的业务逻辑。日期解析函数不限于对文件名的解析,也可以深入文件内容,一切以满足需要的日期精度为标准。
NameParserFactory:文件名解析器工厂类,利用反射机制,通过数据类型在运行时动态的创建所需的ConcreteNameParser。
上述的领域模型可以使得编程人员只需要专注于业务逻辑的实现。每有一类新的数据,只需要实现相应的文件名解析器类即可。因为使用了工厂和反射机制,应用层的代码不需要进行任何改动即可自动兼容新的内容。这一领域模型同时也很自然的符合了现实生活中对象的交互方式以及编程人员的心智模型,能够有效解决实际需求。
2.4 数据库表的仓储模式
作为一个综合的定量遥感产品生产系统,而且要实现日常在线生产,不可避免地涉及数据库的使用和维护。从领域模型的角度来看,数据库是领域对象的主要入口和出口。领域对象可以来自对数据库的对象关系映射ORM(Object Relational Mapping)将关系数据库的记录包装成类的对象实体(Barry和Stanienda,1998; O'Neil,2008),有的领域对象也需要被持久化到数据库中去。Repository模式是领域驱动设计中所推荐的一种与数据库交互的模式。该模式封装了存储,读取和查找的逻辑,主要的好处是将领域模型从应用层代码和数据访问层之间解耦出来,开发人员无需了解底层的数据库细节,通过Repository类提供的接口可以直接进行数据操作,就像是在操作内存中的一个对象集合一样。原则上每一个Repository 负责一张数据库表。
Repository模式是让开发人员聚焦于领域模型而不是零散的功能代码的天然约束,因为如果你从数据库中拿到的就是一个个封装好的领域对象,那么你对这些对象的操作必然就是建立在领域模型之上的。本系统也设计并实现了一套有针对性的Repository模式,如图 4所示。

Session:数据库会话类,是对数据库连接的进一步封装,提供了缓存和延迟加载等高级功能。提供了统一的基础增删改查操作接口。对数据库表的所有操作原则上都要通过Session来实现。
SessionFactory:数据库会话工厂类,主要的职责就是创建数据库会话,在内部维护一个数据库连接池。基本上所有的ORM框架(http://nhforge.org/)都会提供类似Seesion和SessionFactory的实现。
Repository<T>:泛型的仓储模式实现,T代表所要管理的对象的类型,也即指定了所要操作的数据库表,该类的实例负责相应的数据库表的基础增删改查操作。Repository<T>内部包含了对Session的创建和使用。
ProductRepository<T>:在Repository<T>的基础上,封装了专门为产品表和数据表定制的业务逻辑和查询方式,例如指定日期和网格的查询等。
TaskRepository<T>:在Repository<T>的基础上,封装了专门为各种任务表定制的业务逻辑和查询方式。例如统计各种状态的任务的数量等。
SpecificRepository:除了产品和任务,其他的领域模型也可能需要特殊的数据库操作,例如系统用户User,需要权限设置等操作,虽然这些操作都可以用Repository<T>所提供的基础功能来搭建,但是应用层代码会比较冗杂,因此可以专门实现一个UserRepository类,来封装对于User表特殊的业务逻辑。注意这里的SpecificRepository不代表具体的一个类,而是代表一系列类。
RepositoryPool:顾名思义,这个类是每一个Repository类的一个实例集合,是一系列全局静态对象集合。常规的Repository模式在使用时一般需要在本地代码创建相关的Repository实例,然后调用其方法。过于频繁的实例化各种Repository操作会使应用层代码非常冗余拖沓,因此这里将所有的Repository类在系统启动时统一实例化,并储存在全局范围,开发人员可以在代码的任何位置直接使用这些静态Repository对象,就像使用全局静态方法一样。这样一来应用层代码就会被大大简化,开发人员可以更加专注于应用层的业务逻辑,而不必担心与数据库的交互。使用全局静态对象的一个风险是对象长时间驻留在内存中可能被损坏而且没有机会被重建,但因为Repository对象实际上只包含对方法的封装而没有维护任何属性和内部变量,所以基本不会有对象损坏的风险。
基于上述数据访问层模型,除了极为特殊的查询要求,系统开发人员不需要编写任何数据库访问和查询逻辑,也不需要写任何Structured Query Language(SQL)语句,所有数据库操作和各种查询逻辑都被封装在了相应的Repository类中,只需要在RepositoryPool中添加相关的Repository实例即可在全局范围访问数据库,得到包装好的领域模型对象。只有灵活便捷的数据访问层,才能培养不同水平的开发人员主动使用领域模型而不是随意堆积功能代码的习惯。
