
Ship detection in remote sensing images via feature reuse and dilated convolution
-
摘要: 在光学遥感图像中,港口内的舰船目标通常处于密集的船只群中,并受到周围环境的干扰和遮挡,如集装箱、车辆等。为了进一步提高现有舰船目标检测算法的精度和泛化性能,提出了一种基于特征重用和膨胀卷积的遥感图像舰船检测算法。首先构建了基于分组卷积和拆分注意力的残差块来提取特征,同时嵌入可变形卷积提取更加符合舰船尺度变化的特征;接着,构造了多尺度感受野模块,通过并行提取多尺度特征后再进行融合来减少信息损失;最后,在原有特征金字塔的基础上构建了一条自底向上的特征重用聚合路径以提高特征表示能力。在大型遥感数据集DOTA和舰船数据集HRSC2016上进行实验,实验结果表明,所提方法能够有效缓解舰船目标漏检和误检问题,提高了遥感图像舰船目标检测的精度。Abstract: In optical remote sensing images, ship targets in ports are often densely grouped and obstructed by the surrounding environment, such as containers and vehicles. To further improve the accuracy and generalization performance of existing ship target detection algorithms, this study proposes a remote sensing image ship detection algorithm based on feature reuse and dilated convolution. First, a residual block based on grouped convolution and split attention is constructed to extract features, with deformable convolution embedded to better handle ship scale variations. Afterward, a multiscale receptive field module is designed to reduce information loss by parallel extraction and fusion of multiscale features. Finally, a bottom-up feature reuse aggregation path is developed based on the original feature pyramid to enhance feature representation. Experiments were conducted on the large-scale remote sensing dataset, DOTA and the ship dataset, HRSC2016. The results show that the proposed method effectively alleviates the issues of missing and false detections of ship targets, leading to increased accuracy in ship target detection in remote sensing images.
-
随着遥感技术的不断发展和进步,遥感成像方式也呈现出多样化,基于遥感图像的目标检测也因此成为计算机视觉领域中一个重要的研究分支。舰船作为海上重要交通工具和经济活动的关键组成部分,对于国家安全和经济发展具有至关重要的作用[1]。光学遥感图像可以获取高分辨率的图像,能够提供更为详细和精准的地表信息,可以获取可见光、红外等多种波段信息,捕捉地表微小目标[2],但是在海陆交接区域,受岸上车辆、集装箱等影响,进行舰船目标检测时会出现误检、漏检现象。另外近岸港口和海上舰船目标分布不平衡,港口通常会有大量密集停靠的船舶,而海上拍摄的图像可能只包含单个目标,这种分布不平衡的数据会影响机器学习模型的学习和识别能力。
传统的目标检测方法包括滑动窗口法[3]、模板匹配法[4]、背景建模法[5]、轮廓法[6]等,由于容易受目标尺寸、位置、形状和遮挡等因素的影响,这些方法的检测效果受到限制,对复杂的场景目标存在误检和漏检等问题,并且传统方法通常需要手动设计特征或分类器,难以适应不同场景目标,难以进行有效的迁移学习。2012年AlexNet网络[7]的提出给遥感图像舰船检测带来新的机遇和挑战,目前基于深度学习的目标检测方法分为基于锚框(anchor-base)和无锚框(anchor-free)检测方法,基于锚框的检测方法是指通过预定义的一组锚框,在图像上生成候选框,然后利用卷积神经网络对候选框进行分类和回归,具体细分为Faster R-CNN(faster region-based convolutional neural network)[8]、Oriented R-CNN[9]、ReDet(rotation-equivariant detector)[10]、ROI Transformer(region of interest Transformer)[11]等两阶段检测方法和YOLO(you only look once)[12]、RetinaNet[13]、S2A-Net(single-shot alignment net)[14]、STYOLO(ShuffleNet Tiny-YOLO)[15]等一阶段检测方法,基于锚框的检测方法可以在不同尺度上生成多个不同大小和长宽比的锚框,以适应不同尺寸和形状的目标,因此检测精度较高;无锚检测方法则直接在输入图像上对目标位置进行回归,不需要生成锚框,通常具有更简单的网络和更快的检测速度,例如FCOS(fully convolutional one-stage object detector)[16]、Sasm_reppoints(shape-adaptive selection and measurement reppoints)[17]、CornerNet[18]等。
