
Study on entropy of system fault evolution process and its influence on logical relationships
-
摘要: 为研究系统故障演化过程中系统功能状态变化的混乱程度,引入熵概念提出了系统故障演化过程熵(简称演化熵)。演化熵是演化过程某时刻的系统功能状态混乱程度,是系统演化从一时刻发展到另一时刻的系统功能状态混乱程度的变化度量,数值上等于该时刻事件故障概率分布熵(简称分布熵)。研究表明演化熵只能通过某时刻事件故障概率分布得到,且具有确定的值域范围;演化过程中的事件逻辑关系对演化熵的变化有直接影响,或逻辑使演化熵降低且小于任意参与事件的分布熵,与逻辑使演化熵增加且大于任意参与事件的分布熵;随传递次数增加,与逻辑和或逻辑分别对演化熵的提高和降低作用减小。最后通过实例展示了演化熵的确定过程,总结了目前研究存在的问题,提出了后继研究方向。Abstract: To study the chaotic degree of system function state change in the system fault evolution process, the concept of entropy is introduced, and the entropy of the system fault evolution process (evolution entropy for short) is proposed. Evolution entropy is the chaotic degree of the system function state at a certain time in the evolution process. It is a measure of change in the chaotic degree of the system function state when the system evolution develops from one moment to another. It is numerically equal to the event fault probability distribution entropy at that moment (referred to as distribution entropy). The research shows that the evolution entropy can only be obtained from the event fault probability distribution at a certain moment and has a certain range of value domains. The logical relationship of events in the evolution process directly impacts the change in evolution entropy. The OR logic reduces the evolution entropy to less than the distribution entropy of any participating event. Moreover, the AND logic increases the evolution entropy to greater than the distribution entropy of any participating event. With the increase in transfer time, the effect of AND logic and OR logic on the increase and decrease in evolution entropy reduces, respectively. Finally, the determination process of evolution entropy is exhibited by an example, summarizing the problems existing in the current research and putting forward the following research direction.
-
系统存在的意义是完成预定功能,系统在规定条件下完成预定功能的能力称为可靠性,与之互补的是失效性。那么系统完成预定功能的状态作者定义为系统功能状态[1-2],是可靠状态和失效状态的叠加态。这意味着系统功能状态不可能完全是可靠状态或是失效状态。如果设定系统功能状态空间只有可靠和失效状态,则系统功能状态可用可靠状态或失效状态之一表示。又考虑到我们通常更关注系统失效,即系统发生故障的过程,以便干预系统故障使系统安全。因此将系统失效状态作为研究重点,将系统功能状态的变化过程称为系统故障演化过程[3-4]。系统故障演化过程中的任意时刻,系统功能状态都是确定的。系统故障演化过程是诠释系统在各因素作用下系统功能状态变化的过程。系统在自然状态下功能性逐渐降低,而人的作用是减缓或阻止该过程。这与熵的定义较为一致,即系统在自然状态下存在熵增现象。系统故障演化过程能表示系统在自然情况下的系统功能状态变化。在该变化中系统越混乱,系统的功能状态就趋向于失效状态。因此系统故障演化过程就代表了系统功能状态混乱性的变化过程。该过程是否可以使用熵概念描述,是论文研究的关键问题。
