
A data augmentation method built on GPT-2 model
-
摘要: 针对句子分类任务常面临着训练数据不足,而且文本语言具有离散性,在语义保留的条件下进行数据增强具有一定困难,语义一致性和多样性难以平衡的问题,本文提出一种惩罚生成式预训练语言模型的数据增强方法(punishing generative pre-trained transformer for data augmentation, PunishGPT-DA)。设计了惩罚项和超参数α,与负对数似然损失函数共同作用微调GPT-2(generative pre-training 2.0),鼓励模型关注那些预测概率较小但仍然合理的输出;使用基于双向编码器表征模型 (bidirectional encoder representation from transformers, BERT)的过滤器过滤语义偏差较大的生成样本。本文方法实现了对训练集16倍扩充,与GPT-2相比,在意图识别、问题分类以及情感分析3个任务上的准确率分别提升了1.1%、4.9%和8.7%。实验结果表明,本文提出的方法能够同时有效地控制一致性和多样性需求,提升下游任务模型的训练性能。Abstract: The sentence classification task often faces the problem of insufficient training data. Moreover, text language is discrete, and it is difficult to perform data augmentation under the condition of semantic preservation. Balancing semantic consistency and diversity is also challenging. To address these issues, this paper proposes a punishing generative pre-trained transformer for data augmentation, PunishGPT-DA for short. A penalty term and hyperparameter α are designed. They work together with the negative log-likelihood loss function to fine tune GPT-2 (generative pre-training 2.0) and encourage the model to focus on the outputs with small predicted probabilities but still reasonable. A filter based on BERT (bidirectional encoder representation from transformers) is used to remove generated samples with significant semantic bias. The method has achieved 16-fold expansion of the training set and improved accuracy by 1.1%, 4.9%, and 8.7% in intent recognition, question classification, and sentiment analysis, respectively when compared with GPT-2. Experimental results demonstrate that the proposed method can effectively balance the requirements for semantic consistency and diversity, enhancing the training performance of downstream task models.
-
句子分类[1](sentence classification,SC)是最基本和常见的自然语言处理(natural language process,NLP)任务之一,广泛应用于NLP的很多子领域,如意图识别、情感分析、问题分类等。当给定一个句子作为输入时,其任务是将其分配给一个预定义标签。深度神经网络往往需要大规模的高质量标记的训练数据来实现高性能,然而在特定领域,由于人工标注数据集代价昂贵,常常只有少量样本可供使用。本文研究在数据匮乏情况下的句子分类任务准确率较低的问题,训练数据的不足使得句子分类任务模型无法得到有效的训练,从而导致泛化能力差。为解决这一问题,数据增强是一种有效的方法。
通常,数据生成的语义一致性和多样性对目标任务至关重要[2],语义保留即前后语义保持一致是数据增强最基本的要求,训练样本的丰富表达能使神经网络更好地学习权重。一些学者的研究工作已经开始注重数据的多样性和质量。如在计算机视觉中,文献[3]使用代理网络来学习如何增强多样性。孙晓等[4]利用生成对抗网络生成同一个人的不同面部表情实现数据增强。NLP中的一些研究[5]对原句进行随机替换、随机交换、插入和删除操作实现增强数据的多样性,为了避免简单数据增强方法(easy data augmentation, EDA)方法引入过多噪声,一种更简单的数据增强方法(an easier data augmentation, AEDA) [6]将随机插入token改为随机插入标点符号,一定程度上缓解了噪声引起的语义偏差问题,然而随机插入标点符号可能会不恰当地断句,语义保留和多样性仍无法同时有效控制。随着大规模预训练语言模型的问世,一些研究将其应用于数据增强,Anaby等[7]提出基于语言模型的数据增强方法(language-model-based data augmentation, LAMBADA),采用训练数据微调GPT-2模型[8],在训练过程中将相应的标签拼接到每个样本,以便为该类生成新数据,在句子分类方面取得了显著的改进。然而,该方法采用top-k和top-p采样的方式增加多样性,这种方式很有可能会导致累计误差的产生,使得生成句子质量低下。
