
Ironic sentence recognition model integrating ironic language features
-
摘要: 反讽是采用内隐的形式来表达情感的一种方法,反讽语句在文字和所想表达的情感上存在着不同,这使得对反讽语句进行情感分类变得更加困难。针对这一现象,提出一种融合反讽语言特征的反讽语句识别模型,通过加入反讽语言特征来提高反讽语句的识别准确率。首先,采用卡方检验算法对反讽语言进行分析并获取语言特征;然后,利用Word2Vec对语言特征进行训练获取语言特征的特征表示,同时使用注意力机制与Bi-GRU(双向门控循环神经单元)模型获取句子的特征表示;最后,将语言特征的特征表示与句子的特征表示进行融合并作为情感分类层的输入,对反讽语句进行识别。与CNN-AT、CNN-Adv、EPSN等3种模型进行对比,实验结果表明,该模型可以有效提高对于反讽语句的识别准确率。Abstract: Irony is a method of expressing sentiment implicitly. Differences between the words and the emotions of ironic sentences are abundant, causing difficulty in the sentiment classification of ironic sentences. To solve this problem, an ironic sentence recognition model integrating ironic language features (ISR) is proposed to improve the recognition accuracy of the ironic sentence by adding ironic language features. Initially, the Chi-square test algorithm is used to analyze ironic language and obtain language features. Then, Word2Vec is used to train the language features to obtain the feature representation of the language features. At the same time, the attention mechanism and Bi-GRU (bidirectional gated recursive neural unit) model are used to obtain the feature representation of the sentence. Finally, the feature representations of language features and sentences are fused as the input of the sentiment classification layer to identify the ironic sentences. The model has been compared with CNN-AT, CNN-Adv, and EPSN models. Experiment results show that the proposed model has high recognition accuracy for the ironic sentence.
-
反讽是一种特殊的修辞表达方式,其所要表达的真实意图和字面含义完全相反。随着社交网络的兴起以及人们表达情感的方式含蓄而内隐,反讽语句在中文文本中愈发普遍。例如:“节假日还要去加班,真是太充实了!”该语句通过一种反讽的方式来表达自己对于节假日加班的不满。
目前针对反讽识别的研究,主要面向英文文本,缺乏中文语料库。然而基于中文特有的语言现象,对于中文反讽语句的识别研究完全不同于英文文本,这使得对于中文反讽语句深层语义的挖掘成为了文本情感分析领域的重要研究内容和主要难点。
中文反讽识别的研究目前主要存在以下难点:1)至今没有权威的反讽语料库;2)社交平台中的语句或评论较为口语化,多为短文本,难以获取上下文语义信息;3)不同语言下的语言结构差异较大,基于中文语言下的特殊表达习惯,一些外文反讽方法无法直接用在中文反讽识别上。
基于以上考虑,本文提出一种融合反讽语言特征的反讽语句识别模型。本文的目的是利用卡方检验算法与Word2Vec模型,获取反讽语言特征,提高识别的准确率。本文的主要贡献包括:
1) 获取反讽语言特征的特征词汇,能够更好地对反讽语句进行识别。通过卡方检验算法对反讽语言特征进行计算,获取特征词汇,并使用Word2Vec得到该词汇的特征表示。
2) 构建融合语言特征的反讽识别模型,以提高中文文本反讽识别的准确率。模型使用Bi-GRU和注意力机制为主框架,得到句子对应的特征表示,并将反讽语言特征与句子特征融合,丰富模型的输入信息,提高准确率。
1. 相关工作
在情感表达上,人们通常喜欢采用隐式的方法,反讽用语则属于隐式情感分析中的重要组成部分,因此众多学者对此展开了探索。本文的相关工作主要从情感分析和反讽识别两个方面对反讽语句识别工作进行了研究。
1.1 情感分析方法
