



通常,搜索引擎会将用户查询的网页,按照某种算法排序,并返回给用户. 搜索引擎的排序算法涉及商业机密,往往不予公开, 但是大多数搜索引擎排序算法依然是基于TF-IDF,PageRank等经典算法. 据调查,有75%的用户只查看搜索引擎返回结果的第1页. 尤其对商业网站来说,点击往往意味着交易, 因此他们更是设法让自己的网页出现在搜索结果靠前的位置, 从而获得更多商机. 在商业利益驱使下,页面作弊行为层出不穷, 愈演愈烈. 所谓搜索引擎排序作弊, 是指页面使用各种手段欺骗搜索引擎排序算法, 从而获得比应得排名更加靠前的位置[1]. Henzinger等[2]早在2002年就曾指出, 搜索引擎排序作弊是搜索引擎将要面对的主要挑战之一.
作弊手段分为内容作弊(content spam),链接作弊(link spam)等形式. 搜索引擎优化与排序作弊的界限较为模糊,过度的优化常会被认为是作弊. 因此,本文提出搜索引擎作弊倾向系数,任何网页都具有作弊倾向, 该系数越大,作弊嫌疑就越大,反之亦然. 在此基础上, 从文本内容和链接结构分析的视角,提出识别搜索引擎排序作弊的方法.
论文组织结构是: 第1节针对不同的作弊方式, 对作弊技术及其检测方法进行文献综述; 第2节提出了作弊倾向系数算法; 第3节通过2个实验,验证所提方法的有效性; 第4节是结论和展望.
1 相关文献综述 1.1 搜索引擎内容作弊及检测技术内容作弊通过修改网页的文本内容来提高页面与特定查询的相关性. 内容作弊主要有3种: ①关键词堆砌,②虚假关键词,③内容工厂. 内容作弊网页在文本语义及文字词频统计特征等方面与正常网页会有所差别.
针对内容作弊的特征, Westbrook等[3]通过自然语言处理来识别内容作弊网页. 建立网页分析器,对语句的平均长度,停用词频度等网页特征进行统计, 将网页分析器与决策树分类器结合起来判断网页是否作弊. 贾志洋等[4]利用网站内容的作弊特征构建检测模型, 帮助搜索引擎识别垃圾网页. 使用SVM技术,根据网站的内容来识别欺骗性网页也是一个可行的方法[5].
有研究者应用统计方法检测页面内容,认为当某些词出现频率大于阈值时, 则该页面具有内容作弊嫌疑,[6]. 李俊[7]通过页面相似性分析来识别内容作弊. 在搜索引擎抓取网页的时候, 若同一域名下具有多个相似或完全相同的页面, 就判定这些页面属于内容作弊. 何秀等[8]研究了用户的搜索在特定搜索上下文中对搜索行为的影响, 提出查询上下文影响权重最大,用户上下文次之,页面上下文的影响最小. 董乐等[9]在计算文档相似度时除了考虑查询词与短摘要的相似度外, 还融合了URL信息. Jia[10]使用一种反欺骗的爬虫程序检测网页作弊, 这个程序是基于信息主题实现的. Zhao等[11]提出了一种根据网页内容自动抽取网页关键词的算法, 并把该算法应用于搜索引擎优化.
Najork[12]提出收集用户感知的策略, 并通过一定的方式反馈给搜索引擎, 搜索引擎根据用户反馈结果来判断是否存在隐藏内容作弊. 针对页面重定向的作弊行为,微软提出了Strider系统[13], 它通过分析网页的重定向行为来检测作弊页面. Wu等[14]通过比较同一个网页不同版本差异进行内容作弊的检测: 对每个URL,同时抓取其对应网页的3个版本C1,C2和B1. 其中C1, C2使用两个独立的Web爬虫抓取,B1 是以浏览器形式抓取的. 然后计算C1, C2间的差异记为NCC,计算B1和C1间的差异记为NBC. 如果NBC大于NCC, 则认为该网页可能是内容伪装. 王暾[15]对网站重定向技术进行对比, 发现JavaScript重定向技术对垃圾识别系统有显著作用. Mavridis等[16]从语意角度对提高搜索引擎排名提出了建议, 但该方法游走于黑帽SEO与白帽SEO之间. Zhang等[17]除了根据传统的网页内容和链接外,还考虑更新时间、 网页权威性等,使网页排序结果有明显提升.
1.2 搜索引擎链接作弊及检测技术链接作弊是针对基于链接排序算法(PageRank,HITS等)的作弊手段. 作弊网站会刻意制造一些链接结构,以迷惑搜索引擎. 链接作弊的方式繁多,如交换链接、蜜罐、链接工厂、锚文本链接等. 针对这类行为的反作弊研究,学者们提出了两种解决思路: 基于白名单的方法和基于黑名单的方法.
Gyongyi等[18]提出的TrustRank算法是采用白名单方法的代表, 其思想是: 好的网站很少会链接到坏的网站; 反之则不成立, 即很多垃圾网站会链接到权威、高信任度的网站, 以试图提高自己的信任度. TrustRank算法的步骤是: 挑选一批种子网站, 将这些网站的TrustRank初始值设为1,其余网站设为0. 然后采用平均分配的方式传播TrustRank值, 最后根据页面的TrustRank值对网站排名. 改进的算法认为可以通过比较PageRank和TrustRank值的差异来识别链接作弊行为[1]. Caverlee等[19]提出链接可靠度的概念以及将页面质量跟链接质量分离的观点. 实验表明,该算法较PageRank和TrustRank具有更强的反作弊性能. Du等[20]对TrustRank算法进行了拓展, 使其在检测链接工厂这类作弊方式的时候具有显著效果. 另外, TSPageRank也是对PageRank的有效改进[21]. Liu等[22]根据用户在网页上的停留时间, 提出一种改进的PageRank算法,并证明了该算法的有效性. 王德广等[23]基于用户满意度提出了类似的PageRank改进算法. 鉴于迭代计算PageRank速度缓慢,Duong等[24]提出一种并行PageRank 计算方法(GPU),实验证明该方法比传统方法速度提升了10$\sim$20 倍.