关于熵描述各类系统的混乱性和不确定性的研究较多。目前主要研究包括DSM与信息熵的装备体系结构贡献率[5];EWT的压力样本熵分析[6];连续−离散系统自适应最大相关熵滤波算法[7];皮尔逊系数和信息熵的数据融合[8];混合系统线性状态空间模型辨识[9];预测不确定性与对抗鲁棒性关系[10];逆信息熵因果推理[11];熵修正混合人工蜂群−蝙蝠算法[12];多粒度形式不确定性度量与最优粒度[13];信息熵信息物理系统融合控制[14];不确定性空间信息重建[15];知识粒度框架的不确定性度量[16];改进EMD算法计算熵性能[17]。国外也对这类问题进行了研究,包括图像熵均衡[18];联合图熵知识提取[19-20];EEMD信息熵[21];信息熵协同理论[22];信息熵和灰色关联分析[23]等。但这些研究一般关注于系统某种条件下的混乱情况或是信息来源的混乱及不确定性。但实际上这种混乱程度通过熵值只能得到一个相对量,缺乏比较性,不能分析熵的具体变化程度。更为有效的方法是度量某演化过程对系统功能状态混乱性的变化程度,即通过系统故障演化过程来衡量系统功能状态混乱性的变化程度。这是一种从演化过程角度研究系统功能状态变化的方法,但类似研究目前仍然鲜见。
根据作者对系统故障演化过程的研究[3-4],认为通过系统故障演化过程研究系统功能状态混乱程度是可行的。由此,论文提出了系统故障演化过程熵(下文简称“演化熵”)的概念,衡量演化过程造成系统功能状态下降的程度。演化熵变化越大,系统向着失效状态的变化越大。研究了演化过程中最基本的事件逻辑关系,即“与或”逻辑关系,对演化熵的影响,从而估计系统故障演化过程对演化熵造成的影响。
1. 事件故障概率分布熵的基本概念
在说明演化熵之前,需要论述其基础概念,即事件故障概率分布熵。描述系统故障演化过程中的系统功能状态混乱性,需要确定事件故障概率分布熵和系统故障演化过程熵,前者简称为分布熵,后者简称为演化熵,分布熵是演化熵的基础。
系统功能状态代表了系统在某一演化时刻实现其功能的可能性。或者理解为无数系统功能状态按照演化过程组合在一起形成了系统故障演化过程。而系统功能状态是所有参与系统功能实现的事件的功能性的共同作用。作者为表示这些事件的功能性提出了事件故障概率分布。
事件故障概率分布[24-25]是空间故障树理论基础的重要概念,空间故障树理论基础[24]是空间故障树理论体系的第一阶段,因此事件故障概率分布贯穿了整个空间故障树理论体系。事件故障概率分布描述执行该事件元件的故障概率变化情况,该变化受到多因素影响,以这些因素作为坐标轴形成因素空间。则不同因素情况下的事件故障概率就在该因素空间中形成了变化曲面,即事件故障概率分布。事件故障概率分布中,各因素影响下概率变化程度可通过信息熵的形式描述,即形成了上文提到的分布熵。通过分布熵结合系统故障演化过程特征即可得到演化熵。
论述分布熵的构造过程,设因素集合为
$F= \left\{ {{f_1},{f_2}, \cdots ,{f_N}} \right\}$ ,$ n = 1,2, \cdots ,N $ ,N为因素总数;各因素值域等距划分点数量集合$ D{\text{ = }}\left\{ {{d_1},{d_2}, \cdots ,{d_N}} \right\} $ ,$ {f_n} $ 值域的划分点数量为$ {d_n} \in D $ ;事件故障概率的分类集合$ Q = \left\{ {{q_1},{q_2}, \cdots ,{q_M}} \right\} $ ,$m=1,2, \cdots, M$ ,${q_1} = \left[ {0,1/M} \right), {q_2} = \left[ {1/M,2/M} \right), \cdots ,{q_M} = \left[ {(M - 1)/M,M/M} \right]$ ,${q_1} \cup {q_2} \cdots \cup {q_M} = [0,1]$ ,$M$ 是分类总数;$P({x_1},{x_2}, \cdots ,{x_N})$ 为事件故障概率分布,${x_1}、{x_2}、\cdots、{x_N}$ 分别为因素${f_1}、{f_2}、\cdots、{f_N}$ 的具体值。对$P({x_1},{x_2}, \cdots ,{x_N})$ 中的所有故障概率点按照M类进行归类计数:$$ {N_m} = \left\{ \begin{gathered} {N_1} = {N_1} + 1,\;P({x_1},{x_2}, \cdots ,{x_N}) \in {q_1} \\ {N_2} = {N_2} + 1,\;P({x_1},{x_2}, \cdots ,{x_N}) \in {q_2} \\ \vdots \\ {N_M} = {N_M} + 1,\;P({x_1},{x_2}, \cdots ,{x_N}) \in {q_M} \\ \end{gathered} \right. $$ (1) 式中:
$ {N_m} $ 表示$ P({x_1},{x_2}, \cdots ,{x_N}) $ 中属于第m类的故障概率点数量,数量集合为$ N = \{ {N_1},{N_2}, \cdots ,{N_M}\} $ 。式(1)实现了对事件故障概率分布中所有故障概率点的统计。首先划定了M个分类,主要目的是将故障概率的值域进行划分,从而将落在不同区域的故障点统计出来。在不同故障概率区间中的点的数量是随后计算分布熵的基础。本质上不同概率区间中的点的数量代表了故障概率点在整个故障概率分布中的混乱程度,即为式(1)的基本逻辑意义。
进一步的,设
$ {N_m} $ 与总故障概率点数量${d_1} \times {d_2} \times \cdots \times {d_N}$ 的比值为$ {b_m} = {N_m}/({d_1} \times {d_2} \times \cdots \times {d_N}) $ ,比值集合为$ B = \left\{ {{b_1},{b_2}, \cdots ,{b_M}} \right\} $ 。那么分布熵$\varGamma ({b_1}, {b_2}, \cdots , {b_M})$ 可表示为$$ \varGamma ({b_1},{b_2}, \cdots ,{b_M}) = - \sum\limits_{m = 1}^M {{b_m}{{\log }_2}{b_m},\;0 \leqslant {b_m} \leqslant 1} ,\;\sum\limits_{m = 1}^M {{b_m} = 1} $$ (2) 可通过拉格朗日优化函数得到分布熵的最大值是
