
Detection of transformer oil leakage based on deep separable atrous convolution pyramid
-
摘要: 为了降低影响并提高对变压器渗漏油巡检图像的检测效率,提出一种基于深度可分离空洞卷积金字塔的变压器渗漏油检测模型。首先,将空洞金字塔中普通卷积块修改为深度可分离卷积块,以此扩大金字塔感受野,使特征提取网络提取到的特征图语义信息更加丰富;然后,改进了特征提取阶段低阶语义特征与高阶语义特征融合过程,进一步增强特征提取网络产生特征图的语义信息;最后,为了避免经过多次卷积、池化操作后特征图语义信息的损失,在融合过程中引入空间注意力机制和通道注意力机制,进一步增强特征图中的语义信息。与UNet(convolutional networks for biomedical image segmentation)、PSPNet(pyramid scene parseing network)、DeepLabv3+(encoder-decoder with atrous separable convolution for semantic image segmentation)和MCNN(multi-class convolutional neural network)等算法进行对比实验发现,本文所提出网络检测模型效果好,查准率达到了76.85%,平均交并比达到了64.63%,召回率达到了73.56%,检测速率达到了30 f/s。为了验证本文提出方法的有效性,设计了消融实验,与基础网络模型相比,查准率提高了9.33%,平均交并比提高了7.15%,召回率提高了5.66%。Abstract: To improve the detection efficiency of the transformer oil leakage patrol inspection image, a deep separable atrous convolution pyramid-based transformer oil leakage detection model is suggested. First, the ordinary convolution block in the atrous pyramid is modified into a deep separable convolution block for expansion of the pyramid receptive field and further enrichment of the semantic information of the feature graph extracted by the feature extraction network. Afterward, the fusion of low-order and high-order semantic features in the feature extraction stage is improved for further enhancement of the semantic information of the feature graph generated by the feature extraction network. Finally, to avoid semantic information loss in the feature graph after several convolution and pooling operations, spatial attention and channel attention mechanisms are introduced into the fusion process to further enhance the semantic information in the feature graph. It is found by comparing with algorithms such as traditional UNet (Convolutional Networks for Biomedical Image Segmentation), PSPNet (Pyramid Scene Parsing Network), DeepLabv3 + (Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation), and MCNN (Multiclass Convolutional Neural Network) via tests that the proposed network detection model is effective, with 76.85% precision, 64.63% average cross-merger ratio, 73.56% recall rate, and 30 frames per second. To confirm the effectiveness of the proposed method, an ablation experiment is designed. Compared with the basic network model, the precision, average intersection ratio, and recall rate are increased by 9.33%, 7.15%, and 5.66%, respectively.