Sobek[25]提出的BadRank算法是通过黑名单页面进行反作弊的代表, 其核心思路是将链接指向低质量作弊页面的页面要受到惩罚. Liang等[26]为BadRank算法所采用的初始值进行各种尝试, 通过该算法赋予的初始值,能够较准确地找出潜在的作弊页面. Caverlee等[19]基于初始黑名单页面,对每条链接进行评估, 提出基于链接可靠度的半自动排序算法. 实验表明, 该算法较PageRank和TrustRank具有更强的反作弊性能. Saraswathi等[28, 29]提出基于SVMLight的链接工厂检测工具, 构造了一个链接工厂作弊分类器.
1.3 研究评述目前,搜索引擎广泛采用传统的TF-IDF,PageRank,HITS等算法, 衡量网页与用户请求的相关性,并以此为据排序. 各种针对上述算法的作弊手段也就应运而生,如链接作弊、内容作弊、 非法重定向等. 为此,学者们采用自然语言分析、机器学习、 统计学等方法,对作弊网页进行检测,并取得了一定成效. 但是, 作弊页面采用的手段具有多样性、隐蔽性、复合性等特点, 针对某一种作弊方式的反作弊手段面对海量页面时难以取得良好成效. 因此, 综合考虑网页内容及链接特征的反作弊比单独考虑基于内容或链接的反作弊措施更为有效.
传统的基于内容的反作弊策略大都依据网页的关键词分析, 例如计算关键词词频,检测堆砌关键词,关键词与网页内容的相关度等. 这些方法在实际应用中面临以下两个问题: 一是算法复杂性问题, 二是作弊者往往会混合使用多种作弊方式,单纯的关键词策略很难检测. 因而基于关键词的反作弊措施往往实际效果有限, 本文拟从统计角度解决该问题, 即基于绝大部分检索词词性都为名词的特征, 根据不同类型网站的名词比例,来计算网页的内容作弊倾向系数. 另外, 传统的基于链接的反作弊策略一般是通过黑名单迭代产生作弊系数, 但是在该迭代过程中没有考虑目标网站与黑名单网站的距离. 换句话说, 直接指向黑名单网站的网站才受到惩罚, 而间接指向黑名单网站的网站不受惩罚, 现实中作弊者很容易通过链接工厂产生大量间接链接,因而被作弊者利用. 鉴于此, 本文拓展该算法为同时考虑与黑名单页面链接距离来确定链接作弊倾向系数. 最后再综合内容作弊倾向系数和链接作弊倾向系数得出网页作弊倾向系数, 这比单一的反作弊策略更加有效.
2 作弊倾向系数排序算法 2.1 搜索引擎排序作弊行为定义作弊页面不同于垃圾或色情页面, 它是因为违反搜索引擎的排序规则而应受惩罚的页面. 虽然两者可能存在交集,但本质上并不能划上等号. 一些学者并不严格区分这些概念,例如, Caverlee等[19]采用通过识别含有色情词汇的网页地址来构建初始黑名单页面(作弊网页列表), 说明他们认为色情网站就是作弊网站. 事实上,两者是有本质区别的: 含有色情词汇的网站可能只是出售成人用品的商业网站或是关于成人教育的网站, 因此不能将这些页面全部视为作弊页面.
直观上讲, 搜索引擎排序作弊就是通过技术手段试图提高网页与搜索请求的相关性, 从而达到提高搜索排名的目的. 这种行为将导致用户花费更多的时间来查找所需的信息, 严重影响用户体验. 目前, 各大商业搜索引擎对作弊行为都有着各自的定义,但本质上还是比较一致. 通常,我们将存在下述行为的网站视为作弊: 凡是在页面源代码中任何位置,故意添加误导性关键词或重复性关键词, 不管这些关键词与页面内容是否相关,也不管这些关键词是否对用户可见, 均视为内容作弊; 人为地故意制造大量链接指向某一网址的行为或是包括欺骗性重定向、 镜像站点、隐藏链接等链接作弊技术的,均视为链接作弊; 同时, 有链接指向作弊网站的网站,需要负连带责任.
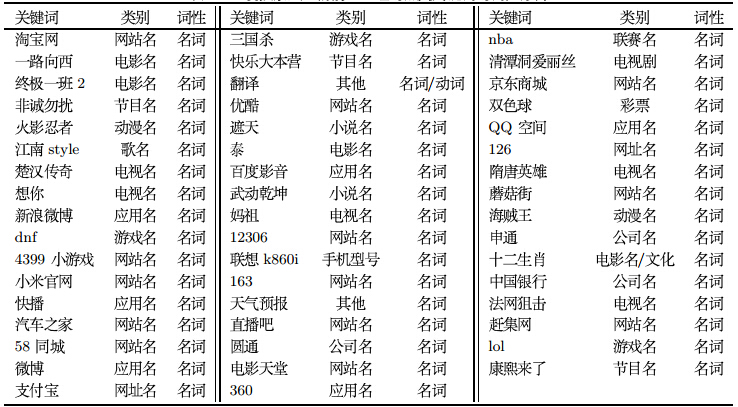
2.2 内容作弊倾向系数内容作弊表现为在页面中添加重复关键词以及误导性关键词, 所以关键字检测被视为识别内容作弊的突破口. 关键词涵盖范围广, 形式多样,很难通过构造关键词字典去匹配网页上的高频词汇进行识别. 通常, 作弊页面会根据搜索引擎的热门关键词来对页面的关键词进行动态调整, 从而获得更高的点击率. 为此, 本文对百度搜索风云榜上某段时间内的搜索指数前50名的热门关键词及其词性进行统计, 结果如表 1所示.
不难发现,热门关键词基本全部是名词. 为此, 本文假定内容作弊方式所添加的关键词也绝大部分为名词.自然地, 如果正常页面中的名词与其他词性词语的比例(称为关键词密度)为$a$, 在人为添加关键词之后,该比例为$b$,显然有$0 <a<b<1$. 当$a$ 与$b$相差越大,该页面的作弊可能性就越大. 同时,由于网站类型的差异, 不同类别网站的关键词密度不尽相同, 搜索引擎对不同网站或网页的关键词密度有不同的容忍度区间.
