
Aspect-level sentiment classification model combining Transformer and interactive attention network
-
摘要: 现有的大多数研究者使用循环神经网络与注意力机制相结合的方法进行方面级情感分类任务。然而,循环神经网络不能并行计算,并且模型在训练过程中会出现截断的反向传播、梯度消失和梯度爆炸等问题,传统的注意力机制可能会给句子中重要情感词分配较低的注意力权重。针对上述问题,该文提出了一种融合Transformer和交互注意力网络的方面级情感分类模型。首先利用BERT(bidirectional encoder representation from Transformers)预训练模型来构造词嵌入向量,然后使用Transformer编码器对输入的句子进行并行编码,接着使用上下文动态掩码和上下文动态权重机制来关注与特定方面词有重要语义关系的局部上下文信息。最后在5个英文数据集和4个中文评论数据集上的实验结果表明,该文所提模型在准确率和F1上均表现最优。Abstract: At present, most researchers use a combination of recurrent neural networks and attention mechanisms for aspect-level sentiment classification tasks. However, the recurrent neural network cannot be computed in parallel, and the models encounter problems, such as truncated backpropagation, gradient vanishing, and gradient exploration, in the training process. Traditional attention mechanisms may assign reduced attention weights to important sentiment words in sentences. An aspect-level sentiment classification model combining Transformer and interactive attention network is proposed to solve these problems. In this approach, the pretrained model, which considers bidirectional encoder representation from Transformers (BERT), is initially used to construct word embedding vectors. Then, Transformer encoders are used to perform parallel encoding for input sentences. Subsequently, the contextual dynamic mask-off code and the contextual dynamic weighting mechanisms are applied to focus on local context information semantically relevant to specific aspect words. Finally, the model is tested on five English datasets and four Chinese review datasets. Experimental results demonstrate that the proposed model outperforms others in terms of accuracy and F1.
-
随着互联网的快速发展,越来越多的用户在网上购物、学习、社交等,并发表和分享个人言论。当用户对某一实体发表主观意见时,往往会以不同的情感极性来评价某一实体的不同方面。方面级情感分析是一项细粒度情感分析任务,包括方面词提取和方面级情感分类[1]。本文研究的是方面级情感分类任务,旨在判断评论语句S中某一特定方面词A的情感极性(如积极、中性和消极)[2]。例如,以评论文本“lots of extra space but the keyboard is ridiculously small”为例,space和keyboard为两个方面词,对应的情感类别为积极和消极。
方面级情感分类任务的研究基于情感词典和机器学习方法开展。Deng等[3]构建了情感词汇,通过层次化监督主题模型来判断句子的情感极性。Pang等[4]使用支持向量机(support vector machines , SVM)来确定情感分类任务中的文本表示。Jiang等[5]提出一种结合特征工程来确定情感分类的统计方法。上述方法需要依赖大量的人工干预,语义理解能力较弱,很难突破性能瓶颈。
近年来,基于神经网络的方法,如循环神经网络(recurrent neural network,RNN)、长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gated recurrent unit,GRU)等深度学习技术在方面级情感分类任务中均表现出优越性。Tang等[6]设计了TD-LSTM和TC-LSTM两种经过改进的模型,使用两个LSTM分别提取前上下文和后上下文情感语义特征。Ma等[7]提出了一种扩展的LSTM模型,使用两阶段注意力机制来构建方面词与上下文之间的关联程度。Gu等[8]提出位置感知的双向门控循环单元(bi-directional gated recurrent unit, Bi-GRU)进行方面级情感分类。但是RNN对每个句子进行编码时,无法建模长序列关系,难以进行并行计算,需要花费较长的训练时间。Tang等[9]使用深度记忆网络(memory networks,MemNet)来关注上下文对特定方面词的重要程度。Xue等[10]利用卷积神经网络(convolution neural network,CNN)来解决并行计算问题。虽然CNN可以有效地减少模型的训练时间,但它无法捕获句子中的长距离依赖关系。Vaswani等[11]提出了一种基于注意力机制的Transformer模型,该模型能够对输入序列进行并行编码,在提高分类性能的同时减少了模型训练时间。
注意力机制能够对句子中每个单词分配不同的注意力权重。Chen等[12]提出了一种基于记忆机制的递归注意力(recurrent attention on memory,RAM)模型,使用GRU实现对注意力的多层抽象。Wang等[13]提出一种了ATAE-LSTM网络,使用LSTM来表示上下文和方面词的隐藏状态,然后通过注意力机制来关注句子中重要的情感词。Ma等[14]提出了一种交互注意力网络(interactive attention networks,IAN)对方面词与上下文进行建模。Song等[15]使用注意力编码器网络(attentional encoder network,AEN)来表示目标词与上下文之间的隐藏状态和语义交互。Xu等[16]使用多注意力网络进行方面级情感分类任务。肖宇晗等[17]提出了一种基于双特征嵌套注意力的方面词情感分析算法,有效地捕捉了方面词与上下文之间的语义关联。曾义夫等[18]提出了一种双记忆注意力网络,该网络首先使用GRU来表示句子的隐层状态,然后通过注意力机制从一个复杂的句子中提取出某一特定方面词的情感极性。虽然上述模型在方面级情感分类任务中取得不错效果,但是它们在捕获一个句子中方面词与上下文语义交互时忽略了语法依赖关系。例如,在评论“the cuisine from what i have gathered is without a doubt the most delicious”中,“cuisine”为方面词,模型会重点关注“without a doubt”短语,因为它与方面词“cuisine”的距离较近,而上下文“delicious”会被分配较低的注意力权重,因为它与方面词“cuisine”的距离较远,从而得到情感极性为negative,使得模型预测错误。
针对上述问题,本文提出了一种融合Transformer和交互注意力网络的方面级情感分类模型(aspect-level sentiment classification model combining Transformer and interactive attention network,TIAN)。首先使用BERT预训练模型来初始化词嵌入向量,利用Transformer编码器获取输入向量的隐藏状态;然后为了加强方面词与上下文之间的语义交互,使用依存句法树中两个单词之间的最短路径作为语法相对距离,根据语法相对距离使用上下文动态掩码(context dynamic mask, CDM)和上下文动态权重(context dynamic weighting, CDW)来关注与特定方面词有重要语义关系的局部上下文信息。本文使用的CDM和CDW机制与文献[19]不同,文献[19]简单地将两个单词之间的单词计数作为语义相对距离(syntactic relative distance,SRD),而忽略了单词之间句法关系。本文结合了依赖解析树中两个单词之间的最短距离和句子序列中单词距离作为最终的SRD,通过SRD掩码和权重衰减与方面词相关度较小的上下文,从而得到局部上下文表示。为丰富方面词信息,将局部和全局特征进行融合操作,通过多头自注意力机制和池化操作映射到全连接层和softmax分类器;最后输出方面级情感分类结果。
1. 本文模型
方面级情感分类任务定义为:给定一个长度为n的句子