-
变压器渗漏油是造成变压器故障的最主要原因,严重时会发生击穿事故[1],导致大面积停电甚至电网崩溃事故的发生[2],常规的变压器巡检主要采取人工巡检通过目测法判断变压器是否渗漏油,这种巡检方式效率较低。而无人机巡检、高清摄像头巡检和地面智能巡检机器人巡检正在成为变压器智能巡检的常态化巡检方式。所以,目前变压器巡检的主要痛点是大幅增长的复杂背景下的巡检图像缺陷检测需求与检测精度、效率的相对低下之间的矛盾。基于深度学习神经网络的发展对目标缺陷检测起到了巨大推进作用[3-4]。随着深度学习发展的同时数据匮乏这个问题显得尤为突出[5],因此如何在少量数据样本中训练出高精度网络也非常值得思考。电力视觉技术的提出在电力系统、计算机视觉、深度学习三者之间建立了联系[6]。近年来具有良好图像分类效果的网络通常是由卷积神经网络(convolutional neural network,CNN)构成,因为CNN往往具有很强的特征提取能力,在物体检测、分割中有很好的表现。现在的目标检测网络主要分为两大类,一类是单阶段检测网络,如Redmon等[7]提出的单次检测算法YOLO(you only look once)、YOLOv2[8]、YOLOv3[9],Bochkovskiy等[10]提出的YOLOv4、YOLOv7[11],Liu等[12]提出的单阶段多框检测算法(single shot multibox detector,SSD)。另一类是双阶段检测网络,如Girshick等[13]提出的基于候选区域的卷积神经网络(region-based convolutional neural network, R-CNN)和Ren等[14]提出的Faster R-CNN。其中单阶段检测网络的精度低于双阶段检测网络,但单阶段检测网络在检测速度方面却明显高于双阶段检测网络。Li等[15]利用荧光标记法进行渗漏油图像识别,通过构造饱和度和强度间的线性关系实现变压器渗漏油的检测。文献[16]提出了一种基于RGB图像与热图像特征相融合的管道渗漏油检测网络。Li等[17]为了能够在日光下利用荧光标记法实现变压器渗漏油的检测,增加了可见光组件来获得变压器表面强烈的镜面反射,借此补充日光下荧光标记法的不足。鲍伟超等[18]利用循环训练的方法实现变压器地面渗漏油的检测,通过引入带有阴影的变压器图像提升模型对阴影的特征提取能力,该方法有效提高了地面渗漏油的检测精度。Ghorbani等[19]通过迁移学习,利用VGG16检测图像中是否存在渗漏油,随后,使用语义分割网络进行像素级溢油检测。Wang等[20]通过捕获温度与油位之间的关系,提出了一种基于惩罚卷积的渗漏油检测模型,以此捕获温度和油位之间的关系,然后,得到除温度影响外静态油位计和油量之间的真实关系,以此判断是否存在渗漏油情况。Chen等[21]先利用VGG进行溢油分类,然后利用多类分割网络完成渗漏油检测。Li等[22]提出了一种两阶段的变电设备缺陷检测模型,第一阶段利用分割算法提取目标设备,第二阶段通过缺陷识别方法来识别红外图像中的变电设备存在的缺陷。文献[15]与文献[17]实验数据停留在实验室阶段,对观测条件和设备要求较高,无法应用到复杂背景下的变压器日常巡检任务中。文献[18]提出算法对于地面渗漏油检测精度较高,与背景复杂多变的巡检图像相比,地面渗漏油图像背景较为单一。综上所述,以上算法均不适用于本文所提出复杂背景下的变压器渗漏油检测。无人机巡检、高清摄像头巡检和地面智能巡检机器人巡检等巡检方式可以全方位、无死角的覆盖到设备的各个层面,有利于快速且准确地判断变压器缺陷情况。因此,利用光学检测图像处理、计算机视觉和深度学习技术等研究变压器巡检图像中变压器渗漏油的视觉检测方法是非常紧迫和必要的,可提高其检测的精度和效率,及时发现早期渗漏油,使变压器的运行维护更为高效和智能。
针对变压器渗漏油形状的不规则性,渗漏油所处背景的复杂性,本文选用DeepLabv3+[23]作为复杂背景下变压器渗漏油检测的基本模型,Xception[24]作为特征提取网络。在此基础之上,提出一种基于深度可分离空洞卷积金字塔结构的变压器渗漏油检测模型。首先,将预处理后的变压器图像输入到特征提取网络,为增强特征图语义信息的同时控制计算开销,在特征提取网络中提出了深度可分离空洞卷积金字塔结构。其次,为减少进行采样时产生信息丢失,改进了低阶特征与高阶特征融合过程。最后,在特征融合过程中引入多注意力机制,进一步增强特征图中的语义信息。
1. 基本原理
DeepLabv3+采用编码器解码器结构,如图1所示。编码器中采用Xception作为特征提取网络。然后在特征提取网络尾端引入空洞卷积金字塔模块,增强特征图语义信息。相比DeepLabv3[25],DeepLabv3+在解码器中将低阶特征与高阶特征进一步融合,提升语义分割边界的准确性。