从本质上讲,语义一致性和多样性的目标其实是相互冲突的,即生成多样性高的样本更可能导致语义发生变化,因此,需要同时考虑多样性与语义一致性,对生成数据进行控制,得到较为平衡的数据。本文提出一种引入惩罚项的数据增强方法(punishing generative pre-trained transformer for data augmentation, PunishGPT-DA),用于生成增强数据来改进句子分类任务。此方法的数据增强过程建立在预训练语言模型GPT-2基础上,通过设计惩罚项、超参数,使用双向编码器表征模型(bidirectional encoder representations from transformers,BERT)[9]作为过滤器完成数据增强。实验结果表明了该方法的有效性。
1. 数据增强相关工作
从增强数据的多样性来看,数据增强方法可以大致分为基于复述的方法、基于噪声的方法和基于采样的方法3类。
基于复述的方法包括在词汇、短语、句子层面的重写。Zhang等[10]首先利用词库(a electronic lexical database, WordNet)替换句子中的同义词应用于数据增强;条件BERT(conditional bert, CBERT)[11]掩盖句子的部分字符,由BERT生成替换词;Jiao等[12]使用数据增强来获得特定任务的蒸馏训练数据,利用BERT将单词标记为多个单词片段,并形成候选集;回译以生成的方式重写整个句子,被应用于低资源句子分类[13],使用不同的二级语言提高了分类精度,Hou等[14]通过L层变换器对串联的多个输入话语进行编码,利用重复感知注意和面向多样性的正则化生成更多样化的句子。Kober等[15]使用对抗生成网络(generative adversarial network, GAN)生成与原始数据非常相似的样本。
基于噪声的方法添加微弱噪声,使其适当偏离原始句子。EDA[5]通过随机插入、删除、替换、交换操作得到增强数据。Peng等[16]通过删除对话语句中的槽值来获得更多的组合;Sahin等[17]通过依赖树变形对句子进行旋转。Sun等[18]将混合技术应用到基于Transformer的预训练模型中进行数据增强(Mixup-Transformer),将Mixup与基于Transformer的预训练结构相结合,进行数据增强;Feng等[19]在提示部分随机删除、交换和插入文本字符,用于微调文本生成器;Andreas[20]提出了一种简单的数据增强规则,通过采用出现在一个类似环境中的其他片段替换真实的训练样本的某个片段,来合成新的样本。Guo等[21]提出一种序列到序列模型的混合方法(sequence-level mixed sample data augmentation,SeqMix),通过组合训练集中的输入输出序列来创建新的合成样本。丁家杰等[22]通过对原始数据集中的噪声进行处理扩充数据集,在问答任务上实现了良好效果。
基于采样的方法掌握数据分布,并在其中采样新的样本。大型语言模型(large language models, LLMs)的出现为生成类似于人类标注的文本样本创造了新的条件。LLMs的参数空间允许它们存储大量知识,大规模预训练使得LLMs能够编码用于文本生成的丰富知识。如生成式预训练语言模型(generative pre-trained transformer, GPT)系列,GPT~GPT-3[8,23-24]采用预训练+微调的方式,其中预训练阶段通过大规模的无标注数据对模型进行训练,使其学习到通用的语言表示和语义理解能力,微调阶段利用有标注数据进行监督学习,使模型能够适应特定的任务要求,提高性能和准确度。GPT系列目前已经发展到4.0, 聊天生成预训练转换器(chat generative pre-trained transformer, ChatGPT)遵循指导生成预训练转换器(instruct generative pre-trained transformer,InstructGPT)[25]的训练方式,利用带有人类反馈的强化学习(reinforcement learning from human feedback, RLHF),使其在对话领域能够对输入产生更丰富的响应。这些最先进的模型也被广泛地用来进行数据增强,Abonizio等[26]通过连接样本中的3个随机token作为GPT-2模型生成阶段的前缀生成样本。Kumar等[27]研究了不同类型的基于Transformer的预训练语言模型,表明将类标签处理到文本序列为微调预训练模型进行数据增强提供了一种简单有效的方法;Bayer等[28]设计了一种基于GPT-2的方法,通过设计不同的前缀分别处理短文本和长文本的生成,在短文本任务和长文本任务上都取得了很好的改进。类似的,Claveau等[29]使用特定于类的数据微调GPT-2模型,并从原始文本中输入一个随机单词进行生成。然后应用分类器对生成的数据样本进行过滤。Liu[30]冻结GPT-2模型softmax之前的层,采用强化学习对softmax之后的层进行微调。随着ChatGPT的问世,Dai等[31]提出了ChatAug,利用ChatGPT为文本生成增强数据,获得了显著提升。
引入噪声的方法可以有效提升数据的多样性,利用预训练语言模型的数据增强方法可以更好地学习到语言规律和语义信息,因此,基于上述工作,本文提出惩罚生成式预训练语言模型的数据增强方法(punishing generative pre-trained transformer for data augmentation, PunishGPT-DA),通过设计损失函数微调预训练语言模型GPT-2,有效保证增强数据的质量。