$ {\log _2}M $ ,最小值为0。2. 系统故障演化过程熵
系统故障演化过程可理解为按照演化顺序的无数系统功能状态的有序集合,过程中每个时刻都呈现为一个确定的系统功能状态。因此系统功能状态在系统故障演化过程中是连续的,每个时刻的系统功能状态都对应着一个演化熵。
系统故障演化过程是演化开始的原因事件,即边缘事件,以及演化过程中由边缘事件产生的过程事件和演化结果的最终事件组成的。在演化过程中这些事件由于因素作用产生的故障概率变化用事件故障概率分布表示,每个事件都有自己的故障概率分布。边缘事件是演化过程的起始事件,不受任何其他事件影响;过程事件由边缘事件产生,是演化过程的主体事件;最终事件是由过程事件和边缘事件导致的,是演化过程的最终状态事件。由于系统故障演化过程中任何事件都具有事件故障概率分布,所以过程事件的故障概率分布由边缘事件或边缘事件与前继过程事件的故障概率分布共同产生;最终事件故障概率分布由过程事件或过程事件和边缘事件的故障概率分布共同产生。
由上节可知,系统故障演化过程中的所有事件故障概率分布都可计算对应的分布熵。那么边缘事件的分布熵是边缘事件故障概率分布确定的;过程事件的分布熵由过程事件故障概率分布确定;最终事件分布熵由最终事件故障概率分布确定。需注意的事,这些分布熵不是通过前继事件分布熵使用解析方法确定的,而是使用前继事件故障概率分布得到的该时刻事件故障概率分布,再根据式(1)和式(2)确定的。因此系统故障演化过程中事件之间的相互作用和传递是通过事件故障概率分布完成的。分布熵只是对某时刻系统功能状态进行的度量,是通过该状态下事件故障概率分布计算得到的。因此分布熵不具有传递性,只是演化过程中某一时刻的功能状态混乱性的度量。
演化熵能衡量系统故障演化过程中某一时刻的系统功能状态的混乱程度,演化熵是通过该时刻的事件故障概率分布计算得到的,而该事件故障概率分布是通过前期参与演化的所有事件的故障概率分布计算得到的。所以演化熵是演化过程某时刻的分布熵。由于式(1)借助了概率的离散统计方法,因此前继事件的分布熵与当前时刻的演化熵,以及不同时刻的演化熵之间目前没有明确的函数关系。即不能直接通过分布熵或前期的演化熵直接得到后继演化熵。但在系统故障演化过程中,可通过不同时刻的演化熵来衡量系统功能状态的变化程度和趋势。因为各种边缘事件的加入,系统故障演化过程的演化熵必然发生变化。
对演化熵进行总结:1)演化熵表征了系统故障演化过程的某时刻的系统功能状态;2)演化熵不能通过前继演化熵或分布熵直接计算得到,只能通过该时刻事件故障概率分布得到;3)演化熵与分布熵一样,具有确定的值域范围。
3. 与或逻辑的演化熵变化规律
第2节提到演化熵不能通过前继演化熵或分布熵直接计算得到,目前没有明确的解析关系,但演化熵的规律性是研究演化熵的重要前提。系统故障演化过程由经历事件、影响因素、演化条件和事件逻辑关系组成,其中经历事件和影响因素统一由事件故障概率分布表示;演化条件由传递概率表示;逻辑关系是事件间相互作用的逻辑关系。在研究演化熵时,主要考虑事件和事件间逻辑关系,虽然传递概率影响演化熵的数值,但这里假设为1,暂不考虑。
那么演化熵主要受到前期事件故障概率分布和事件逻辑关系影响。第1、2节已说明了分布熵的构造和分布熵与演化熵的关系,这里不再赘述。系统故障演化过程由众多事件组成,虽然这些事件是基础,但演化过程自身的结构才是决定演化本身的关键因素。演化过程结构是这些事件的联系方式,即事件相互作用的方式,这些方式主要通过逻辑关系体现。最一般的逻辑关系是与或非逻辑关系,当然逻辑关系有很多种类和形式。何华灿教授[26-27]提出了20种柔性逻辑关系,也可作为描述事件间逻辑关系的形式。当逻辑关系复杂时可通过逻辑关系叠加形式进行表示。这里使用二元算子的与或逻辑关系,以3种典型情况为例,进行“与或”演化过程的演化熵性质分析。
设实例系统受影响的因素集合为
$F=\left\{ {f_1} = t, {f_2} = c \right\}$ ;因素值域划分点数量集合$D{\text{ = }}\left\{ {d_1} = 101, {d_2} = 51 \right\}$ ,使用时间t为100 d,间隔为1 d,使用温度c为0~50℃,间隔为1℃;故障概率分类为$ {q_1} = \left[ {0,1\% } \right),{q_2} = \left[ {1\% ,2\% } \right), \cdots ,{q_{100}} = \left[ {99\% ,100\% } \right] $ ;事件故障概率分布$P({x_1},{x_2})$ ,${x_1}、{x_2}$ 分别为因素$ {f_1}、 {f_2} $ 的具体值。图1给出该系统中的5个事件X1~X5受因素t和c影响的事件故障概率分布曲面[25]。 图 1 X1~X5的事件故障概率分布曲面Fig. 1 Event fault probability distribution surface of X1~X5
图 1 X1~X5的事件故障概率分布曲面Fig. 1 Event fault probability distribution surface of X1~X5 下载:
全尺寸图片
下载:
全尺寸图片
图2给出了与或演化过程的演化熵性质,包括3类演化熵:第1类为相同事件构成的与或关系的演化熵,如图2(a)和2(b);第2类为相同事件与或关系传递两次的演化熵,如图2(c)和2(d);第3类为不同事件构成的与或关系的演化熵,如图2(e)和2(f)。
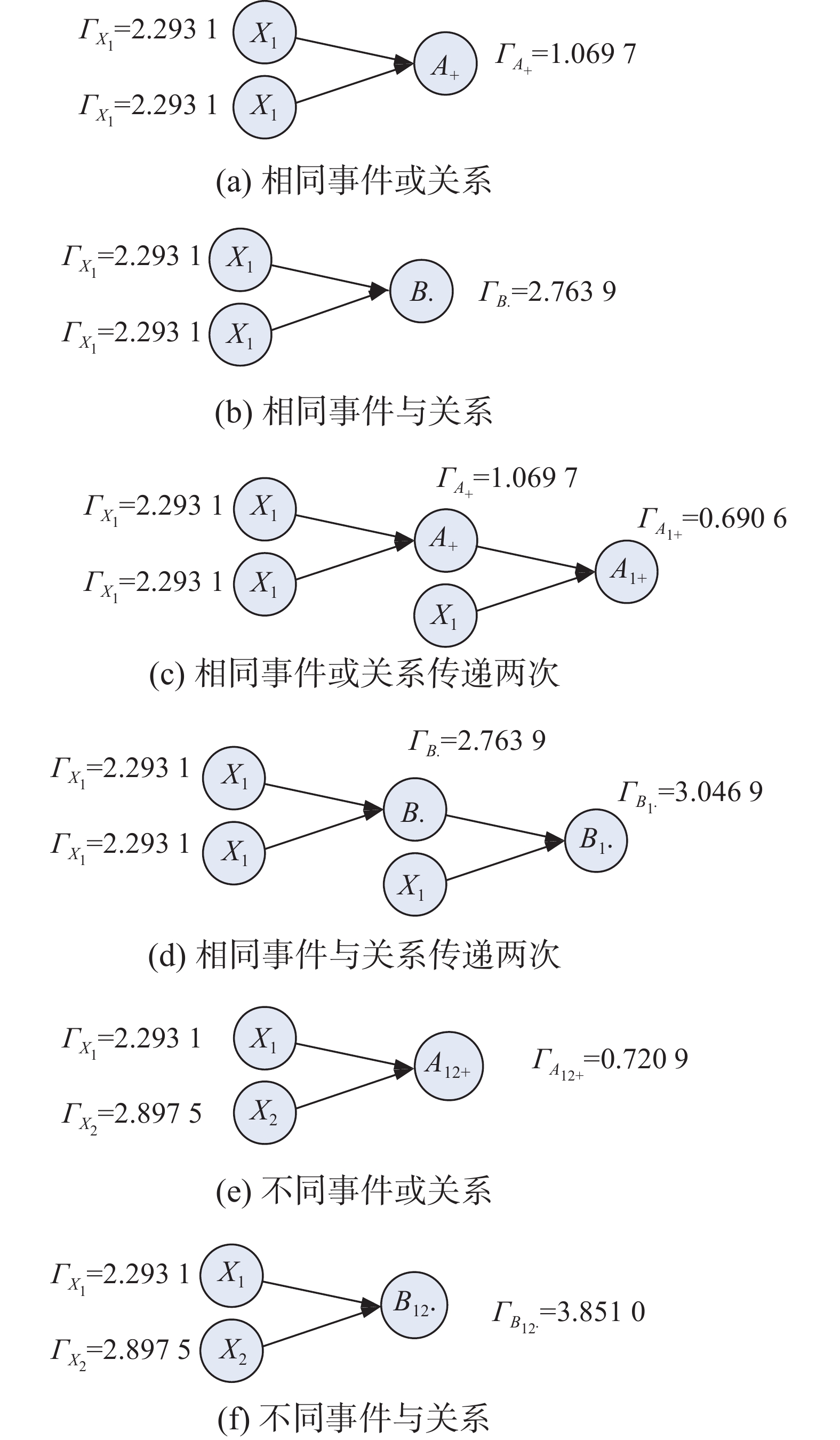 图 2 与或演化过程的演化熵性质Fig. 2 Evolution entropy property of AND OR evolution process下载:
全尺寸图片
图 2 与或演化过程的演化熵性质Fig. 2 Evolution entropy property of AND OR evolution process下载:
全尺寸图片
图2中
$\varGamma $ 为事件的分布熵,如${\varGamma _{{X_1}}}$ 是图1(a)的事件故障概率分布确定的分布熵。具体过程是,使用图1(a)的概率分布,通过式(1)统计在M=100时各类概率数量,之后再使用式(2)计算得到该事件的分布熵。图2中事件${A}_{+}、{B}_{\cdot }、{A}_{1+}、 {B}_{1\cdot }、 {A}_{12+}、{B}_{12\cdot }$ 的分布熵都可成为演化熵。例如图2(c)的系统故障演化过程的演化熵就是${A_{1 + }}$ 的分布熵。它代表了3个边缘事件${X_1}$ 参与演化过程,传递了两次后展现的该时刻的演化熵${\varGamma _{{A_{1 + }}}}$ 。${\varGamma _{{A_{1 + }}}}$ 是通过${A_{1 + }}$ 的故障概率分布计算得到的,受${X_1}$ 的故障概率分布、事件间逻辑关系和传递次数等作用。如下对图2中各情况代表的含义进行说明。相同事件构成的与或关系的演化熵,对比图2(a)与图2(b),
$ {\varGamma _{{X_1}}} = 2.293\;1 $ 、$ {\varGamma _{{A_ + }}} = 1.069\;7 $ 、$ {\varGamma _{{B_{{\cdot}}}}} = 2.763\;9 $ 。说明在相同两边缘事件一次传递条件下,或逻辑使演化熵明显降低,与逻辑明显使演化熵增加。或逻辑使演化熵降低为原有的46%;与逻辑使演化熵增加为原有的120%。或逻辑对演化熵的降低作用大于与逻辑对演化熵的增加作用。因此随着演化过程的延伸,或逻辑将使演化熵逐渐降低,与逻辑使演化熵逐渐增加。相同事件与或关系传递两次的演化熵,对比图2(c)与图2(d)。当演化过程有两次传递时,对于或逻辑,
$ {\varGamma _{{X_1}}} = 2.293\;1 $ 、$ {\varGamma _{{A_ + }}} = 1.069\;7 $ 、$ {\varGamma _{{A_{1 + }}}} = 0.690\;6 $ ,演化熵依次降低为原有演化熵的46.6%和64.5%,可预见随着传递次数的增加,或逻辑关系对演化熵的降低作用逐渐减小。对于与逻辑,$ {\varGamma _{{X_1}}} = 2.293\;1 $ 、${\varGamma _{{B_{{\cdot}}}}} = 2.763\;9$ 、$ {\varGamma _{{B_{1 \cdot }}}} = 3.046\;9 $ ,演化熵依次升高为原有演化熵的120.5%和110.2%,可预见随着传递次数的增加,与逻辑关系对演化熵的提高作用逐渐减小。其原因在于宏观上演化熵的有界性,即[$ {\log _2}M $ ,0],因此与或逻辑关对演化熵的改变均在该范围内。不同事件构成的与或关系的演化熵,对比图2(e)与图2(f)。两个不同边缘事件的分布熵分别为
$ {\varGamma _{{X_1}}} = 2.293\;1 $ 和$ {\varGamma _{{X_2}}} = 2.897\;5 $ ,或逻辑关系作用下的分布熵,即演化熵为$ {\varGamma _{{A_{12 + }}}} = 0.720\;9 $ 。这说明或逻辑关系得到的演化熵小于任意参与演化事件的分布熵。与逻辑关系作用下的分布熵,即演化熵为$ {\varGamma _{{B_{{\text{12}} \cdot }}}} = 3.851\;0 $ 。这说明与逻辑关系得到的演化熵大于任意参与演化事件的分布熵。$ {\varGamma _{{A_{12 + }}}} $ /$ {\varGamma _{{A_ + }}} $ =67%,$ {\varGamma _{{B_{{\text{12}} \cdot }}}} $ /$ {\varGamma _{{B_{{\cdot}}}}} $ =139%,这比两边缘事件相同情况下改变演化熵的程度增加了30%~40%。因此,或逻辑关系演化熵小于任意参与演化事件的分布熵;与逻辑关系演化熵大于任意参与演化事件的分布熵。由于演化熵目前不能使用前继事件的分布熵或演化熵通过解析方法直接得到。因此上述采取了具有特征的举例分析方式,关注的特点在于相同事件构成的与或关系的演化熵、相同事件与或关系传递两次的演化熵、不同事件构成的与或关系的演化熵3种情况。考察两事件与或逻辑关系得到的演化熵与原有分布熵的关系,可得到普遍适用的演化熵变化规律。
4. 两个演化过程的演化熵比较
在研究简单的系统演化过程的演化熵之后,继续研究两个较为复杂的演化过程。接续上节实例,该过程由5个边缘事件组成,它们的事件故障概率分布如图1所示。根据式(1)和式(2)计算得到这5个事件的分布熵,研究的两个演化过程如图3所示。
 图 3 多次传递的演化过程Fig. 3 Evolution process with multiple transfer下载:
全尺寸图片
图 3 多次传递的演化过程Fig. 3 Evolution process with multiple transfer下载:
全尺寸图片
图3给出了多次传递的演化过程,它们的边缘事件相同,为事件X1~X5。图3(a)经历了两次传递达到最终事件