基于上述考虑,结合TF-IDF算法,对页面$p$而言, 本文提出页面内容作弊倾向(content spam tendency rate, CSTR)的计算公式,如公式(1).
| \begin{equation} {\rm{CSTR}}(p) = \left\{ {\begin{array}{*{20}{l}} 0,&{Prob(p) = 0}\\ {\frac{1}{{\delta \times {{(\log Prob(p))}^{\rm{2}}} + 1}}},&{0 < Prob(p) < 1}\\ 1,&{Prob(p) = 1} \end{array}} \right. \end{equation} | (1) |
 |
| 图 1 CSTR取值示意图 |
以网页http://edu.533.com/news/zytb/2008-5-30/4009.html(标题: 重庆2008高考招生计划出炉,七成考生可上大学)为例,共有407个词语, 其中名词90个,因此$\textit{Prob}$(p)=90/407=22.1%. 若网站管理员增加该页面与"高考"之间 的相关性,则会在网页的标题、 正文等位置添加诸如"上海高考" "北京高考" "浙江高考" "山东高考"等相关词汇.之后,搜索引擎会将这些词语分词为类似"上海" "高考"的关键词,因此关键词"高考"的频率将会增加, $\textit{Prob}$(p)值将会超过25%甚至更高. 因此, 通过统计网页中名词的比例,可以识别网页内容作弊.
2.3 链接作弊倾向系数链接作弊倾向系数(link spam tendency rate)是指页面存在链接作弊行为的可能性. 对于用户而言, 内容作弊比较直观,但是链接作弊就比较隐蔽. 而在搜索引擎的排序算法中, 基于链接的排序因子往往占据更大的权重,因此危害性更大.
对于给定网络G=P, L>$, 页面P=P$_{n}$ $\cup P$_{u}$ $\cup P$$_{b}$为所有网页的集合, 其中P$_{n}$代表普通网页(即经鉴别不存在作弊行为的正常页面); P$_{u}$代表未鉴别的网页; 而P$_{b}$ 代表黑名单网页(即经鉴别存在作弊行为, 作弊倾向系数较高的作弊页面). 事实上, 由于互联网过于庞大且新网页层出不穷, 因此无法标记每一个页面是否作弊, 只有少数网页是鉴别过的, 即: $|$P$_{n}$$|$$<<$$|$P$|$, $|$P$_{b}$$|$$<<$$|$P$|$. 1) 黑名单页面
正如PageRank算法将页面的链接行为视为投票行为, 相应的作弊手段就相当于出现拉票等违反秩序的行为, 最终造成票选排名有失公正. 对于这种行为,本文与百度有着类似的观点: 即将链接指向作弊页面(网站)的页面(网站),需要负连带责任[30]. 而作弊网站上链接指向的网站,不算作弊. 这是因为,对于一个页面而言, 它无法控制其链入链接(自返链接除外),也无法知晓链入链接页面的质量, 但是它可以控制其链出链接所指向的页面, 也可以清楚地了解或是调查其链出链接所指向页面的质量. 就好比投票过程中,无法控制别人对自己的投票, 但自己可以选择投票给谁.
鉴于上述考虑, 本文认为通过对作弊页面的链接分析是检测潜在作弊页面的有效方法. 初始黑名单里的网页是经鉴别确认存在作弊行为的页面, 因此仅占网页数量的极小比例, 如何通过少量的初始黑名单页面对其余的页面进行作弊倾向系数计算是算法的要点. 事实上,各大搜索引擎都拥有自己的黑名单, 因此基于黑名单页面的反作弊算法是切实可行的.
2) 链接作弊倾向系数
黑名单中页面的数量远小于所有页面的总数. 因此, 仅仅通过检测某个页面是否存在链出链接直接指向黑名单网页来衡量页面作弊倾向有欠妥当, 因为通过这种方式仅仅影响到作弊页面相邻的小规模页面, 而无法对整个网络进行有效评估. 以图 2的网络结构为例, 网页P$_{1}$为黑名单页面, 网页P$_{2}$和P$_{3}$都存在链出链接直接指向页面P$_{1}$, 因此P$_{2}$和P$_{3}$具有较高的链接作弊倾向. 若是认为黑名单页面的链出链接页面也属于作弊页面, 则网页P$_{4}$也将成为作弊页面, 事实上我们并无足够的证据证明P$_{4}$属于链接作弊, 而是仅仅存在一定的作弊可能性; 而若是不将具有较高链接作弊倾向的页面P$_{2}$和P$_{3}$加入黑名单页面集合, 那么页面P$_{4}$指向一个具有较高作弊倾向的页面P$_{2}$却不会受到任何惩罚, 这显然不合理. 因此,本文借鉴BadRank算法思想,从黑名单页面开始, 一个页面若是有链接指向可能存在作弊行为的页面(链接作弊倾向系数非0), 则该页面也将被认为存在一定的链接作弊倾向. 通过一定次数的迭代, 可以将链接作弊倾向系数在网络中传播扩散, 从而对连通网络中的所有页面进行链接作弊可能性的评估, 而不仅仅局限于初始黑名单页面的相邻页面.
 |
| 图 2 某网络结构图 |
给定网络图G=$<$P, L$>$, 页面${p}\in{P}$, 页面p的链接作弊倾向系数可由公式(2)计算.
| \begin{equation} {\rm LS}(p) = \tan {\rm{ }}sig\bigg((1 - d){\rm{E}}(p) + d\sum\limits_{i = 1}^n \frac{{{\rm{LS}}({q_i})}}{{{\rm{C}}({q_i})}}\bigg) \end{equation} | (2) |
| \begin{equation} \tan sig\left( x \right) = \frac{2}{{1 + {{\rm e}^{ - 2x}}}} - 1 \end{equation} | (3) |
以图 2为例,其中$p$$_{1}$$\in P_{b}$,LS(p) = $(LS(p_{1}), LS(p_{2}),LS(p_{3}),LS(p_{4}),LS(p_{5}))^{\rm T}$. 取阻尼系数${d}=0.85$,第1次迭代得LS(p) = $(0.15,0.425, 0.425,0,0)^{\rm T}$; 第2次迭代得LS(p) = $(0.632,0.064, 0.184,0.12,0)^{\rm T}$; 第3次迭代得LS(p) = $(0.376, 0.2686,0.338,0.02,0)^{\rm T}$. 经过10次迭代,算法收敛, 收敛后的作弊倾向为LS(p) = $(0.468,0.199,0.28,0.056, 0)^{\rm T}$.