2.5 任务脚本生成
分布式系统所要执行的任务,一般都是通过一个任务脚本或者类似的概念来描述的。本系统的分布式任务管理是基于PBS(Portable Batch System)的(Feitelson等,2005; Henderson,1995),因此每个生产任务的具体流程都是通过PBS脚本来描述的。这就要求系统具有一套自动且灵活的PBS脚本生成体系。
PBS脚本主要包含两部分,头部(Head)需要用指定的格式写明任务调度相关的信息和对计算资源的需求,例如shell类型(一般是bash,Bourne,1978; Burtch,2004),任务名称,标准输出文件地址,标准错误文件地址,任务队列,任务需求的虚拟处理器数量,内存需求等。正文(Body)则是任务的内容,格式就是普通的shell脚本。另外为了系统集成的需要,增加了结尾(Foot)部分,其内容也是shell语句,但提供了对程序完成时间以及其他指定信息的采集。
本系统涉及的数据预处理和共性定量产品生产流程总共有上百种,生成这些流程脚本的Head和Foot部分的业务逻辑是相同的,只是参数有区别,因此将共有的业务逻辑封装成基类,如图 5所示。每种脚本的Body部分有很大差别,这一部分的生成工作被安排在相应的子类当中,各自实现。生成整个脚本的函数接口也在子类当中。
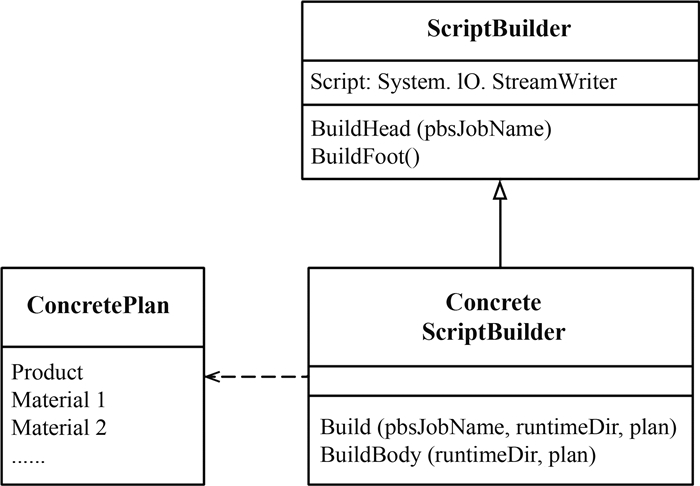
ScriptBuilder:脚本生成器的基类,封装了操作脚本文本的StreamWriter对象,并实现了生成Head和Foot部分的共用的业务逻辑。
ConcreteScriptBuilder:针对某一流程的专门脚本生成器类,实现了脚本Body部分的生成以及整个脚本的生成。Head和Foot部分的生成默认是在基类中实现的,也可以在子类中重写这两部分。
ConcretePlan:任务计划类,每一种生产流程都有专门的任务计划类,描述了该类生产任务的输入(数据和参数)和输出(产品)。任务计划类的对象集合了一次具体任务的所有输入和输出对象,是脚本生成函数的主要参数。
可以看到所有的ConcretePlan并没有一个统一的基类,这是因为不同的生产流程,无论是从文件数量,类别数量,类型等各个方面来看,其输入输出的差异很大。要是强行将其抽象,则会造成过度抽象,引入很大程度上的元数据依赖,并且会使得领域模型丧失现实意义,让程序员很难直观理解。更关键的是,算法输入输出的变动非常频繁,不完备的盲目抽象可能会引起重构的困难,难以灵活地应对可能的变化。因此选择保持模型适度的分散,便于应对各种复杂性。在这种领域模型下,每一个ConcretePlan类还可以被当成是用代码写成的严格的算法输入输出说明书,便于项目人员精确地理解算法需求,从实践上来看,这往往比算法文档清楚的多。每有一类新的流程,则需要实现相应的脚本生成器类。
2.6 订单配置
对于定量遥感产品生产任务来说,用户提交的订单需要提供3种主要信息:产品的类型、时间范围和空间范围。因为本系统生产的大多是合成产品,瞬时产品较少,而且瞬时产品也可以被认为是时间窗非常短的合成产品,所以采用时间窗这一概念来刻画每个产品所覆盖的时间范围。以10天合成产品为例,时间窗的长度是10天,每一年的时间窗总数和每个时间窗的起止日期是确定的,即从每年的第一天开始每10天为一个时间窗,最后不足10天的也算一个时间窗,时间窗不跨年。因为产品是要被分幅的,所以每个产品所覆盖的空间范围依照惯例可以用网格来描述,全球被划分为若干个标准网格,每个产品都会对应某一个网格。从以上的说明可以看出,每一个产品都对应着一个固定的网格和一个固定的时间窗。
本系统是按需生产,即订单驱动。用户提交订单时,除了选择产品类型,还要指定需要哪一段时间内的哪些网格内的产品。系统接到订单,首先就要对订单进行分解,确定哪些产品是要被生产的,也即是要确定用户指定的时间范围内包含了哪些时间窗,以及用户指定了哪些网格。确定了产品之后,接下来要根据系统内现存的数据资源,分析每一个产品能不能被生产以及选择生产的流程。这里采用了最简单的解决方案,即对于每一种可能的生产流程,通过排查数据库中所需的数据是否全部存来判断能否进行生产。以上这些关于订单的操作统称为对订单的配置。每一类产品的订单都需要经过类似的配置过程,抽象过程用如图 6所示的领域模型。
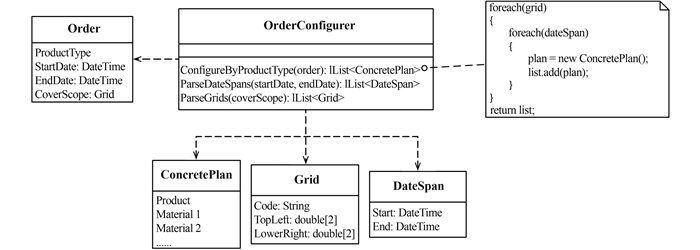