${B_{AB \cdot }}$ ,${A_{12 + }}$ 和${B_{45 \cdot }}$ 是该演化过程的过程事件,它们的分布熵分别为$ {\varGamma _{{B_{AB \cdot }}}} = 4.846\;1 $ 、$ {\varGamma _{{A_{12 + }}}} = 0.720\;9 $ 、$ {\varGamma _{{B_{45 \cdot }}}} = 3.980\;7 $ 。图3(b)经历了3次传递达到最终事件${A_{B5 + }}$ ,${A_{234 + }}$ 和${B_{1A \cdot }}$ 是该演化过程的过程事件,分布熵分别为$ {\varGamma _{{A_{B5 + }}}} = 0.814\;8 $ 、${\varGamma _{{A_{234 + }}}} = 0.644\;4$ 、$ {\varGamma _{{B_{1A \cdot }}}} = 2.315\;5 $ 。在图3(a)中,系统的演化熵即为
${\varGamma _{{B_{AB \cdot }}}} = 4.846\;1$ ,演化过程由边缘事件X1~X5及过程事件${A_{12 + }}$ 和${B_{45 \cdot }}$ 共同组成。这时事件${B_{AB \cdot }}$ 的分布熵就是该时刻系统演化的演化熵。同理在图3(b)中,系统的演化熵即为$ {\varGamma _{{A_{B5 + }}}} = 0.814\;8 $ ,演化过程由边缘事件X1~X5及过程事件${A_{234 + }}$ 和${B_{1A \cdot }}$ 共同组成。这时事件${A_{B5 + }}$ 的分布熵就是该时刻系统演化的演化熵。对于${B_{1A \cdot }}$ ,系统的演化熵即为$ {\varGamma _{{B_{1A \cdot }}}} = 2.315\;5 $ ,演化过程由边缘事件X1~X4及过程事件${A_{234 + }}$ 组成。对于${A_{234 + }}$ ,系统的演化熵即为$ {\varGamma _{{A_{234 + }}}} = 0.644\;4 $ ,演化过程由边缘事件X2~X4组成。将系统故障演化过程中${A_{234 + }}$ 、${B_{1A \cdot }}$ 和${A_{B5 + }}$ 作为演化的3个节点时刻,这3个节点时刻的演化熵就是这些事件的分布熵。由此也可得由${A_{234 + }}$ 演化到${A_{B5 + }}$ 的过程中,系统的演化熵增加了$ {\varGamma _{{A_{B5 + }}}} $ −$ {\varGamma _{{A_{234 + }}}} $ =0.170 4。而且虽然$ {\varGamma _{{A_{B5 + }}}} $ 和$ {\varGamma _{{A_{234 + }}}} $ 是熵的相对值,但得到的0.170 4是该过程中演化熵变化的绝对值。这对演化过程中系统功能状态混乱性的变化度量有重要意义。将熵概念引入系统故障演化过程的研究尚处于起始阶段,存在许多重要问题需要探讨。系统故障演化过程由4部分组成,包括经历事件、影响因素、逻辑关系和演化条件。影响因素对经历事件的影响通过事件故障概率分布描述,引入熵形成了事件故障概率分布熵,在另文中已进行了说明。分布熵是研究演化熵的基础之一。对于逻辑关系,文中研究了最基本的与或逻辑关系对演化熵的影响。但更为复杂的柔性逻辑关系对演化熵的影响有待研究。演化条件在系统故障演化过程中的定义是原因事件引起结果事件的概率,文中没有具体研究,仅设为1,消除其对演化熵的影响,以待后续研究。
因此系统故障演化过程熵至少要从两方面考虑,一是影响因素与经历事件合成的分布熵,二是逻辑关系和演化条件构成的演化熵。前者表示演化的单元,后者表示演化的结构。还有一个值得关注的问题,作为表示系统功能状态混乱程度的演化熵一定随着演化递增吗?文中给出的研究结果显示不一定。如果演化过程中以与逻辑关系主导则演化熵是增加的,以或逻辑关系主导时演化熵减小。这与熵增原理可能不矛盾。与逻辑关系表示事件直接参与演化,共同影响后继事件,与逻辑关系的两个参与事件存在相互通讯,两事件必须合作完成缺一不可,这增加了混乱性使演化熵增加。而或逻辑关系完全不同,因为其中每个参与事件都可引起后继事件发生,因此这些参与事件相互是不通讯的,不知道其他事件的存在,也可理解为两事件完全独立的造成了结果,这的确使演化熵减小了。关于这些问题作者将在后继研究中探讨。
5. 结束语
论文在事件故障概率分布熵的基础上提出了系统故障演化过程熵,用于衡量系统故障演化过程中系统功能状态的混乱性,并研究了演化熵的变化特征。主要结论如下:
1)讨论了使用熵概念描述系统故障演化过程中系统功能状态混乱程度的可行性。研究认为描述系统故障演化过程至少考虑两方面,一是事件和影响因素,二是逻辑关系和演化条件。前者通过事件故障概率分布熵描述,后者通过系统故障演化过程熵描述。某时刻系统故障演化过程的系统功能状态由事件分布熵描述,对演化过程而言该时刻的演化熵就是该分布熵。得到的演化熵性质包括:演化熵表征了系统故障演化过程的某时刻的系统功能状态;演化熵只能通过某时刻的事件故障概率分布得到;演化熵具有确定的值域范围。
2)系统故障演化过程熵受演化过程中事件逻辑关系的直接影响。以最基本的与或逻辑关系为例研究了事件逻辑关系对演化熵的影响。结果表明:或逻辑使演化熵降低,与逻辑使演化熵增加;随传递次数的增加,与逻辑对演化熵的提高作用及或逻辑对演化熵的降低作用均减小;或逻辑的演化熵小于任意参与事件的分布熵;与逻辑的演化熵大于任意参与事件的分布熵。
3)通过两个系统故障演化过程实例给出了演化熵的确定过程。通过演化熵可以确定系统故障演化过程从一个时刻发展到另一时刻的熵的绝对变化量,也表征了该期间系统功能状态混乱程度的绝对变化量。这对演化过程中系统功能状态的变化度量有重要意义。
-
图 1 X1~X5的事件故障概率分布曲面
Fig. 1 Event fault probability distribution surface of X1~X5
下载:
全尺寸图片
图 2 与或演化过程的演化熵性质
Fig. 2 Evolution entropy property of AND OR evolution process
下载:
全尺寸图片
图 3 多次传递的演化过程
