
UAV image small-target detection based on improved Yolov5
-
摘要: 为了解决无人机航拍图像小目标检测算法检测速度与精度无法兼顾的问题,在Yolov5的基础上,提出了针对于无人机图像小目标检测的Yolov5_GBCS算法。在新的算法中,添加一个额外的检测头,以便增强对小目标的特征融合效果;在主干网络中分别采用GhostConv卷积模块、GhostBottleneckC3模块替换部分Conv模块和C3模块用以提取丰富特征和冗余特征以提高模型效率;引入加权双向特征金字塔网络(bidirectional feature pyramid network, BiFPN)结构,用以提高对小目标的检测精度;在主干网络和颈部网络中引入轻量化的卷积块注意力模块(convolutional block attention module, CBAM),关注重要特征并抑制不必要的特征,增强小目标特征表达能力;使用Soft-NMS算法来替换NMS,因此降低了小目标在密集场景下的漏检率。通过在VisDrone2019数据集上的实验结果表明,集成了所有改进的方法后的Yolov5_GBCS算法,不仅提高了检测精度,而且有效地提高了检测速度,模型的mAP从38.5%提高到43.2%,检测速度也从53 f/s提高到59 f/s。Yolov5_GBCS算法可以有效地实现无人机航拍图像中小目标识别。
-
关键词:
- 图像处理 /
- GhostConv卷积模块 /
- 双向特征金字塔网络 /
- 卷积块注意力模块 /
- Soft双向特征金字塔网络 /
- 轻量化模型 /
- 小目标检测 /
- VisDrone数据集
Abstract: The detection speed and accuracy of small targets captured by UAV aerial photography cannot be considered at the same time. To address this problem, a new algorithm based on the Yolov5 algorithm, namely Yolov5_GBCS, is proposed for small-target detection of UAV-captured images. In the new algorithm, an additional detector head is added to enhance the feature fusion effect of small targets. In the backbone network, the GhostConv convolution module and GhostBottleneckC3 module are used to replace some original Conv modules and C3 modules for extracting rich and redundant features, respectively, to improve the model efficiency. The weighted bidirectional feature pyramid network structure is introduced to enhance the detection accuracy of small targets. The lightweight convolutional block attention module is introduced into the backbone and neck networks to focus on important features and suppress unnecessary features to boost the ability of small-target feature expression. The Soft-NMS algorithm is used to replace the NMS for reducing the miss detection rate of small targets in dense scenes. Experimental results on the VisDrone 2019 dataset show that the Yolov5_GBCS algorithm integrating all improved methods enhances the detection accuracy and effectively improves the detection speed. The mAP of the subject model has been increased from 38.5% to 43.2%, and the detection speed from 53 f/s to 59 f/s. Therefore, the Yolov5_GBCS algorithm can effectively recognize small targets in the image captured by UAV aerial photography. -
随着网络技术的快速发展,无人机图像目标检测技术具有广泛的应用范围,包括森林防火、农业信息、电力线检测、道路和桥梁损伤评估等。相较于自然环境视角下拍摄的图像,无人机航拍图像具有巨大的高空视角优势。但无人机拍摄图像却存在背景复杂度高、目标尺寸小、外观模糊等缺陷。同时,基于传统方法的目标检测技术对小目标检测精度低,对复杂背景下目标的适应性弱,容易发生漏检和误检。随着深度学习的发展,基于卷积神经网络的目标检测方法近年来迅速发展起来[1],在检测精度和速度方面都超过了传统的目标检测方法,然而当前大多数目标检测模型仅仅适用于处理自然环境图像,如果采用同样的算法用于处理无人机航拍图像就会存在一些问题。首先,目前大多数目标检测模型无法满足实时检测需求,关键是在提高检测精度的同时减少计算量和参数量;其次,无人机航拍图像中含有大量小目标,其形态表征能力较弱,严重影响小目标的检测精度。
近些年来,Yolo系列检测模型因其速度快,精度高而被广泛引用于无人机航拍图像目标检测。Liu等[2]提出MTI-YOLO用于无人机电力线路检查中的绝缘子等目标,在Yolov3Tiny的基础上添加特征融合结构和SPP模块来扩展颈部网络,并且添加了主干网络的输出层。发现,这种模型在颈部网络的改进是多余的,需要优化网络结构。为了提高小目标检测精度,Sahin等[3]扩展了Yolov3的主干输出层,以检测图像中不同尺度的物体,将原来的3个检测层增加到5个,这样的结构在特征融合部分起到一定的作用,但这也导致了检测模型参数量极大增加,从而增加了训练和计算成本。Wang等[4]提出了LDS-YOLO检测模型,考虑到无人机图像中小目标特征难以提取的问题,该模型在Yolov5的基础上构造了一个新的特征提取模块,在SPP模块中引入SoftPool结构,并采用深度可分离卷积替代传统卷积。该模型的优点在于参数量较小,但由于训练时样本不足,很容易使模型无法学习到目标特征。为了解决电力巡检无人机检测速率与精度无法兼顾的问题,提出ED-YOLO目标检测算法,在Yolov4算法上引入注意力机制和深度可分离卷积,使得模型检测速度大大提升,但伴随着精度的下降[5]。为了提高无人机小目标检测精度,陈蕊等[6]提出了AF-YOLO模型,引入了自适应融合机制,在检测精度超过了原模型,但是精度的提升是在牺牲检测性能的情况下获得的。
