
Aspect-based sentiment analysis model based on multilevel knowledge enhancement
-
摘要: 在方面级情感分析任务中,现有研究侧重于挖掘评论语句的语义信息和句法依赖约束,未能综合考虑情感知识、概念知识和单词之间的句法依赖类型对方面情感倾向判别准确性的影响。针对这一问题,提出一种基于多层次知识增强的方面级情感分析模型(multilevel knowledge enhancement,MLKE),利用外部知识对评论语句进行情感、句法和概念3个层次的知识增强。首先,利用情感知识及单词之间的依赖类型来增强句子的依赖图,并通过图卷积网络建模节点特征,得到情感和句法增强的特定方面表征;其次,利用概念图谱对方面词概念增强后,与特定方面表征进行融合,得到多层次知识增强的方面表征;最后,采用交互注意力机制实现上下文表征与方面表征之间的协调优化。5个公共数据集上的实验结果表明,所提模型的准确率和宏F1值均得到提高。Abstract: In aspect-based sentiment analysis tasks, mining semantic information and syntactic dependency constraints from comment sentences is a key focus in existing research. However, this often underestimates the influence of comprehensive factors, including sentiment knowledge, conceptual knowledge, and syntactic dependency types between words on aspect sentiment orientation judgment. To address this problem, we propose an aspect-based sentiment analysis model based on multilevel knowledge enhancement (MLKE), which uses external knowledge to enhance the knowledge of comment sentences on three levels: sentiment, syntax, and concept. First, sentiment knowledge and the dependency types between words are employed to enhance the dependency graph of sentences. Specific aspect representations containing sentiment and syntactic enhancements are obtained through graph convolution networks that model modular node features. Second, to obtain multilevel knowledge-enhanced aspect representation, the concept graph is used to enhance the conceptual understanding of aspect words, and then the aspect word representation is fused with the specific aspect representation obtained in the previous step. Finally, the coordination and optimization between context representation and aspect representation is achieved using an interactive attention mechanism. The experimental results show that the accuracy and macro-F1 values of the model are improved on five datasets.
-
方面级情感分析(aspect-based sentiment analysis, ABSA)任务旨在将评论语句中的方面词与意见词之间建立联系,从而对特定方面的情感极性做出判断[1-2]。例如,在句子“The food is very good but the price are unreasonable.”中提到了两个方面,分别为“food”和“price”,前者对应的观点词为“good”,相应的情感极性为积极;而后者的意见词为“unreasonable”,则含有消极情感。
早期研究中,ABSA任务主要对句子的语义信息建模,采用神经网络模型和注意力机制捕捉句子的语义关联,从而判别特定方面的情感极性[3-4]。但注意力机制在方面词较多的长句中,可能会错误地关注无关的情感线索。例如:“This screen looks very good, but the sound is below average.”,在判断“sound”的情感极性时,注意力机制容易忽略否定连词“but”的作用,反而分配“good”较大的权重,导致对方面“sound”的情感倾向判别错误。而句法依存树能够提供单词之间的依存关系和依赖类型,结合句法依存树,方面词就可以准确关注到与自身有依赖关系的上下文词。
最近的研究中,图卷积神经网络(graph convolutional network,GCN)被广泛应用到ABSA任务当中,来处理句法依存树这类图结构信息[5-8],并取得了较好的效果。但大多方法仅关注词与词之间是否存在依赖关系,并未充分利用单词之间依赖关系的类型。实际上,句子中的方面词可能与多个上下文词都存在依赖关系,但这些上下文词对判别方面情感极性的贡献应该是不同的,模型应更关注针对方面词的意见词(例如形容词)。将单词之间的依赖类型融入到依赖图的构建[9],模型就可以根据词与词之间的依赖类型准确地关注到与方面有关的上下文情感线索,进而做出正确的判断。神经网络模型虽然能够集成句子的语义和语法信息,然而由于短评论文本自身语义信息不丰富,所提供的特征有限,因此需要利用外部知识丰富句子的特征表示。在ABSA任务中,SenticNet[10-11]情感词典被广泛应用于增强文本的情感表征[12]。知识图谱也被用于情感分析,利用外部知识解决词语的一词多义问题及对句子中可能涉及的概念进行增强表示[13-14]。
综合上述考虑,本文提出一种基于多层次知识增强(multilevel knowledge enhancement, MLKE)的方面级情感分析模型。利用多种外部知识对评论语句的上下文和方面进行增强表示,进而提高模型的分类能力。本文主要贡献如下:
1) 提出一种多层次知识增强的图神经网络,通过融入情感、句法、概念3个层次的外部知识来丰富文本语义表征。
2) 采用交互注意力机制协调优化上下文表征和方面增强的特征表示,充分融合了情感知识、句法知识和概念知识。
3) 在5个ABSA任务公开数据集上的实验结果表明,所提模型的准确率和宏F1值较最优模型均有提升,进一步验证了本文所提模型的有效性。
1. 相关工作
1.1 方面级情感分析
方面级情感分析是情感分析的一个子任务,其目的是识别评论语句中给定方面的情感极性,近几年在电子商务和市场营销等方面都有广泛的应用。传统的机器学习方法依赖人工构建的特征工程,且领域适应性不强。基于深度学习的方法以神经网络为基础,通过拟合函数实现特征的自学习,代价更低且效果更好。因此目前大多数方面级情感分析方法都基于深度学习展开。Tang等[3]通过构建融合方面信息的长短期记忆神经网络(long short-term memory, LSTM),充分挖掘方面词与上下文的语义关联信息。Wang等[15]基于注意力机制构建LSTM模型,根据方面对上下文分配不同的注意分数。但这些方法都侧重于对上下文建模,未考虑方面自身的重要性。Ma等[4]将方面词和上下文词视为同等重要的信息,通过交互注意力网络获得方面表示和上下文表示,进一步优化两者之间的交互关系,使得方面词和意见词可以更准确地匹配。Chen等[16]针对方面与情感特征距离较远的问题,提出一种基于多注意力机制的神经网络来捕捉间隔较远的情感信息。Fan等[17]提出一种更细粒度的注意力机制,通过捕捉方面和上下文之间的词级交互实现文本语义的整合。
文本自身包含的语义信息对于判别方面情感倾向非常重要,但评论语句中单词之间的句法依赖关系也很有研究价值。Zhang等[6]利用句法依赖树获取评论语句中词与词之间的节点信息,以此来构建邻接矩阵,并使用图卷积网络建模句法信息和文本语义之间的关系。Sun等[18]将句法依存图输入到图卷积网络对句子表示进行句法增强嵌入。虽然这些模型在ABSA任务上都取得了较好的表现,但仅使用单一的句子信息,未考虑融入外部知识来丰富评论语句的语义特征和增强文本表示,影响了ABSA任务的预测性能。
1.2 结合外部知识的ABSA任务
