
Recommendation method based on dynamic interest propagation and knowledge graph
-
摘要: 知识图谱推荐作为一种信息过滤方法被广泛应用于电子商务和网络社交等领域,然而多数基于知识图谱的推荐方法未采取合适的策略来解决传播过程中实体语义关联性衰减问题,且单维度建模无法利用知识图谱同时丰富用户和项目表示。针对以上问题提出一种基于动态兴趣传播和知识图谱的推荐方法(recommendation method based on dynamic interest propagation and knowledge graph,RDPKG)。首先,通过传播网络挖掘层级用户兴趣生成用户表示,并采用注意力机制区分不同传播层数下用户兴趣的重要性;然后,通过交叉压缩单元提取知识图谱中的有效信息生成项目表示,并采用多任务学习优化推荐单元和知识图谱嵌入单元;最后,将最终的用户表示和项目表示内积获得交互概率。在推荐系统领域的3种公共数据集上进行对比实验,实验结果表明在点击率预测任务中RDPKG的准确率分别达到85.42%、76.09%和69.39%,优于其他对比方法,充分验证了RDPKG方法的有效性。Abstract: As an information filtering method, knowledge graph recommendation is widely used in the fields of e-commerce and social networking. However, most knowledge graph-based recommendation methods did not adopt appropriate strategies to solve the problem of entity semantic relevance decay during the propagation process. Additionally, single-dimensional modeling could not utilize knowledge graph to enrich user and item representations at the same time. Therefore, we propose RDPKG, a recommendation method based on dynamic interest propagation and knowledge graph. Specifically, RDPKG employs a propagation network to mine user interests of different layers to generate use representation; and applies an attention mechanism to distinguish the importance of user interests under different propagation layers. Then, RDPKG employs a cross-compression unit to extract valid information in the knowledge graph to generate item representation, and applies multi-task learning to optimize the recommendation unit and the knowledge graph embedding unit. Last, RDPKG takes the inner product of the final user representation and the item representation to obtain the interaction probability. Comparative experiments on three real-world public datasets in the field of recommender systems were carried out. The results demonstrate that the accuracy of RDPKG in the click-through rate prediction task has reached 85.42%, 76.09% and 69.39% respectively. RDPKG outperforms other comparison methods, which fully verifies the validity of RDPKG method.
-
网络信息的爆炸式增长为用户提供诸多选择的同时也使用户面临着信息过载问题。为缓解信息过载问题,个性化推荐系统应运而生。在众多推荐算法中,协同过滤(collaborative filtering,CF)[1]算法具有简单、稳定、可解释等特点一直备受关注[2]。然而仅依据用户与项目间交互信息来进行推荐使得协同过滤经常面临数据稀疏性问题。为解决数据稀疏性问题,研究人员开始在推荐中加入不同的辅助信息,例如社交网络[3-4]、项目属性[5]、多媒体信息[6-7]以及上下文信息[8-9]等。
各类辅助信息中,知识图谱(knowledge graph,KG)因包含丰富的语义关系被广泛使用。知识图谱是一种有向信息异构图,其中节点代表实体,有向边代表实体间的关系[10]。将知识图谱中结构化信息扩充到推荐方法中,不仅可以捕获项目间的语义关系,提升模型的项目表达能力,还可以挖掘用户与项目间的细粒度关系,更精准地获取用户兴趣[11]。相比较于协同过滤推荐,基于知识图谱的推荐可以使推荐结果更准确且具有一定的可解释性,因此越来越多基于知识图谱的推荐方法被提出,例如Lyu等[12]提出了知识图谱增强的可解释性推荐,利用外部知识库中的语义知识对用户和项目表示学习。
目前,基于知识图谱的推荐方法主要包括基于路径的方法(path-based methods)、基于嵌入的方法(embedding-based methods)和基于联合的方法(unified methods)[13]。其中基于路径的方法利用实体间的连接模式实现推荐,例如Shi等[14]提出利用加权元路径来识别不同路径属性值并通过评分预测实现推荐;何云飞等[15]提出了一种元路径感知评分协同过滤推荐方法,基于元路径来计算用户或项目间的相似性,并将用户间以及项目间的相似性相乘来获得评分之间的相似性实现推荐;Li等[16]首次将多任务学习引入到基于路径的推荐模型中,采用注意力机制识别元路径中每个成分的重要性,并联合优化推荐和链接预测任务。上述方法实现了对知识图谱结构化信息的有效利用,使推荐结果具有一定的解释性,但需要一定的专业知识来定义元路径的类型和数量,并且设计的元路径无法迁移到不同的领域场景。基于嵌入的方法通过知识图谱嵌入模型对知识图谱中的实体和关系进行表示,进而丰富用户和项目特征,其中图嵌入模型主要分为两类[17]:基于距离的模型,如用于建模多关系数据的嵌入式翻译(translating embeddings for modeling multi-relational data,TransE)[18]、知识解析中的实体与关系嵌入学习(learning entity and relation embeddings for knowledge resolution ,TransR)[19]等;基于语义的匹配的模型,如多关系数据集体学习的三元模型(a three-way model for collective learning on multi-relational data,RESCAL)[20]、知识库中实体与关系的嵌入学习与推理(embedding entities and relations for learning and inference in knowledge bases,DistMult)[21]等。例如Zhang等[22]提出了嵌入推荐系统的协作知识库(collaborative knowledge base embedding for recommender systems,CKE),CKE在协同过滤的基础上使用知识图谱嵌入模型将知识图谱中的项目属性和文本、视觉知识嵌入表示来扩充项目特征的语义信息;Palumbo等[23]通过特定属性的知识图谱嵌入来学习用户与项目的相关性,从而实现物品推荐;Wang等[24]提出了知识图谱增强多任务特征学习推荐方法(multi-task feature learning for knowledge graph enhanced recommendation,MKR),MKR通过图嵌入方法学习实体间关系实现推荐功能的优化;Li等[25]提出了公平感知偏好图嵌入,将用户、项目属性及其相关性知识融入实体表示中,并缓解用户属性在项目上的不公平分布。