2. PunishGPT-DA
2.1 方法概述
句子分类是一种基于句子数据进行分类的任务,属于监督学习问题的一个实例。给定训练集
${D_{{\rm{train}}}} = \{ ({x_i},{l_i})\} _{i = 1}^N$ ,包含N个训练样本,其中xi是由$\{ {x_i}^1,{x_i}^2,\cdots ,{x_i}^p\} $ 组成的文本序列,包含p个字符, li∈{1, 2, ···, q}表示在含有q个标签的集合中,样本xi对应的标签。xi∈X,X代表整个样本空间,假设对于所有N,存在函数f,使li=f(xi),监督学习的目标是在仅给定数据集Dtrain的情况下在整个X上近似f,从Dtrain的域推广到整个X,即在Dtrain上训练分类算法F,使其能够近似f,然而如果Dtrain非常小,将显著地影响算法F的性能。数据增强试图通过合成额外的训练数据来解决这个问题,给定训练集Dtrain和算法F,本文的目标是生成${D_{{\rm{aug}}}} = \{ ({y_j},{l_j})\} _{j = 1}^T$ ,$ {D_{{\rm{aug}}}} = {D_{{\rm{train}}}} \cup {D_{{\rm{filter}}}} $ ,其中Dfilter是方法每次迭代后生成的数据,Daug是最终数据集,包含T个样本, yj是由$\{ {y_j}^1,{y_j}^2,\cdots ,{y_j}^m\} $ 组成的文本序列,包含m个字符,对应标签为lj。为此,本文提出了一种面向句子分类的数据增强方法PunishGPT-DA。PunishGPT-DA由生成器Gθ和过滤器F 2个模块组成。图1说明了本方法的步骤:1)通过改进的损失函数微调生成器的语言模型,训练生成器学习在原始句子的基础上合成新样本,得到参数被微调之后的生成器Gθ。2)对Dtrain进行处理作为Gθ的输入生成数据Dsyn,Dsyn相较于原损失函数训练出的生成器生成的数据拥有更高的多样性,但也不可避免地引入了噪声。3)针对此问题,采用原始数据Dtrain微调过滤器F,将每次迭代生成的样本Dsyn由F过滤,丢弃低质量的样本,得到过滤后的增强样本Dfilter,Dfilter并入原始数据集中作为新的Dtrain进行下一次迭代,经过一定次数的迭代后得到最终的数据集Daug。
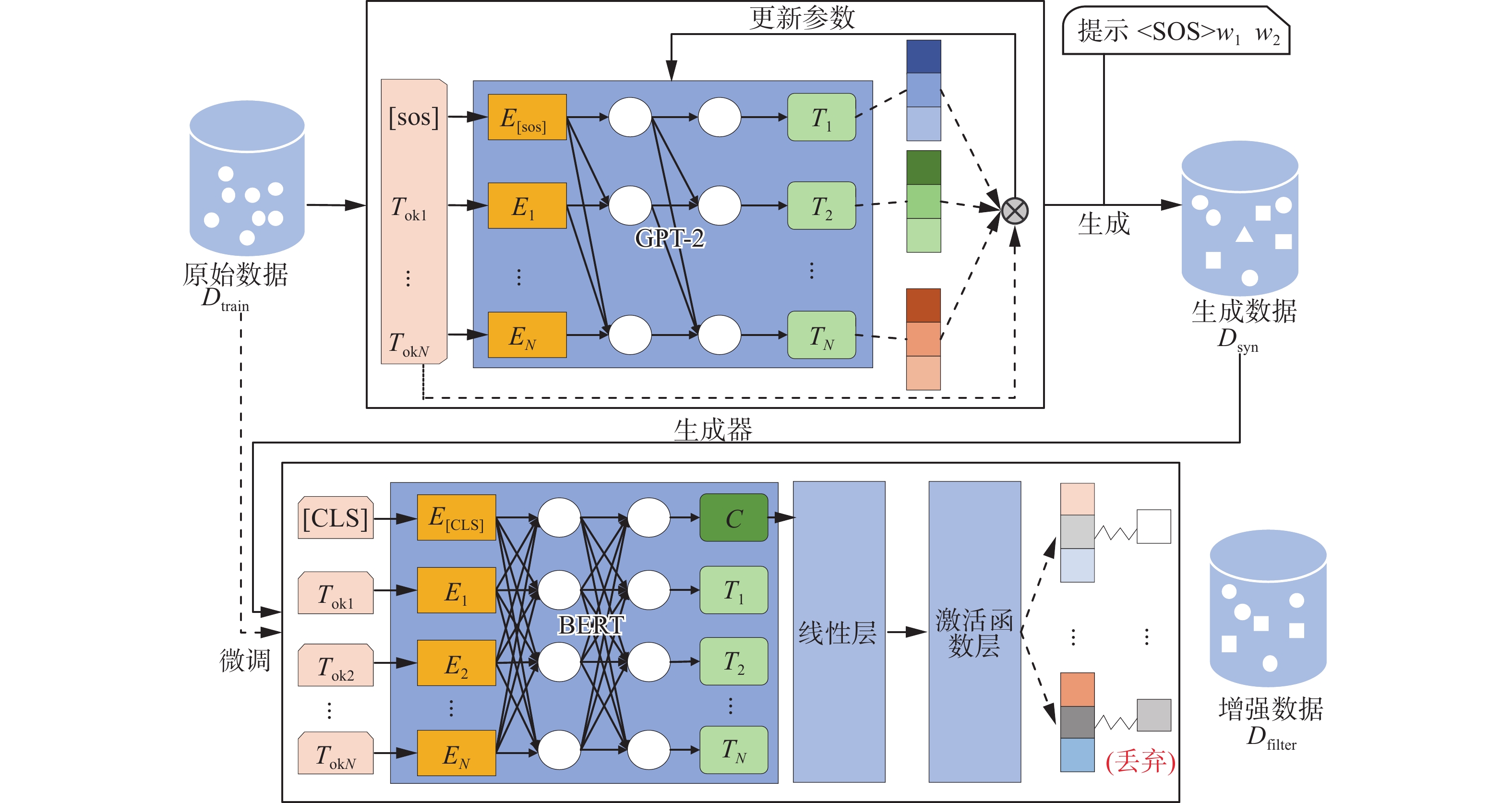 图 1 PunishGPT-DA数据增强过程Fig. 1 PunishGPT-DA data augmentation process
图 1 PunishGPT-DA数据增强过程Fig. 1 PunishGPT-DA data augmentation process 下载:
全尺寸图片
下载:
全尺寸图片
2.2 生成器
PunishGPT-DA采用预训练语言模型GPT-2生成数据,GPT-2是一个在海量数据集上训练的语言模型,采用“预训练+微调”的二段式训练策略,它利用庞大的语料库进行预训练,语料库被处理成由token组成的长序列,由
$ {{{U}}} = {w^1},{w^2},\cdots, {w^j},\cdots , {w^T} $ 表示,生成模型采用无监督自回归训练的方式,以最大化生成目标序列的概率为目标,根据极大似然估计,可以最大化目标序列U出现的概率,即最大化P(U),根据条件概率的链式法则,可以将生成目标序列的概率表示为条件概率的乘积:$$ P(U) = \prod\nolimits_{j = 1}^T {{{{{G}}}_\theta }({{{{w}}}^j}|{{{{w}}}^{j - k}},{{{{w}}}^{j - k-1}},\cdots ,{{{{w}}}^{j - 1}})} $$ (1) 将式(1)取对数并加上负号,得到负对数似然损失函数为
$$ \begin{gathered} {J_\theta } = - \log \left(\prod\nolimits_{j = 1}^T {{{{{G}}}_\theta }({{{{w}}}^j}|{{{{w}}}^{j - k}},{{{{w}}}^{j - k-1}},\cdots ,{{{{w}}}^{j - 1}})} \right)= \\ - \sum\limits_j {\log ({{{{G}}}_\theta }({{{{w}}}^j}|{{{{w}}}^{j - k}},{{{{w}}}^{j - k-1}},\cdots ,{{{{w}}}^{j - 1}}))} \\ \end{gathered} $$ (2) 在数据增强任务中,同预训练一致,以句子自身指导模型的微调,即以最大化生成目标序列的概率为目标,因此,以负对数似然函数作为损失函数的生成模型鼓励生成与原数据相似的句子,使生成的文本趋于重复和“枯燥”,当以此为目标训练得非常好时,甚至会生成与输入句子完全一致的样本数据。
为了关注生成数据的多样性,本文引入惩罚项来中和现有的损失函数,同时为了平衡多样性与语义一致性,引入超参数
$\alpha $ ,改进后的损失函数为$$ {L'}=\alpha \cdot {J}_{\theta }+(1-\alpha )\cdot \mathrm{exp}(-{J}_{\theta }) $$ (3) 式(3)是一种加权损失函数,由Jθ 和
