
Two-person interaction recognition based on the interactive relationship hypergraph convolution network model
-
摘要: 为提高学校、商场等公共场所的安全性,实现对监控视频中的偷窃、抢劫和打架斗殴等异常双人交互行为的自动识别,针对现有基于关节点数据的行为识别方法在图的创建中忽略了2个人之间的交互信息,且忽略了单人非自然连接关节点间的交互关系的问题,提出一种基于交互关系超图卷积模型用于双人交互行为的建模与识别。首先针对每一帧的关节点数据构建对应的单人超图以及双人交互关系图,其中超图同时使多个非自然连接节点信息互通,交互关系图强调节点间交互强度。将以上构建的图模型送入时空图卷积对空间和时间信息分别建模,最后通过SoftMax分类器得到识别结果。该算法框架的优势是在图的构建过程中加强考虑双人的交互关系、非自然连接点间结构关系以及四肢灵活的运动特征。在NTU数据集上的测试表明,该算法得到了97.36%的正确识别率,该网络模型提高了双人交互行为特征的表征能力,取得了比现有模型更好的识别效果。Abstract: To enhance the security of schools, shopping malls, and other public places, it is important to achieve automatic identification of abnormal two-person interaction behaviors, such as stealing, robbing, fighting, and assaulting, in surveillance videos. However, the current behavior recognition method based on joint data in graph creation neglects the two-person interaction information as well as the interaction relationship between the single unnatural connection joints. To address this issue, a two-person interaction behavior recognition model based on the interactive relationship hypergraph convolution network is proposed to model and identify human interactions. First, the corresponding single hypergraph and two-person interaction graph are created for the joint-point data of each frame, where the hypergraph makes the information of multiple unnaturally connected nodes interchangeable at the same time, and