


0 引言
集装箱码头堆场是集装箱运输作业的统一集散地, 也是港口运作不可或缺的重要资源. 集装箱堆场的主要装卸设备-场桥的作业调度对堆场甚至整个码头的作业效率有直接影 响. 对于出口箱而言, 集装箱到达顺序的不确定性将直接增加场桥堆存作业的随机性,进而 降低其作业效率. 不确定的交箱序列以及堆场规模的限制也会导致出口箱装船时出现一定数 量的翻箱. 以国内现代化水平较高的集装箱码头的调查数据为例, 翻箱率约为14%左右,且长期居高不下. 场桥调度以及翻箱作业已成为影响集装箱码头作业效率的瓶颈因素, 如何优化出口箱堆存策略以有效提高场桥作业效率并减少翻箱作业, 已成为码头面临的重要课题.
许多学者研究了基于不同优化目标的场桥堆存作业优化问题, Kim等[1, 2]研究了单台场桥的最优路径问题, 建立混合整数规划模型以优化场桥总作业时间, 并且给出了模型的精确求解方法; 针对同样的问题, Kim等[3]又提出了相应的遗传算法和集束搜索算法进行求解; Narasimhan等[4]在已知出口集装箱的贝位计划的前提下, 开发了分枝定界算法求解场桥作业时间最小化问题; Kim等[5]考虑场桥作业的不同限制条件建立混合整数规划模型, 设计了分枝界定法进行求解, 并用贪婪随机适应搜索过程来克服其在计算机求解时的缺点. Ng等[6]在作业任务数量、 作业任务预期时间己知条件下研究了单台场桥作业顺序问题, 模型中考虑了集卡到来时刻对场桥调度的影响, 并利用启发式算法对该问题进行求解. 韩晓龙[7]讨论了在出口装船过程中单台场桥的最优路径问题, 建立了以场桥完成任务总时间最短为目标函数的混合整数规划模型, 并采用Lingo软件对模型进行了求解. Kim等[8]以最大化堆场集卡和场桥工作效率为目标建立箱位分配模型, 并运用约束满足技术进行求解; 何军良等[9]提出了基于整数规划模型和爬山算法的场桥调度混合策略, 同时考虑场桥调度和堆存空间分配构建了场桥动态调度模型. 周鹏飞等[10]引用顺序统计量描述集装箱随机到达序列, 建立同时考虑翻箱数和场桥大车移动距离的两阶段箱位分配优化模型, 并设计了禁忌搜索算法进行求解. 周鹏飞等[11]考虑集装箱进出堆场时间的不确定性, 建立出口箱位随机双层规划模型,分别优化预期翻箱数和场桥作业成本, 并开发了启发式算法进行求解.
上述研究大多都将存取箱作业任务设定为已知条件, 而港口实际作业中是不可确定的; 而且, 集港过程中集装箱遵循按客户分批到达, 同一客户的集装箱属性基本一致的规律,而非现行研究中的 "每两个集装箱作业任务都有先后顺序之分"的前提条件; 对于同时优化场桥作业问题和翻箱问题的研究也比较缺乏. 本文基于集装箱码头作业实务中集装箱到达序列的随机性、成批性的特点, 运用马尔可夫链来处理出口箱随机交箱序列, 建立同时考虑翻箱问题和场桥调度问题的场桥堆存作业优化两阶段模型, 并开发了相应的静态与动态优化算法进行求解. 1 场桥堆存作业问题描述与建模 1.1 问题描述
出口箱的集港过程大致可以分为客户预约, 港方编制堆存计划以及入港堆存三个阶段. 客户预约时会向港口提供集装箱的数量、箱型、尺寸、 挂靠港口以及预计集港时间等信息, 港口根据这些信息编制堆存计划以确定每个集装箱的具体堆存位置. 每位客户会有若干集装箱需要服务,这一组集装箱通常会同时到达港口. 按照同一客户的集装箱尽量集中堆放的原则, 每一客户的集装箱可堆存为若干栈并余下若干零散集装箱, 这些零散的集装箱造成了后续装船作业时的翻箱. 鉴于此, 本文将每个客户的集装箱分为两个集合,其一是不参与翻箱的集装箱集合, 记为集合$A_n$,这些集装箱可以构成若干完全由客户$n$的集装箱构成的 "整栈",所有的集合$A_n$组成一个集合$A$; 其二是参与翻箱的集装箱集合,记为集合$B_n$, 其数量应小于堆场的额定堆存高度,所有的集合$B_n$组成一个集合$B$, 这些集装箱构成了若干"翻箱栈".
