
Disinformation diffusion control method integrating user propagation risk and node influence analysis
-
摘要: 在线社交网络中虚假信息传播蔓延成为当前网络空间安全治理面临的重要挑战。提出一种融合用户传播风险和节点影响力分析的虚假信息传播控制方法DDC-UPRNI (disinformation diffusion control method integrating user propagation risk and node influence analysis)。综合考虑虚假信息传播特征空间的多样性和复杂性,通过自注意力机制实现用户传播虚假信息行为维度、时间维度和内容维度特征的嵌入表示,运用改进的无监督聚类K-means++算法实现不同用户传播风险等级的自动划分;设计一种自适应加权策略实现对离散粒子群优化算法的改进,进而提出一种基于离散粒子群优化的虚假信息传播关键节点选取方法,用于从具有特定传播风险等级的用户节点集合中选取若干个具有影响力的控制驱动节点,从而实现精准、高效的虚假信息传播控制;基于现实在线社交网络平台上开展试验,结果表明,所提出的DDC-UPRNI方法与现有算法相比,在控制效果和时间复杂度等重要指标上具有明显优势。该方法为社会网络空间中的虚假信息管控治理提供重要参考。Abstract: The spread of disinformation on online social networks (OSNs) has become a critical challenge for cyberspace security governance. This paper presents DDC-UPRNI, a disinformation diffusion control method, by integrating user propagation risk with node influence analysis. First, comprehensively considering the diversity and complexity of the characteristic space of disinformation propagation, an embedded representation of the behavior, time and content dimensions of user propagation of disinformation is realized through the self-attention mechanism, and the automatic classification of different user propagation risk levels is achieved using the improved unsupervised clustering K-means++ algorithm. Second, an adaptive weighting strategy is designed to improve the discrete particle swarm optimization algorithm, and a method for selecting key nodes of disinformation propagation is proposed based on the discrete particle swarm optimization. This method determines several influential control driving nodes from the user node set with a specific propagation risk level to achieve accurate and highly efficient disinformation propagation control. Finally, experiments are performed on a real OSN platform, and the results demonstrate that the proposed DDC-UPRNI method has obvious advantages over other existing algorithms in some important indicators, including control effect and time complexity. This method provides a significant reference value for the current governance of disinformation in social cyberspace.
-
在线社交网络(online social networks,OSNs)已经成为人们传递信息和表达情感的重要载体。然而,OSNs在为用户带来便利的同时,也滋生了大量虚假信息和谣言[1]。虚假信息由于具有突发性、隐蔽性和散布性等特点,所以给社会带来了巨大的负面影响力。相关研究表明,虚假信息在早期传播阶段与真实信息在传播方式上具有明显的区别[2]。此外,虚假信息甚至比真实信息传播得更快、更远和更广[3]。因此,虚假信息的控制和治理已经成为政府和社交平台管理者亟待解决的关键问题。
OSNs虚假信息和谣言的传播控制指通过采用合适的智能理论和技术,选取并控制某些特殊的关键传播节点(驱动节点),从而达到控制信息在整个网络中大规模传播的目的[4-5]。特别的,关键传播节点是指在虚假信息传播过程中起重要作用的节点。这些关键节点在传播广度、传播深度和传播速度上对社交网络平台造成严重影响。因此,准确有效识别关键传播节点成为OSNs虚假信息和谣言传播控制的重要手段之一[6]。目前,关键传播节点的识别方法主要分为两类,1)贪心算法[7-9]:该类算法在运行过程中能够获取很好的近似解,但由于涉及到蒙特卡罗仿真,故计算成本很高。此外,该类算法针对大规模社交网络时表现的性能并不理想。2)元启发式算法[10-12]:该类算法的优势在于能够有效地避免在运行过程中使用蒙特卡罗仿真,从而降低了计算的时间开销。因此,元启发式算法更适用于大规模社交网络中关键节点的识别。
情境分析作为一种以人为中心的新型计算范式的基础,在软件工程领域得到了广泛关注[13]。随着社会网络服务的多样化,人−人和人−机器在交互过程中产生了大量以人为中心的数据。在早期的研究中,Zhang等[14]通过将情境分析技术推广到社会网络领域,提出了一套社会情境理论,并将其用于社交用户行为模式的分析和发现。在此基础上,张志勇等[15]进一步提出了适用于社交网络虚假信息传播场景的社会情境安全分析框架(socialsitu security)。由于本研究开展的虚假信息传播风险研究与用户传播行为模式之间具有潜在的关系,因此社会情境安全分析框架为本研究工作的开展奠定了重要的基础。
粒子群优化(particle swarm optimizer,PSO)算法作为一种经典的群智能优化算法,具有简单、高效和收敛速度快等显著优势,但该算法在迭代过程中容易陷入局部最优。近年来,一些研究人员开始通过设计一些加权策略对PSO算法进行改进,但这些算法只适用于连续的搜索空间,不能直接适用于求解离散空间的寻优问题[16]。因此,Gong等[17]开始对离散粒子群优化(discrete particle swarm optimizer,DPSO)算法进行深入研究,提出了一种标准的DPSO算法,用于解决社交网络离散空间的寻优问题。随后,Tang和Liu等[18-19]开始对标准的DPSO算法进行改进,并将其用于识别社交网络中具有影响力的关键节点。在谣言传播控制方面,Liu等[19]提出了一种基于进化搜索策略的DPSO算法,用于识别社交网络中具有影响力的谣言传播节点。
虚假信息和谣言传播风险评估和感知研究近年来受到了学者们的广泛关注[20-22]。研究人员主要采用传播动力学模型和风险感知因素分析的方式展开深入研究。例如,Zhang等[20]基于改进的谣言传播动力学模型ICSAR(无知者I、信息载体C、信息传播者S、倡导者A、移除者R)和动态的个人活动轨迹数据,建立了谣言传播动态时空综合风险评估模型,得到社交网络中谣言传播风险分布图。洪巍等[21]选取社交网络中关于食品安全主题的谣言作为研究对象,重点针对谣言关注度的风险感知影响因素进行深入研究,提出了“谣言−风险感知−关注度”的理论研究框架。
本研究的创新点主要包括:
1)构建了一种用户传播风险划分模型,该模型能够根据用户传播虚假信息的行为维度特征、时间维度特征和内容维度特征,实现对具有不同传播风险程度的用户自动划分。
2)提出了一种基于改进DPSO的虚假信息传播关键节点选取方法,用于从具有特定传播风险的用户集合中选取出具有影响力的关键传播节点,使得传播控制效果达到最大化。
