
Remote sensing image object detection based on MobileViT and multiscale feature aggregation
-
摘要: 针对遥感图像目标检测存在复杂背景干扰、微小目标提取难和目标多尺度差异问题,提出一种基于MobileViT和多尺度特征聚合的遥感图像目标检测算法(FWM-YOLOv7t)。首先设计多尺度特征聚合模块,建立遥感目标上下文依赖关系,提升多尺度目标和小目标检测精度;然后利用MobileViT模块,融合卷积神经网络和视觉Transformer优点,有效编码局部和全局信息,抑制非目标噪声干扰;最后引入Wise-IoU损失函数,重点关注普通质量锚框,提高算法检测性能。在公共数据集RSOD和NWPU VHR-10上的实验结果表明,FWM-YOLOv7t能够显著提升遥感图像目标检测的平均准确率。与其他目标检测算法相比,FWM-YOLOv7t对复杂背景目标、小目标和多尺度目标的检测更有效。
-
关键词:
- 深度学习 /
- 遥感图像 /
- 目标检测 /
- YOLOv7-tiny /
- MobileViT模块 /
- 多尺度特征融合 /
- 上下文信息 /
- Wise-IoU
Abstract: A new algorithm is proposed based on MobileViT and multi-scale feature aggregation (referred to as FWM-YOLOv7t) to address problems such as complex background interference, difficulty in extracting small objects, and object multi-scale differences in remote sensing image object detection. First, we design a multi-scale feature aggregation module to establish context dependencies for remote sensing targets, which improves the accuracy of detecting multi-scale and small targets. Then, we utilize the MobileViT module to fuse the advantages of convolutional neural networks and vision transformers for effective local and global information encoding to suppress non-target noise interference. Finally, we introduce the Wise-IoU loss function, which focuses on ordinary quality anchor boxes to enhance the detection performance of the algorithm. Experimental evaluations on the public RSOD and NWPU VHR-10 dataset demonstrate that FWM-YOLOv7t can significantly improve the average accuracy of remote sensing image target detection. Furthermore, compared with other object detection algorithms, the FWM-YOLOv7t algorithm exhibits superior effectiveness in detecting complex, small, and multiscale objects in remote sensing imagery. -
遥感图像的目标检测是一项重要的计算机视觉技术,旨在对图像中的物体进行识别和定位,在环境监测、土地规划和军事侦察等领域有着广阔的应用前景[1]。由于遥感图像场景变化剧烈、背景杂乱、物体尺度多变和环境因素等特点会导致各种不可预测的干扰,目标检测难度较大。因此,亟待设计一种精准且高效的遥感图像目标检测算法[2-3]。
传统的目标检测算法常采用滑动窗口进行区域选择,进而构建目标的特征表征,构建方法有尺度不变特征变换[4]和定向梯度直方图[5]等,然后使用分类器完成目标的检测。虽然传统目标检测算法理论较为完善,但其面对复杂场景仍有不足之处:一是滑动窗口区域选择缺乏针对性,造成窗口冗余严重,算法效率低下。二是基于手工设计的特征难以适应多样化的任务场景。随着深度学习快速发展,卷积神经网络(convolutional neural network, CNN)被广泛应用于计算机视觉等领域[6-7]。当前,以CNN为基础的目标检测算法分为一阶段算法和二阶段算法两大类。二阶段算法包括R-CNN(region-based convolutional neural network)[8]、Fast R-CNN[9]和Faster R-CNN[10]等,对目标检测精度高但速度慢。针对其缺点,Liu等学者提出SSD(single shot multibox detector)[11]、YOLO(you only look once)[12-14]系列等一阶段算法,删除生成候选区域阶段,直接完成目标位置和类别预测,提高检测实时性。吴萌萌等[15]在YOLOv5算法基础上设计自适应双向特征金字塔网络,引入可学习的特征融合因子动态调整各阶段特征图的融合权重,以增强模型的特征表示能力。但改进后的算法损失函数没有充分考虑数据集目标尺寸的长尾分布特点,导致模型对不同尺寸目标的检测能力存在差异,特别是对大目标的检测精度提高不明显。文献[16]改进YOLOX网络,引入自适应空间特征融合结构应对不同尺度目标检测问题,设计高效通道注意力模块,抑制无关背景信息,该网络虽然取得较好的检测效果,但仍存在微小目标特征信息丢失严重等问题。Wang等[17]构建YOLOX_w算法,使用切片辅助超推理(slicing aided hyper inference, SAHI)[18]对图像进行预处理以及数据增强,将包含丰富空间信息的浅层特征图引入特征融合结构,有效地提高检测小型物体的能力,但也导致模型实时性降低。上述算法虽然有不错的检测表现,但仍未较好地解决检测中复杂背景信息干扰、小尺寸目标检测难和目标尺度多变问题。