Grid:网格类,表示数据对应的空间范围。根据产品空间分辨率的不同有两套预留的全球标准分幅网格。标准网格具有网格编码,例如H35V17,H20V15。
DateSpan:时间窗类,表示产品所覆盖的时间范围。一旦时间窗的长度被指定,那么每年内时间窗的数量和起止日期就确定了,时间窗不跨年。
Order:产品订单类,充血模型。表示用户提交的订单,会被持久化在数据库中。与产品生产相关的属性有产品类型,所需求产品的时间和空间范围。
OrderConfigurer:订单配置服务类,这是一个服务类而不是一个实体类,实现了配置每一类产品订单的业务逻辑,其中的方法都是静态方法。提供了从订单中分解出所有Grid和DateSpan的公用函数。
ConcretePlan:任务计划类,即一次生产任务的输入输出的集合类,每一类产品都有专门的ConcretePlan类。ConcretePlan记录了每一个产品生产所需要的所有信息,包括从数据库中搜索到的可用的各类输入数据,输出的产品,生产算法需要的参数等等。订单配置最终返回的就是一系列的ConcretePlan。
2.7 任务执行与监控
不同的分布式系统下执行算法任务,在概念上都存在如下几个过程:任务脚本的构建,任务的提交,任务执行状态的监控,任务结果的返回。可以观察到这些过程都是围绕这一项具体任务展开的,因此需要将任务抽象出来,在其之上构建相关的功能接口。本系统基于Torque PBS(http://www.adaptivecomputing.com/products/open-source/torque/)来进行任务调度,先将一般的PBS任务进行抽象成为PbsJob类,PbsJob封装了一般的PBS任务执行所需要属性和方法,比如脚本的地址,PBS任务的编号,以及之前提到的对任务的各种基本操作。
定量遥感产品的生产任务相比一般PBS任务来说,需要关注额外的几个方面,首先每一个任务在数据库中可能是需要有相应的记录,任务状态的改变,比如任务成功,失败,超时等,需要在数据库中及时更新。所以在PbsJob基础上派生的定量产品生产任务类PbsJob_QP需要维护一个任务记录类(Task)的对象,用来跟踪数据库内的任务记录。本领域模型中的Task指的是数据库层面的任务记录,而Job则指的是在分布式计算系统中执行的PBS任务。其次是生产任务的结果不光体现在返回的文本信息上,需要的是磁盘上的产品文件,PbsJob_QP需要知道自己生产出来的产品是什么,在哪里,还需要负责将生产完成的产品拷贝到存储服务器上并在数据库中相应的表里增加一条产品记录。因此PbsJob_QP需要维护一个产品类(Product)的对象(详见2.2节)。系统的计算资源和存储资源经常是分开的,所以PbsJob_QP还需要负责将原料数据上传到计算节点上。这就要求PbsJob_QP 包含所有相关原料数据对象的引用,其类型是IUploadable(详见2.2节),即实现了底层的数据上传业务逻辑。
对于任务状态的监控,选择了常规的轮询策略,即每隔一段时间就查询一次当前任务状态,直至侦测到任务完成为止。轮询显然应该被实现为一个异步操作,需要后台线程来完成。创建的PbsJobResult 枚举表示任务可能出现的若干种完成状态,是对已完成任务状态的细分,例如成功,运行失败,超时等。
另外一个PbsJob_QP只代表生产一个产品的原始任务,要实现多级产品的级联生产,则需要应用层代码对多个PbsJob_QP进行必要的排布和组合。
实现时,用PbsJob_QP中的AsyncRun()函数封装一个任务全部的执行流程,包括任务的提交,在任务执行的过程中不断地监控任务状态,判断任务成功或失败,生产成功之后进行产品下载和数据库更新等等,而且是异步执行的。PBS任务脚本是在PbsJob_QP的构造函数中就被创建了,参数是订单配置之后得到的任务计划类(ConcretePlan)的实例。构造PbsJob_QP时的可选参数是Task,如果提供了一个Task类的实例,那么PbsJob_QP就会跟踪维护Task在数据库中的记录,否则这个PbsJob_QP就是一个临时任务,在数据库中没有相应的记录。
对于每一类具体产品的生产任务,将从PbsJob_QP 派生出了相应的类,这些类才是应用层代码真正会使用的类。例如生产30 m分辨率的植被指数VI产品的PBS任务类叫做PbsJob_VI30M。它在业务逻辑上完全继承了PbsJob_QP,只不过使用了更具体的Plan和Task类型,即Plan_VI30M和Task_ VI30M,如图 7所示的相关领域模型描述如下。
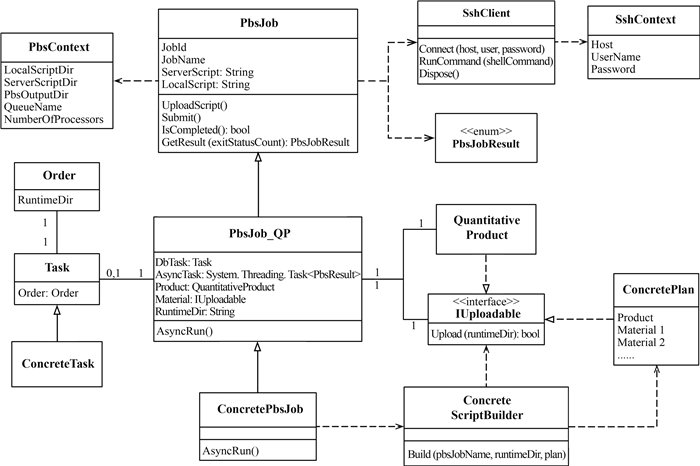