随着深度学习的广泛应用,越来越多的研究者将其应用到遥感图像舰船检测领域,Yang等[19]提出了自上而下的密集连接特征金字塔来融合多尺度特征并且设计特征对齐模块来提高舰船检测精度;成倩等[20]对聚合网络进行改进,同时使用Swish函数作为激活函数,提高网络对数据非线性特征的表征能力,提高模型对尺度变化大的数据集的泛化能力;Ran等[21]使用复平面代替传统平面角度解决了旋转检测框边界不连续问题;王昌安等[22]引入生成对抗网络增强细粒度的类别间判别能力,有效地了提升舰船目标的细粒度识别精度。尽管上述算法取得了不错的效果,提高了检测精度并解决了预测框与目标匹配不准确问题,但是在近岸舰船目标密集排列等复杂场景中,由于岸上车辆、集装箱等背景噪声的影响,模型不能够有效提取舰船目标特征,仍会存在目标的误检、漏检问题,检测算法精度仍然有待提高。针对以上问题,本文以两阶段目标检测算法为基础,提出了一种基于特征重用和膨胀卷积[23]的遥感图像舰船目标检测算法,本文的主要工作如下:1) 使用多分支和通道注意力结合的拆分注意力机制构造新的残差块进行特征提取,同时嵌入可变形卷积网络(deformable convolution network, DCN)[24]提取更加符合目标形状的特征图。2) 针对特征图通道数骤减造成的信息损失问题,构造了多尺度感受野(multi scale receptive field, MSRF)模块,使用不同膨胀率的膨胀卷积并行提取多感受野特征。3) 针对原始特征金字塔特征提取不充分问题,在原始特征金字塔基础上构建了一条新的自底向上的特征重用聚合路径(feature reuse aggregation path, FRAP),提高特征提取能力。
1. 理论基础
两阶段目标检测算法通过在特征图上均匀生成大量不同尺度和长宽比的候选框,然后对候选框进行分类和回归,从而得到最终的检测结果,因此两阶段检测算法精度较高。以Oriented R-CNN算法为例,整体结构由主干网络、特征金字塔网络(feature pyramid network, FPN)、方向区域生成网络(oriented region proposal network, Oriented RPN)和Oriented R-CNN Head 4部分组成。首先,输入图像经过主干网络进行特征提取,得到提取后的特征图,深层特征具有更强的语义信息,适用于目标分类,浅层特征具有更高的分辨率,适合候选框的回归,FPN通过简单的自上而下路径将深层语义信息和浅层细节信息特征进行融合,以更好地适应大小不同的目标。
为了减少计算资源的消耗、提高检测效率,Oriented RPN首先以[1∶2,1∶1,2∶1]不同长宽比生成不同尺度的水平锚框,每组锚框用
$ {\boldsymbol{a}} = ({a_x},{a_y},{a_w},{a_h}) $ 表示,其中$({a_x},{a_y})$ 表示锚框的中心点坐标,${a_w}$ 和${a_h}$ 分别代表锚框的宽和高,使用1×1卷积的回归分支生成锚框的6个偏移量$ {\boldsymbol{J}} = ({\vartheta _x},{\vartheta _y},{\vartheta _w},{\vartheta _h},{\vartheta _\alpha },{\vartheta _\beta }) $ ,接着对回归结果进行解码得到旋转框,公式表示为$$ \left\{\begin{array}{*{20}{l}}x=\vartheta_x\cdot a_w+a_x,\ y=\vartheta_y\cdot a_h+a_y \\ w=a_w\cdot\text{e}^{\vartheta_w},\ h=a_h\cdot\text{e}^{\vartheta_h} \\ \Delta\alpha=\vartheta_{\alpha}\cdot w,\ \Delta\beta=\vartheta_{\beta}\cdot h\end{array}\right. $$ 式中:
$(x,y)$ 表示预测框的中心点坐标,$w$ 和$h$ 分别代表预测框的宽和高,$\Delta \alpha $ 和$\Delta \beta $ 分别表示预测框顶点相对于外接矩形上侧和右侧中心点的偏差,坐标偏差可视化如图1所示。$(\Delta \alpha ,0)$ 表示旋转预测框顶点P1相对于水平框上侧中心点的偏移量,$(0,\Delta \beta )$ 表示旋转预测框顶点P2相对于水平框右侧中心点的偏移量,计算旋转检测框的4个顶点坐标公式为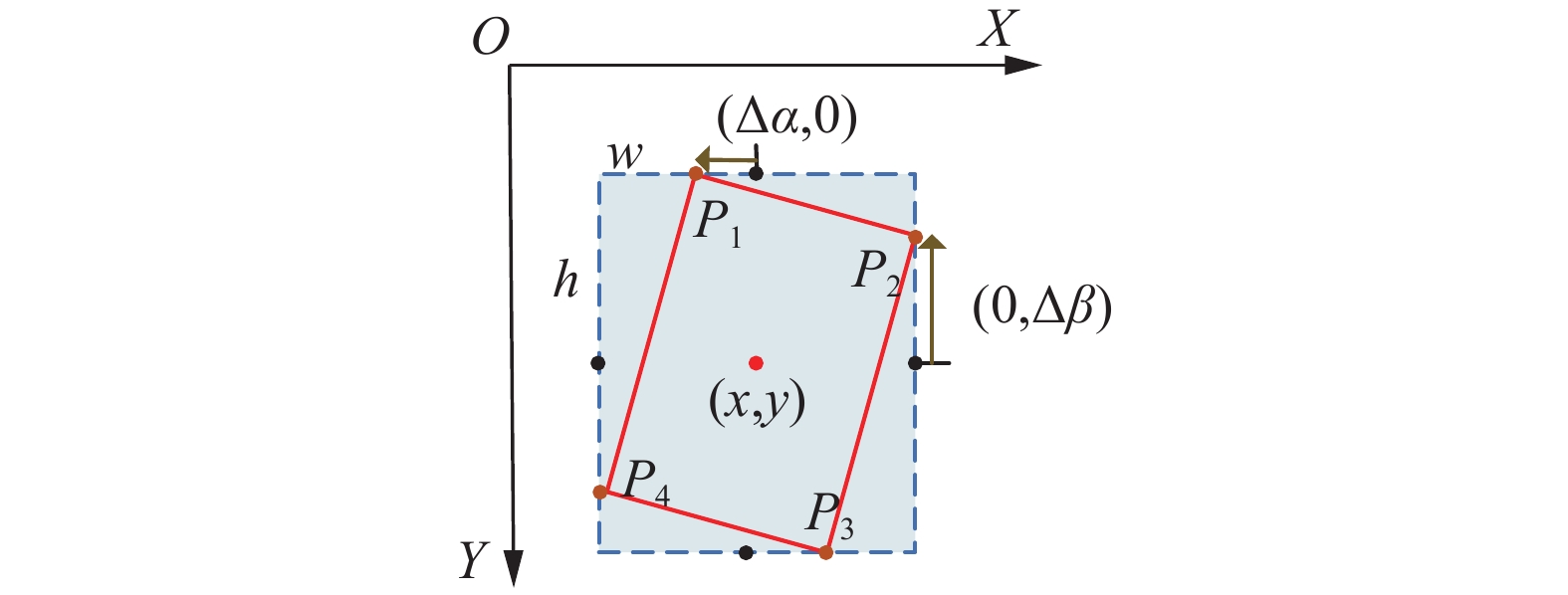 图 1 坐标偏差可视化Fig. 1 Coordinate deviation visualization
图 1 坐标偏差可视化Fig. 1 Coordinate deviation visualization 下载:
全尺寸图片
下载:
全尺寸图片
$$ \left\{ {\begin{array}{*{20}{l}} {{P_1} = \left( {x,y - {h \mathord{\left/ {\vphantom {h 2}} \right. } 2}} \right) + \left( {\Delta \alpha ,0} \right)} \\ {{P_2} = \left( {x + {w \mathord{\left/ {\vphantom {w 2}} \right. } 2},y} \right) + \left( {0,\Delta \beta } \right)} \\ {{P_3} = \left( {x,y + {h \mathord{\left/ {\vphantom {h 2}} \right. } 2}} \right) + \left( { - \Delta \alpha ,0} \right)} \\ {{P_4} = \left( {x - {w \mathord{\left/ {\vphantom {w 2}} \right. } 2},y} \right) + \left( {0, - \Delta \beta } \right)} \end{array}} \right. $$ RPN输出特征图经过Oriented R-CNN Head的感兴趣区域对齐(regions of interest align, ROIAlign)模块,将目标特征转化为固定大小区域,然后连接全连接层,最后由分类和回归分支对预测框进行分类和坐标回归调整,得出最终的预测框。本文算法整体结构如图2所示。
 图 2 算法整体结构Fig. 2 Overall structure of the algorithm下载:
全尺寸图片
图 2 算法整体结构Fig. 2 Overall structure of the algorithm下载:
全尺寸图片
2. 改进算法
2.1 主干网络ResNeSt
ResNet50[25]已经广泛应用于各类计算机视觉任务,并且表现出不错的性能,但是在大规模、复杂图像数据场景中,提取目标特征能力有限。ResNeSt50[26]在ResNet50基础上使用拆分注意力和分组卷积技术,在保持计算效率的同时提高了模型精度和泛化能力。ResNet残差块只使用简单的卷积和残差结构,特征提取能力有限,而ResNeSt残差块对特征图进行分组卷积,并且使用拆分通道注意力,在减少计算量的同时提高特征提取能力。