综上所述,基于无人机平台目标检测算法的性能问题,提出了两个指导思想:1)在不降低检测精度的同时,通过轻量化设计理念提高检测性能;2)提升小目标检测算法的检测精度。
于是对原有的Yolov5s模型采用了5种改进方法:1)添加P2特征级别;2)在主干网络部分采用GhostConv卷积模块替换baseline中的部分Conv模块,在backbone网络部分采用GhostBottleneckC3模块替换baseline中的部分C3模块;3)在颈部网络采用BiFPN(bidirectional feature pyramid network)特征提取结构,弥补下采样特征信息丢失,以便快速地进行多尺度特征融合;4)在主干网络和颈部网络中采用了卷积注意力模块(convolutional block attention module,CBAM)[7],用于提取重要特征,提升模型检测精度;5)在预测网络中引入Soft-NMS算法[8],解决了NMS对密集物体检测的检测效果欠佳的问题。
1. Yolov5网络改进
1.1 Yolov5s网络结构改进
本研究基于Yolov5提出了改进网络Yolov5_GBCS。为了确保提升小目标检测算法的检测精度的同时,提高检测效率,在主干网络采用GhostConv取代后3个普通卷积,再采用由GhostBottleneck结果组成的GhostBottleneckC3取代主干网络的前3个C3模块,极大地减少了参数量。同时,分别在主干网络和颈部网络引入CBAM,增强了网络的特征提取能力的同时保持精度;添加P2特征级别,提高了网络的深度和小目标检测的准确性;在颈部网络采用BiFPN结构,快速的进行多尺度特征融合。改进后的网络结果如图1所示。
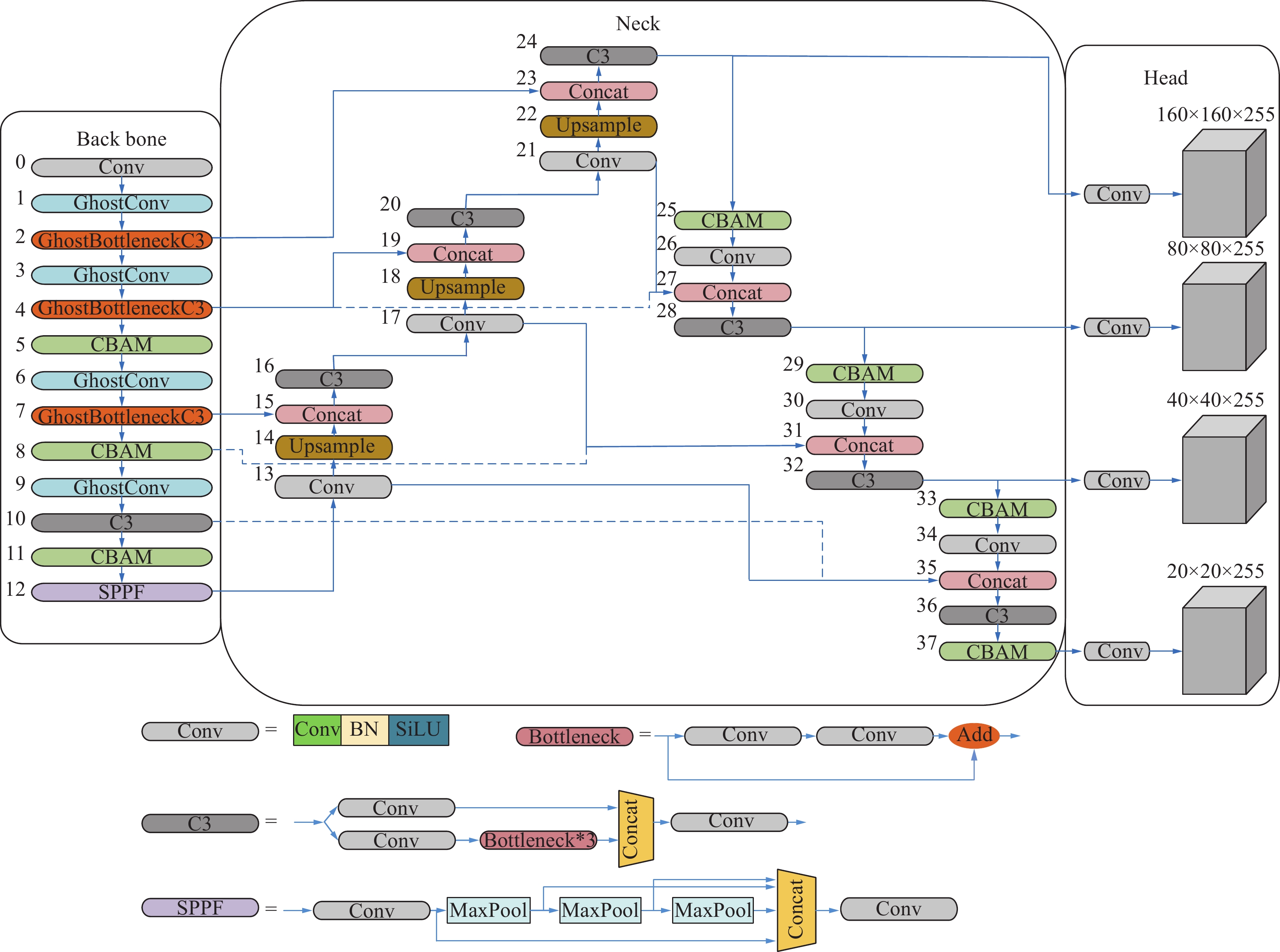 图 1 Yolov5_GBCS结构Fig. 1 Yolov5_GBCS structure diagram
图 1 Yolov5_GBCS结构Fig. 1 Yolov5_GBCS structure diagram 下载:
全尺寸图片
下载:
全尺寸图片
1.2 引入CBAM
在无人机航拍图像中含有大量非目标区域,可以通过引入注意机制使模型更好地关注目标区域的信息。注意力机制从大量的信息中选择少量的重要信息。改进模型中使用的CBAM是一种结合空间和通道的混合注意机制模块,图2为CBAM的整体流程结构,它由通道注意力模块和空间注意力模块两大模块构成。与只关注通道本身的SENet[9]相比,CBAM整合了通道注意力(见图2(a))与空间注意力(见图2(b))映射过程,可以保留更多的特征信息,有效地提高训练出来的网络模型的检测速度,同时提高网络的特征提取能力和检测精度。CBAM注意力模块的结构如图2(c)所示。
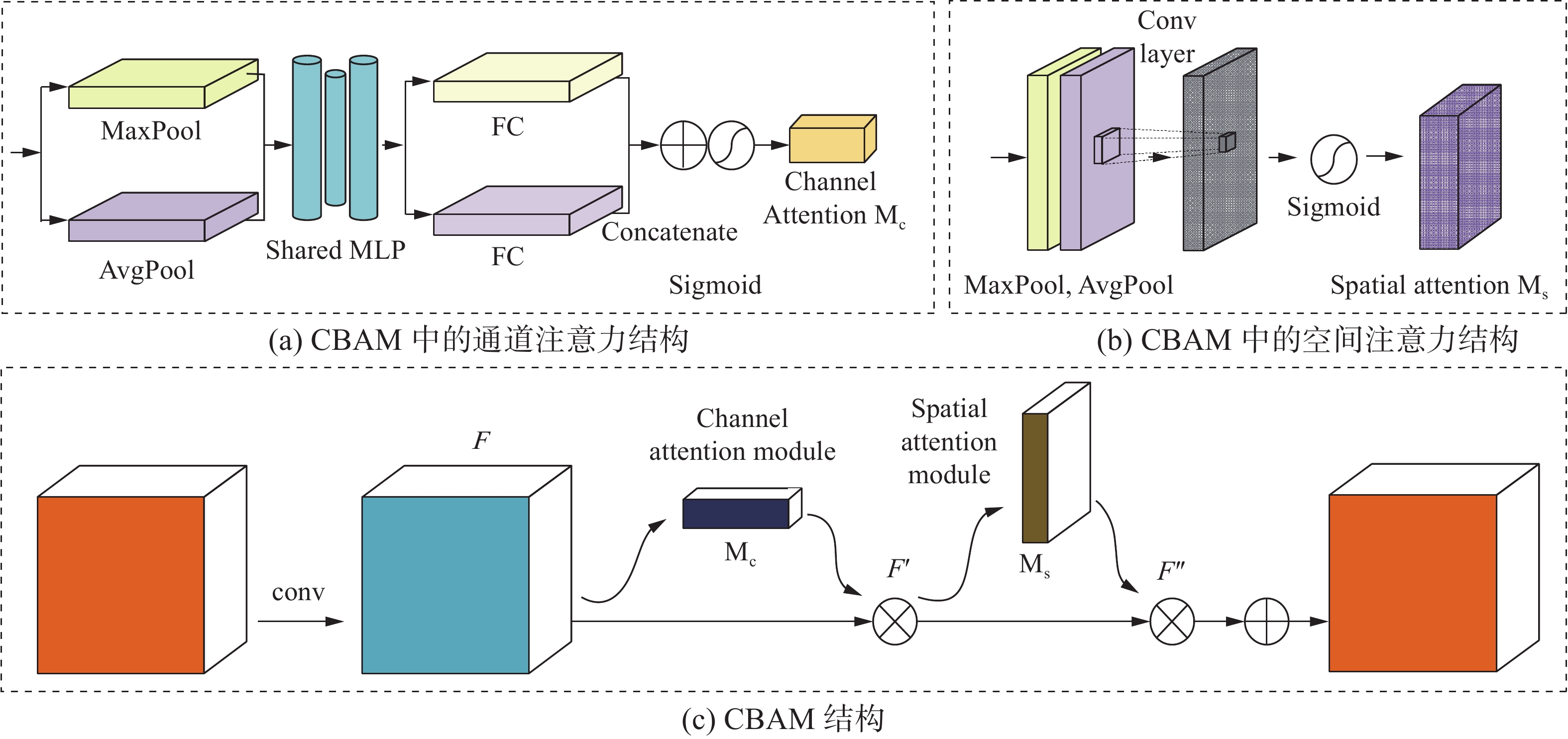 图 2 CBAM模块以及子模块结构Fig. 2 Structure of CBAM module and sub modules下载:
全尺寸图片
图 2 CBAM模块以及子模块结构Fig. 2 Structure of CBAM module and sub modules下载:
全尺寸图片
图2(a)所示的通道注意力模块首先分别对输入特征图的宽度和高度维度进行全局最大池化和全局平均池化,以聚合特征图的空间信息。然后将结果传递到多层感知机中,以便使用共享的全连接层进行处理。最后,通过Sigmod激活函数,生成最终的通道注意力特征图
$ {M}_{c}\left(F\right) $ 。该特征图的结果与输入特征图加权后,作为空间注意力模块的输入特征。通道注意特征图
$ {M}_{c}\left(F\right) $ 的数学表达式:$$ \begin{array}{c}{M}_{c}\left(F\right)=\sigma \left(\mathrm{M}\mathrm{L}\mathrm{P}\left(\mathrm{A}\mathrm{v}\mathrm{g}\mathrm{P}\mathrm{o}\mathrm{o}\mathrm{l}\left(F\right)\right)+\mathrm{M}\mathrm{L}\mathrm{P}\left(\mathrm{M}\mathrm{a}\mathrm{x}\mathrm{P}\mathrm{o}\mathrm{o}\mathrm{l}\left(F\right)\right)\right)\end{array} $$ (1) 式中:σ为Sigmod激活函数,MLP为层间的连接权值操作,AvgPool和MaxPool分别表示最大池化操作和平均池化操作。
在通道注意力模块之后,引入了如图2(b)所示的空间注意力模块。与通道注意力类似,空间注意力机制压缩通道,并分别在通道维度上进行均值池化和最大池化。首先,输入特征层在每个特征点的通道上取最大值和平均值。之后将两个结果叠加。最后通过Sigmoid函数生成空间注意力特征图
$ {M}_{s}\left(F\right) $ ,其数学表达式为$$ \begin{array}{c}{M}_{s}\left(F\right)=\sigma \left({f}^{7\times 7}\left(\left[\mathrm{A}\mathrm{v}\mathrm{g}\mathrm{P}\mathrm{o}\mathrm{o}\mathrm{l}\left(F\right);\mathrm{M}\mathrm{a}\mathrm{x}\mathrm{P}\mathrm{o}\mathrm{o}\mathrm{l}\left(F\right)\right]\right)\right)\end{array} $$ (2) 式中:7×7表示卷积核的大小,即对特征图进行7×7的卷积操作。经验表明,7×7的卷积核优于3×3的卷积核。在主干网络和颈部网络引入了CBAM。
从图3中可以看出,在添加了CBAM后,改进的算法相对于原Yolov5s能够更多地关注目标区域,而忽略杂乱背景中的不相关因素,有利于提高目标特征的学习能力,提高检测精度。
 图 3 热力图可视化结果对比Fig. 3 Comparison of visualization results of thermal map下载:
全尺寸图片
图 3 热力图可视化结果对比Fig. 3 Comparison of visualization results of thermal map下载:
全尺寸图片
1.3 基于BiFPN的特征融合网络
无人机的拍摄视角更高,视野更广可以捕捉到更多的物体,但是这也考验了检测算法对小目标识别的精度,所以如何表示和处理多尺度特征是一个难题。图4给出了多尺度特征处理结构。其中,图4(a)为FPN的结构,该方法将多尺度特征相结合,使用复合特征层和更多的语义信息进行预测。根据这一想法,图4(b)的PANet[10]继续在FPN之上添加一个自下而上的路径聚合网络,同时考虑了顶层的语义信息和底层的位置信息。Yolov5框架将多尺度特性与FPN+PAN结构集成在一起,但由于输入特性的分辨率不同,FPN+PAN结构对融合输出特性的贡献往往是不均匀的,不同尺度之间的特性不能得到充分利用。因此,在Yolov5框架中引入了一种简单、高效的BiFPN网络结构,以提高检测精度。