Fig. 3 Evolution process with multiple transfer
下载:
全尺寸图片
-
[1] 崔铁军, 李莎莎. 系统可靠−失效模型的哲学意义与智能实现[J]. 智能系统学报, 2020, 15(6): 1104–1112. CUI Tiejun, LI Shasha. Philosophical significance and implementation of an intelligent system based on the system reliability-failure model[J]. CAAI transactions on intelligent systems, 2020, 15(6): 1104–1112. [2] 崔铁军, 李莎莎. 系统故障演化过程的可拓学原理[J]. 广东工业大学学报, 2020, 37(5): 1–6. CUI Tiejun, LI Shasha. An extension theory of system fault evolution process[J]. Journal of Guangdong University of Technology, 2020, 37(5): 1–6. [3] 崔铁军. 空间故障网络理论与系统故障演化过程研究[J]. 安全与环境学报, 2020, 20(4): 1255–1262. CUI Tiejun. Profound trace and exploration into the space fault network theory and the system fault evolution process[J]. Journal of safety and environment, 2020, 20(4): 1255–1262. [4] 崔铁军. 系统故障演化过程描述方法研究[J]. 计算机应用研究, 2020, 37(10): 3006–3009. CUI Tiejun. Research on description method of system fault evolution process[J]. Application research of computers, 2020, 37(10): 3006–3009. [5] 魏东涛, 刘晓东, 周骏, 等. 基于DSM与信息熵的装备体系结构贡献率分析[J/OL]. 系统工程与电子技术, 2022: 1−9. (2022−03−16). https://kns.cnki.net/kcms/detail/11.2422.tn.20220314.1602.008.html. WEI Dongtao, LIU Xiaodong, ZHOU Jun, et al. Evaluation method of equipment’s structure contribution rate to system-of-systems based on DSM and information entropy[J/OL]. Systems engineering and electronics, 2022: 1−9. (2022−03−16). https://kns.cnki.net/kcms/detail/11.2422.tn.20220314.1602.008.html. [6] 刘雁, 李宇宸, 张赫, 等. 基于EWT的离心压气机出口动态压力样本熵分析[J]. 航空动力学报, 2023, 38(3): 655–664. LIU Yan, LI Yuchen, ZHANG He, et al. Sample entropy characteristics of dynamic pressure at outlet of centrifugal compressor based on EWT[J]. Journal of aerospace power, 2023, 38(3): 655–664. [7] 胡浩然, 陈树新, 吴昊, 等. 面向连续−离散系统的自适应最大相关熵滤波算法[J/OL]. 西安交通大学学报 2022(6): 1−9. (2022−03−08). https://kns.cnki.net/kcms/detail/61.1069.T.20220304.1843.006.html. HU Haoran, CHEN Shuxin, WU Hao, et al. Adaptive maximum correntropy filtering algorithm for continuous-discrete systems[J/OL]. Journal of Xi’an Jiaotong University, 2022(6): 1−9. (2022−03−08). https://kns.cnki.net/kcms/detail/61.1069.T.20220304.1843.006.html. [8] 陶洋, 祝小钧, 杨柳. 基于皮尔逊相关系数和信息熵的多传感器数据融合[J/OL]. 小型微型计算机系统, 2022: 1−7. (2022−03−01). https://kns.cnki.net/kcms/detail/21.1106.tp.20220225.1128.006.html. TAO Yang, ZHU Xiaojun, YANG Liu. Multi-sensor data fusion based on Pearson coefficient and information entropy[J/OL]. Journal of Chinese computer systems, 2022: 1−7. (2022−03−01). https://kns.cnki.net/kcms/detail/21.1106.tp.20220225.1128.006.html. [9] 伍文城, 王晓茹, 宋新立. 