图 1是街区俯视示意图,其中带有数字标号的栈是不参与翻箱的栈, 栈内集装箱都属于同一客户. 例如贝位1有三个"整栈", 其中的集装箱属于集合$A_1$和集合$A_5$; 图中没有标号的栈即由参与翻箱的集装箱组成的"翻箱栈", 其中的集装箱属于集合$B$.
 |
| 图 1 街区示意图 |
本文旨在优化集合$B$的堆存方案的基础上, 求解集合$A$与集合$B$的整体堆存方案,进而优化场桥的移动路径. 模型分为两个阶段, 第一阶段针对集合$B$建立以最小化预翻箱数为目标函数的堆存优化模型, 优化"翻箱栈"内的箱位分配. 第二阶段针对集合$A$与集合$B$建立以场桥作业移动距离最小为目标函数的场桥堆存作业优化模型, 以栈为最小调度对象优化场桥作业路径. 本文的研究是在基于以下前提:
1)已知待分配的街区;
2)所有待堆存集装箱箱型相同,如均为20英尺标准集装箱;
3)客户的集装箱交箱时间、目的港、重量等信息已知; 同一客户的集装箱交箱时间、目的港、重量相同(否则视为不同客户);
4)基于装船作业实务,翻箱数量按照长途箱压短途箱、 重箱压轻箱的规则进行加权计算;
5)场桥的移动距离以贝位为单位计算,初始位置为贝位1;
6)根据每一个客户的集港堆存方案,场桥按照贝位顺次作业. 1.2 第一阶段模型 1.2.1 符号说明
$I$: 堆场堆垛栈的额定高度;
$N$: 待进港客户总数;
$M$: 一个充分大的正数; $U_n$: 客户$n$的待进港集装箱数量;
$F_n$: 客户$n$参与翻箱的集装箱数量,也即$F_{n}=U_{n}mbox{mod}\ I$;
$T$: 所有客户参与翻箱的集装箱构成的翻箱栈的总数, 也即$T=[\sum_{n=1}^{N}F_n-(\sum_{n=1}^{N}F_n)mbox{mod}\ I]/I+1$;
$O_n$: 客户$n$的进场顺序;
$d_n$: 客户$n$集装箱的目的港序号;
$w_n$: 客户$n$集装箱的重量等级,最大重量等级为$W$;
$c_n$: 客户$n$集装箱的堆存优先级,其中$c_n=Wd_n+w_n$;
$slot(t,i)$: 位于第$t$个翻箱栈第$i$层的箱位.
决策变量有:
$s_{nti}$: 第$t$个翻箱栈第$i$层是否被第$n$个客户的集装箱占据,即:
$ s_{nti}=\left\{ \begin{array}{ll} 1 ,& \mbox{当$slot(t,i)$被客户$n$的集装箱占据;}\\ 0 ,& \mbox{其他. } \end{array} \right. $
$n=1,2,\cdots,N;t=1,2,\cdots,T;i=1,2,\cdots,I.$
$R_{t(i-z)}(s_{nti},s_{nt(i-z)})$: 堆放在$slot(t,i)$与$slot(t,i-z)$ 上的集装箱是否有翻箱,如果前者的优先级小于后者,则产生翻箱,即:
$ R_{t(i-z)}(s_{nti},s_{nt(i-z)})=\left\{ \begin{array}{ll} 1,&\mbox{当分配到$slot(t,i)$的集装箱权值$c_n$小于分配到$slot(t,i-z)$ 上的集装箱;}\\ 0 ,&\mbox{其他. } \end{array} \right. $
$t=1,2,\cdots,T;i=2,3,\cdots,I;z=1,2,\cdots,i-1.$ 1.2.2 目标函数与约束条件
目标函数:
| $$P_1=\min\sum_{t=1}^T\sum_{i=2}^I\sum_{z=1}^{i-1} R_{t(i-z)}(s_{nti},s_{nt(i-z)}) $$ | (1) |
约束条件为:
| $$\sum_{t=1}^T\sum_{i=1}^I s_{nti}=F_n ,\qquad n=1,2,\cdots,N $$ | (2) |
| $$\sum_{n=1}^N s_{nti}\le1 ,\qquad t=1,2,\cdots,T;i=1,2,\cdots,I $$ | (3) |
| $$\sum_{n=1}^N s_{nti} \le \sum_{n=1}^N s_{nt(i-1)},\qquad t=1,2,\cdots,T;i=2,3,\cdots,I $$ | (4) |
| $$\sum_{n=1}^N O_n s_{nti} +\bigg(1-\sum_{n=1}^N s_{nti}\bigg)M >\sum_{n=1}^N O_n s_{nt(i-1)}, \qquad t=1,2,\cdots,T;i=2,3,\cdots,I$$ | (5) |
$$R_{t(i-z)}(s_{nti},s_{nt(i-z)})=\bigg\lceil \frac{V}{\exp(V)} \bigg\rceil $$
其中
| $$V=\sum_{n=1}^N S_{nti} \bigg\lceil \exp\bigg(\sum_{n=1}^N c_n s_{nt(i-z)} - \sum_{n=1}^N c_n S_{nti} \bigg)-1\bigg\rceil$$ $$t=1,2,\cdots,T;i=2,3,\cdots,I;z=1,2,\cdots,i-1 $$ | (6) |
目标函数式(1)表示最小化翻箱次数; 约束(2)保证每一客户在翻箱栈中占据的箱位等于该客户参与翻箱的总数; 约束(3)表示每一个箱位只能放一个集装箱; 约束(4) 表示每一个集装箱都不会悬空; 约束(5)确保每一个集装箱的进场顺序后于其下面的集装箱; 式(6)的含义是当处于$slot(t,i)$的集装箱的优先级小于处于$slot(t,i-z)$ 的集装箱时,记为一次预翻箱. 1.3 第二阶段模型 1.3.1 符号说明
根据第一阶段模型的计算结果,可以得到由集合$B$中元素构成的$T$ 个 "翻箱栈"的堆存方案,设这$T$个"翻箱栈"构成集合$H$, $H_t$即为其中第$t$个"翻箱栈"; 设所有客户构成的"整栈" 的集合为$Z$, 集合$Z_n$表示由集合$A_n$中元素构成的若干整栈的集合.