残差块结构如图3所示。首先将输入通道数为c,尺寸为h×w的特征图平均划分为k个基组,每个基组又均分为r个拆分单元,一共有G = k×r个拆分单元,每个单元的通道数为c/(k×r),特征图经过拆分单元卷积通道数变为c/k,基组内经过拆分单元的特征图由拆分注意力进行合并,最后将基组输出的特征图在通道维度进行拼接,经过1×1卷积融合特征后输出。在拆分单元中嵌入3×3可变形卷积,传统卷积每个卷积核的采样位置是固定的,对于存在形变情况的目标,规则卷积可能会引入噪声,影响模型准确性,而可变形卷积通过引入可变形卷积核,更好地适应不同形状的目标,提高模型的空间不变性。可变形卷积设计如图4所示。可变形卷积在每个位置生成1个偏移量,用于控制卷积核在特征图上进行可变形变换,从而适应不同形状和尺度的目标物体。偏移量可以通过一个额外的可学习的偏移网络进行计算,图4中偏移特征通道维数为
$2N$ ,“2”分别对应X和Y 2个二维偏移,$N$ 是通道数。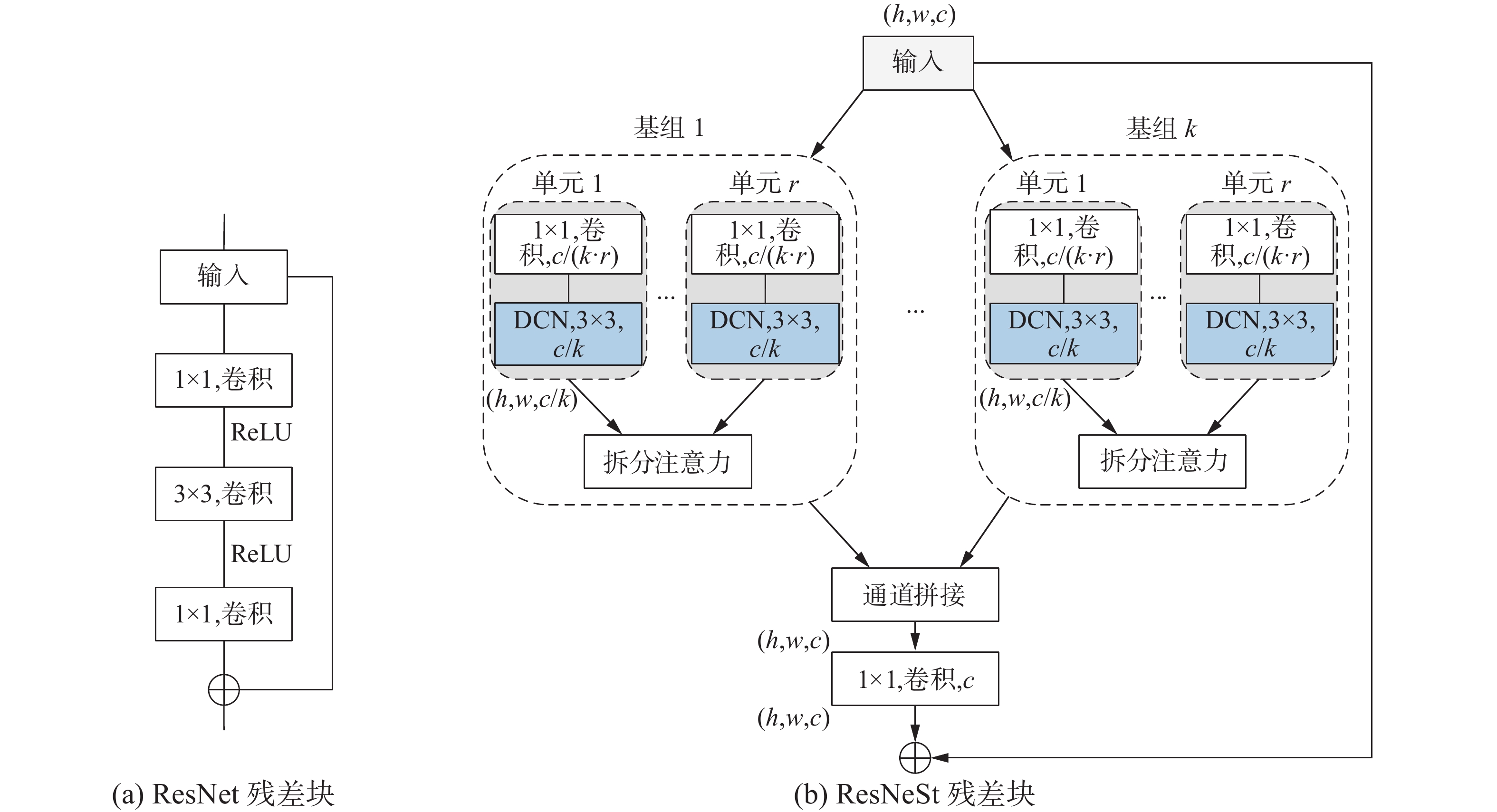 图 3 残差块对比Fig. 3 Residual block comparison下载:
全尺寸图片
图 3 残差块对比Fig. 3 Residual block comparison下载:
全尺寸图片
 图 4 可变形卷积Fig. 4 Deformable convolution下载:
全尺寸图片
图 4 可变形卷积Fig. 4 Deformable convolution下载:
全尺寸图片
常规卷积分为2步:1) 使用尺寸为
$c \times c$ 的卷积核在特征图x上采样,卷积核尺寸定义感受野大小和扩张;2) 将采样范围内的像素与卷积核参数${\boldsymbol{w}}$ 进行加权求和。则卷积后特征图y上的任意像素位置值为$$ {{\boldsymbol{y}}}\left( {{{{\boldsymbol{p}}}_0}} \right) = \sum\limits_{n = 1}^{c \times c} {{\boldsymbol{w}}\left( {{{{\boldsymbol{p}}}_n}} \right) \cdot {{\boldsymbol{x}}}\left( {{{{\boldsymbol{p}}}_0} + {{{\boldsymbol{p}}}_n}} \right)} $$ 式中
${{{\boldsymbol{p}}}_n}$ 为卷积核中的位置向量。可变形卷积在常规卷积计算公式上加了位置偏移向量
$\Delta {{{\boldsymbol{p}}}_n}$ ,其中,$\left\{ {\Delta {{{\boldsymbol{p}}}_n}\left| {n = 1,2, \cdots ,N} \right.} \right\},N = c \times c$ ,可变形卷积计算公式为$$ {{\boldsymbol{y}}}\left( {{{{\boldsymbol{p}}}_0}} \right) = \sum\limits_{n = 1}^{c \times c} {{\boldsymbol{w}}\left( {{{{\boldsymbol{p}}}_n}} \right) \cdot {{\boldsymbol{x}}}\left( {{{{\boldsymbol{p}}}_0} + {{{\boldsymbol{p}}}_n} + \Delta {{{\boldsymbol{p}}}_n}} \right)} $$ 2.2 多尺度感受野模块
在深度神经网络中,浅层特征具有更高的分辨率和丰富的细节信息,但是缺乏语义信息;深层特征具有更丰富的语义信息,但是分辨率较低。在检测任务中,通常使用特征金字塔结构来融合不同层次的特征信息,以得到既具有丰富语义信息又保留高分辨率细节的特征表示。不同层次的特征通常具有不同的通道数,为了将它们融合在一起,会使用1×1卷积将通道数进行统一,但是这种通道数的统一可能会造成信息损失。针对此问题,本文构造了多尺度感受野模块,替换原有1×1横向连接,以减少信息损失。首先使用不同膨胀率的卷积并行提取多感受野特征,进而提高特征多样性;然后使用注意力机制强化舰船目标特征,同时抑制噪声背景的干扰,减少噪声和冗余。
本文MSRF结构设计如图5所示。遥感图像中的舰船目标存在尺度变化大等特点,MSRF模块首先对Ci(i=2,3,4,5)特征并行使用膨胀率为(5,9,13)的3×3膨胀卷积提取多尺度、多感受野特征,同时将Ci特征经过自适应平均池化和1×1卷积来减少通道数,然后与多感受野特征进行通道维度上的拼接,接着使用卷积块注意力模块(convolutional block attention module, CBAM)[27]提高其性能和泛化能力,最后将通过注意力机制的特征图和Ci特征图相加,减少信息损失。
 图 5 MSRF结构Fig. 5 MSRF structure下载:
全尺寸图片
图 5 MSRF结构Fig. 5 MSRF structure下载:
全尺寸图片
CBAM结构设计如图6所示,CBAM是由通道注意力和空间注意力结合来增强特征图的表示能力,通道注意力通过学习每个通道的重要性加权和,加强了特征图的通道关联性,以提高特征的表达能力,空间注意力模块通过学习每个空间位置的重要性加权和,增强了特征图的空间位置关联性,以提高特征的局部感知能力。
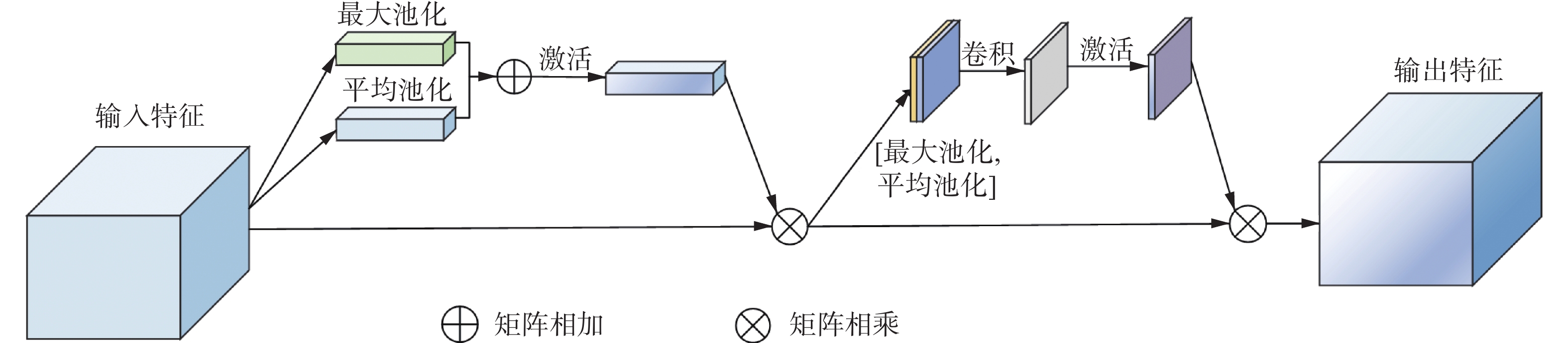 图 6 CBAM模块Fig. 6 CBAM module下载:
全尺寸图片
图 6 CBAM模块Fig. 6 CBAM module下载:
全尺寸图片
2.3 特征重用聚合网络
主干网络会生成一组分辨率不同的特征图,为了使深层特征具有位置信息,浅层特征具有足够的语义信息,FPN采用了自上而下的结构来优化网络,这样使得深层特征图的信息向低层特征进行传递,从而增强浅层特征的语义信息。然而,由于经过多次下采样,深层特征的语义信息虽然很丰富,但是可能丢失小目标的语义信息,同时主干网络中生成的特征图拥有丰富的目标特征,但是未被重复利用。本文构建特征重用聚合路径,具体来说,在原有特征金字塔路径基础上,将原始特征进行重用,构建了自底向上的聚合路径,提高特征提取能力。FRAP结构如图7所示。
 图 7 FRAP结构Fig. 7 Structure of FRAP下载:
全尺寸图片
图 7 FRAP结构Fig. 7 Structure of FRAP下载:
全尺寸图片