面向阻尼控制的交直流混合系统线性状态空间模型辨识[J/OL]. 电力系统自动化, 2022: 1−15. (2022−02−18) [ 2022−09−18]. https://kns.cnki.net/kcms/detail/32.1180.TP.20220217.1544.002.html. WU Wencheng, WANG Xiaoru, SONG Xinli. Linear state space model identification of AC/DC hybrid system for damping control[J/OL]. Automation of electric power systems, 2022: 1−15. (2022−02−18)[ 2022−09−18]. https://kns.cnki.net/kcms/detail/32.1180.TP.20220217.1544.002.html. [10] 陈思宏, 沈浩靖, 王冉, 等. 预测不确定性与对抗鲁棒性的关系研究[J]. 软件学报, 2022, 33(2): 524–538. CHEN Sihong, SHEN Haojing, WANG Ran, et al. Relationship between prediction uncertainty and adversarial robustness[J]. Journal of software, 2022, 33(2): 524–538. [11] 穆钢, 陈奇, 刘洪波, 等. 揭示电力系统运行数据中因果关系的逆信息熵因果推理方法[J/OL]. 中国电机工程学报, 2022: 1−14. (2022−01−27) [2022−09−18]. https://kns.cnki.net/kcms/detail/11.2107.TM.20220125.1748.007.html. MU Gang, CHEN Qi, LIU Hongbo, et al. A reciprocal information entropy causal inference method for exploring the cause-effect relationship in power system operation data[J/OL]. Proceedings of the CSEE, 2022: 1−14. (2022−01−27) [2022−09−18]. https://kns.cnki.net/kcms/detail/11.2107.TM.20220125.1748.007.html. [12] 郁彤彤, 王坚, 陈晓薇. 熵修正的混合人工蜂群−蝙蝠算法人群疏散模型[J]. 哈尔滨工业大学学报, 2021, 53(12): 80–88. YU Tongtong, WANG Jian, CHEN Xiaowei. Hybrid artificial bee colony-bat algorithm-based evacuation model with entropy correction[J]. Journal of Harbin institute of technology, 2021, 53(12): 80–88. [13] 李金海, 贺建君. 多粒度形式背景的不确定性度量与最优粒度选择[J]. 控制与决策, 2022, 37(5): 1299–1308. LI Jinhai, HE Jianjun. Uncertainty measurement and optimal granularity selection for multi-granularity formal context[J]. Control and decision, 2022, 37(5): 1299–1308. [14] 杨挺, 张璐, 张亚健, 等. 基于信息熵计算模型的电力信息物理系统融合控制方法[J]. 电力系统自动化, 2021, 45(12): 65–74. YANG Ting, ZHANG Lu, ZHANG Yajian, et al. Fusion control method for cyber-physical power system based on information entropy calculation model[J]. Automation of electric power systems, 2021, 45(12): 65–74. [15] 屠红艳, 张挺, 夏鹏飞, 等. 基于改进型变分自编码器的不确定性空间信息重建方法[J]. 计算机应用, 2021, 41(10): 2959–2963. TU Hongyan, ZHANG Ting, XIA Pengfei, et al. Reconstruction method for uncertain spatial information based on improved variational auto-encoder[J]. Journal of computer applications, 2021, 41(10): 2959–2963. [16] 吕萍, 常玉慧, 钱进. 知识粒度框架下不确定性度量研究[J]. 模糊系统与数学, 2020, 34(6): 140–149. LYU Ping, CHANG Yuhui, QIAN Jin. Research on uncertainty measures using knowledge granulation[J]. Fuzzy systems and mathematics, 2020, 34(6): 140–149. [17] 于本成, 丁世飞. 基于改进EMD算法的熵性能研究[J]. 