卷积操作的局部性限制了CNN获取全局上下文信息的能力。相反,Transformer可以全局关注不同区域图像特征之间的关系,并通过自注意力机制来提取充分的特征信息[19]。因此,研究人员尝试将Transformer应用于遥感图像目标检测。Zhu等[20]在YOLOv5算法基础上将原卷积预测头替换为Transformer预测头,集成卷积块注意力模块(convolutional block attention module, CBAM)以提高网络检测能力。Sahin等[21]增加检测层数量并在颈部网络头部引入视觉Transformer(vision Transformer, ViT)[22]解决小目标检测难的问题。上述模型在目标检测领域虽然有不错表现和贡献,但计算复杂度过高,网络实时性较差。因此,本文受此启发,引入轻量化MobileViT模块[23]嵌入算法主干网络底部,结合CNN和ViT的优点,捕获图像全局信息,减少计算复杂度。
综上所述,针对遥感图像检测中存在的问题,本文提出一种基于MobileViT和多尺度特征聚合的遥感图像目标检测算法(FWM-YOLOv7t)。首先设计多尺度特征聚合模块替换原模型中模块,以更好地学习不同尺度特征信息,增加网络对目标尺度多变的鲁棒性和微小目标的检测精度。然后为解决图像中复杂背景信息对检测的干扰,引入轻量化MobileViT模块,提高模型全局信息感知力的同时,抑制背景信息噪声。最后使用Wise-IoU损失函数以提高算法整体检测性能。
1. YOLOv7-tiny算法
2022年Wang等[14]提出YOLOv7算法,其检测速度和精度超越以往YOLO系列算法。根据应用场景与需求的不同,YOLOv7算法变体为tiny、x、d6、e6、w6等版本。其中,YOLOv7-tiny算法在YOLOv7基础上进行精简,相比于其他变体具有参数量低、检测速度快、硬件兼容性高等特点。鉴于遥感图像目标检测对资源占用、实时性能以及检测精度等多方面要求,本文选用轻量级算法YOLOv7-tiny作为基线模型,并对其进行改进。YOLOv7-tiny算法主要由输入端(input)、主干网络(backbone)、颈部网络(neck)和头部网络(head) 4部分组成,算法结构如图1所示。
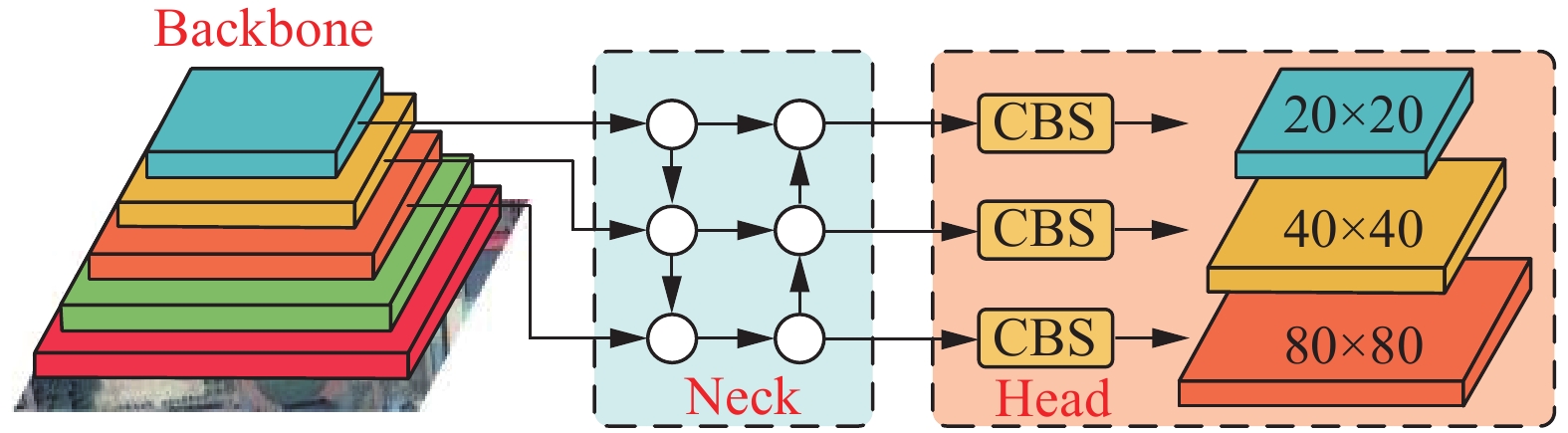 图 1 YOLOv7-tiny网络结构Fig. 1 YOLOv7-tiny network structure
图 1 YOLOv7-tiny网络结构Fig. 1 YOLOv7-tiny network structure 下载:
全尺寸图片
下载:
全尺寸图片
首先输入端通过马赛克、混合数据增强技术和自适应锚框计算等方法对输入图像进行预处理。然后主干网络采用若干卷积计算单元、高效层聚合网络(efficient layer aggregation networks, ELAN)和最大池化层交替组合提取图像特征信息。接着颈部网络利用路径聚合网络结构对主干提取的多尺度特征信息进行融合以提高检测精度和鲁棒性。最后头部网络对图像特征层预设不同大小的先验框,根据先验框中是否包含目标及其类别进行评分,筛选出满足置信度要求的预测框,并通过非极大抑制得到最终的预测框,输出目标检测结果。
2. FWM-YOLOv7t算法
2.1 算法设计
针对遥感图像中目标尺度变化大、微小目标提取难和非目标噪声干扰等问题,本文以YOLOv7-tiny为基础模型,提出基于MobileViT和多尺度特征聚合算法(FWM-YOLOv7t),算法结构如图2所示。首先设计多尺度特征聚合模块(multi-scale feature aggregation module, MFAM)替换ELAN,获取不同尺度显著性特征信息,增强对目标尺度变化的鲁棒性,提高算法对微小目标的敏感度。其次主干网络网络中引入融合CNN和Transformer优点的轻量化模型MobileViT替代尾部MFAM,抑制复杂背景信息干扰,扩展模型专注于不同位置能力,提升全局表达能力。最后通过Wise-IoU损失函数重点专注普通质量锚框,提高网络检测性能。
 图 2 FWM-YOLOv7t网络结构Fig. 2 FWM-YOLOv7t network structure下载:
全尺寸图片
图 2 FWM-YOLOv7t网络结构Fig. 2 FWM-YOLOv7t network structure下载:
全尺寸图片
2.2 多尺度特征聚合模块
在计算机视觉任务中,利用不同尺度卷积核对图片进行特征捕获来获得多尺度信息具有良好效果,针对不同尺度特征之间上下文信息易丢失、遥感图像小目标特征提取难的问题,本文设计一种多尺度特征聚合模块(MFAM),其结构如图3所示。
 图 3 多尺度特征聚合模块Fig. 3 Multi-scale feature aggregation module下载:
全尺寸图片
图 3 多尺度特征聚合模块Fig. 3 Multi-scale feature aggregation module下载:
全尺寸图片
MFAM通过不同尺寸的卷积核进行显著性特征信息提取。其中,为降低计算成本,有效提取遥感目标特征,利用多个连续的
$ 3 \times 3 $ 卷积替代$ 5 \times 5 $ 卷积和$ 7 \times 7 $ 卷积。同时,针对网络层数堆叠易出现网络退化和梯度爆炸等问题,引入跳跃连接,输出初始特征图,实现早期特征重用。输入遥感图像经5条并行支路进行特征提取后,可捕获多尺度特征信息。再通过Concat和$ 1 \times 1 $ 卷积操作对不同支路所包含的特征信息进行交互以实现跨支路的信息聚合,可进一步加强网络特征学习能力。其具体表达式为$$ \begin{gathered} {C_{i \times i}}\left( {{{\boldsymbol{P}}_{\mathrm{in}}}} \right) = {\mathrm{Cat}}\left[ {C_{1 \times 1}}\left( {{{\boldsymbol{P}}_{\mathrm{in}}}} \right),{C_{3 \times 3}}\left( {{{\boldsymbol{P}}_{\mathrm{in}}}} \right), \right.\\ \left.{C_{3 \times 3}}\left( {{C_{3 \times 3}}\left( {{{\boldsymbol{P}}_{\mathrm{in}}}} \right)} \right), {C_{3 \times 3}}\left( {{C_{3 \times 3}}\left( {{C_{3 \times 3}}\left( {{{\boldsymbol{P}}_{\mathrm{in}}}} \right)} \right)} \right) \right] \end{gathered} $$ $$ {{\boldsymbol{M}}_{\mathrm{out}}} = {C_{1 \times 1}}\left( {{\mathrm{Cat}}\left[ {{{\boldsymbol{P}}_{\mathrm{in}}},{C_{i \times i}}\left( {{{\boldsymbol{P}}_{\mathrm{in}}}} \right)} \right]} \right) $$ 式中:
$ {{\boldsymbol{P}}_{\mathrm{in}}} $ 表示多尺度特征聚合模块的输入,$ {C_{3 \times 3}}\left( \cdot \right) $ 表示卷积核尺寸$ 3 \times 3 $ 的卷积操作,$ {{\boldsymbol{M}}_{\mathrm{out}}} $ 表示多尺度特征聚合模块的输出。2.3 MobileViT模块
在遥感目标检测任务中,能否提取到更多的准确目标特征信息对检测结果非常重要。CNN使用固定尺寸的卷积核对图像进行局部特征建模,但随着网络层数增加,容易出现网络退化和梯度爆炸等问题。ViT通过Self-Attention编码图像全局特征,但具有较高的计算复杂性,导致模型实时性较差。
为捕获更多遥感图像目标像素,抑制背景噪声干扰,引入MobileViT(MViT)模块[23],如图4所示。MViT模块结合CNN和ViT的优点,同时使用卷积和自注意力机制,可以有效地将局部和全局信息进行编码,聚合和处理图像中特征信息,扩展模型专注于不同位置能力,具有全局感受野,提高目标检测能力。MViT模块由局部特征提取块、全局特征提取块和特征融合3部分组成。首先输入特征块
$ {{\boldsymbol{X}}_{\mathrm{I}}} \in {{\bf{R}}^{H \times W \times C}} $ 通过局部特征提取块进行特征建模,内部经过尺寸为$ n \times n $ 的卷积核进行局部建模,再通过$ 1 \times 1 $ 大小的卷积核将输入特征投影到高维空间得到特征块$ {{\boldsymbol{X}}_{\mathrm{L}}} \in {{\bf{R}}^{H \times W \times d}} $ 。在全局特征提取块部分,为学习具有空间归纳偏置,将局部特征块$ {{\boldsymbol{X}}_{\mathrm{L}}} \in {{\bf{R}}^{H \times W \times d}} $ 展开为$ N $ 个序列块$ {{\boldsymbol{X}}_{\mathrm{U}}} \in {{\bf{R}}^{P \times N \times d}} $ 输入到L组Transformer中编码图像全局特征,具体公式为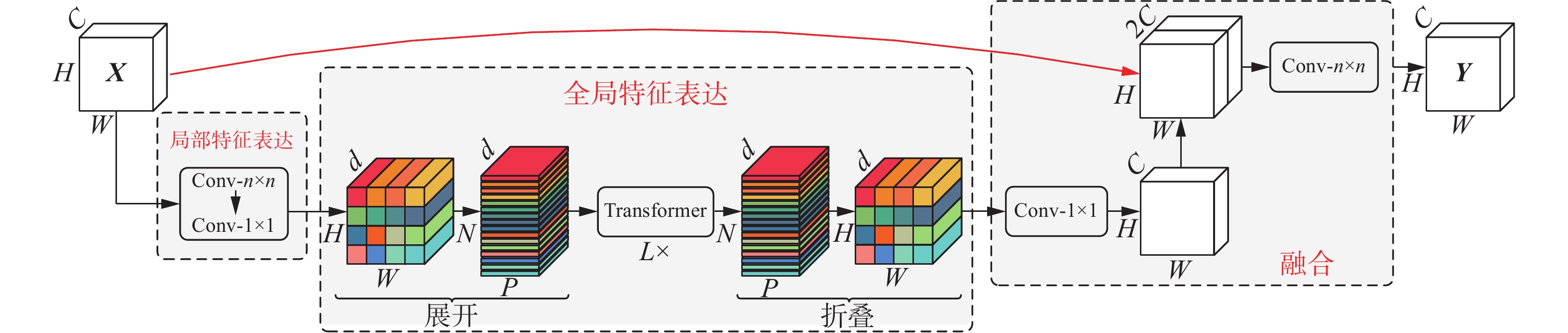 图 4 MobileViT模块Fig. 4 MobileViT module下载:
全尺寸图片
图 4 MobileViT模块Fig. 4 MobileViT module下载:
全尺寸图片
$$ {{\boldsymbol{X}}_{\mathrm{G}}}\left( p \right) = L \times {\mathrm{Trans}}\left( {{{\boldsymbol{X}}_{\mathrm{U}}}\left( p \right)} \right),p \in \left[ {1,P} \right] $$ 式中:
$ {{\boldsymbol{X}}_{\mathrm{G}}} $ 表示全局特征块,$ p $ 表示每个序列块中位置为$ p $ 的像素信息,L设置为3,详见3.4节实验分析。然后将输出的全局特征块$ {{\boldsymbol{X}}_{\mathrm{G}}} \in {{\bf{R}}^{P \times N \times d}} $ 折叠还原得到$ {{\boldsymbol{X}}_{\mathrm{F}}} \in {{\bf{R}}^{H \times W \times d}} $ 。最后通过逐点卷积对通道进行投影还原,经通道拼接操作建立输入特征块和全局特征块的上下文依赖关系,最终通过$ n \times n $ 大小卷积核融合全局和局部特征实现对遥感目标特征的提取,其数学表达式为$$ {{\boldsymbol{X}}_{\mathrm{O}}} = {C_{n \times n}}\left( {{\mathrm{Cat}}\left( {{{\boldsymbol{X}}_{\mathrm{I}}},{C_{1 \times 1}}\left( {{{\boldsymbol{X}}_{\mathrm{F}}}} \right)} \right)} \right) $$ 式中:
$ {{\boldsymbol{X}}_{\mathrm{O}}} $ 表示输出融合特征块,$ {C_{1 \times 1}}\left( \cdot \right) $ 表示卷积核尺寸$ 1 \times 1 $ 的卷积操作,${\mathrm{Cat}}\left( \cdot \right)$ 表示特征块通道维度进行拼接操作,$ {C_{n \times n}}\left( \cdot \right) $ 表示卷积核尺寸$ n \times n $ 的卷积操作。图4中的Transformer由多头自注意力模块和全连接前馈网络2部分构成,每一部分均进行归一化处理,并采用残差结构,形成跳跃连接,提升模型检测效果。多头自注意力机制的运算公式为
$$ A\left( {{\boldsymbol{Q}},{\boldsymbol{K}},{\boldsymbol{V}}} \right) = {\mathrm{softmax}}\left( {{{{\boldsymbol{Q}}{{\boldsymbol{K}}^{\mathrm{T}}}} \mathord{\left/ {\vphantom {{Q{K^T}} {\sqrt {{d_k}} }}} \right. } {\sqrt {{d_k}} }}} \right){\boldsymbol{V}} $$ $$ {H_i} = A\left( {{\boldsymbol{QW}}_i^{\boldsymbol{Q}},{\boldsymbol{KW}}_i^{\boldsymbol{K}},{\boldsymbol{VW}}_i^{\boldsymbol{V}}} \right),i = 1,2, \cdot \cdot \cdot ,h $$ $$ {M_{{\text{MultiHead}}}}\left( {{\boldsymbol{Q}},{\boldsymbol{K}},{\boldsymbol{V}}} \right) = {\mathrm{Cat}}\left( {{H_1}, {H_2}, \cdots ,{H_h}} \right){{\boldsymbol{W}}^{\mathrm{O}}} $$ 式中:
$ {\boldsymbol{Q}} $ 、$ {\boldsymbol{K}} $ 、$ {\boldsymbol{V}} $ 分别表示查询、键和值向量,$ {d_k} $ 表示缩放因子,$ A\left( \cdot \right) $ 表示进行自注意力运算,$ {\boldsymbol{W}}_i^{\boldsymbol{Q}} $ 、$ {\boldsymbol{W}}_i^{\boldsymbol{K}} $ 和$ {\boldsymbol{W}}_i^{\boldsymbol{V}} $ 表示线性变换的权重矩阵,$ \boldsymbol{W}\mathrm{^O} $ 表示输出的权重矩阵,$ {M_{{\text{MultiHead}}}}\left( \cdot \right) $ 表示进行多头自注意力运算。2.4 Wise-IOU损失函数