$K$: 街区内的贝位总数;
$J$: 每一贝堆垛的栈数;
$ZE_n$: 每个客户不参与翻箱的"整栈"数, 也即$E_n=(U_n-F_n)/I$;
决策变量为:
$h_{tjk}$: 第$k$贝第$j$栈是否被$H_t$占据, 即:
$ h_{tjk}=\left\{ \begin{array}{ll} 1 ,&\mbox{当$k$贝中第$j$栈被$H_t$占据;}\\ 0 ,&\mbox{其他. } \end{array} \right. $\\ $t=1,2,\cdots,T;j=1,2,\cdots,J;k=1,2,\cdots,K.$\\ $g_{njk}$:
第$k$贝第$j$栈是否被$Z_n$占据, 即:
$ g_{njk}=\left\{ \begin{array}{ll} 1 ,&\mbox{当$k$贝中第$j$栈被$Z_n$占据;}\\ 0,&\mbox{其他. } \end{array} \right. $\\ $n=1,2,\cdots,N;j=1,2,\cdots,J;k=1,2,\cdots,K.$\\ $e_{nk}$:
第$k$贝是否存在客户$n$的集装箱, 即:
$ e_{nk}=\left\{ \begin{array}{ll} 1,&\mbox{当第$k$贝存在客户$n$的集装箱,即$\sum_{j=1}^J g_{njk} +\sum_{t=1}^T \sum_{j=1}^J (h_{tjk} \sum_{i=1}^I s_{nti}) \geq 0$;}\\ 0 ,&\mbox{其他. } \end{array} \right. $
$n=1,2,\cdots,N;k=1,2,\cdots,K.$
$E_{nkp}$: 客户$n$在堆存时第$k$贝与第$p$贝是否存在顺次移动距离, 即:
$ E_{nkp}\!=\!\left\{ \begin{array}{ll} 1,&\mbox{当客户$n$在堆存时第$k$贝与第$p$贝是否存在顺次移动距离,即$e_{nk}e_{np}(1\!\!+\!\! \sum_{q=k+1}^{p-1}e_{nq})\!=\!1$;}\\ 0,&\mbox{其他. } \end{array} \right. $
$n=1,2,\cdots,N;k=1,2,\cdots,K-1;p=k+1,K+2,\cdots,K.$
每一个客户集港完毕后,场桥会停留在其最后工作的贝位. 在开始下一次集港作业之前需要移动到其顺次作业的初始贝位, 本文将这一段移动距离称作场桥的切换作业移动距离. 由于同一位客户的若干栈集装箱的待堆存位置可能分布在街区内的不同贝位, 因此上一次场桥最后工作的贝位会与其存在如图 2的三种关系.
 |
| 图 2 三种切换作业 |
场桥对于包含同一客户的集装箱栈是顺次作业, 因此需要给出一个切换作业移动规则来指定本次堆存任务的起始贝位. 当待作业贝位处于场桥的同一侧时, 则移动到距离最近的贝位向另一端顺次堆存; 当待作业贝位分布在场桥工作结束位置的两侧时, 移动到距离其分布端点贝位较近一侧开始向另一侧顺次堆存, 若距离相同则随机选择一段进行堆存. 可以证明此堆存路径为场桥局部作业移动距离最短路径.
$O_n^{\prime}$: 第$n$个进场的客户编号,$O_{O_n}^{\prime}=n$, $n=1,2,\cdots,N.$
${\rm Max}_n$: 第$n$个进场的客户堆存的贝位序号最大值, 其值为$\max\{ke_{(O_n^{\prime})k}\}$,$n=1,2,\cdots,N$.
${\rm Min}_n$: 第$n$个进场的客户堆存的贝位序号最小值, 其值为$\min\{ke_{(O_n^{\prime})k}\}$,$n=1,2,\cdots,N$.