情感分析任务中,外部情感知识可以看作是文本语义的情感补充来源。SenticNet是一个公开的情感知识库,可为每个概念提供相应的情感分数,被广泛应用到情感分析任务中。Xing等[19]通过与其他情感词典的对比发现,SenticNet情感词典在增强评论语句的情感特征上有着显著的性能。Ma等[20]最先将外部情感知识整合到LSTM神经网络中,用来判别特定方面的情感极性。Liang等[12]利用SenticNet情感词典构建图神经网络,将情感知识融入到句子的依存图中来挖掘方面词和上下文词之间的情感特征。Yang等[21]采用多头注意力机制提取上下文中句法和语义的交互特征,对句子进行情感增强后用GCN对节点建模,在中文数据集上也表现较好。除情感知识外,概念知识图谱的本质是语义网络知识库,它可以为句子提供丰富的背景信息,增强文本语义表示,现已应用到多数情感分析任务当中。Hu等[22]为解决短文本语义信息有限的问题,提出异构信息网络来集成外部知识,以弥补文本的语义稀疏性。Microsoft发布的概念图谱(Microsoft concept graph)[23]通过学习海量的网页和日志数据构建常识知识库,可以为模型提供丰富的先验知识,在许多任务上都表现出色[24-25]。
受上述工作启发,本文提出MLKE模型,利用SenticNet情感词典、单词之间的句法关系和句法依赖类型、Microsoft概念知识图谱对文本进行情感、句法和概念3个层次的知识增强以丰富句子的语义特征,从而提高模型对方面情感判别的准确率,并通过实验验证了所提模型的有效性及优越性。
2. MLKE模型
MLKE模型的总体结构如图1所示。首先通过双向长短期记忆神经网络(bi-directional long short-term memory, Bi-LSTM)编码上下文信息,然后在句法依赖树的基础上利用SenticNet情感词典对评论语句进行情感增强,再利用扩展的敏感关系集合
$ {S}_{ {\mathrm{DR}}}' $ 更新依赖图,实现句法增强,将增强后的依赖图融入图神经网络的构建;其次,采用Microsoft概念图谱增强方面词的先验概念知识,融合后获得情感、句法、概念增强后的方面表征;最后使用交互注意力协调优化上下文表征与方面表征,得到最终的文本表示进行情感分类。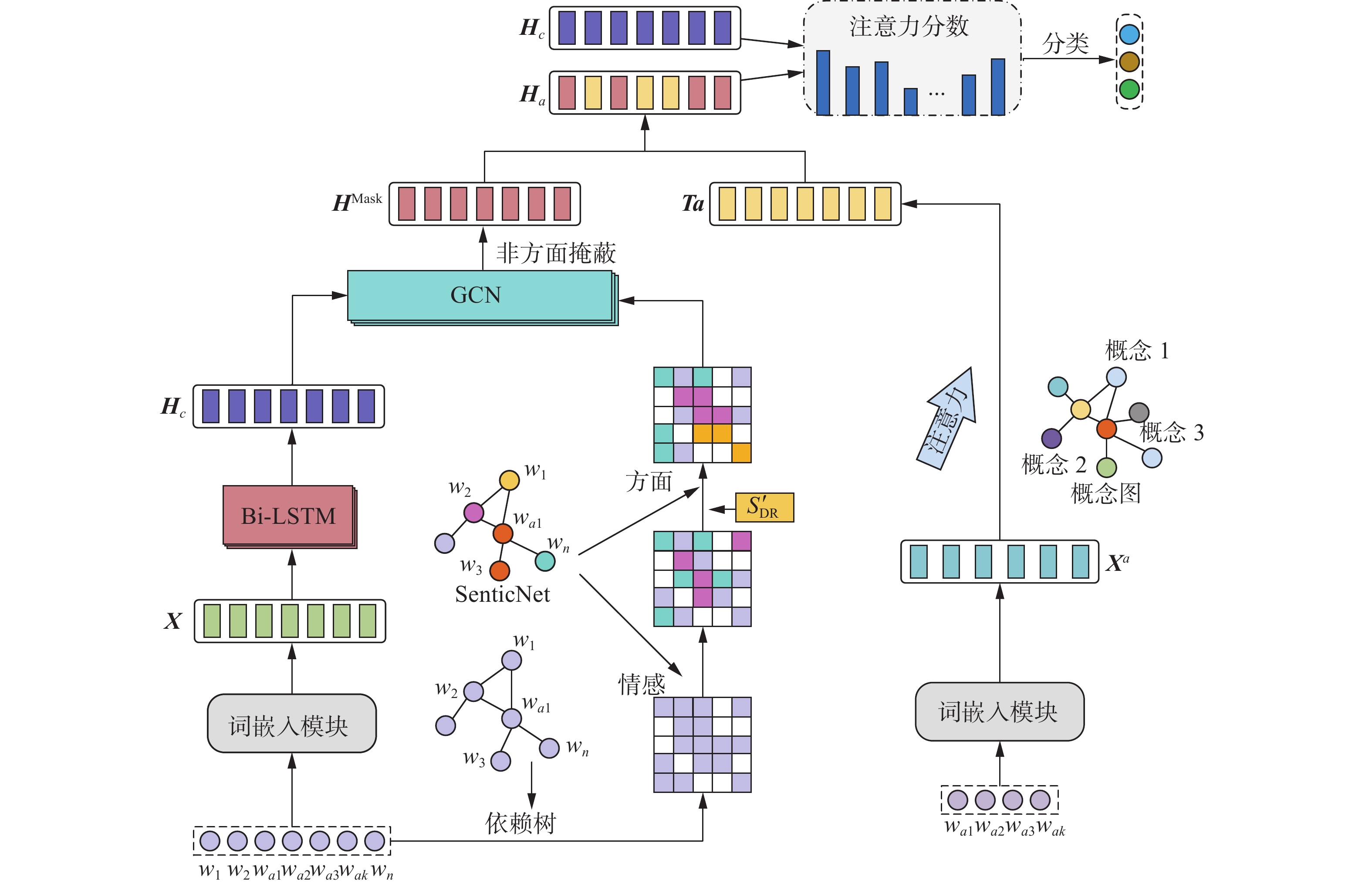 图 1 MLKE模型结构Fig. 1 Structure of MLKE model
图 1 MLKE模型结构Fig. 1 Structure of MLKE model 下载:
全尺寸图片
下载:
全尺寸图片
2.1 任务定义
给定一个由n个单词组成的句子:
$ S = \{ {w_1},{w_2}, \cdots , {w_{a1}},{w_{a2}}, \cdots ,{w_{ak}}, \cdots ,{w_n}\} $ ,句子包括长度为k的方面词序列$ a=\{{w}_{a1},{w}_{a2},\cdots ,{w}_{ak}\} $ ,并且方面a是句子S的一个子序列。其中${w_i}$ 代表上下文中第i个词语,${w_{ai}}$ 代表第i个方面词。方面级情感分析的任务就是从给定句子的上下文中提取与方面相关的情感特征以预测特定方面的情感极性。2.2 词嵌入层和Bi-LSTM层
本文采用Glove[26]词嵌入矩阵
${\boldsymbol{W}} \in {{\mathbf{R}}^{d \times V}}$ 将句子中的单词嵌入到指定维度的向量中,得到句子的嵌入矩阵$ {\boldsymbol{E}} = \left[ {{{\boldsymbol{e}}_1},{{\boldsymbol{e}}_2}, \cdots ,{{\boldsymbol{e}}_{a1}},{{\boldsymbol{e}}_{a2}}, \cdots ,{{\boldsymbol{e}}_{ak}}, \cdots ,{{\boldsymbol{e}}_n}} \right] $ ,其中d是词的维度,V是词汇的总数,${{\boldsymbol{e}}_i} \in {{\mathbf{R}}^d}$ 是第i个上下文词的词嵌入表示,${{\boldsymbol{e}}_{ai}} \in {{\mathbf{R}}^d}$ 是第i个方面词的词嵌入表示。Bi-LSTM[27]可以同时捕获文本中正向和逆向的上下文信息,深层次提取文本两个方向的语义特征。将词嵌入后得到的句子初始化向量E送入Bi-LSTM,学习句子中单词的隐藏信息,获得评论语句正向与逆向的上下文隐藏表示:
$$ {{\overrightarrow{{\boldsymbol{h}}_t}}} = \overrightarrow {{\mathrm{LSTM}}} ({{\boldsymbol{E}}_i}) = \overrightarrow {{\mathrm{LSTM}}} ({{\boldsymbol{e}}_1},{{\boldsymbol{e}}_2}, \cdots ,{{\boldsymbol{e}}_{a1}},{{\boldsymbol{e}}_{a2}}, \cdots ,{{\boldsymbol{e}}_n}) $$ (1) $$ {{ \overleftarrow {\boldsymbol{h}}_t}} = \overleftarrow {{\mathrm{LSTM}}} ({{\boldsymbol{E}}_i}) = \overleftarrow {{\mathrm{LSTM}}} ({{\boldsymbol{e}}_1},{{\boldsymbol{e}}_2}, \cdots ,{{\boldsymbol{e}}_{a1}},{{\boldsymbol{e}}_{a2}}, \cdots ,{{\boldsymbol{e}}_n}) $$ (2) 将正向与逆向的句子隐藏表示拼接后,得到完整的上下文句子隐藏表示为
$ {{\boldsymbol{h}}}_{t}=\left[\overrightarrow{{{\boldsymbol{h}}}_{t}},\overleftarrow{{{\boldsymbol{h}}}_{t}}\right] $ ,进而获得句子的上下文表征${{\boldsymbol{H}}_c} = \{ {{\boldsymbol{h}}_1},{{\boldsymbol{h}}_2}, \cdots ,{{\boldsymbol{h}}_n}\} \in {{\mathbf{R}}^{n \times 2d}}$ 。2.3 多层次知识增强层
1) 情感知识增强
首先,使用Stanza[28]自然语言解析工具获得句子的句法依存树,进而根据句法依存树构建邻接矩阵
${\boldsymbol{T}} \in {{\mathbf{R}}^{n \times n}}$ ,其中n表示评论语句中词语的个数。邻接矩阵构建规则为$$ {{\boldsymbol{T}}}_{i,j}=\left\{\begin{array}{l}1\text{,}如果{w}_{i},{w}_{j}\text{ }存在依赖\\ 1\text{,}i\text=j\\ 0\text{,}其他\end{array}\right. $$ (3) 由于有向图仅可以单向通信,会丢失部分依赖信息,因此本文构建无向图以保留单词自身的节点信息,得到的邻接矩阵对角线上的值全为1,即
${{\boldsymbol{T}}_{i,j}} = {{\boldsymbol{T}}_{j,i}} = 1$ 。为充分挖掘上下文词和方面词之间的情感信息,本文利用SenticNet6[11]情感词典构建情感强度邻接矩阵
${{\boldsymbol{S}}_{i,j}}$ ,通过情感矩阵增强上下文词和方面词之间的情感特征:$$ {{\boldsymbol{S}}}_{i,j}=\left\{\begin{array}{l} {2} \cdot {\mathrm{SenticNet}}({w}_{i}),\\ \quad { |}{\mathrm{SenticNet}} {(}{w}_{i} {)| > |}{\mathrm{SenticNet}} {(}{w}_{j} {)|}\\ {2}\cdot {\mathrm{SenticNet}}({w}_{j}) , \\ \quad {|}{\mathrm{SenticNet}} {(}{w}_{i} {)|} \leqslant {|}{\mathrm{SenticNet}} {(}{w}_{j} {)|}\end{array} \right.$$ (4) 其中,
${\mathrm{SenticNet}}({w_i}) \in [ - 1,1]$ ,表示单词wi在词典中对应的情感分数,强消极词情感分数接近−1,强积极词情感分数趋向于+1,当${\mathrm{SenticNet}}({w_i}) = 0$ 时,表示单词wi的情感倾向为中性或者在词典中不存在。SenticNet中部分单词与其情感分数示例在表1给出。表 1 词语情感分数示例Table 1 Example of word sentiment score词语 SenticNet(word) Fantastic 0.870 Great 0.857 Hard −0.059 Bad −0.800 2) 句法知识增强
通过句法依赖树可以获得方面词与上下文词之间的依赖关系,但在ABSA任务中所有的词级依赖关系不应被视为同等重要,模型在判断特定方面的情感倾向时,应更加关注与方面词对应的意见词,即方面词与意见词的依赖关系是更为重要的。