the interaction graph emphasizes the interaction strength between nodes. The above-constructed graph models are fed into the spatiotemporal graph convolution to model the spatial and temporal information separately, and lastly, the recognition results are acquired by the SoftMax classifier. The benefits of the proposed algorithm framework are that the interactive relationship between two persons, the structural relationship between unnatural connections, and the flexible motion characteristics of limbs are regarded in the graph construction process. Tests on the NTU data set demonstrate that the algorithm attains a correct recognition rate of 97.36%. The findings indicate that the network model enhances the ability to represent the characteristics of two-person interaction and has better recognition performance than the current models.
-
Keywords:
- two-person interaction /
- behavior recognition /
- skeleton node data /
- deep learning /
- ST-GCN /
- hypergraph /
- graph structure /
- neural networks
-
随着计算机科学技术的迅速发展,基于视频的双人交互行为识别已经成为计算机视觉领域的研究热点[1-2],且取得了一定的研究进展。RGB视频获取简单且包含丰富的外观信息,但缺少深度维度信息,对于复杂行为的识别准确性不高[3]。Kinect设备获取的人体三维关节点数据表达信息全面,且数据简便,不仅可以记录每个人关节的运动信息,也可以记录双人关节之间的交互信息[4-6]。深度学习的方法与关节点数据有效融合,为提高双人交互行为识别的精度提供了新的解决方案。