通过公式(2)得到作弊倾向系数反映了页面作弊可能性, 但对于有链接直接指向黑名单页面的高作弊倾向页面却略显偏低. 以图1为例, 页面p$_{2}$将唯一的链出链接指向黑名单页面p$_{1}$, 因此p$_{2}$与p$_{1}$的关联度w(p$_{2}$, p$_{1}$) = 1, 但p$_{2}$链接作弊倾向系数LS(p$_{2}$)仅为0.199. 本文进一步考虑页面与初始黑名单页面的关联度, 并以此为依据来调整与初始黑名单页面有直接关联的页面的链接作弊倾向系数.
给定网络图G=$<$P,L$>$, 且p$\in$P,q$\in$P. w(p, q)为页面p与页面q的关联度. 如果p有链出链接指向q,则w(p, q)=1/$|$Out(p)$|$,否则,w(p, q)=0. 实际上,w(p, q)就是用户从网页p直接转移到网页q的概率. 由于p可能指向多个作弊页面, 因此p与作弊页面的关联度R(p)可由公式(4) 计算.
| \begin{equation} {\rm{R}}(p) = \left\{ \begin{array}{*{20}{l}} \sum\limits_{{q_i} \in {\rm{Out}}(p) \cap {P_b}} {w(p,{q_i})} ,&p \notin {P_b}\\ 1,&p \in {P_b} \end{array} \right. \end{equation} | (4) |
综合公式(2)和公式(4), 最终链接作弊倾向系数如公式(5).
| \begin{equation} {\rm{LSTR}}\left( p \right)= \alpha {\rm{LS}}\left( p \right) + \beta {\rm{R}}\left( p \right) \end{equation} | (5) |
综合公式(1),公式(5),有如下2种计算策略.
1)在考虑权重的情况下,页面p的作弊倾向系数可由公式(6)求得.
| \begin{equation} {\rm{STR}}\left( p \right){\rm{ }} = \lambda {\rm{CSTR}}\left( p \right) + \mu {\rm{LSTR}}\left( p \right) \end{equation} | (6) |
由于两方面的作弊倾向系数算法会存在准确度上的差异, 因此可以根据算法的信任度赋予不同权重,进而更有效地识别作弊页面.
2)从概率论的角度衡量页面p的作弊倾向系数, 可由公式(7)求得.
| \begin{equation} {\rm{STR}}\left( p \right){\rm{ }} = 1 - {\rm{ }}\left( {1 - {\rm{CSTR}}\left( p \right)} \right){\rm{ }}(1 - {\rm{LSTR}}\left( p \right)) \end{equation} | (7) |
由于0 $\leq$ CSTR(p) $\leq$ 1,0 $\leq$ LSTR(p) $\leq$ 1,因此STR$({p})\in[0, 1]$,且有MAX\{CSTR(p), LSTR(p)\}$\leq$ STR(p). 相对于公式(6), 公式(7)无需考虑二者权重.
公式(6), (7)中的两个因子(内容作弊倾向系数, 链接作弊倾向系数)可以独立设定阈值,如果某个作弊倾向系数大于阈值, 则视这个页面为作弊页面,因为一个页面只要采取了某种作弊方式, 那么这个页面就可以被视为作弊页面.
关于作弊倾向系数阈值T的选择上,可以采用以下方法: 已有研究表明整个web中约有10%$\sim$15%的页面为作弊页面[1]; 中文网页中也有10% 左右的网页是作弊网页[31], 因此选择排名约前10%的STR(p)作为作弊倾向系数的阈值, 作弊倾向系数大于T的网页均认为是作弊页面.
公式(6)和公式(7)描述的两种作弊检测算法本质上是两种不同的融合算法. 现实中,作弊者常常采用各种各样的作弊手段, 单一的作弊检测算法对于某一类别的作弊检测也许是有效的, 但是对于复杂的复合作弊方法,往往需要多种作弊检测算法才能有效识别, 因此凡是有助于提升作弊倾向识别的融合算法均可以用于作弊检测. 尽管如此,公式(6)和公式(7)还是有比较大的区别: 公式(6) 可以人工调整参数,而且对作弊行为的容忍度稍大; 而公式(7)不需要人工设置参数,但是对作弊行为更加严苛. 例如: 当CSTR(p)和LSTR(p)分别为0.7和0.5 时, 公式(6)的计算结果为[0.5,0.7] 之间(依$\lambda$和$\mu$取值而定); 而公式(7)的计算结果为0.85. 显然,由于后者是一种联合概率模型, 其作弊倾向系数值也更大. 在实际应用中, 应该根据需要选择合适的融合方法,一般来说公式(6)更加符合实际应用, 因为可以采用回归、机器学习、人工神经网络、 级联融合等方法确定每种算法的权重. 本文后续的实验中, 也采取了公式(6)的计算方法.
2.5 作弊惩罚策略对网页p而言, 1$-$STR(p)表示p为非作弊页面的可能性. 本文引入惩罚因子,其目的是降低作弊页面排名, 使其排名不高于其实际应得排名. 可以将作弊倾向系数作为惩罚因子, 那么p的最终排名如公式(8)所示.
| \begin{equation} {\rm{FR}}\left( p \right){\rm{ }} = {\rm{ FR}}'\left( p \right)*{\rm{ }}\left( {1 - {\rm{STR}}\left( p \right)} \right) \end{equation} | (8) |
百度公司认为: "作弊行为的定义是针对网站而不是网页的. 一个网站内即使只有一个网页作弊,该网站也被认为是有作弊行为"1. 由于是以网站为单位进行惩罚, 因此网站中所有页面的惩罚因子都是由其所属网站的作弊倾向系数决定的, 但是排序因子还是以网页为单位独立计算[30].