1. 相关工作
近年来,国内外研究学者主要通过采用贪心算法和元启发式算法选取社交网络中合适的关键用户节点,并对这些关键的用户节点进行阻塞,从而实现虚假信息和谣言的大规模传播和控制。
1.1 贪心算法
贪心算法作为一种传统的关键节点选取方法,受到研究人员的广泛关注。例如,Kempe等[23]提出了一种爬山(hill-climb, HC)算法,该算法能够用于识别社交网络中具有影响力的前K个关键节点。Leskovec等[8]通过利用子模块特性开发了一个有效的贪心算法CELF(cost-effective lazy forward)。Goyal等[9]通过对CELF算法进行优化,提出了CELF++算法用于识别具有影响力的关键节点。Taherinial等[24]根据网络中的核心节点组成最小跨越节点集合,使用蒙特卡罗仿真估计最小跨越节点集合的传播影响力。
1.2 元启发式算法
近年来,相关学者开始针对一些元启发式算法展开研究。例如,Tang等[18]设计了一种基于网络拓扑结构的局部搜索策略,并对DPSO算法进行改进,从而识别前k个具有影响力的关键节点。Chen等[4]设计了一种具有自适应维数选择机制的蚁群优化算法,提出了一种多目标优化模型,用于识别社交网络中关键传播者。图1给出OSNs虚假信息传播控制示意图。
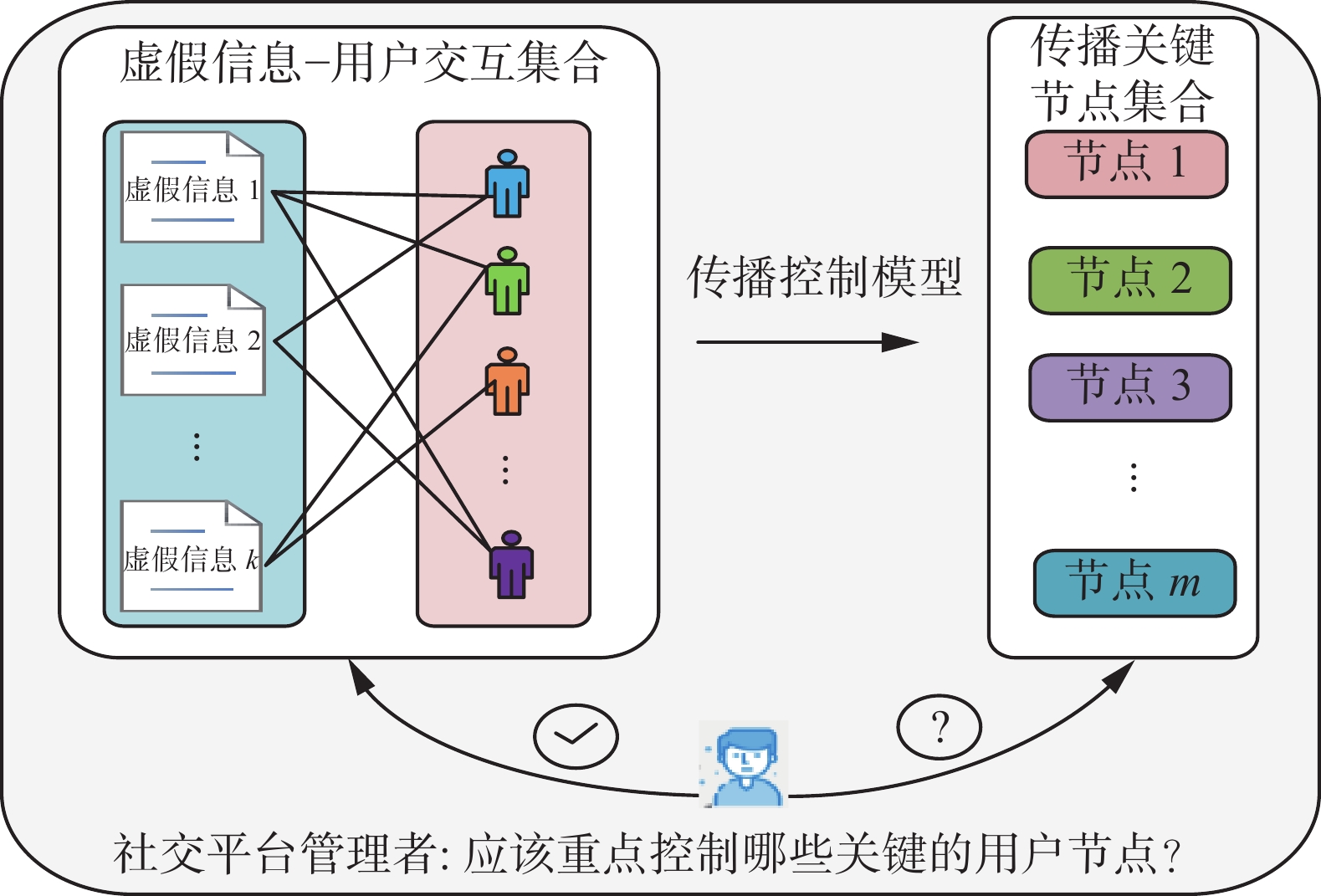 图 1 OSNs虚假信息传播控制示意Fig. 1 Schematic diagram of OSNs disinformation diffusion control
图 1 OSNs虚假信息传播控制示意Fig. 1 Schematic diagram of OSNs disinformation diffusion control 下载:
全尺寸图片
下载:
全尺寸图片
2. 相关定义与解决方案
2.1 相关定义
定义1[15] 社会情境Socialsitu(t)={obj, ID, d, A, E, T}t,其中,obj指社交客体,ID指用户所属的群组和角色,d指用户的意愿,A指用户的行为集合,E指用户所处的环境,T指受众实体的类型。
定义2 用户历史传播虚假信息对应的集合
$ G_F^{{u_i}} = \left\{ {(F,{u_i})|F = \{ {f_1},{f_2}, \cdots ,{f_n}\} ,{u_i} \in U} \right\} $ 。这里$ G_F^{{u_i}} $ 指用户ui传播虚假信息组成的序列F,U指社交网络中用户的集合,虚假信息$ {f_n} = \{ {w_1},{w_2}, \cdots ,{w_{{n_m}}}\} $ ,$ {w_{{n_m}}} $ 表示虚假信息fn中的第nm个单词。定义3 虚假信息传播路径序列集合P={p(f1), p(f2), …, p(fn)},这里p(fn)=<(u0,Socialsitu(t0)),(u1,Socialsitu(t1)),…,(uk,Socialsitu(tk))>。
定义4 用户传播虚假信息的历史行为集合
$B = \left\{ {({a_i},{b_i},{c_i},{u_i},\Delta \left. {t)} \right|{u_i} \in U,\Delta t \in \varphi } \right\}$ 。其中$ {a_i} $ 、$ {b_i} $ 和$ {c_i} $ 分别指在$ \Delta t $ 时间段内用户$ {u_i} $ 分享、点赞和评论虚假信息的数量。定义5 虚假信息传播控制效果L(S)。选取局部影响估计子(local influence estimation, LIE)[17]作为评估虚假信息传播关键节点集合S在独立级联(independent cascade, IC)模型2-hop区域内的传播控制效果。LIE函数的表达式如下
$$ \begin{gathered} {{L}}(S) = {\sigma _0}\left( S \right) + \sigma _1^*\left( S \right) + {{\tilde \sigma }_2}\left( S \right) = \\ {\text{ |}}S{\text{|}} + \left(1 + \frac{1}{{\left| {N_s^{(1)}\backslash S} \right|}}\sum\limits_{u \in N_s^{(2)}\backslash S} {p_u^*d_u^*} \right)\sum\limits_{i \in N_S^{(1)}\backslash S} {\left(1 - \mathop \prod \limits_{(i,j) \in E,j \in S} (1 - {p_{ij}})\right)} \end{gathered} $$ (1) 式中:
$ {\sigma _0}\left( S \right) $ 表示S中节点数量;$ \sigma _1^*\left( S \right) $ 和$ {\tilde \sigma _2}\left( S \right) $ 分别表示1-hop和2-hop区域期望影响传播值;$ N_s^{(1)} $ 和$ N_s^{(2)} $ 表示S中节点在1-hop和2-hop区域的邻居集合;$ p_u^* $ 表示$ N_s^{(2)}\backslash S $ 中节点u在传播模型中恒定的激活概率;$ d_u^* $ 表示$ N_s^{(2)}\backslash S $ 中节点u在$ N_s^{(1)} $ 和$ N_s^{(2)} $ 中边数;E表示节点之间的边集合;pij表示虚假信息传播概率。2.2 用户传播风险划分模型
本节首先对用户传播特征进行提取,并通过自注意力机制实现特征的嵌入表示;其次,使用改进的无监督聚类算法K-Means++,对上述用户传播特征嵌入向量进行聚类划分。最后,假定传播虚假信息影响力越大的簇,其对应的用户传播风险等级越高。根据每一个簇中包含的传播特征向量,得到其对应的用户节点集合,进而计算这些用户节点对应的LIE值。若上述得到的簇对应的LIE值越大,则其对应的用户集合传播风险等级越高。图2给出具体的用户传播风险划分流程图。
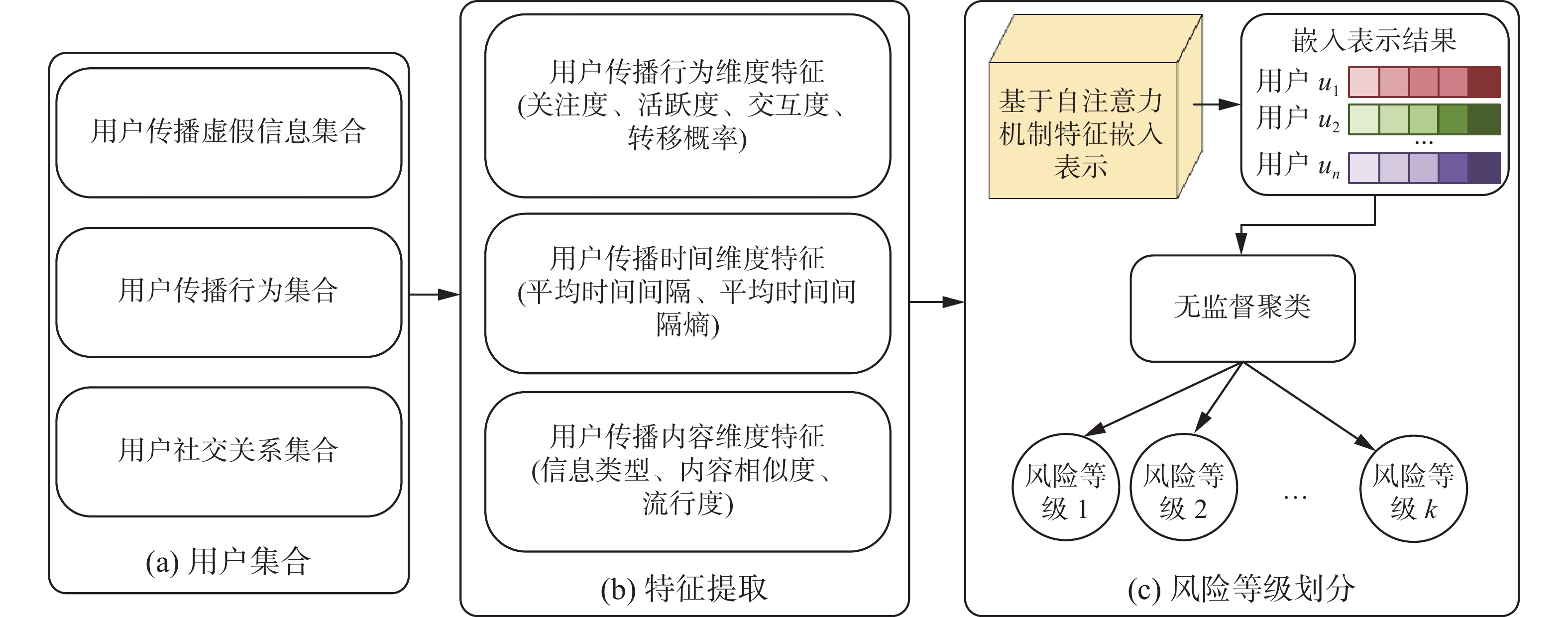 图 2 用户传播风险划分流程Fig. 2 Flow chart of user dissemination risk division下载:
全尺寸图片
图 2 用户传播风险划分流程Fig. 2 Flow chart of user dissemination risk division下载:
全尺寸图片
2.2.1 基于自注意力机制的用户传播特征嵌入表示
用户行为维度特征包括用户传播虚假信息的活动关注度、活跃度、交互度和转移概率。该维度的特征具体描述如下。
1)用户活动关注度:用户活动关注度能够从整体上度量用户对虚假信息的关注程度,具体定义如下
$$ A\left( {{u_i}} \right) = \frac{{M_{{u_i}}^{({\rm{RT}})} + M_{{u_i}}^{({\rm{like}})} + M_{{u_i}}^{({\rm{RV}})}}}{{\Delta T \times \dfrac{1}{N}\displaystyle\sum\limits_{i = 1}^N {\left(M_{{u_i}}^{({\rm{RT}})} + M_{{u_i}}^{({\rm{like}})} + M_{{u_i}}^{({\rm{RV}})}\right)} }} $$ (2) 式中:
$ M_{{u_i}}^{({\rm{RT}})} $ 、$ M_{{u_i}}^{({\rm{like}})} $ 和$ M_{{u_i}}^{({\rm{RV}})} $ 分别表示用户在$ \Delta T $ 时间区间内对虚假信息的分享数量、点赞数量和评论数量,N表示传播虚假信息的用户总数。2)用户传播虚假信息的活跃度:用户在特定时间内转发虚假信息数量,能够准确地反映用户的活跃程度,具体定义为[25]
$$ R\left( {{u_i}} \right) = \frac{{n_2^{{u_i}}}}{{n_1^{{u_i}}}} $$ (3) 式中:
$ n_2^{{u_i}} $ 表示用户$ {u_i} $ 在$ \Delta T $ 时间段内转发虚假信息帖子的总数量;$ n_1^{{u_i}} $ 表示用户$ {u_i} $ 在$ \Delta T $ 时间区间内转发所有帖子的总数量。3)用户传播虚假信息的交互度:用户的交互度是以在一定时间段内用户传播虚假信息的数量为基数,以用户的好友数作为覆盖指数,具体定义如下
$$ I({u_i}) = {(f_{rr}^{})^{{\rm{lg}}\left(\left| {{N^{{\rm{out}}}}({u_i})} \right| + 1\right)}} $$ (4) 式中:
${f_{rr}}^{} = \dfrac{{n_2^{{u_i}}}}{{\Delta T}}$ ,$ n_2^{{u_i}} $ 表示用户$ {u_i} $ 在$ \Delta T $ 时间区间内转发虚假信息帖子的总数量;${N^{{\rm{out}}}}({u_i})$ 表示用户$ {u_i} $ 的好友数量。4)用户传播虚假信息的转移概率:根据随机过程中状态转移概率的定义,结合虚假信息传播的行为模式,给出用户传播虚假信息的转移概率,具体表示为
$$ {P}\left({{u}}_{{i}}\right)=\frac{{\displaystyle \sum _{{t}}\left\{{X(t+1)=j,X(t)=i}\right\}}}{{\displaystyle \sum _{{t}}{X(t)=i}}}{,}{t}\in {ΔT} $$ (5) 式中:
$\displaystyle\sum\limits_t {X(t) = i}$ 表示用户处于状态i的总数;$\displaystyle\sum\limits_t {\left\{ {X(t + 1) = j,X(t) = i} \right\}}$ 表示在t时刻用户处于状态i,在t+1时刻处于状态j的总数。用户时间维度特征包括用户传播虚假信息的平均时间间隔和时间间隔熵。该维度的特征具体描述如下。
1)用户传播虚假信息的平均时间间隔。用户传播虚假信息的平均时间间隔由发布者发布信息时间和传播者传播信息时间决定,具体定义如下:
$$ T({u_i}) = \frac{1}{{n_2^{{u_i}}}}\sum\limits_{k = 1}^K {\left(t_1^{\left( k \right)} - t_0^{(k)}\right)} $$ (6) 式中
$ t_1^{(k)} $ 和$ t_0^{(k)} $ 分别表示用户$ {u_i} $ 传播第k条信息的时间及该信息对应的发布时间。2)用户传播虚假信息的时间间隔熵。时间间隔熵能够准确反应社交网络中用户行为在时间上的分布规律,具体表示为[26]
$$ H\left( {{u_i}} \right) = - \sum\limits_{i = 1}^{{n_T}} {p(\Delta {t_i}){{\lg }}(p(\Delta {t_i}))} $$ (7) 式中:
$p(\Delta {t_i}) = \dfrac{{{n_{\Delta {t_i}}}}}{{\displaystyle\sum\limits_{k = 1}^{{n_T}} {{n_{\Delta {t_k}}}} }}$ ,$ {n_{\Delta {t_i}}} $ 表示用户在第i个时间间隔$ \Delta {t_i} $ 内传播虚假信息的数量。用户传播内容维度特征包括用户传播虚假信息类型、流行度和内容相似度。该维度的特征具体描述如下。
1)虚假信息类型。虚假信息通常以文本或文本和图片相结合的形式存在于社交网络中,社交用户通常更倾向于传播带有图片或URL的虚假信息[27],具体表达式如下
$$ C({u_i}) = \frac{{\left| {{n_{{u_i}}} p} \right| + \left| {{n_{{u_i}}} r} \right|}}{{\left| {{n_{{u_i}}}} \right|}} $$ (8) 式中:
$ \left| {{n_{{u_i}}} p} \right| $ 和$ \left| {{n_{{u_i}}} r} \right| $ 分别表示用户ui传播虚假信息中包含图片的虚假信息数量和包含URL的虚假信息数量;$ \left| {{n_{{u_i}}}} \right| $ 表示用户ui传播包含所有虚假信息类型的总数量。2)虚假信息的流行度。社交网络中谣言和虚假信息的传播过程类似于物理学领域放射性元素半衰期过程[28]。因此,根据放射性元素半衰期的定义和2.1节的定义2,将虚假信息流行度定义为
$$ K({u_i}) = \sum\limits_{i = 1}^n \left(D({f_i},t) \times {{(1/2)}^{\tfrac{{t - {t_0}}}{\gamma }}} \right) $$ (9) 式中:D(fi,t)表示虚假信息fi从发布时刻t0到当前时刻t的传播总数量;
${(1/2)^{\tfrac{{t - {t_0}}}{\gamma }}}$ 表示虚假信息流行度的半衰期函数;$ \gamma $ 表示正则化参数。3)虚假信息的内容相似度。为了准确衡量用户之间传播虚假信息内容的相似度,给出相似度具体定义:
$$ S({u_i},v) = \sum\limits_{v \in {N^{({u_i})}}} {J({u_i},v)} $$ (10) 式中:
$J({u_i},v) = \dfrac{{{{\boldsymbol{V}}_i} \cdot {{\boldsymbol{V}}_j}}}{{\left\| {{{\boldsymbol{V}}_i}} \right\|\left\| {{{\boldsymbol{V}}_j}} \right\|}}$ ;这里$ {N^{({u_i})}} $ 表示用户ui的邻居用户集合;Vi和Vj分别表示运用Doc2vec算法[29]得到用户ui和邻居用户v对应的d维向量。综上,首先分别对用户行为维度、时间维度和内容维度特征进行建模,具体表示如下
$$ {f_{{\rm{behavior}}}}({u_i}) = A\left( {{u_i}} \right) \times R\left( {{u_i}} \right) \times I({u_i}) \times P\left( {{u_i}} \right) $$ (11) $$ {f_{{\rm{time}}}}({u_i}) = T({u_i}) \times H\left( {{u_i}} \right) $$ (12) $$ {f_{{\rm{content}}}}({u_i}) = C({u_i}) \times K({u_i}) \times S({u_i},v) $$ (13) 然后通过嵌入层将每个用户对应的上述维度特征进行嵌入表示,并输入到全连接层。根据加性注意力机制[30],将每个用户对应特征的权重系数表示为
$$ \alpha _p^{\left( {{u_i}} \right)} ={\rm{ Softmax}}{\left( {{{\boldsymbol{w}}^{\rm{T}}}{\rm{tanh}}({\boldsymbol{W\tilde H}})} \right)^{\rm{T}}} $$ (14) 式中:
${\boldsymbol{w}} \in {{\bf{R}}^{{\varepsilon _2} \times 1}}$ ,$ {\boldsymbol{W}} \in {{\bf{R}}^{{\varepsilon _2} \times {\varepsilon _1}}} $ ,${\rm{Softmax}}( \cdot )$ 和${\rm{ tanh}}( \cdot )$ 指激活函数。进而通过自注意力机制学习每个用户对应的特征,得到其特征嵌入表示$ {\boldsymbol{r}}_p^{({u_i})} $ 。最后,构建全连接层并将每个用户所有特征的嵌入向量进行拼接,在输出层得到用户ui所有特征的嵌入表示向量$ {{\boldsymbol{r}}^{({u_i})}} $ 。2.2.2 基于改进K-Means++的用户传播风险等级划分
标准的K-Means算法通常采用随机的方式选取初始的簇中心,因此如果初始簇中心的选取不合适,则容易导致算法陷入局部最优。为了有效地克服上述聚类算法存在的不足之处,根据2.2.1节中用户嵌入表示向量
$ {{\boldsymbol{r}}^{({u_i})}} $ ,构建用户集合U的传播特征矩阵$ {{\boldsymbol{R}}^{(U)}} = \{ {{\boldsymbol{r}}^{_{({u_i})}}}|{u_i} \in U\} _{i = 1}^n $ ,并将其作为改进K-Means++聚类算法的输入。该聚类算法首先从传播特征矩阵$ {{\boldsymbol{R}}^{(U)}} $ 中随机选取一个用户特征向量作为初始的簇中心,计算剩余用户对应的特征向量与簇中心之间的最短距离$ D({{\boldsymbol{r}}^{({u_i})}}) $ 。然后,从传播特征矩阵$ {{\boldsymbol{R}}^{(U)}} $ 中选取某一个用户特征向量作为下一个簇中心,并通过以下方式计算其对应的概率值$ p({{\boldsymbol{r}}^{({u_i})}}) $ ,直至得到第k个初始的簇中心。最后,通过标准的K-Means算法对用户特征嵌入向量进行聚类,从而得到k个不同的簇。根据每一个簇中包含的传播特征向量,得到其对应的用户节点集合,进而计算这些用户节点对应的LIE值。若上述得到的簇对应的LIE值越大,则其对应的传播风险等级越高。2.3 基于改进离散粒子群优化的控制驱动节点集选取