$ \exp ( - {J_\theta }) $ 2部分组成。其中Jθ,即式(2)是负对数似然损失,用于衡量生成的序列和目标序列之间的差距;$ \exp ( - {J_\theta }) $ 将其视为惩罚项,用于惩罚过度相似的生成结果,这意味着,如果生成器产生与目标序列中过于相似的token,它将受到惩罚。本文拟通过添加$ \exp ( - {J_\theta }) $ ,使模型会在给定上下文条件下,根据语言的语法和语义规则,更加关注可能性较小但仍然有一定意义与合理性的输出。这些输出可能是预测概率较小但仍然合理的单词、短语、句子结构等,在某些情况下可能会提供更有趣、更具创造性的文本。$\alpha $ 是一个用于控制Jθ 和$ \exp ( - {J_\theta }) $ 2部分在损失函数中重要程度的超参数,当α较小时,$ \exp ( - {J_\theta }) $ 的影响更大,从而鼓励生成多样性更高的样本。相反,当$\alpha $ 较大时,Jθ 的影响更大,从而鼓励生成语义一致性更高的样本。因此,式(3)可以看作在保证生成序列准确的基础上,通过惩罚过度自信的生成结果来鼓励生成更多的多样性,通过调整$\alpha $ 的值,可以在一致性和多样性之间进行平衡,获得高质量的生成结果。此外,在预测阶段,通常采用序列的前i个字符作为前缀提示后续词语的生成,然而,Dtrain中存在多个序列前i个字符相同,以相同的前缀作为提示会导致原本不同标签的2个句子对应的增强样本可能相同,使得增强样本语义标签不明。因此,本文为每条训练数据添加了数字序号作为该数据的唯一标志,数字序号随训练数据一起参与训练。在预测阶段,数字序号与前i个字符一起作为前缀,确保了前缀的唯一性,并为生成器提供了额外的上下文,形式为(
$\left\langle {\rm{SOS}} \right\rangle $ ,w1,w2,···,wi),其中$\left\langle {\rm{SOS}} \right\rangle $ 是数字序号,(w1,w2,···,wi)是样本的前i个字符。这种操作确保了增强样本彼此不同,但仍然基于实际数据。2.3 过滤器
使用增强样本的一个障碍是它可能引入的噪声和误差。虽然在微调生成器时同时考虑了语义保留和丰富表达,避免了模型过度生成低频词,但自然语言具有复杂性,有可能微小的改动便会影响句子的语义,导致增强数据集中的低质量样本对下游任务模型的性能产生影响。为此,如图1所示,本文使用基于BERT的过滤器F对其进行过滤选择,过滤器F包括BERT层、线性层、ReLU激活函数层。输入数据首先经过BERT层获取特征表示,其次通过Dropout技术进行正则化处理,以减少过拟合风险,然后将Dropout层的输出输入到一个具有786个输入特征和类别数量输出特征的线性变换层,将特征表示映射到分类标签的空间,最后经过ReLU激活函数得到最终的分类结果。对于生成的样本 (y,l),验证是否F(y)=l,若分类正确则保留,不正确舍弃。因此,每一次完整的迭代后会得到增强数据集Dfilter,Dfilter并入原始集作为新的训练集。
3. 实验结果与分析
3.1 数据集
本文共使用了3个公开的句子分类数据集,分别是由法国公司SNIPS在人机交互过程中收集的数据集SNIPS,包含7个意图类别共14 484条数据。由文本检索会议(text retrieval conference, TERC)标注的细粒度问题分类数据集TREC,包含6种问题类型共5 952条数据。由斯坦福大学自然语言处理组标注的情感分析数据集(stanford sentiment treebank v2, SST-2), SST-2属于电影评论情感分类的数据集,用2个标签(positive和negative)标注,共8 741条数据。
3.2 实验设置
根据先前工作[25]模拟用于句子分类少样本场景的设置,本文针对每个任务的训练集进行子采样,每个类随机选择10个样本,每个数据增强模型均对其进行16倍扩充。为避免数据集的随机性带来误差,本文一个任务下的对比实验均采用相同的子数据集。为更好地测试模型的性能,本文的验证集和测试集采用完整的数据集。
在微调GPT-2阶段,设置批量大小为2,迭代次数为100,学习率设定为1×10−5,样本最大长度为20,超过则截断;生成数据时每条句子的提示为“i w1 w2”。BERT在大量数据上进行预训练,并在几个句子分类任务上表现出最先进的性能。因此,本文使用BERT模型构建过滤器及句子分类器,本文使用“BERT-Base-Uncased” 模型,该模型有12层,768个隐藏状态和12个头。PunishGPT-DA使用BERT模型第1个特殊字符([CLS])的输出作为句子的特征表示,在传入下一层进行分类之前,以0.1的dropout设置应用于句子表示。训练过程采用自适应矩估计算法(adaptive moment estimation,Adam)进行优化,学习率设置为4×10−5,本文对模型进行100个epoch的训练,并在验证集上选择表现最好的模型进行评估。
所有的实验均在Intel Core i5-9500 3.00 GHz处理器,GeForce RTX 2028 SUPER显卡,Ubuntu 20.04.4 LTS,python 3.8.0下进行。
本文实验将与以下模型进行对比:
1) GPT-2[7]:为验证本文提出损失函数的有效性,本文以GPT-2作为基准模型,该模型以式(1)为损失函数,其余条件与PunishGPT-DA保持一致。
2) EDA[4]:以词替换、交换、插入和删除为基础的数据增强方法。
3) AEDA[5]:在句子中随机插入标点符号实现数据增强。
4) GPTcontext[25]:采用文献[6]中的方式,将标签与序列连接起来构造训练集:y1SEPx1EOSy2, ···, ynSEPxnEOS。在此基础上以yiSEPw1, ···, wk作为生成阶段的提示,生成增强数据。
3.3 实验结果与分析
本文对比了在意图识别、问题分类及情感分析任务少样本情景下的数据增强策略,表1总结了多种数据增强方法下同一模型在不同数据集中的分类准确率。
如表1所示,与基线模型GPT-2相比,本文提出的数据增强方法在3个数据集上的准确率相对提升了1.1%、4.9%和8.7%,这说明本文提出的损失函数能有效提升增强数据的质量;相较于EDA、AEDA和GPTcontex方法,本文提出的数据增强方法在3个数据集上的准确率均有提升,表明了本文增强方法的普遍性。