$ {S=\{w}_{1},{w}_{2},\cdots ,{w}_{i},\cdots ,{w}_{i+m-1},\cdots ,{w}_{n}\} $ 和长度为m的方面词$ {A=\{w}_{i},{w}_{i+1},\cdots ,{w}_{i+m-1}\} $ ,方面级情感分类主要目的是判断方面词A在句子S中的情感极性。TIAN模型框架包括以下4个部分(图1):词嵌入层、Transformer编码层、交互注意力层和输出层。 图 1 TIAN模型结构Fig. 1 Structure of TIAN model
图 1 TIAN模型结构Fig. 1 Structure of TIAN model 下载:
全尺寸图片
下载:
全尺寸图片
1.1 词嵌入层
词嵌入是将句子中的每个单词
$ {w}_{i} $ 映射到一个低维、连续、稠密的向量。BERT不仅能克服一词多义的关键性问题,而且还能充分考虑单词上下文语境。因此,本文使用BERT预训练模型来初始化单词的向量表示。为了更好地使BERT进行训练和微调,本文将句子转换成以下形式作为模型的输入,即“[CLS]+上下文+[SEP]”“[CLS]+方面词+[SEP]”和“[CLS]+上下文+[SEP]+方面词+[SEP]”结构,其中[CLS]表示句子输入的开始,[SEP]用于分隔上下文与方面词。经过词嵌入层处理后,分别得到上下文词向量${\boldsymbol{E}}^{{\rm{s}}}= \{{\boldsymbol{e}}_{1}^{{\rm{s}}},{\boldsymbol{e}}_{2}^{{\rm{s}}},\cdots ,{\boldsymbol{e}}_{n}^{{\rm{s}}}\}{\in \mathbf{R}}^{{n\times d}_{w}}$ ,方面词向量${\boldsymbol{E}}^{{\rm{a}}}=\{{\boldsymbol{e}}_{1}^{{\rm{a}}},{\boldsymbol{e}}_{2}^{{\rm{a}}},\cdots , {\boldsymbol{e}}_{m}^{{\rm{a}}}\}\in {\mathbf{R}}^{{m\times d}_{w}}$ 和全局特征向量${\boldsymbol{E}}^{{\rm{sa}}}=\{{\boldsymbol{e}}_{1}^{{\rm{sa}}},{\boldsymbol{e}}_{2}^{{\rm{sa}}},\cdots ,{\boldsymbol{e}}_{n+m}^{{\rm{sa}}}\}\in {\mathbf{R}}^{{(n+m)\times d}_{w}}$ ,其中$ {d}_{w} $ 表示词向量的维度,n表示上下文长度,m表示方面词长度。1.2 Transformer编码层
Transformer编码器主要由两部分组成:多头注意力机制和前馈网络。每一部分之后连接残差网络和层归一化模块,图2为Transformer编码器结构[11]。
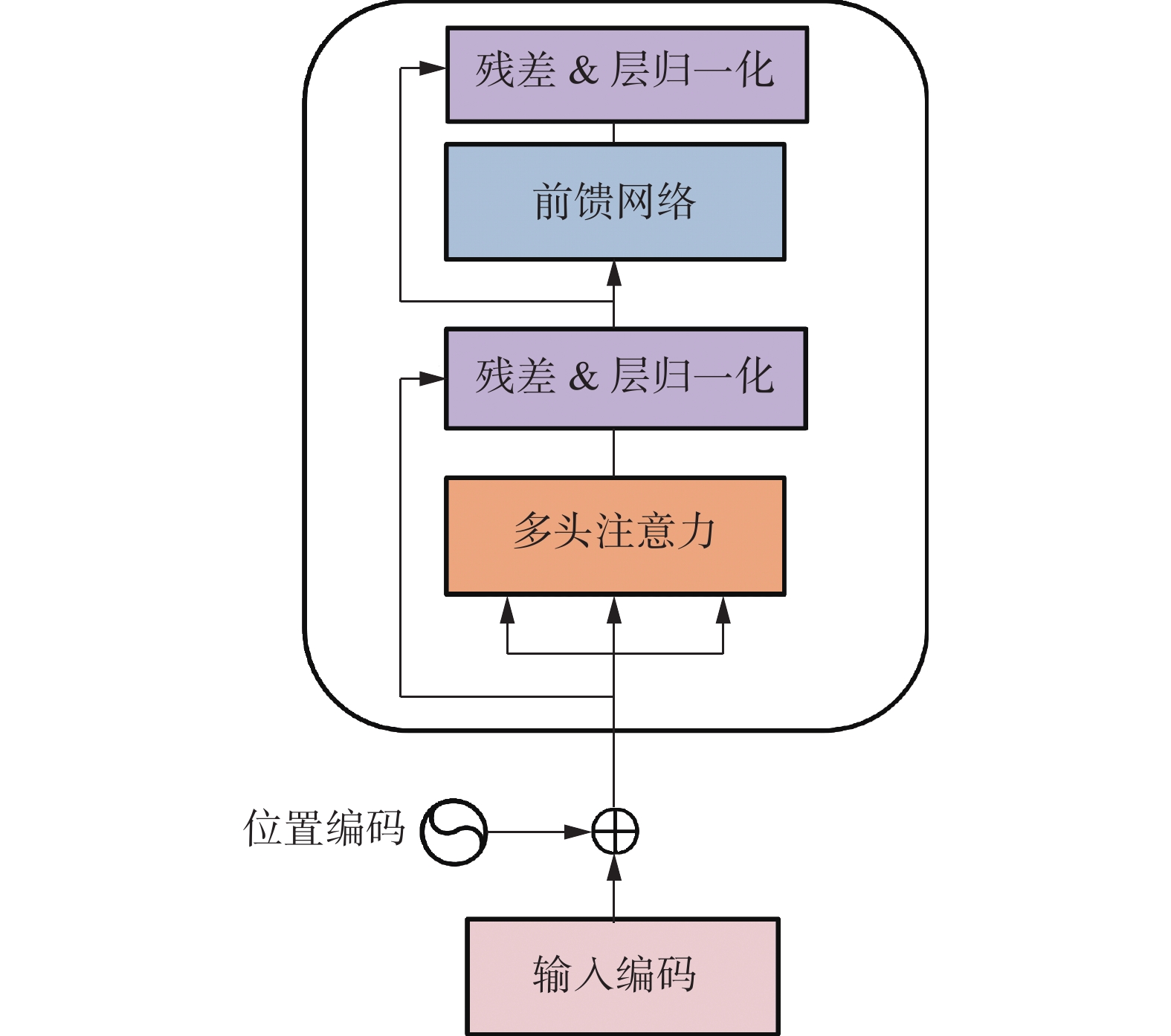 图 2 Transformer编码器结构Fig. 2 Structure of Transformer encoder下载:
全尺寸图片
图 2 Transformer编码器结构Fig. 2 Structure of Transformer encoder下载:
全尺寸图片
多头注意力机制是通过多个注意力机制进行堆叠操作来得到句子中每个单词的注意力权重。注意力机制输入是3个维度相同的矩阵
$\boldsymbol{Q}= [{\boldsymbol{q}}_{1}\;\; {\boldsymbol{q}}_{2}\;\; \cdots \;\; {\boldsymbol{q}}_{n}]$ 、$\boldsymbol{K}=[{\boldsymbol{k}}_{1}\;\;{\boldsymbol{k}}_{2}\;\; \cdots \;\;{\boldsymbol{k}}_{n}]$ 和$\boldsymbol{V}=[{\boldsymbol{v}}_{1}\;\; {\boldsymbol{v}}_{2}\;\; \cdots \;\; {\boldsymbol{v}}_{n}]$ ,其中$ {\boldsymbol{q}}_{i}\in {\boldsymbol{R}}^{{d}_{h}} $ ,$ {\boldsymbol{k}}_{i}\in {\mathbf{R}}^{{d}_{h}} $ ,$ {\boldsymbol{v}}_{i}\in {\mathbf{R}}^{{d}_{h}} $ ,$ {d}_{h} $ 表示隐藏层的维度。通过查询序列Q、键序列K和值序列V,可以得到注意力值为$$ A\left(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}\right)=\mathrm{s}\mathrm{o}\mathrm{f}\mathrm{t}\mathrm{m}\mathrm{a}\mathrm{x}\left(\frac{\boldsymbol{Q}{\boldsymbol{K}}^{\mathrm{T}}}{\sqrt{{d}_{k}}}\right)\boldsymbol{V} $$ (1) 其中
$ \sqrt{{d}_{k}} $ 表示缩放因子,主要目的是为了防止反向传播过程中梯度消失。多头注意力机制是从不同的表示子空间中获得文本的语义特征向量,然后将多个注意力头得到的结果拼接并线性变换:
$$ {h}_{i}=A\left({\boldsymbol{W}}_{i}^{Q}\boldsymbol{Q},{\boldsymbol{W}}_{i}^{K}\boldsymbol{K},{\boldsymbol{W}}_{i}^{V}\boldsymbol{V}\right) $$ (2) $$ M=C\left({h}_{1},{h}_{2},\cdots ,{h}_{h}\right){\boldsymbol{W}}^{O} $$ (3) 其中:
$ {\boldsymbol{W}}_{i}^{Q}\in {\mathbf{R}}^{{d}_{q}\times {d}_{h}} $ ,$ {\boldsymbol{W}}_{i}^{K}\in {\mathbf{R}}^{{d}_{k}\times {d}_{h}} $ ,$ {\boldsymbol{W}}_{i}^{V}\in {\mathbf{R}}^{{d}_{v}\times {d}_{h}} $ 和$ {{\boldsymbol{W}}^{O}\in \mathbf{R}}^{{d}_{o}\times {d}_{h}} $ 为权重矩阵。输入向量
$ {\boldsymbol{E}}^{\mathrm{s}} $ 、$ {\boldsymbol{E}}^{\mathrm{a}} $ 、$ {\boldsymbol{E}}^{\mathrm{s}\mathrm{a}} $ 与式(3)进行残差网络和层归一化运算,以$ {\boldsymbol{E}}^{\mathrm{s}} $ 为例,计算如下:$$ {\boldsymbol{X}}^{\mathrm{s}}=L({\boldsymbol{E}}^{\mathrm{s}}+M({\boldsymbol{E}}^{\mathrm{s}})) $$ (4) 前馈网络对多头注意力机制获得的隐层表示进行转换,假设输入序列为H,其计算为
$$ F\left(\boldsymbol{H}\right)=\mathrm{m}\mathrm{a}\mathrm{x}\left(0,\boldsymbol{H}{\boldsymbol{W}}_{1}+{\boldsymbol{b}}_{1}\right){\boldsymbol{W}}_{2}+{\boldsymbol{b}}_{2} $$ (5) 其中:
$ {\boldsymbol{W}}_{1} $ 和$ {\boldsymbol{W}}_{2} $ 表示权重矩阵,$ {\boldsymbol{b}}_{1} $ 和$ {\boldsymbol{b}}_{2} $ 表示偏置值。最后通过残差网络和层归一化计算得到$ {\boldsymbol{H}}^{\mathrm{s}} $ 、$ {\boldsymbol{H}}^{\mathrm{a}} $ 和$ {\boldsymbol{H}}^{\mathrm{s}\mathrm{a}} $ 隐层表示,以上下文隐层表示$ {\boldsymbol{H}}^{\mathrm{s}} $ 为例,计算式为$$ {\boldsymbol{H}}^{\mathrm{s}}=L({\boldsymbol{X}}^{\mathrm{s}}+F({\boldsymbol{X}}^{\mathrm{s}})) $$ (6) 1.3 交互注意力层
上下文特征向量