上述方法有效解决了推荐方法依赖元路径的问题,更易应用于实践,但依赖于知识图谱嵌入模型,且缺少对知识图谱中高阶关系的利用,难以捕捉用户的高阶信息。基于联合的方法有效结合了基于路径的方法与基于嵌入的方法的优点,依靠知识图谱中实体间的连接关系,通过传播实体语义表示挖掘实体间的高阶关系,充分利用知识图谱中的信息实现更好的推荐。基于联合的方法包括基于用户历史行为的方法和基于项目多跳邻居的方法,前者基于用户历史项目在知识图谱中以波纹的形式进行传播,通过融合每层的用户特征得到最终用户特征,例如基于知识图谱传播用户偏好的推荐系统(propagating user preferences on the knowledge graph for recommender systems,RippleNet)[26]、基于注意力增强的知识感知用户偏好建模的推荐系统(attention-enhanced knowledge-aware user preference model for recommendation,AKUPM)[27]、基于注意力的知识图谱嵌入的个性化推荐(attentive knowledge graph embedding for personalized recommendation,RCoLM)[28]等;而基于项目多跳邻居的方法主要是通过聚合目标项目与多跳邻居信息来更新项目特征,例如基于知识图谱卷积推荐系统(knowledge graph convolutional networks for recommender systems,KGCN)[29]、融合知识感知与标签平滑正则化图神经网络的推荐系统(knowledge-aware graph neural networks with label smoothness regularization for recommender systems,KGCN-LS)[30]等。但目前基于联合的方法仍存在一定的局限性,一方面这类方法在向外传播过程中实体语义关联性会随着传播层数的增加而减弱,而多数方法在融合层级信息时并没有采取合适的策略来模拟信息衰减的特性,从而影响模型的表达能力;另一方面多数方法仅单一考虑用户端或项目端,未能充分地利用知识图谱来扩充用户和项目特征的语义信息。
为此,本文针对上述不足提出了一种基于动态兴趣传播和知识图谱的推荐方法(recommendation method based on dynamic interest propagation and knowledge graph,RDPKG)。本文的主要贡献如下:
1)提出了一种动态兴趣传播方法,即采用注意力机制融合用户历史项目生成用户浅层兴趣表示,并基于用户历史项目在知识图谱中向外传播来挖掘用户深层兴趣表示,然后依据原始用户表示与用户兴趣表示的相关程度自适应地生成用户特征向量。
2)提出了一种基于动态兴趣传播和知识图谱的推荐方法,即采用动态兴趣传播方法获得用户特征向量,然后通过交叉压缩单元获得项目特征向量,并采用多任务学习优化推荐单元和知识图谱嵌入单元。
3)本文充分利用用户历史行为和知识图谱,分别从用户和项目视角学习用户和项目特征向量,然后根据用户和项目特征向量的内积预测用户点击项目的概率,在推荐系统领域3种公共数据集上的实验结果表明:本文所提的RDPKG较其他推荐方法,具有较优的推荐性能。
1. RDPKG模型
1.1 问题描述
在为用户推荐项目时, 用户集合和项目集合表示为
$U = \left\{ {{u_1},{u_2}, \cdot \cdot \cdot ,{u_M}} \right\}$ 和$V = \left\{ {{v_1},{v_2}, \cdot \cdot \cdot ,{v_N}} \right\}$ 。根据用户与项目的隐式反馈信息(点击、购买、观看等),用户与项目的交互矩阵定义为$$ {\boldsymbol{Y}} = \left\{ {{y_{uv}}|u \in U,v \in V} \right\} $$ 其中
$$ {y}_{uv}=\left\{\begin{array}{ll}1, & \left(u,v\right)存在交互 \\ 0, & \left(u,v\right)不存在交互 \end{array} \right.$$ 式中当
${y_{uv}} = 1$ 时表示用户$u$ 和项目$v$ 之间存在交互。知识图谱$G$ 由三元组$\left( {h,r,t} \right)$ 组成,其中$h \in E$ 、$t \in E$ 、$r \in R$ 分别表示三元组的头实体、尾实体和实体间的关系,$E$ 和$R$ 分别表示知识图谱$G$ 中的实体和关系集合。给定交互矩阵${\boldsymbol{Y}}$ 和知识图谱$G$ ,本文模型的目标是预测用户对项目的潜在偏好,预测函数为$$ {\hat y_{uv}} = F\left( {u,v|\varTheta ,{\boldsymbol{Y}},G} \right) $$ 式中:
${\hat y_{uv}}$ 为用户$u$ 点击项目$v$ 的概率,$\varTheta$ 为函数$F$ 的参数。1.2 模型概述
RDPKG主要由交叉压缩单元、知识图谱嵌入单元和推荐单元组成,RDPKG框架如图1所示。推荐单元首先通过动态兴趣传播模块提取用户特征向量,然后通过交叉压缩单元提取项目特征向量,最后将用户和项目特征向量输入到预测模块预测用户和项目交互值;知识图嵌入单元首先使用多层结构从三元组中提取头实体和关系的特征,然后将头实体和关系的特征向量作为多层感知机(multilayer perceptron,MLP)的输入得到预测的尾实体,最后通过相似度函数计算三元组得分;交叉压缩单元在推荐单元和知识图谱嵌入单元间建立一种连接纽带,通过项目和实体交换2个单元的潜在信息。
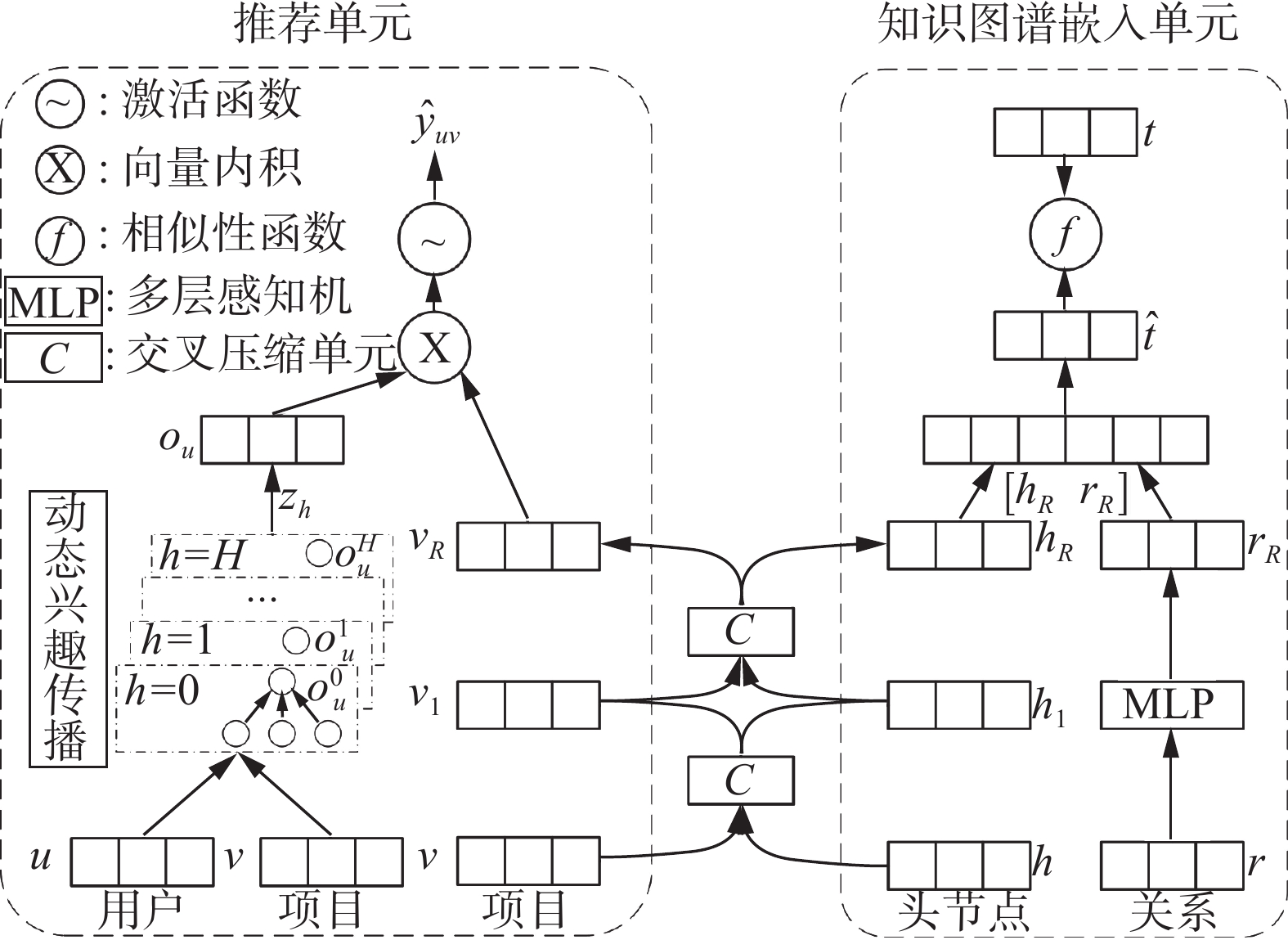 图 1 RDPKG框架Fig. 1 RDPKG framework
图 1 RDPKG框架Fig. 1 RDPKG framework 下载:
全尺寸图片
下载:
全尺寸图片
1.3 交叉压缩单元
为实现推荐单元和知识图谱嵌入单元之间信息共享,本文通过交叉压缩单元在推荐单元和知识图谱嵌入单元之间建立一种连接纽带,自动控制2个单元的交叉知识转移,交叉压缩单元结构如图2所示。
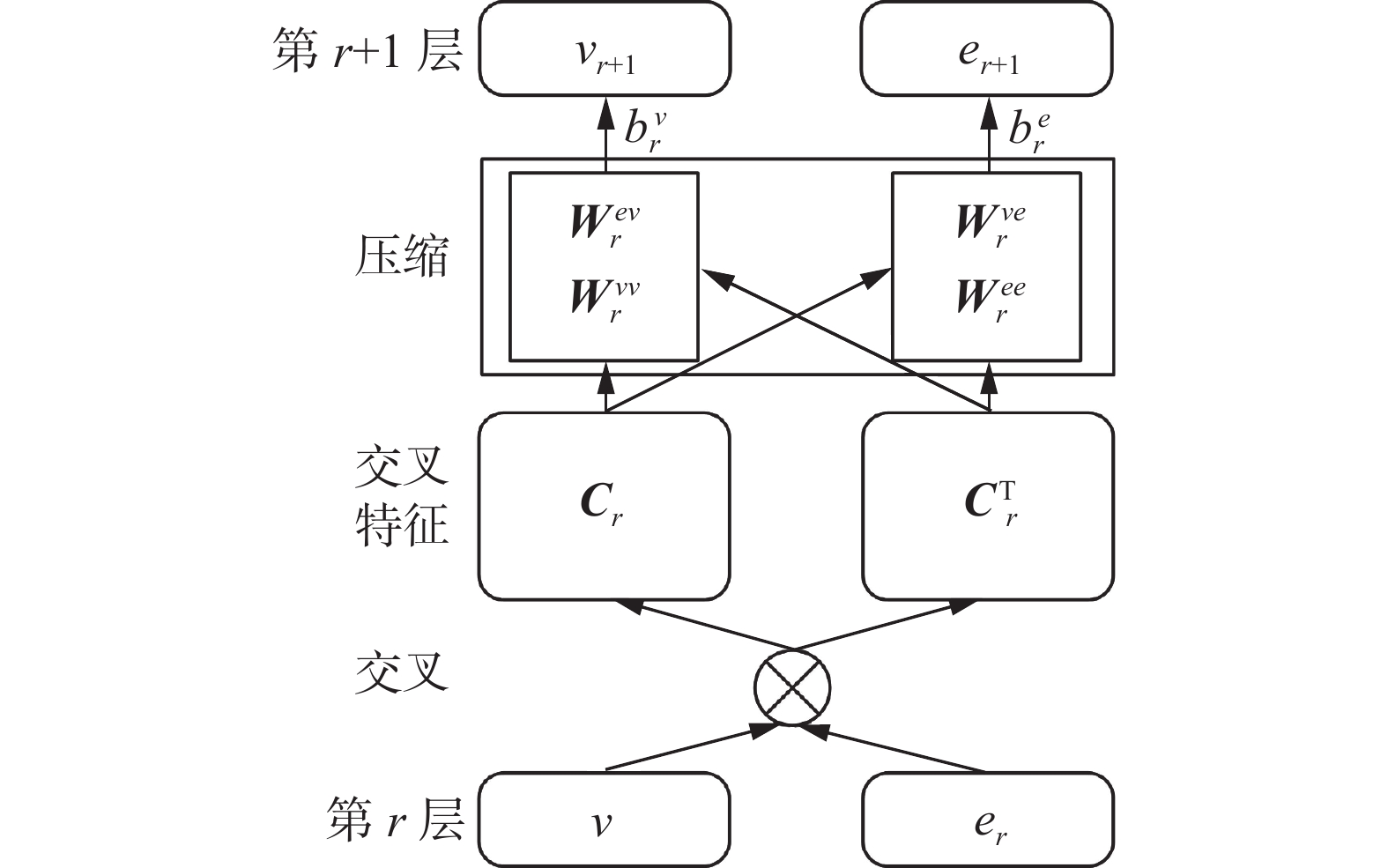 图 2 交叉压缩单元Fig. 2 Cross & Compress unit structure下载:
全尺寸图片
图 2 交叉压缩单元Fig. 2 Cross & Compress unit structure下载:
全尺寸图片
首先构建项目
$v$ 与对应实体$e$ 之间的交叉特征矩阵${{\boldsymbol{C}}_r} \in {{\bf{R}}^{d \times d}}$ :$$ {{\boldsymbol{C}}_r} = {{\boldsymbol{v}}_r}{\boldsymbol{e}}_r^{\rm T} = \left[ {\begin{array}{*{20}{c}} {v_r^{\left( 1 \right)}e_r^{\left( 1 \right)}}&{\cdots }&{v_r^{\left( 1 \right)}e_r^{\left( d \right)}} \\ {\vdots }&{\ddots}&{\vdots } \\ {v_r^{\left( d \right)}e_r^{\left( 1 \right)}}&{\cdots }&{v_r^{\left( d \right)}e_r^{\left( d \right)}} \end{array}} \right] $$ 式中:
${{\boldsymbol{v}}_r} \in {{\bf{R}}^d}$ 和${{\boldsymbol{e}}_r} \in {{\bf{R}}^d}$ 分别为第$r$ 层的项目和实体特征向量,$d$ 为隐藏层的维度。然后对交叉特征矩阵进行压缩操作,将矩阵维度从
${{\bf{R}}^{d \times d}}$ 投影到${{\bf{R}}^d}$ :$$ {{\boldsymbol{v}}_{r + 1}} = {{\boldsymbol{C}}_r}W_r^{vv} + {\boldsymbol{C}}_r^{\rm T}W_r^{ev} + {\boldsymbol{b}}_r^v $$ $$ {{\boldsymbol{e}}_{r + 1}} = {{\boldsymbol{C}}_r}W_r^{ev} + {\boldsymbol{C}}_r^{\rm T}W_r^{ee} + {\boldsymbol{b}}_r^e $$ 式中:
${{\boldsymbol{W}}_r} \in {{\bf{R}}^d}$ 为交叉压缩单元权重,${{\boldsymbol{b}}_r} \in {{\bf{R}}^d}$ 为偏置向量。为便于使用,将交叉压缩操作表示为
$$ \left[ {{{\boldsymbol{v}}_{r + 1}},{{\boldsymbol{e}}_{r + 1}}} \right] = C\left( {{{\boldsymbol{v}}_r},{{\boldsymbol{e}}_r}} \right) $$ 1.4 知识图谱嵌入单元
为了将知识图谱三元组映射到低维空间,同时保持知识图谱原有结构,本文采用语义匹配模型分析项目属性知识图谱。给定知识图谱中的三元组
$\left( {h,r,t} \right)$ ,将头实体和对应关系作为输入,分别使用交叉压缩单元和多层感知机提取头实体和关系的特征向量,得到头实体特征向量${{\boldsymbol{h}}_R}$ 和关系的特征向量${{\boldsymbol{r}}_R}$ :$$ {{\boldsymbol{h}}_R} = {E_{v\sim S\left( h \right)}}{C^R}\left( {{\boldsymbol{v}},{\boldsymbol{h}}} \right)\left[ {\boldsymbol{e}} \right] $$ $$ {{\boldsymbol{r}}_R} = M\left( {M\left( { \cdot \cdot \cdot M\left( {\boldsymbol{r}} \right)} \right)} \right) = {M^R}\left( {\boldsymbol{r}} \right) $$ 式中:
$S\left( h \right)$ 为知识图谱中头实体的相关项目集合,${C^R}$ 为$R$ 层交叉压缩操作,$\left[ {\boldsymbol{e}} \right]$ 为通过交叉压缩单元输出的实体特征向量,$M\left( \boldsymbol{x}\right)$ 为一个全连接神经网络,即$$ M\left( {\boldsymbol{x}} \right) = \sigma \left( {{{\boldsymbol{W}}_q}{\boldsymbol{x}} + {{\boldsymbol{b}}_q}} \right) $$ 式中:
${{\boldsymbol{W}}_q}$ 为训练参数,${{\boldsymbol{b}}_q}$ 为偏置向量,$\sigma $ 为非线性激活函数sigmoid。然后将头实体特征向量
${{\boldsymbol{h}}_R}$ 和关系特征向量${{\boldsymbol{r}}_R}$ 串联,经过$K$ 层多层感知机得到尾实体的预测值${\boldsymbol{\hat t}}$ :$$ {\boldsymbol{\hat t}} = {M^K}\left( {\left[ {\begin{array}{*{20}{c}} {{{\boldsymbol{h}}_R}} \\ {{{\boldsymbol{r}}_R}} \end{array}} \right]} \right) $$ 最后通过相似性函数来计算三元组
$\left( {h,r,t} \right)$ 分数。$$ {\text{score}}\left( {h,r,t} \right) = {f_{KG}}\left( {{\boldsymbol{t}},{\boldsymbol{\hat t}}} \right) $$ 式中
${f_{KG}}$ 函数以内积的形式定义,并通过非线性激活函数sigmoid标准化输出:$$ {f_{KG}}\left( {{\boldsymbol{t}},{\boldsymbol{\hat t}}} \right) = \sigma \left( {{{\boldsymbol{t}}^{\rm T}}{\boldsymbol{\hat t}}} \right) $$ 1.5 基于动态兴趣传播的用户特征提取
用户特征是推荐系统建模的核心要素,用户特征的准确与否决定着推荐模型质量。RippleNet在用户特征提取方面已取得了很大的成就,但该方法未挖掘用户历史行为对用户兴趣的差异性影响,且在层间兴趣传播时忽略了用户兴趣的衰减问题。相较于RippleNet,RDPKG首先在传播初始阶段采用注意力机制动态融合用户历史项目获得用户浅层兴趣表示;然后基于用户历史项目沿着知识图谱中的连接路径以波纹的形式向外传播来挖掘用户深层兴趣表示,并在向外层传播过程中抛弃对候选项目特征向量的更新;最后通过注意力机制计算得到权重因子,从而识别层间兴趣传播的动态变化。动态兴趣传播过程如图3所示。
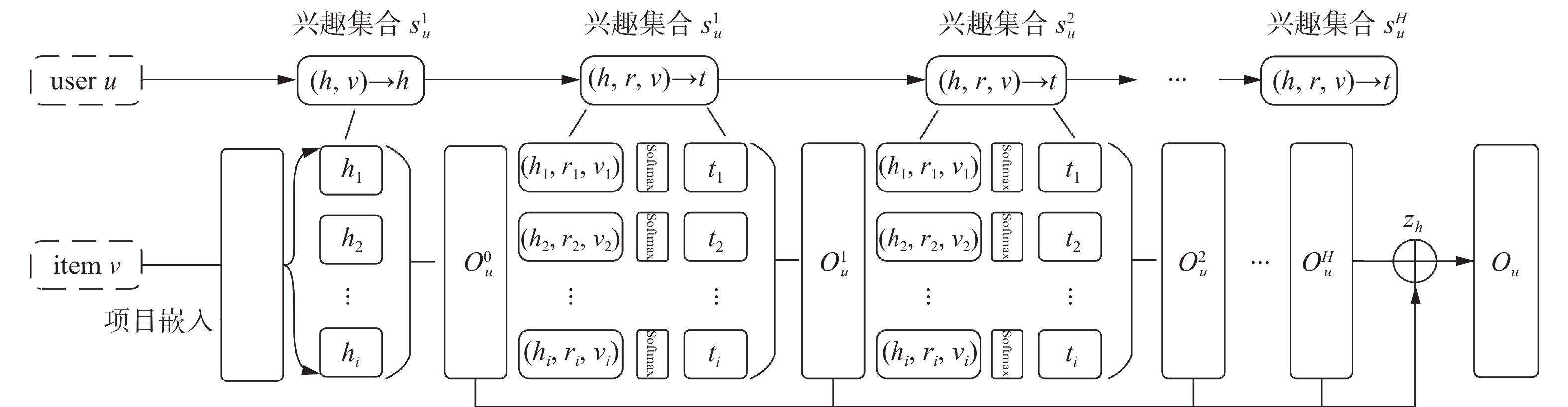 图 3 动态兴趣传播示意Fig. 3 Dynamic interest propagation schematic diagram下载:
全尺寸图片
图 3 动态兴趣传播示意Fig. 3 Dynamic interest propagation schematic diagram下载:
全尺寸图片
1.5.1 兴趣集合
给定交互矩阵
${\boldsymbol{Y}}$ 和知识图谱$G$ ,用户$u$ 的$h$ 层邻居节点定义为$\varepsilon _u^h$ :$$ \varepsilon _u^h = \left\{ {t|\left( {h,r,t} \right) \in G{\text{ , }}h \in \varepsilon _u^{h - 1}} \right\} $$ 式中:
$h = 1,2, \cdot \cdot \cdot ,H$ 为传播层数,$\varepsilon _u^0 = \left\{ {v|{y_{uv}} = 1} \right\}$ 为用户$u$ 历史项目集合。然后将
$\varepsilon _u^0$ 作为知识图谱中的种子集,沿着知识图谱中的连接路径通过类似波纹的传播方式构建用户$u$ 的层级兴趣集合,兴趣集合$S_u^h$ 定义为$$ S_u^h = \left\{ {\left( {h,r,t} \right)|\left( {h,r,t} \right) \in G{\text{ and }}h \in \varepsilon _u^{h - 1}} \right\} $$ 1.5.2 兴趣传播
用户历史行为是用户兴趣建模的重要信息,通过挖掘用户历史行为可以提高模型的兴趣表达能力,因此本文首先采用注意力机制对用户历史项目进行融合,并将融合获得的用户特征向量作为用户浅层兴趣表示。注意力机制的输入为用户历史项目和候选项目,将项目向量
${{\boldsymbol{h}}_i}$ 和候选实体向量${\boldsymbol{v}}$ 拼接,通过Softmax函数进行标准化得到权重${{\boldsymbol{c}}_i}$ ,以权重${{\boldsymbol{c}}_i}$ 动态融合用户历史项目获得用户兴趣表示${\boldsymbol{u}}_u^0$ ,定义为$$ {{\boldsymbol{c}}_i} = {\text{Softmax}}\left( {{{\boldsymbol{W}}_c}\left[ {{{\boldsymbol{h}}_i},{\boldsymbol{v}}} \right]} \right) $$ $$ {\boldsymbol{u}}_u^0 = \sum\limits_{{h_i} \in S_u^1} {{{\boldsymbol{c}}_i}} {{\boldsymbol{h}}_i} $$ 然后基于用户历史项目在知识图谱中以波纹的形式向外传播来挖掘用户深层兴趣表示。给定候选项目
$v$ 和用户$u$ 的$h$ 层偏好集合$S_u^h$ ,通过计算候选项目${\boldsymbol{v}}$ 与兴趣集合$S_u^h$ 中头实体${{\boldsymbol{h}}_i}$ 在关系空间${r_i}$ 下相关性得到层内融合权重${{\boldsymbol{p}}_i}$ ,如$$ {{\boldsymbol{p}}_i} = {\text{Softmax}}\left( {{{\boldsymbol{v}}^{\rm T}}{{\boldsymbol{R}}_i}{{\boldsymbol{h}}_i}} \right) = \frac{{{\text{exp}}\left( {{{\boldsymbol{v}}^{\rm T}}{{\boldsymbol{R}}_i}{{\boldsymbol{h}}_i}} \right)}}{{\sum\limits_{\left( {h,r,t} \right) \in S_u^h} {{\text{exp}}\left( {{{\boldsymbol{v}}^{\rm T}}{{\boldsymbol{R}}_i}{{\boldsymbol{h}}_i}} \right)} }} $$ 式中