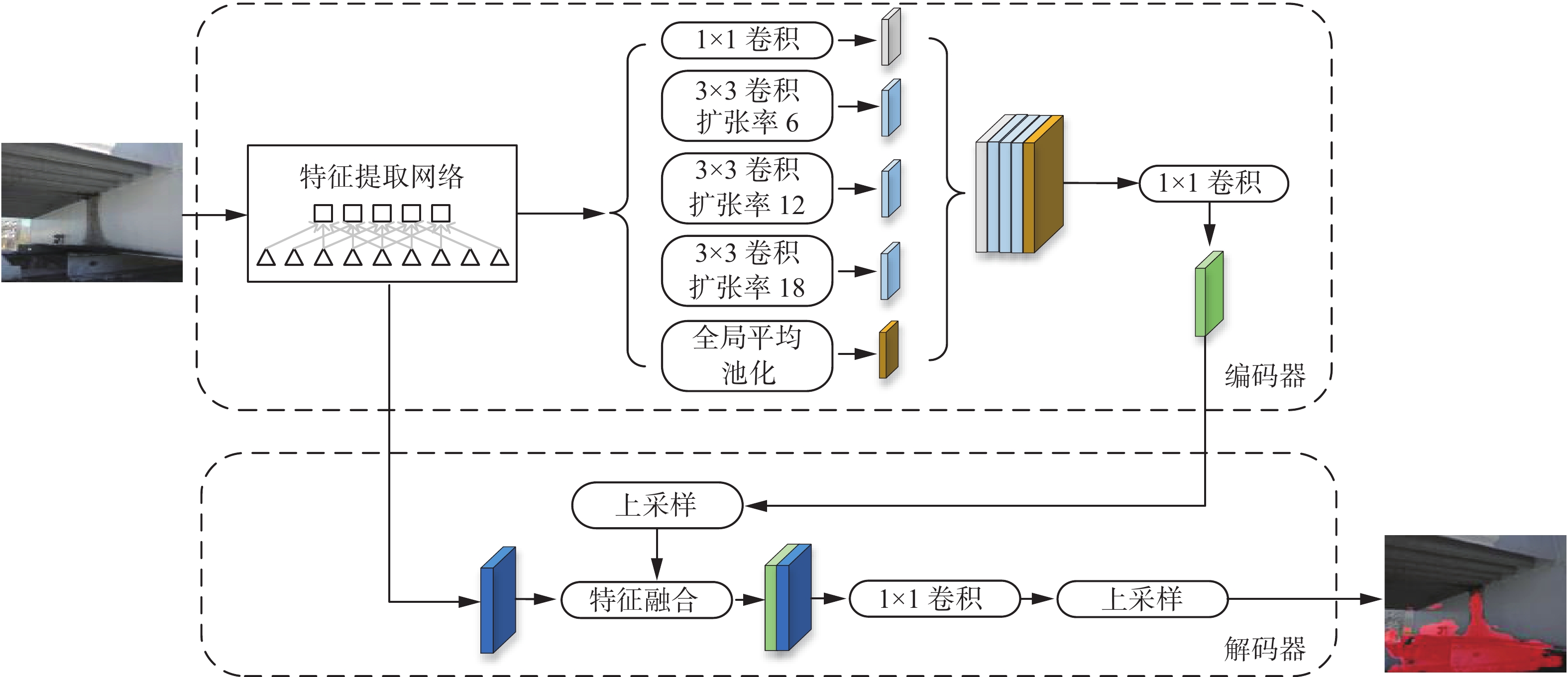 图 1 DeepLabv3+网络结构Fig. 1 DeepLabv3+ network structure
图 1 DeepLabv3+网络结构Fig. 1 DeepLabv3+ network structure 下载:
全尺寸图片
下载:
全尺寸图片
1.1 Xception特征提取网络
Xception主要由普通卷积层和深度可分离卷积层组成。深度可分离卷积层采用前向特征传播,上一层的输出用作本层的输入,在每2层深度可分离卷积层后引入残差边,提高网络的特征提取能力。同时在每一个深度可分离卷积层后添加最大池化层来减少计算量。
1.2 空洞卷积金字塔
空洞卷积金字塔由1个1×1卷积层、3个不同倍率的空洞卷积层(膨胀系数分别为6、12、18)、一个池化层组成,将提取到的特征输入空洞卷积金字塔后得到5个具有不同感受野的特征图,最后,将得到的特征图进行拼接,并通过卷积调整通道数大小。
2. 基于深度可分离空洞卷积金字塔的变压器渗漏油检测模型
图2为本文提出的基于深度可分离空洞卷积金字塔的变压器渗漏油检测模型(depth-separable atrous convolution pyramid,DSACP)。该模型主要包括图像预处理模块、深度可分离空洞卷积金字塔模块、特征融合模块、多注意力模块等。图像预处理模块会对变压器渗漏油图像进行不失真调整,将原图像调整至512像素×512像素。深度可分离空洞卷积金字塔模块起到特征提取作用,相较于普通卷积,该模块在卷积核大小相同情况下,感受野更大且计算开销更低。特征融合模块将低阶语义信息特征图与高阶语义信息特征图融合,进一步丰富特征图语义信息,在融合过程中引入多注意力机制,可以使模型对变压器渗漏油图像中渗漏油部分有更好的特征提取能力。在此基础之上,完成变压器渗漏油检测。
 图 2 基于深度可分离空洞卷积金字塔的变压器渗漏油检测模型Fig. 2 Transformer leakage oil detection model based on depth-separable atrous convolution pyramid下载:
全尺寸图片
图 2 基于深度可分离空洞卷积金字塔的变压器渗漏油检测模型Fig. 2 Transformer leakage oil detection model based on depth-separable atrous convolution pyramid下载:
全尺寸图片
2.1 图像预处理
首先,对变压器渗漏油图像进行预处理,将图像长宽限制为512像素×512像素。然后将预处理后的变压器图片输入到特征提取网络。
2.2 变压器渗漏油图像特征提取网络
特征提取网络完成变压器渗漏油图像特征提取。该主干网络由多层深度可分离卷积块构成,块内前向传播实现变压器特征信息重用,增强特征图的语义信息。同时块间添加残差边来丰富特征图的语义信息,在特征提取网络后部引入深度可分离空洞卷积金字塔结构。
图3为深度可分离空洞卷积金字塔结构。深度可分离空洞卷积金字塔由深度空洞卷积(Depthwise Atrous Convolution)和点卷积(Pointwise Convolution)两部分构成。Depthwise Atrous Convolution的计算方式十分简单,空洞卷积可以在卷积核不变的情况下扩大感受野,它对输入特征图的每一个通道进行空洞卷积,其中rate代表空洞倍率,最后将卷积结果进行拼接,然后通过1×1卷积得到最终特征图。Pointwise Convolution实际上为1×1卷积,它主要有两个作用。第1个作用是能够调整期望输出通道数,第2个作用是对Depthwise Atrous Convolution输出的特征图进行通道融合。
 图 3 深度可分离空洞卷积金字塔结构Fig. 3 Depthwise-separable dilated convolutional pyramid structure下载:
全尺寸图片
图 3 深度可分离空洞卷积金字塔结构Fig. 3 Depthwise-separable dilated convolutional pyramid structure下载:
全尺寸图片
下面对深度可分离空洞卷积金字塔和普通卷积的计算量进行分析,假设输入特征图尺寸为
$ D_{K} \times D_{K} \times M $ ,卷积核尺寸为${D_F} \times {D_F} \times M$ ,卷积核数量为$N$ 。假设对应特征图的每一个点都会进行一次卷积操作。单个卷积核计算量为
$$ {D_K} \times {D_K} \times {D_F} \times {D_F} \times M $$ (1) $N$ 个卷积核计算量为$$ {D_K} \times {D_K} \times {D_F} \times {D_F} \times M \times N $$ (2) Depthwise Atrous Convolution计算量为
$$ {D_K} \times {D_K} \times {D_F} \times {D_F} \times M $$ (3) Pointwise Convolution计算量为