定位损失函数在目标检测中起到关键作用,其合理的定义将为网络带来显著的性能提升。YOLOv7-tiny网络采用Complete-IoU(CIoU)[24]计算定位损失,CIoU考虑了重叠面积、归一化中心点距离和纵横比3个几何因素,但训练数据中不可避免的会包含低质量示例,归一化中心距离和纵横比等几何因素会加重对低质量示例的惩罚,从而降低模型的泛化能力。
为使预测框回归过程聚焦普通质量锚框,增强模型泛化能力,本文引入Wise-IoU损失函数(WIoU)[25]。WIoU使用离散度来评估锚框质量,并根据离散度动态分配梯度增益,降低高质量锚框的竞争力和低质量示例产生的有害梯度,重点关注普通质量锚框,以提高网络的检测性能。WIoU具体表达式为
$$ {\mathcal{L}_{{\mathrm{WIoU}}}} = \frac{\beta }{{\delta {\alpha ^{\beta - \delta }}}}\exp \left( {\frac{{{{\left( {x - {x_{{\text{gt}}}}} \right)}^2} + {{\left( {y - {y_{{\text{gt}}}}} \right)}^2}}}{{{{\left( {W_{\text{g}}^2 + H_{\text{g}}^2} \right)}^ * }}}} \right)\left( {1 - {I_{{\text{oU}}}}} \right) $$ $$ \beta = {{\mathcal{L}_{{\text{IoU}}}^ * } \mathord{\left/ {\vphantom {{\mathcal{L}_{{\text{IoU}}}^ * } { {\overline{\mathcal{L}}_{{\text{IoU}}}} }}} \right. } { {\overline{\mathcal{L}}_{{\text{IoU}}}} }} \in \left[ {0, + \infty } \right) $$ 式中:
$ {\mathcal{L}_{{\mathrm{WIoU}}}} $ 表示定位损失函数值,$ \alpha $ 和$ \delta $ 表示超参数,$ \beta $ 表示离群度,$ x $ 和$ y $ 表示预测框的中心坐标,$ {x_{{\text{gt}}}} $ 和$ {y_{{\text{gt}}}} $ 表示真实框的中心坐标,$ {W_{\text{g}}} $ 和$ {H_{\text{g}}} $ 分别表示包围真实框和预测框最小矩形的宽高,$ * $ 表示将$ {W_{\text{g}}} $ 和$ {H_{\text{g}}} $ 从梯度计算中分离出来,$ {I_{{\text{oU}}}} $ 表示预测框和真实框的交并比,$ \mathcal{L}_{{\text{IoU}}}^ * $ 表示单调聚焦系数,$ {\overline{\mathcal{L}}_{{\text{IoU}}}} $ 表示动量为m的滑动平均值。m的数学表达为$$ m = 1 - \sqrt[{tn}]{{0.5}} $$ 式中:t为平均准确率均值提升明显减慢的轮次,n为批次数量,
$ t \times n $ 为7000 。3. 实验
3.1 实验环境与参数设定
实验基于PyTorch2.0.0框架和Python3.8.16语言进行编程实现,处理器为Intel(R) Core(TM) i9-13900H @2.60 GHz、显卡为NVIDIA GeForce RTX 4060、显存为8 GB。实验设置输入图像分辨率为640像素×640像素,初始学习率为0.01,动量参数为0.937,权重衰减系数为
0.0005 ,训练轮次为300,批量大小为16,WIoU损失函数超参数$ \alpha $ 和$ \delta $ 通过迭代最优解分别设为1.9和3。3.2 实验数据集
实验使用武汉大学标注的数据集RSOD[26]进行训练验证,该数据集涵盖976张遥感图像,覆盖飞机、油桶、操场、立交桥4种目标,共6 950个标注样本信息。为验证模型的泛化性,使用西北工业大学标注的数据集NWPU VHR-10[27]进行实验,该数据集包含目标的图像共650张,涵盖飞机、油罐、船只、田径场、网球场、棒球场、篮球场、桥梁、港口和车辆10类目标,共3 651个标注样本信息。2个数据集均采用8∶2比例随机划分训练集和验证集。
3.3 评价指标
为实现对遥感目标检测结果的量化评价和分析,本文用准确率(precision, P)、召回率(recall, R)、平均准确率(average precision, AP)、平均准确率均值(mean average precision, mAP)和检测速度(每秒处理图像数量)等评价指标进行比较分析。AP和mAP分别表示模型在单类和多类目标检测的精确度,mAP@0.5表示交并比(intersection over union, IoU)阈值为0.5时的平均准确率均值,其计算式分别为
$$ P = \frac{{{N_{{\text{TP}}}}}}{{{N_{{\text{TP}}}} + {N_{{\text{FP}}}}}} $$ $$ R = \frac{{{N_{{\text{TP}}}}}}{{{N_{{\text{TP}}}} + {N_{{\text{FN}}}}}} $$ $$ {A_{{\text{AP}}}} = \int\limits_0^1 {P\left( R \right)} {\mathrm{d}}R $$ $$ {M_{{\text{mAP}}}} = \frac{1}{N}\sum\limits_{i = 1}^N {A_{{\text{AP}}}^i} $$ 式中:
$ {A_{{\text{AP}}}} $ 表示平均准确率,$ {M_{{\text{mAP}}}} $ 表示平均准确率均值,$ {N_{{\text{TP}}}} $ 表示正类样本被检测为正类的数量,即模型检测成功的遥感目标;$ {N_{{\text{FN}}}} $ 表示正类样本被检测为负类的数量,即模型漏检的遥感目标;$ {N_{{\text{FP}}}} $ 表示负类样本被检测为正类的数量,即模型误检的遥感目标;N表示数据集中目标类别数。3.4 消融实验
为探究MobileViT模块中Transformer层数对实验结果的影响,在RSOD数据集上对重叠因子L进行对比实验,检测结果如表1所示,其中加粗表示该项的最佳指标。M0表示YOLOv7-tiny引入MFAM,并以此为对比基准;M1(L=k)表示在M0基础上加入包含k层Transformer的MobileViT模块。观察表1可知,随着Transformer层数的增加,参数量也随之增加,但平均准确率均值并非与之呈正相关。因此,在综合考虑参数量和平均准确率均值的平衡关系,本文选用L=3时的MobileViT模块作为最优方案。