${SW}_n$:第$n$个进场客户的场桥作业结束所在贝位序号, 为一个递推序列, 其中:
${SW}_1={\rm Max}_1$,
$ {SW}_n=\left\{ \begin{array}{llll} {\rm Min}_n ,&\mbox{当${SW}_{n-1}\geq {\rm Max}_n$;}\\ {\rm Max}_n,&\mbox{当${SW}_{n-1}\leq {\rm Min}_n$;}\\ {\rm Min}_n,&\mbox{当${SW}_{n-1}-{\rm Min}_n\geq {\rm Max}_n-{SW}_{n-1}$;}\\ {\rm Max}_n ,&\mbox{当${SW}_{n-1}-{\rm Min}_n\leq {\rm Max}_n-{SW}_{n-1}$;}\\ \end{array} \right. $
$n=2,3,\cdots,N.$
${DS}_n$:第$n-1$个进场客户与第$n$个进场客户的场桥切换作业移动距离, 为一个递推序列, 其中:\\ ${DS}_1={\rm Min}_1$,
$ DS_n=\left\{ \begin{array}{llll} {SW}_{n-1}-{\rm Max}_n,&\mbox{当${SW}_{n-1}\geq {\rm Max}_n$;}\\ {\rm Min}_n-{SW}_{n-1},&\mbox{当${SW}_{n-1}\leq {\rm Min}_n$;}\\ \min\{{SW}_{n-1}-{\rm Min}_n,{\rm Max}_n-{SW}_{n-1}\},&\mbox{当${\rm Min}_n<{SW}_{n-1}<{\rm Max}_n$;}\\ \end{array} \right. $
$n=2,3,\cdots,N.$ 1.3.2 目标函数与约束条件
目标函数为:
| $$P_2=\min\bigg(\sum_{n=1}^N {DS}_n+\sum_{n=1}^N \sum_{k=1}^K \sum_{p=k+1}^K (p-k)E_{nkp}\bigg)$$ | (7) |
| $$\sum_{j=1}^J \sum_{n=1}^N g_{njk} + \sum_{j=1}^J \sum_{t=1}^T h_{tjk}\leq J,\qquad k=1,2,\cdots,K $$ | (8) |
约束条件为:
| $$\sum_{k=1}^K \sum_{j=1}^J g_{njk}=ZE_n,\qquad n=1,2,\cdots,N $$ | (9) |
| $$\sum_{k=1}^K \sum_{j=1}^J h_{tjk}=1,\qquad t=1,2,\cdots,T $$ | (10) |
| $$\sum_{n=1}^N g_{njk} \sum_{t=1}^T h_{ijk}\leq1,\qquad j=1,2,\cdots,J;k=1,2,\cdots,K $$ | (11) |
目标函数(7)表示最小化场桥移动距离; 约束(8)表示每一贝集装箱堆放栈数小于额定堆存栈数; 约束(9)表示每个客户分布在堆场内的"整栈"数量应等于该客户的"整栈"总数; 约束(10)表示每一个"翻箱栈"只能 且必须占用一个栈位; 约束(11)表示每个栈位只能存放一个"整栈"或" 翻箱栈". 2 算法设计
算法针对集装箱堆场作业流程分为两部分: 第一部分是在客户集港之前制定初始堆 存方案, 首先运用马尔可夫链对广义交箱序列进行预测, 基于预测序列运用模拟退火算法求解 翻箱量最小化问题以及场桥调度问题; 第二部分是当客户集港顺序与预测序列出现偏差时,结合客 户到达信息对预测交箱序列进行修正, 并基于该序列给出实时调度阶段的堆存策略和场桥移动路径, 同时对堆存方案进行更新,作为下一客户集港的基础,算法流程如图 3所示.
 |
| 图 3 算法流程图 |
在集港期限内,客户按照已提交的预约时间集港, 客户的集港序列称为交箱序列. 由于在实际集 港过程中部分客户无法在预约时间到达港口, 导致港口无法确定客户的交箱序列. 本文称这种带有不 确定因素的交箱序列为广义交箱序列. 交箱序列是港口编制堆存计划的基础,也是降低翻箱率的重 要依据, 本文采用典型的离散随机过程------马尔可夫链 (以下简称马氏链) 对该序列进行预测.
在码头实际作业中,受客户的地理位置,区域交通条件, 企业管理水平等内外部条件的影响, 总会存在到达顺序稳定(即与其预约集港时间大致吻合) 的客户与到达顺序相对混乱 (即与其预约集港时间不相符) 的客户, 后者即为预测对象. 根据客户集港的历史数据, 可以整理出混乱客户的不同到达序列,组成马氏链的离散状态集合$S$.
图 4列举了七位客户的三个不同的到达序列. 显然客户2、3以及4的到达顺序相对混乱,因此选择这三个客户进行预测, 而到达顺序2-4-3、3-2-4、4-3-2则作为马氏链的三个离散状态------ $S_1$,$S_2$ 以及$S_3$.
 |
| 图 4 客户到达序列示意 |
基于选定的离散状态,将历史数据中各序列互相转化的次数进行统计, 计算转移概率$P_{ij}=(X_{t+1}=S_j|X_t=S_i)$, 可得出马氏链的状态转移概率矩阵. 将上一次集港顺序作为初始状态$X_t$, 就可以根据状态转移概率的最大似然值 $\max P_{ij}=(X_{t+1}=S_j|X_t=S_i)$预测本次集港的客户广义交箱序列.
基于上述预测序列, 针对第一阶段模型的解的结构特点设计了记忆模拟退火算法求解. 解编码为$I$ 行$T$列的实数矩阵,数值由客户编号与"0" 构成. 矩阵中的一列对应一个" 翻箱栈", 从第一列至第$T$列与"翻箱栈"依次对应. 列内每一行的数值为其对应"翻箱栈"中对应位置集装箱的客户编号, 空箱位用"0"代替.