${{\boldsymbol{R}}_i} \in {{\bf{R}}^d}$ 、${{\boldsymbol{h}}_i} \in {{\bf{R}}^d}$ 和${\boldsymbol{v}} \in {{\bf{R}}^d}$ 为关系${r_i}$ 、头实体${h_i}$ 和项目$\boldsymbol{v}$ 的嵌入表示。在得到融合权重后,将
$S_u^h$ 中的尾实体向量表示${\boldsymbol{t}}$ 和相应的融合权重${{\boldsymbol{p}}_i}$ 相乘并求和得到$h$ 层用户兴趣表示${\boldsymbol{o}}_u^h$ ,定义为$$ {\boldsymbol{o}}_u^h = \sum\limits_{\left( {{h_i},{r_i},{t_i}} \right) \in S_u^h} {{{\boldsymbol{p}}_i}} {{\boldsymbol{t}}_i} $$ 经上述计算,得到多层用户兴趣表示集合
${O_u} = \left\{ {{\boldsymbol{o}}_u^0,{\boldsymbol{o}}_u^1, \cdot \cdot \cdot ,{\boldsymbol{o}}_u^H} \right\}$ 。然而在向外传播过程中,随着层数的增大,用户兴趣也会相应的衰减,若直接累加每层的兴趣表示将给模型带来较多噪声。为模拟向外传播过程中不同层数下用户兴趣的动态变化,本文将不同层数下的用户兴趣表示
${\boldsymbol{o}}_u^h$ 和原始用户表示${\boldsymbol{u}}$ 输入到注意力网络计算不同层数下的用户兴趣表示与原始用户间的权重${{\boldsymbol{{\textit{z}}}}_h}$ :$$ {{\boldsymbol{{\textit{z}}}}_h} = {\text{Softmax}}\left( {{{\boldsymbol{W}}_h}\left[ {{\boldsymbol{o}}_u^h,{\boldsymbol{u}}} \right]} \right) $$ 式中
${{\boldsymbol{W}}_h}$ 为训练参数。最后根据权重
${{\boldsymbol{{\textit{z}}}}_h}$ 动态融合用户兴趣表示${\boldsymbol{o}}_u^h$ 生成最终用户特征向量${{\boldsymbol{o}}_u}$ ,定义为$$ {{\boldsymbol{o}}_u} = \sum\limits_{h = 0}^H {{{\boldsymbol{{\textit{z}}}}_h}} {\boldsymbol{o}}_u^h $$ 1.6 推荐单元
1.6.1 概率预测
RDPKG的推荐单元输入为用户特征向量
${\boldsymbol{u}}$ 和候选项目特征向量${\boldsymbol{v}}$ ,用户特征向量${\boldsymbol{u}}$ 经过动态兴趣传播得到最终的用户特征向量${{\boldsymbol{o}}_u}$ ,项目特征向量${\boldsymbol{v}}$ 经过交叉压缩单元获得最终的项目特征向量$ {{\boldsymbol{v}}_R} $ :$$ {{\boldsymbol{o}}_{\boldsymbol{u}}} = {\text{DP}}\left( {\boldsymbol{u}} \right) $$ $$ {{\boldsymbol{v}}_R} = {E_{{\boldsymbol{e}}\sim S\left( v \right)}}\left[ {{C^R}\left( {{\boldsymbol{v}},{\boldsymbol{e}}} \right)\left[ {\boldsymbol{v}} \right]} \right] $$ 式中:DP为动态兴趣传播模块,
$S\left( v \right)$ 为项目$v$ 相关实体集,${C^R}$ 为$R$ 层交叉压缩操作,$\left[ {\boldsymbol{v}} \right]$ 为交叉压缩单元输出的项目特征向量。将计算得到用户特征向量
${{\boldsymbol{o}}_u}$ 和项目特征向量${{\boldsymbol{v}}_R}$ 进行内积来预测用户点击项目的概率${\hat y_{uv}}$ ,定义为$$ {\hat y_{uv}} = \sigma \left( {{\boldsymbol{o}}_u^{\rm T}{{\boldsymbol{v}}_R}} \right) $$ 1.6.2 模型训练
为了优化模型性能,本文采用如下损失函数
$$ \begin{gathered} \mathcal{L}= \sum _{u,v\in Y}\mathcal{J}\left({\hat{y}}_{uv},{y}_{uv}\right)\text{ }-\\ \text{}\text{}\text{}\text{}\text{}\text{}\text{}\text{}\text{}{\lambda }_{1}\left(\sum _{\left(h,r,t\right)\in G}{\rm{score}}\left(h,r,t\right)-\sum _{\left({h}^{\prime },r,{t}^{\prime }\right)\notin G}{\rm{score}}\left({h}^{\prime },r,{t}^{\prime }\right)\right)+{\lambda }_{2}{\Vert F\Vert }_{2}^{2} \end{gathered}$$ 式中:第1项
$ \mathcal{J} $ 为交叉熵损失;第2项是知识图谱嵌入单元损失,${\lambda _1}$ 是损失值参数;第3项$ {\lambda _2}\left\| F \right\|_2^2 $ 为${L_2}$ 正则化损失,${\lambda _2}$ 是正则化参数。根据上述损失函数并采用多任务学习方式更新参数值直至收敛,便可得到最优模型。针对模型训练过程如算法 1 所示。
算法1 基于动态兴趣传播和知识图谱的推荐方法(RDPKG)
输入 交互矩阵
${\boldsymbol{Y}}$ ,知识图谱$G$ ;输出 预测函数
${\hat y_{uv}} = F\left( {u,v|\varTheta ,{\boldsymbol{Y}},G} \right)$ 。1)初始化所有参数
2)计算每个用户
$u$ 的兴趣集合${S_u}$ 3)while RDPKG has not converged do
4)for t steps do
5)对
${\boldsymbol{Y}}$ 进行正负采样6)将
${S_u}$ 和${\boldsymbol{Y}}$ 中的minibatch传入推荐单元7)采用梯度下降函数更新
$F$ 参数8)end for
9)对
$G$ 中三元组进行正负采样10)将
$G$ 中minibatch传入知识图谱嵌入单元11)采用梯度下降函数更新
$F$ 参数12)end while
2. 实验结果及分析
2.1 实验数据集与实验设置
实验选取了3种推荐领域公开数据集,分别为MovieLens-1M、Last.FM和Book-Crossing。3种数据集的基本信息如表1所示。
表 1 数据集的基本信息Table 1 Basic information of the datasets数据集 用户 项目 交互 实体 关系 三元组 MovieLens-1M 6036 2347 753772 6729 7 20195 Last.FM 1872 3846 42346 9366 60 15588 Book-Crossing 17860 14910 139746 24039 10 19793 3种公开数据集为用户显式反馈数据,为更好体现模型性能,需将显式反馈数据转化为隐式反馈数据。对于MovieLens-1M,设置评分阈值为4,评分不小于4的记录标记为1,否则标记为0;对于Last.FM和Book-Crossing,用户对项目有评分记录则标记为1,否则标记为0。实验使用的知识图谱来自文献[24]中已构建的知识图谱。将每种数据集以6∶2∶2比例划分为训练集、验证集和测试集。
RDPKG参数设置如表2所示,其中