PbsJob:是对一般PBS任务的抽象,作为基类实现了一般PBS任务远程调度的基础方法体系,包含PBS脚本的上传、任务脚本的提交、任务状态的监控以及任务结果的返回等。特别强调此类是一般PBS任务的抽象,并没有涉及产品生产任务的概念。
PbsJob_QP:是对产品生产PBS任务的抽象,在PbsJob的基础上增加了产品生产任务所额外关注的属性和业务逻辑。其AsyncRun()方法整合了一个生产任务的全部流程,且提供了异步的实现。可以认为此类是一种抽象类,因为它只提供了共性的业务逻辑,还没有涉及具体的产品类型。
ConcretePbsJob:具体到某一类产品生产的PBS任务的抽象,在PbsJob_QP的基础上使用了与产品类别相应的ConcretePlan,ConcreteTask和ConcreteProduct。每一类生产任务都有一个ConcretePbsJob的实现,这才是应用层代码真正使用到的生产任务类。
PbsContext:静态类,集中了所有与分布式系统PBS相关的配置信息,比如主控节点上存放PBS任务标准输出和标准错误文本的位置,PBS脚本存放的位置,PBS任务的队列名称,任务需求的虚拟内核数量等。每次读取属性时都会重新读取配置文件,所以支持配置信息的即时修改。如果不使用PBS则此类的内容则为所采用的分布式系统的各类配置信息。
SshContext:静态类,集中了所有与SSH连接相关的配置信息,主要是主控节点的IP地址以及所使用的用户名和密码。Context这种模式也是领域驱动设计中所推荐的,将相关的背景信息整合在一处,便于使用和更新。
SshClient:封装了一个SSH连接,支持远程SSH命令的调用与结果(标准输出与标准错误)的返回。PbsJob的各类操作中与主控节点的通信都是通过SshClient完成的。SshClient可以从第三方的SSH库中得到,一般不需要自己实现。如若使用其他的远程连接方式,则也可以依照此类构建相应的类。
PbsJobResult:PbsJob完成状态的枚举类,是对已经完成的任务的状态的进一步细分,包括成功,运行失败,超时,数据上传失败,下数据载失败。
Task:任务记录类,是生产任务在数据库中的记录,根据产品类型的不同又被派生为更具体的ConcreteTask。逻辑上一个订单可以包含许多Task。对于Order和Task的对应关系,选择让每个Task都维护一个自己所属的Order的引用,而不是在Order中维护一个Task的集合。这是因为Task是可以和PbsJob_QP一一对应的,在使用时通过和PbsJob_QP相对应的Task来调用Order而不是通过Order来查找Task。这样会节省很多集合索引操作并且更贴近模型的现实意义,即一个Task记录了相应的PbsJob_QP。
3 系统实例
依照本领域模型,实现了一个完整的多源数据协同定量遥感产品生产系统。该领域模型自始至终指导着本系统的实现,用一种统一的方式解决了多源遥感数据协同生产中的各环节的问题,并大大简化了各类生产流程的集成。
3.1 多源数据协同定量遥感产品生产系统
本系统是一个较完整的产品生产系统,包含了数据管理,产品生产,订单管理,元数据管理等主要功能。主要子系统的功能如下:
(1)数据管理:维护数据库记录与所有存储磁盘上的数据文件实体之间的一致性。提供数据按时间和空间范围的查询。提供数据备份和下载。
(2)产品生产:各类原始数据的预处理,包括几何校正,大气校正,辐射校正,标准分幅。多种源数据协同生产各类定量遥感产品。产品生产是订单驱动的,系统根据订单指定的产品类型和空间时间范围,自动生产所有能够生产的产品。
(3)订单管理:维护订单的数据库记录,订单查询,订单内每个子产品生产情况的跟踪。
(4)元数据管理:维护关于系统的所有配置信息,例如数据库配置,远程连接配置,高性能计算平台配置,各类算法的版本,参数设置等。
该系统的最大特点在于多源数据协同使用,在生产某一分辨率下的产品时,具有相近分辨率的传感器平台的源数据都会参与生产。本系统的产品是分层级的,有些高级产品需要用另外一些低级产品当做输入数据。当用户需要高级产品时,相应的低级产品会被自动生产。
目前该系统已经完成了几千景产品的生产,并且新算法还在不断地集成到系统当中。本文提出的领域模型持续展示出对各种不同数据源的数据和不同生产流程的兼容能力,可以不加修改的支持各种数据的协同使用。部分产品的数据协同使用具体情况见表 1。可以观察到基本上每种产品都会协同使用到多种源数据或者辅助数据。
表 1 部分产品的数据协同使用情况
Table 1 Data synergy of different categories of products