任何网站均由很多页面相互链接构成, 一个有作弊行为的网站既包含作弊页面也包含大量正常的页面, 单纯的按照平均值的方式来计算网站的作弊倾向系数并不合理. 我们采用网站作弊页面的比例来衡量网站作弊倾向系数, 具体来说, 令网站s=p$_{i}$}, $_{i}=1,2,\cdots,t$, 其中p$_{i}$为s包含的网页, STR$_{s}$=\{ p$_{1}$, p$_{2}$,$\cdots$, p$_{k}$表示作弊网页集合. 则网站作弊倾向系数FR(s)可由网站s下所有作弊网页p$_{i}$在网站s中所有页面的比例得到[21], 如公式(9)所示. 其中, t和k分别表示网站总页面数和作弊页面数. 作弊网页的比例越高, 网站的作弊倾向系数越大. 同样, 搜索引擎可以根据历史数据学习, 得到合适的网站作弊倾向系数阈值.
| \begin{equation} {\rm{FR}}\left( s \right) = \frac{k}{t} \end{equation} | (9) |
以搜狗实验室提供的用户检索日志为数据来源(见表 2),该数据库包含2006年8月份共20757462条搜狗搜索引擎的用户检索记录. 我们对该数据集进行检索词提取,词性标注,标注提取,统计分析等处理,目的是探究用户检索词的词性.

如表 2所示,字段1为用户ID,是根据用户使用浏览器访问搜索引擎时的Cookie信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户ID; 字段2为查询关键词,是用户输入的检索语句; 字段3分两部分,第一部分为检索结果中的排名,第二部分为用户点击的顺序号; 字段4即该URL的地址信息. 例如,用户输入检索关键字"清华电脑学堂",在该次查询中点击了4次链接来查找信息,依次点击的URL排名分别为1,4,5,7. 本次实验是探究用户检索词的词性,对于同一用户多次查询点击,只计1次关键词,例如表 2中关于"清华电脑学堂"的4条记录,预处理后,只保留1条"清华电脑学堂"记录. 对于其他用户输入的"清华电脑学堂"查询记录也保留1条记录,即对于一个用户ID保留唯一不重复查询词.
数据预处理之后,用户检索日志中的记录还剩9579065条,包含3041088条不同的查询,也就是本文检索词词性分析实验的素材.
本文采用北京大学汉语词性标记集(共39个词性标注),其词性标注记号如表 3所示.

以表 2最后一条记录为例进行处理说明: 第1步是提取检索词"新民晚报"; 第2步分词和词性标注后得到"新民/n晚报/n"; 第3步提取词性标注,得到"/n/n"; 第4步对词性标记结果进行统计.
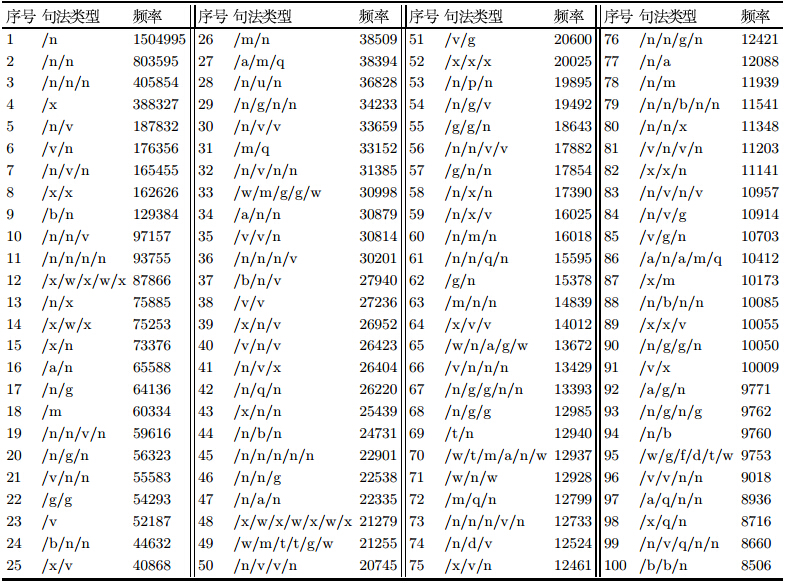
对全部的9579065条查询语句进行数据处理,共识别得到308681种不同的句法类型,表 4是出现频率前100的句法类型.
根据表 4所示的100个高频标记结果,按排名序号绘制折线图,如图 3所示. 不难看出,在高频句法类型部分,用户查询语句的词性标记结果基本符合负幂分布,折线图为经典的长尾型.
在频率排序为前100位的词性标注结果中,共包含6337096条实际用户查询,占到总查询的66.16%,而剩余308581条记 录仅包含33.84%的用户查询. 可以认为,对于这100个高频词性标注结果进行研究具有一定的代表性.
 |
| 图 3 高频句法类型折线图 |
根据表 4,3个词以内的纯名词组合垄断了三甲,而排名5个词以内的纯名词组合出现频率至少是前45名, 占高频句法组合的44.51%; 而排名前100 的句法类型中,包含名词的则有79种,共计5148401个查询,占 到高频词性标注结果中的81.24%,由此可以推断名词是搜索引擎查询中使用最广泛的关键词,验证了本文的假设.
3.2 基于链接作弊倾向的反作弊试验采用C++对本文算法以及相关的排序算法编程实现,数据处理过程在SQL Server 2005中进行. 由于素材中无法包含相应的网页内容, 将公式(6)的网页作弊倾向系数完全由链接作弊倾向系数决定, 即内容作弊倾向系数为0,而基本的排名算法采用经典的PageRank算法.
实验素材来自搜狗实验室,共包含3537379个网页8456740条链接. 以网站为研究对象,对网页预处理,去除网站的自反链接以及重复链接. 同时,去掉没有链出链接的网站,因为这类网站对PageRank算法是无效的. 最后,得到6031个网站,以及相互间的27994 条链接. 然而, 上述6031个网站中,有3888个网站只有链出而没有链入链接, 这对基于链接分析的反作弊算法有一定程度的影响. 因此, 增加一个虚拟网站,使这3888个网站也有链入链接. 所以, 实验样本是6032个网站和31882条链接.