本文对比了不同超参数α设置下PunishGPT-DA的性能,采用SNIPS 的子采样后的数据集,每个类别包含10个样本,对其进行16倍扩充。如图2所示,α=0.3之前模型准确率较低,这是因为在超参数控制下增强数据多样性较强,为数据集引入了过多的噪声;随着α增大,曲线逐渐上升,直到α=0.45时下游任务模型准确率达到最高,此时生成模型能够很好地控制数据多样性和一致性之间的平衡,使模型准确率达到最好的效果;随着α继续增大,一致性占据优势,使得生成数据相较于原数据只有微小的改动,致使模型准确率下降,趋于平缓。这表明,本文提出的损失函数能够同时控制语义和多样化的表达,有效平衡数据的一致性和多样性。
 图 2 不同超参数下模型准确率Fig. 2 Model accuracy under different hyperparameters下载:
全尺寸图片
图 2 不同超参数下模型准确率Fig. 2 Model accuracy under different hyperparameters下载:
全尺寸图片
本文研究了过滤机制对PunishGPT-DA性能的影响,分别在3个子采样后的数据集上进行了消融实验。实验结果如表2所示,删除了过滤机制后,模型准确率均有下降。这表明过滤器对整个增强过程至关重要。
表 2 过滤机制对PunishGPT-DA的影响Table 2 Influence of filtering mechanism on PunishGPT-DA% 方法 SNIPS TREC SST-2 PunishGPT-DA 87.4 68.1 61.2 过滤 87.0 59.3 52.5 此外,本文还研究了在不同数据集大小情况下PunishGPT-DA对下游任务模型性能的影响。表3为模型在SNIPS 数据集上进行实验的结果,每种意图类别分别取为5、10、20、50、100条数据作为训练样本,构成少样本数据集,并进行16倍扩充。如表3所示,随着训练数据的增多,本文的数据增强方法对下游任务模型性能的提升作用越来越弱。这表明在少样本情境下,本文所提出的数据增强方法可以有效提升句子分类任务模型性能,当训练数据较为充足时,已经能为下游任务模型提供较为丰富的信息,数据增强带来的效益也就随之减弱。
表 3 PunishGPT-DA在不同数据集大小下的准确率Table 3 Accuracy of PunishGPT-DA under different dataset sizes% 方法 5 10 20 50 100 无增强 75.9 84.4 88.9 94.6 97.0 PunishGPT-DA 78.9 87.4 91.3 95.3 97.1 为了更加明确损失函数的作用机制,本文分别对采用2种损失函数生成的数据进行了探索,如表4所示,本文分别摘取了部分数据。通过观察损失函数式(3)生成的数据及过滤后的数据可以发现,数据较原始数据有较大的多样性,但大体上符合标签语义;采用损失函数式(2)生成的数据较原始数据只有个别单词的变化,多样性引入不足。由此可以发现本文提出损失函数的有效性。
表 4 生成数据示例Table 4 Generate data samples操作 数据示例 原始数据 1. book a brasserie(BookRestaurant)
2. play a melody by colin blunstone(PlayMusic)
3. can you add some disco to my playlist called genuine r&b(AddToPlaylist)损失函数式(3)生成数据 1. book a restaurant where i can get a burrito
2. play a melody by kaori utatsuki off the album that has top-twenty hits
3. can you play a song off a disc that has a top ten hit rate of 2%损失函数式(3)过滤后数据 1. book a restaurant where i can get a burrito
2. play a melody by kaori utatsuki off the album that has top-twenty hits损失函数式(2)生成数据 1. book a restaurant
2. play a melody by colin blunstone please
3. can you please add some disco music to my playlist called genuine r&b损失函数式(2)过滤后数据 1. book a restaurant
2. play a melody by colin blunstone please
3. can you please add some disco to my playlist called genuine r&b注:表中“原始数据”行括号内单词代表该句子的标签;表格中加粗部分代表相对于原始数据的不同之处。 4. 结束语
针对少样本句子分类任务中训练数据不足的问题,本文提出一种平衡语义一致性和多样性的数据增强方法PunishGPT-DA,与当前主流方法相同,此方法建立在大规模的预训练语言模型的基础上,同时又区别于当前主流方法修改提示指导生成模型生成阶段的做法,本文提出的方法从训练角度指导模型生成数据。实验结果表明,在小样本情景下,本文方法可以更有效地保证数据质量,有效提高句子分类模型的分类准确率。尽管本文解决了增强样本质量不高的问题,然而通过损失函数控制数据的生成,可能会导致语法不可控地变化,不符合人类正常的阅读习惯,因此,在句子结构多样性方面还有一定的提升空间。下一步将探索句子结构方面的改进,使其更加自然流畅。
-
图 1 PunishGPT-DA数据增强过程
Fig. 1 PunishGPT-DA data augmentation process
下载:
全尺寸图片
图 2 不同超参数下模型准确率