图像输入主干网络后得到特征图{C2,C3,C4,C5},接着,这些特征图经过MSRF模块和自顶向下路径后得到特征图{D2, D3, D4, D5}。其中,C2经过3×3卷积后,特征图尺寸减半,得到中间特征图M1,M1与D3层特征相加后经过3×3卷积生成最终特征图P3;同样将C3经过3×3卷积后与经过最大池化的M1相加,然后经过ReLU激活函数后再与D4相加,经过3×3卷积后得到最终特征图P4,以此类推,得到最终特征图P5,P5层经过最大池化得到P6层,P2层特征图直接由D2层得到。此聚合路径不仅继承了FPN的优点,同时将主干特征图进行重用,使得每层特征不仅直接融合了上一层特征信息,还直接融合了下一层特征信息,从而提高了网络的特征提取能力。
3. 实验结果与分析
3.1 数据集
DOTA数据集[28]是一个大型遥感检测数据集,收集了Google Earth和多个卫星平台的图像,数据集包含了16个类别和40万个标注的实例对象,包括了密集排列、任意方向的目标,每个图片像素在800×800~4 000×4 000。鉴于本文检测算法的特殊性,只提取了舰船1个类别进行检测,考虑到硬件的限制,输入尺寸较大时难以训练,将图片切割为800像素×800像素,重叠像素为200,最终得到3 868张训练数据,967张测试数据。部分数据集实例如图8(a)所示。
 图 8 数据集可视化Fig. 8 Dataset visualization下载:
全尺寸图片
图 8 数据集可视化Fig. 8 Dataset visualization下载:
全尺寸图片
HRSC2016数据集[29]是由中国科学院自动化研究所发布的专门用于舰船检测遥感图像数据集,该数据集涵盖了不同光照、天气条件下的舰船图像,这些图像覆盖了不同的舰船尺度、类型和舰船姿态,图像尺寸在300×300~1 500×900,分辨率介于0.4~2 m。该数据集共有1 061张标注图像,其中617张图像用于训练,444张图像用于测试,实验中将图像统一调整为800像素×512像素。部分数据集实例如图8(b)所示。
3.2 实验平台与参数设置
本次实验所使用的平台为:Dell Precision 7920工作站,Inter(R) Xeon(R) Silver
4216 处理器,128 GB内存,GeForce RTX 2080Ti显卡,软件环境为:Windows10操作系统,PyTorch 1.8.0、MMRotate 0.3.3、Python 3.8、CUDA 10.2和cuDNN 11。训练过程中使用MMRotate框架[30]中的默认参数,残差块基数组k设置为1,拆分单元r设置为2,批次大小设置为2,采用SGD优化器进行优化,动量设置为0.9,衰减权重为0.000 1,初始学习率为0.005。为了加速收敛,所有实验使用在ImageNet数据集[31]上的预训练权重。训练一共设置12个epoch,在第8个和第11个epoch时学习率乘以0.1。训练过程中,使用水平翻转、垂直翻转和对角翻转来增加数据多样性,提高模型的泛化能力和鲁棒性。从图9所示的训练损失函数曲线可以看出,本文方法具有更低的损失,说明模型可以更准确地识别出目标类别,并更准确地预测出目标框的位置。
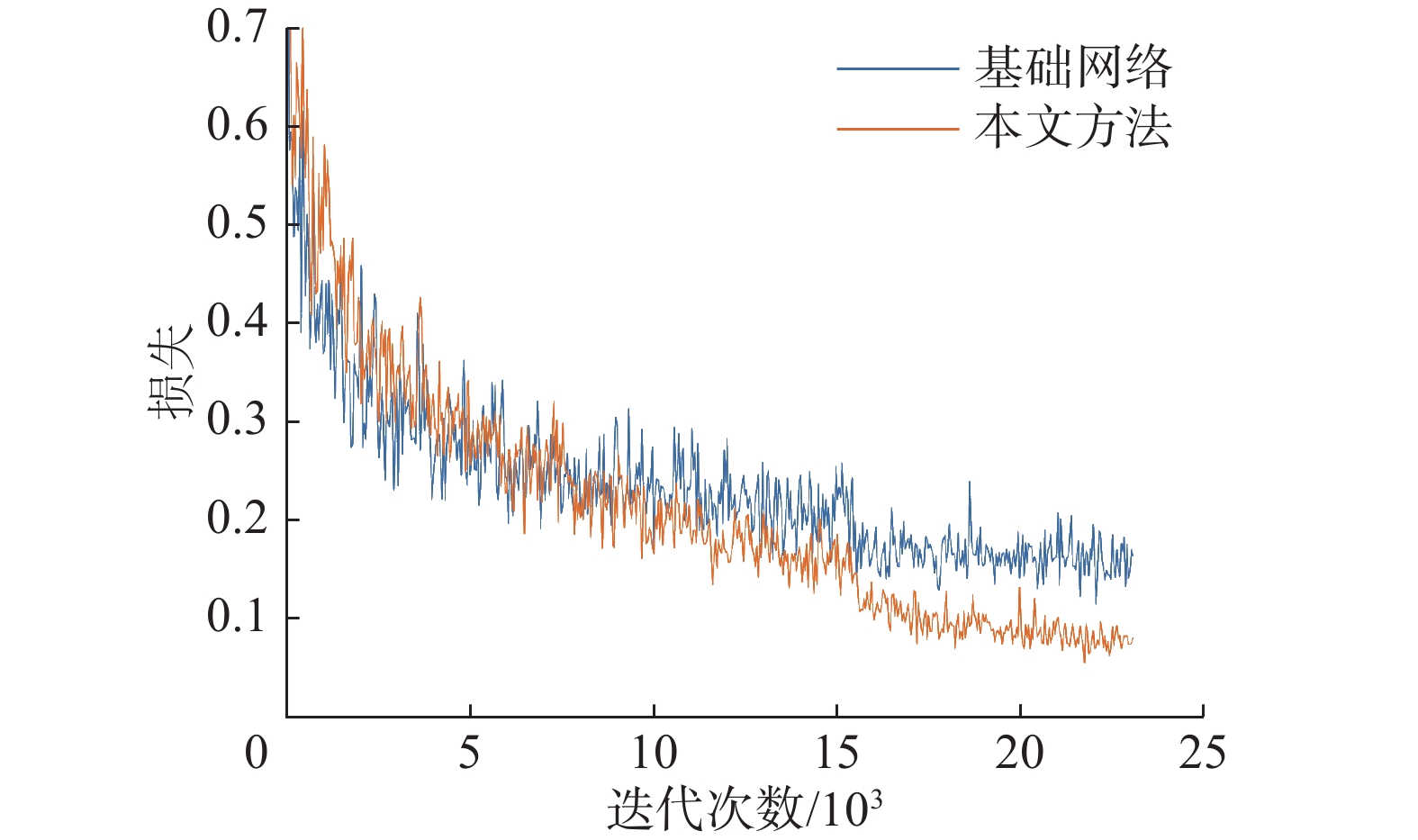 图 9 损失函数Fig. 9 Loss function下载:
全尺寸图片
图 9 损失函数Fig. 9 Loss function下载:
全尺寸图片
3.3 评价指标
平均精度(average precision, PAP)已经被用于各类目标检测的评估,其是由召回率(recall, R)和精确率(precision, P)计算得出的,召回率是指在所有真实目标中检测正确的比例,精确率是指检测出的目标中真实目标所占的比例,召回率和精确率的计算公式为
$$ P = \frac{{{N_{{\text{TP}}}}}}{{{N_{{\text{TP}}}} + {N_{{\text{FP}}}}}} $$ $$ R = \frac{{{N_{{\text{TP}}}}}}{{{N_{{\text{TP}}}} + {N_{{\text{FN}}}}}} $$ 式中:NTP表示真正例(true positive),即被正确检测出来的目标数量,NFP表示假正例(false positive),即被错误检测出来的目标数量,NFN表示假负例(false negative),即未被检测出来的目标数量。
${P^{{\text{AP}}}}$ 是由PR曲线下面的面积计算得出,计算公式为$$ {P^{{\text{AP}}}} = \int_0^1 {P\left( R \right){\text{d}}R} $$ ${P^{{\text{AP}}}}$ 通过不同的阈值细分为:$P_{50}^{{\text{AP}}}$ 、$P_{75}^{{\text{AP}}}$ 、$P_{50:95}^{{\text{AP}}}$ 。$P_{50}^{{\text{AP}}}$ 和$P_{75}^{{\text{AP}}}$ 分别表示预测框和真实框的交并比(intersection over union, IOU)阈值取0.5和0.75时的精度,$P_{50:95}^{{\text{AP}}}$ 表示IOU阈值从0.5取到0.95,步长为0.05下的精度均值。IOU阈值用来判断预测框和真实目标框的匹配程度,IOU阈值越高,预测框和真实目标框的重叠度就越高,$P_{75}^{{\text{AP}}}$ 指标需要检测方法在更高的IOU阈值下表现良好,因此对于算法的准确性和稳定性提出更高的要求,$P_{50:95}^{{\text{AP}}}$ 是在不同阈值下对检测方法进行全面的评估,从而更准确地反映方法的性能。3.4 对比实验
为了验证本文所提方法的有效性,与两阶段检测算法Rotated Faster R-CNN[32]、ReDet[10]、ROI Transformer[11]和一阶段检测算法Sasm_reppoints[17]、S2A-net[14]等主流检测算法进行比较,不同算法在DOTA数据集上的检测性能见表1。在速度损耗有限的情况下,本文方法保持较高的检测精度,
$P_{50}^{{\text{AP}}}$ 、$P_{75}^{{\text{AP}}}$ 和$P_{50:95}^{{\text{AP}}}$ 分别达到91.95%、77.94%和62.08%。表 1 不同检测方法在DOTA数据集上对比Table 1 Comparison of different detection methods on the DOTA dataset模型 输入大小 $P_{50}^{{\text{AP}}}$/% $P_{75}^{{\text{AP}}}$/% $P_{50:95}^{{\text{AP}}}$/% 检测速度/(f/s) Rotated Faster R-CNN (800,800) 87.37 45.62 46.82 18.3 ReDet (800,800) 85.14 47.08 46.69 8.0 ROI Transformer (800,800) 89.80 53.90 51.07 15.1 Sasm_reppoints (800,800) 87.42 45.01 46.62 17.2 S2A-net (800,800) 88.47 37.66 44.70 17.4 Oriented R-CNN (800,800) 89.83 54.88 51.26 16.4 本文方法 (800,800) 91.95 77.94 62.08 12.2 注:加粗字体为本列最优结果。 为了进一步验证本文所提算法的泛化性和扩展性,本文还将所提算法与其他几种算法在HRSC2016专门舰船检测数据集上进行了对比,实验结果见表2。从表2中可以看出,本文所提算法依然保持较高的检测精度,