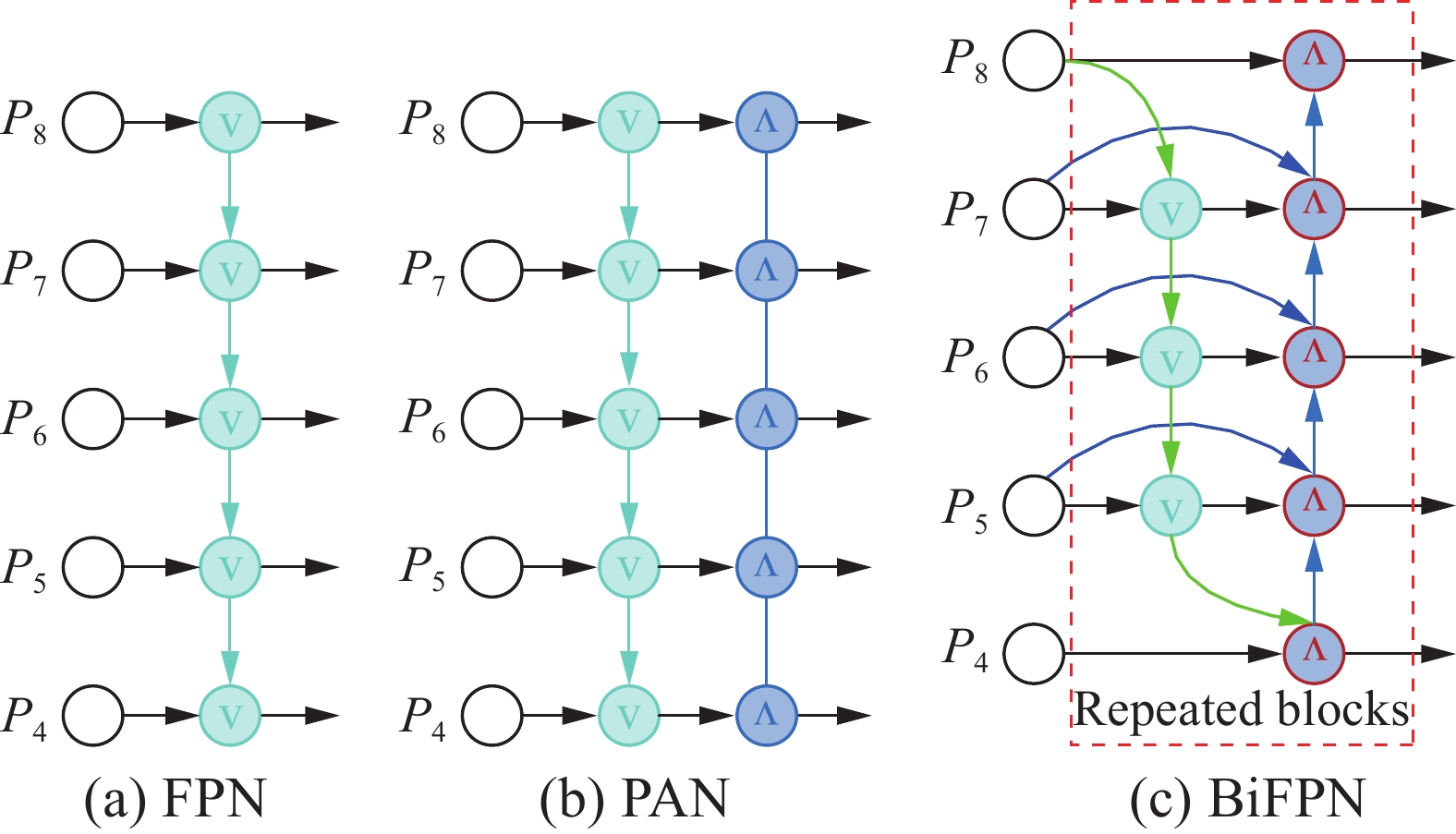 图 4 不同特征融合网络结构Fig. 4 Structure of different feature fusion networks下载:
全尺寸图片
图 4 不同特征融合网络结构Fig. 4 Structure of different feature fusion networks下载:
全尺寸图片
如图4(c)所示,BiFPN网络加强了更高层次的特征融合,将每个双向路径作为特征网络层进行处理,并在同一层上重复多次。通过加权特征的融合,学习不同输入特征的重要性,并对不同的特征进行区分融合。
BiFPN使用快速归一化来融合加权特征,其定义为
$$ \begin{array}{c}O=\displaystyle\sum _{i}\dfrac{{W}_{i}}{\varepsilon +\displaystyle\sum _{j}{W}_{j}}\cdot {I}_{i}\end{array} $$ (3) 式中:学习权重
$ {W}_{i} $ 使用ReLU激活函数,其值为ε=0.0001,以加强该值的稳定性。为了进一步提高深度网络学习模型的检测效率,BiFPN使用了可分离的卷积融合特征,并在每次卷积后添加了批处理归一化和激活函数操作。以第6层为例,描述2个融合特征的定义如下:$$ \begin{array}{c}{P}_{ 6}^{\mathrm{t}\mathrm{d}}={\rm{Conv}}\left(\dfrac{{W}_{1}\cdot {P}_{ 6}^{\mathrm{i}\mathrm{n}}+{W}_{2}\cdot {R}_{\mathrm{e}\mathrm{s}\mathrm{i}\mathrm{z}\mathrm{e}}\left({P}_{ 7}^{\mathrm{i}\mathrm{n}}\right)}{{W}_{1}+{W}_{2}+\mathrm{\varepsilon }}\right)\end{array} $$ (4) $$ \begin{array}{c}{P}_{ 6}^{\mathrm{o}\mathrm{u}\mathrm{t}}={\rm{Conv}}\left(\dfrac{{W}_{1}'\cdot {P}_{ 6}^{\mathrm{i}\mathrm{n}}+{W}_{2}'\cdot {P}_{ 6}^{\mathrm{t}\mathrm{d}}+{W}_{3}'\cdot {R}_{\mathrm{e}\mathrm{s}\mathrm{i}\mathrm{z}\mathrm{e}}\left({P}_{ 5}^{\mathrm{o}\mathrm{u}\mathrm{t}}\right)}{{W}_{1}'+{W}_{2}'+{W}_{3}'+\varepsilon }\right)\end{array} $$ (5) 其中:
$ {P}_{ 6}^{\mathrm{t}\mathrm{d}} $ 从上到下表示第6层的中间特征,$ {P}_{ 6}^{\mathrm{o}\mathrm{u}\mathrm{t}} $ 是第6层从下到上的输出特征。通过不同层间的互连和融合,最终实现了BiFPN的双向交叉尺度连接和快速归一化融合。基于上述优点,引入BiFPN,改进特征金字塔结构,增强多尺度特征融合,提高模型检测精度。1.4 针对小目标增加预测头
Yolov5_GBCS骨干网络包含连续的下采样卷积层,因此在特征信息提取过程中,特征图的尺寸随着网络的加深而减小。特征图的小尺寸影响了对图像中的小物体的检测。然而,无人机图像中包含了大量的小物体。为了增强小物体的特征融合效果,于是添加了一个额外的检测头。改进的模型如图1所示。在第20层之后,继续对特征图进行上采样,以确保特征图继续扩展,在第23层,将尺寸为160×160的特征图与主干网络中第2层的特征图进行融合,以获得小目标的更大特征图输入至第24层后的检测头中。将高层、低层的特征信息进行特征融合,使添加的检测头对小物体更加敏感。最后,检测头的4种不同尺度特征更能适应无人机图像物体尺度的剧烈变化。
1.5 网络结构轻量化设计
GhostNet提出了一个创新的模块Ghost,它用更少的参数与计算量得到更多的特征图。Ghost模块一部分是普通卷积,另一部分是线性运算。Ghost的工作原理如图5所示。
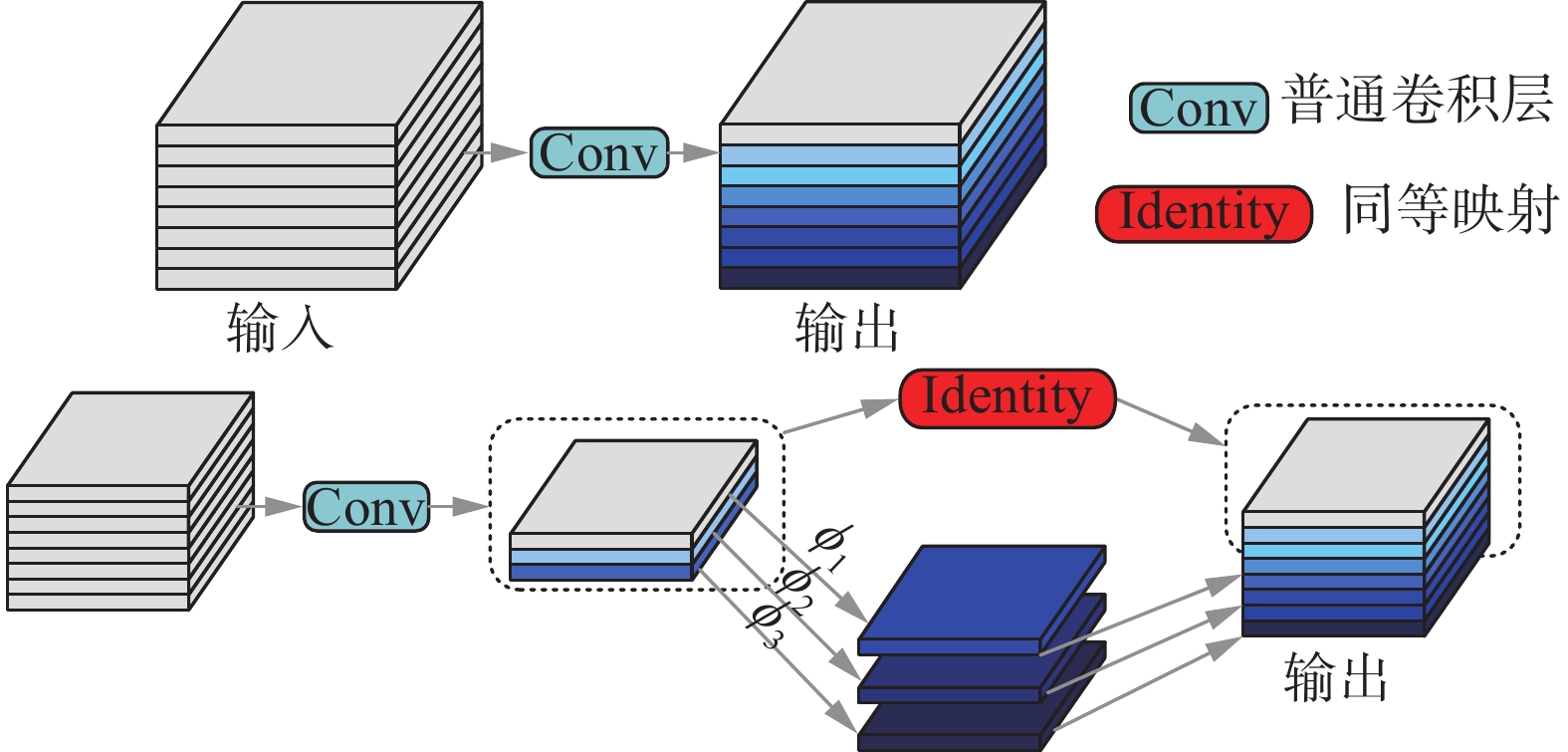 图 5 Ghost卷积与普通卷积的比较Fig. 5 Comparison of Ghost convolution and general convolution下载:
全尺寸图片
图 5 Ghost卷积与普通卷积的比较Fig. 5 Comparison of Ghost convolution and general convolution下载:
全尺寸图片
普通卷积层的操作为
$$ \begin{array}{c}Y=X\cdot f+b\end{array} $$ (6) Ghost模块首先通过普通卷积生成少量的特征图;然后对第1步得到的特征图进行计算量较小的线性操作,生成Ghost特征图。最后,对两组特征图进行通道拼接,生成足够的特征图来匹配给定的输出通道数量。
Ghost卷积采用了逐步进行的策略,计算方法为
$$ \begin{array}{c}{Y}'=X\cdot {f}'\end{array} $$ (7) $$ \begin{array}{c}{Y}_{ij}={\phi }_{ij}\cdot {Y}_{i}',iϵ\left[1,m\right],jϵ\left[1,s\right]\end{array} $$ (8) 式中:
$ Y\in {\mathbf{R}}^{{W}'\times {H}'\times m} $ 表示输入X在经过普通卷积$ {f}'\in {\mathbf{R}}^{k\times k\times C\times m} $ 生成的$ m $ 个特征图($ m \ll n$ );然后将$ m $ 个特征图逐个进行线性操作,每个特征图生成1个特征图,共生成$ n=m\times s $ 个特征图。特征图$ {\phi }_{ij} $ 表示对第1步卷积生成的第$ j $ 个特征图,$ {Y}_{i}' $ 表示第$ i $ 次线性运算。为了保证CPU或GPU的效率和实用性,将每个线性操作的卷积核的大小设置为$ d\times d $ ;那么普通卷积和Ghost卷积的速度比可以通过下式计算得出:$$ \begin{array}{c} {R}_{s}=\dfrac{{W}'\cdot {H}'\cdot n\cdot k\cdot k\cdot C}{{W}'\cdot {H}'\cdot m\cdot k\cdot k\cdot C+{W}'\cdot {H}'\cdot \left(n-m\right)\cdot d\cdot d\cdot C}= \\ \dfrac{{W}'\cdot {H}'\cdot n\cdot k\cdot k\cdot C}{{W}'\cdot {H}'\cdot \left(n/s\right)\cdot k\cdot k\cdot C+{W}'\cdot {H}'\cdot \left(s-1\right)\cdot d\cdot d}= \\ \dfrac{k\cdot k\cdot C}{\left(1/s\right)\cdot k\cdot k\cdot C+\left(s-1\right)/{s}\cdot d\cdot d}\approx \\ \dfrac{s\cdot C}{s+C-1}\approx s \end{array} $$ (9) Ghost卷积是一个更轻、更快的模块。在此基础上,主干网络采用了GhostConv以及基于Ghost模块的GhostBottleneckC3模块,具体结构如图6所示。