Fig. 2 Model accuracy under different hyperparameters
下载:
全尺寸图片
表 1 不同增强策略下的模型准确率
Table 1 Model accuracy under different augmentation strategies
% 表 2 过滤机制对PunishGPT-DA的影响
Table 2 Influence of filtering mechanism on PunishGPT-DA
% 方法 SNIPS TREC SST-2 PunishGPT-DA 87.4 68.1 61.2 过滤 87.0 59.3 52.5 表 3 PunishGPT-DA在不同数据集大小下的准确率
Table 3 Accuracy of PunishGPT-DA under different dataset sizes
% 方法 5 10 20 50 100 无增强 75.9 84.4 88.9 94.6 97.0 PunishGPT-DA 78.9 87.4 91.3 95.3 97.1 表 4 生成数据示例
Table 4 Generate data samples
操作 数据示例 原始数据 1. book a brasserie(BookRestaurant)
2. play a melody by colin blunstone(PlayMusic)
3. can you add some disco to my playlist called genuine r&b(AddToPlaylist)损失函数式(3)生成数据 1. book a restaurant where i can get a burrito
2. play a melody by kaori utatsuki off the album that has top-twenty hits
3. can you play a song off a disc that has a top ten hit rate of 2%损失函数式(3)过滤后数据 1. book a restaurant where i can get a burrito
2. play a melody by kaori utatsuki off the album that has top-twenty hits损失函数式(2)生成数据 1. book a restaurant
2. play a melody by colin blunstone please
3. can you please add some disco music to my playlist called genuine r&b损失函数式(2)过滤后数据 1. book a restaurant
2. play a melody by colin blunstone please
3. can you please add some disco to my playlist called genuine r&b注:表中“原始数据”行括号内单词代表该句子的标签;表格中加粗部分代表相对于原始数据的不同之处。 -
[1] AGGARWAL C C, ZHAI Chengxiang. A survey of text classification algorithms[M]. Boston: Springer, 2012: 163−222. [2] ASH J T, ZHANG Chicheng, KRISHNAMURTHY A, et al. Deep batch active learning by diverse, uncertain gradient lower bounds[EB/OL]. (2020−02−24)[2023−04−30]. https://arxiv.org/abs/1906.03671.pdf. [3] CUBUK E D, ZOPH B, MANÉ D, et al. AutoAugment: learning augmentation strategies from data[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 113−123. [4] 孙晓,丁小龙. 基于生成对抗网络的人脸表情数据增强方法[J]. 计算机工程与应用, 2020, 56(4): 115–121. SUN Xiao, DING Xiaolong. A facial expression data enhancement method based on generative adversarial networks[J]. Computer engineering and applications, 2020, 56(4): 115–121. [5] WEI J, ZOU Kai. EDA: easy data augmentation techniques for boosting performance on text classification tasks[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA, USA: Association for Computational Linguistics, 2019: 6382−6388. [6] KARIMI A, ROSSI L, PRATI A. AEDA: an easier data augmentation technique for text classification[C]//Findings of the Association for Computational Linguistics: EMNLP 2021. Stroudsburg, PA, USA: Association for Computational Linguistics, 2021: 