$$ {D_K} \times {D_K} \times M \times N $$ (4) 深度可分离空洞卷积金字塔的计算总量为
$$ {D_K} \times {D_K} \times {D_F} \times {D_F} \times M + {D_K} \times {D_K} \times {D_F} \times {D_F} \times M \times N $$ (5) 深度可分离空洞卷积金字塔与标准卷积计算量比值为
$$ \frac{1}{N} + \frac{1}{{D_F^2}} $$ (6) 由式(6)可知深度可分离空洞卷积金字塔效率远高于标准卷积。
2.3 变压器渗漏油特征融合
2.3.1 多注意力模块
多注意力模块借鉴了空间注意力和位置注意力思想[26],如图4所示。输入的变压器渗漏油特征图会经过一个通道注意力模块,通道注意力模块对输入的变压器渗漏油图像特征图分别进行平均池化和最大值池化对特征图在空间层面进行压缩。之后,通过共享全连接层后进行元素合并。最后,通过Sigmod函数得到通道注意力特征图。空间注意力模块将通道注意力特征图作为输入,通道注意力特征图经过平均池化和最大池化后通道被压缩。然后,在经过1次卷积层后通道数被调整为1。最后,根据Sigmod函数生成多注意力特征图。
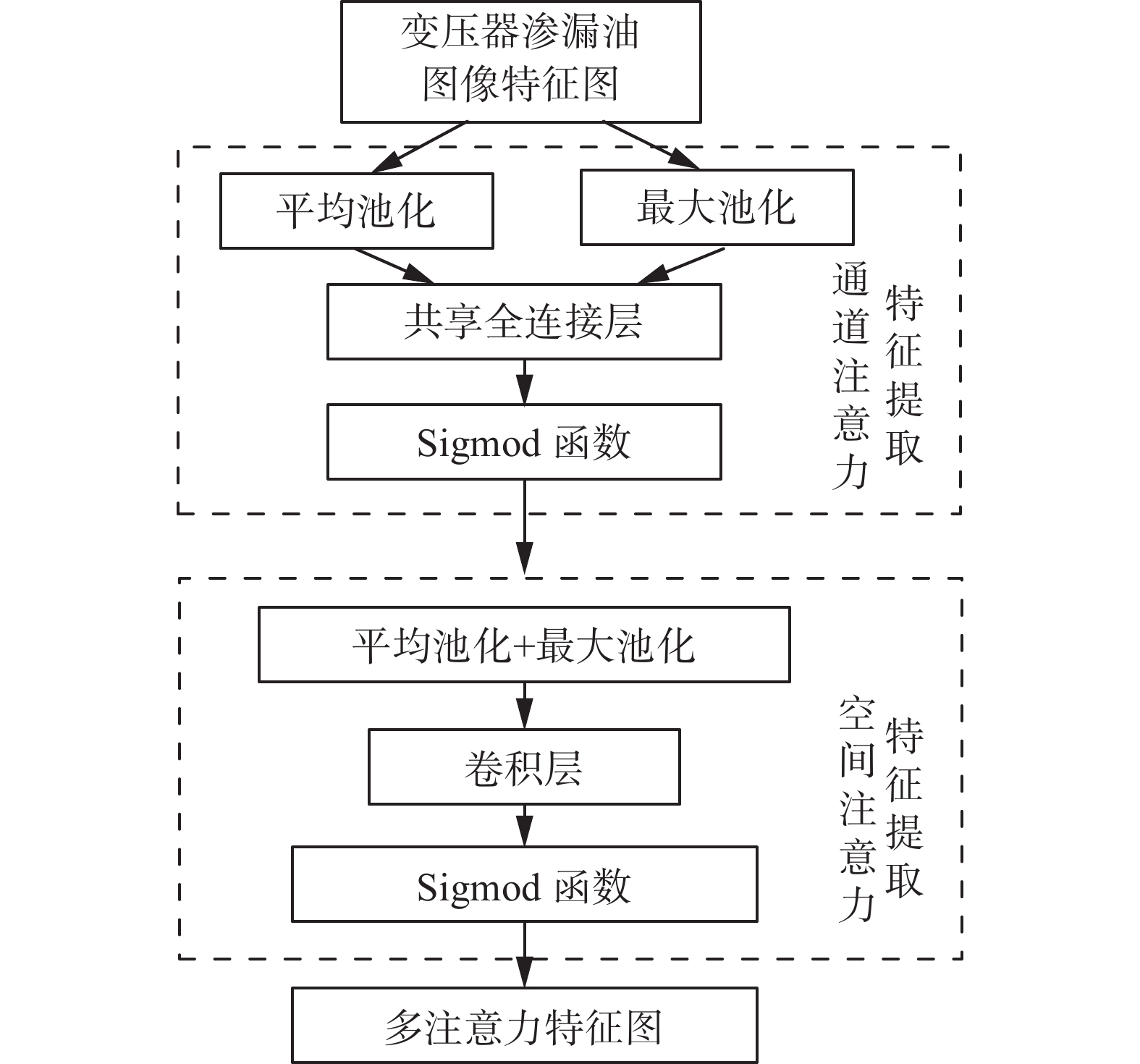 图 4 多注意力模块Fig. 4 Multi-attention module schematic下载:
全尺寸图片
图 4 多注意力模块Fig. 4 Multi-attention module schematic下载:
全尺寸图片
2.3.2 改进的特征融合模块
图5是改进的特征融合过程。本文在低阶特征F1与高阶特征F3融合的基础上,增加了低阶特征F2与融合后的特征(F1,F3)的融合。在输入低阶特征后,会对特征图添加注意力机制得到注意力特征图。首先,输入高阶特征图F3后会对高阶特征图F3进行上采样,将高阶特征图F3尺寸与低阶特征F1调整一致。其次,上采样完成后会对低阶特征图F1与高阶特征图F3进行拼接操作。然后对融合后的特征图(F1,F3)进行上采样,将特征图(F1,F3)尺寸与低阶特征图F2调整一致。最后,对低阶特征图F2与特征图(F1,F3)进行拼接操作。
 图 5 改进特征融合过程Fig. 5 Improved feature fusion process下载:
全尺寸图片
图 5 改进特征融合过程Fig. 5 Improved feature fusion process下载:
全尺寸图片
2.4 Dice损失函数
Dice系数是一种集合相似度度量函数,通常用于计算两个样本的相似度(取值范围为[0,1]),公式为
$$ {D_{{\text{ice}}}} = \frac{{2|X \cap Y|}}{{|X| + |Y|}} $$ (7) 式中:
$|X \cap Y|$ 表示集合X和Y的交集,$|X|$ 和$|Y|$ 表示元素个数,对于语义分割任务,$|X|$ 和$|Y|$ 分别代表GroundTrue和PredictMask。Dice系数越大代表重合度越大,但作为Loss是越小越好,所以Diceloss=1−Dice。为了防止分母为零,通常会添加一个Smooth作为缓冲,由此得到Diceloss:$$ {D_{{\text{iceloss}}}} = 1 - \frac{{2|X \cap Y| + S_{\rm{mooth}}}}{{|X| + |Y| + S_{\rm{mooth}}}} $$ (8) 3. 实验及结果分析
3.1 数据及实验参数
本文实验数据集为变电站中实际采集数据,共计变压器渗漏油图像2000幅,以9∶1的比例划分为训练集和测试集。利用开源数据标记软件Labelme对图像完成标记操作。本文使用的操作系统为Windows11,GPU选用NVIDIA GTX 3060Ti,深度学习框架为Pytorch1.12.1。为了减少特征提取网络的初始化权重对实验结果造成的影响,本文所选取骨干网络Xception已在ImageNet上进行过预训练,采用随机梯度下降法进行模型参数的更新。
本文实验参数设置如表1所示。
表 1 实验参数Table 1 Experimental parameters参数名称 参数值 epoch 300 batchsize 8 learningrate 0.007 weightdecay 0.0004 momentum 0.9 3.2 实验结果及分析
采用查准率(Precision, P)、平均交并比mIOU(Mean Intersection over Union, mIoU)、召回率(Recall, R)、检测速率作为评价指标进行实验结果的分析。