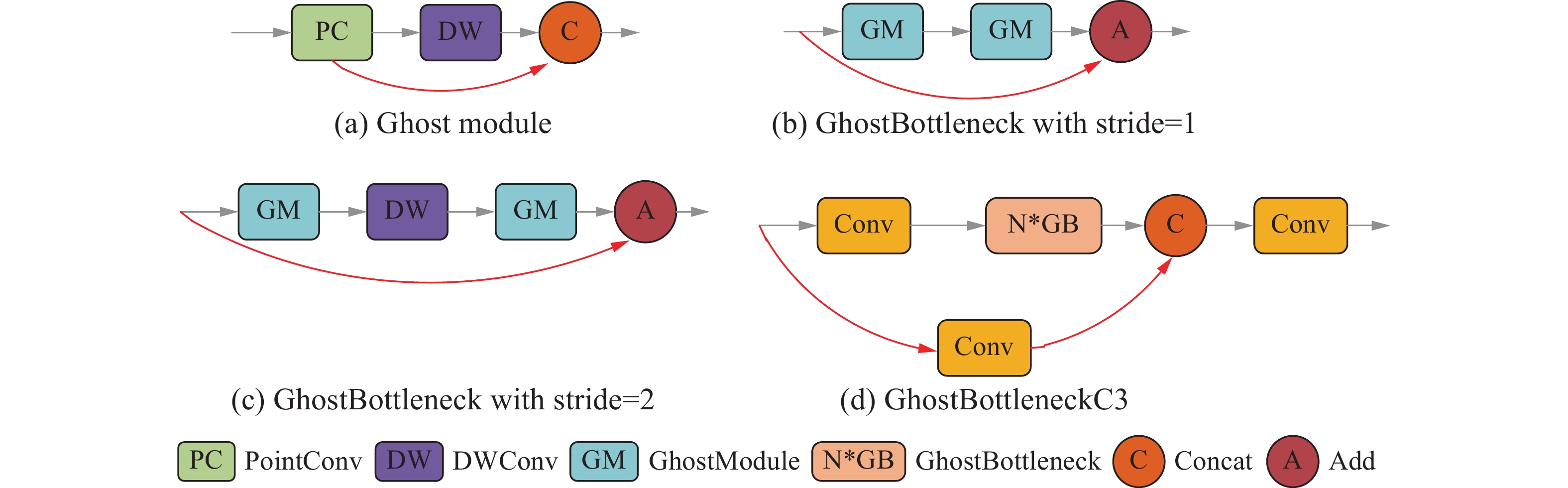 图 6 Ghost module模块、GhostBottleneck模块以及GhostBottleneckC3模块结构Fig. 6 Structure of Ghost module, GhostBottleneck module, and GhostBottleneckC3 module下载:
全尺寸图片
图 6 Ghost module模块、GhostBottleneck模块以及GhostBottleneckC3模块结构Fig. 6 Structure of Ghost module, GhostBottleneck module, and GhostBottleneckC3 module下载:
全尺寸图片
由于Bottleneck中使用了较多3×3标准卷积,因此用GhostBottleneck结构替换C3模块中的Bottleneck模块能够将模型的体积和计算量进一步压缩。用图6(b)的GhostBottleneck结构替换Yolov5s中C3的Bottleneck模块得到新的GhostBottleneckC3结构,如图6(d)所示。GhostBottleneckC3结构可以减少模型的计算量并压缩体积。
1.6 NMS的改进
NMS被应用于大多数最先进的检测器,因为它能够显著地减少了假阳性的数量。NMS算法的流程图如图7所示。首先,列表中的所有检测框都根据它们的置信度得分进行排序。其次,将得分最高的检测框
$ {B}_{M} $ 移动到最终的检测列表D中,并为剩余的检测框分配一个唯一的标识符$ {B}_{i} $ 。第三,去除任何与的重叠面积大于一定阈值$ {N}_{t} $ 的预测框$ {B}_{i} $ 。对其余的框$ {B}_{i} $ 重复此过程,直到初始列表被置空为止。然而,由于无人机视角的特殊性,会导致大量小目标重叠,于是会导致NMS算法的检测失误。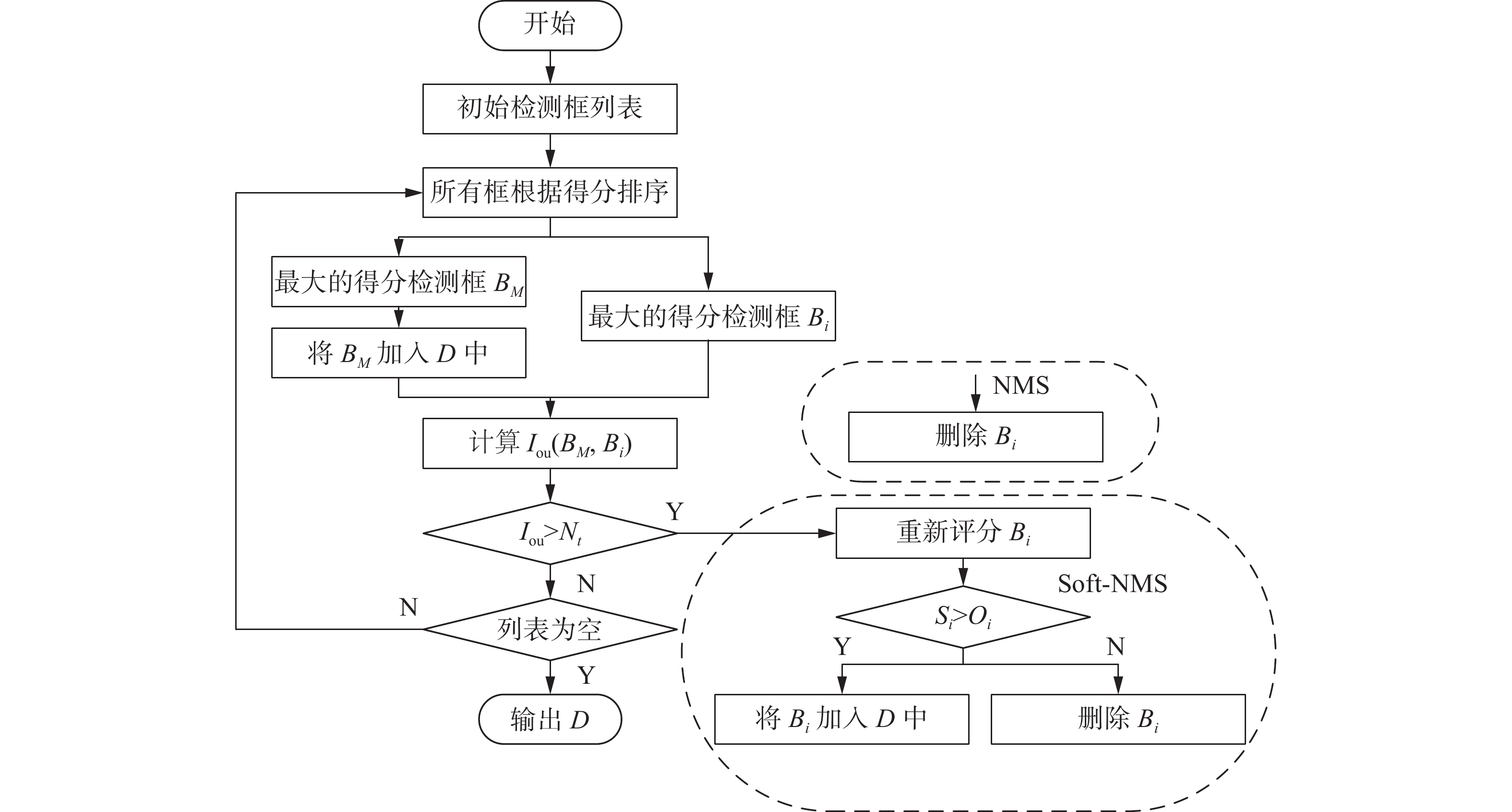 图 7 NMS和Soft-NMS的算法流程Fig. 7 The algorithm flow of NMS and Soft-NMS下载:
全尺寸图片
图 7 NMS和Soft-NMS的算法流程Fig. 7 The algorithm flow of NMS and Soft-NMS下载:
全尺寸图片
接下来,对于无人机的密集目标的场景,本身属于两个目标的检测框可能
$ {I}_{{\rm{ou}}} $ 很高,如果使用NMS算法,会将置信度较小的那个检测框删除掉,有可能造成漏检,降低了模型的召回率。因此,引入了Soft-NMS而不是NMS来处理检测结果。Soft-NMS的核心思想是使用一个惩罚函数来减弱与
$ {B}_{M} $ 重叠的预测框的分数,而不是将这些分数设置为零。Soft-NMS的$ {S}_{i} $ 的计算方式为$$ \begin{array}{l} {S}_{i}=\left\{ \begin{array}{l}{S}_{i},\quad{I}_{\mathrm{o}\mathrm{u}}\left({B}_{M},{B}_{i}\right) < {N}_{t}\\ {S}_{i}\cdot {\rm{exp}}\left(-\dfrac{{I}_{\mathrm{o}\mathrm{u}}{\left({B}_{M},{B}_{i}\right)}^{2}}{\sigma }\right),\quad {I}_{\mathrm{o}\mathrm{u}}\left({B}_{M},{B}_{i}\right)\geqslant {N}_{t}\end{array}\right. \end{array} $$ (10) 式中:
$\mathrm{e}\mathrm{x}\mathrm{p}\left(-\dfrac{{I}_{{\rm{ou}}}{\left({B}_{M},{B}_{i}\right)}^{2}}{\sigma }\right)$ 是一个高斯惩罚函数,而$ \sigma $ 是根据经验选择的超参数。很明显,与$ {B}_{M} $ 重叠较大的预测框的得分会大大降低,而远离$ {B}_{M} $ 的检测框则不会受到影响。如果预测框的得分仍然高于惩罚后的置信阈值$ {O}_{t} $ 。然后,预测框将被保留,而不是被丢弃。在目标密集的场景中,使用Soft-NMS来处理小目标检测问题,可以大大降低误检率。2. 实验结果与分析
2.1 数据集及实验环境
为了评价改进后的Yolov5s方法,使用VisDrone2019数据集对该算法进行检验。VisDrone2019数据集中共计包含6 471张训练集图像、548张验证集图像和1 610张测试集图像。数据集中包含各种交通场景,包括高速公路、十字路口、丁字路口,不同的环境背景,包括白天、夜晚、雾霾天、雨天。该类数据集满足实验训练的需求,能够满足无人机对地面小目标的检测效果验证的需要。本实验中的所有算法均在训练集上进行训练,并在验证集上进行评估。
实验平台的硬件环境为CPU:Intel(R) Xeon(R) Silver 4114 CPU,GPU:TeslaV100S-PCIE 32 GB,内存:64 GB,软件环境为CUDA10.1+cudnn 7.6.5+Python-3.9.12 +Pytorch1.8.1。
2.2 实验步骤
Visdrone2019数据集和VOC数据集的目标尺度与宽高比大不相同,先验框不再合适本次实验,需要重新计算。因此,在训练步骤之前,使用k-means[11]聚类算法在Visdrone2019数据集上计算新的先验框。
对所有实验学习率均采用Warmup[12]训练,保持模型的深度稳定性。在热身训练阶段,学习率从0上升到设置大小的0.01。在预热阶段结束后,使用余弦退火算法更新学习速率,在模型训练中采用Adam优化器。网络模型的权值进行更新和优化。具体参数设置为:bitch size大小为64,学习率为0.01,动量参数为0.937,权重衰减因子为0.0005,训练轮数设置为300。
2.3 评价指标
在本实验中,选择mAP@0.5、参数量、每秒千兆浮点运算量(gigabit floating-point operations per second,GFLOPS)和检测速率来作为目标检测模型的评价指标。其中mAP@0.5表示在
$ {I}_{\mathrm{o}\mathrm{u}} $ 阈值为0.5时的平均检测精度$ {P}_{{\rm{A}}} $ 。参数量和计算量是衡量深度学习算法的重要指标,计算量对应的是算法的时间复杂度,参数量对应的是算法的空间复杂度,mAP@0.5主要用于体现模型的识别能力,检测速率为每秒检测图像的数量,值越大检测速度越快,效率越高。