表 1 重叠因子L对比分析Table 1 Comparative analysis of overlap factor L模型 准确率/ % 召回率/ % mAP@0.5/% 参数量/106 M0 94.6 94.3 97.0 7.9 M1(L=1) 95.5 94.5 97.0 7.6 M1(L=2) 96.2 94.8 97.6 8.1 M1(L=3) 96.6 95.1 97.8 8.6 M1(L=4) 95.5 92.3 97.4 9.1 M1(L=5) 93.1 93.5 96.5 9.6 为更好地检验本文提出模型的有效性,使用RSOD数据集进行消融实验对比,检测得到的准确率、召回率、平均准确率和mAP@0.5,如表2所示,其中加粗表示此项的最优指标。A1表示YOLOv7-tiny,A2表示设计MFAM替换A1模型中ELAN,A3表示引入MViT模块代替A2模型主干网络尾部的MFAM,A4表示在A3中引入WIoU损失函数,构成本文模型。
表 2 消融实验数据Table 2 Ablation experimental data% 模型 准确率 召回率 平均准确率 mAP@0.5 飞机 油桶 立交桥 操场 A1 90.9 94.1 98.7 97.2 89.2 98.0 95.8 A2 94.6 94.3 98.9 98.3 92.3 98.6 97.0 A3 96.6 95.1 98.7 97.5 95.6 99.2 97.8 A4 96.0 95.3 98.9 97.5 97.0 99.2 98.1 由表2可知,YOLOv7-tiny模型对遥感目标具有良好的检测效果,初始模型检测飞机和操场遥感目标已经达到98.7%和98.0%的平均准确率,但其准确率、召回率在模型结构固定的情况下仍然较低,检测复杂背景下立交桥遥感目标的平均准确率仍有提升空间,于是本文对初始模型进行改进,以提高模型性能。通过设计MFAM替换A1内部ELAN,各项指标均有提升,其中准确率提升3.7百分点,检测飞机和油桶遥感目标的平均准确率达到该项最优。说明MFAM充分融合多尺度特征信息,减少信息丢失,提升飞机小目标和多尺度检测能力。在A2基础上引入MViT模块,准确率、召回率和检测复杂背景下立交桥遥感目标的平均准确率有所提升,其中准确率达到最优值,检测立交桥的平均准确率提升3.3百分点,说明MViT模块可以有效地捕捉复杂背景下目标,具有全局敏感性。最后引入WIoU损失函数,召回率、平均准确率均值达到各项最优,说明模型预测框回归过程聚焦普通质量锚框可提高模型整体性能。
综上所述,本文提出的模型与基线模型相比准确率、召回率和平均准确率均值均有显著提升,分别提升5.1百分点、1.2百分点和2.3百分点,证明本文提出模型的有效性和合理性。
3.5 多种模型检测结果与分析
3.5.1 定量分析
为客观评价本文提出模型的优势,将其他目标检测算法同本文模型FWM-YOLOv7t应用于RSOD数据集,实验得到的参数量、检测速度、平均准确率和mAP@0.5如表3所示,其中加粗表示此项的最优指标。
表 3 不同算法检测数据对比Table 3 Comparison of detection data from different algorithms模型 参数量/M 检测速度/(f/s) 平均准确率/% mAP@0.5/% 飞机 油桶 立交桥 操场 Faster R-CNN[10] 72.0 7 77.4 97.9 94.5 100.0 92.5 SSD[11] 24.4 41 68.6 96.5 90.2 99.8 88.8 YOLOv3[12] 61.5 24 96.1 97.8 91.5 95.9 95.3 YOLOv4-tiny[13] 6.1 50 70.7 97.3 61.7 99.1 82.4 YOLOv5l 46.6 29 96.4 96.5 89.5 97.8 95.0 YOLOv5s 7.0 85 95.2 96.2 84.8 97.1 93.3 YOLODrone+[21] 153.1 22 97.7 99.2 84.8 99.5 95.3 YOLOv7[14] 36.5 27 99.2 97.4 94.6 99.5 97.7 YOLOv7-tiny[14] 6.0 79 98.7 97.2 89.2 98.0 95.8 FWM-YOLOv7t 8.6 77 98.9 97.5 97.0 99.2 98.1 观察表3可知,本文提出模型相较于Faster R-CNN、SSD、YOLOv3、YOLOv5l、YOLOv7算法,在参数量、检测速度和mAP@0.5这3个指标上都具有明显优势。与YOLOv4-tiny算法相比,虽然本文算法参数规模上略有扩增,但检测速度和mAP@0.5显著提高,其中检测速度增长27 f/s,mAP@0.5提升15.7百分点。同YOLOv5s、YOLOv7-tiny算法比较,在牺牲较少参数量的情况下,保持检测速度基本不变,mAP@0.5指标分别增长4.8百分点、2.3百分点。
YOLODrone+基于YOLOv5s算法,在其颈部网络头部引入ViT模块,同时增加检测头数量。文献[21]在VisDrone数据集中实验证明YOLODrone+相比基线算法YOLOv5s可有效提升小目标检测精度。为检验该模型的有效性,本文在RSOD数据集上进行实验,发现各类别准确率AP均有提高,但模型参数量过大,检测速度明显降低。本文提出模型在参数量、检测速度和mAP@0.5指标上都优于YOLODrone+算法,其中mAP@0.5增长2.8百分点。
在各个类别的检测结果中,本文提出的模型对于具有复杂背景的立交桥遥感目标取得了比其他算法更优的结果,优于基线YOLOv7-tiny模型7.8百分点。对于包含多尺度和微小目标的飞机类别,平均准确率值达到98.9%,虽略低于YOLOv7算法,但优于其他算法,和基线YOLOv7-tiny模型比较有小幅提升。
3.5.2 定性分析
为直观展现本文提出模型的检测效果,将本文模型FWM-YOLOv7t同其他目标检测算法在遥感图片上进行检测,检测结果如图5所示。其中,第1、4行表示背景复杂遥感图像,第2、5行表示微小目标遥感图像,第3、6行表示多尺度目标遥感图像。图5(a)~(j)分别表示原图、Faster R-CNN算法、SSD算法、YOLOv3算法、YOLOv4-tiny算法、YOLOv5s算法、YOLODrone+算法、YOLOv7算法、YOLOv7-tiny算法和FWM-YOLOv7t算法的检测结果图。
 图 5 不同算法遥感目标检测结果Fig. 5 Remote sensing target detection results of different algorithms下载:
全尺寸图片
图 5 不同算法遥感目标检测结果Fig. 5 Remote sensing target detection results of different algorithms下载:
全尺寸图片
由图5分析可知,在第1、4行复杂背景下遥感图像目标检测结果中,SSD算法、YOLOv3算法、YOLOv4-tiny算法和YOLOv5s算法存在目标漏检现象;YOLODrone+算法出现误检问题;Faster R-CNN算法、YOLOv7算法、YOLOv7-tiny算法和FWM-YOLOv7t算法均能有效检测出立交桥目标,其中FWM-YOLOv7t算法和Faster R-CNN算法在检测立交桥目标时表现出最高的置信度。
在第2、5行微小目标检测结果中,Faster R-CNN算法、YOLOv3算法和YOLODrone+算法有较多的重叠框问题;SSD算法和YOLOv4-tiny算法存在着目标漏检状况,其中SSD算法对小目标特征信息丢失严重,导致漏检率较高;YOLOv5s算法和YOLOv7-tiny算法出现对无关物体误检现象;而FWM-YOLOv7t算法和YOLOv7算法能够有效地捕获微小目标特征信息,实现目标的精准检测。
在第3、6行多尺度目标检测结果中,Faster R-CNN算法、SSD算法、YOLOv4-tiny算法和YOLOv7-tiny算法表现不佳,均出现目标漏检现象;YOLODrone+算法能够较好地检测出多尺度目标,但存在着重叠框问题;YOLOv5s算法对不相关物体产生误检;而FWM-YOLOv7t算法、YOLOv3算法和YOLOv7算法准确无误地检测出所有目标,说明3种算法对目标尺度变化更具鲁棒性。
综合分析,本文提出模型FWM-YOLOv7t相较于其他目标检测算法不仅有良好的检测精度,且具有较低参数量和较快检测速度。此外,在面对复杂背景、微小目标以及多尺度目标时表现出更卓越的检测能力,其综合检测结果优于其他对比算法。
3.6 泛化性验证
为进一步验证本文提出模型的泛化能力,将模型YOLOv7、YOLOv7-tiny与本文模型FWM-YOLOv7t在NWPU VHR-10数据集上进行实验对比,实验结果如表4所示,其中加粗表示此项的最优指标。
通过对表4分析可知,相比于YOLOv7模型,FWM-YOLOv7t在参数量较小的情况下,尽管召回率略有下降,但其准确率增长3.6百分点,且mAP@0.5值基本持平。FWM-YOLOv7t相较于基准算法YOLOv7-tiny虽参数量略有增加,召回率基本保持不变,但准确率提升2.2百分点,mAP@0.5值提升1.7百分点。此外,本文模型检测速度达到91 f/s,具有较强的实时性能,能够适应实际应用场景的需求。
本文模型和YOLOv7-tiny算法对不同目标类别检测的平均准确率如图6所示。从图6可以看出,在对涵盖复杂背景环境的目标类别,例如桥梁、港口以及网球场进行检测时,本文模型取得比YOLOv7-tiny算法更显著的结果,分别实现4.8百分点、5.5百分点和1.1百分点的提升。对于包含多尺度目标和微小目标的船只类别,其检测结果也优于YOLOv7-tiny算法1.5百分点。
 图 6 不同目标类别检测平均准确率结果Fig. 6 Average accuracy results for detection of different target categories下载:
全尺寸图片
图 6 不同目标类别检测平均准确率结果Fig. 6 Average accuracy results for detection of different target categories下载:
全尺寸图片
实验结果表明,FWM-YOLOv7t不仅在RSOD数据集中展现出优异的目标检测表现,在其他类别的数据集上,也表现出显著的性能提高,其泛化性能优异。
4. 结束语
针对遥感图像目标检测时存在背景信息干扰、小尺寸目标提取难和目标尺度多变问题,本文提出FWM-YOLOv7t模型。首先使用多尺度特征聚合模块替代网络中ELAN,提取图像不同尺度的特征信息,搭建目标上下文关系,提高对多尺度目标和微小目标的检测精度。然后在主干网络网络中加入MobileViT模块替换尾部MFAM,实现对非目标信息的抑制,关注遥感目标的特征信息。最后引入Wise-IoU损失函数以提高模型整体性能。通过RSOD数据集实验,FWM-YOLOv7t相较于基线算法YOLOv7-tiny,mAP@0.5提升2.3百分点,说明FWM-YOLOv7t对提高遥感目标整体检测效果的有效性;通过NWPU VHR-10数据集实验,mAP@0.5提升1.7百分点,表明FWM-YOLOv7t的泛化能力强;在包含复杂背景的桥梁、港口、网球场目标类别和具有多尺度目标和微小目标的船只类别上,平均准确率均显著提高,得出FWM-YOLOv7t可以有效应对遥感图像目标检测问题。但本文提出模型在轻量化方面仍有改进空间。保持模型高速度的同时,实现高精度和轻量化的平衡,将是今后的探索方向,从而更好满足工业场景的需求。
-
图 1 YOLOv7-tiny网络结构
Fig. 1 YOLOv7-tiny network structure
下载:
全尺寸图片
图 2 FWM-YOLOv7t网络结构
Fig. 2 FWM-YOLOv7t network structure
下载:
全尺寸图片
图 3 多尺度特征聚合模块
Fig. 3 Multi-scale feature aggregation module
下载:
全尺寸图片
图 4 MobileViT模块
Fig. 4 MobileViT module
下载:
全尺寸图片
图 5 不同算法遥感目标检测结果
Fig. 5 Remote sensing target detection results of different algorithms
下载:
全尺寸图片
图 6 不同目标类别检测平均准确率结果
Fig. 6 Average accuracy results for detection of different target categories
下载:
全尺寸图片
表 1 重叠因子L对比分析
Table 1 Comparative analysis of overlap factor L
模型 准确率/ % 召回率/ % mAP@0.5/% 参数量/106 M0 94.6 94.3 97.0 7.9 M1(L=1) 95.5 94.5 97.0 7.6 M1(L=2) 96.2 94.8 97.6 8.1 M1(L=3) 96.6 95.1 97.8 8.6 M1(L=4) 95.5 92.3 97.4 9.1 M1(L=5) 93.1 93.5 96.5 9.6 表 2 消融实验数据
Table 2 Ablation experimental data
% 模型 准确率 召回率 平均准确率 mAP@0.5 飞机 油桶 立交桥 操场 A1 90.9 94.1 98.7 97.2 89.2 98.0 95.8 A2 94.6 94.3 98.9 98.3 92.3 98.6 97.0 A3 96.6 95.1 98.7 97.5 95.6 99.2 97.8 A4 96.0 95.3 98.9 97.5 97.0 99.2 98.1 表 3 不同算法检测数据对比