$P_{50}^{{\text{AP}}}$ 、$P_{75}^{{\text{AP}}}$ 和$P_{50:95}^{{\text{AP}}}$ 分别达到93.13%、73.87%和61.27%。表 2 不同检测方法在HRSC2016数据集上对比Table 2 Comparison of different detection methods on the HRSC2016 dataset模型 输入大小 $P_{50}^{{\text{AP}}}$/% $P_{75}^{{\text{AP}}}$/% $P_{50:95}^{{\text{AP}}}$/% 检测速度/(f/s) Rotated Faster R-CNN (800,512) 71.00 14.20 26.94 24.3 ReDet (800,512) 79.80 60.00 50.84 9.4 ROI Transformer (800,512) 88.20 40.90 45.75 18.5 Sasm_reppoints (800,512) 92.10 70.30 59.40 27.6 S2A-net (800,512) 92.00 57.50 53.09 17.3 Oriented R-CNN (800,512) 86.90 55.30 49.55 22.7 本文方法 (800,512) 93.13 73.87 61.27 16.5 注:加粗字体为本列最优结果。 PR曲线可以更好地体现召回率和准确率的关系,曲线越接近(1,1)位置,曲线下的面积越大,说明模型检测性能越好。6种检测算法在2个数据集上IOU阈值为0.5的PR曲线如图10所示,在DOTA数据集上相比其他算法,本文算法在同一召回率下拥有较高准确率,在同一准确率下,召回率也是最高的,在HRSC2016数据集上,虽然本文算法在准确率接近1时,召回率并未达到最高,但是整体曲线下的面积最大,模型整体性能较好。
 图 10 不同模型的PR曲线Fig. 10 PR curves of different models下载:
全尺寸图片
图 10 不同模型的PR曲线Fig. 10 PR curves of different models下载:
全尺寸图片
3.5 消融实验
为了证明本文所提模块的有效性,以Oriented R-CNN为基础网络,在DOTA数据集上进行消融实验,设置了5组实验,使用
$P_{50}^{{\text{AP}}}$ 、$P_{75}^{{\text{AP}}}$ 、$P_{50:95}^{{\text{AP}}}$ 、检测速度、参数量和浮点运算次数(floating point of operations, FLOPs)作为评价指标,为公平地比较实验结果,所有参数均保持一致,消融实验结果见表3。表 3 消融实验结果Table 3 Ablation experiment results模型 输入大小 $P_{50}^{{\text{AP}}}$ /% $P_{75}^{{\text{AP}}}$ /% $P_{50:95}^{{\text{AP}}}$ /% 检测速度/(f/s) 参数量/106 FLOPs 基础网络 (800,800) 89.83 54.88 51.26 18.4 41.13 121.58 + ResNeSt50+DCN (800,800) 91.47 74.85 60.06 15.4 43.01 128.06 + MSRF (800,800) 90.99 74.12 59.59 13.8 48.10 138.06 + FRAP (800,800) 90.36 72.96 58.61 16.3 45.13 132.66 本文方法 (800,800) 91.95 77.94 62.08 12.2 53.98 155.62 注:加粗字体为本列最优结果。 基础网络使用常规卷积提取舰船特征,容易引入背景噪声,无法提取有效的、符合舰船目标的特征,同时,基础网络没有将主干特征图进行重用,导致检测结果中的精度普遍较低,因此
$P_{75}^{{\text{AP}}}$ 和$P_{50:95}^{{\text{AP}}}$ 较低,只有54.88%和51.26%。+ResNeSt50+DCN通过引入分组卷积和拆分注意力,同时使用可变形卷积提取更加符合舰船的特征,减少噪声和冗余,将$P_{50}^{{\text{AP}}}$ 、$P_{75}^{{\text{AP}}}$ 和$P_{50:95}^{{\text{AP}}}$ 分别提升至91.47%、74.85%和60.06%。MSRF模块通过并行膨胀卷积提取多尺度特征,减少信息损失,将$P_{50}^{{\text{AP}}}$ 、$P_{75}^{{\text{AP}}}$ 和$P_{50:95}^{{\text{AP}}}$ 分别提升至90.99%、74.12%和59.59%;FRAP通过构建自底向上的聚合路径将主干特征进行重用,提升了特征表达能力,将$P_{50}^{{\text{AP}}}$ 、$P_{75}^{{\text{AP}}}$ 和$P_{50:95}^{{\text{AP}}}$ 分别提升至90.36%、72.96%和58.61%,本文方法在基础网络上引入ResNeSt50和DCN,同时整合MSRF和FRAP,进一步提升了算法的检测性能,最终$P_{50}^{{\text{AP}}}$ 、$P_{75}^{{\text{AP}}}$ 和$P_{50:95}^{{\text{AP}}}$ 分别达到了91.95%、77.94%和62.08%。由于在模型中引入了额外的卷积运算,因此模型的参数量和计算复杂度有所增加,但相较于模型精度的提升,额外付出的代价是可以接受的。
为了定性分析本文所提算法的特征提取能力,对特征金字塔输出的前12个通道的特征图进行可视化,可视化特征图如图11所示,图11(a)中基础网络输出的特征图目标特征比较模糊,轮廓不清晰,图11(b)中本文算法输出的特征图相比基础网络输出的特征图目标区域更加明显,可以更准确地识别目标所在位置和边界,同时目标与背景的差异更大,可以更好地区分目标和背景,从而更准确地识别目标的类别。
 图 11 特征可视化Fig. 11 Feature visualization下载:
全尺寸图片