如图2所示,方面词“service”与单词“poor”和“the”之间都含有依赖关系,但形容词“poor”是与方面词相对应的意见词,其依赖类型为“nsubj”,即“service”是“poor”的名词性主语,而方面词与“the”之间的依赖类型为“det”,说明单词“the”仅仅是“service”的限定词。显然,相比于“det”而言,“nsubj”这种依赖类型对于判别方面的情感倾向应该是更重要的。
 图 2 句法依赖关系Fig. 2 Syntactic dependency下载:
全尺寸图片
图 2 句法依赖关系Fig. 2 Syntactic dependency下载:
全尺寸图片
文献[9]根据依赖关系类型定义了敏感关系集合SDR,来区分判别方面情感极性时更重要的依赖类型,本文通过对敏感关系集合SDR扩充后得到:
$ {S}_{ {\mathrm{DR}}}'$ ={'amod','neg','advmod','ccomp','compound','nmod','nummod','nsubj'},利用其构建句法增强邻接矩阵${{\boldsymbol{D}}_{i,j}}$ ,从而进一步强化方面词与对应意见词之间的句法依赖关系。具体实现方式为$$ {{\boldsymbol{D}}}_{i,j}=\left\{\begin{array}{l}1\text{,}{w}_{i}是方面词并且\text{ }{R}_{{w}_{i},{w}_{j}}\in {S}_{ {\mathrm{DR}}}'\\ 0\text{,}其他\end{array}\right. $$ 式中
${R_{{w_i},{w_{ai}}}}$ 表示上下文词和方面词之间的依赖关系类型,当$ {R}_{{w}_{i},{w}_{ai}}\in {S}_{ {\mathrm{DR}}}' $ 时,认为上下文词${w_i}$ 与方面词${w_{ai}}$ 之间是更重要的依赖类型。此外,方面词同样也是ABSA任务中不可或缺的词,根据
$ {w}_{i}、{w}_{j} $ 是否为方面词的情况构建邻接矩阵以进一步强化单词之间的依赖关系:$$ {{\boldsymbol{Z}}}_{i,j}=\left\{\begin{array}{l}1\text{,}\text{ }{w}_{i}\text{ }或\text{ }{w}_{j}\text{ }是方面词\\ 0\text{,}其他\end{array}\right. $$ 通过上述计算后,得到句法和情感知识增强后的邻接矩阵,其中I为单位矩阵:
$$ {{\boldsymbol{A}}_{i,j}} = {{\boldsymbol{T}}_{i,j}} \times ({{\boldsymbol{S}}_{i,j}} + {{\boldsymbol{D}}_{i,j}} + {{\boldsymbol{Z}}_{i,j}} + {\boldsymbol{I}}) $$ 将得到的增强邻接矩阵输入到图卷积神经网络建模节点特征,第l个GCN层的第i个节点表示通过其邻域的隐藏层更新:
$$ {\boldsymbol{h}}_i^l = {\mathrm{RELU}}\left( {{\tilde {\boldsymbol{A}}_i}} {\boldsymbol{g}}_i^{l - 1}{{\boldsymbol{W}}^l} + {{\boldsymbol{b}}^l}\right) $$ $$ {\boldsymbol{g}}_i^{l - 1} = F\left({\boldsymbol{h}}_i^{l - 1}\right) $$ 式中:
${{\boldsymbol{W}}^l}$ 和${{\boldsymbol{b}}^l}$ 分别是权重矩阵和偏置项矩阵;${\boldsymbol{g}}_i^{l - 1}$ 为前一层GCN的输出结果,其作为节点在第$l$ 层输入的隐藏状态;$F( \; )$ 是位置转换函数,通过位置加权来建模靠近方面词的上下文词,用来减少过程中产生的噪声[6];$ {{\tilde {\boldsymbol{A}}_i}} $ 是经标准化后的邻接矩阵:$$ {{\tilde {\boldsymbol{A}}_i}} = {{\boldsymbol{A}}_i}/({{\boldsymbol{E}}_i} + 1) $$ 式中
${{\boldsymbol{E}}_i}$ 为节点的度,计算公式为$$ {{\boldsymbol{E}}_i} = \sum\limits_{j = 1}^n {{{\boldsymbol{A}}_{i,j}}} $$ 第
$l$ 层图卷积神经网络的输出结果为$$ {{\boldsymbol{H}}^l} = \{ {\boldsymbol{h}}_1^l,{\boldsymbol{h}}_2^l, \cdots ,{\boldsymbol{h}}_{a1}^l,{\boldsymbol{h}}_{a2}^l, \cdots ,{\boldsymbol{h}}_{am}^l, \cdots ,{\boldsymbol{h}}_n^l\} $$ 为突出方面词的显著特征和消除其他状态的噪声,将GCN层输出向量中的非方面表征进行掩蔽,并保持方面表征不变,掩蔽方式为
$$ {{\boldsymbol{h}}}_{t}^{l}=\left\{\begin{array}{l}{{\boldsymbol{h}}}_{t}^{l}\text{,}{a}_{1} < t < {a}_{m}\\ 0\text{,}其他\end{array}\right. $$ 其中a1和am分别表示方面序列的开始和结束,经过非方面表征掩蔽后得到情感和句法增强后的特定方面表示:
$$ {{\boldsymbol{H}}^{{\mathrm{Mask}}}} = \{ 0,0, \cdots ,{\boldsymbol{h}}_{a1}^l,{\boldsymbol{h}}_{a2}^l, \cdots ,{\boldsymbol{h}}_{am}^l, \cdots ,0\} $$ 3) 概念知识增强
本文使用Microsoft知识图谱对方面词概念化,得到概念集
${\boldsymbol{C}} = \{ {{\boldsymbol{c}}_1},{{\boldsymbol{c}}_2}, \cdots ,{{\boldsymbol{c}}_n}\} $ ,其中包含n个概念数据,${{\boldsymbol{c}}_i}$ 为概念集中第$i$ 个概念表示,通过自注意力机制[29]计算,获得每个方面词最合适的概念向量,计算过程如下:$$ {\alpha _i} = {\text{softmax}}\left({\boldsymbol{V}} \cdot {\mathrm{tanh}}({{\boldsymbol{W}}_{{c_i}}}) + {\boldsymbol{b}}\right) $$ 式中:
${\boldsymbol{W}}$ 为权重矩阵,${\boldsymbol{b}}$ 为偏置项,${\boldsymbol{V}}$ 是权重向量,${\alpha _i}$ 表示概念集中第$i$ 个概念获得的注意力分数,通过加权计算后获得方面词最终的概念向量为$$ {{\boldsymbol{T}}_i} = \sum\limits_{i = 1}^v {{\alpha _i}} {{\boldsymbol{c}}_i} $$ 将概念向量T与方面向量a拼接后得到概念增强方面表征
${\boldsymbol{Ta}} = \{ {\boldsymbol{T}}{{\boldsymbol{a}}_1},{\boldsymbol{T}}{{\boldsymbol{a}}_2}, \cdots ,{\boldsymbol{T}}{{\boldsymbol{a}}_k}\} $ ,将其与情感、句法增强后的特定方面掩盖表示$ {{\boldsymbol{H}}^{{\mathrm{Mask}}}} $ 拼接后,得到情感、句法和概念3个层次知识增强后的特定方面表征${{\boldsymbol{H}}_a} = [{\boldsymbol{Ta}},{{\boldsymbol{H}}^{{\mathrm{Mask}}}}]$ 。2.4 特征信息融合层
本文使用交互注意力机制将得到的上下文表征与特定方面表征进行协调优化,
${{\boldsymbol{H}}_a}$ 为多层次知识增强后的特定方面表示,${{\boldsymbol{H}}_c}$ 为Bi-LSTM输出的上下文表征。1) 方面−上下文注意力计算:
$$ {\gamma _{ac}} = \sum\limits_{i = 1}^n {{\boldsymbol{H}}_c^{\mathrm{T}}} \cdot {\boldsymbol{H}}_a^i $$ $$ {\alpha _i} = \frac{{\exp ({\gamma _{ac}})}}{{\displaystyle\sum\limits_{i = 1}^n {\exp (\gamma _{ac}^i)} }} $$ $$ {{\boldsymbol{c}}_r} = \sum\limits_{i = 1}^n {{\alpha _i}} \cdot {{\boldsymbol{H}}_c} $$ 通过计算两者的语义关联为每个上下文词分配相应的注意力权重
${\alpha _i}$ ,从而得到上下文表示。2) 上下文−方面注意力计算:
$$ {\gamma _{ca}} = \sum\limits_{i = 1}^n {{\boldsymbol{H}}_a^{\mathrm{T}}} \cdot {\boldsymbol{H}}_c^i $$ $$ {\beta _i} = \frac{{\exp ({\gamma _{ca}})}}{{\displaystyle\sum\limits_{i = 1}^n {\exp (\gamma _{ca}^i)} }} $$ $$ {{\boldsymbol{a}}_r} = \sum\limits_{i = 1}^n {{\beta _i}} \cdot {{\boldsymbol{H}}_a} $$ 式中:
${\gamma _{ac}}$ 代表方面与上下文的语义相关性,${\gamma _{ca}}$ 表示上下文与方面的语义相关性。${\beta _i}$ 为每个方面词的注意力权重。最后将上下文表示$ {{\boldsymbol{c}}_r} $ 和方面表示$ {{\boldsymbol{a}}_r} $ 融合后得到语句的最终表示$r = [{{\boldsymbol{c}}_r},{{\boldsymbol{a}}_r}]$ ,其中${\boldsymbol{r}} \in {{\bf{R}}^{4d}}$ 。2.5 情感分类层
将交互注意力层的最终输出r作为全连接层的输入,通过softmax获得最终的情感极性y,计算方法为
$$ y = {{\mathrm{softmax}}} ({\boldsymbol{Wr}} + {\boldsymbol{b}}) $$ 式中:W为权重矩阵,b为偏置项,本文采用梯度下降算法更新权重,使用交叉熵损失函数对模型进行优化:
$$ L = - \sum\limits_{i = 1}^S {\sum\limits_{j = 1}^C {y_i^j \cdot \log \left(y_{pi}^j\right) + \lambda ||\theta ||} } $$ 式中:
$S$ 是训练样本数,$C$ 为类别数,$y_i^j$ 为训练数据中的真实标签,$ y_{pi}^j $ 为预测标签,$\theta $ 为可训练参数,$\lambda $ 代表正则化系数。3. 实验与结果分析
3.1 数据集
选择ABSA任务的5个公开数据集(Twitter[30]、Lap14[31]、Rest14[31]、Rest15[32]、Rest16[33])对模型进行评估,各数据集详细统计信息见表2。
表 2 数据集统计信息Table 2 Statistics of datasets数据集 积极 中性 消极 训练集 测试集 训练集 测试集 训练集 测试集 Twitter 1561 173 3127 346 1560 173 Lap14 994 341 464 169 870 128 Rest14 2164 728 637 196 807 196 Rest15 1178 439 50 35 382 328 Rest16 1620 597 88 38 709 190 3.2 参数设置和评价指标
本文使用Glove预训练词嵌入模型进行初始词嵌入,模型各超参数设置见表3。
表 3 实验参数设置Table 3 Experimental parameters setting参数 参数值 隐藏层节点维度 300 词向量维度 300 学习率 0.001 迭代次数 100 批量大小 32 丢失率 0.5 正则化系数 0.00002 本文采用方面级情感分析任务常用的评价指标准确率(Accuracy,
${A_{{\text{cc}}}}$ )和宏F1值(Macro-F1,${F_{{\text{M}}1}}$ )评价模型效果:$$ {A_{{\text{cc}}}} = \frac{T}{N} $$ $$ {F_{{\text{M}}1}} = \frac{1}{C}\sum\limits_{i = 1}^C {\frac{{2 \times {P_i} \times {R_i}}}{{{P_i} + {R_i}}}} $$ 式中:T为正确预测的样本数,N为样本总数,P为预测为正的样本中预测正确的概率,R为正样本预测正确的概率,C为情感类别数。
3.3 对比实验
为验证MLKE模型的有效性,并评估在ABSA任务中的性能,将本文所提模型与以下模型进行比较,并按照特征将对比模型分为3类:
1) 基线模型:
LSTM[3]:使用LSTM建模方面词和上下文词之间的特征,将最后一层的输出作为文本表征输入到分类器获得情感倾向。
TNET-AS[34]:使用CNN代替注意力机制,提取双向RNN层输出的显著上下文特征,并利用组件生成句子中特定方面的单词表征。
2) 注意力模型:
RAM[16]:使用多注意力机制捕获间隔较远的特征信息,将特定方面与长距离情感特征建立联系。
MGAN[17]:一种细粒度和粗粒度交互的注意力机制,通过捕获词级之间的交互从而降低损失。
IAN[4]:利用交互注意力网络学习上下文词和方面词中的关联信息,将两种表示协调优化后输入分类器以预测特定方面的情感极性。
3) 混合模型:
ASGCN[6]:使用图卷积神经网络挖掘依赖树中包含的句法信息,并通过注意力机制对方面特征和上下文特征进行交互优化。
AEGCN[35]:采用多头注意力机制和图卷积网络结合编码句子的语义信息和句法信息,并且为图神经网络额外添加注意力机制从而实现对文本的增强表示。
Sentic-LSTM[20]:通过扩展LSTM进行外部知识嵌入,并结合注意力机制将情感知识整合到神经网络的训练中。
MTKEN[36]:通过整合多个知识源,生成多种上下文表示,并将其融入预训练层,捕捉句子之间的关联信息后进行情感分类。
CDT[18]:使用双向长短期记忆网络建模上下文,并将句法依赖树送入图卷积神经网络进行增强嵌入从而提取方面特征。
BiGCN[37]:设计双概念层次结构区分不同依赖关系和词对,并且同时考虑句法依赖和单词之间的词共现模式,最后使用交互式图卷积神经网络将两部分信息进行融合。
SK-GCN[38]:一种同时考虑语法和外部知识的图神经网络模型,对语法和常识进行特征编码以丰富句子表示,并进行情感分类。
Kuma-GCN[39]:采用门控单元和自注意力机制动态组合的方法,学习潜在的依赖图信息对句法特征补充和监督,从而进行情感分类。
Sentic-GCN[12]:通过整合SenticNet词典中的情感知识构建图神经网络,以增强评论语句的依存图,丰富上下文词和方面词之间的语义特征。
MIGCN[40]:使用GCN建模文本的位置距离和语法距离,并将方面词与上下文词进行交互,学习评论语句的语义和语法信息。
3.4 实验结果与分析
本文在5个数据集上与15组模型进行对比实验,对比模型数据来源于参考文献,实验结果见表4。
表 4 不同模型的对比结果Table 4 Comparison results of different models% 类别 模型 Twitter14 Lap14 Rest14 Rest15 Rest16 ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ 基线模型 LSTM 69.56 67.70 69.28 63.09 78.13 67.47 77.37 55.17 86.80 63.88 TNET-AS 74.90* 73.60 76.54 71.75 80.69 71.27 — — — — 注意力模型 RAM 69.36 67.30 74.49 71.35 80.23 70.80 — — — — MGAN 72.54 70.81 75.39 72.47 81.25 71.94 — — — — IAN 72.50 70.81 72.05 67.38 79.26 70.09 78.54 52.65 84.74 55.21 混合模型 ASGCN 72.15 70.40 75.55 71.05 80.77 72.02 79.89 61.89 88.99 67.48 AEGCN 73.86 71.59 75.91 71.88 81.43 73.66 80.85 63.96 88.76 68.73 Sentic-LSTM 70.66 67.87 70.88 67.19 79.43 70.32 — — — — MTKEN 69.80 67.54 73.43 69.12 79.47 68.08 80.67 58.38 88.28 66.15 CDT 74.66 73.66* 77.19 72.99 82.30 74.02 — — 85.58 69.93 BiGCN 74.16 73.35 74.59 71.84 81.97 73.48 81.16 64.79 88.96 70.84 SK-GCN 71.97 70.22 73.20 69.18 80.36 70.43 80.12 60.70 85.17 68.08 Kuma-GCN 72.45 70.77 76.12 72.42 81.43 73.64 80.69 65.99 89.39 73.19 Sentic-GCN 72.83 71.28 77.90* 74.71* 84.03* 75.38* 82.84* 67.32* 90.88* 75.91* MIGCN 73.31 72.12 76.59 72.44 82.32 74.31 80.81 64.21 89.50 71.97 本文模型 MLKE 75.36 74.41 78.72 75.28 85.01 77.68 84.26 69.37 91.12 75.84 注:将MLKE模型的结果加粗,对比模型中的最优结果用“*”标记,“—”代表缺少原始数据。 MLKE模型在Twitter14、Lap14、Rest14、Rest15和Rest16数据集上的准确率均取得最优结果,分别为75.36%、78.72%、85.01%、84.26%和91.12%,相较于对比模型中的最优结果,准确率分别提高了0.46百分点、0.82百分点、0.98百分点、1.42百分点和0.24百分点。在Rest16数据集上,MLKE模型的宏F1值低于最优结果0.07个百分点,分析其原因为Rest16中的评论语句包含多个方面词和意见词,且句子的语法结构相对较弱,区分单词之间的依赖类型可能会错误地提高与方面无关意见词的贡献度,影响了分类效果。MLKE模型虽然在Rest16上的宏F1值未取得最优效果,但在前4个数据集上,所提模型的宏F1值都取得最优结果,分别为74.41%、75.28%、77.68%和69.37%,较最优结果分别提高了0.75百分点、0.57百分点、0.3百分点和2.05百分点,尤其是在平均宏F1值最低的Rest15数据集上,宏F1值提高最为明显,进一步验证了所提模型的有效性。