上述各指标的计算公式如下:
$$ \begin{array}{c}P=\dfrac{{N}_{\mathrm{T}\mathrm{P}}}{{N}_{\mathrm{T}\mathrm{P}}+{N}_{\mathrm{F}\mathrm{P}}}\end{array} $$ (11) $$ \begin{array}{c}R=\dfrac{{N}_{\mathrm{T}\mathrm{P}}}{{N}_{\mathrm{T}\mathrm{P}}+{N}_{\mathrm{F}\mathrm{N}}}\end{array} $$ (12) $$ \begin{array}{c}{P}_{\mathrm{A}}={\displaystyle\int }_{0}^{1}P\mathrm{d}R\end{array} $$ (13) $$ \begin{array}{c}{P}_{\mathrm{m}}=\dfrac{\displaystyle\sum _{i=1}^{N}{P}_{\mathrm{A}i}}{N}\end{array} $$ (14) $$ \begin{array}{c}v=\dfrac{{N}_{\mathrm{F}\mathrm{i}\mathrm{g}\mathrm{u}\mathrm{r}\mathrm{e}}}{{T}_{\mathrm{T}\mathrm{o}\mathrm{t}\mathrm{a}\mathrm{l}}}\end{array} $$ (15) 式中:NTP、NFP和NFN分别表示物体被正确检测的数量、物体被错误检测的数量和没有被检测到的物体的数量,
${P}_{{\rm{A}}i}$ 为第$ i $ 类物体的平均检测精度,N为物体的类别数量,$ {N}_{\mathrm{F}\mathrm{i}\mathrm{g}\mathrm{u}\mathrm{r}\mathrm{e}} $ 表示检测图片的总数,$ {T}_{\mathrm{T}\mathrm{o}\mathrm{t}\mathrm{a}\mathrm{l}} $ 表示总检测需要消耗的时间。2.4 对比实验
在VisDrone2019数据集上测试了Yolov5_GBCS模型,并将结果与其他具有代表性的模型进行了比较。结果如表1所示。证明了其对无人机图像的小目标检测的有效性。这些结果表明,该模型可以在保持目标检测性能的同时,提高了小目标检测能力。
表 1 不同网络模型下不同目标的平均检测精度与mAP@0.5Table 1 Average precision and mAP@0.5 of different targets under different network models模型 不同目标的PA mAP@0.5 Pedestrain People Bicycle Car Van Trunk Tricycle Awing-t Bus Motor Yolov5s 0.542 0.474 0.282 0.645 0.528 0.525 0.429 0.304 0.627 0.505 0.385 CenterNet[13] 0.173 0.105 0.056 0.483 0.263 0.185 0.084 0.055 0.309 0.155 0.336 RetinaNet[14] 0.084 0.031 0.002 0.414 0.154 0.100 0.040 0.030 0.134 0.074 0.191 Cascade-RCNN[15] 0.199 0.123 0.084 0.541 0.353 0.264 0.174 0.092 0.422 0.196 0.390 Fcos[16] 0.173 0.093 0.033 0.513 0.267 0.225 0.086 0.070 0.341 0.096 0.319 Tridentnet[17] 0.169 0.105 0.059 0.508 0.288 0.224 0.144 0.071 0.330 0.168 0.353 Faster-RCNN[18] 0.176 0.120 0.072 0.505 0.301 0.233 0.144 0.089 0.372 0.182 0.371 FSAF[19] 0.221 0.141 0.056 0.538 0.293 0.215 0.089 0.058 0.309 0.165 0.364 ATSS[20] 0.197 0.065 0.074 0.544 0.310 0.245 0.142 0.087 0.370 0.181 0.363 DDOD 0.219 0.119 0.074 0.553 0.314 0.254 0.145 0.086 0.372 0.198 0.382 TOOD[21] 0.219 0.130 0.086 0.562 0.330 0.260 0.161 0.091 0.388 0.214 0.398 VFNet[22] 0.206 0.091 0.067 0.553 0.323 0.253 0.147 0.083 0.390 0.192 0.373 LDS-YOLO 0.557 0.459 0.335 0.692 0.541 0.519 0430 0.326 0.688 0.521 0.415 M-YOLO 0.581 0.492 0.366 0.652 0.557 0.521 0.443 0.314 0.741 0.533 0.424 Yolov5_GBCS 0.574 0.540 0.350 0.683 0.569 0.528 0.447 0.334 0.736 0.546 0.432 从表1中可以看出,与Yolov5s相比,提出的模型无论各个物体类别的精度还是mAP@0.5超过了Yolov5s。Pedestrain的
$ {P}_{\mathrm{A}} $ 提升了3.2%,People的$ {P}_{\mathrm{A}} $ 提升了6.6%,Bicycle的$ {P}_{\mathrm{A}} $ 提升了6.8%,Car的$ {P}_{\mathrm{A}} $ 提升了3.8%,Van的$ {P}_{\mathrm{A}} $ 提升了4.1%,Tricycle的$ {P}_{\mathrm{A}} $ 提升了13.9%,Awing-Tricycle的$ {P}_{\mathrm{A}} $ 提升了3.0%,Bus的$ {P}_{\mathrm{A}} $ 提升了10.9%,Motor的$ {P}_{\mathrm{A}} $ 提升了4.1%,其中Trunk的$ {P}_{\mathrm{A}} $ 提升的并不大,只有0.3%。最后,改进后的模型Yolov5_GBCS的mAP@0.5比Yolov5s提升了5.1%,与LDS-YOLO和M-YOLO这两个同样基于改进的Yolov5的小目标检测算法相比mAP@0.5分别提升了1.7%和0.8%。由此可以得出结论,在针对无人机图像小目标检测方面,Yolov5_GBCS模型比原Yolov5s更加优秀。图8中给出了来自VisDrone2019数据集上的Yolov5_GBCS的一些具有代表性的检测结果。可以看出相对于Yolov5s,Yolov5_GBCS可以检测出更多的小目标。
 图 8 VisDrone2019数据集上的检测结果的可视化Fig. 8 Visualization of detection results on the VisDrone2019 dataset下载:
全尺寸图片
图 8 VisDrone2019数据集上的检测结果的可视化Fig. 8 Visualization of detection results on the VisDrone2019 dataset下载:
全尺寸图片
2.5 消融实验
为了验证5种改进方法的有效性,于是基于VisDrone 2019数据集进行了消融实验。在表2和图9中Model1为在Yolov5s中增加P2特征级别检测头,Model2为在Model1的基础上将主干网络分别采用GhostConv卷积模块、GhostBottleneckC3模块替换baseline中的部分Conv模块和C3模块,Model3为在Model2的基础上引入BiFPN结构,Model4为在Model3的基础上加入Soft-NMS算法,Model5为在Model4的基础上加入CBAM注意力模块。
表 2 VisDrone数据集上6种模型的消融研究Table 2 Ablation study of six models on VisDrone dataset模型 P2 Ghost BiFPN CBAM Soft-NMS 参数量/106 GFLOPS 检测速率/(f/s) mAP@0.5/% Yolov5s — — — — — 7.04 16.0 53 38.5 Model1 √ — — — — 7.27 19.3 45 40.2 Model2 √ √ — — — 5.96 14.6 59 41.3 Model3 √ √ √ — — 5.96 14.6 59 42.1 Model4 √ √ √ √ — 5.97 14.6 59 42.8 Model5 √ √ √ √ √ 5.97 14.6 59 43.2 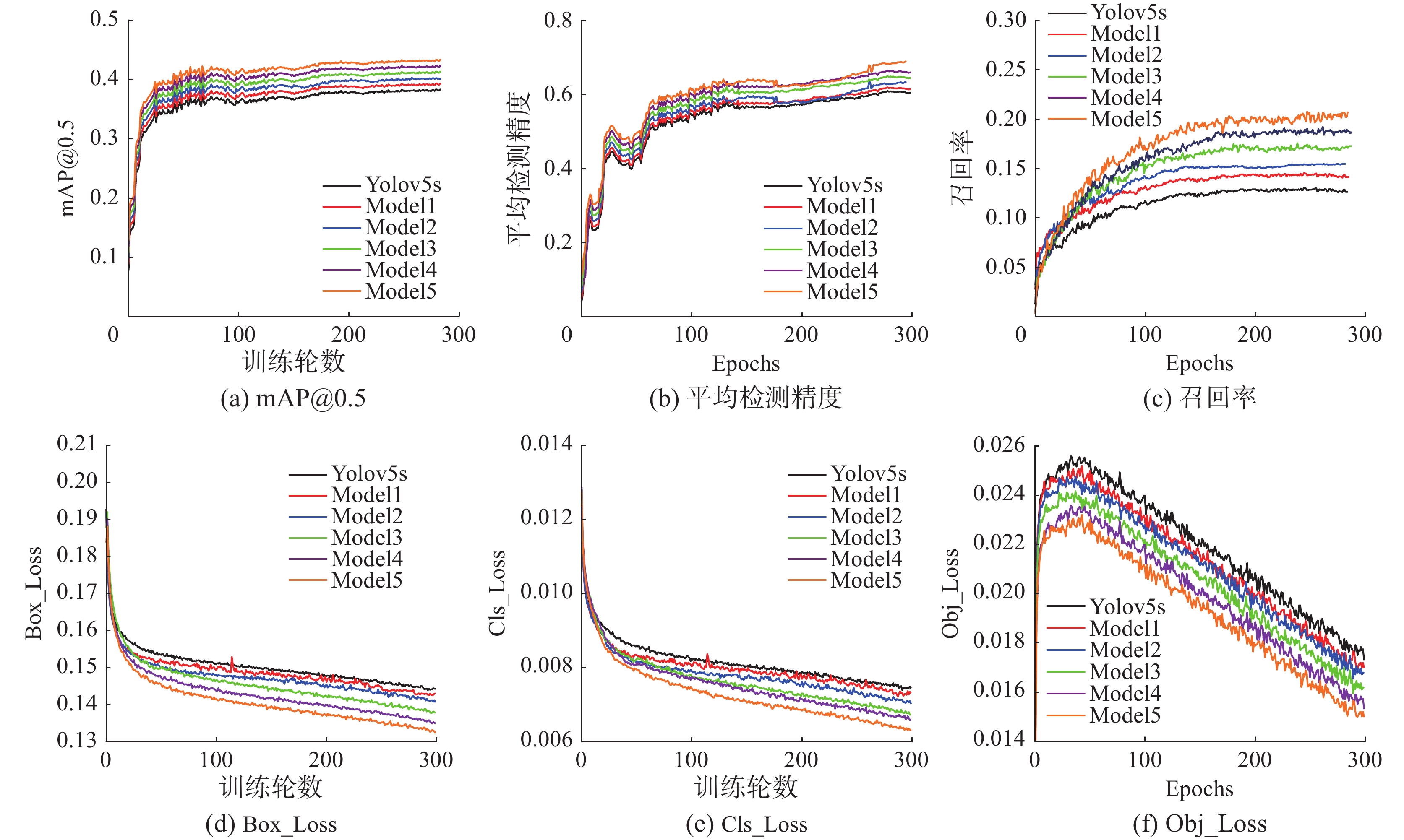 图 9 比较6个模型的训练结果Fig. 9 Compare the training results of the six models下载:
全尺寸图片
图 9 比较6个模型的训练结果Fig. 9 Compare the training results of the six models下载:
全尺寸图片
如图9所示,在训练过程中,损失函数值呈下降趋势,Adam算法对网络进行优化,网络权值等参数不断更新。在训练到40轮之前,损失函数值迅速下降,平均值测精度、召回率和mAP@0.5值迅速提高。当训练到100轮左右时,损失函数值的下降逐渐减慢。同样,平均值测精度、召回率和mAP@0.5的提升也有所放缓。当训练期到250轮时,训练的损失曲线几乎没有下降趋势,其他指标值也趋于稳定,网络模型基本达到收敛状态,并在训练结束时得到最优的网络权值。图9(a)显示,Model5模型经过约200轮训练后,mAP@0.5达到了42%,并逐渐稳定,最大值达到43.5%。图9(b)显示,当Model5模型训练到230轮时,平均检测精度达到63.82%,并继续增长到68.88%。图9(c)显示,Model5模型的召回率在40轮之前快速上涨,然后继续增长到20.3%的最高值。整体的模型性能已经达到了预期水平,甚至超出了预期水平。该模型的具体损失函数如图9(d)、(e)、(f)所示。从图9中可以看出,随着训练轮数的逐渐增加,Model5模型算法曲线逐渐收敛,损失值越来越小。当模型迭代230次时,损失值基本稳定,网络基本收敛。与其他模型相比,Model5模型对无人机小目标具有更好的检测性能和识别效果,回归速度更快、更准确,证明了该模型的有效性。消融实验试验结果表明,每种改进的方法都比原来的Yolov5s模型有一定的改进。
通过比较表2中Yolov5s和Model1的数据,发现增加P2特征级别检测头可以使模型的mAP@0.5从38.5%增加到40.2%,这表明针对小目标数据集增加尺度更大的检测头,保留了更丰富的小目标特征信息,在图像中的错误检测和遗漏检测得到改进,使得目标框和先验框都能更好地匹配并帮助损失函数更好地收敛,但是参数量和GFLOPS分别增加了3.3%和20.6%,直接导致塑料明显下降。对比表2中Model1与Model2的数据可以看出,在引入了GhostConv模块和GhostBottleneckC3模块后参数量、GFLOPS分别下降了18.0%和24.3%,mAP@0.5上涨了0.9%,检测速率也由45 f/s上涨至59 f/s。这表面对网络结构进行轻量化处理后,在避免了网络模型过于复杂从而造成的实时性能损失的同时,检测精度有也有所提升,达到速度与精度的平衡。对比表中Model2和Model3的数据,参数量和GFLOPS都没有增加的情况下,mAP@0.5上涨了0.8%,这表明在颈部网络采用BiFPN后,弥补下采样特征信息丢失,增强多尺度特征融合,提高了模型检测精度。CBAM注意力模块旨在提高网络提取重要特征的能力,从表中可以看出,Model4相对与Model3的mAP@0.5在检测速率、参数量和GFLOPS几乎不变的情况下,上涨了0.7%,可以说明CBAM机制的增加了网络模型的深度,在保证速度不变的同时,提高了小目标的检测效果。用Soft-NMS算法取代NMS算法后,模型有效地克服了待检测对象相互重叠时漏检的问题,模型的检测精度得到提高。Yolov5_GBCS相对于Yolov5s,mAP@0.5方面提高到4.7%;在参数量、GFLOPS方面,分别下降了15.2%和8.7%;检测速率从53 f/s提升到59 f/s。基于上述可以得知,Yolov5_GBCS无论是在检测效率方面还是检测精度方面都远远优于Yolov5s。
3. 结束语
无人机的飞行高度、视角和速度均会导致无人机图像中的目标较小,背景复杂,遮挡量大,给无人机图像中的目标检测带来了困难。为了解决上述问题,提出了一种改进的无人机航拍图像目标检测模型Yolov5_GBCS算法。通过增加一个P2特征级别的检测头,算法在具有复杂背景的无人机图像中检测小目标的能力得到了提高。引入Ghost模块和GhostBottleneckC3模块取代Yolov5中的Conv和C3模块,减小了模型的参数量与运算量。添加BiFPN来进行多尺度特征融合,提高特征提取性能。将注意机制CBAM融入算法中,提高复杂背景下对象区域的显著性,有效提高检测器的精度。此外,Soft-NMS有效的解决多目标重叠的问题,降低了误检和漏检的概率。在Visdrone2019数据集上的实验表明,Yolov5_GBCS算法能够有效地实时检测无人机视觉中的小物体,并且在mAP@0.5方面超过Yolov5s以及其他大多数检测模型,证明了该方法的有效性。
后续计划在Yolov5_GBCS算法的卷积层上进行通道剪枝,以减少网络参数的数量,加快网络计算速度。同时,将采用知识蒸馏来补偿剪枝模型的精度损失。轻量级设计使计算速度和精度之间的平衡,以满足部署无人机等嵌入式设备的需求。显然,该算法对环境监测、地质灾害探测、精准农业、城市规划等各种民用和军事任务具有较高的实用价值。
-
图 1 Yolov5_GBCS结构
Fig. 1 Yolov5_GBCS structure diagram
下载:
全尺寸图片
图 2 CBAM模块以及子模块结构
Fig. 2 Structure of CBAM module and sub modules
下载:
全尺寸图片
图 3 热力图可视化结果对比
Fig. 3 Comparison of visualization results of thermal map