目前针对骨架关节点数据,基于深度学习识别方法主要分为三类:基于循环神经网络(recurrent neural network, RNN)的方法[7]、基于卷积神经网络(convolutional neural networks, CNN)的方法[8]、基于图卷积神经网络(graph convolution network, GCN)的方法[9]。其中基于RNN的方法侧重对行为时序关系的表示,Liu等[10]提出时空长短时记忆网络(spatial-temporal long short-term memory, ST-LSTM),通过对原始关节数据进行树状结构排列建立关节点间关系,送入LSTM进行时序建模与识别,该类方法往往缺少空间信息的合理表示。基于CNN的方法试图学习双人之间交互的动态表征,Choutas等[11]将关节点序列以颜色编码的方式进行图像化,并用CNN对图像提取特征,该算法实现简单,但是其以颜色编码方式压缩时序维度,造成了无法弥补的信息损失。
基于CNN和RNN的方法往往将原始骨架数据转化为网格状的输入,只考虑卷积核内相邻的共现特征,不能充分利用关节点数据的结构信息。近几年,基于GCN的方法以一种更灵活的方式处理关节点数据,将卷积从图像推广到图,可以很好地探索关节点之间的结构关系。Yan等[12]首先将GCN引入基于关节点的动作识别中,提出了时空图卷积网络(spatial temporal GCN, ST-GCN),构造一个以关节点为顶点,以人体结构自然连接为边的时空图,用 SoftMax分类器将图中高级特征映射为相应的动作类别。在此基础上,Cheng等[13]提出了一种改进的移位图进化网络(shift-GCN)来增强空间图的表达能力,其中移位图操作为空间图和时间图提供了灵活的感受野。研究表明行为识别中动作在空间域上的变化幅度要大于在时间域上的,因此Song等[14]提出丰富的激活图卷积网络(richly activated GCN, RAGCN),该网络通过对每个邻接矩阵学习新的权重来突出边的重要性。以上方法在双人行为识别中独立识别单人构造的自然连接图,未考虑非自然连接点(如手、脚)交互关系和双人之间交互关系,在交互动作识别中没有显式地构建图结构,难以学习无物理联系的关节间的关系[15]。针对ST-GCN预定图中非自然连接,距离远且信息不互通的问题,Li等[16]提出动作结构图卷积网络(actional-structural GCN, AS-GCN),通过引入额外的邻接矩阵的方式,建立动作相关的依赖,这种表征动作连接的邻接矩阵可以视为一种新的、用来表征非自然连接关节点间动作相关性的邻接矩阵。为了表示双人交互关节点间的关系,成科杨等[17]把两人作为一个整体,将两人间交互关节连接为边构建为交互连接图,保留了双人运动的局部交互信息。Wu等[18]提出行动者关系图卷积(actor relation GCN, ARGCN)对关系图进行关系推理,根据个体的位置和特征,以个体之间的连接为边建立多个关系图。将各个关系图的结果融合在一起,生成所有参与者个体的关系表示,分别进行个体行为识别和群组行为识别。Chen等[19]提出通道拓扑细化图卷积网络(channel-wise topology refinement GCN, CTR-GCN)来动态学习不同的拓扑图,并有效地聚合不同通道的关节特征。Lee等[20]提出层次分解图卷积网络(hierarchically decomposed GCN, HD-GCN) 将每个关节节点分解为多个集合,提取主要的相邻边和远边,并利用其构建包含这些边的HD-Graph,令这些边位于人体骨骼的相同语义空间中。
根据以上分析,为解决预定的关节点连接图仅表示人体物理结构,对非自然连接和交互关节点间的关系无法有效表达的问题,现阶段研究试图直接连接单人非自然连接点和双人间交互关节点作为普通边,来获取非自然连接点间和交互关节点间信息,但该方法只能表达关节点间物理结构关系,未能有效利用灵活的四肢关系特征以及双人交互相关性特征。