根据结果可知,本文所提模型的整体性能进一步得到提高,可以看出引入外部知识对于增强文本语义信息的重要性。这是因为数据中存在较多短文本,自身所能提供的语义特征有限,而MLKE模型可以有效融合外部的情感、句法和概念知识来丰富文本的语义表示,进而指导模型对特定方面的情感倾向做出正确的判断。
3.5 消融实验
为明确所提模型中各个部分或组件对模型性能的独立影响,本文还进行了消融实验。其中:
1) w/o em表示不使用SenticNet情感词典对评论语句进行情感特征增强;
2) w/o co表示不使用Microsoft知识图谱对方面词进行概念特征增强;
3) w/o as表示不区分方面词与上下文词,即将方面词与上下文词视为同等重要;
4) w/o de表示不使用扩充后的敏感关系集合更新邻接矩阵;
5) w/o in表示不使用交互注意力机制融合上下文表征和方面表征,直接将Ha、Hc两个特征拼接后输入分类器得到情感倾向;
6) MLKE:本文所提模型。
实验结果见表5,根据实验结果可以看出,去掉任何一个模块后,MLKE模型在5个数据集上的准确率和宏F1值均有所下降。
表 5 消融实验Table 5 Ablation experiments% 模型 Twitter14 Lap14 Rest14 Rest15 Rest16 ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ w/o em 74.27 72.64 74.31 70.26 82.51 69.80 82.14 67.25 88.63 69.54 w/o co 74.59 73.10 72.64 69.57 81.09 74.27 81.62 66.17 86.53 72.68 w/o as 74.91 73.60 76.14 71.96 83.80 73.29 82.90 67.51 89.60 74.05 w/o de 74.30 73.29 77.51 74.63 84.20 75.07 83.54 67.81 90.68 75.81 w/o in 74.21 73.39 77.60 74.19 83.71 74.64 83.53 68.20 89.24 72.90 MLKE 75.36 74.41 78.72 75.28 85.01 77.68 84.26 69.37 91.12 75.84 其中,w/o em模型在所有数据集上的准确率平均下降了2.52个百分点,宏F1值平均下降了4.62个百分点,进一步说明了引入情感知识对方面级情感分析任务的重要性;w/o co模型的准确率和宏F1值平均下降了3.60个百分点和3.36个百分点,这表明外部概念知识对丰富方面词的语义特征有着显著的作用,尤其是在Lap14和Rest14数据集上去掉概念增强模块,准确率和宏F1值下降尤为明显,分析其原因为这两个数据集中包含的专有名词较多,提供外部概念知识可以丰富专有名词的文本语义表征,为模型提供更准确的监督信号,进而指导模型做出准确的预测;w/o as模型的准确率和宏F1值平均下降了1.42个百分点和2.43个百分点,因为方面词是ABSA任务中不可或缺的词,区分方面词和上下文词很有必要;w/o de模型的准确率和宏F1值平均下降了0.85个百分点和1.19个百分点,说明区分单词之间的依赖关系类型有助于方面词更准确地关注到与自身关联的意见词,提高语义关联性。但在Rest16数据集上,不区分依赖类型,模型的宏F1值仅下降0.03个百分点,波动幅度极小,进一步验证了本文3.4节的想法,原因为该数据集方面词较多且语法依赖较弱,区分句法依赖关系对效果提升不明显;w/o in模型的准确率和宏F1值较MLKE模型平均下降了1.24个百分点和1.85个百分点,说明使用交互注意力机制可以协调优化上下文表征和方面表征,提高模型的语义解析能力。综合上述分析,从总体上看,所有组件对本文提出的模型都是有益的。
3.6 GCN层数分析
为探究图卷积神经网络的层数对模型性能的影响,将GCN层数分别设置为
$L \in \{ 1,2, \cdots ,10\} $ ,在5个数据集上进行实验,探索GCN层数与准确率和宏F1值的关系。实验结果如图3、图4所示。从图中可以看出,该模型的整体效率在网络层数为2的时候达到最优状态。当网络层数为1时,模型特征捕获能力明显不足,因此增加网络深度后,模型准确率和宏F1值都会显著提高。之后,随网络层数的增加,准确率出现较小的下降趋势,整体波动并不明显。但在模型达到最优性能后,随GCN层数的增加,模型的宏F1值明显出现剧烈的波动,这主要是由于随网络深度增加,模型参数过多造成信息冗余与过拟合,导致模型性能不稳定。
 图 3 GCN层数与准确率Fig. 3 GCN layers and accuracy下载:
全尺寸图片
图 3 GCN层数与准确率Fig. 3 GCN layers and accuracy下载:
全尺寸图片
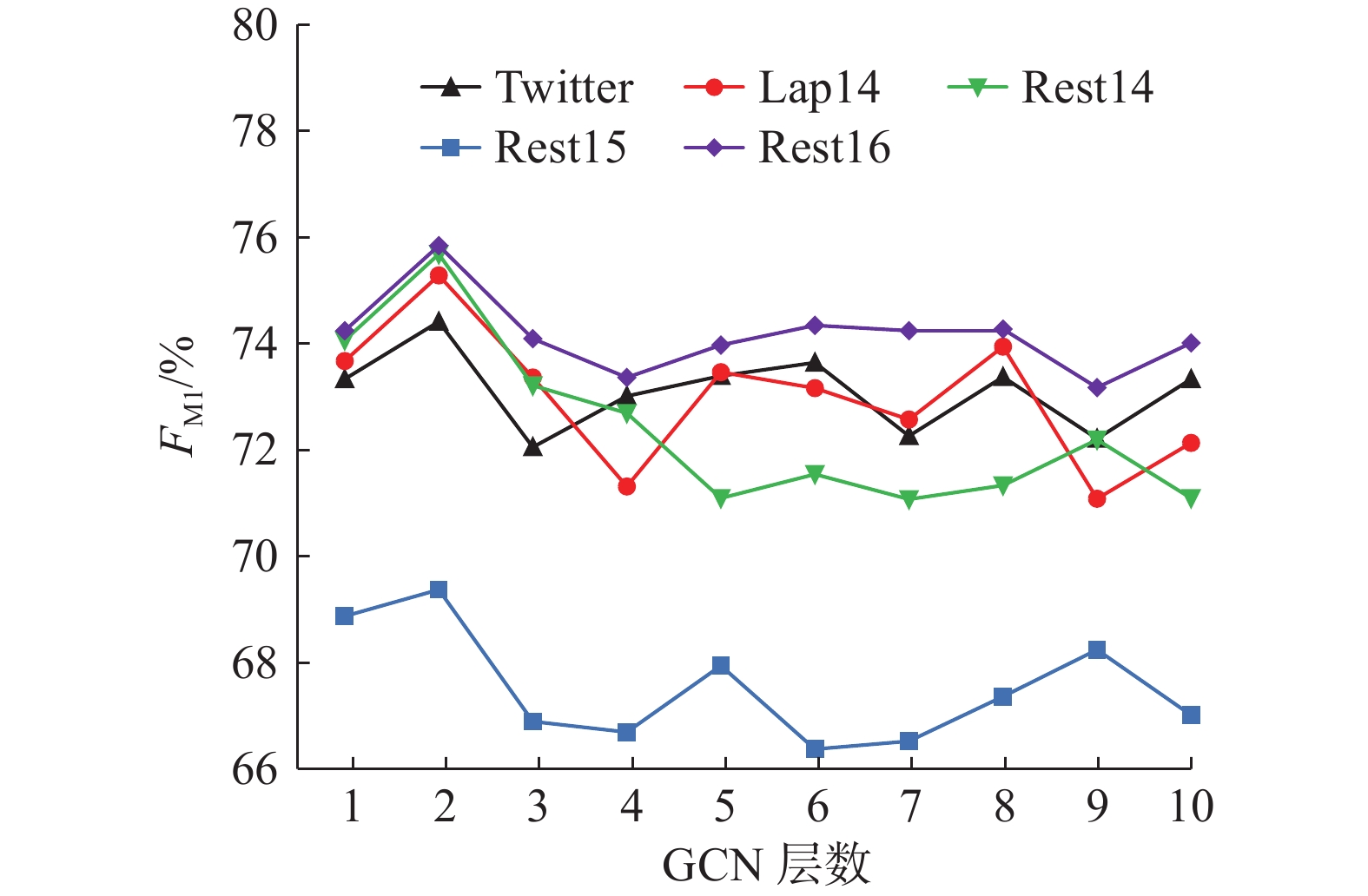 图 4 GCN层数与宏F1值Fig. 4 GCN layers and FM1下载:
全尺寸图片
图 4 GCN层数与宏F1值Fig. 4 GCN layers and FM1下载:
全尺寸图片
3.7 案例分析
为评估所提模型在实际应用中的性能及表现,本文从5个数据集中选择个别案例,与LSTM、IAN、ASGCN、Sentic-GCN经典模型进行对比,详细实验结果见表6。
表 6 案例预测结果Table 6 Case prediction results句子 LSTM IAN ASGCN Sentic-GCN MLKE 1. The [battery]P is very longer. P P P P P 2. The [Food]P is delicious and the [environment]P is good,
but the [service]N is too bad.P;P;P× P;P;P× P;P;N P;P;N P;P;N 3. The [keyboard]N is indeed the part I care most about,
but it did not satisfy me.P× P× O× O× N 4. Due to [geographical location]P, I will definitely
consider it next time.N× O× O× O× P 注:P、O、N分别代表积极、中性、消极;结果后带有“×”表示模型预测错误,否则预测正确。 句子1较为简单,仅含一个方面词,并且方面词与意见词距离相近,句法依赖也较为明显,5组模型都做出了正确的预测;句子2中包含多个方面词,且方面情感极性不同,前两组基于上下文与注意力机制的模型不能较好地捕捉特定方面的情感特征导致判断错误,而引入句法依赖和情感知识可以较好地指导模型关注与方面词有关的意见词并且丰富文本语义特征,进而做出了正确的预测;句3中方面词与观点词距离较远,且表达的情感不明显,句4中方面词没有明确对应的意见词,因此模型需要从语义中学习隐含情感来做出判断。句3和句4的情感倾向前4组模型均预测失败,但MLKE模型全部预测正确,这是因为针对评论语句进行句法、概念、情感知识增强后,模型能够准确捕获方面情感信息,从而可以对特定方面的情感极性做出正确的判断,也进一步验证了所提模型的合理性。
4. 结束语
针对现有方法在ABSA任务上的不足,为了充分利用外部知识对评论语句表征进行补充和增强,本文提出了多层次知识增强的MLKE模型。通过将情感、句法和概念3个层次的外部知识嵌入评论语句实现对上下文词和方面词的语义增强表示,并考虑单词之间的依赖类型对判别方面情感极性的影响。本文对敏感关系集合补充后,利用其更新邻接矩阵,强化方面词与上下文词之间的语法关联;最后采用交互注意力机制协调融合方面表征与上下文表征。在5个数据集上的对比实验结果证明了MLKE模型的有效性,消融实验结果则表明不同模块对于提高模型整体的性能都是有利的。
未来的工作将侧重于研究引入外部知识带来的噪声和信息冗余问题,并探索更有效的上下文表征和方面表征的融合机制。
-
图 1 MLKE模型结构
Fig. 1 Structure of MLKE model
下载:
全尺寸图片
图 2 句法依赖关系