$d$ 为知识图谱向量表示维度,${k_n}$ 为兴趣集合采样数,$h$ 为传播层数,$t$ 为模型推荐单元训练频率,${\lambda _1}$ 和${\lambda _2}$ 为超参数。表 2 模型参数Table 2 Model parameters数据集 $d$ ${k_n}$ $h$ $t$ ${\lambda _1}$ ${\lambda _2}$ MovieLens-1M 8 64 1 3 0.5 10−7 Last.FM 8 16 2 1 0.1 4×10−7 Book-Crossing 16 16 2 2 0.1 5×10−7 2.2 评价指标
为验证RDPKG实用性,在点击通过率(click through rate,CTR)预测实验中,使用准确率(accuracy,ACC)和接收者操作特征曲线(receiver operating characteristic curve, ROC)下方的面积(area under curve,AUC)来评价模型效果;在Top-N实验中,使用准确率(Precision@N)和召回率(Recall@N)来衡量模型推荐效果。ACC指标是预测正确的样本数量占总数量的比例,公式为
$$ A_{\text{CC}} = \frac{{{N_{{\text{TP}}}} + {N_{{\text{TN}}}}}}{{{N_{{\text{TP}}}} + {N_{{\text{TN}}}} + {N_{{\text{FP}}}} + {N_{{\text{FN}}}}}} $$ 式中:
${N_{{\text{TP}}}}$ (true position)为将正例预测正确的个数,${N_{{\text{TN}}}}$ (true negative)为将负例预测正确的个数,${N_{{\text{FP}}}}$ (false positive)为将负例预测错误的个数,${N_{{\text{FN}}}}$ (true negative)为将正例预测错误的个数。AUC指标的取值范围为0.5~1.0,AUC值越大表示算法性能越优,公式为
$$A_{\text{UC}} = \frac{{\displaystyle\sum\limits_i^n {\left( {{P_{{\text{pos}}}} > {P_{{\text{neg}}}}} \right) + 0.5 \times \displaystyle\sum\limits_i^n {\left( {{P_{{\text{pos}}}} = {P_{{\text{neg}}}}} \right)} } }}{{M \times N}}$$ 式中:M、N分别为正样本和负样本的数量,
${P_{{\text{pos}}}}$ 为正样本的得分,${P_{{\text{neg}}}}$ 为负样本得分。Precision@N表示模型推荐列表中相关项目数占项目总数的比例,Recall@N表示模型推荐列表中相关项目数占所有相关项目总数的比例。2.3 评价指标
2.3.1 模型性能对比
为验证RDPKG有效性,本文选取了相关工作中提到的CKE[22]、KGCN[29]、RippleNet[26]、KGCN-LS[30]、MKR[24]以及KRGCN[31]进行对比实验,RDPKG和参比方法的CTR预测实验结果如表3所示。
表 3 CTR预测实验结果Table 3 CTR prediction experimental results% 方法 MovieLens-1M Last.FM Book-Crossing AUC ACC AUC ACC AUC ACC CKE 80.12 74.23 74.46 67.31 67.14 63.37 KGCN 90.69 83.40 79.43 72.38 69.44 63.54 RippleNet 91.79 84.27 79.94 73.40 72.04 64.77 KGCN-LS 91.35 84.03 79.53 72.57 68.97 63.53 MKR 91.22 83.74 79.50 75.04 73.42 70.22 KRGCN 92.23 84.88 80.53 73.80 73.10 66.77 RDPKG 92.81 85.42 82.46 76.09 73.45 69.39 注:加黑代表最优结果,下同。 由表3可知,RDPKG在3种数据集上相较于其他推荐模型均取得较好的性能。在MovieLe-ns-1M数据集上,RDPKG较RippleNet和KGCN在AUC评价指标上分别提高了1.02个百分点和2.12个百分点,在ACC评价指标上分别提高了1.15个百分点和2.02个百分点;在Last.FM数据集上,RDPKG较RippleNet和KGCN在AUC评价指标上分别提高了2.52个百分点和3.03个百分点,在ACC评价指标上分别提高了2.69个百分点和3.71个百分点;在Book-Crossing数据集上,RDPKG较RippleNet和KGCN在AUC评价指标上分别提高了1.41个百分点和4.01个百分点,在ACC评价指标上分别提高了4.62个百分点和5.85个百分点。从实验结果分析可知,基于嵌入的CKE模型在3种数据集上推荐性能弱于基于混合的模型,说明知识图谱的高阶关系可以有效提高模型性能。RDPKG在CTR预测实验中均优于从单维度建模的模型,其中RippleNet仅通过在知识图谱中进行层级传播来构建用户偏好,未利用知识图谱中的信息对项目建模;与RippleNet类似,KGCN和 KGCN-LS仅通过图神经网络聚合项目邻居节点得到项目表示,忽略了知识图谱对用户兴趣建模的重要性。KRGCN虽然同时对用户和项目建模,但效果弱于RDPKG,其主要原因是KRGCN在聚合时并没有采取合适的策略来模拟信息衰减的特性。
为进一步分析RDPKG推荐效果,本文对6种模型进行TOP-N推荐实验,实验结果如图4、图5 所示。由图4可知本文所提的RDPKG在3种数据集中在准确率上较其他模型有一定的提升,在MovieLens-1M数据集上,当N取5和10时RDPKG准确率提升明显,较RippleNet分别提高了14.28%和11.65%,较KGCN分别提高了12.28%和18.55%;在Last.FM数据集上,当N取5时RDPKG准确率提升明显,较RippleNet提高了35.71%,较KGCN提高了46.15%;在Book-Crossing数据集上,当N取2时RDPKG准确率提升明显,较RippleNet提高了50%,较KGCN提高了28.57%。由图5可知本文所提的RDPKG在3种数据集上的召回率较其他模型有一定的提升,在MovieLens-1M 数据集上,当N取10时RDPKG召回率提升明显,较RippleNet提高了16.88%,较KGCN提高了52.06%;在Last.FM数据集上,当N取10时RDPKG召回率提升明显,较RippleNet提高了96.06%,较KGCN提高了16.24%;在Book-Crossing数据集上,当N取20时RDPKG召回率提升明显,较RippleNet提高了33.33%,较KGCN提高了26.32%。RippleNet在MovieLens-1M数据集中表现较好,在Last.FM和Book-Crossing数据集上表现一般,其主要原因是Last.FM和Book-Crossing数据集数据稀疏,RippleNet在融合邻居节点时易引入噪声,影响模型性能,而RDPKG在3种数据集上表现较好,表明RDPKG有较好推荐场景适应性,在数据稀疏场景中仍具有较优表现。RDPKG在3种数据集上准确率和召回率均高于RippleNet和KGCN,RDPKG优势在于用户特征融合了用户历史行为信息和知识图谱中的高阶关联信息,项目特征融合了知识图谱中的相关实体信息。KRGCN在3种数据集中均取得较优的表现,但效果不如RDPKG,其原因在于距离用户交互历史项目越远,存在的无关信息越多,若不采用合适的方式融合则会影响用户表征的正确性。
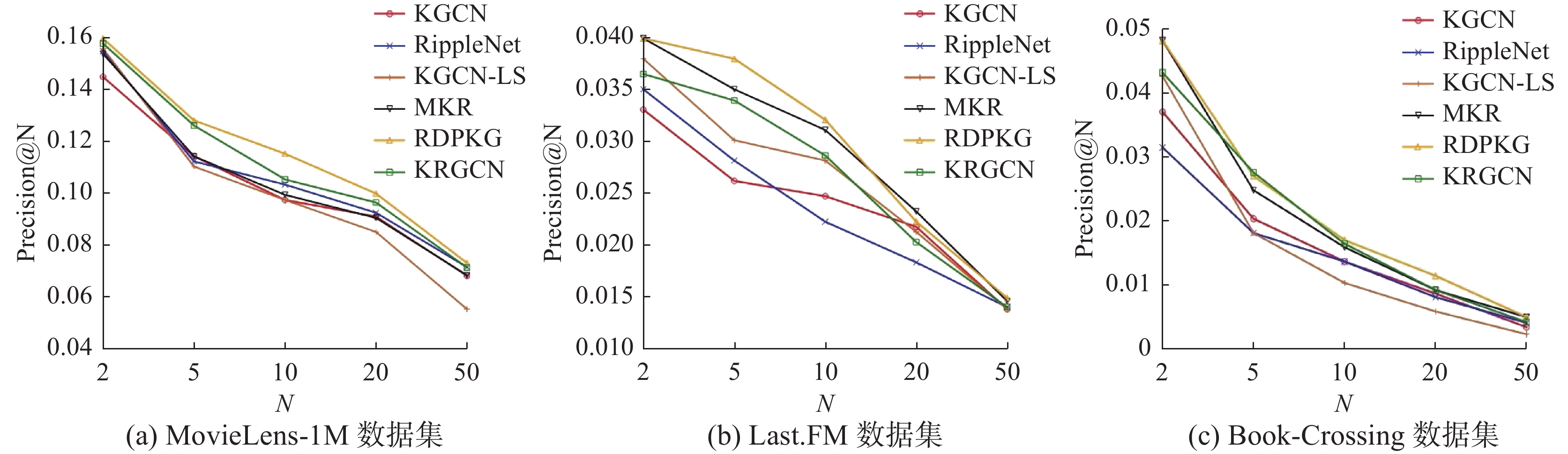 图 4 TOP-N推荐精准率Fig. 4 TOP-N recommendation precision下载:
全尺寸图片
图 4 TOP-N推荐精准率Fig. 4 TOP-N recommendation precision下载:
全尺寸图片
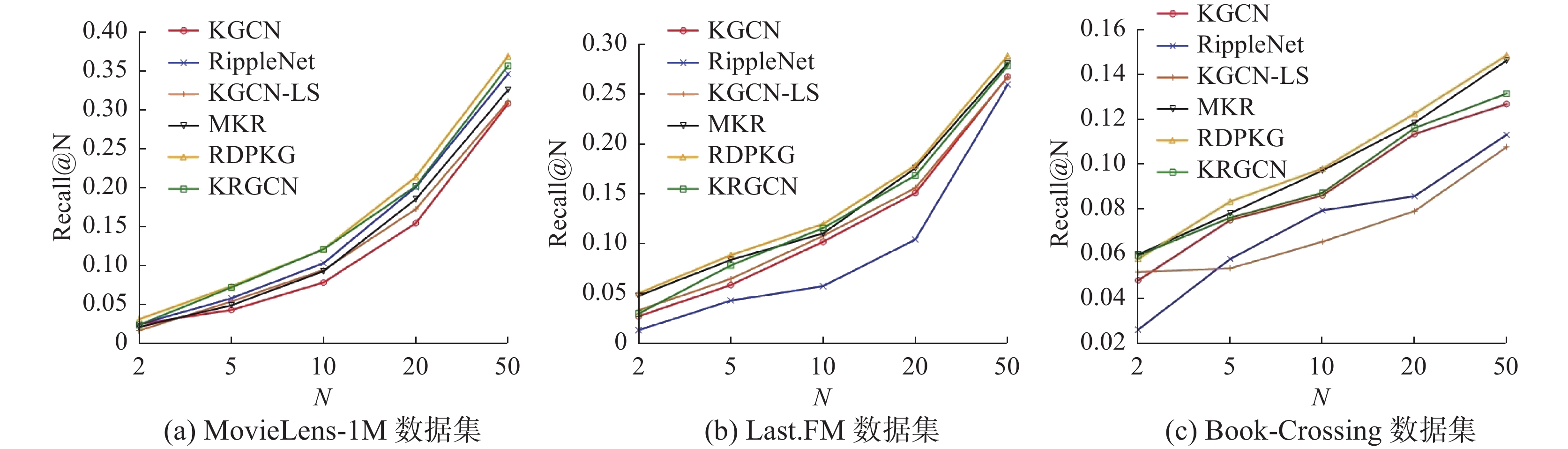 图 5 TOP-N推荐召回率Fig. 5 TOP-N recommendation recall下载:
全尺寸图片
图 5 TOP-N推荐召回率Fig. 5 TOP-N recommendation recall下载:
全尺寸图片
2.3.2 消融实验