$$ P = \frac{{{p_{ii}}}}{{{p_{ii}} + {p_{ji}}}} $$ (9) $$ \begin{gathered} m_{{\rm{IOU}}} = \frac{1}{{n + 1}}\sum\limits_{i = 0}^n {{{\frac{{{p_i}_i}}{{\displaystyle\sum\limits_{j = 0}^n {{p_i}_j} + \displaystyle\sum\limits_{j = 0}^n {{p_{ji}} - } {p_{ij}}}}}_{}}} \\ \\ \end{gathered} $$ (10) $$ {{{R}}} = \frac{1}{{n + 1}}\sum\limits_{i = 0}^n {{{\frac{{{p_i}_i}}{{\displaystyle\sum\limits_{j = 0}^n {{p_i}_j} }}}_{}}} $$ (11) 式(9)~(11)所用符号注释已在表2中给出。
表 2 符号注释Table 2 Symbol notes符号 对应注释 ${{n} }$ 类别总数 pii 像素类别为i被预测为类别i的总数量 pij 像素类别为i被预测为类别j的总数量 pji 像素类别为j被预测为类别i的总数量 3.2.1 变压器渗漏油数据集上的消融实验
本文设计了5组消融实验,实验结果如表3所示。表3中,B_LINE代表基础网络,IFFN代表改进特征融合过程的网络,MN(多注意力机制网络,multi-head attention net)代表结合多注意力机制的网络,IFFN+MN代表结合多注意力机制和改进特征融合的网络,DSACP代表结合多注意力机制+改进特征融合+深度可分离空洞卷积金字塔的网络。
表 3 消融实验结果Table 3 Ablation experimental result% 序号 方法 P mIOU R #1 B_LINE 67.52 57.48 67.90 #2 IFFN 70.03 61.48 69.87 #3 MN 73.19 62.52 72.97 #4 IFFN+MN 75.15 64.07 74.07 #5 DSACP 76.85 64.63 73.56 由表3可知,使用未经任何修改的模型进行训练,模型的查准率、平均交并比、召回率分别为67.52%、57.48%、67.90%。分析B_LINE和IFFN的实验结果发现,网络的查准率、平均交并比、召回率分别提升了2.51%、4.00%、1.97%,说明对特征融合过程改进后增强了特征图上的变压器渗漏油语义信息。分析B_LINE和MN的实验结果发现,网络的查准率、平均交并比、召回率分别提升了5.67%、5.04%、5.07%,说明添加多注意力机制可以提高网络的学习能力。分析IFFN+MN和DSACP的实验结果发现,改进后的深度可分离空洞卷积金字塔结构与原空洞卷积金字塔结构相比,改进后的网络查准率、平均交并比分别提升了1.7%、0.56%,这是由于深度空洞卷积可以在卷积核大小不变的情况下扩大特征提取网络感受野,使特征提取网络提取到的特征图语义信息更加丰富,从而导致网络查准率、平均交并比的提升,以此说明提出的深度可分离空洞卷积金字塔结构增强了特征提取网络的提取能力。分析B_LINE和DSACP的实验结果发现,网络的查准率、平均交并比、召回率分别提升了9.33%、7.15%、5.66%。综上所述,说明本文提出的3种改进方法对变压器渗漏油图像检测确有优势。
消融实验结果可视化如图6所示。
 图 6 消融实验可视化检测结果Fig. 6 Visualization of ablation experiment results下载:
全尺寸图片
图 6 消融实验可视化检测结果Fig. 6 Visualization of ablation experiment results下载:
全尺寸图片
消融实验部分结论分析部分的查准率、平均交并比、召回率的百分数提升如表4所示。
表 4 消融实验结果提升率Table 4 Improvementrate of ablation experimental result% 序号 方法 ΔP ΔmIOU ΔR #1 B_LINE — — — #2 IFFN 2.51 4.00 1.97 #3 MN 5.67 5.04 5.07 #4 IFFN+MN 7.63 6.59 6.17 #5 DSACP 9.33 7.15 5.66 3.2.2 与其他常用语义分割模型比较
为进一步验证本文所提出模型的有效性,在变压器渗漏油数据集上,使用本文提出模型DSACP与其他常用语义分割模型进行了对比。对比实验参数的设置和本文方法的实验参数设置一致,卷积核大小均为3×3,实验结果如表5所示。
表 5 与其他算法比较Table 5 Comparison with other model arithmetic方法 P/% mIOU/% R/% FPS/(f/s) UNet 63.55 58.88 63.41 20 PSPNet 74.10 60.24 67.80 27 DeepLabv3+ 67.52 57.48 67.90 34 MCNN[19] 62.12 59.26 71.00 25 DSACP 76.85 64.63 73.56 30 由表5可知,分析UNet与DSACP的实验结果发现,本文所提模型DSACP的查准率、平均交并比、召回率相较于UNet分别提升了13.3%、5.75%、10.15%,检测速率提升了10 f/s。分析PSPNet与DSACP的实验结果发现,本文所提模型DSACP的查准率、平均交并比、召回率相较于PSPNet分别提升了2.75%、4.39%、5.76%,检测速率提升了3 f/s。