在情感文本分析领域,面对复杂且多层次的社交关系,Zhang等[1]考虑到了异构结构和内容信息,基于此提出一种异构图神经网络HetGNN,更好地捕捉其深层结构。同时,Yao等[2]提出一种图卷积神经网络文本分类模型,通过使用词语共现关系和文本之间的关联性,来构建文本图谱。Chen等[3]使用图卷积神经网络和注意力机制来解决基于方面的情感分类任务。
在深度学习方法中,Wang等[4]针对CNN和递归神经网络(recursive neural network,RNN)存在的缺陷,提出一种DRNN模型去同时获取长距离依赖关系和关键短语信息,更加深入地分析文本。在采用卷积神经网络提取隐式情感特征时,预测模型擅长获取句子的关键短语特征,但模型的池化操作会丢失句子的位置特征[5]。Sun等[6]提出一种基于多极正交注意力的双向长短期记忆网络 (Bi-directional long short-term memory,BiLSTM)隐式情感分析方法,分析了句子情感极性的不同。翟学明等[7]提出混合神经网络与条件随机场相结合,同时Zhuang等[8]提出一种考虑上下文信息、句法信息和语义信息3个方面的多特征神经网络模型,都是为了更好地获取句子的语义信息,并在情感分析上取得了较好的效果。
1.2 反讽识别方法
注意力机制[9-11]的模型能够依据信息的权重去度量不同信息特征的重要性,以加强关键信息,弱化无用信息,在反讽识别上也被广泛应用。卢欣等[12]通过对中文微博反讽的语言特征进行归纳,提出了一种融合语言特征的卷积神经网络反讽识别方法。Mehndiratta等[13]尝试利用CNN、RNN等技术对数据进行分类,以提高分类精度,以及讨论了不同的嵌入方式对数据集的影响。张庆林等[14]提出一种对抗学习框架,以期提高分类器的鲁棒性和泛化能力,改善模型在目标领域上的识别性能。
对于反讽识别的情感分析任务,需要从上下文中获取语义信息识别反讽语句,随着深度学习的发展,LSTM等多种深度学习的模型被广泛应用。Shah等[15]提出了一个依赖于高级深度语义特征和手工特征的神经模型。应用多核卷积神经网络(multi-kernel convolutional neural network,MKCNN)和LSTM的组合,提取更高层次的深度特征。樊小超等[16]针对反讽识别中缺乏上下文语境信息和修辞表达信息的问题,从多个维度对反讽文本的进行了研究。Pandey等[17]提出了一个混合注意的长短时记忆网络(hybrid attention-LSTM, HA-LSTM)来识别讽刺语句,提出的HA-LSTM在隐藏层中结合了16种不同的语言特征。
Dong等[18]针对中文社会评论的反讽识别问题,DC-BiGRU-CNN从结构优化的角度而不是文本矢量化机制的角度提出,它是一种结合BiGRU的双通道CNN,并以注意机制和多粒度卷积神经网络为主要框架。潘宏鹏等[19]为解决传统文本分析模型无法准确判别掺杂反讽语义文本的情感极性问题,设计了一种协同双向编码表征模型。张铭泉等[20]结合双BERT和注意力机制,以更全面地捕捉文本的情感信息。曾碧卿等[21]利用层次化结构,结合句子级和文档级的双重注意力机制,从多个层次上捕捉情感线索。PANDEY等[22]提出一种混合注意力长短时记忆网络,该网络在隐藏层中融合16种不同的语言特征,增强了模型的表征能力。ZHU等[23]通过开发一个框架来识别和分析中文语言中的修辞格,包括反讽修辞等,特别关注它们如何在跨句子或更大文本单元中发挥作用。HAO等[24]提出一种多尺度反讽情感识别算法,利用句子分层表示以提高性能,在实验中验证了其有效性,为反讽情感识别领域的研究提供新思路。
基于以上研究分析,现有方法虽然可以对反讽语句进行识别,但仍有不足之处。现有的反讽识别方法没有考虑多个特征,造成无法深入挖掘语义信息的现象,导致识别反讽语句准确率较低。本文通过将反讽语言特征融入到语义特征中,传入ISR模型进行分析,得到识别结果,提高识别准确率。
2. 语言特征获取
现阶段,有关反讽语句的研究主要面向英文文本,而针对中文反讽语句的识别和使用是一个更复杂的认知过程。因此,本文旨在构建一个中文反讽语料库,从中获取具有代表性的反讽特征,并将其转化为词向量输入至模型中,以增强语义信息,提高反讽识别准确率。
2.1 反讽语言特征分析
通过对网上收集的海量反讽数据进行分析,主要分为搭配规则和词汇特征两种语言类型。
1) 搭配规则。
搭配规则指反讽语句中常出现的两个词之间的固定搭配。如“可以···一点”,例如“这个天气可以再糟糕一点吗?感冒是好不了了”。
2) 词汇特征。
由于反讽词性较多,又将词汇特征分为带有情感的副词、语气词、网络词3种,具体反讽词汇特征实例如表1所示。
表 1 反讽词汇特征实例Table 1 Examples of ironic lexical features词汇特征 词汇 例句 情感副词 实在 这电影实在好看,
我都要睡着了语气词 呵呵 呵呵,你游戏打得
真好,一直送人头网络词 醉了 作业这么多我也是醉了 2.2 反讽语言特征获取
文本分类通常使用卡方检验、词袋模型以及TF-IDF的方法进行特征选择,而分类性能最终的优劣程度取决于特征选择的方法。由于卡方检验可以得到精确的显著性水平,本文选取了卡方验证进行反讽语句的特征选择。
卡方检验方法,先通过假设特征和类别两者之间是相互独立的,再根据偏差来判断相关性。当卡方检验值较低时,说明两者之间的相关性可能是由于偶然性所导致的,不具有说服性;当卡方检验值较大时,说明两者之间的相关性也越高,可以用来作为类别特征。因此,卡方检验是最有效且最合适的特征选取方法。
卡方检验公式为