图 11 特征可视化Fig. 11 Feature visualization下载:
全尺寸图片
检测结果如图12所示,从检测结果可以看出,基础网络Oriented R-CNN算法在复杂背景下有误检、漏检,黄色标记框内存在漏检舰船,绿色标记框内将车辆误检为舰船,而本文算法通过使用嵌入可变形卷积的主干网络和构造多尺度感受野模块提取更有效的符合舰船目标的特征,能够有效解决误检、漏检问题,提高检测效果,图12蓝色框内排除车辆误检,并正确检测到舰船目标。
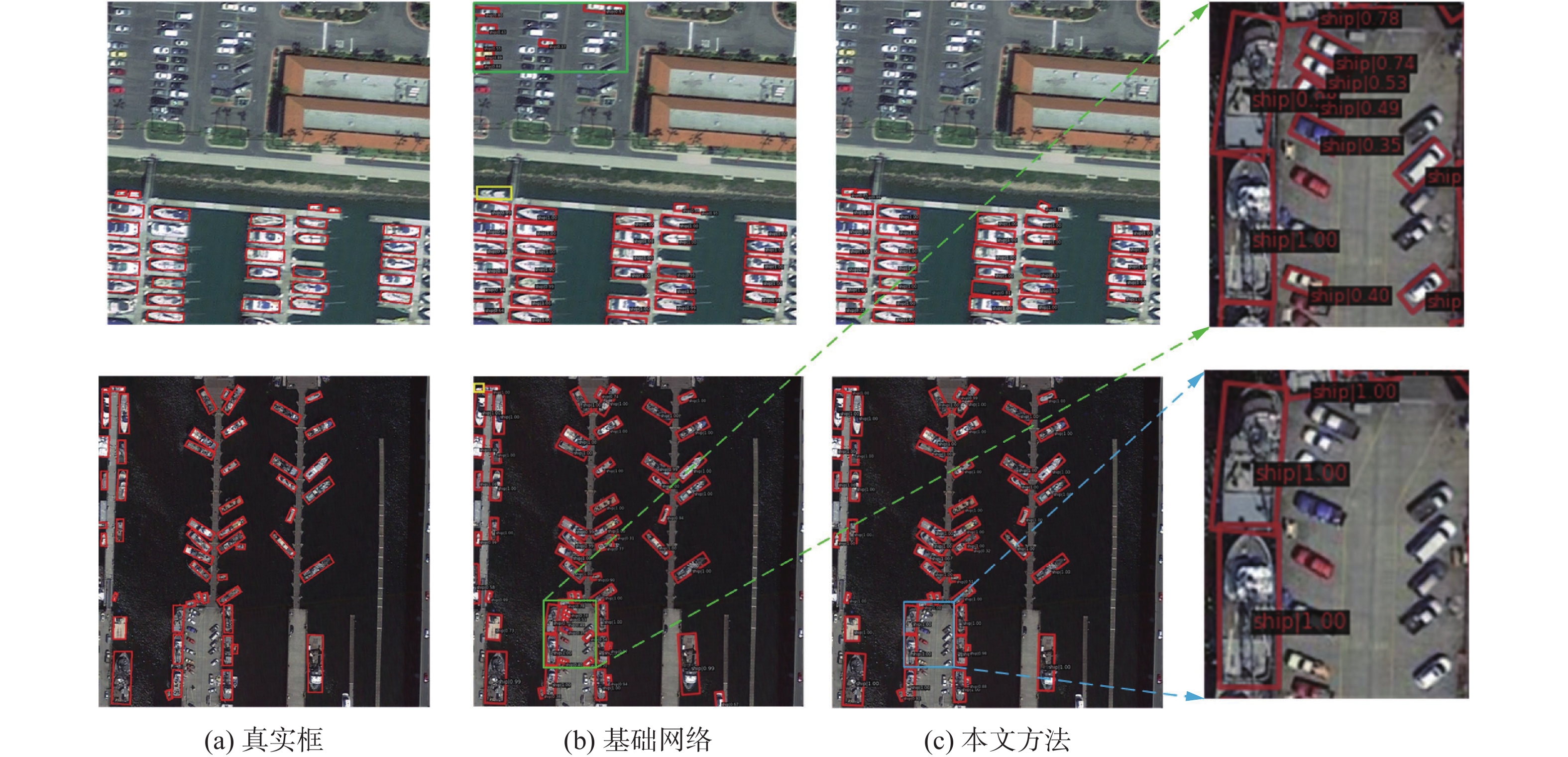 图 12 检测结果可视化Fig. 12 Visualization of detection results下载:
全尺寸图片
图 12 检测结果可视化Fig. 12 Visualization of detection results下载:
全尺寸图片
4. 结束语
针对目标检测算法中对舰船小目标错检、漏检问题,本文提出了一种基于特征重用和膨胀卷积的遥感图像舰船目标检测算法,该算法使用具有更强大特征提取能力的主干网络,并通过特征重用来提高特征提取能力,另外,还构造了多尺度感受野模块以减少特征在传递过程中因通道数骤减造成的信息损失。本文所提模块的协同合作使得目标检测精度明显提高,最后在DOTA和HRSC2016数据集上
$P_{50}^{{\text{AP}}}$ 分别达到91.95%和93.13%,虽然成功提高了模型的检测精度,但也意味着需要更多的时间和计算资源来完成任务,下一步将进一步优化模型的结构和算法,尝试在保持高精度的同时提高模型的处理速度。 -
图 1 坐标偏差可视化
Fig. 1 Coordinate deviation visualization
下载:
全尺寸图片
图 2 算法整体结构
Fig. 2 Overall structure of the algorithm
下载:
全尺寸图片
图 3 残差块对比
Fig. 3 Residual block comparison
下载:
全尺寸图片
图 4 可变形卷积
Fig. 4 Deformable convolution
下载:
全尺寸图片
图 5 MSRF结构
Fig. 5 MSRF structure
下载:
全尺寸图片
图 6 CBAM模块
Fig. 6 CBAM module
下载:
全尺寸图片
图 7 FRAP结构
Fig. 7 Structure of FRAP
下载:
全尺寸图片
图 8 数据集可视化
Fig. 8 Dataset visualization
下载:
全尺寸图片
图 9 损失函数
Fig. 9 Loss function
下载:
全尺寸图片
图 10 不同模型的PR曲线
Fig. 10 PR curves of different models
下载:
全尺寸图片
图 11 特征可视化
Fig. 11 Feature visualization
下载:
全尺寸图片
图 12 检测结果可视化
Fig. 12 Visualization of detection results
下载:
全尺寸图片
表 1 不同检测方法在DOTA数据集上对比
Table 1 Comparison of different detection methods on the DOTA dataset
模型 输入大小 $P_{50}^{{\text{AP}}}$/% $P_{75}^{{\text{AP}}}$/% $P_{50:95}^{{\text{AP}}}$/% 检测速度/(f/s) Rotated Faster R-CNN (800,800) 87.37 45.62 46.82 18.3 ReDet (800,800) 85.14 47.08 46.69 8.0 ROI Transformer (800,800) 89.80 53.90 51.07 15.1 Sasm_reppoints (800,800) 87.42 45.01 46.62 17.2 S2A-net (800,800) 88.47 37.66 44.70 17.4 Oriented R-CNN (800,800) 89.83 54.88 51.26 16.4 本文方法 (800,800) 91.95 77.94 62.08 12.2 注:加粗字体为本列最优结果。 表 2 不同检测方法在HRSC2016数据集上对比
Table 2 Comparison of different detection methods on the HRSC2016 dataset
模型 输入大小 $P_{50}^{{\text{AP}}}$/% $P_{75}^{{\text{AP}}}$/% $P_{50:95}^{{\text{AP}}}$/% 检测速度/(f/s) Rotated Faster R-CNN (800,512) 71.00 14.20 26.94 24.3 ReDet (800,512) 79.80 60.00 50.84 9.4 ROI Transformer (800,512) 88.20 40.90 45.75 18.5 Sasm_reppoints (800,512) 92.10 70.30 59.40 27.6 S2A-net (800,512) 92.00 57.50 53.09 17.3 Oriented R-CNN (800,512) 86.90 55.30 49.55 22.7 本文方法 (800,512) 93.13 73.87 61.27 16.5 注:加粗字体为本列最优结果。 表 3 消融实验结果
Table 3 Ablation experiment results
模型 输入大小 $P_{50}^{{\text{AP}}}$ /% $P_{75}^{{\text{AP}}}$ /% $P_{50:95}^{{\text{AP}}}$ /% 检测速度/(f/s) 参数量/106 FLOPs 基础网络 (800,800) 89.83 54.88 51.26 18.4 41.13 121.58 + ResNeSt50+DCN (800,800) 91.47 74.85 60.06 15.4 43.01 128.06 + MSRF (800,800) 90.99 74.12 59.59 13.8 48.10 138.06 + FRAP (800,800) 90.36 72.96 58.61 16.3 45.13 132.66 本文方法 (800,800) 91.95 77.94 62.08 12.2 53.98 155.62 注:加粗字体为本列最优结果。 -