$ {\boldsymbol{H}}^{\mathrm{s}} $ 未考虑方面信息,为了加强方面词与上下文之间的情感语义关系,使用交互注意力网络进行学习。本文首先利用依赖解析树来计算上下文与方面词之间SRD,然后使用CDM和CDW两种机制分别掩盖和削弱与方面词无关的上下文权重。本节使用变量S来表示上下文与方面词之间SRD,使用$ {S}_{\mathrm{s}\mathrm{e}\mathrm{q}}\left( \right) $ 和$ {S}_{\mathrm{d}\mathrm{e}\mathrm{p}}\left( \right) $ 来计算SRD的序列距离和依存距离。序列距离是指一个句子中两个单词之间的实际距离,如图3所示,${S}_{\mathrm{s}\mathrm{e}\mathrm{q}}\left(\mathrm{t}\mathrm{h}\mathrm{e}\;\mathrm{ }\mathrm{s}\mathrm{e}\mathrm{r}\mathrm{v}\mathrm{i}\mathrm{c}\mathrm{e}\mathrm{ },\;\mathrm{s}\mathrm{l}\mathrm{o}\mathrm{w}\right)= 2$ 。依存距离是利用依赖解析树来计算单词对应节点之间的最短距离,当方面词是短语时,则上下文与方面词之间的SRD值等于方面词中的每个单词与上下文单词之间的平均距离,如${S}_{\mathrm{d}\mathrm{e}\mathrm{p}}\left(\mathrm{t}\mathrm{h}\mathrm{e}\mathrm{ },\;\mathrm{s}\mathrm{l}\mathrm{o}\mathrm{w}\right)=3$ ,${S}_{\mathrm{d}\mathrm{e}\mathrm{p}}\left(\mathrm{s}\mathrm{e}\mathrm{r}\mathrm{v}\mathrm{i}\mathrm{c}\mathrm{e}\mathrm{ },\;\mathrm{s}\mathrm{l}\mathrm{o}\mathrm{w}\right)=2$ ,方面词the service与上下文slow之间的依存距离为${S}_{\mathrm{d}\mathrm{e}\mathrm{p}}\left(\mathrm{t}\mathrm{h}\mathrm{e}\mathrm{s}\mathrm{e}\mathrm{r}\mathrm{v}\mathrm{i}\mathrm{c}\mathrm{e},\;\mathrm{s}\mathrm{l}\mathrm{o}\mathrm{w}\right)=2.5$ 。因此,本文提出了一种新的SRD计算方法,即将SRD的序列距离和依存距离进行综合考虑,计算公式为$S=\mathrm{m}\mathrm{i}\mathrm{n}\left({S}_{\mathrm{s}\mathrm{e}\mathrm{q}},\;{S}_{\mathrm{d}\mathrm{e}\mathrm{p}}\right)$ 。由此,方面词the service与上下文slow之间的最终SRD计算结果为$S=\mathrm{m}\mathrm{i}\mathrm{n}\left({S}_{\mathrm{s}\mathrm{e}\mathrm{q}},\;{S}_{\mathrm{d}\mathrm{e}\mathrm{p}}\right)=2$ 。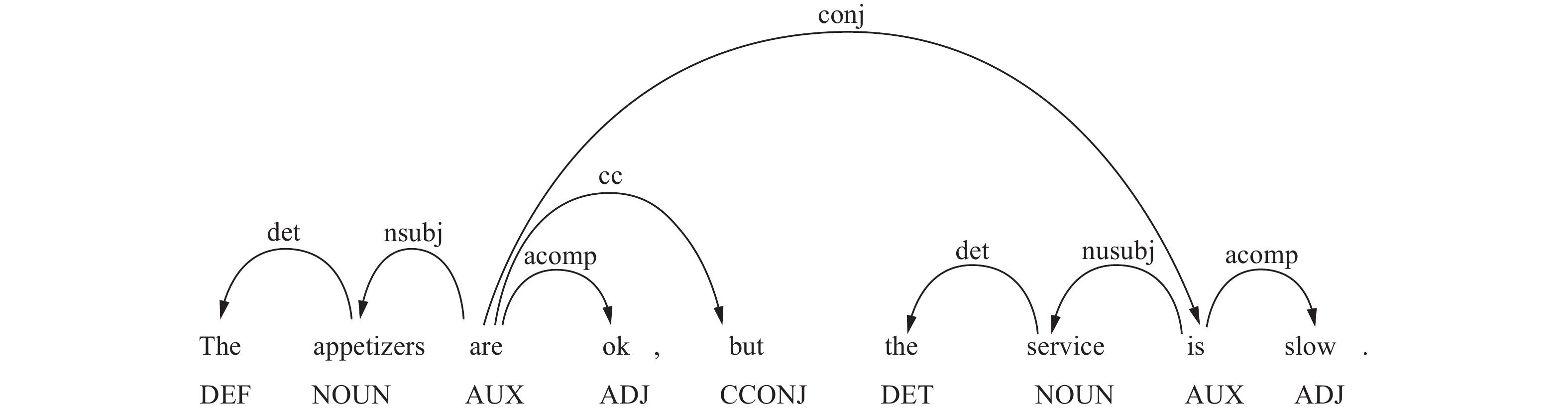 图 3 Restaurant训练数据集中一个例句的依存句法树实例Fig. 3 Example diagram of a dependency syntax tree for an example sentence in the Restaurant training dataset下载:
全尺寸图片
图 3 Restaurant训练数据集中一个例句的依存句法树实例Fig. 3 Example diagram of a dependency syntax tree for an example sentence in the Restaurant training dataset下载:
全尺寸图片
CDM表示掩盖了方面词的SRD大于预定义阈值α的低语义上下文特征。根据上一层得到的上下文隐藏状态
$ {\boldsymbol{H}}^{\mathrm{s}} $ ,基于SRD和阈值α得到掩码向量$ {\boldsymbol{V}}_{i}^{\mathrm{m}} $ 和新的上下文隐藏状态$ {\boldsymbol{H}}^{\mathrm{s}\mathrm{m}} $ :$$ {\boldsymbol{v}}_{i}^{\mathrm{m}}=\left\{\begin{array}{l}{\boldsymbol{O}}, \qquad S_{i} > \alpha \\ {\boldsymbol{E}},\qquad {S}_{i}\leqslant \alpha \end{array}\right. $$ (7) $$ \boldsymbol{M}=\mathrm{C}({\boldsymbol{v}}_{1}^{\mathrm{m}},{\boldsymbol{v}}_{2}^{\mathrm{m}},\cdots ,{\boldsymbol{v}}_{n}^{\mathrm{m}}) $$ (8) $$ {\boldsymbol{H}}^{\mathrm{s}\mathrm{m}}={\boldsymbol{H}}^{\mathrm{s}} \odot \boldsymbol{M} $$ (9) CDW表示完全保留小于等于阈值α的上下文特征,通过权重衰减来削弱大于阈值α的上下文特征:
$$ {\boldsymbol{v}}_{i}^{\mathrm{w}}=\left\{\begin{array}{l}\left(1-\dfrac{{{S}}_{i}-\alpha }{N}\right)\cdot E, \quad {{S}}_{i} > \alpha \\ E, \quad {{S}}_{i}\leqslant \alpha \end{array}\right. $$ (10) $$ \boldsymbol{W}=\mathrm{C}\mathrm{o}\mathrm{n}\mathrm{c}\mathrm{a}\mathrm{t}\mathrm{e}({\boldsymbol{v}}_{1}^{\mathrm{w}},{\boldsymbol{v}}_{2}^{\mathrm{w}},\cdots ,{\boldsymbol{v}}_{n}^{\mathrm{w}}) $$ (11) $$ {\boldsymbol{H}}^{\mathrm{s}\mathrm{w}}={\boldsymbol{H}}^{\mathrm{s}} \odot \boldsymbol{W} $$ (12) 其中:O和E分别表示0和1向量,
$ \boldsymbol{O}\in {\mathbf{R}}^{h} $ ,$ \boldsymbol{E}\in {\mathbf{R}}^{h} $ ;h表示上下文隐藏向量$ {\boldsymbol{h}}_{i}^{\mathrm{s}} $ 的维度;$ \odot $ 表示矩阵逐元素乘法运算;${\boldsymbol{H}}^{\mathrm{s}\mathrm{w}}=\{{\boldsymbol{h}}_{1}^{\mathrm{s}\mathrm{w}},{\boldsymbol{h}}_{2}^{\mathrm{s}\mathrm{w}}, \cdots ,{\boldsymbol{h}}_{n}^{\mathrm{s}\mathrm{w}}\}$ 。在得到上下文隐层表示
$ {\boldsymbol{H}}^{\mathrm{s}\mathrm{m}} $ 和$ {\boldsymbol{H}}^{\mathrm{s}\mathrm{w}} $ 后,使用注意力机制来捕获上下文与方面词之间的交互情感特征。当使用CDM机制来获取局部上下文隐层表示时,如下式所示:$$ f\left({\boldsymbol{h}}_{j}^{\mathrm{s}\mathrm{m}},{\boldsymbol{h}}_{k}^{\mathrm{a}}\right)=\mathrm{t}\mathrm{a}\mathrm{n}\mathrm{h}\left({\left({\boldsymbol{h}}_{j}^{\mathrm{s}\mathrm{m}}\right)}^{\mathrm{T}}\cdot \boldsymbol{W} \cdot {\boldsymbol{h}}_{k}^{\mathrm{a}}+\boldsymbol{b}\right) $$ (13) $$ {\boldsymbol{I}}_{kj}=\frac{\mathrm{e}\mathrm{x}\mathrm{p}\left(f\left({\boldsymbol{h}}_{j}^{\mathrm{s}\mathrm{m}},{\boldsymbol{h}}_{k}^{\mathrm{a}}\right)\right)}{\displaystyle\sum _{i=1}^{n}\mathrm{e}\mathrm{x}\mathrm{p}\left(f\left({\boldsymbol{h}}_{i}^{\mathrm{s}\mathrm{m}},{\boldsymbol{h}}_{k}^{\mathrm{a}}\right)\right)} $$ (14) $$ {\boldsymbol{h}}_{k}^{\mathrm{t}\mathrm{s}\mathrm{a}}=\sum _{j=1}^{n}{\boldsymbol{I}}_{kj}\cdot {\boldsymbol{h}}_{j}^{\mathrm{s}\mathrm{m}} $$ (15) 同理,当使用CDW机制获取局部上下文隐层表示时,如下式所示:
$$ f\left({\boldsymbol{h}}_{j}^{\mathrm{s}\mathrm{w}},{\boldsymbol{h}}_{k}^{\mathrm{a}}\right)=\mathrm{t}\mathrm{a}\mathrm{n}\mathrm{h}\left({\left({\boldsymbol{h}}_{j}^{\mathrm{s}\mathrm{w}}\right)}^{\mathrm{T}}\cdot \boldsymbol{W}\cdot {{\boldsymbol{h}}}_{k}^{\mathrm{a}}+\boldsymbol{b}\right) $$ (16) $$ {\boldsymbol{I}}_{kj}=\frac{\mathrm{e}\mathrm{x}\mathrm{p}\left(f\left({\boldsymbol{h}}_{j}^{\mathrm{s}\mathrm{w}},{\boldsymbol{h}}_{k}^{\mathrm{a}}\right)\right)}{\displaystyle\sum _{i=1}^{n}\mathrm{e}\mathrm{x}\mathrm{p}\left(f\left({\boldsymbol{h}}_{i}^{\mathrm{s}\mathrm{w}},{\boldsymbol{h}}_{k}^{\mathrm{a}}\right)\right)} $$ (17) $$ {\boldsymbol{h}}_{k}^{\mathrm{t}\mathrm{s}\mathrm{a}}=\sum _{j=1}^{n}{\boldsymbol{I}}_{kj}\cdot {\boldsymbol{h}}_{j}^{\mathrm{s}\mathrm{w}} $$ (18) 其中:
$ {\boldsymbol{I}}_{kj}\in {\mathbf{R}}^{m\times n} $ 是由方面词隐藏状态$ {\boldsymbol{h}}_{k}^{\mathrm{a}} $ 与第j个上下文隐藏状态$ {\boldsymbol{h}}_{j}^{\mathrm{s}\mathrm{m}} $ 计算而得到的注意力权重得分,$ {\boldsymbol{h}}_{k}^{\mathrm{t}\mathrm{s}\mathrm{a}}\in {\mathbf{R}}^{m\times {d}_{h}} $ 是隐藏表示的加权和,$ \mathrm{t}\mathrm{a}\mathrm{n}\mathrm{h}\left(\mathrm{ }\right) $ 是一个非线性激活函数,$ \boldsymbol{W}\in {\mathbf{R}}^{{d}_{h}\times {d}_{h}} $ 和$ \boldsymbol{b}\in {\mathbf{R}}^{{d}_{h}} $ 分别表示权重矩阵和偏置。1.4 输出层
通过平均池化得到新的隐藏表示,然后再融合局部特征和全局特征。当使用CDM机制时,其计算方法为
$$ {\boldsymbol{H}}_{\mathrm{a}\mathrm{v}\mathrm{g}}^{\mathrm{s}\mathrm{m}}=\frac{1}{n}\sum _{j=1}^{n}{\boldsymbol{h}}_{j}^{\mathrm{s}\mathrm{m}} $$ (19) $$ {\boldsymbol{H}}_{\mathrm{a}\mathrm{v}\mathrm{g}}^{\mathrm{t}\mathrm{s}\mathrm{a}}=\frac{1}{m}\sum _{i=1}^{m}{\boldsymbol{h}}_{i}^{\mathrm{t}\mathrm{s}\mathrm{a}} $$ (20) $$ {\boldsymbol{H}}_{\mathrm{a}\mathrm{v}\mathrm{g}}^{\mathrm{a}}=\frac{1}{m}\sum _{k=1}^{m}{\boldsymbol{h}}_{k}^{\mathrm{a}} $$ (21) $$ {\boldsymbol{H}}_{\mathrm{a}\mathrm{v}\mathrm{g}}^{\mathrm{s}\mathrm{a}}=\frac{1}{n+m}\sum _{p=1}^{n+m}{\boldsymbol{h}}_{p}^{\mathrm{s}\mathrm{a}} $$ (22) $$ {\boldsymbol{O}}^{\mathrm{s}\mathrm{a}}={\boldsymbol{W}}^{\mathrm{s}\mathrm{a}}\cdot \left[{\boldsymbol{H}}_{\mathrm{a}\mathrm{v}\mathrm{g}}^{\mathrm{s}\mathrm{m}}\quad {\boldsymbol{H}}_{\mathrm{a}\mathrm{v}\mathrm{g}}^{\mathrm{t}\mathrm{s}\mathrm{a}}\quad {\boldsymbol{H}}_{\mathrm{a}\mathrm{v}\mathrm{g}}^{\mathrm{a}}\quad {\boldsymbol{H}}_{\mathrm{a}\mathrm{v}\mathrm{g}}^{\mathrm{s}\mathrm{a}}\right]+{\boldsymbol{b}}^{\mathrm{s}\mathrm{a}} $$ (23) 同理,当使用CDW机制时,只需将式(19)中
$ {\boldsymbol{H}}_{\mathrm{a}\mathrm{v}\mathrm{g}}^{\mathrm{s}\mathrm{m}} $ 和$ {\boldsymbol{h}}_{j}^{\mathrm{s}\mathrm{m}} $ 分别变换为$ {\boldsymbol{H}}_{\mathrm{a}\mathrm{v}\mathrm{g}}^{\mathrm{s}\mathrm{w}} $ 和$ {\boldsymbol{h}}_{j}^{\mathrm{s}\mathrm{w}} $ ,其他公式保持不变。其中,$ {\boldsymbol{W}}^{\mathrm{s}\mathrm{a}}\in {\mathbf{R}}^{{d}_{h}\times 4{d}_{h}} $ 和$ {\boldsymbol{b}}^{\mathrm{s}\mathrm{a}}\in {\mathbf{R}}^{{d}_{h}} $ 分别表示权重矩阵和偏置值。通过多头自注意力机制得到融合后的特征:$$ \boldsymbol{O}=\mathrm{M}({\boldsymbol{O}}^{\mathrm{s}\mathrm{a}},{\boldsymbol{O}}^{\mathrm{s}\mathrm{a}},{\boldsymbol{O}}^{\mathrm{s}\mathrm{a}}) $$ (24) 然后,对O进行池化操作:
$$ \boldsymbol{x}=\mathrm{P}\mathrm{O}\mathrm{O}\mathrm{L}\left(\boldsymbol{O}\right) $$ (25) 将x通过全连接层映射到维度为C的向量空间中:
$$ {\boldsymbol{x}}'=\boldsymbol{W}\cdot \boldsymbol{x}+\boldsymbol{b} $$ (26) 其中
$ \boldsymbol{W}\in {\mathbf{R}}^{C\times {d}_{h}} $ 、$ \boldsymbol{b}\in {\mathbf{R}}^{C} $ 分别表示权值矩阵和偏置值。通过softmax归一化计算,最后得到方面级情感极性概率$ \boldsymbol{y}\in {\mathbf{R}}^{C} $ :$$ \boldsymbol{y}=\mathrm{s}\mathrm{o}\mathrm{f}\mathrm{t}\mathrm{m}\mathrm{a}\mathrm{x}\left({\boldsymbol{x}}'\right)=\frac{\mathrm{e}\mathrm{x}\mathrm{p}\left({\boldsymbol{x}}'\right)}{\displaystyle\sum _{i=1}^{C}\mathrm{e}\mathrm{x}\mathrm{p}\left({\boldsymbol{x}}'\right)} $$ (27) 其中C表示情感类别数。
1.5 损失函数
本文所提出的模型在有监督的数据上以端到端的学习方式进行训练,训练的目的是优化所有参数,从而尽可能最小化损失函数。损失函数由交叉熵损失函数和
$ {L}_{2} $ 正则化项两部分组成:$$ L\left(\theta \right)=-\sum _{i=1}^{C}{\boldsymbol{y}}_{i}\mathrm{l}\mathrm{o}\mathrm{g}\left(\widehat{{\boldsymbol{y}}_{i}}\right)+\lambda \sum _{\theta \in \varTheta }{\theta }^{2} $$ (28) 其中:
$ \widehat{{\boldsymbol{y}}_{i}} $ 表示某个方面词模型预测得到的情感极性;$ {\boldsymbol{y}}_{i}\in {\mathbf{R}}^{C} $ 是某个方面词真实的情感极性,它用one-hot向量来进行表示;Θ 表示模型参数集合,λ表示$ {L}_{2} $ 正则化系数。2. 实验及结果分析
2.1 实验数据集和参数设置
为了验证模型的有效性,本文首先在5个主流的英文数据集上进行实验,即SemEval 2014的任务4(restaurant和laptop)、SemEval 2015的任务12 (restaurant)、SemEval 2016的任务5 (restaurant)和Twitter数据集。数据集中每一条评论文本包括句子、方面词和情感极性,情感类别为积极、中性和消极。SemEval 2014的任务4中Laptop和Restaurant包括积极、中性、消极和冲突4个情感极性,由于冲突类别的评论语句较少,因此本文借鉴了前人的数据预处理的方法,删除了冲突类别的评论文本,5个英文数据集的详细信息如表1所示。