$$ {\chi ^2}{\text{ = }}\sum\limits_{i = 1}^n {\frac{{{{({M_i} - {G_i})}^2}}}{{{G_i}}}} $$ (1) 其中:
$n$ 为所要进行检验的特征个数,${M_i}$ 为实际值,${G_i}$ 为理论值,$ {\chi ^2} $ 为特征卡方值。针对人工收集的2 000条反讽语句数据集,通过特征卡方值的计算,按照卡方值的高低排序,选取前20个词语搭配作为反讽的搭配规则,选取的部分词语搭配如表2所示;根据词汇特征选取卡方值较高的带有情感的副词、语气词、网络词各20个,选取的部分词汇如表3所示。
表 2 搭配规则特征表Table 2 Collocation rules of feature table序号 特征 卡方值 1 再···一点 75.352 2 很好···又 70.212 3 可以···一点 69.250 4 可以···再 65.367 5 很好···但是 61.295 表 3 词汇特征表Table 3 Lexicon of feature table词汇特征 特征 情感副词 很、太、极好、真是、非常 语气词 呵呵、啊、哇、哟、得了 网络词 醉了、键盘侠、内卷、凡尔赛、躺平 2.3 数据集构建
目前,针对反讽语句的研究主要面向英文语料库,对中文的研究较少,缺乏具有公开性和权威性的中文反讽语料库。本文在微博平台上,收集了近4万条的评论数据。但这些文本数据中存在大量的噪声,为了过滤这些噪声,通过以下方法对其进行预处理。
1) 删除重复数据。部分评论语句存在重复,还有一些标点符号重复使用,对其直接删除。
2) 去除无关无效评论。使用jieba分词处理句子无用的表情符号、中文标点混合英文标点符号与停用词等。首先加载自定义词典,然后借助函数获取关键词,接着针对不同的对象去除停用词,最后通过计算关键词词频进行数据处理。
3) 人工标注。在过滤后的评论数据集上对文本情感倾向进行积极、消极以及中性的人工标注。
4) 判断是否反讽。在情感倾向标注的同时,判断文本评论是否反讽,若为反讽则标为1,反之为0。
经过预处理并二分类判别,最终获得2 000条反讽语句构成反讽数据集。为平衡数据集,本文选取 2 000条反讽语句与2 000条非反讽语句作为数据集。
3. 融合反讽语言特征的反讽语句识别模型
为了解决反讽语句识别准确率较低的问题,本文提出一种融合反讽语言特征的反讽语句识别模型。本文在特征处理层借助卡方检验方法,获取反讽语言的语言特征,并利用Word2Vec对语言特征进行训练获取语言特征的特征表示,同时使用Bi-GRU与注意力模型获取句子的特征表示;然后,在特征融合层将语言特征的特征表示与句子的特征表示进行融合,作为输入向量传入反讽语句识别模型中;最后,在情感分析层使用Sigmoid函数对待判定句子进行反讽二分类识别,得出识别结果。融合反讽语言特征的反讽语句识别模型如图1所示。
 图 1 融合反讽语言特征的反讽语句识别模型Fig. 1 Ironic sentence recognition model based on ironic language features
图 1 融合反讽语言特征的反讽语句识别模型Fig. 1 Ironic sentence recognition model based on ironic language features 下载:
全尺寸图片
下载:
全尺寸图片
3.1 基础模型架构
Bi-GRU是由前向的GRU算法和后向的GRU算法共同组成,即采用双向传播的方式获取句子语义,具备同Bi-LSTM相同的长短期记忆能力和更简洁的结构。注意力机制能够对获得的特征进行结合,使模型更好的利用不同特征之间的关系。
对本文在使用Bi-GRU获取反讽句子的特征向量的基础上,引入注意力机制,从而对上下文重要反讽特征进行加权输出。Bi-GRU与注意力机制的结构如图2所示。
 图 2 Bi-GRU与注意力机制结构Fig. 2 Structure diagram of Bi-GRU and attention mechanism下载:
全尺寸图片
图 2 Bi-GRU与注意力机制结构Fig. 2 Structure diagram of Bi-GRU and attention mechanism下载:
全尺寸图片
图2中
${s_N}$ 表示输入的句子,在Bi-GRU模型中将词语的前向及反向状态进行合成为$[ \overrightarrow{{h_T}} , {\overleftarrow{h_T}]}$ ,${\text{weigh}}{{\text{t}}_N}$ 为特征的不同权重分配。3.2 特征处理层
首先使用Bi-GRU,通过前向和后向GRU的计算,获取了反讽语句的双向语义特征,则计算过程为
$$ {h_T} = (1 - {Z_T}) \cdot {h_{T - 1}} + {Z_T} \cdot {\tilde h_T} $$ (2) $$ {Z_T} = \sigma ({Q_Z}{x_T} + {U_Z}{h_{T - 1}} + {b_Z}) $$ (3) $$ {{\tilde h_T}} = \tanh ({Q_h}{x_T} + {r_T} \cdot ({U_h}{h_{T - 1}}) + {b_h}) $$ (4) $$ {r_T} = \sigma ({Q_r}{x_T} + {r_T} \cdot ({U_r}{h_{T - 1}}) + {b_r}) $$ (5) $$ {{\boldsymbol{H}}_T} = [{\overrightarrow {{\rm{GRU}}} {(x{}_T)}},{\overleftarrow {{\rm{GRU}}} {(x{}_T)}}] $$ (6) 式中:
${h_T}$ 为GRU神经元当前状态,${h_{T - 1}}$ 为上一刻状态,${\tilde h_T}$ 为隐藏状态,${Z_{{T}}}$ 为更新门当前状态。$ {Q_Z} $ 、$ {Q_h} $ 、$ {Q_r} $ 和$ {U_Z} $ 、$ {U_h} $ 、$ {U_r} $ 均为要学习的权重,$ {b_Z} $ 、$ {b_h} $ 、$ {b_r} $ 均为需要学习的偏置,“·”为点乘操作。$ {{\boldsymbol{H}}_T} $ 表示Bi-GRU提取的反讽语句特征向量,$\overrightarrow {{\rm{GRU}}}$ 表示前向传播GRU,$\overleftarrow {{\rm{GRU}}}$ 表示后向传播GRU,$ {x_T} $ 表示T时刻的输入。其次,在注意力层对获得的语义特征赋予不同的权重,则计算过程为
$$ {\mu _T} = \tanh ({{\boldsymbol{Q}}_\omega }{h_T} + {b_\omega }) $$ (7) $$ {\alpha _T} = \frac{{\exp (\mu _T^t{\mu _\omega })}}{{\displaystyle\sum\limits_T {\exp (\mu _T^t{\mu _\omega })} }} $$ (8) $$ {s_T} = \displaystyle\sum\limits_{\text{T}} {{\alpha _{T}}{h_T}} $$ (9) 式中:
$ {\mu _T} $ 为计算出的$ {h_T} $ 的隐藏单元,$ {{\boldsymbol{Q}}_\omega } $ 为注意力机制层的权重矩阵,$ {b_\omega } $ 为注意力机制层的偏置项,$ {\mu _\omega } $ 为随机初始化的实数序列,$ {\alpha _T} $ 为每个输入分配的独立权重,$ {s_T} $ 为分配权重后的输出。输出后的特征为反讽语句的重要情感特征,即反讽特征向量为
$$ {\boldsymbol{h}} = [{h_1}\;{h_2}\; \cdot \cdot \cdot \;{h_n}] $$ (10) 3.3 特征融合层
在本文第2部分获得反讽语言特征词汇的基础上,使用Word2Vec中one-hot的方式对该特征词汇进行训练,得到词汇特征的特征向量,即:
$$ {\boldsymbol{k}} = [{k_1}\;{k_2}\; \cdot \cdot \cdot \;{k_j}] $$ (11) 式中:由于所得到的词汇特征有80个,则
$j \in [1,80]$ 。若其中一个${k_j}$ 为1,其余则全部为0,代表该词汇特征的特征向量表示。将词汇特征的特征向量
${\boldsymbol{k}}$ 与第3.2节获得的反讽语句特征向量${\boldsymbol{h}}$ 进行融合,融合公式为$$ {\boldsymbol{W}} = {\boldsymbol{k}} \otimes {\boldsymbol{h}} $$ (12) 若两者的特征维度不同,则移除该语句特征向量中非主谓宾核心位置且不会对该语句造成影响的数据,并通过线性变换转换成同维向量,进行归一化和标准化处理。
融合语言特征的句子特征表示流程如图3所示。
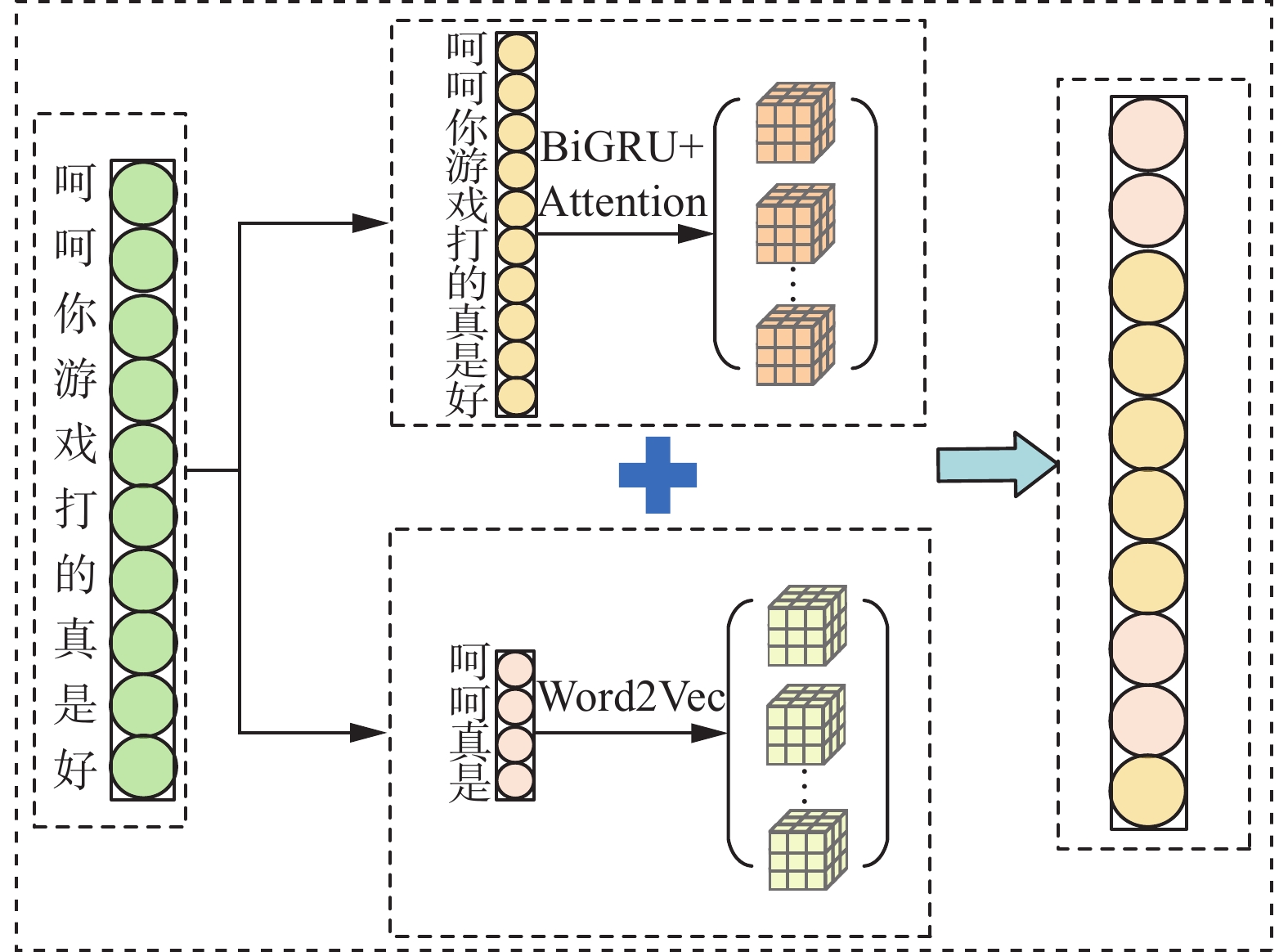 图 3 特征融合流程Fig. 3 Flow chart of feature fusion下载:
全尺寸图片
图 3 特征融合流程Fig. 3 Flow chart of feature fusion下载:
全尺寸图片
3.4 情感分析层
将融合后的句子特征输入到Sigmoid函数中去,使用该分类器对待判定句子进行反讽二分类识别,计算公式为
$$ f(x) = {\text{Sigmoid}}\left(\frac{1}{{1 + {{\rm{e}}^{ - x}}}}\right) $$ (13) 该函数的概率输出在0到1之间,若输出概率不小于0.5,则判定为反讽语句,反之则判定为非反讽,反讽判别步骤如图4所示。
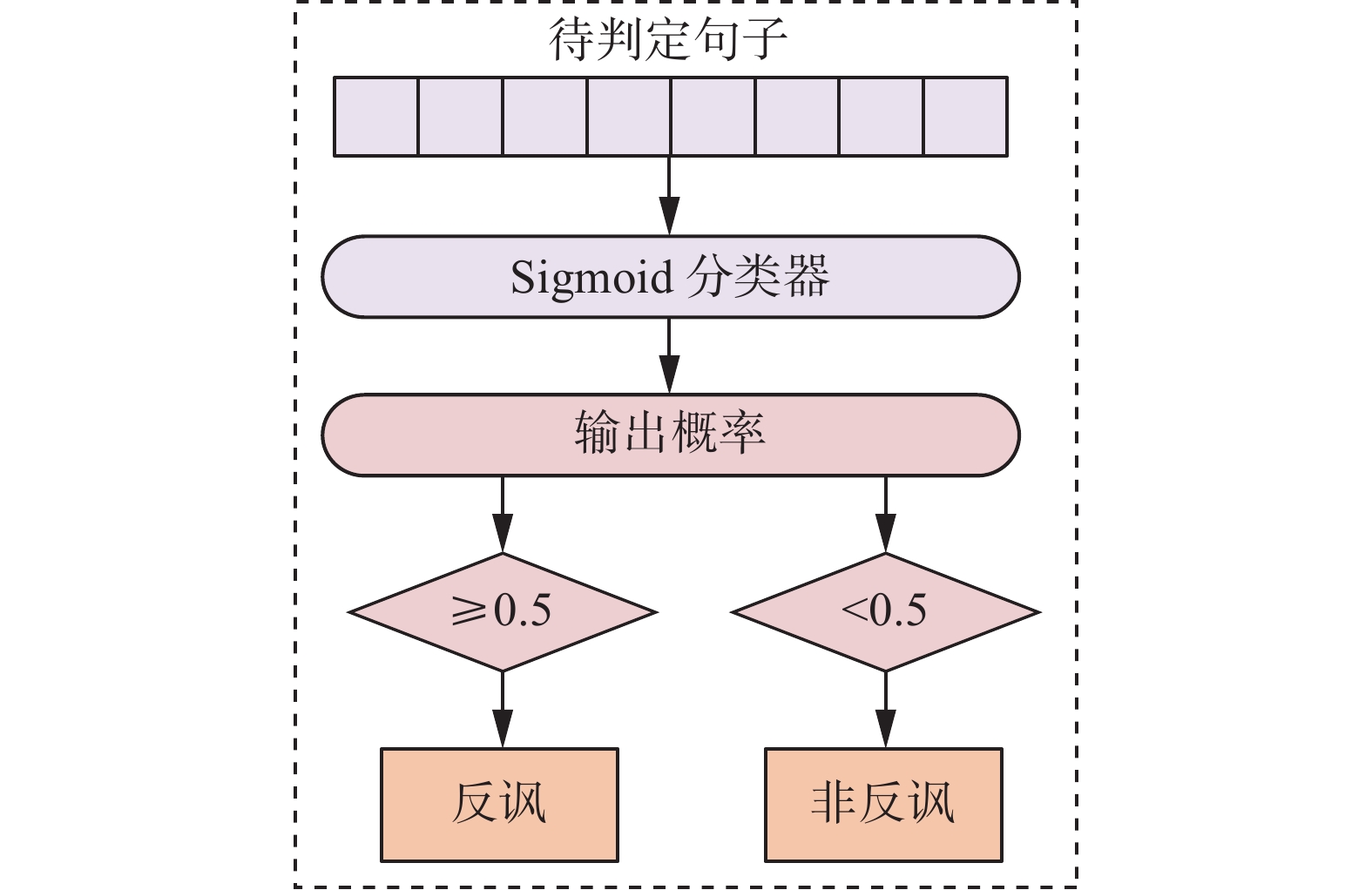 图 4 反讽判别步骤Fig. 4 Ironic discriminant diagram下载:
全尺寸图片
图 4 反讽判别步骤Fig. 4 Ironic discriminant diagram下载:
全尺寸图片
3.5 损失函数
本文模型采用了交叉熵损失函数,计算公式为
$$ {\text{Loss}} = - \sum\limits_i {\sum\limits_j {y_i^j} } \log y' + \lambda ||\theta |{|^2} $$ (14) 式中:
$y$ 为正确标签,$y'$ 为预测标签,$i$ 为句子序号,$j$ 为类别编号,$\lambda $ 为正则化参数,$\theta $ 为超参数。4. 实验及结果分析
为了验证本文提出的融合反讽语言特征的反讽语句识别模型的效果,在本文构建的数据集上进行了实验。本次实验环境为笔记本电脑、MySql5.0和Python3.8。
4.1 实验数据