2748−2754. [7] ANABY-TAVOR A, CARMELI B, GOLDBRAICH E, et al. Do not have enough data? deep learning to the rescue![J]. Proceedings of the AAAI conference on artificial intelligence, 2020, 34(5): 7383–7390. doi: 10.1609/aaai.v34i05.6233 [8] RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9. [9] DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis: Association for Computational Linguistics, 2019: 4171−4186. [10] ZHANG Xiang, ZHAO Junbo, LECUN Y. Character-level convolutional networks for text classification[C]//NIPS'15: Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1. Cambridge: MIT Press, 2015: 649−657. [11] WU Xing, LV Shangwen, ZANG Liangjun, et al. Conditional BERT contextual augmentation[C]//International Conference on Computational Science. Cham: Springer, 2019: 84−95. [12] JIAO Xiaoqi, YIN Yichun, SHANG Lifeng, et al. TinyBERT: distilling BERT for natural language understanding[C]//Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg: Association for Computational Linguistics, 2020: 4163−4174. [13] NG N, YEE K, BAEVSKI A, et al. Facebook FAIR’s WMT19 news translation task submission[C]//Proceedings of the Fourth Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1). Stroudsburg: Association for Computational Linguistics, 2019: 314−319. [14] HOU Yutai, CHEN Sanyuan, CHE Wanxiang, et al. C2C-GenDA: cluster-to-cluster generation for data augmentation of slot filling[J]. Proceedings of the AAAI conference on artificial intelligence, 2021, 35(14): 13027–13035. doi: 10.1609/aaai.v35i14.17540 [15] KOBER T, WEEDS J, BERTOLINI L, et al. Data augmentation for hypernymy detection[C]//Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg: Association for Computational Linguistics, 2021: 1034−1048. [16] PENG Baolin, ZHU Chenguang, ZENG M, et al. Data augmentation for spoken language understanding via pretrained language models[EB/OL]. (2021−03−11)[2023−04−30]. https://arxiv.org/abs/2004.13952.pdf. [17] SAHIN G G, STEEDMAN M. Data augmentation via dependency tree morphing for low-resource languages[EB/OL]. (2019−03−22)[2023−04−30]. https://arxiv.org/abs/1903.09460.pdf. [18] SUN Lichao, XIA Congying, YIN Wenpeng, et al. Mixup-transformer: dynamic data augmentation for NLP tasks[C]//Proceedings of the 28th International Conference on Computational Linguistics. Stroudsburg, PA, USA: International Committee on Computational Linguistics, 2020: 3436−3440. [19] FENG S Y, GANGAL V, KANG D, et al. GenAug: data augmentation for finetuning text generators[C]//Proceedings of Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Architectures. Stroudsburg: Association for Computational Linguistics, 2020: 29−42. [20] ANDREAS J. Good-enough compositional data augmentation[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2020: 7556−7566. [21] GUO Demi, KIM Y, RUSH A. Sequence-level mixed sample data augmentation[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2020: 5547−5552. [22] 丁家杰, 肖康, 叶恒等. 