下载:
全尺寸图片
图 4 不同特征融合网络结构
Fig. 4 Structure of different feature fusion networks
下载:
全尺寸图片
图 5 Ghost卷积与普通卷积的比较
Fig. 5 Comparison of Ghost convolution and general convolution
下载:
全尺寸图片
图 6 Ghost module模块、GhostBottleneck模块以及GhostBottleneckC3模块结构
Fig. 6 Structure of Ghost module, GhostBottleneck module, and GhostBottleneckC3 module
下载:
全尺寸图片
图 7 NMS和Soft-NMS的算法流程
Fig. 7 The algorithm flow of NMS and Soft-NMS
下载:
全尺寸图片
图 8 VisDrone2019数据集上的检测结果的可视化
Fig. 8 Visualization of detection results on the VisDrone2019 dataset
下载:
全尺寸图片
图 9 比较6个模型的训练结果
Fig. 9 Compare the training results of the six models
下载:
全尺寸图片
表 1 不同网络模型下不同目标的平均检测精度与mAP@0.5
Table 1 Average precision and mAP@0.5 of different targets under different network models
模型 不同目标的PA mAP@0.5 Pedestrain People Bicycle Car Van Trunk Tricycle Awing-t Bus Motor Yolov5s 0.542 0.474 0.282 0.645 0.528 0.525 0.429 0.304 0.627 0.505 0.385 CenterNet[13] 0.173 0.105 0.056 0.483 0.263 0.185 0.084 0.055 0.309 0.155 0.336 RetinaNet[14] 0.084 0.031 0.002 0.414 0.154 0.100 0.040 0.030 0.134 0.074 0.191 Cascade-RCNN[15] 0.199 0.123 0.084 0.541 0.353 0.264 0.174 0.092 0.422 0.196 0.390 Fcos[16] 0.173 0.093 0.033 0.513 0.267 0.225 0.086 0.070 0.341 0.096 0.319 Tridentnet[17] 0.169 0.105 0.059 0.508 0.288 0.224 0.144 0.071 0.330 0.168 0.353 Faster-RCNN[18] 0.176 0.120 0.072 0.505 0.301 0.233 0.144 0.089 0.372 0.182 0.371 FSAF[19] 0.221 0.141 0.056 0.538 0.293 0.215 0.089 0.058 0.309 0.165 0.364 ATSS[20] 0.197 0.065 0.074 0.544 0.310 0.245 0.142 0.087 0.370 0.181 0.363 DDOD 0.219 0.119 0.074 0.553 0.314 0.254 0.145 0.086 0.372 0.198 0.382 TOOD[21] 0.219 0.130 0.086 0.562 0.330 0.260 0.161 0.091 0.388 0.214 0.398 VFNet[22] 0.206 0.091 0.067 0.553 0.323 0.253 0.147 0.083 0.390 0.192 0.373 LDS-YOLO 0.557 0.459 0.335 0.692 0.541 0.519 0430 0.326 0.688 0.521 0.415 M-YOLO 0.581 0.492 0.366 0.652 0.557 0.521 0.443 0.314 0.741 0.533 0.424 Yolov5_GBCS 0.574 0.540 0.350 0.683 0.569 0.528 0.447 0.334 0.736 0.546 0.432 表 2 VisDrone数据集上6种模型的消融研究
Table 2 Ablation study of six models on VisDrone dataset
模型 P2 Ghost BiFPN CBAM Soft-NMS 参数量/106 GFLOPS 检测速率/(f/s) mAP@0.5/% Yolov5s — — — — — 7.04 16.0 53 38.5 Model1 √ — — — — 7.27 19.3 45 40.2 Model2 √ √ — — — 5.96 14.6 59 41.3 Model3 √ √ √ — — 5.96 14.6 59 42.1 Model4 √ √ √ √ — 5.97 14.6 59 42.8 Model5 √ √ √ √ √ 5.97 14.6 59 43.2 -
[1] 曹家乐, 李亚利, 孙汉卿, 等. 基于深度学习的视觉目标检测技术综述[J]. 中国图象图形学报, 2022, 27(6): 1697–1722. CAO Jiale, LI Yali, SUN Hanqing, et al. A survey on deep learning based visual object detection[J]. Journal of image and graphics, 2022, 27(6): 1697–1722. [2] LIU Chuanyang, WU Yiquan, LIU Jingjing, et al. MTI-YOLO: a light-weight and real-time deep neural network for insulator detection in complex aerial images[J]. Energies, 2021, 14(5): 1426. doi: 10.3390/en14051426 [3] SAHIN O, OZER S. YOLODrone: improved YOLO architecture for object detection in drone images[C]//2021 44th International Conference on Telecommunications and Signal Processing. Brno: IEEE, 2021: 361–365. [4] WANG Xuewen, ZHAO Qingzhan, JIANG Ping, et al. LDS-YOLO: A lightweight small object detection method for dead trees from shelter forest[J]. Computers and electronics in agriculture, 2022, 198: 107035. doi: 10.1016/j.compag.2022.107035 [5] 彭继慎, 孙礼鑫, 王凯, 等. 