本节将虚假信息传播控制驱动节点集选取作为一种带约束的优化问题,即在2.2节风险节点等级划分的基础上,通过设计一种改进的DPSO算法,用于从高风险节点集合中筛选出具有重要影响力的关键传播节点,并将其作为控制驱动节点。
2.3.1 粒子位置和速度向量离散化表示和初始化
在DPSO中,粒子i的位置由s维整数向量
$ {{\boldsymbol{X}}_i} $ 进行编码,即$ {{\boldsymbol{X}}_i} = ({x_{i1}},{x_{i2}}, \cdots ,{x_{is}}) $ ,($ i = 1,2, \cdots ,{n_1} $ ),其中xij指高风险节点。粒子i的速度表示为$ {{\boldsymbol{V}}_i} = ({v_{i1}},{v_{i2}}, \cdots ,{v_{is}}) $ ,其中,$ {v_{ij}} \in \{ 0,1\} $ 。当$ {v_{ij}} = 1 $ 时,该处对应的用户节点需要使用其他用户节点进行替换。当$ {v_{ij}} = 0 $ 时,该处对应的用户节点保持不变。粒子i的初始速度向量$ {{\boldsymbol{V}}_i} = {\boldsymbol{0}} $ ,初始位置向量$ {{\boldsymbol{X}}_i} $ 由基于度和K-壳的启发式算法(算法1)生成。算法1中$ \hat D({x_{ij}}) $ 指节点xij的度k(xij)和改进标准K-壳$ k_s^*({x_{ij}}) $ 的组合,具体表示为$$ \hat D({x_{ij}}) = k({x_{ij}}) + k_s^*({x_{ij}}) $$ (15) 式中:k(xij)指节点xij的度;
$ k_s^*({x_{ij}}) $ 指改进的标准K-壳,即$k_s^*({x_{ij}}) = {k_s}({x_{ij}}) + \dfrac{{p({x_{ij}})}}{{\mathop {\max }\limits_k q({x_{ik}}) + 1}}$ ;$ {k_s}({x_{ij}}) $ 表示节点xij的标准K-壳值;q(xik)表示节点xik在K-壳分解过程的阶段总数;p(xij)表示节点xij在移除阶段的次序。受万有引力定律的启发,将节点$ \hat D $ 值作为其质量,将网络中2个节点之间的最短距离作为它们的距离,则虚假信息传播的高风险用户节点xij的度和K-壳通过引力模型可进一步表示为[31]$$ \hat M({x_{ij}}) = \sum\limits_{j \ne k,d\left( {{x_{ij}},{x_{ik}}} \right) \leqslant R} {\frac{{\hat D({x_{ij}})\hat D({x_{ik}})}}{{{d^2}({x_{ij}},{x_{ik}})}}} $$ (16) 式中:
$ d({x_{ij}},{x_{ik}}) $ 表示节点xij和xik之间的最短距离;R表示截断半径。算法1 基于度和K-壳的粒子位置向量初始化
输入 种群个数n1,种子节点个数d,传播虚假信息的高风险节点集合M,截断半径R
输出 粒子的初始位置向量X
1)Begin
2)for i=1:n1 do
3)根据式(17)计算
$ {{\boldsymbol{X}}_i} $ 中节点$ \hat D $ ($ {{\boldsymbol{X}}_i} $ )4)根据式(18)计算
$ {{\boldsymbol{X}}_i} $ 中节点$ \hat M $ ($ {{\boldsymbol{X}}_i} $ )5)
$ {{\boldsymbol{X}}_i} $ $ \leftarrow $ ($ {{\boldsymbol{X}}_i} $ )6)for all
$ {x_{ij}} \in {{\boldsymbol{X}}_i} $ do7) if r(xij)>1/2 then // r(xij)表示
$ {{\boldsymbol{X}}_i} $ 中xij位置对应的[0,1]之间随机数8)xij
$ \leftarrow $ l(xij,M) // l表示将xij用高风险节点集合M中其他节点进行代替9)endif
10)endfor
11)endfor
12)End
2.3.2 粒子位置和速度向量更新规则的改进
粒子的速度向量使得粒子位置朝着更优的方向前进,标准的粒子速度向量更新规则表示如下[17]
$$ \begin{split} &{{\boldsymbol{V}}_i}(l + 1) \leftarrow H\left( w \times {{\boldsymbol{V}}_i}(l) + {c_1} \times {r_1} \times \left( {{{\boldsymbol{E}}_i}(l){ \cap _{(1)}}{{\boldsymbol{X}}_i}(l)} \right) +\right. \\ &\qquad\qquad \left. {c_2} \times {r_2} \times \left( {{\boldsymbol{B}}(l){ \cap _{(1)}}{{\boldsymbol{X}}_i}(l)} \right) \right) \end{split} $$ (17) 式中:l表示迭代次数;w表示惯性权重;c1和c2分别表示认知加速系数和社会加速系数;r1和r2为[0,1]的随机数;决策函数
$ H( \cdot ) $ 用于确定$ {{\boldsymbol{V}}_i} $ 中的元素$ {v_{ij}} \in \{ 0,1\} $ ;$ { \cap _{(1)}} $ 表示逻辑相似交叉运算符。算法2 虚假信息传播控制算法
输入 用户集合
$ U = \{ {u_1},{u_2}, \cdots ,{u_{\left| U \right|}}\} $ ,虚假信息集合F。用户历史传播虚假信息集合
$G_F^{{u_i}} = \left\{ (F,{u_i})|F = \right. \left.\{ {f_1},{f_2}, \cdots ,{f_n}\} ,{u_i} \in U \right\}$ ,用户历史行为集合$B = \{ {a_i}, {b_i}, {c_i},{u_i},\Delta t\left| {{u_i} \in U,\Delta t \in \varnothing } \right.\}$ 。虚假信息传播路径序列集合P={p(f1), p(f2),…,p(fn)},聚类个数k,传播概率p
输出 控制驱动节点集合S
1)Begin
2)控制驱动节点集合S初始化
$S = \varnothing$ 3)for each
$ {u_i} \in U $ 且i$ \leftarrow $ 1 to$ \left| U \right| $ do4)根据式(11)计算用户ui传播行为维度特征
$ {f_{{\rm{behavior}}}}({u_i}) $ 5)根据式(12)计算用户ui传播时间维度特征
$ {f_{{\rm{time}}}}({u_i}) $ 6)根据式(13)计算用户ui传播内容维度特征
$ {f_{{\rm{content}}}}({u_i}) $ 7)计算用户ui对应的特征嵌入表示向量
$ {{\boldsymbol{r}}^{({u_i})}} $ 8)endfor
9)生成用户集合U的传播特征
$ {{\boldsymbol{R}}^{(U)}} $ 10)生成初始的簇中心集合C
11)通过标准的K-means算法生成高风险用户节点集合M
12)根据集合M和改进的自适应加权DPSO算法生成控制驱动节点
13)对控制驱动节点进行筛选,生成控制驱动节点集合S
14)End
由于上述标准粒子速度向量更新规则中认知加速系数c1和社会加速系数c2为常数,在算法迭代过程中不能根据粒子个体当前的位置与其局部最优位置(Pbest)和群体全局最优位置(Gbest)的距离进行自适应地调整。本研究基于Sigmoid函数设计了一种自适应加权更新策略,具体表示如下
$$ \begin{split} &{{\boldsymbol{V}}_i}(l + 1) \leftarrow H( w \times {{\boldsymbol{V}}_i}(l) + {c_{{g_{pi}}}}(l) \times {r_1} \times \left( {{{\boldsymbol{E}}_i}(l){ \cap _{(1)}}{{\boldsymbol{X}}_i}(l)} \right) + \\ &\qquad\qquad {c_{{g_{gi}}}}(l) \times {r_2} \times \left( {{\boldsymbol{B}}(l){ \cap _{(1)}}{{\boldsymbol{X}}_i}(l)} \right) ) \\[-10pt] \end{split} $$ (18) 式中,认知加速系数