产生新解的方法即基于当前解构造邻域, 并从中选取一个新解来判断是否接受.本算法的邻域构造方法为随机选取不同两列中编号不同的数值进行交换. 新解产生后可能生成不可行解(不满足进场顺序), 需要在栈内按照进场顺序重新堆存. 图 5(a) 所示为解编码构造邻域, 若此时客户进场顺序为3-1-2-4, 交换后第一列与第三列均不能满足进场顺序,需要将"1" 置于"4"下面, 产生的新解为图 5(b).
 |
| 图 5 第一阶段模型解的邻域构造 |
上述算法的求解结果为"翻箱栈"的堆存方案, 是第二阶段优化算法的基础. 鉴于第二阶段解的结构特点与第一阶段 比较类似,亦采用记忆模拟退火算法对其行求解. 第二阶段模型是以栈为最小调度单位,因而根据街区的俯视 图设计编码. 编码的矩阵表示街区,每一列表示一个贝位,每一个数值表示一栈集装箱. 若该栈是由同一组客户构成的"整栈",则用 该客户的编号作为代表该栈的数值; 若该栈是"翻箱栈", 则根据该栈在$T$个"翻箱栈"内的排序依次将其值设定为$N+t$, 其中$t=1,2,\cdots,T$.
如图 6所示, 第二阶段算法的邻域构造方法为随机选取不同两列中编号不同的数值进行交换, 其实质是交换位于 不同贝位且集装箱堆存结构不同的两栈集装箱. 新解产生后不会破坏模型约束,均为可行解.
 |
| 图 6 第二阶段模型解的邻域构造 |
两个阶段的算法参数设置如下: 结合不同规模的算例实验以及$\Delta
f$值的大小设计初始温度; 结束温度设为1度,
温度下降系数$\alpha$根据不同规模问题来确定;
由于该问题涉及现实规模较大,设计了自适应性内循环次数$L_t=a-(t/b)$,
以有效减小不同温度下马氏链收敛步长,其中$t$ 为当前 温度,
参数$a$与$b$的值根据规模取值不同.
2.2 实时调度算法}
在入港堆存阶段,当客户的集港序列与预测序列发生偏差时,
需要进行实时堆存再调度,以减少预测偏差带
来的翻箱数和场桥作业移动距离的增加.
实时调度的基础为通过已构建的马氏链并基于实际集港客户
的信息对发生偏差的预测交箱序列进行修正.
对于客户总数为$N$的集港过程,每个客户的交箱时刻作为
一个实时调度的决策时点,堆场在堆存过程中共需要做出$N$次再调度决策;
将上 述由马氏链预测的交箱序列设为$Q$,
该序列中在第$n$个到达港口的客户设为$Q_n$; 设 实际交箱序列为$C$,
第$n$个实际到达港口的客户设为$C_n$; 当$C_n$与$Q_n$ 不一致时,在马
氏链的离散状态集$S$中找到满足条件的交箱序列,
条件为该序列从第1位到第$n-1$位满足序列 $Q$ 且第$n$位为$C_n$.
将符合条件的所有序列组成临时备选状态集$S^{\prime}$,
并基于初始状态$X_t$ 在$S^{\prime}$
中寻找状态转移概率为最大似然值$\max
P_{ij}=(X_{t+1}=S+j|X_t=S_i)$的序列作为更新的预
测交箱序列$Q^{\prime}$.
如图 7所示为一个预测交箱序列的更新过程,图中实际交箱序列与预测序列不一致. 备选状态集中满足前3位排序为1-2-4的由状态$S_1$,$S_2$以及$S_3$. 初始状态为$X_t$,转移概率$P_{t1}$,$P_{t2}$以及$P_{t3}$中最大者为$P_{t1}$,因此序列$S_1$ 作为更新后的预测序列$Q^{\prime}$. 客户预测交箱序列更新之后即成为制定本次集港实时调度和更新整体堆存方案的基础.
由于集卡从闸口到达堆场的时间较短,并且当客户集中集港时没有作业切换间歇,因此要求实时调度算法快速收敛. 根据这一特性设计了基于Local Search思想的局部快速收敛迭代算法来求解实时调度方案并更新整体堆存方案. 设堆存方案的集合为$Pl$,$Pl_n$为第$n$个客户集港之前的堆存方案,$Pl_1$ 即为初始堆存方案; 设街区在第$n$个决策时点的堆存状态为$ST_n$,$ST_1$即表示未堆存集装箱的空堆场. 该算法实质是基于$Q^{\prime}$通过改动$Pl_n$ 内未堆存的箱位进行搜索局部最优解,进而在$ST_n$上堆存客户$C_n$的集装箱产生$ST_{n+1}$,并给出更新的堆存方案$Pl_{n+1}$.
设$f(x)$为计算某栈翻箱数的函数,$f(H_t)$表示栈$H_t$的翻箱数. 针对集合$B_{C_n}$的集装箱堆存,迭代算法步骤如下:
Step 1 按照$Q^{\prime}$调整$Pl_n$内每一栈集装箱的堆垛顺序,设定正整数$\beta$,$\alpha$;
Step 2 若$\alpha=\beta$,算法结束; 否则基于方案$Pl_n$在集合$H$ 内随机选取两个不同的"翻箱栈"$H_{t1}$和$H_{t2}$,并分别在$H_{t1}$和$H_{t2}$内随机选取两个编号不同的未集港客户的集装箱进行交换形成$H_{t1}^{\prime}$和$H_{t2}^{\prime}$,并根据$Q^{\prime}$调整该两栈内的堆存顺序;
Step 3 计算翻箱量差值$\Delta f=f(H_{t1}^{\prime})+f(H_{t2}^{\prime})-f(H_{t1})-f(H_{t2})$,
若$\Delta f\leq0$,则接受新解,并令$\alpha=0$,否则保留原解,并令$\alpha=\alpha+1$,执行Step 2;
该算法旨在$ST_n$基础上堆存集合$B_{C_n}$中的集装箱,同时得到方案$Pl_n$中集合$H$的更新解$H^{\prime}$. 常数$\beta$为控制算法收敛的未改善迭代次数阈值,其含义为当算法连续迭代$\beta$步之后目标函数值没有改善则认为收敛到局部最优解.