基于模型压缩的ED-YOLO电力巡检无人机避障目标检测算法[J]. 仪器仪表学报, 2021, 42(10): 161–170. PENG Jishen, SUN Lixin, WANG Kai, et al. ED-YOLO power inspection UAV obstacle avoidance target detectionalgorithm based on model compression[J]. Chinese journal of scientific instrument, 2021, 42(10): 161–170. [6] 陈蕊, 郑华飞, 蒋鸿宇, 等. 结合仿真迁移学习和自适应融合的无人机小目标检测[J/OL]. 小型微型计算机系统, 2022: 1–10. (2022–05–10). https://kns.cnki.net/kcms/detail/21.1106.TP.20220509.1930.032.html. CHEN Rui, ZHENG Huafei, JIANG Hongyu, et al. Combination of simulation-based transfer learning and adaptive fusion for UAV small object detection[J/OL]. Journal of Chinese computer systems, 2022: 1–10. (2022–05–10). https://kns.cnki.net/kcms/detail/21.1106.TP.20220509.1930.032.html. [7] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//European Conference on Computer Vision. Cham: Springer, 2018: 3–19. [8] BODLA N, SINGH B, CHELLAPPA R, et al. Soft-NMS-improving object detection with one line of code[C]//2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 5562–5570. [9] HU Jie, SHEN Li, SUN Gang. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132–7141. [10] LIU Shu, QI Lu, QIN Haifang, et al. Path aggregation network for instance segmentation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 8759–8768. [11] KRISHNA K, NARASIMHA MURTY M. Genetic K-means algorithm[J]. IEEE transactions on systems, man, and cybernetics, part B (cybernetics), 1999, 29(3): 433–439. doi: 10.1109/3477.764879 [12] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770–778. [13] DUAN Kaiwen, BAI Song, XIE Lingxi, et al. CenterNet: keypoint triplets for object detection[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 6568–6577. [14] WANG Haotong, LIU Bailin, LIU Zhiping, et al. LSS target threat estimation and capture prediction trajectory simulation[C]//2020 7th International Conference on Information Science and Control Engineering. Changsha: IEEE, 2020: 806–813. [15] CAI Zhaowei, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6154–6162. [16] TIAN Zhi, SHEN Chunhua, CHEN Hao, et al. FCOS: fully convolutional one-stage object detection[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 9626–9635. [17] LI Yanghao, CHEN Yuntao, WANG Naiyan, et al. Scale-aware trident networks for object detection[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 6053–6062. [18] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 [19] ZHU Chenchen, HE Yihui, SAVVIDES M. Feature selective anchor-free module for single-shot object detection[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 840–849. [20] ZHANG Shifeng, CHI Cheng, YAO Yongqiang, et al. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 9756–9765. [21] FENG Chengjian, ZHONG Yujie, GAO Yu, et al. TOOD: task-aligned one-stage object detection[C]//2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 3490–3499. [22] AHMED A, TANGRI P, PANDA A, et al. VFNet: a convolutional architecture for accent classification[C]//2019 IEEE 16th India Council International Conference. Rajkot: IEEE, 2019: 1–4.





























