反作弊算法是以一定的黑名单页面(网站)为前提的,而搜索引擎(如Google, 百度等)都不会主动提供黑名单列表. 为此,在Google中输入"site: URL", 并根据是否有返回结果来判断这6031个网站是否被列入黑名单. 通过这种方式,找出了约5%的被Google视为作弊的网站,形成初始黑名单. 根据Gyongyi等的实验, 整个web中约有10%$\sim$15%的页面为作弊页面[1]. 初始黑名单通过迭代能够找到更多的作弊倾向网页, 这与已有研究基本相符. 算法的伪代码如下: $int\_tmain(int argc,\_TCHAR* argv[])\{$
Init(); //初始化处理,记录页面的链出链接数和链入链接数,以及指向关系.
PrRanking$(a,d=0.85)$; //根据文[27],计算当$d=0.85$,$a$值变化时,页面的PageRank值,并排序.
PrRanking$(a=1,d)$; //根据文[27],计算当$a=1$,$d$值变化时,页面的PageRank值,并排序.
PrRanking$(a=0.5,d)$; //根据文[27],计算当$a=0.5$,$d$值变化时,页面的PageRank值,并排序.
TrustRanking(); //根据文[18],计算页面的TrustRank值,并排序.
BadRanking(); //根据文[26],计算页面的BadRank值,并排序.
StRanking(); //根据公式(5),计算页面的链接作弊倾向系数.
STBArank(); //根据公式(8),计算页面最终得分.
Output(); //输出原算法以及新算法的排序结果.
$\}$
首先分析阻尼系数$\textit{d}$的取值对全局网站作弊倾向系数的影响,实验结果如表 5.
由表 5看出,$\textit{d}$的不同取值,对作弊倾向网站的识别, 基本没有影响,但对作弊倾向系数的取值却有影响. 作弊倾向系数的均值与阻尼系数$\textit{d}$负相关,即$\textit{d}$值越大, 作弊倾向系数的均值越小. 原因是,根据公式(2),$\textit{d}$越小, 黑名单页面在(1$-$$\textit{d}$)E(p)的得分就越高, 而对公式后半部分的影响则相对较小. 值得一提的是,Larry Page和Sergey Brin推荐的阻尼系数值为${d}=0.85$, 本文后面的实验尝试了不同的$\textit{d}$值范围对实验结果的影响.

如果某页面有链接直接指向作弊页面,则称其为种子页面. 本实验共有640个种子页面. 将PageRank算法与新算法对种子页面的排名进行对比,通过公式(10), 测试新算法的反作弊性能.
| \begin{equation} {{\rm{S}}_{\rm rank}}(m) = \frac{{\sum_{i - 1}^m {R({E_i})} }}{{\sum_{i - 1}^m {R({B_i})} }} - 1 \end{equation} | (10) |
令阻尼系数${d}=0.85$,调整$\alpha$的不同取值, 观察反作弊效果. 由图 4可知,在$\alpha$的不同取值下, 新算法较PageRank算法的反作弊性能均有提升. 当$\alpha=0$时, 公式(5)的惩罚因子由作弊页面的关联度决定, 因此针对作弊相关页面的惩罚力度较$\alpha$的其它取值更大; 当$\alpha=1$时,惩罚因子则由作弊倾向系数决定, 此时针对全局的惩罚力度较强,并不针对直接将链接指向作弊页面的网页, 同时将链接指向这种页面的页面也会受到一定的连带惩罚; 当$\alpha=0.5$时,则综合考虑了两方面因子, 并且这两方面因子在惩罚因子中的权重一样, 所以其针对种子页面的反作弊表现介于$\alpha=0$与$\alpha=1$之间.
 |
| 图 4 新算法与PageRank算法的对比 |
将$\alpha$取值固定,当$\textit{d}$值变化时, 新算法与PageRank算法的对比,如图 5和图 6所示. 从图 5可以看出, 当$\alpha=1$时,新算法较PageRank 算法的反作弊性能有一定提升, 该性能基本稳定,不随$\textit{d}$值的变化而改变, 这表明当页面作弊倾向系数完全由链接决定而忽略链接之间关联度的时候, $\textit{d}$值对最终结果几乎没有影响. 从图 5也可以看出, 无论$\textit{d}$取值如何,所有的S$_{\rm rank}$($\textit{m}$)图形均遵循相同的走势, 这主要是由以下两方面原因引起的: 首先, $\alpha=1$表明算法完全忽略网页链接之间的关联性,此时, 阻尼系数的变化对算法的准确度几乎没有影响; 其次, 由于忽略了网页之间的链接的关联性, 阻尼系数$\textit{d}$值的变化不能通过页面之间的链接传递作弊关联, 表明此时对阻尼系数取值不敏感.
 |
| 图 5 $\alpha=1$,$d$取值变化,新算法与PageRank算法的对比 |
但当$\alpha=0.5$时, 反作弊性能随$\textit{d}$值的变化而存在较大的起伏,如图 6所示. 由图 6可以看到,数据基本可以分为两组: 当${d}=0.8$ 和${d}=0.85$时, 变化趋势几乎一致; 而当${d}=0.7$,${d}=0.75$和${d}=0.9$时, 走势基本一致. 这表明, 在链接作弊倾向系数和链接关联度权重各为50%时($\alpha=0.5$), 网站数量对计算结果有较大的影响: 参与计算的网站数量单位越小(本实验中小于1000), $\textit{d}$的取值会对最终作弊倾向识别效果影响较大, 且曲线会分为两个明显不同的趋势,当${d}=0.7$,${d}=0.75$和${d}=0.9$ 时,S$_{\rm rank}$($\textit{m}$)值较大,表明此时新算法对PageRank 的反作弊性能有较大提升,但是这只是实验室环境下的结论, 现实网络中有数以百万计的网站数量, 因此应该增大$\textit{m}$的值才能更加真实地模拟实际数据; 另一方面, 当网站数量较多时(本例大于1000),${d}=0.85$的准确率更高, 且最终结果也趋于一致. 这表明,在数量庞大的网站下进行迭代计算, 阻尼系数$\textit{d}$的取值对本算法的准确度不会造成根本影响, 但是从总体来看,${d}=0.85$是比较合理的取值.
 |
| 图 6 $\alpha=0.5$,$d$取值变化,新算法与PageRank算法的对比 |
另一方面,用户在检索信息的时候,常常关注的是前n条结果, 例如75%的用户只看搜索引擎返回结果的第一页, 而不会在意排名1000的结果是什么. 根据类似的思路, 对于作弊倾向网页的识别也只需要关注排名最前面的潜在作弊页面能否被识别出来, 而不用关心大部分其他正常页面, 因为互联网上只有少部分页面是作弊页面. 从这个角度上看, 本文的算法比PageRank的反作弊性能有较大幅度的提升.