为有效利用关节点运动特征识别双人交互动作,提出一种基于交互关系超图卷积模型的双人交互行为识别算法。首先针对仅用普通边连接成的图结构无法有效表达非自然连接点间信息的问题,构造以四肢为超边的人体图结构,有效利用最能区分动作类别的四肢运动特征,且用超图结构打破传统图结构的局限性,实现多个非自然关节点间信息互通。再针对用普通边连接成的图结构无法有效表达双人交互信息的问题,构造双人交互关系图结构,通过提取交互关节之间连接的强度关系作为交互动作特征。最后将构建的人体超图和交互关系图嵌入ST-GCN,将图结构与时空图卷积相结合,更有效地提取关节点间以及帧间的依赖信息。试验结果表明,所提算法在识别率上得到大幅度的提升,同时与现有算法比较,验证了所提方法的有效性。
1. 算法框架
本研究提出一种基于交互关系超图卷积模型的双人交互行为识别算法,该算法将以四肢为超边的人体超图和双人交互关系图与ST-GCN网络结合,算法框架如图1所示。
 图 1 算法整体流程Fig. 1 Overall flow of proposed algorithm
图 1 算法整体流程Fig. 1 Overall flow of proposed algorithm 下载:
全尺寸图片
下载:
全尺寸图片
主要步骤包括:
1) 构建人体超图。首先对人体四肢构建超边,将四肢超边与人体自然连接图联合构建出人体超图,用于表示人体非自然连接点之间交互关系,充分利用运动时最灵活的四肢关节点特征,并用超图概念实现关节点间信息互通。
2) 构建交互关系图。构建双人交互连接,通过计算双人各个对应关节点的反向距离,进而推算出交互的连接强度矩阵,充分考虑突出双人间交互行为信息。
3) 人体超图和交互关系图嵌入ST-GCN。将构建的人体超图与交互关系图嵌入ST- GCN,利用ST-GCN 对所创建的交互身体模型提取四肢交互特征和双人交互行为的时空特征。
4) 识别分类。将ST-GCN处理后得到的特征向量送入SoftMax,生成分类概率进行交互识别。
2. 构建人体超图
现阶段研究中使用的关节点连接图是预定义的,仅表示人体物理结构,对非自然连接点间的交互信息无法有效表达。例如走路,双手双脚之间的关系很重要,但是ST-GCN预定义的人体图中彼此距离很远,而且图中一条边只能包含2个关节点,因此不能在四肢间实现信息互通。这就是传统图结构的局限性,其很容易忽视掉一些高阶结构信息。为了尽可能地保存高阶信息,引入超图(Hypergraph)这一工具[21-22]。超图是一种广义上的图,其边可以和任意数量的顶点连接。
定义人体超图由自然连接的关节点和构建的四肢超边构成,如图2(a)所示。其中四肢超边用
$ {G_H} = \left( {V,{E_h}} \right) $ 表示,$V$ 代表一帧中所有的关节点构成的集合,${E_h}$ 是$V$ 的非空子集称为超边集合,使用超边连接多个相关的关节,包括非自然连接的关节,如手和脚,如图2(b)所示。Yadati等 [23] 提出了具有相同潜在动机的超图拉普拉斯,其讨论的超图的一个特殊方面是,每个超边e都是由单个的一对简单边$ \{{i}_{e},{j}_{e}\} $ 表示的,这个简单边可能会随着时间的变化而变化。