$ {c_{{g_{pi}}}}(l) $ 和社会加速系数$ {c_{{g_{gi}}}}(l) $ 分别表示为$$ {c_{{g_{pi}}}}(l) = F\left( {{g_{pi}}(l)} \right) = \frac{{{b_{}}}}{{1 + {{\rm{e}}^{ - {a_{}} \times {g_{pi}}(l)}}}} + {c_{}} $$ (19) $$ {c_{{g_{gi}}}}(l) = F\left( {{g_{gi}}(l)} \right) = \frac{b}{{1 + {{\rm{e}}^{ - a \times {g_{gi}}(l)}}}} + {c_{}} $$ (20) 式中:
$ F( \cdot ) $ 指自适应加权更新函数;参数a指该函数曲线的陡度;参数b指该曲线的峰值;参数c为常数。此外,在标准的Jaccard系数定义基础上,给出DPSO中粒子i的位置$ {{\boldsymbol{X}}_i} $ 分别与其Ei和群体B距离的定义,具体表示如下$$ {g_{pi}}(l) = 1 - \frac{{|{{\boldsymbol{E}}_i}(l){ \cap _{(2)}}{{\boldsymbol{X}}_i}(l)|}}{{|{{\boldsymbol{E}}_i}(l) \cup {{\boldsymbol{X}}_i}(l)|}} $$ (21) $$ {g_{gi}}(l) = 1 - \frac{{|{\boldsymbol{B}}(l){ \cap _{(2)}}{{\boldsymbol{X}}_i}(l)|}}{{|{\boldsymbol{B}}(l) \cup {{\boldsymbol{X}}_i}(l)|}} $$ (22) 式中:
$ |{{\boldsymbol{E}}_i}(l){ \cap _{(2)}}{{\boldsymbol{X}}_i}(l)| $ 表示$ {{\boldsymbol{E}}_i}(l) $ 与$ {{\boldsymbol{X}}_i}(l) $ 中相同元素的个数;$ \left| {{\boldsymbol{B}}(l) \cup {{\boldsymbol{X}}_i}(l)} \right| $ 表示$ {\boldsymbol{B}}(l) $ 与$ {{\boldsymbol{X}}_i}(l) $ 中所有不同元素的个数。粒子对应位置的更新规则可表示为
$$ {{\boldsymbol{X}}_i}(l + 1) \leftarrow {{\boldsymbol{X}}_i}(l) \oplus {{\boldsymbol{V}}_i}(l) $$ (23) 式中,
$ {{\boldsymbol{X}}_i}(l) \oplus {{\boldsymbol{V}}_i}(l) = {{\boldsymbol{\tilde X}}_i}(l) = \left( {{{\tilde x}_{i1}},{{\tilde x}_{i2}}, \cdots ,{{\tilde x}_{id}}} \right) $ ,特别的,$$ {\tilde x_{ij}} = \left\{ {\begin{array}{*{20}{l}} {{x_{ij}},{\text{ }}{\text{ }}{v_{ij}} = 0} \\ {R({x_{ij}},M),{\text{ }}{\text{ }}{v_{ij}} = 1} \end{array}} \right. $$ (24) 这里,
$ R({x_{ij}},M) $ 表示从集合M中随机选取节点代替$ {x_{ij}} $ ,并且确保替换之后Xi中没有重复的节点。2.3.3 适应度函数的选择
在虚假信息传播控制过程中,需要选择合适的适应度函数来评估粒子群优化迭代过程中全局最优位置。本研究选取LIE函数作为适应度函数,并从传播风险节点中选取具有若干个具有影响力的关键节点,使得LIE函数值最大化。图3给出具体改进的自适应加权DPSO流程。
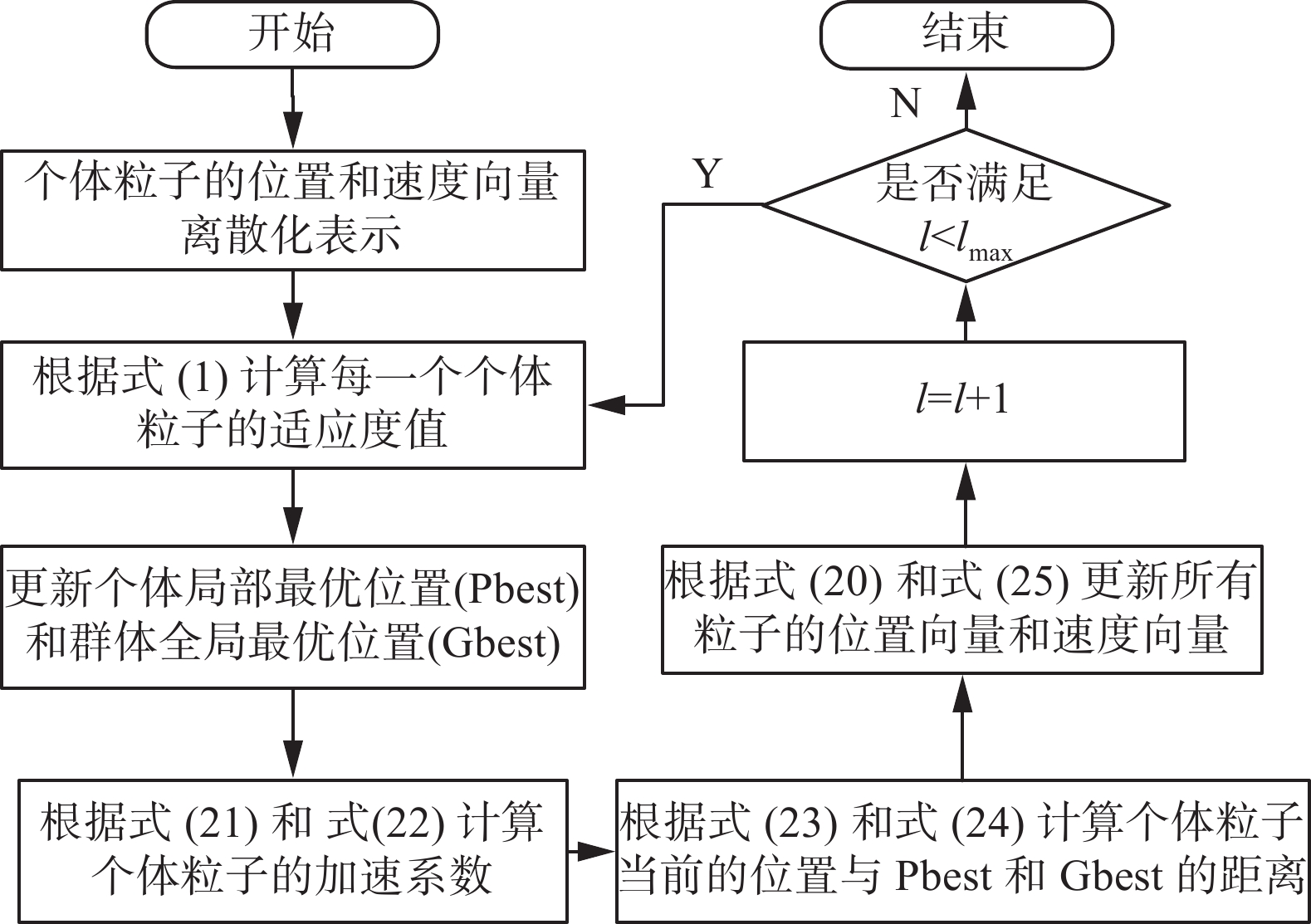 图 3 改进的自适应加权DPSO流程Fig. 3 Improved adaptive weighted DPSO flowchart下载:
全尺寸图片
图 3 改进的自适应加权DPSO流程Fig. 3 Improved adaptive weighted DPSO flowchart下载:
全尺寸图片
2.4 虚假信息传播控制算法描述
虚假信息传播控制算法包括2个方面:1)通过用户传播虚假信息的行为维度、时间维度和内容维度特征,实现不同用户节点风险的划分;2)通过改进的DPSO算法,获取高风险节点集合中具有影响力的关键传播节点。虚假信息传播控制算法的具体描述如算法2所示。
3. 试验设计与结果分析
3.1 试验数据
本研究选取在线社交网络晒科网(又名晒我的) (http://www.shareteches.com)作为试验研究平台[32],该平台包括网站平台和移动应用程序(Android和iOS)。用户通过晒科网App可以随时随地交流和分享前沿的科技话题和附近的科技信息。在晒科网服务器端,通过数据埋点动态实时收集用户访问该平台时产生的社会情境Socialsitu元数据[33]。目前关于社交网络虚假信息和谣言传播控制的相关领域研究,研究人员主要是通过社交网络平台提供的API (application programming interface)接口或者通过采用数据埋点技术获取社交网络平台中相应的元数据。社会情境Socialsitu元数据已经在虚假信息传播分析[34]、社交用户行为模式分析[14]和恶意用户检测[35]等方面得到广泛应用。表1给出该数据集的详细统计信息。
表 1 试验数据集的统计信息Table 1 Statistics of the experimental dataset统计名称 数量 Socialsitu元数据 1460656 Socialsitu六元组元数据 649987 真实信息 36610 虚假信息 10449 用户数量 28857 转发数量 31940 点赞数量 24196 评论数量 7019 3.2 试验结果与分析
3.2.1 传播风险用户聚类个数对虚假信息控制效果的影响
为了探究不同聚类个数对应的虚假信息控制效果,分别计算传播风险用户聚类个数k为3、4、5、6、7时对应的控制效果LIE值。
试验结果如图4所示,随着聚类个数k的增加,虚假信息在传播概率p=0.01和p=0.05时对应传播控制效果LIE值不断减小。这是由于随着聚类个数k的增加,用户节点被更加细粒度的划分为不同的风险等级,并且同一个簇中用户节点在虚假信息传播模式上表现出更强的相似性。本研究选取k取值为3且LIE取得最优值时对应的用户节点集合作为高风险用户节点集合。
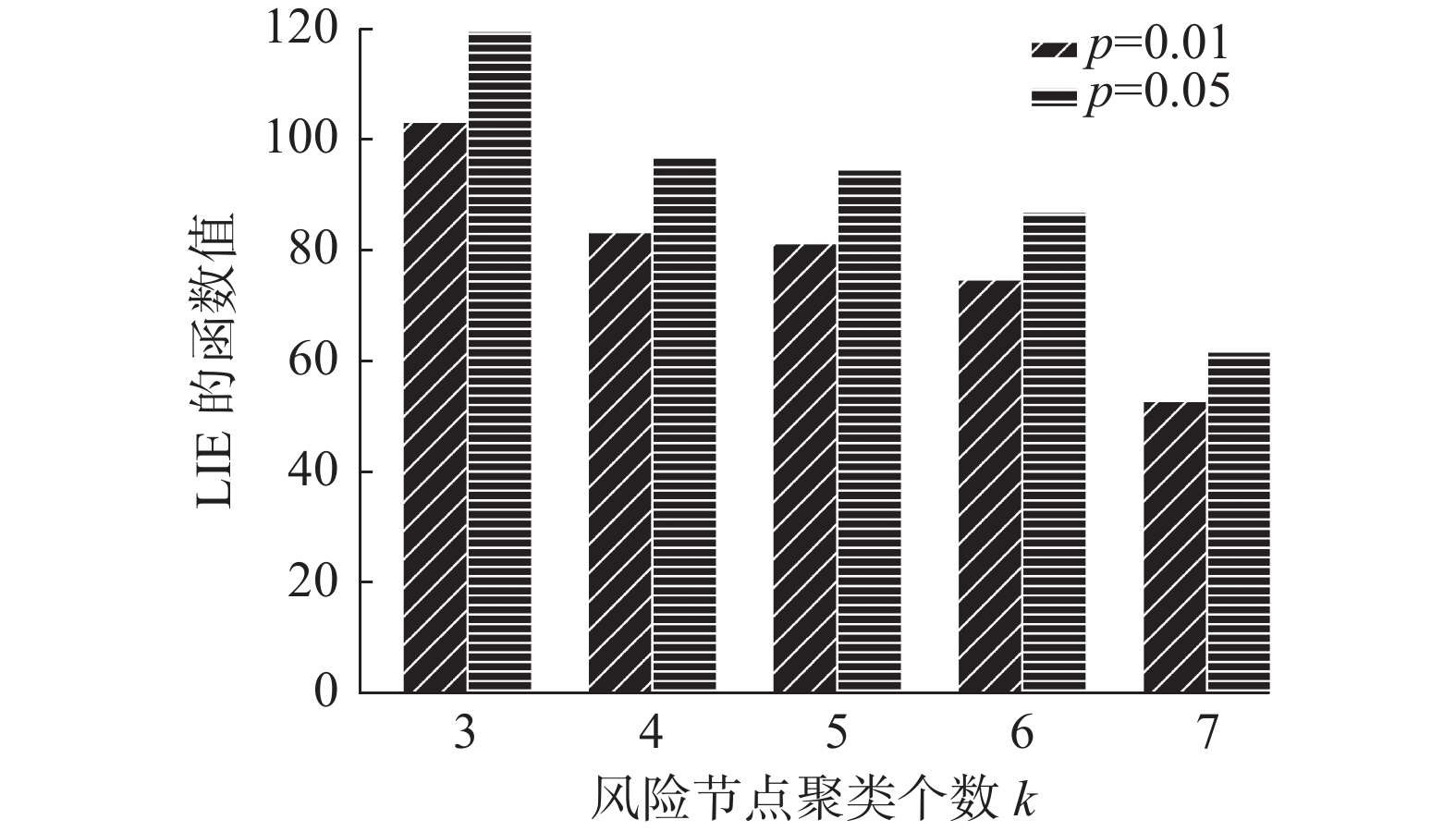 图 4 传播风险节点聚类个数对控制效果的影响Fig. 4 Influence of the number of propagation risk node clusters on the control effect下载:
全尺寸图片
图 4 传播风险节点聚类个数对控制效果的影响Fig. 4 Influence of the number of propagation risk node clusters on the control effect下载:
全尺寸图片
3.2.2 不同离散粒子群优化算法的性能分析
为了证明本研究所提出的融合自适应加权策略DPSO算法的有效性,选取标准的DPSO算法[17]、增强的离散粒子群优化(enhanced local discrete particle swarm optimization,ELDPSO)算法[18]、增强的局部搜索离散粒子群优化(enhanced local search discrete particle swarm optimization,ELSDPSO)算法[19]作为基线方法进行比较。由图5(a)和(b)分析得出,随着控制驱动节点个数的增加,传播控制效果LIE值也在不断增加。图5(a)表明本研究的算法相对于DPSO、ELDPSO和ELSDPSO算法分别平均提高10.76%、7.83%和4.05%。图5(b)表明本研究的算法相对于上述3种算法分别平均提高8.91%、5.01%和2.45%。
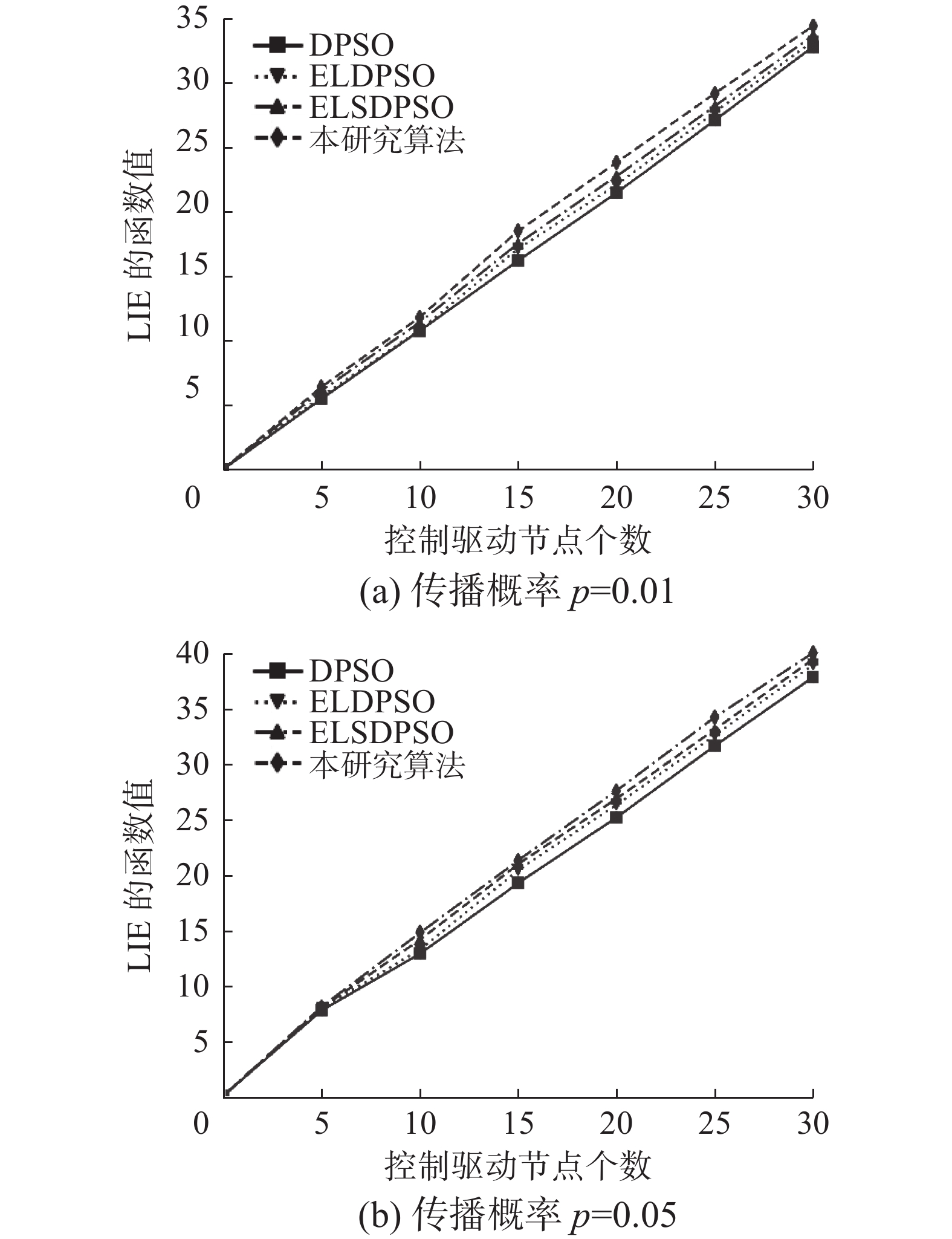 图 5 当传播概率为p=0.01和p=0.05时,4种不同的DPSO算法的性能比较Fig. 5 Performance comparison of three different DPSO algorithms when the propagation probability p=0.01 and p=0.05下载:
全尺寸图片
图 5 当传播概率为p=0.01和p=0.05时,4种不同的DPSO算法的性能比较Fig. 5 Performance comparison of three different DPSO algorithms when the propagation probability p=0.01 and p=0.05下载:
全尺寸图片
3.2.3 不同控制驱动节点选取算法的试验结果对比分析
本研究选取改进的具有成本效益惰性前向选择(CELF++)算法[9]、中介中心度(betweenness centrality,BC)算法[36]、紧密中心度(closeness centrality,CC)算法[37]、PageRank(PR)算法[38]和模拟退火期望传播值(simulated annealing expected diffusion value,SAEDV)算法[7]作为基线方法。
由图6可以发现,在传播概率p=0.01和p=0.05下,本研究所提出算法优于基于中心度的启发式算法和贪心算法CELF++。贪心算法CELF++对应的试验结果仅次于本研究的算法,基于中心度的启发式算法BC和CC对应的试验结果最不理想,这是因为该类算法通常是根据网络拓扑结构特征,选取前s个BC值或CC值最大的节点作为控制驱动节点。
 图 6 当传播概率为p=0.01和p=0.05时,不同控制驱动节点选取算法的性能比较Fig. 6 Performance comparison of different control driven node selection algorithms when the propagation probability p=0.01 and p=0.05下载:
全尺寸图片
图 6 当传播概率为p=0.01和p=0.05时,不同控制驱动节点选取算法的性能比较Fig. 6 Performance comparison of different control driven node selection algorithms when the propagation probability p=0.01 and p=0.05下载:
全尺寸图片
由图7可以发现,在时间复杂度指标上,本研究所提出的算法对应的运行时间优于贪心算法CELF++和启发式算法SAEDV,但是与基于中心性的启发式算法相比,本研究算法需要消耗更长的运行时间。因此,本研究所提出的算法在计算虚假信息传播控制效果和运行时间上得到了很好的权衡。
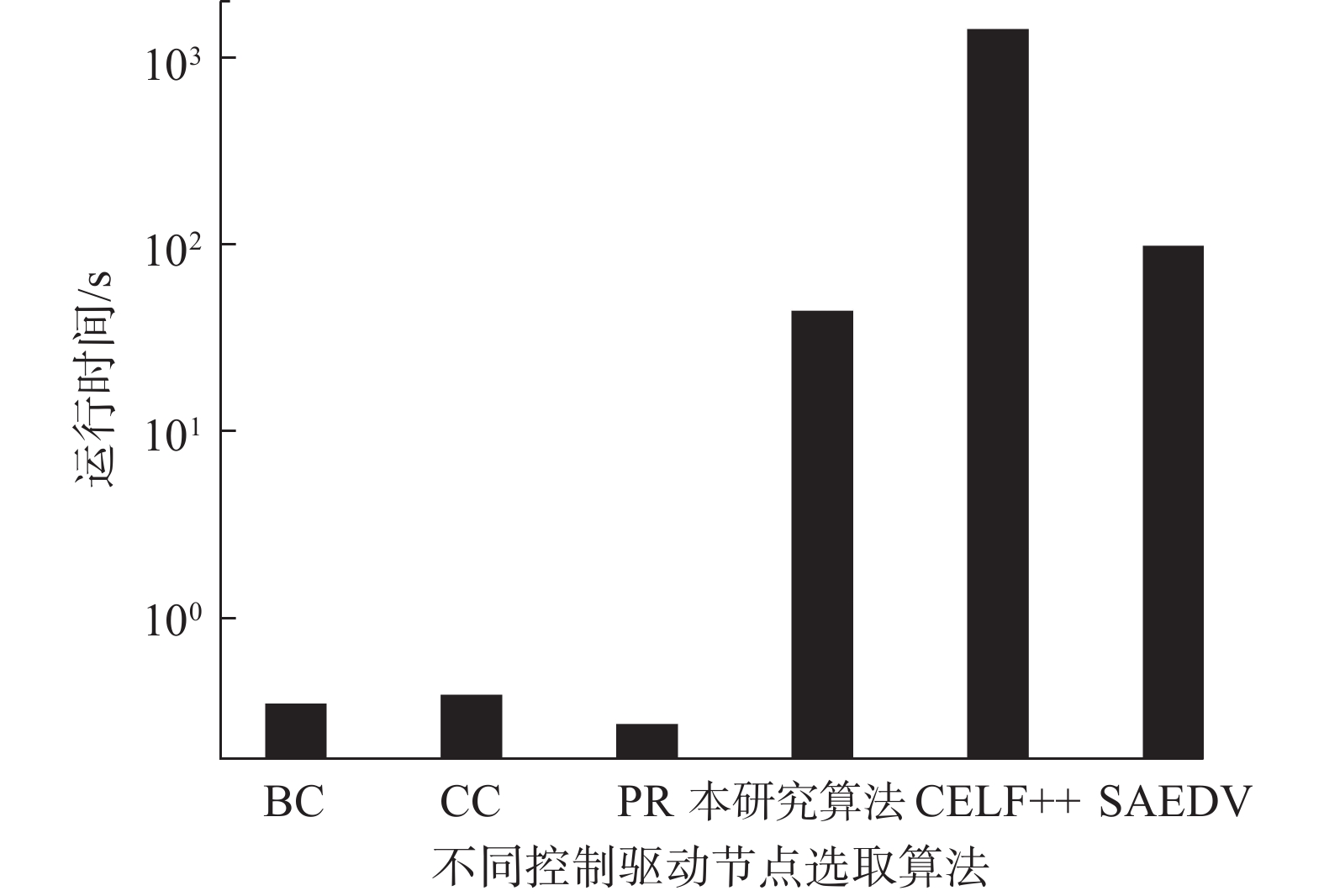 图 7 当传播概率p=0.05时,不同控制驱动节点选取算法的时间复杂度比较Fig. 7 Time complexity comparison of different control driver node selection algorithms when the propagation probability p=0.05下载:
全尺寸图片
图 7 当传播概率p=0.05时,不同控制驱动节点选取算法的时间复杂度比较Fig. 7 Time complexity comparison of different control driver node selection algorithms when the propagation probability p=0.05下载:
全尺寸图片
4. 结束语
本研究提出了一种融合用户传播风险和节点影响力分析的虚假信息传播控制方法DDC-UPRNI。该方法能够准确有效地识别社交网络中虚假信息传播的关键用户节点。社交平台管理者针对这些关键用户节点及时实施“禁言”“封号”等措施,能够大大降低平台的控制成本,从而达到有效控制虚假信息大规模传播的目的。未来,将继续从复杂社会网络和智能控制理论的视角,进一步探究跨平台虚假信息的传播控制方法。
-
图 1 OSNs虚假信息传播控制示意
Fig. 1 Schematic diagram of OSNs disinformation diffusion control
下载:
全尺寸图片
图 2 用户传播风险划分流程
Fig. 2 Flow chart of user dissemination risk division
下载:
全尺寸图片
图 3 改进的自适应加权DPSO流程
Fig. 3 Improved adaptive weighted DPSO flowchart
下载:
全尺寸图片
图 4 传播风险节点聚类个数对控制效果的影响
Fig. 4 Influence of the number of propagation risk node clusters on the control effect
下载:
全尺寸图片
图 5 当传播概率为p=0.01和p=0.05时,4种不同的DPSO算法的性能比较
Fig. 5 Performance comparison of three different DPSO algorithms when the propagation probability p=0.01 and p=0.05
下载:
全尺寸图片
图 6 当传播概率为p=0.01和p=0.05时,不同控制驱动节点选取算法的性能比较
Fig. 6 Performance comparison of different control driven node selection algorithms when the propagation probability p=0.01 and p=0.05
下载:
全尺寸图片
图 7 当传播概率p=0.05时,不同控制驱动节点选取算法的时间复杂度比较
Fig. 7 Time complexity comparison of different control driver node selection algorithms when the propagation probability p=0.05
下载:
全尺寸图片
表 1 试验数据集的统计信息
Table 1 Statistics of the experimental dataset
统计名称 数量 Socialsitu元数据 1460656 Socialsitu六元组元数据 649987 真实信息 36610 虚假信息 10449 用户数量 28857 转发数量 31940 点赞数量 24196 评论数量 7019 -
[1] CHOI D, OH H, CHUN Selin, et al. Preventing rumor spread with deep learning[J]. Expert systems with applications, 2022, 197: 116688. doi: 10.1016/j.eswa.2022.116688 [2] ZHAO Zilong, ZHAO Jichang, SANO Y, et al. Fake news propagates differently from real news even at early stages of spreading[J]. EPJ data science, 2020, 9(1): 7. doi: 10.1140/epjds/s13688-020-00224-z [3] VOSOUGHI S, ROY D, ARAL S. The spread of true and false news online[J]. Science, 2018, 359(6380): 1146–1151. doi: 10.1126/science.aap9559 [4] CHEN Weineng, TAN Dazhao, YANG Qiang, et al. Ant colony optimization for the control of pollutant spreading on social networks[J]. IEEE transactions on cybernetics, 2020, 50(9): 4053–4065. doi: 10.1109/TCYB.2019.2922266 [5] 黄宏程, 赖礼城, 胡敏, 等. 基于严格可控理论的社交网络信息传播控制方法[J]. 