| 产品名称 | 产品层级 | 协同使用的源数据种类 | 使用到的辅助数据种类 | 平均每景处理时间/min |
| 1 km 植被覆盖率 | 2 | 3 | 3 | 7 |
| 1 km 叶面积指数 | 1 | 3 | 5 | 5 |
| 1 km 植被指数 | 1 | 3 | 5 | 2 |
| 1 km 气溶胶光学厚度 | 1 | 1 | 2 | 11 |
| 30 m 叶面积指数 | 1 | 6 | 0 | 8 |
| 30 m 植被指数 | 1 | 6 | 0 | 3 |
| 30 m 气溶胶光学厚度 | 1 | 1 | 0 | 18 |
在系统设计的过程中尽量维持了很简洁的软件环境,系统统一使用C#.NET 4.0实现,数据库使用了Mysql5.6。超算平台部署了Torque PBS在节点间进行任务调度。这种极简的软件环境保证了系统移植的简单快捷。目前硬件环境中超算平台包含了60个节点,每个节点有24 GB的内存和12个CPU。存储直接部署在30 TB的磁盘阵列上。
3.2 新产品集成的简化
该领域模型对多源数据协同生产的各个环节都进行了合理的抽象,提炼并封装了核心的业务逻辑。因此新产品生产流程集成到系统中时,可以节省非常多的代码量。在各个环节的核心业务逻辑都已经被抽象并且封装的基础上,集成人员的思路将会变得十分清晰,不需要再考虑基础设施层的实现细节,可以专注于应用层的逻辑。并且应用层的代码也只是将领域模型提供的接口函数进行简单的堆砌即可。这样的设计还有一个好处是对系统不了解的开发人员也可以迅速的掌握系统的维护和开发。
下面从各个具体的环节说明新产品集成过程是如何简化的。
新产品数据实体的定义:直接继承Quantatitive Product类即可,无需其他代码。
相关新数据原料的定义:直接继承RawData,St and ardProduct或者AuxiliatyData类即可,无需其他代码。
相关新数据库表的增删改查操作:直接创建泛型类Repository<T>系列的实例并调用其接口函数即可,无需其他代码和SQL查询语句的编写。
相关新数据文件名的解析:继承NameParser 类,填充其中的Keywords和Extension属性和ParseDateTime()方法。应用层代码通过反射调用,无需增加逻辑分支。
新产品生产任务数据库记录类的定义:直接继承Task类即可,无需其他代码。
新产品生产脚本的编写:继承ScriptBuilder 类,填充其中的BuildBody()和Buid()方法。
新产品生产任务类的定义:继承PbsJob_QP 类,根据具体的任务情况编写其构造函数,接受相应的输入并调用相应的ScriptBuilder。其他功能直接继承自基类即可,无需其他实现。
新产品订单的配置:在OrderConfigurer中新增一个相应的函数。
可以看出,新产品生产流程的集成基本都是通过直接继承领域模型中现有的基类实现的,绝大多数核心业务逻辑都已经被封装并且以一种统一的方式被复用,因此可以大大减少集成中的工作量,并且集成的思路十分简洁明了,在各个环节的实现中,需要什么就通过继承得到一个相应的类即可。
软件工程领域一般通过代码量和需要实现的功能点来衡量工作量的多少。图 8和图 9就分别展示了在集成某些产品时原始实现和使用本领域模型带来的工作量的差异。


4 结 论
由于多源遥感数据在存储格式,文件命名,文件数量等各方面都存在一定的差异;以及较多的产品种类及其生产流程,多源数据协同定量遥感产品生产系统的设计亟需一种统一的抽象来减少系统各个环节中冗余繁复的逻辑。
本文基于系统开发实践过程中不断的重构,提出了一套领域模型,用一种统一的方式解决多源数据协同生产中各个环节中的问题。基于本领域模型实现的生产系统,成功支持了几十种数据的协同使用和几十种不同层级的定量产品的生产。并且在新生产流程的集成过程中展示出了良好的兼容性和灵活性。由于本领域模型对生产的各个环节都进行了合理的抽象,提炼并封装了核心的业务逻辑。因此可以大大减少产品集成时的代码量,并帮助集成人员厘清思路,减少系统错误可能。
领域模型的价值在于复用。未来,越来越多的多源数据协同定量遥感产品生产系统将会出现,本领域模型作为比较早且较为成熟的一次尝试,为将来系统开发工作提供更高的起点。本领域模型解决了系统设计中的一些共性问题,也可以为其他领域的系统提供参考。
领域模型是需要通过持续不断地迭代进行精炼,还将继续对该领域模型进行维护,争取得到更加精炼灵活的领域模型。还要实现生产流程的嵌套和组合,以支持任意复杂的生产流程。
参考文献
-