已有研究表明,广义超图拉普拉斯算子满足文献[23] 给出的上述拉普拉斯算子所满足的所有性质,借鉴以上思想使用不带权值的初始特征构造带中间介质的超图拉普拉斯矩阵,具有中间介质的超图拉普拉斯中每个超边中简单边的权值之和为1,如图2(c)所示。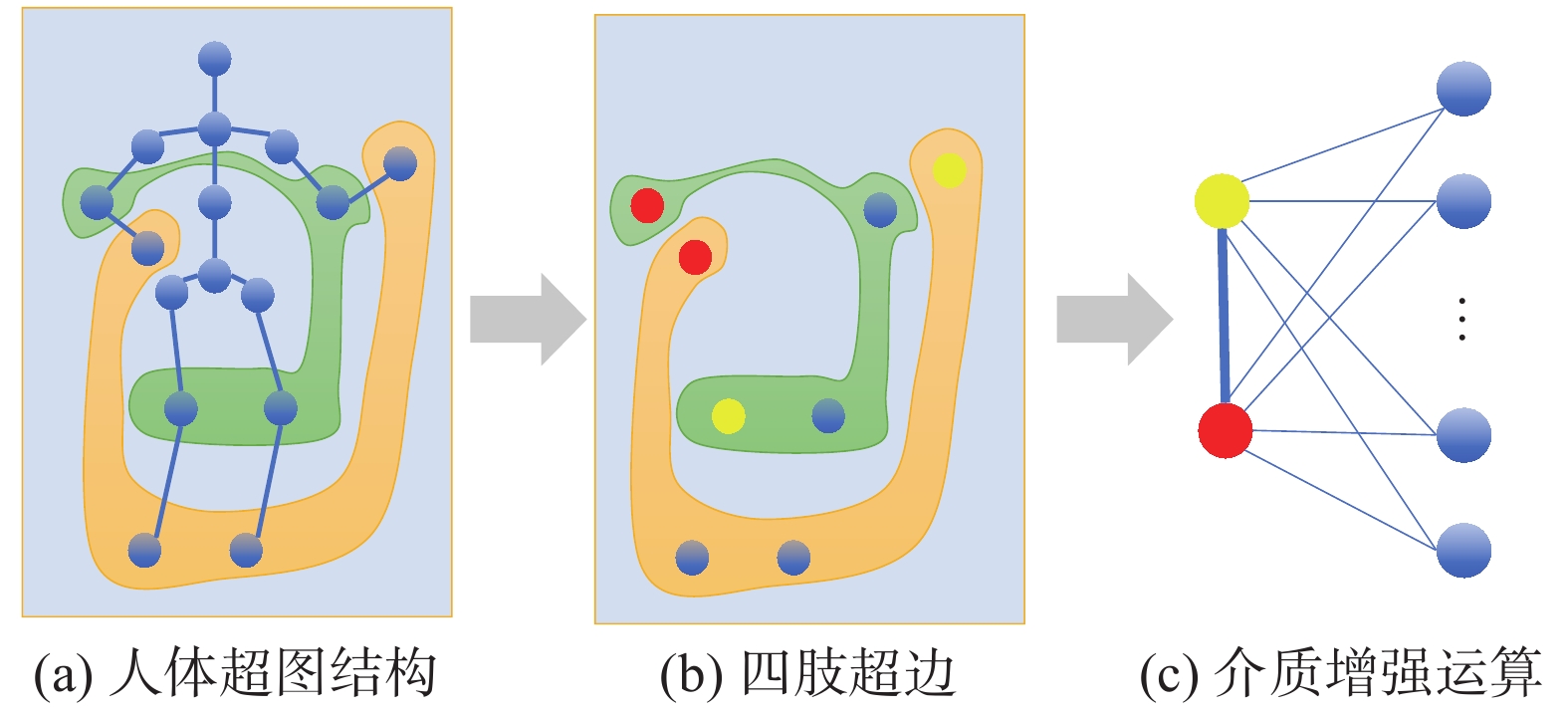 图 2 单人超图结构的创建Fig. 2 Creation of single-player hypergraph structures下载:
全尺寸图片
图 2 单人超图结构的创建Fig. 2 Creation of single-player hypergraph structures下载:
全尺寸图片
常用的双人交互行为识别数据集中关节点标号如图3所示,四肢作为超边的人体超图计算过程如下:首先定义四肢超边的关系矩阵为
$ {{\boldsymbol{A}}_3} = {\rm{diag}}\left( {{{\boldsymbol{A}}_1},{{\boldsymbol{A}}_2}} \right) $ ,其中$ {{\boldsymbol{A}}_1} $ 和$ {{\boldsymbol{A}}_2} $ 分别表示2个超边${{\boldsymbol{A}}_1} = {{\boldsymbol{A}}_2} = {\left[ {\begin{array}{*{20}{c}} {\text{1}}&{\text{1}}&{\text{1}}&{\text{1}} \end{array}} \right]^{\rm{T}}}$ ,$ {{\boldsymbol{A}}_1} $ 中关节点序号分别为8、12、15、9,$ {{\boldsymbol{A}}_2} $ 中关节点序号分别为6、10、14、18。定义超边度矩阵${{\boldsymbol{D}}_e} = {\rm{diag}}\left( {4,4} \right)$ ,矩阵大小为超边的个数,对角数值为每条超边中包含的节点个数,构建的人体超图结构包括2个超边,每条超边中有4个关节点。然后将各个超边权值分别设为${\omega _1}$ ,${\omega _2}$ ,则超边权值矩阵${\boldsymbol{W}} = {\rm{diag}}\left( {{\omega _1},{\omega _2}} \right)$ 。由此计算得到该矩阵的拉普拉斯矩阵$ {{\boldsymbol{L}}_1} $ 。在人体自然连接普通图邻接矩阵基础上,赋予超图拉普拉斯矩阵权重,得到以四肢为超边的人体超图拉普拉斯矩阵$ {{\boldsymbol{A}}_H} $ 。该超图的拉普拉斯矩阵依然是以节点与节点之间的关系为核心,但相较于普通图,不仅实现了非自然连接点间信息互通,而且每条边不局限于两点之间邻接关系,实现四肢权重互通。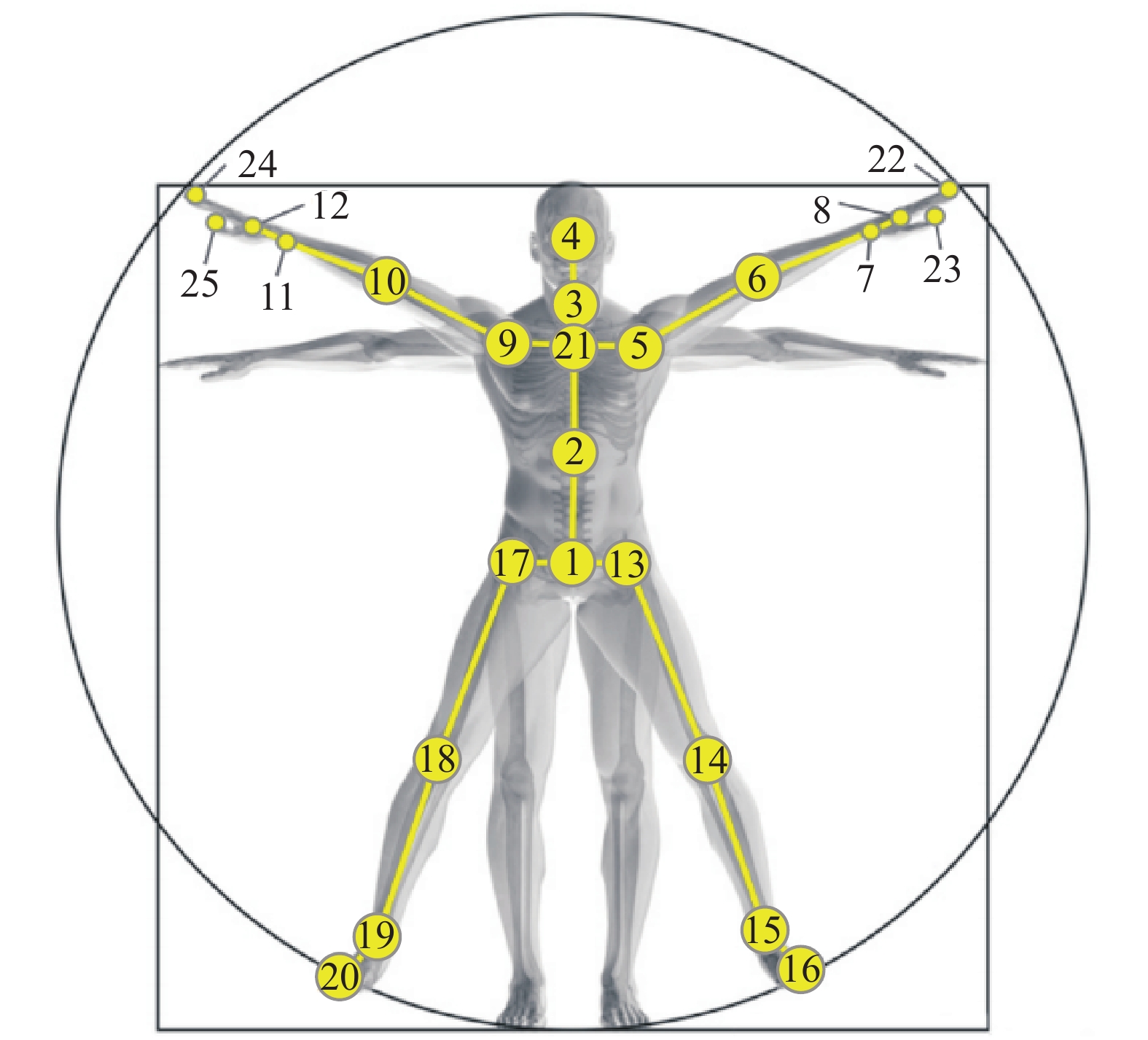 图 3 NTU数据集人体关节点Fig. 3 NTU data set human node下载:
全尺寸图片
图 3 NTU数据集人体关节点Fig. 3 NTU data set human node下载:
全尺寸图片
3. 构建交互关系图