Fig. 2 Syntactic dependency
下载:
全尺寸图片
图 3 GCN层数与准确率
Fig. 3 GCN layers and accuracy
下载:
全尺寸图片
图 4 GCN层数与宏F1值
Fig. 4 GCN layers and FM1
下载:
全尺寸图片
表 1 词语情感分数示例
Table 1 Example of word sentiment score
词语 SenticNet(word) Fantastic 0.870 Great 0.857 Hard −0.059 Bad −0.800 表 2 数据集统计信息
Table 2 Statistics of datasets
数据集 积极 中性 消极 训练集 测试集 训练集 测试集 训练集 测试集 Twitter 1561 173 3127 346 1560 173 Lap14 994 341 464 169 870 128 Rest14 2164 728 637 196 807 196 Rest15 1178 439 50 35 382 328 Rest16 1620 597 88 38 709 190 表 3 实验参数设置
Table 3 Experimental parameters setting
参数 参数值 隐藏层节点维度 300 词向量维度 300 学习率 0.001 迭代次数 100 批量大小 32 丢失率 0.5 正则化系数 0.00002 表 4 不同模型的对比结果
Table 4 Comparison results of different models
% 类别 模型 Twitter14 Lap14 Rest14 Rest15 Rest16 ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ 基线模型 LSTM 69.56 67.70 69.28 63.09 78.13 67.47 77.37 55.17 86.80 63.88 TNET-AS 74.90* 73.60 76.54 71.75 80.69 71.27 — — — — 注意力模型 RAM 69.36 67.30 74.49 71.35 80.23 70.80 — — — — MGAN 72.54 70.81 75.39 72.47 81.25 71.94 — — — — IAN 72.50 70.81 72.05 67.38 79.26 70.09 78.54 52.65 84.74 55.21 混合模型 ASGCN 72.15 70.40 75.55 71.05 80.77 72.02 79.89 61.89 88.99 67.48 AEGCN 73.86 71.59 75.91 71.88 81.43 73.66 80.85 63.96 88.76 68.73 Sentic-LSTM 70.66 67.87 70.88 67.19 79.43 70.32 — — — — MTKEN 69.80 67.54 73.43 69.12 79.47 68.08 80.67 58.38 88.28 66.15 CDT 74.66 73.66* 77.19 72.99 82.30 74.02 — — 85.58 69.93 BiGCN 74.16 73.35 74.59 71.84 81.97 73.48 81.16 64.79 88.96 70.84 SK-GCN 71.97 70.22 73.20 69.18 80.36 70.43 80.12 60.70 85.17 68.08 Kuma-GCN 72.45 70.77 76.12 72.42 81.43 73.64 80.69 65.99 89.39 73.19 Sentic-GCN 72.83 71.28 77.90* 74.71* 84.03* 75.38* 82.84* 67.32* 90.88* 75.91* MIGCN 73.31 72.12 76.59 72.44 82.32 74.31 80.81 64.21 89.50 71.97 本文模型 MLKE 75.36 74.41 78.72 75.28 85.01 77.68 84.26 69.37 91.12 75.84 注:将MLKE模型的结果加粗,对比模型中的最优结果用“*”标记,“—”代表缺少原始数据。 表 5 消融实验
Table 5 Ablation experiments
% 模型 Twitter14 Lap14 Rest14 Rest15 Rest16 ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ ${A_{{\text{cc}}}}$ ${F_{{\text{M}}1}}$ w/o em 74.27 72.64 74.31 70.26 82.51 69.80 82.14 67.25 88.63 69.54 w/o co 74.59 73.10 72.64 69.57 81.09 74.27 81.62 66.17 86.53 72.68 w/o as 74.91 73.60 76.14 71.96 83.80 73.29 82.90 67.51 89.60 74.05 w/o de 74.30 73.29 77.51 74.63 84.20 75.07 83.54 67.81 90.68 75.81 w/o in 74.21 73.39 77.60 74.19 83.71 74.64 83.53 68.20 89.24 72.90 MLKE 75.36 74.41 78.72 75.28 85.01 77.68 84.26 69.37 91.12 75.84 表 6 案例预测结果
Table 6 Case prediction results
句子 LSTM IAN ASGCN Sentic-GCN MLKE 1. The [battery]P is very longer. P P P P P 2. The [Food]P is delicious and the [environment]P is good,
but the [service]N is too bad.P;P;P× P;P;P× P;P;N P;P;N P;P;N 3. The [keyboard]N is indeed the part I care most about,
but it did not satisfy me.P× P× O× O× N 4. Due to [geographical location]P, I will definitely
consider it next time.N× O× O× O× P 注:P、O、N分别代表积极、中性、消极;结果后带有“×”表示模型预测错误,否则预测正确。 -
[1] 陈壮, 钱铁云, 李万理, 等. 低资源方面级情感分析研究综述[J]. 计算机学报, 2023, 46(7): 1445−1472. doi: 10.11897/SP.J.1016.2023.01445 CHEN Zhuang, QIAN Tieyun, LI Wanli, et al. Low-resource aspect-based sentiment analysis: a survey[J]. Chinese journal of computers, 2023, 46(7): 1445−1472. doi: 10.11897/SP.J.1016.2023.01445 [2] 张铭泉, 周辉, 曹锦纲. 基于注意力机制的双BERT有向情感文本分类研究[J]. 智能系统学报, 2022, 17(6): 1220−1227. doi: 10.11992/tis.202112038 ZHANG Mingquan, ZHOU Hui, CAO Jingang. Dual BERT directed sentiment text classification based on attention mechanism[J]. CAAI transactions on intelligent systems, 2022, 17(6): 1220−1227. doi: 10.11992/tis.202112038 [3] TANG Duyu, QIN Bing, FENG Xiaocheng, et al. Effective LSTMs for target-dependent sentiment classification[EB/OL]. (2015−12−03)[2023−08−30]. http://arxiv.org/abs/1512.01100 [4] MA Dehong, LI Sujian, ZHANG Xiaodong, et al. Interactive attention networks for aspect-level sentiment classification[EB/OL]. (2017−09−04)[2023−06−25]. https://arXiv.org/abs:1709.00893. [5] 陈景景, 韩虎, 徐学锋. 面向多方面的双通道知识增强图卷积网络模型[J/OL]. 