[1] 龚声蓉, 徐少杰, 周立凡, 等. 融入混合注意力的可变形空洞卷积近岸SAR小舰船检测[J]. 中国图象图形学报, 2022, 27(12): 3663−3676. GONG Shengrong, XU Shaojie, ZHOU Lifan, et al. Deformable atrous convolution nearshore SAR small ship detection incorporating mixed attention[J]. Journal of image and graphics, 2022, 27(12): 3663−3676. [2] 黎经元, 厉小润, 赵辽英. 基于边缘线分析与聚合通道特征的港口舰船检测[J]. 光学学报, 2019, 39(8): 217−226. LI Jingyuan, LI Xiaorun, ZHAO Liaoying. Docked ship detection based on edge line analysis and aggregation channel features[J]. Acta optica sinica, 2019, 39(8): 217−226. [3] VIOLA P, JONES M. Rapid object detection using a boosted cascade of simple features[C]//Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Kauai: IEEE, 2001: 511−518. [4] 林鹏宇, 马晓珊, 彭晓东. 基于仿真模板和SuperGlue的舰船匹配检测[J]. 计算机仿真, 2023, 40(11): 11−15. doi: 10.3969/j.issn.1006-9348.2023.11.003 LIN Pengyu, MA Xiaoshan, PENG Xiaodong. Ship target match method based on simulation template and SuperGlue feature matching[J]. Computer simulation, 2023, 40(11): 11−15. doi: 10.3969/j.issn.1006-9348.2023.11.003 [5] STAUFFER C, GRIMSON W E L. Adaptive background mixture models for real-time tracking[C]//Proceedings of 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Fort Collins: IEEE, 1999: 246−252. [6] 成艳, 孟祥勇, 于雪莲, 等. 海上舰船目标轮廓检测算法[J]. 智能计算机与应用, 2022, 12(8): 119−122. doi: 10.3969/j.issn.2095-2163.2022.08.022 CHENG Yan, MENG Xiangyong, YU Xuelian, et al. Target contour detection algorithm for marine ships[J]. Intelligent computer and applications, 2022, 12(8): 119−122. doi: 10.3969/j.issn.2095-2163.2022.08.022 [7] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84−90. doi: 10.1145/3065386 [8] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137−1149. doi: 10.1109/TPAMI.2016.2577031 [9] XIE Xingxing, CHENG Gong, WANG Jiabao, et al. Oriented R-CNN for object detection[C]//2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 3500−3509. [10] HAN Jiaming, DING Jian, XUE Nan, et al. ReDet: a rotation-equivariant detector for aerial object detection[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 2785−2794. [11] DING Jian, XUE Nan, LONG Yang, et al. Learning RoI transformer for oriented object detection in aerial images[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 2844−2853. [12] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779−788. [13] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2999−3007. [14] HAN Jiaming, DING Jian, LI Jie, et al. Align deep features for oriented object detection[J]. IEEE transactions on geoscience and remote sensing, 2021, 60: 1−11. [15] 王慧赢, 王春平, 付强, 等. 面向嵌入式平台的轻量级光学遥感图像舰船检测[J]. 光学学报, 2023, 43(12): 121−134. WANG Huiying, WANG Chunping, FU Qiang, et al. Lightweight ship detection based on optical remote sensing images for embedded platform[J]. Acta optica sinica, 2023, 43(12): 121−134. [16] TIAN Zhi, SHEN Chunhua, CHEN Hao, et al. FCOS: fully convolutional one-stage object detection[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 9626−9635. [17] YANG Ze, LIU Shaohui, HU Han, et al. RepPoints: point set representation for object detection[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 9656−9665. [18] LAW H, DENG Jia. CornerNet: detecting objects as paired keypoints[C]//European Conference on Computer Vision. Cham: Springer, 2018: 765−781. [19] YANG Xue, SUN Hao, FU Kun, et al. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks[J]. Remote sensing, 2018, 10(1): 132. doi: 10.3390/rs10010132 [20] 成倩, 李佳, 杜娟. 基于YOLOv5的光学遥感图像舰船目标检测算法[J]. 系统工程与电子技术, 2023, 45(5): 1270−1276. CHENG Qian, LI Jia, DU Juan. Ship target detection algorithm of optical remote sensing image based on YOLOv5[J]. Systems engineering and electronics, 2023, 45(5): 1270−1276. [21] RAN Bohao, YOU Yanan, LI Zezhong, et al. Arbitrary-oriented ship detection method based on improved regression model for target direction detection network[C]//IGARSS 2020 - 2020 IEEE International Geoscience and Remote Sensing Symposium. Waikoloa: IEEE, 2020: 964−967. [22] 王昌安, 田金文. 生成对抗网络辅助学习的舰船目标精细识别[J]. 智能系统学报, 2020, 15(2): 296−301. doi: 10.11992/tis.201901004 WANG Chang’an, TIAN Jinwen. Fine-grained inshore ship recognition assisted by deep-learning generative adversarial networks[J]. CAAI transactions on intelligent systems, 2020, 15(2): 296−301. doi: 10.11992/tis.201901004 [23] WANG Panqu, CHEN Pengfei, YUAN Ye, et al. Understanding convolution for semantic segmentation[C]//2018 IEEE Winter Conference on Applications of Computer Vision. Lake Tahoe: IEEE, 2018: 1451−1460. [24] DAI Jifeng, QI Haozhi, XIONG Yuwen, et al. Deformable convolutional networks[C]//2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 764−773. [25] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770−778. [26] ZHANG Hang, WU Chongruo, ZHANG Zhongyue, et al. ResNeSt: split-attention networks[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New Orleans: IEEE, 2022: 2735−2745. [27] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//European Conference on Computer Vision. Cham: Springer, 2018: 3−19. [28] XIA Guisong, BAI Xiang, DING Jian, et al. DOTA: a large-scale dataset for object detection in aerial images[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 3974−3983. [29] LIU Zikun, YUAN Liu, WENG Lubin, et al. A high resolution optical satellite image dataset for ship recognition and some new baselines[C]//Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods. Porto: SCITEPRESS-Science and Technology Publications, 2017: 324−331. [30] ZHOU Yue, YANG Xue, ZHANG Gefan, et al. MMRotate: a rotated object detection benchmark using PyTorch[C]//Proceedings of the 30th ACM International Conference on Multimedia. Lisboa Portugal: ACM, 2022: 7331−7334. [31] DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 248−255. [32] YANG Sheng, PEI Ziqiang, ZHOU Feng, et al. Rotated faster R-CNN for oriented object detection in aerial images[C]//Proceedings of the 2020 3rd International Conference on Robot Systems and Applications. Chengdu: ACM, 2020: 35−39.




























