电子与信息学报, 2018, 40(7): 1707–1714. doi: 10.11999/JEIT170966 HUANG Hongcheng, LAI Licheng, HU Min, et al. Information propagation control method in social networks based on exact controllability theory[J]. Journal of electronics & information technology, 2018, 40(7): 1707–1714. doi: 10.11999/JEIT170966 [6] JIA Jianfeng, LIU Xuewei, ZHANG Yixin, et al. Rumor propagation controlling based on finding important nodes in complex network[J]. Journal of industrial & management optimization, 2020, 16(5): 2521–2529. [7] JIANG Qingye, SONG Guojie, CONG Gao, et al. Simulated annealing based influence maximization in social networks[C]//Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence. San Francisco: ACM, 2011: 127–132. [8] LESKOVEC J, KRAUSE A, GUESTRIN C, et al. Cost-effective outbreak detection in networks[C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Jose: ACM, 2007: 420–429. [9] GOYAL A, LU Wei, LAKSHMANAN L V S. CELF++: optimizing the greedy algorithm for influence maximization in social networks[C]//Proceedings of the 20th International Conference Companion on World Wide Web. Hyderabad: ACM, 2011: 47–48. [10] LIU Huanli, MA Chuang, XIANG Bingbing, et al. Identifying multiple influential spreaders based on generalized closeness centrality[J]. Physica A:statistical mechanics and its applications, 2018, 492: 2237–2248. doi: 10.1016/j.physa.2017.11.138 [11] LEV T, BEN-GAL I, SHMUELI E. Influence maximization through scheduled seeding in a real-world setting[J]. IEEE transactions on computational social systems, 2022, 9(2): 494–507. doi: 10.1109/TCSS.2021.3109043 [12] SRINIVASAN S, DHINESH BABU L D. A bio-inspired defensive rumor confinement strategy in online social networks[J]. Journal of organizational and end user computing, 2021, 33(1): 47–70. doi: 10.4018/JOEUC.2021010103 [13] CHANG C K. Situation analytics—at the dawn of a new software engineering paradigm[J]. Science China information sciences, 2018, 61(5): 050101. doi: 10.1007/s11432-017-9372-7 [14] ZHANG Zhiyong, SUN Ranran, WANG Xiaoxue, et al. A situational analytic method for user behavior pattern in multimedia social networks[J]. IEEE transactions on big data, 2019, 5(4): 520–528. doi: 10.1109/TBDATA.2017.2657623 [15] 张志勇, 荆军昌, 李斐, 等. 人工智能视角下的在线社交网络虚假信息检测、传播与控制研究综述[J]. 计算机学报, 2021, 44(11): 2261–2282. doi: 10.11897/SP.J.1016.2021.02261 ZHANG Zhiyong, JING Junchang, LI Fei, et al. Survey on fake information detection, propagation and control in online social networks from the perspective of artificial intelligence[J]. Chinese journal of computers, 2021, 44(11): 2261–2282. doi: 10.11897/SP.J.1016.2021.02261 [16] LIU Weibo, WANG Zidong, YUAN Yuan, et al. A novel sigmoid-function-based adaptive weighted particle swarm optimizer[J]. IEEE transactions on cybernetics, 2021, 51(2): 1085–1093. doi: 10.1109/TCYB.2019.2925015 [17] GONG Maoguo, YAN Jianan, SHEN Bo, et al. Influence maximization in social networks based on discrete particle swarm optimization[J]. Information sciences, 2016, 367/368: 600–614. doi: 10.1016/j.ins.2016.07.012 [18] TANG Jianxin, ZHANG Ruisheng, YAO Yabing, et al. Identification of top-k influential nodes based on enhanced discrete particle swarm optimization for influence maximization[J]. Physica A:statistical mechanics and its applications, 2019, 513: 477–496. doi: 10.1016/j.physa.2018.09.040 [19] LIU Zhaoli, QIN Tao, SUN Qindong, et al. SIRQU: dynamic quarantine defense model for online rumor propagation control[J]. IEEE transactions on computational social systems, 2022, 9(6): 1703–1714. doi: 10.1109/TCSS.2022.3161252 [20] ZHANG N, HUANG H, DUARTE M, et al. Risk analysis for rumor propagation in metropolises based on improved 8-state ICSAR model and dynamic personal activity trajectories[J]. Physica A:statistical mechanics and its applications, 2016, 451: 403–419. doi: 10.1016/j.physa.2015.12.131 [21] 洪巍, 王晨雪, 吴林海, 等. 基于保护动机理论的食品安全网络谣言关注度影响因素研究[J]. 系统工程理论与实践, 2022, 42(11): 3121–3138. doi: 10.12011/SETP2021-3088 HONG Wei, WANG Chenxue, WU Linhai, et al. Research on influencing factors of food safety Internet rumor attention based on protection motivation theory[J]. Systems engineering-theory & practice, 2022, 42(11): 3121–3138. doi: 10.12011/SETP2021-3088 [22] 杨洋洋, 谢雪梅. 