表 1 英文数据集信息Table 1 Information of English datasets数据集 积极 中性 消极 总计 训练集 测试集 训练集 测试集 训练集 测试集 训练集 测试集 Restaurant2014 2 164 728 637 196 807 196 3 608 1 120 Laptop2014 994 341 464 169 870 128 2 330 638 Restaurant2015 1 178 439 50 35 382 328 1 610 802 Restaurant2016 1 620 597 88 38 709 190 2 417 825 Twitter 1 561 173 3 127 346 1 560 173 6 248 692 为了评估TIAN模型对中文信息的处理能力,本文在4个中文评论数据集上也进行了实验,分别为Phone、Car、Notebook和Camera数据集。中文评论数据集由Peng等[20]在文献[21]的基础上处理得到,评论文本的情感极性为二分类,分别是积极和消极。数据集中存在个别评论语句方面词缺失和情感极性标记缺失等问题,通过处理后,得到表2所示的4个中文评论数据集信息。
表 2 中文评论数据集信息Table 2 Information of Chinese review datasets数据集 积极 消极 总计 训练集 测试集 训练集 测试集 训练集 测试集 Phone 1 319 341 668 156 1 987 497 Car 708 164 213 66 921 230 Notebook 328 88 168 35 496 123 Camera 1 197 322 546 113 1 743 435 在实验过程中,基于BERT模型使用
$ {\mathrm{B}\mathrm{E}\mathrm{R}\mathrm{T}}_{\mathrm{b}\mathrm{a}\mathrm{s}\mathrm{e}} $ 预训练模型来初始化单词的嵌入向量,在基于非BERT的基线模型中,英文数据集使用GloVe来获得词嵌入,中文数据集使用中文预训练字向量(Chinese word vectors)[22]来得到词嵌入。基于BERT模型词嵌入的维度设置为768,学习率为2×10−5;GloVe预训练词向量的维度设置为300,学习率为0.001。所有权重矩阵使用均匀分布$ U\left(-\varepsilon ,\varepsilon \right) $ 进行随机初始化,其中ε大小设置为0.01,所有偏置设置为0,英文和中文数据集的句子最大长度分别设置为85和50,模型训练过程中使用Adam优化器来优化所有参数,batch_size为16,使用dropout(dropout=0.1)和$ {L}_{2} $ (1×10−5)正则化项来防止模型过拟合。本文使用准确率(Accuracy,Acc)和F1指标来评估模型的分类性能。2.2 对比模型
为了评估TIAN性能,选取了方面级情感分类任务中近几年具有代表性的模型进行了实验对比。本文对比的基线模型分为两组:基于非BERT模型和基于BERT模型。本文对比模型如下:
基于非BERT的基线模型:
1)ATAE-LSTM[13]:在输入层中充分考虑了方面嵌入,并使用注意力机制的LSTM来得到情感分类结果。
2)IAN[14]:使用注意力机制学习上下文与方面词之间的语义交互。
3)MemNet[9]:使用记忆网络将上下文作为外部记忆,并利用多层注意力机制得到特定方面词对上下文的注意力权重。
4)RAM[12]:采用双向LSTM和循环注意力机制来获得文本特征,同时构建了一种位置加权记忆模块来捕获远距离情感信息。
5)MGAN[23]:基于IAN和AOA两种模型,在损失函数上增加了一种方面对齐损失,有效地提高了具有相同上下文中各方面词之间的相互影响。
6)TNet-LF[24]:由CNN、LSTM和CPT模块组成,CPT模块包含特定方面词表示和上下文保存机制。
7)MAN[16]:该模型通过全局和局部注意力机制来捕获上下文和方面词之间的语义交互。
基于BERT的基线模型:
1)BERT-SPC[15]:将序列“[CLS]+上下文+[SEP]+方面词+[SEP]”输入到BERT预训练模型中,用于句子对分类任务。
2)AEN-BERT[15]:使用注意力编码网络来建模上下文和方面词之间的语义交互,利用标签平滑正则化项来解决数据集中标签不可靠性问题。
3)LCF[19]:该模型使用句子序列中单词距离作为语义相对距离,通过语义相对距离来丢弃局部上下文中与方面词无关的情感词。
4)MGMD[25]:该模型是一种基于BERT的多源数据融合的网络,从多个资源库中学习情感词倾向,同时还设计了一种特殊的架构集成来自多层次情感词典的数据。
5)RMN-BERT[26]:该模型使用图卷积神经网络来生成方面表示,并利用双注意力机制捕获方面词与上下文之间的语义关系。
6)TIAN_M/TIAN_W:本文提出的融合Transformer和交互注意力网络的方面级情感分类模型,TIAN_M和TIAN_W分别表示TIAN使用CDM和CDW机制。
2.3 实验结果与分析
本文提出的TIAN模型在5个英文基准数据集上与上述13个基线模型进行实验对比,实验结果如表3所示。表3标有*的基线模型表示直接引用了原论文中的实验结果,“—”表示原论文在该数据集上未取得实验结果。表3中其他基线模型的实验结果,均根据原论文作者发布的代码进行了实验复现,表中加粗的字体表示最好的实验结果。
表 3 各模型在英文数据集上的实验结果Table 3 Experimental results of different models on English datasets模型 Restaurant2014 Laptop2014 Restaurant2015 Restaurant2016 Twitter Acc F1 Acc F1 Acc F1 Acc F1 Acc F1 Non BERT ATAE-LSTM* 77.20 — 68.70 — — — — — — — IAN* 78.60 — 72.10 — — — — — — — MemNet* 80.95 — 72.71 — — — — — — — RAM 80.61 69.79 73.86 70.93 80.78 68.89 84.37 70.50 69.39 67.35 MGAN 81.23 71.90 75.39 72.47 80.78 68.94 85.28 72.53 72.56 70.78 TNet-LF 80.75 70.80 76.21 71.49 81.47 68.79 85.03 71.49 74.55 73.31 MAN* 84.38 71.31 78.13 73.20 82.65 69.10 85.87 73.28 76.56 72.19 BERT BERT-SPC 84.36 76.91 78.56 75.23 83.29 68.98 86.47 74.58 73.55 72.14 AEN-BERT 83.46 74.20 79.82 76.27 83.80 69.19 88.63 76.75 74.68 73.11 LCF-CDM 85.71 78.82 79.96 76.15 84.34 71.08 90.01 77.86 75.66 74.21 LCF-CDW 85.94 79.28 80.23 76.34 84.91 69.23 90.66 78.29 76.73 74.72 MGMD* 86.16 78.83 79.18 74.86 — — — — — — RMN-BERT* 84.56 79.05 77.95 70.83 82.94 66.95 89.38 71.88 — — TIAN_M 86.81 80.71 80.57 76.83 85.79 72.57 91.40 78.46 75.72 74.38 TIAN_W 87.23 81.93 80.92 77.21 86.15 72.13 92.21 79.39 76.68 74.75 由表3可知,TIAN_M和TIAN_W在5个英文数据集上取得最优结果。TIAN_W比TIAN_M优越,原因是 CDW把与方面词较远上下文隐藏表示的权重只是被降低了,而CDM则是把与方面词较远的上下文的权重被完全掩盖为0。在基于RNN的模型中,ATAE-LSTM、IAN、MemNet、RAM都使用了注意力机制,在各个数据集上的实验结果都有所提升,表明RNN与注意力机制结合,对于优化模型性能具有重要意义。MGAN和MAN取得较优的分类效果,验证了交互注意力机制的有效性。BERT-SPC和AEN-BERT在5个英文数据集上均优于使用非BERT的基线模型,表明使用BERT预训练模型能够更好地对方面词与上下文进行向量表示。TIAN_M和TIAN_W在除Twitter数据集上的准确率外,在其他数据集上均优于LCF-CDM和LCF-CDW,表明了语义相对距离对掩码和衰减与方面词相关度较小的上下文具有重要的影响。RMN-BERT对上下文进行位置编码时简单的将两个单词之间的单词计数作为语义相对距离,相比RMN-BERT,本文提出的方法在4个英文数据集上的准确率提升约3%,表明了通过依赖解析树中两个单词之间的最短路径作为语法相对距离能更好地捕获与方面词相关的上下文特征,验证了本文模型的有效性。
为了验证TIAN对中文信息的处理能力,本文在4个中文评论数据集上进行实验,实验结果如表4所示。从表4可以看出,TIAN性能最优。TIAN_M和TIAN_W在大多数中文数据集上的实验效果基本持平,主要原因是中文数据集上的评论文本长度较短,并且这些评论语句大多数都较为简单,此时当CDM和CDW通过SRD阈值α来掩盖和削弱与方面词无关的上下文权重时,句子中的大多数上下文与方面词之间的距离都在SRD阈值α范围内,无论使用CDW还是CDM,上下文被分配较低和完全掩盖为0的隐藏表示权重的情况较少,大部分上下文隐藏表示的权重都是为1的向量。TIAN通过交互注意力机制不仅能捕获方面与上下文之间的语义关系,而且还能着重关注方面词信息,使用CDM和CDW机制能够根据句法相对距离来减少远离目标方面词的不相关上下文的负面影响。