为充分考虑交互依赖关系,突出表示双人之间交互信息的重要性,双人交互特征的提取是对交互身体关节对的帧内特征的提取,通过计算第1个人的每个节点到第2个人的每个节点的反向距离,决定关系连接的强度,这些连接将分离骨架图中的节点连接起来,如图4所示,从而来捕捉两人之间的交互特征。
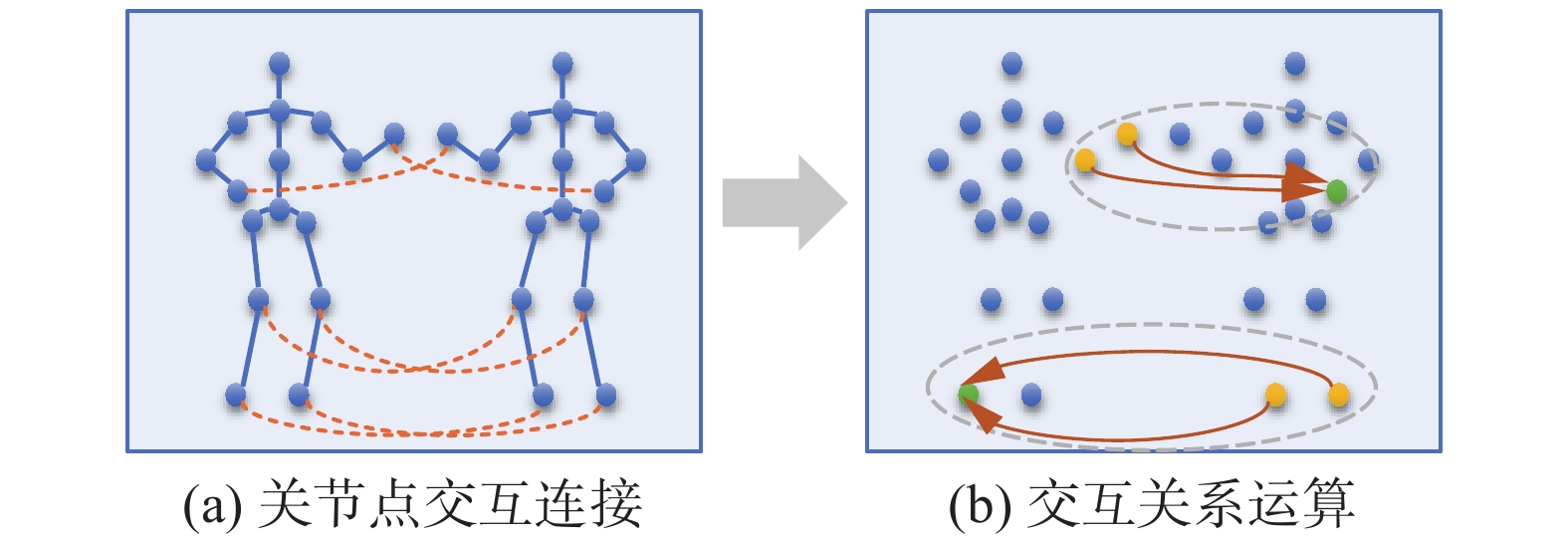 图 4 双人交互关系结构的创建Fig. 4 The creation of a two-person interactive relationship structure下载:
全尺寸图片
图 4 双人交互关系结构的创建Fig. 4 The creation of a two-person interactive relationship structure下载:
全尺寸图片
用
$\hat A$ 表示几何关节相关性,计算公式为$$ \hat A\left[ {t,i,j} \right] = \exp \left( { - - \frac{{{{\left. {\left\| {{F_{{\rm{in}}}}\left( {v_{0,i}^t} \right) - {F_{{\rm{in}}}}\left( {v_{1,{{j}}}^t} \right)} \right.} \right\|}^2}}}{{{C_{{\rm{in}}}}}}} \right) $$ (1) 式中:
$v_{0,i}^t$ 、$v_{1,j}^t$ 分别表示第t帧中两人的第i个关节;${C_{{\rm{in}}}}$ 为输入通道数;$ {F_{{\rm{in}}}}\left( {v_{0,i}^t} \right) $ 、${F_{{\rm{in}}}}\left( {v_{1,j}^t} \right)$ 分别为2个人的输入特征映射,定义${F_{{\rm{in}}}}\left( {v_{m,i}^t} \right) = S_{m,i}^t$ $ \left(S_{m, t}^{t} \in {\rm{R}}^{M \times C_{m} \times T \times N}\right) $ 。${F_{{\rm{in}}}}\left( {v_{m,i}^t} \right) $ 测量了两人之间各个节点的反向距离,$v_{0,i}^t$ 、$v_{1,j}^t$ 之间的欧氏距离越小,$\hat A$ 值越大,代表交互关系越强。为了防止过度拟合和过滤掉不相关的连接,用整流单元直接过滤掉不相关的连接。这个操作有效地消除薄弱环节,从而强调最相关的环节,只保留大多数相关连接,可以帮助模型提取出最具识别性的交互特征。比如,握手时双方脚没动,只保留上肢交互特征。整流公式被定义为
$$ \overline{A}\left[t,i,j\right]=\left\{ \begin{array}{l}\hat{A}\left[t,i,j\right]\text{ }\text{,}\hat{A}\left[t,i,j\right]\geqslant 0.5\\ 0\text{,}其他\end{array}\right. $$ (2) 最后用方程归一化为
$$ {{\boldsymbol{A}}_I} = {\boldsymbol{D}}_{\text{r}}^{ - \frac{1}{2}}\bar {\boldsymbol{A}}{\boldsymbol{D}}_{\text{c}}^{ - \frac{1}{2}} $$ (3) 得出的双人交互关系矩阵