将本文算法与TrustRank算法的反作弊性能进行对比,如图 7所示. 总体上, 本文算法较TrustRank算法具有更强的反作弊性能. 具体来说,表现为: 10 个区间中有7个区间反作弊性能表现比TrustRank好,但有3个区间表现略差. $\alpha$的不同取值对比TrustRank算法的反作弊性能基本与PageRank 算法对比时的表现一致,当$\alpha=0$和$\alpha=0.25$时, 会形成一组走势; 而当$\alpha=0.5$,$\alpha=0.75$和$\alpha=1$时, 形成另一组走势,不再赘述. 值得一提的是,当$\textit{m}$=1000时, S$_{\rm rank}$($\textit{m}$)的取值均在0.7左右,但是, 该结论是受本实验数据影响的,存在一定的偶然性,并不具有普遍意义. 真正有意义的结论是, 新算法的走势在整体上优于TrustRank算法的反作弊能力, 这主要是因为TrustRank是一种基于白名单页面算法, 对有作弊倾向的网站不够敏感. $\alpha$的不同取值本质上是在页面作弊倾向与页面不信任度传递之间分配不同的权重, 当$\alpha=0$和$\alpha=0.25$时, 表明链接作弊倾向比较关注页面之间的不信度传递,此时得到的效果较好, 验证了通过网页链接的关联度来识别潜在作弊网页的有效性.
 |
| 图 7 新算法与TrustRank算法的对比 |
将本文算法与BadRank算法的反作弊性能进行对比,如图 8所示. 总体上看, 本文的算法仍然略优于BadRank算法, 但是提升的幅度没有与其他算法对比时那么显著, 这是由BadRank算法的本质决定的: BadRank算法主要就是针对链接作弊设计的, 对于链接作弊有较好的识别准确率. 与TrustRank截然不同的是, BadRank是一种典型的不信任传播模型,即首先构建作弊网页集合, 之后利用链接关系来将这种不信任分值传递到其他网页. BadRank包含的基本假设是: 如果一个网页将其链接指向作弊页面, 则这个网页也很可能是作弊网页: 而如果一个网页被作弊网页指向, 则不能说明这个网页是有问题的,所以BadRank的基本思路是: 找到那些有链接关系指向已知作弊网页的页面, 这些页面很可能也是作弊网页. 由于BadRank也是从黑名单开始迭代的, 与本文的实验有一定程度的相似性,因此也最具有比较价值. 从图形上看, $\alpha=0.5$时可以得到比较稳定的作弊网页识别准确率; 而在$\alpha=1$ 和$\alpha=0$ 时,效果均不太理想, 这是因为$\alpha=0.5$时同时考虑了链接作弊和目标网页与作弊网页的距离. 尽管如此,在实际中,单一的链接作弊检测方式很容易被作弊者利用, 同时引入本文提出的内容作弊倾向系数和链接作弊倾向系数, 将更加符合实际需要,也更能体现出与BadRank对比的优势.
 |
| 图 8 新算法与BadRank算法的对比 |
本文根据作弊网页的特征, 引入作弊倾向系数这一概念来衡量一个网页作弊可能性. 综合内容作弊系数,链接作弊系数来综合考量一个页面的作弊倾向系数. 根据页面的作弊倾向系数,对惩罚策略进行探讨并提出相应的排序算法. 最后,考虑网页的链接作弊倾向系数的实验结果表明: 本算法能够对作弊相关页面进行识别及惩罚, 反作弊性能优于传统的PageRank和TrustRank算法. 此外, 还对两千多万条查询记录进行词性分析实验, 结果验证了关于内容作弊检测方面提出的假设. 因此, 引入内容作弊倾向系数,结合链接作弊倾向系数, 本算法反作弊性能将优于BadRank算法.
本研究不可避免存在一些不足的地方,以下几方面有待深入研究: 1)网站作弊倾向系数的计算. 可将网站看成网页组成的树状结构, 越底层的网页作弊系数的权重越小,反之亦然,基于这一原则, 根据页面作弊倾向系数设计网站作弊倾向系数的计算方法. 2)种子页面的选取. 对于基于初始黑名单页面的反作弊算法, 种子页面的选取直接影响算法的有效性, 需要探索如何在海量的页面中快速而又准确地选取种子页面. 3)大规模数据验证算法的性能. 本文的实验数据来自搜狗实验室, 包含3537379个网页8456740条链接. 尽管数据量巨大, 但没有提供完整的页面内容信息, 因此实验部分只对基于链接的作弊进行检测,而对基于内容的作弊检测, 仅限于检索词的词性分析. 今后需要收集大规模数据, 并将两者结合起来验证算法有效性. 同时, 大数据下的快速计算也是未来的研究方向之一.