为验证RDPKG中不同模块对模型性能的影响,本文设计了相应的消融实验,实验结果如表4所示。RDPKG-U表示模型移除交叉压缩单元和知识图谱嵌入单元,仅使用动态兴趣传播方法提取用户特征向量;RDPKG-I表示模型移除动态兴趣传播方法,仅使用交叉压缩单元和知识图谱嵌入单元提取项目特征向量;RDPKG-E表示模型未对传播方法进行改进,采用原兴趣传播方法提取用户特征向量。
表 4 消融实验结果Table 4 Ablation experimental results% 方法 MovieLens-1M Last.FM Book-Crossing AUC ACC AUC ACC AUC ACC RDPKG 92.81 85.42 82.36 75.67 73.45 69.39 RDPKG-U 92.20 84.72 80.95 73.55 72.35 65.92 RDPKG-I 91.54 84.20 79.47 74.61 73.42 70.22 RDPKG-E 91.99 84.52 80.64 74.83 73.02 68.81 由表4分析可知,与完整的RDPKG相比,去除动态兴趣传播方法或者交叉压缩单元后的模型性能都有所下降,验证了RDPKG中动态兴趣传播和交叉压缩单元有效性。其中去除交叉压缩单元,用于预测分数的项目特征向量无法从知识图谱中获得相关信息;去除传播方法,用于预测分数的用户特征向量无法获取用户高阶兴趣。当使用原兴趣传播方法时,模型性能下降显著,验证了动态兴趣传播方法的优越性。综合RDPKG-U、RDPKG-I和RDPKG实验结果可知单维度对用户或项目进行建模,模型的性能均低于从用户和项目维度建模的模型,验证了学习用户特征的同时学习项目特征可以有效提高模型推荐性能。
2.3.3 模型参数影响分析
为探究RDPKG推荐单元训练频率
$t$ 、传播层数$h$ 和兴趣集合采样数${k_n}$ 对模型性能的影响,本文在MovieLens-1M数据集上对上述参数进行实验。表5为不同推荐单元训练频率对模型性能的影响。表 5 推荐单元训练频率对模型性能的影响Table 5 Effect of recommendation unit training frequency on model performance% 评价指标 1 2 3 4 5 6 AUC 92.67 92.70 92.81 92.74 92.63 92.68 ACC 85.22 85.31 85.42 85.36 85.13 85.25 由表5可知,对于推荐单元训练频率
$t$ ,当$t$ 为3时模型性能最优,主要知识图谱嵌入单元的训练次数过大会影响推荐单元目标函数,而知识图谱嵌入单元的训练次数过小则无法充分挖掘知识图谱中的信息。表6为不同传播层数对模型性能的影响。表 6 传播层数对模型性能的影响Table 6 Effect of the number of propagation layers on model performance% 评价指标 0 1 2 3 4 5 AUC 92.38 92.81 92.76 92.73 92.67 92.58 ACC 84.87 85.42 85.31 85.28 85.25 85.18 由表6可知,对于传播层数
$h$ ,当$h$ 为1时模型性能最优,而随着传播层数的增加,与用户不相关的实体也在增加,将会给模型带来更多的噪声,影响模型性能。表7为不同兴趣集合采样数对模型性能的影响的结果。
表 7 兴趣集合采样数对模型性能的影响Table 7 Effect of interest set sampling number on model performance% 评价指标 2 4 8 16 32 64 AUC 90.55 91.33 91.96 92.35 92.61 92.81 ACC 83.09 83.92 84.51 84.82 85.19 85.42 由表7可知,对于兴趣集合采样数,随着采样数
${k_n}$ 不断增大,模型性能也在提升,当采样数为64时模型性能最优,主要兴趣集合采样数越大模型从知识图谱中获得的相关节点信息越多,可以有效丰富用户兴趣表示。3. 结束语
本文针对推荐系统中的评分预测问题展开研究,提出一种基于动态兴趣传播和知识图谱推荐方法RDPKG。RDPKG首先在兴趣传播方法中引入注意力机制来模拟用户兴趣衰减特性生成用户表示,提高了模型的用户兴趣表达能力;然后通过多层交叉压缩操作生成项目表示,并采用多任务学习优化推荐单元和知识图嵌入单元,增强了模型的泛化能力;最后利用项目和用户表示为用户进行推荐。选取推荐系统领域3种公共数据集进行实验,结果表明本文提出的RDPKG相比于其他6种对比方法在ACC、AUC指标上均有所提升,并通过消融实验验证了RDPKG各个模块的有效性。
在未来工作中,将从以下2方面展开研究:1)用户兴趣会随时间而产生变化,因此如何挖掘用户的动态信息来学习动态变化的兴趣特征是日后研究重点之一;2)社交网络中拥有较强社交关系的用户间具有相似兴趣,利用用户社交网络中社交关系提升模型性能。
-
图 1 RDPKG框架
Fig. 1 RDPKG framework
下载:
全尺寸图片
图 2 交叉压缩单元
Fig. 2 Cross & Compress unit structure
下载:
全尺寸图片
图 3 动态兴趣传播示意
Fig. 3 Dynamic interest propagation schematic diagram
下载:
全尺寸图片
图 4 TOP-N推荐精准率
Fig. 4 TOP-N recommendation precision
下载:
全尺寸图片
图 5 TOP-N推荐召回率
Fig. 5 TOP-N recommendation recall
下载:
全尺寸图片
表 1 数据集的基本信息
Table 1 Basic information of the datasets
数据集 用户 项目 交互 实体 关系 三元组 MovieLens-1M 6036 2347 753772 6729 7 20195 Last.FM 1872 3846 42346 9366 60 15588 Book-Crossing 17860 14910 139746 24039 10 19793 表 2 模型参数
Table 2 Model parameters
数据集 $d$ ${k_n}$ $h$ $t$ ${\lambda _1}$ ${\lambda _2}$ MovieLens-1M 8 64 1 3 0.5 10−7 Last.FM 8 16 2 1 0.1 4×10−7 Book-Crossing 16 16 2 2 0.1 5×10−7 表 3 CTR预测实验结果
Table 3 CTR prediction experimental results
% 方法 MovieLens-1M Last.FM Book-Crossing AUC ACC AUC ACC AUC ACC CKE 80.12 74.23 74.46 67.31 67.14 63.37 KGCN 90.69 83.40 79.43 72.38 69.44 63.54 RippleNet 91.79 84.27 79.94 73.40 72.04 64.77 KGCN-LS 91.35 84.03 79.53 72.57 68.97 63.53 MKR 91.22 83.74 79.50 75.04 73.42 70.22 KRGCN 92.23 84.88 80.53 73.80 73.10 66.77 RDPKG 92.81 85.42 82.46 76.09 73.45 69.39 注:加黑代表最优结果,下同。 表 4 消融实验结果
Table 4 Ablation experimental results
% 方法 MovieLens-1M Last.FM Book-Crossing AUC ACC AUC ACC AUC ACC RDPKG 92.81 85.42 82.36 75.67 73.45 69.39 RDPKG-U 92.20 84.72 80.95 73.55 72.35 65.92 RDPKG-I 91.54 84.20 79.47 74.61 73.42 70.22 RDPKG-E 91.99 84.52 80.64 74.83 73.02 68.81 表 5 推荐单元训练频率对模型性能的影响
Table 5 Effect of recommendation unit training frequency on model performance
% 评价指标 1 2 3 4 5 6 AUC 92.67 92.70 92.81 92.74 92.63 92.68 ACC 85.22 85.31 85.42 85.36 85.13 85.25 表 6 传播层数对模型性能的影响
Table 6 Effect of the number of propagation layers on model performance