Agrawal A, Karsai G and Ledeczi A. 2003. An end-to-end domain-driven software development framework//Proceedings of the Companion of the 18th annual ACM SIGPLAN Conference on Object-oriented Programming, Systems, Languages, and Applications. New York:ACM:8-15[DOI:10.1145/949344.949347]
-
Balasubramanian K, Gokhale A, Karsai G, Sztipanovits J and Neema S. 2006. Developing applications using model-driven design environments. Computer, 39(2):33-40[DOI:10.1109/MC.2006.54]
-
Barry D and Stanienda T. 1998. Solving the Java object storage problem. Computer, 31(11):33-40[DOI:10.1109/2.730734]
-
Bourne S R. 1978. UNIX time-sharing system:the UNIX shell. The Bell System Technical Journal, 57(6):1971-1990[DOI:10.1002/j.1538-7305.1978.tb02139.x]
-
Bricaud A, Bosc E and Antoine D. 2002. Algal biomass and sea surface temperature in the Mediterranean basin:intercomparison of data from various satellite sensors, and implications for primary production estimates. Remote Sensing of Environment, 81(2-3):163-178[DOI:10.1016/S0034-4257(01)00335-2]
-
Burtch K O. 2004. Linux Shell Scripting with Bash. Indianapolis:Pearson Higher Education
-
Buschmann F, Henney K and Schmidt D C. 2007. Past, present, and future trends in software patterns. IEEE Software, 24(4):31-37[DOI:10.1109/MS.2007.115]
-
Evans E. 2004. Domain-Driven Design:Tackling Complexity in the Heart of Software.[s.l.]:Addison-Wesley Professional
-
Feitelson D G, Rudolph L and Schwiegelshohn U. 2005. Parallel job scheduling-a status report//Feitelson D G, Rudolph L and Schwiegelshohn U, eds. Job Scheduling Strategies for Parallel Processing. Berlin Heidelberg:Springer:1-16[DOI:10.1007/11407522_1]
-
Gamma E, Helm R, Johnson R and Vlissides J. 1994. Design Patterns:Elements of Reusable Object-Oriented Software.[s.l.]:Pearson Education
-
Gao S, Niu Z, Huang N and Hou X H. 2013. Estimating the leaf area index, height and biomass of maize using HJ-1 and RADARSAT-2. International Journal of Applied Earth Observation and Geoinformation, 24:1-8[DOI:10.1016/j.jag.2013.02.002]