Table 3 Comparison of detection data from different algorithms
模型 参数量/M 检测速度/(f/s) 平均准确率/% mAP@0.5/% 飞机 油桶 立交桥 操场 Faster R-CNN[10] 72.0 7 77.4 97.9 94.5 100.0 92.5 SSD[11] 24.4 41 68.6 96.5 90.2 99.8 88.8 YOLOv3[12] 61.5 24 96.1 97.8 91.5 95.9 95.3 YOLOv4-tiny[13] 6.1 50 70.7 97.3 61.7 99.1 82.4 YOLOv5l 46.6 29 96.4 96.5 89.5 97.8 95.0 YOLOv5s 7.0 85 95.2 96.2 84.8 97.1 93.3 YOLODrone+[21] 153.1 22 97.7 99.2 84.8 99.5 95.3 YOLOv7[14] 36.5 27 99.2 97.4 94.6 99.5 97.7 YOLOv7-tiny[14] 6.0 79 98.7 97.2 89.2 98.0 95.8 FWM-YOLOv7t 8.6 77 98.9 97.5 97.0 99.2 98.1 -
[1] 赵文清, 康怿瑾, 赵振兵, 等. 改进YOLOv5s的遥感图像目标检测[J]. 智能系统学报, 2023, 18(1): 86−95. doi: 10.11992/tis.202203013 ZHAO Wenqing, KANG Yijin, ZHAO Zhenbing, et al. A remote sensing image object detection algorithm with improved YOLOv5s[J]. CAAI transactions on intelligent systems, 2023, 18(1): 86−95. doi: 10.11992/tis.202203013 [2] MING Qi, MIAO Lingjuan, ZHOU Zhiqiang, et al. CFC-net: a critical feature capturing network for arbitrary-oriented object detection in remote-sensing images[J]. IEEE transactions on geoscience and remote sensing, 2022, 60: 5605814. [3] CONG Runmin, ZHANG Yumo, FANG Leyuan, et al. RRNet: relational reasoning network with parallel multiscale attention for salient object detection in optical remote sensing images[J]. IEEE transactions on geoscience and remote sensing, 2021, 60: 5613311. [4] SEDAGHAT A, EBADI H. Remote sensing image matching based on adaptive binning SIFT descriptor[J]. IEEE transactions on geoscience and remote sensing, 2015, 53(10): 5283−5293. doi: 10.1109/TGRS.2015.2420659 [5] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego: IEEE, 2005: 886−893. [6] 吴珺, 董佳明, 刘欣, 等. 注意力优化的轻量目标检测网络及应用[J]. 智能系统学报, 2023, 18(3): 506−516. doi: 10.11992/tis.202206014 WU Jun, DONG Jiaming, LIU Xin, et al. Lightweight object detection network and its application based on the attention optimization[J]. CAAI transactions on intelligent systems, 2023, 18(3): 506−516. doi: 10.11992/tis.202206014 [7] 梁礼明, 詹涛, 雷坤, 等. 多分辨率融合输入的U型视网膜血管分割算法[J]. 电子与信息学报, 2023, 45(5): 1795−1806. LIANG Liming, ZHAN Tao, LEI Kun, et al. Multi-resolution fusion input U-shaped retinal vessel segmentation algorithm[J]. Journal of electronics & information technology, 2023, 45(5): 1795−1806. [8] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 580−587. [9] GIRSHICK R. Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 1440−1448. [10] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137−1149. doi: 10.1109/TPAMI.2016.2577031 [11] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[C]//European Conference on Computer Vision. Cham: Springer, 2016: 21−37. [12] FARHADI A, REDMON J. YOLOv3: an incremental improvement[C]//2018 IEEE/CVF Conference on Compu- ter Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 1804−2767. [13] BOCHKOVSKIY A, WANG C Y, LIAO H M, et al. YOLOv4: optimal speed and accuracy of object detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 2−7. [14] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 7464−7475. [15] 吴萌萌, 张泽斌, 宋尧哲, 等. 