目前,针对中文反讽语句未有较为权威的官方数据集,对中文反讽语句进行识别的文章也较少,所使用的数据也未公开,因此需要人工标注。本文在军事、特产小吃、星座等相关领域收集了近4万条微博数据并进行了人工标注。在标注的数据中,分别选取了反讽和非反讽的评论各2 000条作为本实验的数据,具体数据集统计如表4所示。表5给出了本文构建数据集中反讽语句的部分内容。
表 4 实验数据集统计Table 4 Statistics of experimental data划分 反讽 非反讽 总计 训练 1 600 1 600 3 200 测试 400 400 800 总计 2 000 2 000 4 000 表 5 实验数据举例Table 5 Examples of experimental data类别 示例 正向
反讽1. 我家木匠的手艺太差劲了!他做的门窗硬是找不到缝,他刨的木板连苍蝇也落不住
2. 你怎么这么沉不住气,不就考个100分嘛
3. 老王也没啥高人之处,除了比我俩多练个十几年负向
反讽1. 很好,连这种电影也要收费了
2. 真棒,一星好评
3. 今天真是撞了大运,又迟到了
4. 世界杯的时候,中国什么都去了,就是中国队没有去
5. 感谢铁道部,居然足足省了五毛4.2 评价指标
实验采用准确率
$P$ 、召回率$R$ 以及${F_1}$ 指数。计算公式为$$ P = \frac{{{N_{{\text{TP}}}}}}{{{N_{{\text{TP}}}} + {N_{{\text{FP}}}}}} $$ (15) $$ R = \frac{{{N_{{\text{TP}}}}}}{{{N_{{\text{TP}}}} + {N_{{\text{FN}}}}}} $$ (16) $$ {F_1} = \frac{{2 \times P \times R}}{{P + R}} $$ (17) 式中:
$ {N_{{\text{TP}}}} $ 为被模型预测为正类的正样本数,$ {N_{{\text{FP}}}} $ 为被模型预测为正类的负样本数,$ {N_{{\text{FN}}}} $ 为被模型预测为负类的正样本数。4.3 参数设置
本文实验通过Word2Vec训练得到的每个词向量为200维,卷积核数为128。在训练中,设Batch_size的大小为32,全连接层正则化参数为0.001。模型训练的迭代次数设置为20,采用Dropout正则化的方式来达到缓解过拟合的目的,设置为0.5。
4.4 实验结果及分析
根据4.3节的实验方法,本文做了如下实验:
在本文构建的数据集上进行实验,采用卡方检验算法对反讽语言进行分析并获取语言特征,并利用Word2Vec对语言特征进行训练,从而获取语言特征的特征表示,同时,使用Bi-GRU与注意力模型获取句子的特征表示,并与语言特征表示进行拼接,输入到分类层,在分类层使用Sigmoid函数对待判定句子。
进行反讽二分类识别,从而识别出反讽语句。与CNN-AT[25]、CNN-Adv[14]、EPSN[16]等3种模型进行了对比实验,实验结果如表6所示,其中加粗表示识别效果最好。从表6可以看出,本文提出的融合反讽语言特征的反讽语句识别模型在本文构建的数据集上的
${F_1}$ 达到77.93%,比EPSN模型高出约4.34个百分点,$P$ 提高了4.38个百分点,$R$ 提高了4.08个百分点。图5给出了本文构建数据集的实验结果。从图5中可以得出以下结论:融合反讽语言特征的反讽语句识别模型在$P$ 、$R$ 以及${F_1}$ 上均有一定提高,反讽语句识别的准确率得到提高的一个重要原因是本文提出的模型考虑了语言信息,利用Word2Vec获取了语言特征,并将其与句子特征进行融合中,丰富了反讽语句的语义信息。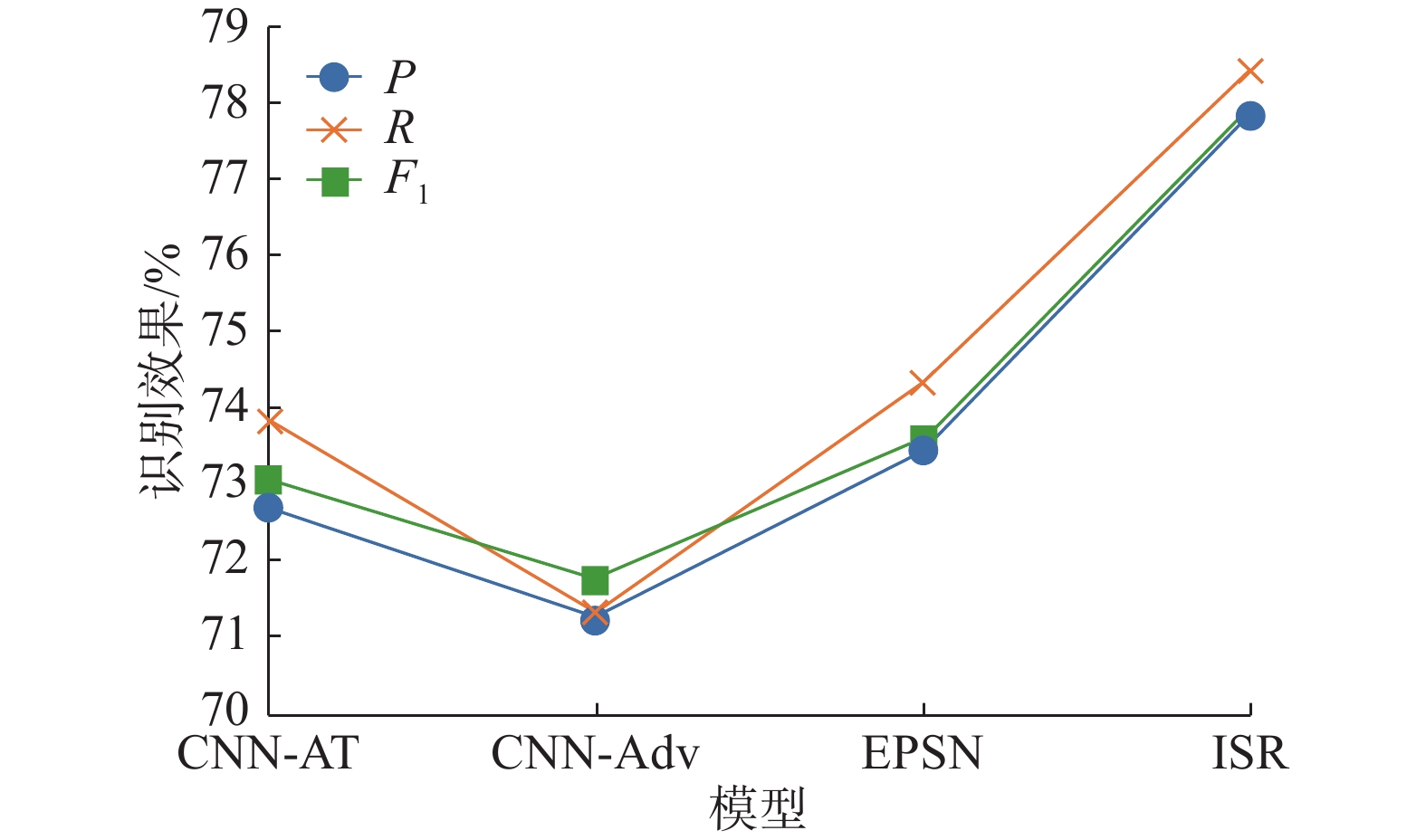 图 5 构建数据集实验结果Fig. 5 Results on constructing data sets下载:
全尺寸图片
图 5 构建数据集实验结果Fig. 5 Results on constructing data sets下载:
全尺寸图片
4.5 消融实验
为验证本文提出的融合反讽语言特征的反讽语句识别模型的有效性,进行了消融实验,实验结果如表7所示。
1)Bi-GRU。为了验证在没有Word2Vec模型下,对Bi-GRU模型造成的影响,本模型只保留了Bi-GRU。从表7中可见,
${F_1}$ 与模型Word2Vec+Bi-GRU相比降低了1.74个百分点,由此可以证明在使用Word2Vec模型下对Bi-GRU模型的有效性。2)Word2Vec+Bi-GRU。为了验证注意力机制对于深入挖掘语义特征方面的影响,对比了在没有注意力机制下的效果。从表7中可见,
${F_1}$ 与本文提出模型ISR相比降低了7.18个百分点,原因是注意力机制可以增强语句中字符之前的链接。由此可以证明注意力机制在本文反讽识别模型中的有效性。3)Bi-GRU-Attention。为了验证Word2Vec获取到的反讽语言特征的有效性,本模型在使用Bi-GRU的基础上,只保留了Attention。从表7中可见,
${F_1}$ 与本文提出模型ISR相比降低了5.52个百分点,由此可以证明加入反讽特征词这一语义信息在本文提出模型ISR中的有效性。上述实验分析表明,本文所提的一种融合语言特征的反讽语句识别模型表现最佳。
5. 结束语
为了丰富反讽语句的语义信息,提高反讽识别的准确率,本文提出了一种融合反讽语言特征的反讽语句识别模型,实现了对反讽语言特征的获取,丰富了语义信息,并将其融入到模型中,优化了模型,提高了准确率。
未来,基于本文提出的反讽语句识别模型,将考虑融入上下文语境进行分析,更好地实现对反讽语句的识别效果。同时,对于已构建的反讽语料库进行扩充,丰富语料库的数据内容。