-
Henderson R L. 1995. Job scheduling under the portable batch system//Feitelson D G and Rudolph L, eds. Job Scheduling Strategies for Parallel Processing. Berlin Heidelberg:Springer:279-294[DOI:10.1007/3-540-60153-8_34]
-
Landre E, Wesenberg H and Olmheim J. 2007. Agile enterprise software development using domain-driven design and test first//Proceedings of the Companion to the 22nd ACM SIGPLAN Conference on Object-oriented Programming Systems and Applications Companion. New York:ACM:983-993[DOI:10.1145/1297846.1297967]
-
Li H, Zeng Y N, Yun P D, Huang J B, Yang K and Zou J. 2007. Study on retrieval urban land surface temperature with multi-source remote sensing data. Journal of Remote Sensing, 11(6):891-898[DOI:10.11834/jrs.200706120](历华, 曾永年, 贠培东, 黄健柏, 杨凯, 邹杰. 2007. 利用多源遥感数据反演城市地表温度. 遥感学报, 11(6):891-898)[DOI:10.11834/jrs.200706120]
-
Nilsson J. 2006. Applying Domain-Driven Design and Patterns:With Examples in C# and.NET.[s.l.]:Pearson Education
-
O'Neil E J. 2008. Object/relational mapping 2008:hibernate and the entity data model(edm)//Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data. New York:ACM:1351-1356[DOI:10.1145/1376616.1376773]
-
Soudani K, François C, Le Maire G, Le Dantec V and Dufrêne E. 2006. Comparative analysis of IKONOS, SPOT, and ETM+ data for leaf area index estimation in temperate coniferous and deciduous forest stands. Remote Sensing of Environment, 102(1-2):161-175[DOI:10.1016/j.rse.2006.02.004]
-
Zhao W, Li A, Bian J H, Jin H A and Zhang Z J. 2014. A synergetic algorithm for mid-morning land surface soil and vegetation temperatures estimation using MSG-SEVIRI products and TERRA-MODIS products. Remote Sensing, 6(3):2213-2238[DOI:10. 3390/rs6032213]
-
Zhong B, Zhang Y H, Du T T, Yang A X, Lv W B and Liu Q H. 2014. Cross-calibration of HJ-1/CCD over a desert site using Landsat ETM imagery and ASTER GDEM product. IEEE Transactions on Geoscience and Remote Sensing, 52(11):7247-7263[DOI:10. 1109/TGRS.2014.2310233]