基于自适应特征增强的小目标检测网络[J]. 激光与光电子学进展, 2023, 60(6): 65−72. WU Mengmeng, ZHANG Zebin, SONG Yaozhe, et al. Small-target detection network based on adaptive feature enhancement[J]. Laser & optoelectronics progress, 2023, 60(6): 65−72. [16] 李美霖, 芮杰, 金飞, 等. 基于改进YOLOX的遥感影像目标检测算法[J]. 吉林大学学报(地球科学版), 2023, 53(4): 1313−1322. LI Meilin, RUI Jie, JIN Fei, et al. Remote sensing image target detection algorithm based on improved YOLOX[J]. Journal of Jilin University (earth science edition), 2023, 53(4): 1313−1322. [17] WANG Xin, HE Ning, HONG Chen, et al. Improved YOLOX-X based UAV aerial photography object detection algorithm[J]. Image and vision computing, 2023, 135: 104697. doi: 10.1016/j.imavis.2023.104697 [18] AKYON F C, ONUR ALTINUC S, TEMIZEL A. Slicing aided hyper inference and fine-tuning for small object detection[C]//2022 IEEE International Conference on Image Processing. Bordeaux: IEEE, 2022: 966−970. [19] 梁礼明, 何安军, 朱晨锟, 等. 融合Transformer和跨级相位感知的结肠息肉分割方法[J]. 生物医学工程学杂志, 2023, 40(2): 234−243. doi: 10.7507/1001-5515.202211067 LIANG Liming, HE Anjun, ZHU Chenkun, et al. Colorectal polyp segmentation method based on fusion of transformer and cross-level phase awareness[J]. Journal of biomedical engineering, 2023, 40(2): 234−243. doi: 10.7507/1001-5515.202211067 [20] ZHU Xingkui, LYU Shuchang, WANG Xu, et al. TPH-YOLOv5: improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios[C]//2021 IEEE/CVF International Conference on Computer Vision Workshops. Montreal: IEEE, 2021: 2778−2788. [21] SAHIN O, OZER S. YOLODrone: improved YOLO architecture for object detection in UAV images[C]//2022 30th Signal Processing and Communications Applications Conference. Safranbolu: IEEE, 2022: 1−4. [22] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale[C]//International Conference on Learning Representations. NewOrleans: ICLR, 2021: 1−22. [23] MEHTA S, RASTEGARI M. MobileViT: light-weight, general-purpose, and mobile-friendly vision transformer[EB/OL]. (2021−10−05)[2023−10−17]. https://arxiv.org/abs/2110.02178. [24] ZHENG Zhaohui, WANG Ping, LIU Wei, et al. Distance-IoU loss: faster and better learning for bounding box regression[C]//Proceedings of the AAAI Conference on Artificial Intelligence. New York: AAAI, 2020: 12993−13000. [25] TONG Zanjia, CHEN Yuhang, XU Zewei, et al. Wise-IoU: bounding box regression loss with dynamic focusing mechanism[EB/OL]. (2023−01−24)[2023−10−17]. https://arxiv.org/abs/2301.10051. [26] LONG Yang, GONG Yiping, XIAO Zhifeng, et al. Accurate object localization in remote sensing images based on convolutional neural networks[J]. IEEE transactions on geoscience and remote sensing, 2017, 55(5): 2486−2498. doi: 10.1109/TGRS.2016.2645610 [27] CHENG Gong, ZHOU Peicheng, HAN Junwei. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images[J]. IEEE transactions on geoscience and remote sensing, 2016, 54(12): 7405−7415. doi: 10.1109/TGRS.2016.2601622











































