-
图 1 融合反讽语言特征的反讽语句识别模型
Fig. 1 Ironic sentence recognition model based on ironic language features
下载:
全尺寸图片
图 2 Bi-GRU与注意力机制结构
Fig. 2 Structure diagram of Bi-GRU and attention mechanism
下载:
全尺寸图片
图 3 特征融合流程
Fig. 3 Flow chart of feature fusion
下载:
全尺寸图片
图 4 反讽判别步骤
Fig. 4 Ironic discriminant diagram
下载:
全尺寸图片
图 5 构建数据集实验结果
Fig. 5 Results on constructing data sets
下载:
全尺寸图片
表 1 反讽词汇特征实例
Table 1 Examples of ironic lexical features
词汇特征 词汇 例句 情感副词 实在 这电影实在好看,
我都要睡着了语气词 呵呵 呵呵,你游戏打得
真好,一直送人头网络词 醉了 作业这么多我也是醉了 表 2 搭配规则特征表
Table 2 Collocation rules of feature table
序号 特征 卡方值 1 再···一点 75.352 2 很好···又 70.212 3 可以···一点 69.250 4 可以···再 65.367 5 很好···但是 61.295 表 3 词汇特征表
Table 3 Lexicon of feature table
词汇特征 特征 情感副词 很、太、极好、真是、非常 语气词 呵呵、啊、哇、哟、得了 网络词 醉了、键盘侠、内卷、凡尔赛、躺平 表 4 实验数据集统计
Table 4 Statistics of experimental data
划分 反讽 非反讽 总计 训练 1 600 1 600 3 200 测试 400 400 800 总计 2 000 2 000 4 000 表 5 实验数据举例
Table 5 Examples of experimental data
类别 示例 正向
反讽1. 我家木匠的手艺太差劲了!他做的门窗硬是找不到缝,他刨的木板连苍蝇也落不住
2. 你怎么这么沉不住气,不就考个100分嘛
3. 老王也没啥高人之处,除了比我俩多练个十几年负向
反讽1. 很好,连这种电影也要收费了
2. 真棒,一星好评
3. 今天真是撞了大运,又迟到了
4. 世界杯的时候,中国什么都去了,就是中国队没有去
5. 感谢铁道部,居然足足省了五毛表 6 各模型在构建数据集上的识别效果
Table 6 The recognition effect of each model on constructing data
% -
[1] ZHANG Chuxu, SONG Dongjin, HUANG Chao, et al. Heterogeneous graph neural network[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Anchorage: ACM, 2019: 793−803. [2] YAO Liang, MAO Chengsheng, LUO Yuan. Graph convolutional networks for text classification[J]. Proceedings of the AAAI conference on artificial intelligence, 2019, 33(1): 7370–7377. doi: 10.1609/aaai.v33i01.33017370 [3] CHEN Junjie, HOU Hongxu, JI Yatu, et al. Graph convolutional networks with structural attention model for aspect based sentiment analysis[C]//2019 International Joint Conference on Neural Networks. Budapest: IEEE, 2019: 1−7. [4] WANG Baoxin. Disconnected recurrent neural networks for text categorization[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: Association for Computational Linguistics, 2018: 2311−2320. [5] SUN Zhiqing, YU Hongkun, SONG Xiaodan, et al. MobileBERT: a compact task-agnostic BERT for resource-limited devices[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online. Stroudsburg: Association for Computational Linguistics, 2020: 2158−2170. [6] SUN Yu, WANG Shuohuan, LI Yukun, et al. ERNIE 2.0: a continual pre-training framework for language understanding[J]. Proceedings of the AAAI conference on artificial intelligence, 2020, 34(5): 8968–8975. doi: 10.1609/aaai.v34i05.6428 [7] 翟学明, 魏巍. 