图 8所示为基于图 7中预测序列更新情况该算法计算前后的堆场堆存方案,左图为客户$C_3$(客户4)集港之前"翻箱栈"$H$的堆存状态,右图为算法收敛得到的堆存方案. 左图中客户4 的集装箱堆放在未集港客户的集装箱之上,不能满足堆存要求 (不能悬空) . 而右图中每一栈的客户顺序按照更新的预测交箱序列$Q^{\prime}$ 排序.
基于上述算法结果,将$H^{\prime}$替换到方案$Pl_n$中产生更新方案$Pl_n^{\prime}$,作为场桥调度的基础. 设$g(x)$为计算某堆存方案场桥大车移动距离的函数,场桥实时调度的迭代算法步骤描述如下:
Step 1 设定正整数$\lambda$,$\alpha=0$;
Step 2 若$\alpha=\lambda$,算法结束; 否则在方案$Pl_n^{\prime}$ 中随机选取两个贝位$K_1$和$K_2$,并分别在$K_1$和$K_2$ 内随机选取两个尚未堆存集装箱且编号不同的栈进行交换,产生新堆存方案$Pl_n^{\prime\prime}$;
Step 3 基于$Q^{\prime}$计算方案$Pl_n^{\prime\prime}$与方案$Pl_n^{\prime}$的大车移动
距离差值$\Delta g=f(Pl_n^{\prime\prime})-f(Pl_n^{\prime})$,若$\Delta g\leq0$,则接受新解,并令$\alpha=0$,
否则保留原解新解,并令$\alpha=\alpha+1$,执行Step 2;
该算法也是收敛到局部最优解,
常数$\lambda$为控制算法收敛的未改善迭代次数阈值.
图 9是基于图 7以及图 8的两个街区俯视图,
左图为将图 8中集合$H^{\prime}$替换入原有整体堆存方案的俯视堆存状态,
右图为算法收敛得到的堆存方案俯视图.
至此,客户$C_n$的集装箱堆存完毕,
堆场堆存状态$ST_n$更新为$ST_{n+1}$,
并得到了更新的堆存方案$Pl_{n+1}$.\vspace{-1mm}
3 数值实验
数值实验共分为两部分: 第一部分在不同航线规模下,
借助于与港口堆场实际调度规则进行对比,以验证算法的实用性;
第二部分构造了基于静态算法的两个不同实时堆存策略,
并分别在不同交箱序列混乱程度下与本文算法进行对比 模拟实验,
以验证动态算法的有效性.
3.1 与现实调度规则的对比 3.1.1 现实调度规则描述
根据调研,堆场实务操作的现行堆存调度规则为: 在制定堆存方案阶段,
对于集装箱批量大的客户,将预留 出若干栈位堆放其集装箱;
对于集装箱批量小的客户,
则尽量安排同一客户的集装箱堆存在同一栈或同一贝 位内相邻的栈,
并将挂靠港口相同或相近客户的集装箱堆存在同一贝位或相邻的贝位.
在实时调度阶段,堆场调度 人员会根据实际集港情况对堆存方案进行调整,
尽量将同一重量等级或同一目的港的集装箱堆存在相邻位置.
3.1.2 结果比较与分析
航线的不同影响集装箱的批量. 外贸航线的出口集装箱批量大,
客户数量少; 内贸航线的出口集装箱批量小,客户数量相对较多. 因此,
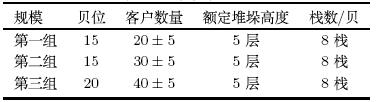
针对客户数量以及堆场规模的不同进行了三组实验,如表 1所示.
针对上述三组航线分别选取最近5周的实际到达序作为模拟交箱序列,
通过与实际堆存调度规则进行实验比较. 算法运用Matlab7.0进行算法编写,
在PC (Intel\circledR Pentium\circledR processor T4200,2.0GHz)
上运行,初始方案算法运行时间在1至3分钟不等,
实时调度算法的运行时间均在1s 内完成.
图 10为第一组规模下初始堆存方案算法收敛图和实时调度算法收敛图.
由图 10(a)可见,针对初始堆存方案设计的记忆模拟退火算法收敛效果良好,
收敛值(预翻箱数)为19,相对于由初始值213有明显改善;
由图 10(b)可以看出,本文设计的动态算法呈"阶梯型"收敛,
在较短时间内快速收敛到局部最优解 (循环次数仅为38次) .
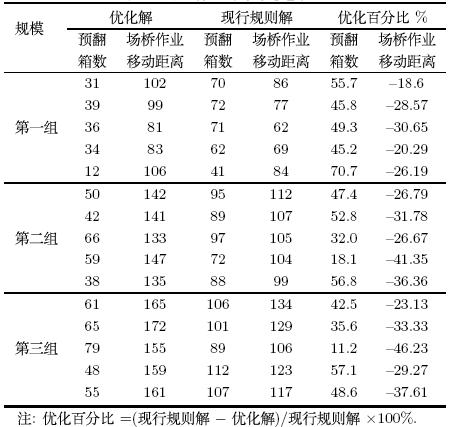
两种堆存策略在三组不同规模的航线下5周内翻箱量与场桥作业移动距离的结果平均数如表 2所示.