% 评价指标 0 1 2 3 4 5 AUC 92.38 92.81 92.76 92.73 92.67 92.58 ACC 84.87 85.42 85.31 85.28 85.25 85.18 表 7 兴趣集合采样数对模型性能的影响
Table 7 Effect of interest set sampling number on model performance
% 评价指标 2 4 8 16 32 64 AUC 90.55 91.33 91.96 92.35 92.61 92.81 ACC 83.09 83.92 84.51 84.82 85.19 85.42 -
[1] CUI Zhihua, XU Xianghua, XUE Fei, et al. Personalized recommendation system based on collaborative filtering for IoT scenarios[J]. IEEE transactions on services computing, 2020, 13(4): 685–695. doi: 10.1109/TSC.2020.2964552 [2] CHEN Liang, XU Yangjun, XIE Fenfang, et al. Data poisoning attacks on neighborhood-based recommender systems[J/OL]. Transactions on emerging telecommunications technologies (2020−01−14) [2022−06−15].https://doi.org/10.1002/ett.3872. [3] CAO Da, HE Xiangnan, MIAO Lianhai, et al. Social-enhanced attentive group recommendation[J]. IEEE transactions on knowledge and data engineering, 2019, 33(3): 1195–1209. [4] 刘华锋, 景丽萍, 于剑. 融合社交信息的矩阵分解推荐方法研究综述[J]. 软件学报, 2018, 29(2): 340–362. LIU Huafeng, JING Liping, YU Jian. Survey of matrix factorization based recommendation methods by integrating social information[J]. Journal of software, 2018, 29(2): 340–362. [5] HAN Jiayu, ZHENG Lei, XU Yuanbo, et al. Adaptive deep modeling of users and items using side information for recommendation[J]. IEEE transactions on neural networks and learning systems, 2019, 31(3): 737–748. [6] ZHANG Jing, YANG Ying, ZHUO Li, et al. Personalized recommendation of social images by constructing a user interest tree with deep features and tag trees[J]. IEEE transactions on multimedia, 2019, 21(11): 2762–2775. doi: 10.1109/TMM.2019.2912124 [7] 王大玲, 冯时, 张一飞, 等. 社会媒体多模态、多层次资源推荐技术研究[J]. 智能系统学报, 2014, 9(3): 265–275. WANG Daling, FENG Shi, ZHANG Yifei, et al. Study on the recommendations of multi-modal and multi-level resources in social media[J]. CAAI transactions on intelligent systems, 2014, 9(3): 265–275. [8] SANG Lei, XU Min, QIAN Shengsheng, et al. Context-dependent propagating-based video recommendation in multimodal heterogeneous information networks[J]. IEEE transactions on multimedia, 2020, 23: 2019–2032. [9] 王立才, 孟祥武, 张玉洁. 上下文感知推荐系统[J]. 软件学报, 2012, 23(1): 1–20. doi: 10.3724/SP.J.1001.2012.04100 WANG Licai, MENG Xiangwu, ZHANG Yujie. Context-aware recommender systems[J]. Journal of software, 2012, 23(1): 1–20. doi: 10.3724/SP.J.1001.2012.04100 [10] 田玲, 张谨川, 张晋豪, 等. 知识图谱综述——表示、构建、推理与知识超图理论[J]. 计算机应用, 2012, 41(8): 2161–2186. TIAN Ling, ZHANG Jinchuan, ZHANG Jinhao, et al. Knowledge graph survey: representation, construction, reasoning and knowledge hypergraph theory[J]. Journal of computer applications, 2012, 41(8): 2161–2186. [11] JI Shaoxiong, PAN Shirui, CAMBRIA E, et al. A survey on knowledge graphs: representation, acquisition and applications[J]. IEEE transactions on neural networks and learning systems, 2022, 33(2): 494–514. doi: 10.1109/TNNLS.2021.3070843 [12] LYU Ziyu, WU Yue, LAI Junjie, et al. Knowledge enhanced graph neural networks for explainable recommendation[J]. IEEE transactions on knowledge and data engineering, 2023, 33(5): 4954–4968. [13] GUO Qingyu, ZHUANG Fuzhen, QIN Cuan, et al. A survey on knowledge graph-based recommender systems[J]. IEEE transactions on knowledge and data engineering, 2022, 34(8): 3549–3568. doi: 10.1109/TKDE.2020.3028705 [14] SHI Chuan, ZHANG Zhiqiang, LUO Ping, et al. Semantic path based personalized recommendation on weighted heterogeneous information networks[C]//Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne. New York: ACM, 2015: 453−462. [15] 何云飞, 张以文, 吕智慧, 等. 异质信息网络中元路径感知的评分协同过滤[J]. 