网络谣言风险测度与治理路径研究[J]. 情报科学, 2021, 39(9): 170–177. YANG Yangyang, XIE Xuemei. Research on risk measurement and governance path of Internet rumors[J]. Information science, 2021, 39(9): 170–177. [23] KEMPE D, KLEINBERG J, TARDOS É. Influential nodes in a diffusion model for social networks[M]//CAIRES L, ITALIANO G F, MONTEIRO L, et al. Automata, Languages and Programming. Berlin: Springer Berlin Heidelberg, 2005: 1127−1138. [24] TAHERINIA M, ESMAEILI M, MINAEI-BIDGOLI B. Optimizing CELF algorithm for influence maximization problem in social networks[J]. Journal of artificial intelligence and data mining, 2022, 10(1): 25–41. [25] XIAO Yunpeng, LI Jinghua, ZHU Yangfu, et al. User behavior prediction of social hotspots based on multimessage interaction and neural network[J]. IEEE transactions on computational social systems, 2020, 7(2): 536–545. doi: 10.1109/TCSS.2020.2969484 [26] GHOSH R, SURACHAWALA T, LERMAN K. Entropy-based classification of ‘retweeting’ activity on twitter[EB/OL]. [2011−06−02](2020−01−01). http://arxiv.org/abs/1106.0346.pdf. [27] FU Boyang, SUI Jie. Multi-modal affine fusion network for social media rumor detection[J]. PeerJ computer science, 2022, 8: e928. doi: 10.7717/peerj-cs.928 [28] XIAO Yunpeng, HUANG Zhen, LI Qian, et al. Diffusion pixelation: a game diffusion model of rumor & anti-rumor inspired by image restoration[J]. IEEE transactions on knowledge and data engineering, 2023, 35(5): 4682–4694. [29] KIM D, SEO D, CHO S, et al. Multi-co-training for document classification using various document representations: TF–IDF, LDA, and Doc2Vec[J]. Information sciences, 2019, 477: 15–29. doi: 10.1016/j.ins.2018.10.006 [30] LIN Zhouhan, FENG Minwei, SANTOS C, et al. A structured self-attentive sentence Embedding[C]//ICLR’2017: Proceedings of the 5th International Conference on Learning Representations. Toulon: OpenReview, 2017. [31] LI Zhe, HUANG Xinyu. Identifying influential spreaders in complex networks by an improved gravity model[J]. Scientific reports, 2021, 11(1): 22194. doi: 10.1038/s41598-021-01218-1 [32] ZHANG Zhiyong, SUN Ranran, ZHAO Changwei, et al. CyVOD: a novel trinity multimedia social network scheme[J]. Multimedia tools and applications, 2017, 76(18): 18513–18529. doi: 10.1007/s11042-016-4162-z [33] JING Junchang, ZHANG Zhiyong, CHOO K K R, et al. Inference of user desires to spread disinformation based on social situation analytics and group effect[J]. IEEE transactions on dependable and secure computing, 2023, 20(3): 1833–1848. doi: 10.1109/TDSC.2022.3165324 [34] JING Junchang, LI Fei, SONG Bin, et al. Disinformation propagation trend analysis and identification based on social situation analytics and multilevel attention network[J]. IEEE transactions on computational social systems, 2023, 10(2): 507–522. doi: 10.1109/TCSS.2022.3169132 [35] 卫新乐, 张志勇, 宋斌, 等. 基于纵向联邦学习的社交网络跨平台恶意用户检测方法[J]. 小型微型计算机系统, 2022, 43(7): 1541–1546. WEI Xinle, ZHANG Zhiyong, SONG Bin, et al. Social networks cross-platform malicious user detection method based on vertical federated learning[J]. Journal of Chinese computer systems, 2022, 43(7): 1541–1546. [36] BRANDES U. On variants of shortest-path betweenness centrality and their generic computation[J]. Social networks, 2008, 30(2): 136–145. doi: 10.1016/j.socnet.2007.11.001 [37] FREEMAN L C. Centrality in social networks conceptual clarification[J]. Social networks, 1978, 1(3): 215–239. doi: 10.1016/0378-8733(78)90021-7 [38] BOLDI P, SANTINI M, VIGNA S. PageRank: functional dependencies[J]. ACM transactions on information systems, 2009, 27(4): 19.

















































































































