由以上实验结果可以看出,相对于集装箱堆场的实际堆存调度规则,
本文提出的堆存优化算法对降低翻箱数效果显著. 场桥
作业移动距离稍逊于现实堆存调度规则,
这是由于现实堆存调度规则总体上遵循"就近堆存"的原则.
在实际作业中,
场桥作业移动距离对堆场作业效率的影响要远小于翻箱作业,
因此在大幅度下降翻箱数量,有效提高装船效率的 条件下,结果可以接受.
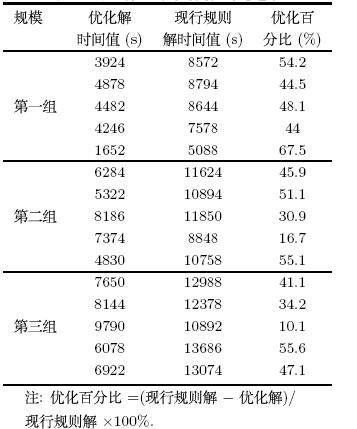
场桥作业移动距离与翻箱数量对堆存作业和装船作业效率的影响主要体现在时间上.
根据实际操作经验,场桥移动一个贝位距离的平均时间为2秒,
一次翻箱操作耗时2分钟,
将预翻箱数量与场桥移动距离分别折算成时间值并进行求和,
计算结果为表 3,可见本文提出的优化算法相比于现行堆存调度规则在时间值上降低30\%至50\%,
优化效果显著.
即根据初始堆存方案算法得出堆存的方案,在实时调度阶段,如果预测序列出现偏差,仍然按照原方案中堆存栈位堆存.
策略2: 贪婪策略
即基于贪婪算法思想的启发式算法,分为如下两个阶段:
设客户$C_n$中第$r$个参与翻箱的集装箱设为$B_{C_nr}$; "翻箱栈"$H_t$ 在第$n$个决策时点的状态设为$H_{tn}$; 函数$f(x)$为计算一个栈的翻箱数,
$f(H_{tn})$ 表示在第$n$个决策时点开始时栈$H_t$的预翻箱数量,$f(B_{C_nr},H_{tn})$表示在第$n$个决策时点将集装箱$B_{C_{nr}}$堆存在栈$H_t$内之后该栈的翻箱数. 令$r=0$,此启发式算法的第一阶段可以描述为:
Step 1 若$r=F_n$,调度结束,否则令$r=r+1$,执行Step 2;
Step 2 依次判断$H_t$是否有空箱位,若存在则计算$\Delta l=l(B_{C_nr},H_{tn})$,并将集装
箱$B_{C_nr}$放入$\Delta l$最小值所在的栈,若该栈不唯一,则等概率选取其中一个,执行Step 1;
第一阶段的启发式算法给出了集合$B_{C_n}$内的集装箱的堆存策略,此时街区内的堆存状态由$ST_n$更新为$ST_n^{\prime}$,基于$ST_n^{\prime}$ 的第二阶段启发式算法调度的是集合$Z_{C_n}$内的集装箱栈.
设集合$Z_{C_n}$中第$r$栈集装箱栈为$Z_{C_nr}$; 设街区内第$k$ 个贝位为$BA_k$; 设$d(x)$为计算大车移动距离的函数,$d(Z_{C_nr},BA_k)$ 表示在第$n$ 个阶段将集装箱栈$Z_{C_nr}$堆存在$BA_k$时龙门吊从原位置移动到贝位$BA_k$的距离,$d(Z_{C_n1},BA_k)$即为切换作业距离$DS_n$. 令$r=0$,此启发式算法的第二阶段可以描述为:
Step 1 若$r={ZE}_n$,调度结束,否则令$r=r+1$,执行Step 2;
Step 2 依次判断${BA}_k$是否有空栈位,
若存在空栈位则计算$d(Z_{C_nr},BA_k)$,将$Z_{C_n1}$放入
函数值最小的贝位$BA_k^{\prime}$ 中,若该贝位不唯一,
则等概率选取其中一个,执行Step 1.
3.2.2 实验设计
为了进一步检测本文算法的动态优化效果,
对广义交箱序列的混乱程度按照两个维度分类:
其一是根据序列中混乱客户的数量划分混乱等级,
诸如在第一组航线规模下,根据混乱客户数量的不同划分了六个混乱等级,
从一级至六级分别对应6、8、10、12、14、16个混乱客户;
其二是根据序列中混乱客户的混乱分散程度
(即混乱客户在序列中的分散情况) 划分混乱度. 图 11列举了两个交箱序列,
序列一中的6 个混乱客户为在序列中分散在两处,则称其混乱度为2;
序列二中的5个混乱客户集中在序列中的一处,则称其混乱度为1.
通过第一组航线规模下交箱序列的不同混乱等级来对比优化算法与两种调度策略的效果,混乱度均
设定为2,每个混乱等级重复模拟实验10次,本文提出的优化算法解与上述两种调度策略的作业时间值平均数见图 12.