分析Deeplabv3+与DSACP的实验结果发现,本文所提模型DSACP的查准率、平均交并比、召回率相较于PSPNet分别提升了9.33%、7.15%、5.66%,检测速率降低了4 f/s,原因是添加多注意力模块后模型的计算开销增加,但在计算开销略有增长的情况下,查准率、平均交并比、召回率明显提升。分析MCNN与DSACP的实验结果发现,本文所提模型DSACP的查准率、平均交并比、召回率相较于MCNN分别提升了14.73%、5.37%、2.56%,检测速率提升了5 f/s。本文所提模型DSACP与其他语义分割模型相比具有明显的优势, 查准率、平均交并比、召回率均有提升,DSACP的检测速率高于UNet、PSPNet和MCNN算法,模型生成的掩码图更加贴合变压器实际渗漏油区域,并且能够很好地捕捉变压器渗漏油图像中的边缘渗漏油区域。进一步证明了本文模型DSACP针对变压器渗漏油图像检测的优势。
不同语义分割模型实验结果可视化如图7所示。
 图 7 不同语义分割算法可视化检测结果Fig. 7 Visualization of detection results of common semantic segmentation algorithms下载:
全尺寸图片
图 7 不同语义分割算法可视化检测结果Fig. 7 Visualization of detection results of common semantic segmentation algorithms下载:
全尺寸图片
4. 结束语
针对变压器渗漏油背景复杂、油液形状多样、特征图语义信息不丰富等问题,本文在语义分割网络DeepLabv3+的基础上提出了基于深度可分离空洞卷积金字塔的变压器渗漏油检测模型。主要工作如下:
1)提出深度可分离空洞卷积金字塔结构,该模块可以增强特征图的视觉信息和语义信息;
2)通过对特征图进行二次融合,改进特征融合过程;
3)引入多注意力机制增强网络对图像的特征提取能力。
实验结果表明,本文所提模型DSACP可以显著提升变压器渗漏油的检测效果,模型的查准率、平均交并比、召回率大幅提升,可为变压器渗漏油检测提供量化依据与指导。本文的研究成果可以推广到其他领域的渗漏油检测中,如:海洋渗漏油检测、铁路轨道渗漏油检测,展现出十分广阔的应用前景。
-
图 1 DeepLabv3+网络结构
Fig. 1 DeepLabv3+ network structure
下载:
全尺寸图片
图 2 基于深度可分离空洞卷积金字塔的变压器渗漏油检测模型
Fig. 2 Transformer leakage oil detection model based on depth-separable atrous convolution pyramid
下载:
全尺寸图片
图 3 深度可分离空洞卷积金字塔结构
Fig. 3 Depthwise-separable dilated convolutional pyramid structure
下载:
全尺寸图片
图 4 多注意力模块
Fig. 4 Multi-attention module schematic
下载:
全尺寸图片
图 5 改进特征融合过程
Fig. 5 Improved feature fusion process
下载:
全尺寸图片
图 6 消融实验可视化检测结果
Fig. 6 Visualization of ablation experiment results
下载:
全尺寸图片
图 7 不同语义分割算法可视化检测结果
Fig. 7 Visualization of detection results of common semantic segmentation algorithms
下载:
全尺寸图片
表 1 实验参数
Table 1 Experimental parameters
参数名称 参数值 epoch 300 batchsize 8 learningrate 0.007 weightdecay 0.0004 momentum 0.9 表 2 符号注释
Table 2 Symbol notes
符号 对应注释 ${{n} }$ 类别总数 pii 像素类别为i被预测为类别i的总数量 pij 像素类别为i被预测为类别j的总数量 pji 像素类别为j被预测为类别i的总数量 表 3 消融实验结果
Table 3 Ablation experimental result
% 序号 方法 P mIOU R #1 B_LINE 67.52 57.48 67.90 #2 IFFN 70.03 61.48 69.87 #3 MN 73.19 62.52 72.97 #4 IFFN+MN 75.15 64.07 74.07 #5 DSACP 76.85 64.63 73.56 表 4 消融实验结果提升率
Table 4 Improvementrate of ablation experimental result
% 序号 方法 ΔP ΔmIOU ΔR #1 B_LINE — — — #2 IFFN 2.51 4.00 1.97 #3 MN 5.67 5.04 5.07 #4 IFFN+MN 7.63 6.59 6.17 #5 DSACP 9.33 7.15 5.66 表 5 与其他算法比较