面向问答领域的数据增强方法[J]. 北京大学学报(自然科学版), 2022, 58(11): 54–60. DING Jiajie, Xiao Kang, Ye Heng, et al. A data augmentation method for the field of question and answer[J]. Acta scientiarum naturalium universitatis pekinensis, 2022, 58(11): 54–60. [23] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[EB/OL]. (2018)[2023−04−26]. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf. [24] BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems. New York: ACM, 2020: 1877−1901. [25] OUYANG Long, WU J, XU Jiang, et al. Training language models to follow instructions with human feedback[C]//Advances in Neural Information Processing Systems. New Orleans: Curran Associates, Inc. , 2022: 27730−27744. [26] ABONIZIO Q H, JUNIOR B S. Pre-trained data augmentation for text classification[C]//Intelligent Systems: 9th Brazilian Conference, BRACIS 2020, Rio Grande, Brazil, October 20–23, 2020, Proceedings, Part I. Cham: Springer International Publishing, 2020: 551−565. [27] KUMAR V, CHOUDHARY A, CHO E. Data augmentation using pre-trained transformer models[C]//Proceedings of the 2nd Workshop on Life-long Learning for Spoken Language Systems. Suzhou, China: Association for Computational Linguistics, 2020: 18−26. [28] BAYER M, KAUFHOLD M A, BUCHHOLD B, et al. Data augmentation in natural language processing: a novel text generation approach for long and short text classifiers[J]. International journal of machine learning and cybernetics, 2023, 14(1): 135–150. doi: 10.1007/s13042-022-01553-3 [29] CLAVEAU V, CHAFFIN A, KIJAK E. Generating artificial texts as substitution or complement of training data[C]//Proceedings of the Thirteenth Language Resources and Evaluation Conference. Marseille, France: European Language Resources Association, 2022: 4260−4269. [30] LIU Ruibo, XU Guangxuan, JIA Chenyan, et al. Data boost: text data augmentation through reinforcement learning guided conditional generation[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2020: 9031–9041. [31] DAI Haixing, LIU Zhengliang, LIAO Wenxiong, et al. AugGPT: leveraging ChatGPT for text data augmentation[EB/OL]. (2023−03−20)[2023−04−30]. https://arxiv.org/abs/2302.13007.pdf.




