计算机工程与科学, 2023: 1−10. (2023−04−13)[2023−06−22]. https://kns.cnki.net/kcms/detail/43.1258.tp.20230411.1325.002.html. CHEN Jingjing, HAN Hu, XU Xuefeng. Multi aspect oriented dual channel knowledge enhanced graph convolution network model[J/OL]. Computer engineering & science, 2023: 1−10. (2023−04−13)[2023−06−25]. https://kns.cnki.net/kcms/detail/43.1258.tp.20230411.1325.002.html. [6] ZHANG Chen, LI Qiuchi, SONG Dawei. Aspect-based sentiment classification with aspect-specific graph convolutional networks[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong: Association for Computational Linguistics, 2019: 4568−4578. [7] WANG Kai, SHEN Weizhou, YANG Yunyi, et al. Relational graph attention network for aspect-based sentiment analysis[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2020: 3229−3238. [8] HOU Xiaochen, QI Peng, WANG Guangtao, et al. Graph ensemble learning over multiple dependency trees for aspect-level sentiment classification[C]//Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: Association for Computational Linguistics, 2021: 2884−2894. [9] 李帅, 徐彬, 韩祎珂, 等. SS-GCN: 情感增强和句法增强的方面级情感分析模型[J]. 计算机科学, 2023, 50(3): 3−11. doi: 10.11896/jsjkx.220700238 LI Shuai, XU Bin, HAN Yike, et al. SS-GCN: aspect-based sentiment analysis model with affective enhancement and syntactic enhancement[J]. Computer science, 2023, 50(3): 3−11. doi: 10.11896/jsjkx.220700238 [10] CAMBRIA E, SPEER R, HAVASI C, et al. Senticnet: A publicly available semantic resource for opinion mining[C]//AAAI fall symposium. Arlington: AAAI, 2010: 14−18. [11] CAMBRIA E, LI Yang, XING F Z, et al. SenticNet 6: ensemble application of symbolic and subsymbolic AI for sentiment analysis[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. Virtual Event: ACM, 2020: 105–114. [12] LIANG Bin, SU Hang, GUI Lin, et al. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks[J]. Knowledge-based systems, 2022, 235: 107643. doi: 10.1016/j.knosys.2021.107643 [13] CHEN Jindong, HU Yizhou, LIU Jingping, et al. Deep short text classification with knowledge powered attention[C]//Proceedings of the AAAI conference on artificial intelligence. Honolulu: AAAI, 2019, 33(1): 6252−6259. [14] BIAN Ximo, FENG Chong, AHMAD A, et al. Targeted sentiment classification with knowledge powered attention network[C]//2019 IEEE 31st International Conference on Tools with Artificial Intelligence. New York: IEEE, 2019: 1073−1080. [15] WANG Yequan, HUANG Minlie, ZHU Xiaoyan, et al. Attention-based LSTM for aspect-level sentiment classification[C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2016: 606−615. [16] CHEN Peng, SUN Zhongqian, BING Lidong, et al. Recurrent attention network on memory for aspect sentiment analysis[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: Association for Computational Linguistics, 2017: 452−461. [17] FAN Feifan, FENG Yansong, ZHAO Dongyan. Multi-grained attention network for aspect-level sentiment classification[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels: Association for Computational Linguistics, 2018: 3433−3442. [18] SUN Kai, ZHANG Richong, MENSAH S, et al. Aspect-level sentiment analysis via convolution over dependency tree[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong: Association for Computational Linguistics, 2019: 5679−5688. [19] XING F Z, PALLUCCHINI F, CAMBRIA E. Cognitive-inspired domain adaptation of sentiment lexicons[J]. Information processing and management: an international journal, 2019, 56(3): 554−564. doi: 10.1016/j.ipm.2018.11.002 [20] MA Yukun, PENG Haiyun, KHAN T, et al. Sentic LSTM: a hybrid network for targeted aspect-based sentiment analysis[J]. Cognitive computation, 2018, 10(4): 639−650. doi: 10.1007/s12559-018-9549-x [21] YANG Qian, KADEER Z, GU Wenxia, et al. Affective knowledge augmented interactive graph convolutional network for chinese-oriented aspect-based sentiment analysis[J]. IEEE access, 2022, 10: 130686−130698. doi: 10.1109/ACCESS.2022.3228299 [22] HU Linmei, YANG Tianchi, SHI Chuan, et al. Heterogeneous graph attention networks for semi-supervised short text classification[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong: Association for