表 4 各模型在中文数据集上的实验结果Table 4 Experimental results of different models on Chinese datasets% 模型 Phone Car Notebook Camera Acc F1 Acc F1 Acc F1 Acc F1 Non BERT ATAE-LSTM 86.44 82.63 81.40 71.50 83.36 82.15 85.29 81.83 IAN 89.74 88.14 85.96 81.58 84.52 79.08 88.75 85.87 MemNet 89.89 88.39 84.91 79.54 86.45 82.72 84.95 81.24 RAM 90.51 88.83 86.67 81.27 86.57 83.22 89.10 86.85 MGAN 91.35 89.90 85.61 81.37 87.10 83.91 89.62 87.13 TNet-LF 91.88 90.69 87.37 82.79 87.24 83.97 90.83 88.53 BERT BERT-SPC 96.02 95.34 96.49 95.44 94.84 93.82 95.67 94.87 AEN-BERT 96.78 96.29 96.14 95.13 92.90 91.44 95.42 94.56 TIAN_M 96.97 96.45 98.60 98.22 94.84 93.89 96.54 95.83 TIAN_W 97.12 96.64 98.25 97.78 95.48 94.56 96.89 96.29 2.4 模型训练时间分析
为了更好地比较本文所提模型与基于RNN模型的训练时间,TIAN这里使用Glove预训练模型来初始化单词嵌入向量。同时,本文在相同的GPU和深度学习框架等环境下分析不同模型在Laptop2014数据集上完成一次迭代的训练时间,实验结果如表5所示。
表 5 不同模型在Laptop2014数据集上一次迭代的训练时间Table 5 Training time for different models to complete one epoch on the Laptop2014 datasets 模型 训练时间 ATAE-LSTM 284.35 RAM 257.64 MGAN 273.59 TNet-LF 361.08 MemNet 53.82 MAN 46.71 TIAN_M 44.52 TIAN_W 43.64 由表5可知,TIAN_M和TIAN_W模型的训练时间最短。相反,基于LSTM的基线模型,模型训练时间较长。这主要是因为Transformer编码器中的注意力机制的时间复杂度为
$ O\left({l}_{m}^{2}{d}_{w}\right) $ ,而LSTM的时间复杂度为$ O\left({l}_{m}{d}_{w}^{2}\right) $ ,$ {l}_{m} $ 表示输入序列的最大长度,$ {d}_{w} $ 表示词向量的维度[27],通常情况下,$ {l}_{m} $ 比$ {d}_{w} $ 更小。本文在实验过程中,$ {l}_{m} $ 设置为85,$ {d}_{w} $ 设置为300。Transformer模型在训练文本时是并行处理的,而RNN模型对当前的输入需要建立在上一时刻的输出上,模型训练时非常缓慢,其循环结构增加了模型的训练难度。2.5 消融实验
为了验证TIAN模型中各个模块的合理性,本节在5个英文数据集上进行消融实验,实验结果如表6所示,“w/o”表示“未使用”。TIAN(M)和TIAN(F)分别表示Transformer编码层中仅使用多头注意力机制和仅使用前馈神经网络。TIAN(L)表示使用双向LSTM来代替Transformer模型。
表 6 消融实验结果Table 6 Ablation experiment results% 模型 Restaurant2014 Laptop2014 Restaurant2015 Restaurant2016 Twitter Acc F1 Acc F1 Acc F1 Acc F1 Acc F1 TIAN(M)_M 85.46 78.13 78.83 74.47 84.21 68.35 88.39 75.06 74.09 72.67 TIAN(M)_W 85.65 78.74 78.98 74.82 84.76 68.54 88.42 75.41 76.73 74.67 TIAN(F)_M 85.62 78.80 77.75 74.55 84.37 67.37 87.92 74.39 73.81 72.94 TIAN(F)_W 86.30 78.92 78.19 74.71 84.50 68.46 89.20 76.23 73.95 73.12 TIAN(L)_M 86.91 79.68 79.47 75.84 83.95 68.15 88.57 75.56 73.37 72.53 TIAN(L)_W 87.34 79.89 79.94 76.23 85.02 72.04 88.96 76.18 73.51 72.61 TIAN w/o Local 83.67 76.75 77.81 74.04 82.49 68.20 87.62 74.21 72.94 71.93 TIAN_M w/o Global 84.85 77.23 78.22 74.20 82.81 68.27 87.02 73.98 73.25 72.22 TIAN_W w/o Global 84.98 77.42 78.35 74.48 83.02 68.60 87.07 74.06 73.32 72.29 TIAN w/o MW 85.11 77.59 78.56 74.80 83.21 68.83 88.04 74.86 74.68 73.31 TIAN_M 86.81 80.71 80.57 76.83 85.79 72.57 91.40 78.46 75.72 74.38 TIAN_W 87.23 81.93 80.92 77.21 86.15 72.13 92.21 79.39 76.68 74.75 由表6可知,除了在某些特殊情况外,TIAN_M和TIAN_W在5个英文数据集上均取得了最好的分类效果。TIAN w/o MW实验结果略差,表明CDM和CDW机制对TIAN模型的贡献程度较大,这也验证了本文使用CDM和CDW机制的有效性。TIAN w/o Local在5个数据集上的准确率下降3.11%~4.59%,表明局部上下文特征能够有效地提高模型识别方面的情感修饰词的能力。TIAN_M w/o Global和TIAN_W w/o Global在5个数据集上的准确率分别下降1.96%~4.38%和2.25%~5.14%,表明TIAN只关注局部上下文特征会丢失句子中的重要信息,全局上下文特征对方面情感预测也是不可或缺的。TIAN(M)_W在Twitter数据集上取得不错的分类效果,这可能是因为Twitter数据集中的评论语句表达方式更适合TIAN(M)_W学习文本的语义特征。虽然TIAN(L)_W在Restaurant2014数据集上的准确率达到最佳,但是TIAN(L)_W不能进行并行计算,模型需要花费较长的训练时间。
3. 结束语
针对方面级情感分类任务中存在模型训练时间较长、未有效地建立方面词与上下文交互信息的问题,本文提出了一种融合Transformer和交互注意力网络的方面级情感分类模型(TIAN)。该模型使用BERT预训练模型来初始化词嵌入,这种词嵌入方法比常用的Word2vec和Glove等方法效果更好。TIAN使用Transformer编码器来表示文本的隐藏状态,在提高性能的同时,模型的训练时间明显减少,然后使用CDM和CDW机制来关注与特定方面词有重要语义关系的局部上下文信息。为了验证所提模型的有效性,在5个英文数据集和4个中文评论数据集上进行了广泛实验,TIAN的实验结果优于目前主流的方面级情感分类模型。今后将考虑对Transformer编码器内部结构进行改进,如在编码器中嵌入RNN、CNN、动态路由等多种结构。此外,我们也会考虑使用更大文本语料库的RoBERTa和XLNet等预训练模型来初始化方面词和上下文的嵌入向量,通过上下文与方面词之间的交互,学习到更广泛和更深入的语言知识,提供更丰富的文本表示能力,提高模型性能。
-
图 1 TIAN模型结构
Fig. 1 Structure of TIAN model
下载:
全尺寸图片
图 2 Transformer编码器结构
Fig. 2 Structure of Transformer encoder
下载:
全尺寸图片
图 3 Restaurant训练数据集中一个例句的依存句法树实例
Fig. 3 Example diagram of a dependency syntax tree for an example sentence in the Restaurant training dataset
下载:
全尺寸图片
表 1 英文数据集信息
Table 1 Information of English datasets
数据集 积极 中性 消极 总计 训练集 测试集 训练集 测试集 训练集 测试集 训练集 测试集 Restaurant2014 2 164 728 637 196 807 196 3 608 1 120 Laptop2014 994 341 464 169 870 128 2 330 638 Restaurant2015 1 178 439 50 35 382 328 1 610 802 Restaurant2016 1 620 597 88 38 709 190 2 417 825 Twitter 1 561 173 3 127 346 1 560 173 6 248 692 表 2 中文评论数据集信息
Table 2 Information of Chinese review datasets
数据集 积极 消极 总计 训练集 测试集 训练集 测试集 训练集 测试集 Phone 1 319 341 668 156 1 987 497 Car 708 164 213 66 921 230 Notebook 328 88 168 35 496 123 Camera 1 197 322 546 113 1 743 435 表 3 各模型在英文数据集上的实验结果
Table 3 Experimental results of different models on English datasets