混合神经网络和条件随机场相结合的文本情感分析[J]. 智能系统学报, 2021, 16(2): 202–209. ZHAI Xueming, WEI Wei. Text sentiment analysis combining hybrid neural network and conditional random field[J]. CAAI transactions on intelligent systems, 2021, 16(2): 202–209. [8] ZHUANG Yin, LIU Zhen, LIU Tingting, et al. Implicit sentiment analysis based on multi-feature neural network model[J]. Soft computing, 2022, 26(2): 635–644. doi: 10.1007/s00500-021-06486-7 [9] XIANG Chunli, REN Yafeng, JI Donghong. Identifying implicit polarity of events by using an attention-based neural network model[J]. IEEE access, 2019, 7: 133170–133177. doi: 10.1109/ACCESS.2019.2938966 [10] 余本功, 王惠灵, 朱晓洁. 基于BG-DATT-CNN网络的方面级别情感分析[J]. 计算机工程与应用, 2022, 58(24): 151–157. doi: 10.3778/j.issn.1002-8331.2105-0483 YU Bengong, WANG Huiling, ZHU Xiaojie. Aspect-level sentiment analysis based on BG-DATT-CNN network[J]. Computer engineering and applications, 2022, 58(24): 151–157. doi: 10.3778/j.issn.1002-8331.2105-0483 [11] TAY Y, TUAN L A, HUI S C, et al. Reasoning with sarcasm by reading in-between[EB/OL]. (2018–05−08)[2022−09−13]. http://arxiv.org/abs/1805.02856. [12] 卢欣, 李旸, 王素格. 融合语言特征的卷积神经网络的反讽识别方法[J]. 中文信息学报, 2019, 33(5): 31–38. doi: 10.3969/j.issn.1003-0077.2019.05.004 LU Xin, LI Yang, WANG Suge. Linguistic features enhanced convolutional neural networks for irony recognition[J]. Journal of Chinese information processing, 2019, 33(5): 31–38. doi: 10.3969/j.issn.1003-0077.2019.05.004 [13] MEHNDIRATTA P, SONI D. Identification of sarcasm using word embeddings and hyperparameters tuning[J]. Journal of discrete mathematical sciences and cryptography, 2019, 22(4): 465–489. doi: 10.1080/09720529.2019.1637152 [14] 张庆林, 杜嘉晨, 徐睿峰. 基于对抗学习的讽刺识别研究[J]. 北京大学学报(自然科学版), 2019, 55(1): 29–36. ZHANG Qinglin, DU Jiachen, XU Ruifeng. Sarcasm detection based on adversarial learning[J]. Acta scientiarum naturalium universitatis pekinensis, 2019, 55(1): 29–36. [15] SHAH S, CHY A N. Fusion of hand-crafted features and deep semantic features in a unified neural model for irony detection in microblogs[C]//2020 IEEE 8th R10 Humanitarian Technology Conference. Kuching: IEEE, 2020: 1−6. [16] 樊小超, 杨亮, 林鸿飞, 等. 基于多语义融合的反讽识别[J]. 