Computational Linguistics, 2019: 4821−4830. [23] JI Lei, WANG Yujing, SHI Botian, et al. Microsoft concept graph: mining semantic concepts for short text understanding[J]. Data intelligence, 2019, 1(3): 238−270. doi: 10.1162/dint_a_00013 [24] ZHU Zhenfang, ZHANG Dianyuan, LI Lin, et al. Knowledge-guided multi-granularity GCN for ABSA[J]. Information processing & management, 2023, 60(2): 103223. [25] WANG Xiting, LIU Kunpeng, WANG Dongjie, et al. Multi-level recommendation reasoning over knowledge graphs with reinforcement learning[C]//Proceedings of the ACM Web Conference 2022. Lyon: ACM, 2022: 2098–2108. [26] PENNINGTON J, SOCHER R, MANNING C. Glove: global vectors for word representation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha: Association for Computational Linguistics, 2014: 1532−1543. [27] ZHOU Peng, SHI Wei, TIAN Jun, et al. Attention-based bidirectional long short-term memory networks for relation classification[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin: Association for Computational Linguistics, 2016: 207−212. [28] QI Peng, ZHANG Yuhao, ZHANG Yuhui, et al. Stanza: a python natural language processing toolkit for many human languages[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Stroudsburg: Association for Computational Linguistics, 2020: 101−108. [29] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach: ACM, 2017: 6000–6010. [30] DONG Li, WEI Furu, TAN Chuanqi, et al. Adaptive recursive neural network for target-dependent twitter sentiment classification[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Baltimore: Association for Computational Linguistics, 2014: 49−54. [31] PONTIKI M, GALANIS D, PAVLOPOULOS J, et al. SemEval-2014 task 4: aspect based sentiment analysis[C]//Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014). Dublin: Association for Computational Linguistics, 2014: 27−35. [32] PONTIKI M, GALANIS D, PAPAGEORGIOU H, et al. SemEval-2015 task 12: aspect based sentiment analysis[C]//Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015). Denver: Association for Computational Linguistics, 2015: 486−495. [33] PONTIKI M, GALANIS D, PAPAGEORGIOU H, et al. SemEval-2016 task 5: aspect based sentiment analysis[C]//Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016). San Diego: Association for Computational Linguistics, 2016: 19−30. [34] LI Xin, BING Lidong, LAM W, et al. Transformation networks for target-oriented sentiment classification[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne: Association for Computational Linguistics, 2018: 946−956. [35] XU Guangtao, LIU Peiyu, ZHU Zhenfang, et al. Attention-enhanced graph convolutional networks for aspect-based sentiment classification with multi-head attention[J]. Applied sciences, 2021, 11(8): 3640. doi: 10.3390/app11083640 [36] WU Sixing, XU Yuanfan, WU Fangzhao, et al. Aspect-based sentiment analysis via fusing multiple sources of textual knowledge[J]. Knowledge-based systems, 2019, 183: 104868. doi: 10.1016/j.knosys.2019.104868 [37] ZHANG Mi, QIAN Tieyun. Convolution over hierarchical syntactic and lexical graphs for aspect level sentiment analysis[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2020: 3540−3549. [38] ZHOU Jie, HUANG J X, HU Q V, et al. SK-GCN: modeling Syntax and Knowledge via Graph Convolutional Network for aspect-level sentiment classification[J]. Knowledge-based systems, 2020, 205: 106292. doi: 10.1016/j.knosys.2020.106292 [39] CHEN Chenhua, TENG Zhiyang, ZHANG Yue. Inducing target-specific latent structures for aspect sentiment classification[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2020: 5596−5607. [40] 王汝言, 陶中原, 赵容剑, 等. 多交互图卷积网络用于方面情感分析[J]. 电子与信息学报, 2022, 44(3): 1111−1118. doi: 10.11999/JEIT210459 WANG Ruyan, TAO Zhongyuan, ZHAO Rongjian, et al. Multi-interaction graph convolutional networks for aspect-level sentiment analysis[J]. Journal of electronics & information technology, 2022, 44(3): 1111−1118. doi: 10.11999/JEIT210459























































