模型 Restaurant2014 Laptop2014 Restaurant2015 Restaurant2016 Twitter Acc F1 Acc F1 Acc F1 Acc F1 Acc F1 Non BERT ATAE-LSTM* 77.20 — 68.70 — — — — — — — IAN* 78.60 — 72.10 — — — — — — — MemNet* 80.95 — 72.71 — — — — — — — RAM 80.61 69.79 73.86 70.93 80.78 68.89 84.37 70.50 69.39 67.35 MGAN 81.23 71.90 75.39 72.47 80.78 68.94 85.28 72.53 72.56 70.78 TNet-LF 80.75 70.80 76.21 71.49 81.47 68.79 85.03 71.49 74.55 73.31 MAN* 84.38 71.31 78.13 73.20 82.65 69.10 85.87 73.28 76.56 72.19 BERT BERT-SPC 84.36 76.91 78.56 75.23 83.29 68.98 86.47 74.58 73.55 72.14 AEN-BERT 83.46 74.20 79.82 76.27 83.80 69.19 88.63 76.75 74.68 73.11 LCF-CDM 85.71 78.82 79.96 76.15 84.34 71.08 90.01 77.86 75.66 74.21 LCF-CDW 85.94 79.28 80.23 76.34 84.91 69.23 90.66 78.29 76.73 74.72 MGMD* 86.16 78.83 79.18 74.86 — — — — — — RMN-BERT* 84.56 79.05 77.95 70.83 82.94 66.95 89.38 71.88 — — TIAN_M 86.81 80.71 80.57 76.83 85.79 72.57 91.40 78.46 75.72 74.38 TIAN_W 87.23 81.93 80.92 77.21 86.15 72.13 92.21 79.39 76.68 74.75 表 4 各模型在中文数据集上的实验结果
Table 4 Experimental results of different models on Chinese datasets
% 模型 Phone Car Notebook Camera Acc F1 Acc F1 Acc F1 Acc F1 Non BERT ATAE-LSTM 86.44 82.63 81.40 71.50 83.36 82.15 85.29 81.83 IAN 89.74 88.14 85.96 81.58 84.52 79.08 88.75 85.87 MemNet 89.89 88.39 84.91 79.54 86.45 82.72 84.95 81.24 RAM 90.51 88.83 86.67 81.27 86.57 83.22 89.10 86.85 MGAN 91.35 89.90 85.61 81.37 87.10 83.91 89.62 87.13 TNet-LF 91.88 90.69 87.37 82.79 87.24 83.97 90.83 88.53 BERT BERT-SPC 96.02 95.34 96.49 95.44 94.84 93.82 95.67 94.87 AEN-BERT 96.78 96.29 96.14 95.13 92.90 91.44 95.42 94.56 TIAN_M 96.97 96.45 98.60 98.22 94.84 93.89 96.54 95.83 TIAN_W 97.12 96.64 98.25 97.78 95.48 94.56 96.89 96.29 表 5 不同模型在Laptop2014数据集上一次迭代的训练时间
Table 5 Training time for different models to complete one epoch on the Laptop2014 dataset
s 模型 训练时间 ATAE-LSTM 284.35 RAM 257.64 MGAN 273.59 TNet-LF 361.08 MemNet 53.82 MAN 46.71 TIAN_M 44.52 TIAN_W 43.64 表 6 消融实验结果
Table 6 Ablation experiment results
% 模型 Restaurant2014 Laptop2014 Restaurant2015 Restaurant2016 Twitter Acc F1 Acc F1 Acc F1 Acc F1 Acc F1 TIAN(M)_M 85.46 78.13 78.83 74.47 84.21 68.35 88.39 75.06 74.09 72.67 TIAN(M)_W 85.65 78.74 78.98 74.82 84.76 68.54 88.42 75.41 76.73 74.67 TIAN(F)_M 85.62 78.80 77.75 74.55 84.37 67.37 87.92 74.39 73.81 72.94 TIAN(F)_W 86.30 78.92 78.19 74.71 84.50 68.46 89.20 76.23 73.95 73.12 TIAN(L)_M 86.91 79.68 79.47 75.84 83.95 68.15 88.57 75.56 73.37 72.53 TIAN(L)_W 87.34 79.89 79.94 76.23 85.02 72.04 88.96 76.18 73.51 72.61 TIAN w/o Local 83.67 76.75 77.81 74.04 82.49 68.20 87.62 74.21 72.94 71.93 TIAN_M w/o Global 84.85 77.23 78.22 74.20 82.81 68.27 87.02 73.98 73.25 72.22 TIAN_W w/o Global 84.98 77.42 78.35 74.48 83.02 68.60 87.07 74.06 73.32 72.29 TIAN w/o MW 85.11 77.59 78.56 74.80 83.21 68.83 88.04 74.86 74.68 73.31 TIAN_M 86.81 80.71 80.57 76.83 85.79 72.57 91.40 78.46 75.72 74.38 TIAN_W 87.23 81.93 80.92 77.21 86.15 72.13 92.21 79.39 76.68 74.75 -
[1] PONTIKI M, GALANIS D, PAVLOPOULOS J, et al. SemEval-2014 task 4: aspect based sentiment analysis[C]//Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014). Dublin: Association for Computational Linguistics, 2014: 27–35. [2] LIU Bing. Sentiment analysis and opinion mining[J]. Synthesis lectures on human language technologies, 2012, 5(1): 1–167. doi: 10.1007/978-3-031-02145-9 [3] DENG Dong, JING Liping, YU Jian, et al. Sentiment lexicon construction with hierarchical supervision topic model[J]. IEEE/ACM transactions on audio, speech, and language processing, 2019, 27(4): 704–718. doi: 10.1109/TASLP.2019.2892232 [4] PANG Bo, LEE L, VAITHYANATHAN S. Thumbs up? : sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing - EMNLP '02. Morristown: Association for Computational Linguistics, 2002: 79–86. [5] JIANG Long, YU Mo, ZHOU Ming, et al. Target-dependent Twitter sentiment classification[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies - Volume 1. Portland: ACM, 2011: 151–160. [6] TANG D, QIN B, FENG X, et al. Effective LSTMs for Target-Dependent Sentiment Classification[C]//Proceedings of the 26th International Conference on Computational Linguistics. Stroudsburg: ACL, 2016: 3298–3307. [7] MA Yukun, PENG Haiyun, KHAN T, et al. Sentic LSTM: a hybrid network for targeted