中文信息学报, 2021, 35(6): 103–111. FAN Xiaochao, YANG Liang, LIN Hongfei, et al. Irony recognition based on multiple semantic fusion[J]. Journal of Chinese information processing, 2021, 35(6): 103–111. [17] PANDEY R, KUMAR A, SINGH J P, et al. Hybrid attention-based long short-term memory network for sarcasm identification[J]. Applied soft computing, 2021, 106: 107348. doi: 10.1016/j.asoc.2021.107348 [18] DONG Yuanfang, ZHANG Yitong, LI Jun. DC-BiGRU-CNN algorithm for irony recognition in Chinese social comments[J]. Mathematical problems in engineering, 2022, 2022: 5909033. [19] 潘宏鹏, 汪东, 刘忠轶, 等. 考虑反讽语义识别的协同双向编码舆情评论情感分析研究[J]. 情报杂志, 2022, 41(5): 99–105,111. PAN Hongpeng, WANG Dong, LIU Zhongyi, et al. Public opinion comments sentiment analysis research considering ironic semantic recognition based on the collaborative BERT[J]. Journal of intelligence, 2022, 41(5): 99–105,111. [20] 张铭泉, 周辉, 曹锦纲. 基于注意力机制的双BERT有向情感文本分类研究[J]. 智能系统学报, 2022, 17(6): 1220–1227. ZHANG Mingquan, ZHOU Hui, CAO Jingang. Dual BERT directed sentiment text classification based on attention mechanism[J]. CAAI transactions on intelligent systems, 2022, 17(6): 1220–1227. [21] 曾碧卿, 韩旭丽, 王盛玉, 等. 层次化双注意力神经网络模型的情感分析研究[J]. 智能系统学报, 2020, 15(3): 460–467. ZENG Biqing, HAN Xuli, WANG Shengyu, et al. Hierarchical double-attention neural networks for sentiment classification[J]. CAAI transactions on intelligent systems, 2020, 15(3): 460–467. [22] PANDEY R, KUMAR A, SINGH JYOTI P, et al. Hybrid attention-based long short-term memory network for sarcasm identification[J]. Applied soft computing journal, 2021, 106: 107348. [23] ZHU Dawei, ZHAN Qiusi, ZHOU Zhejian, et al. ConFiguRe: exploring discourse-level Chinese figures of speech[C]//Proceedings of the 29th International Conference on Computational Linguistics. Gyeongju: ACL, 2022: 3374−3385. [24] HAO Y, ZHANG L, ZHENG Q, et al. A multi-scale sarcasm sentiment recognition algorithm incorporating sentence hierarchical representation[C]//Third International Conference on Artificial Intelligence and Computer Engineering. Dalian: SPIE, 2023, 12610: 666−675. [25] LIU Lizhen, ZHANG Donghai, SONG Wei. Exploiting syntactic structures for humor recognition[C]//Proceedings of the 27th International Conference on Computational Linguistics. Santa Fe: ACL, 2018: 1875−1883.









































