郑州大学学报(理学版), 2018, 50(4): 39–44,49. YU Bencheng, DING Shifei. Research on entropy performance based on improved EMD algorithm[J]. Journal of Zhengzhou university (natural science edition), 2018, 50(4): 39–44,49. [18] HAYASHI T, CIMR D, FUJITA H, et al. Image entropy equalization: a novel preprocessing technique for image recognition tasks[J]. Information sciences, 2023, 647: 119539. doi: 10.1016/j.ins.2023.119539 [19] TIAN Zhiqiang, LI Weigang, HU Junwei, et al. Joint graph entropy knowledge distillation for point cloud classification and robustness against corruptions[J]. Information sciences, 2023, 648: 119542. doi: 10.1016/j.ins.2023.119542 [20] ZHANG Yucun, WU Zihao, LI Qun, et al. Research on point cloud simplification algorithm for ring forgings based on joint entropy evaluation[J]. Measurement science and technology, 2023, 34(12): 125203. doi: 10.1088/1361-6501/acf14c [21] DONG Delong, WANG Tianzhong, WANG Jinhui, et al. Study on tool wear state monitoring based on EEMD information entropy and PSO-SVM[J]. Journal of physics: conference series, 2023, 2566(1): 012111. doi: 10.1088/1742-6596/2566/1/012111 [22] XIONG Lijun, YUAN Haiping, LIU Gaoliang, et al. Synergetic theory of information entropy based on failure approach index for stability analysis of surrounding rock system[J]. Entropy, 2023, 25(8): 1237. doi: 10.3390/e25081237 [23] DENG Hongxing, WEN Wen, ZHOU Jie. Competitiveness evaluation of express delivery enterprises based on the information entropy and gray correlation analysis[J]. Sustainability, 2023, 15(16): 12469. doi: 10.3390/su151612469 [24] 崔铁军, 马云东. 基于多维空间事故树的维持系统可靠性方法研究[J]. 系统科学与数学, 2014, 34(6): 682–692. CUI Tiejun, MA Yundong. Research on the maintenance method of system reliability based on multi-dimensional space fault tree[J]. Journal of systems science and mathematical sciences, 2014, 34(6): 682–692. [25] 崔铁军, 马云东. 多维空间故障树构建及应用研究[J]. 中国安全科学学报, 2013, 23(4): 32–37,62. CUI Teijun, MA Yundong. Research on multi-dimensional space fault tree construction and application[J]. China safety science journal, 2013, 23(4): 32–37,62. [26] 何华灿. 重新找回人工智能的可解释性[J]. 智能系统学报, 2019, 14(3): 393–412. HE Huacan. Refining the interpretability of artificial intelligence[J]. CAAI transactions on intelligent systems, 2019, 14(3): 393–412. [27] 何华灿. 泛逻辑学理论: 机制主义人工智能理论的逻辑基础[J]. 智能系统学报, 2018, 13(1): 19–36. HE Huacan. Universal logic theory: logical foundation of mechanism-based artificial intelligence theory[J]. CAAI transactions on intelligent systems, 2018, 13(1): 19–36.




























































