Table 5 Comparison with other model arithmetic
方法 P/% mIOU/% R/% FPS/(f/s) UNet 63.55 58.88 63.41 20 PSPNet 74.10 60.24 67.80 27 DeepLabv3+ 67.52 57.48 67.90 34 MCNN[19] 62.12 59.26 71.00 25 DSACP 76.85 64.63 73.56 30 -
[1] RAJOTTE C. Guide for transformer maintenance[R]. Paris: Cigre Working Group A2.34, 2011. [2] Power transformers - Part 7: Loading guide for oil-immersed power transformers: IEC 60076-7 Ed. 1.0 b: 2005[S]. International Electrotechnical Commission [iec], 2005. [3] 翟永杰, 杨旭, 赵振兵, 等. 融合共现推理的Faster R-CNN输电线路金具检测[J]. 智能系统学报, 2021, 16(2): 237–246. ZHAI Yongjie, YANG Xu, ZHAO Zhenbing, et al. Integrating co-occurrence reasoning for Faster R-CNN transmission line fitting detection[J]. CAAI transactions on intelligent systems, 2021, 16(2): 237–246. [4] 苏丽, 孙雨鑫, 苑守正. 基于深度学习的实例分割研究综述[J]. 智能系统学报, 2022, 17(1): 16–31. SU Li, SUN Yuxin, YUAN Shouzheng. A survey of instance segmentation research based on deep learning[J]. CAAI transactions on intelligent systems, 2022, 17(1): 16–31. [5] 马岽奡, 唐娉, 赵理君, 等. 深度学习图像数据增广方法研究综述[J]. 中国图象图形学报, 2021, 26(3): 487–502. MA Dongao, TANG Ping, ZHAO Lijun, et al. Review of data augmentation for image in deep learning[J]. Journal of image and graphics, 2021, 26(3): 487–502. [6] 赵振兵, 张薇, 翟永杰, 等. 电力视觉技术的概念、研究现状与展望[J]. 电力科学与工程, 2020, 36(1): 1–8. ZHAO Zhenbing, ZHANG Wei, ZHAI Yongjie, et al. Concept, research status and prospect of electric power vision technology[J]. Electric power science and engineering, 2020, 36(1): 1–8. [7] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779−788. [8] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6517−6525. [9] FARHADI A, REDMON J. YOLOv3: an incremental improvement[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 1804−2767. [10] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020−04−23)[2023−03−29]. https://arxiv.org/abs/2004.10934. [11] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[EB/OL]. (2022−07−06)[2023−03−29]. https://arxiv.org/abs/2207.02696. [12] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[C]//European Conference on Computer Vision. Cham: Springer, 2016: 21−37. [13] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 580−587. [14] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 [15] LI Lu, ICHIMURA S, MORIYAMA T, et al. A system to detect small amounts of oil leakage with oil visualization for transformers using fluorescence recognition[J]. IEEE transactions on dielectrics and electrical insulation, 2017, 24(2): 1249–1255. doi: 10.1109/TDEI.2017.006110 [16] LI Anqi, YE Dongxu, LYU Erli, et al. RGB-thermal fusion network for leakage detection of crude oil transmission pipes[C]//2019 IEEE International Conference on Robotics and Biomimetics. Dali: IEEE, 2020: 883−888. [17] LI Lu, ICHIMURA S, YAMAGISHI A, et al. Oil film detection under solar irradiation and image processing[J]. IEEE sensors journal, 2020, 20(6): 3070–3077. doi: 10.1109/JSEN.2019.2955088 [18] 鲍伟超, 顾理, 何劲松, 等. 基于循环训练法的变压器漏油检测[J]. 计算机辅助设计与图形学学报, 2021, 33(3): 431–438. BAO Weichao, GU Li, HE Jinsong, et al. Transformer oil leakage detection based on loop training method[J]. Journal of computer-aided design & computer graphics, 2021, 33(3): 431–438. [19] GHORBANI Z, BEHZADAN A H. Monitoring offshore oil pollution using multi-class convolutional neural networks[J]. Environmental pollution, 2021, 289: 117884. doi: 10.1016/j.envpol.2021.117884 [20] WANG Feng, ZHONG Zhen, WANG Guang, et al. A penalized convolution model for oil leakage detection in electrohydraulic railway point systems[J]. IEEE transactions on instrumentation and measurement, 2021, 70: 1–9. [21] CHEN Xu, LIU Lei, HUANG Wei. The detection and prediction for oil spill on the sea based on the infrared images[J]. Infrared physics & technology, 2016, 77: 391–404. [22] LI Bing, WANG Tian, HU Zhedong, et al. Two-level model for detecting substation defects from infrared images[J]. Sensors, 2022, 22(18): 6861. doi: 10.3390/s22186861 [23] CHEN L C, ZHU Yukun, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//European Conference on Computer Vision. Cham: Springer, 2018: 833−851. [24] CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1800−1807. [25] CHEN L C, GEORGE P, FLORIAN S, etal. Rethinking atrous convolution for semantic image segmentation[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1601−1614. [26] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//European Conference on Computer Vision. Cham: Springer, 2018: 3−19.




