| [1] | Gyongyi Z, Garcia-Molina H. Web spam taxonomy[C]// First International Workshop on Adversarial Information Retrieval on the Web (AIRWeb 2005), 2005: 1-8. |
| [2] | Henzinger M R, Motwani R, Silverstein C. Challenges in web search engines[C]// ACM SIGIR Forum, ACM, 2002, 36(2): 11-22. |
| [3] | Westbrook A, Greene R. Using semantic analysis to classify search engine spam[EB/OL]. [2002-11-05]. http://www. stanford.edu/class/cs276a/projects/reports. |
| [4] | 贾志洋, 夏幼明, 高炜, 等. 搜索引擎垃圾网页检测模型研究[J]. 重庆文理学院学报(自然科学版), 2011, 30(5): 53-58.Jia Zhiyang, Xia Youming, Gao Wei, et al. Research of web spam detection models[J]. Journal of Chongqing University of Arts and Sciences (Natural Science Edition), 2011, 30(5): 53-58. |
| [5] | Huang H, Qian L, Wang Y. A SVM-based technique to detect phishing URLs[J]. Information Technology Journal, 2012, 11(7): 921-925. |
| [6] | Cafarella M J, Cutting D R, Building Nutch: Open source search[J]. Queue, 2004, 2(2): 54-61. |
| [7] | 李俊. 反搜索引擎作弊的相关探讨[J]. 网络与信息, 2011(1): 35.Li Jun. Discussions on the anti-spam for search engine[J]. Networking and Information, 2011(1): 35. |
| [8] | 何秀, 牛之贤, 孙静宇. 上下文对用户搜索行为的影响[J]. 情报杂志, 2012, 31(10): 122-125.He Xiu, Niu Zhixian, Sun Jingyu. The effect of context on user search behavior[J]. Journal of Intelligence, 2012, 31(10): 122-125. |
| [9] | 董乐, 谢红薇. 元搜索引擎中排序融合算法的优化研究[J]. 计算机应用与软件, 2012, 29(10): 188-190.Dong Le, Xie Hongwei. Study on optimization of rank fusion algorithm in meta search engine[J]. Computer Applications and Software, 2012, 29(10): 188-190. |
| [10] | Jia X Q. Topic information acquisition system based on an improved anti-spoofing topic crawler algorithm[J]. International Journal of Digital Content Technology and its Applications, 2012, 6(16): 290-297. |
| [11] | Zhao H, Bai C S, Zhu S. Automatic keyword extraction algorithm and implementation[J]. Applied Mechanics and Materials, 2011, 44: 4041-4049. |
| [12] | Najork M A. System and method for identifying cloaked web servers: U.S. Patent 6,910,077[P]. 2005-6-21. |
| [13] | Microsoft. Strider search defender[EB/OL]. [2006-05]. http://research.microsoft.com/SearchDefender. |
| [14] | Wu B, Davison B D. Cloaking and redirection: A preliminary study[C]// AIR Web, 2005: 7-16. |
| [15] | 王暾. 基于JavaScript的网页重定向作弊技术研究[J]. 计算机与数字工程, 2012, 40(3): 86-88.Wang Tun. Research of webpage redirection spam technology based on Javascript[J]. Computer & Digital Engineering, 2012, 40(3): 86-88. |
| [16] | Mavridis T, Symeonidis A L. Identifying webpage semantics for search engine optimization[C]// WEBIST, 2012: 272-275. |
| [17] | Zhang F, Guo C Y. New page ranking algorithm based on website force[J]. Journal of Computer Applications, 2012, 32(6): 1666-1669. |
| [18] | Gyongyi Z, Garcia-Molina H, Pedersen J. Combating web spam with trustrank[C]// Proceedings of the Thirtieth International Conference on Very Large Data Bases-Volume 30. VLDB Endowment, 2004: 576-587. |
| [19] | Caverlee J, Liu L. Countering web spam with credibility-based link analysis[C]// Proceedings of the Twenty-Sixth Annual ACM Symposium on Principles of Distributed Computing. ACM, 2007: 157-166. |
| [20] | Du Y, Shi Y, Zhao X. Using spam farm to boost PageRank[C]// Proceedings of the 3rd International Workshop on Adversarial Information Retrieval on the Web. ACM, 2007: 29-36. |
| [21] | 贺志明, 王丽宏, 张刚, 等. 一种抵抗链接作弊的PageRank改进算法[J]. 中文信息学报, 2012, 26(5): 101-106.He Zhiming, Wang Lihong, Zhang Gang, et al. An improved pagerank algorithm with anti-link spam[J]. Journal of Chinese Information Processing, 2012, 26(5): 101-106. |
| [22] | Liu D X, Yan X, Xie W. Improved pagerank algorithm based on the residence time of the website[M]// Intelligent Computing Theories and Applications. Springer Berlin Heidelberg, 2012: 601-607. |
| [23] | 王德广, 周志刚, 梁旭. PageRank算法的分析及其改进[J]. 计算机工程, 2010, 36(22): 291-293.Wang Deguang, Zhou Zhigang, Liang Xu. Analysis of pagerank algorithm and its improvement[J]. Computer Engineering, 2010, 36(22): 291-293. |
| [24] | Duong N T, Nguyen Q A P, Nguyen A T, et al. Parallel PageRank computation using GPUs[C]// Proceedings of the Third Symposium on Information and Communication Technology. ACM, 2012: 223-230. |
| [25] | Sobek M. PR0 —— Google's PageRank 0 Penalty [EB/OL]. http://pr.efactory.de/e-pr0.shtml, 2002. |
| [26] | Liang C, Ru L, Zhu X. R-SpamRank: A spam detection algorithm based on link analysis[J]. Journal of Computational Information Systems, 2007, 3(4): 1705-1712. |
| [27] | Page L, Brin S, Motwani R, et al. The PageRank citation ranking: Bringing order to the web[R]. Stanford InfoLab, 1999. |
| [28] | Saraswathi D, Kathiravan A V, Kavitha R. Link farm detection using SVMLight tool[C]// Computer Communication and Informatics (ICCCI), 2012 International Conference on IEEE, 2012: 1-5. |
| [29] | Saraswathi D, Kathiravan A V, Kavitha R. A new enhanced technique for link farm detection[C]// Pattern Recognition, Informatics and Medical Engineering (PRIME), 2012 International Conference on IEEE, 2012: 74-81. |
| [30] | 昝辉. SEO实战密码[M].北京: 电子工业出版社, 2011: 277-278, 396-402. Zan Hui. SEO in action[M]. Beijing: Electronic Industry Press, 2011: 277-278, 396-402. |
| [31] | 刘俊熙. 搜索引擎应对网站作弊的搜索策略和用户的检索策略[J]. 现代情报, 2007, 6(6): 168-170.Liu Junxi. Search strategies for search engine on spam and the search strategies for users[J]. Modern Information, 2007, 6(6): 168-170. |