图 13为其中一次模拟实验三种方案在集港过程中的预翻箱数增长情况,由于三种堆存方案的初始方案都是基于预测交箱序列的,因此在集港客户数量较少的集港前期,其表现出的优化效果基本一致. 随着集港客户的增加,在集港中期策略1明显显示出劣势,而策略2的优化效果优于本文算法,这是因为本文算法的侧重点为结合更新预测序列的全体客户堆存方案最优,该方案并不一定符合当前最优. 在集港后期,随着全体客户集港完毕,逐渐显示出本文算法优于策略2.
基于第一组航线规模在混乱等级为六级的条件,
在混乱度从1至6度级下分别对三种算法进行10次模拟实验,结果见图 14.
可以看出在同一混乱等级下,
随着混乱分散程度的增加本文算法的解有明显改善,
这是由于混乱度的增加致使每一处 混乱客户的数量减小,
大大减小了马氏链的离散状态集,从而增加了马氏链预测的准确性.
由于策略1缺乏实 时调度策略,混乱度的增加对其解改善幅度较小.
策略2在实时调度阶段的启发式算法没有结合预测信 息,
当预测序列发生偏差以后,
启发式算法会对原有方案的优化性能起到"破坏"作用,因此混乱度的
增加对其解几乎没有影响.
4 结论与展望
本文结合集装箱堆场操作的实际情况,结合历史数据构建广义交箱序列,
并基于该序列建立了分别以预翻
箱数最小和场桥作业移动距离最短为目标函数的出口集装箱场桥堆存作业优化数学模型,
并开发了模拟退 火算法进行求解. 针对马尔可夫链预测的偏差,结合Local
Search的思想设计了基于更新预测序列的实时 调度算法.
一系列的数值实验验证了基于广义交箱序列的堆存模型以及优化算法的实用性与有效性,
为进 一步的深入研究打下了基础.
进一步的研究将在以下三方面展开: 其一为松弛,将每个客户的待集港集装箱分为"整栈"与"零散箱"分别处理的前
提条件; 其二尝试建立场桥作业移动距离与预翻箱数量之间的内在联系; 其三是结合装船信息,将场桥与
岸桥及集卡等其他资源进行集成调度优化.

图 7 预测交箱序列的更新 
图 8 "翻箱栈"调度前后堆存情况对比图 
图 9 整体堆存情况调度前后对比图 
图 10 算法收敛图 
图 11 混乱序列 
图 12 不同混乱等级下与两种调度策略的对比 
图 13 集港过程中与两种调度策略的预翻箱数对比 
图 14 不同混乱度下与两种调度策略的对比
| [1] | Kim K Y, Kim K H. A routing algorithm for a single transfer crane to load export containers onto a containership[J]. Computers & Industrial Engineering, 1997, 33(3-4): 673-676. |
| [2] | Kim K H, Kim K Y. An optimal routing algorithm for a transfer crane in port container terminals[J]. Transportation Science, 1999, 33(1): 17-33. |
| [3] | Kim K Y, Kim K H. Heuristic algorithm for routing yard-side equipment for minimizing loading times in container terminals[J]. Naval Research Logistics, 2003, 50(5): 498-514. |
| [4] | Narasimhan A, Palekar U S. Analysis and algorithms for the transtainer routing problem in container port operations[J]. Transportation Science, 2002, 36(1): 63-78. |
| [5] | Kim K H, Park Y M. A crane scheduling method for port container terminals[J]. European Journal of Operational Research, Part E, 2004, 156: 752-768. |
| [6] | Ng W C, Mark K L. An effective heuristic for scheduling a yard crane to handle jobs with different ready times[J]. Engineering Optimization, 2005, 37(8): 867-877. |
| [7] | 韩晓龙. 集装箱港口龙门吊的最优路径问题[J]. 上海海事大学学报, 2005, 26(2): 39-41. Han Xiaolong. Routing problem of transfer crane at container terminals[J]. Journal of Shanghai Maritime University, 2005, 26(2): 39-41. |
| [8] | Kim K H, Lee J S.Satisfying constraints for locating export containers in port container terminals[C]// International Conference on Computational Science and Its Applications, 2006: 564-573. |
| [9] | 何军良, 宓为建, 严伟.基于爬山算法的集装箱堆场场桥调度[J].上海海事大学学报, 2007, 28(4): 11-15. He Junliang, Mi Weijian, Yan Wei. Container yard crane scheduling based on hill-climbing algorithm[J]. Journal of Shanghai Maritime University, 2007, 28(4): 11-15. |
| [10] | 周鹏飞, 方波. 基于随机交箱序列的集装箱堆场出口箱箱位优选[J]. 沈阳工业大学学报, 2011, 33(6): 678-685. Zhou Pengfei, Fang Bo. Slot allocation optimization for export container in container storage yard based on stochastic delivery sequence[J]. Journal of Shenyang University of Technology, 2011, 33(6): 678-685. |
| [11] | 周鹏飞, 李丕安. 不确定条件下集装箱堆场出口箱具体箱位优选[J]. 工业工程, 2013, 16(1): 25-30. Zhou Pengfei, Li Pian. Slot allocation for export containers in container yard with arrival and leaving time uncertainties delivery sequence[J]. Industrial Engineering Journal, 2013, 16(1): 25-30. |