aspect-based sentiment analysis[J]. Cognitive computation, 2018, 10(4): 639–650. doi: 10.1007/s12559-018-9549-x [8] GU S, ZHANG L, HOU Y, et al. A position-aware bidirectional attention network for aspect-level sentiment analysis[C]//Proceedings of the 27th International Conference on Computational Linguistics. Stroudsburg: ACL, 2018: 774–784. [9] TANG Duyu, QIN Bing, LIU Ting. Aspect level sentiment classification with deep memory network[C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2016: 214–224. [10] XUE Wei, LI Tao. Aspect based sentiment analysis with gated convolutional networks[EB/OL]. (2018−05−18)[2023−03−08]. http://arxiv.org/abs/1805.07043. [11] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach: ACM, 2017: 6000–6010. [12] CHEN Peng, SUN Zhongqian, BING Lidong, et al. Recurrent attention network on memory for aspect sentiment analysis[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2017: 452–461. [13] WANG Yequan, HUANG Minlie, ZHU Xiaoyan, et al. Attention-based LSTM for aspect-level sentiment classification[C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2016: 606–615. [14] MA Dehong, LI Sujian, ZHANG Xiaodong, et al. Interactive attention networks for aspect-level sentiment classification[C]//Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne: ACM, 2017: 4068–4074. [15] SONG Youwei, WANG Jiahai, JIANG Tao, et al. Attentional encoder network for targeted sentiment classification[EB/OL]. (2019–02–09)[2023–03–08]. http://arxiv.org/abs/1902.09314. [16] XU Qiannan, ZHU Li, DAI Tao, et al. Aspect-based sentiment classification with multi-attention network[J]. Neurocomputing, 2020, 388(C): 135–143. [17] 肖宇晗, 林慧苹, 汪权彬, 等. 基于双特征嵌套注意力的方面词情感分析算法[J]. 智能系统学报, 2021, 16(1): 142–151. doi: 10.11992/tis.202012024 XIAO Yuhan, LIN Huiping, WANG Quanbin, et al. An algorithm for aspect-based sentiment analysis based on dual features attention-over-attention[J]. CAAI transactions on intelligent systems, 2021, 16(1): 142–151. doi: 10.11992/tis.202012024 [18] 曾义夫, 蓝天, 吴祖峰, 等. 基于双记忆注意力的方面级别情感分类模型[J]. 计算机学报, 2019, 42(8): 1845–1857. doi: 10.11897/SP.J.1016.2019.01845 ZENG Yifu, LAN Tian, WU Zufeng, et al. Bi-memory based attention model for aspect level sentiment classification[J]. Chinese journal of computers, 2019, 42(8): 1845–1857. doi: 10.11897/SP.J.1016.2019.01845 [19] ZENG Biqing, YANG Heng, XU Ruyang, et al. LCF: a local context focus mechanism for aspect-based sentiment classification[J]. Applied sciences, 2019, 9(16): 3389. doi: 10.3390/app9163389 [20] PENG Haiyun, MA Yukun, LI Yang, et al. Learning multi-grained aspect target sequence for Chinese sentiment analysis[J]. Knowledge based systems, 2018, 148: 167–176. doi: 10.1016/j.knosys.2018.02.034 [21] ZHAO Yanyan, QIN Bing, LIU Ting. Creating a fine-grained corpus for Chinese sentiment analysis[J]. IEEE intelligent systems, 2015, 30(1): 36–43. doi: 10.1109/MIS.2014.33 [22] LI Shen, ZHAO Zhe, HU Renfen, et al. Analogical reasoning on Chinese morphological and semantic relations[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg: Association for Computational Linguistics, 2018: 138–143. [23] FAN Feifan, FENG Yansong, ZHAO Dongyan. Multi-grained attention network for aspect-level sentiment classification[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2018: 3433–3442. [24] LI Xin, BING Lidong, LAM W, et al. Transformation networks for target-oriented sentiment classification[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: Association for Computational Linguistics, 2018: 946–956. [25] CHEN F, YUAN Z, HUANG Y. Multi-source data fusion for aspect-level sentiment classification[J]. Knowledge-based systems, 2020, 187: 104831. doi: 10.1016/j.knosys.2019.07.002 [26] ZENG Jiandian, LIU Tianyi, JIA Weijia, et al. Relation construction for aspect-level sentiment classification[J]. Information sciences, 2022, 586: 209–223. doi: 10.1016/j.ins.2021.11.081 [27] VASWANI A, BENGIO S, BREVDO E, et al. Tensor2Tensor for neural machine translation[C]//Proceedings of the 13th Conference of the Association for Machine Translation in the Americas (Volume 1: Research Track). Boston: Association for Machine Translation in the Americas, 2018: 193–199.













































































