计算机学报, 2020, 43(12): 2385–2397. doi: 10.11897/SP.J.1016.2020.02385 HE Yunfei, ZHANG Yiwen, LYU Zhihui, et al. Meta-path aware scoring collaborative filtering in heterogeneous information networks[J]. Chinese journal of computers, 2020, 43(12): 2385–2397. doi: 10.11897/SP.J.1016.2020.02385 [16] LI Hui, WANG Yanlin, LYU Ziyu, et al. Multi-task learning for recommendation over heterogeneous information network[J]. IEEE transactions on knowledge and data engineering, 2022, 34(2): 789–802. doi: 10.1109/TKDE.2020.2983409 [17] WANG Quan, MAO Zhendong, WANG Bin, et al. Knowledge graph embedding: a survey of approaches and applications[J]. IEEE transactions on knowledge and data engineering, 2017, 29(12): 2724–2743. doi: 10.1109/TKDE.2017.2754499 [18] BORDES A, USUNIER N, GARCIA-DURAN A, et al. Translating embeddings for modeling multi-relational data[J]. Advances in neural information processing systems, 2013, 26: 2787–2795. [19] LIN Hailun, LIU Yong, WANG Weiping, et al. Learning entity and relation embeddings for knowledge resolution[J]. Procedia computer science, 2017, 108: 345–354. doi: 10.1016/j.procs.2017.05.045 [20] NICKEL M, TRESP V, KRIEGEL H P. A three-way model for collective learning on multi-relational data[C]//Proceedings of the 28th International Conference on Machine Learning. New York: ACM, 2011: 809–816. [21] YANG Bishan, YIH Wen-tau, HE Xiaodong, et al. Embedding entities and relations for learning and inference in knowledge bases[EB/OL]. (2015−08−29) [2022−06−15].https://arxiv.org/pdf/1412.6575v4.pdf. [22] ZHANG Fuzheng, YUAN N J, LIAN Defu, et al. Collaborative knowledge base embedding for recommender systems[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 353−362. [23] PALUMBO E, MONTI D, RIZZO G, et al. Entity2rec: property-specific knowledge graph embeddings for item recommendation[J]. Expert systems with applications, 2020, 151: 113235. doi: 10.1016/j.eswa.2020.113235 [24] WANG Hongwei, ZHANG Fuzheng, ZHAO Miao, et al. Multi-task feature learning for knowledge graph enhanced recommendation[C]//Proceedings of the 2019 World Wide Web Conference. New York: ACM, 2019: 2000−2010. [25] LI Chengte, HSU Cheng, ZHANG Yang. FairSR: fairness-aware sequential recommendation through multi-task learning with preference graph embeddings[J]. ACM transactions on intelligent systems and technology, 2022, 13(1): 1–21. [26] WANG Hongwei, ZHANG Fuzheng, WANG Jialin, et al. RippleNet: propagating user preferences on the knowledge graph for recommender systems[C]//Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York: ACM, 2018: 417−426. [27] TANG Xiaoli, WANG Tengyun, YANG Haizhi, et al. AKUPM: attention-enhanced knowledge-aware user preference model for recommendation[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2019: 1891−1899. [28] SHA Xiao, SUN Zhu, ZHANG Jie. Attentive knowledge graph embedding for personalized recommendation [EB/OL]. (2021−09−15)[2022−06−15]. https://arxiv.org/pdf/1910.08288.pdf. [29] WANG Hongwei, ZHAO Miao, XIE Xing, et al. Knowledge graph convolutional networks for recommender systems[C]//Proceedings of the 2019 World Wide Web Conference. New York: ACM, 2019: 3307−3313. [30] WANG Hongwei, ZHANG Fuzheng, ZHANG Mengdi, et al. Knowledge-aware graph neural networks with label smoothness regularization for recommender systems[C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2019: 968−977. [31] 崔焕庆, 宋玮情, 杨峻铸. 知识水波图卷积网络推荐模型[J/OL]. 计算机科学与探索 (2022−07−14) [2022−07−20]. http://kns.cnki.net/kcms/detail/11.5602.TP.20220713.2010.002.html. CUI Huanqing, SONG Weiqing, YANG Junzhu. Knowledge ripple graph convolutional network for recommendation[J/OL]. Journal of frontiers of computer science and technology(2022−07−14) [2022−07−20]. http://kns.cnki.net/kcms/detail/11.5602.TP.20220713.2010.002.html.










































































































































