${{\boldsymbol{A}}_I}$ ,用来在数学上表示动作序列中所有帧的关系图和人体超图关系图。4. 人体超图和交互关系图嵌入ST- GCN
ST-GCN网络结构如图5所示,首先做归一化(batch normalization, BN)处理,并在进行图卷积之前,加入注意力模型(attention model,AM)。在运动过程中,不同的关节点重要性是不同的,因此,ST-GCN 对不同关节点进行了加权,且每个 ST-GCN单元都训练不同的权重参数。接着,该模型通过不断堆叠ST-GCN,从图结构输入中持续提取高级的语义特征,交替使用 GCN 和时间卷积网络(temporal convolutional network, TCN),对时间和空间维度进行变换。最后,引入全局平均池化(global average pooling, GAP)以及全连接层(fully convolutional network,FCN)输出预测分支。
 图 5 ST-GCN网络结构Fig. 5 ST-GCN network structure diagram下载:
全尺寸图片
图 5 ST-GCN网络结构Fig. 5 ST-GCN network structure diagram下载:
全尺寸图片
嵌入时空图卷积融合人体超图结构和双人交互关系图结构,以此捕捉关节点之间更丰富的相关性特征,并提取到更丰富有效的判别性特征。图结构嵌入时空图卷积的具体结构如图6所示,其结构由空间卷积和时间卷积交替组合而成。为了提取到丰富的关节点相关特征,空间卷积操作由2个分支组成,分别是人体超图、双人交互关系图所对应的关系矩阵
$ {{\boldsymbol{A}}_H} $ 、$ {{\boldsymbol{A}}_I} $ 。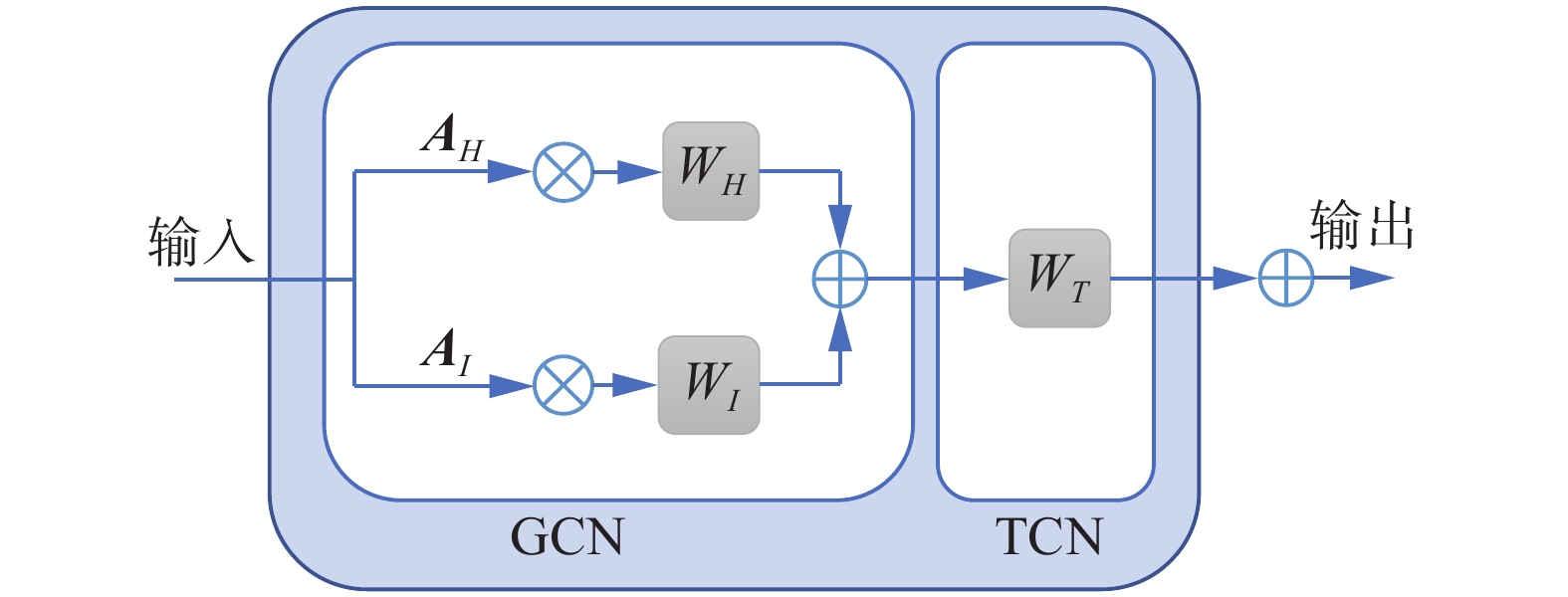 图 6 图结构嵌入时空图卷积结构Fig. 6 Graph structure embedded space-time graph convolution下载:
全尺寸图片
图 6 图结构嵌入时空图卷积结构Fig. 6 Graph structure embedded space-time graph convolution下载:
全尺寸图片
空间卷积操作分别用图卷积提取2个图结构的特征,然后对其特征通过对应元素逐点相加的方式进行融合。用图集
$G = \left\{ {\left. {H,I} \right\}} \right.$ 表示其组合,空间卷积操作可以被表示为$$ {{\boldsymbol{F}}_{{\rm{out}}}} = \sum\limits_{g \in G} {\sigma \left( {{{\boldsymbol{W}}_g}{{\boldsymbol{F}}_{{\rm{in}}}}\left( {{{\boldsymbol{A}}_g} \circ {{\boldsymbol{M}}_g}} \right)} \right)} $$ (4) 式中:
${{\boldsymbol{A}}_g}$ 代表图邻接矩阵;$ {{\boldsymbol{M}}_g} $ 代表可学的权重分配重要性;$ {{\boldsymbol{F}}_{{\rm{in}}}} $ 是输入特征向量;$ {{\boldsymbol{W}}_g} $ 代表边缘惊醒线性特征变换;$ \circ $ 代表逐元素相乘;$\sigma $ 是修正线性单元(rectified linear unit, ReLu);$ {{\boldsymbol{F}}_{{\rm{out}}}} $ 是输出特征向量。将人体超图和交互关系图嵌入至ST-GCN 单元中,矩阵在GCN中进行运算,实现空间维度信息的聚合,利用TCN网络实现时间维度信息的聚合。叠加10个ST-GCN单元,这些ST-GCN单元具有不同的输出通道和时间跨度。前4个ST-GCN单元有64个输出通道,中间3个有128个输出通道,后3个有256个通道。第5和第8个ST-GCN单元的时间跨度是2,其他的是1。实现双人交互关系图结构和超图结构与时空图卷积结合成为交互关系超图卷积模型。
5. 试验结果分析
5.1 数据集介绍
在NTU RGB+D[24]数据集上进行训练与测试,该数据集是目前最大的行为识别数据集,是利用Kinect v2相机获得,包含RGB视频帧、深度信息和3D关节点信息。该数据集包含56000个视频序列,共60类动作。包括40类日常行为、9类医疗健康相关行为以及11类双人交互行为。采用关节点数据中的11类交互动作(Mutual),对所提算法进行评估,即击打、踢、推、指、拥抱、递物品、握手、靠近、远离、摸口袋和拍背,骨架数据结构图如图7所示。该数据集的官方评估方法的协议有2种类型:交叉受试者(cross-subject, CS)和交叉视角(cross-view, CV)。CV按相机编号划分,三台相机角度分别为−45°、0°、45°,为应对实际场景中视角不同且多变的情形,本试验根据CV协议进行评估,共采用8408个双人交互行为视频数据,训练集是由5606个2号摄像头和3号摄像头捕获的视频,验证集是由2802个1号摄像头捕获的视频,训练集与验证集比例为2∶1。
 图 7 NTU RGB+D骨架数据示例Fig. 7 NTU RGB+D skeleton data example下载:
全尺寸图片
图 7 NTU RGB+D骨架数据示例Fig. 7 NTU RGB+D skeleton data example下载:
全尺寸图片
5.2 试验结果
遵循文献[25]中NTU-RGB+D的数据预处理过程。输入张量的形状为M (2)×C (3)×T (300)×N (25)。对于一个batch的视频用4维矩阵(M, C, T, N)表示,其中M代表视频中实施动作的人数,C代表关节的特征维度,T代表一个视频帧的数量,N代表关节的数量,这里是25个关节。
试验在Ubuntu16.04操作系统下进行,采用基于Python3.7的深度学习框架Pytorch, GPU为NIVIDIA 1080 Ti的深度学习环境。将 NTU 数据集中交互部分的关节点数据以行为类别进行划分,按照 CV 标准进行训练测试。经过时空卷积得到的张量用BN层归一化,并由ReLu层激活。由于硬件的限制,对NTU-RGB+D (Mutual)的批处理大小设定为10,初始学习率设置为0.01,使用交叉熵损失函数计算损失,并使用随机梯度下降法(stochastic gradient descent, SGD)算法进行优化。本试验采用 50 次迭代进行训练,得到的训练集和测试集对应的准确率和损失函数的变化曲线如图8所示。
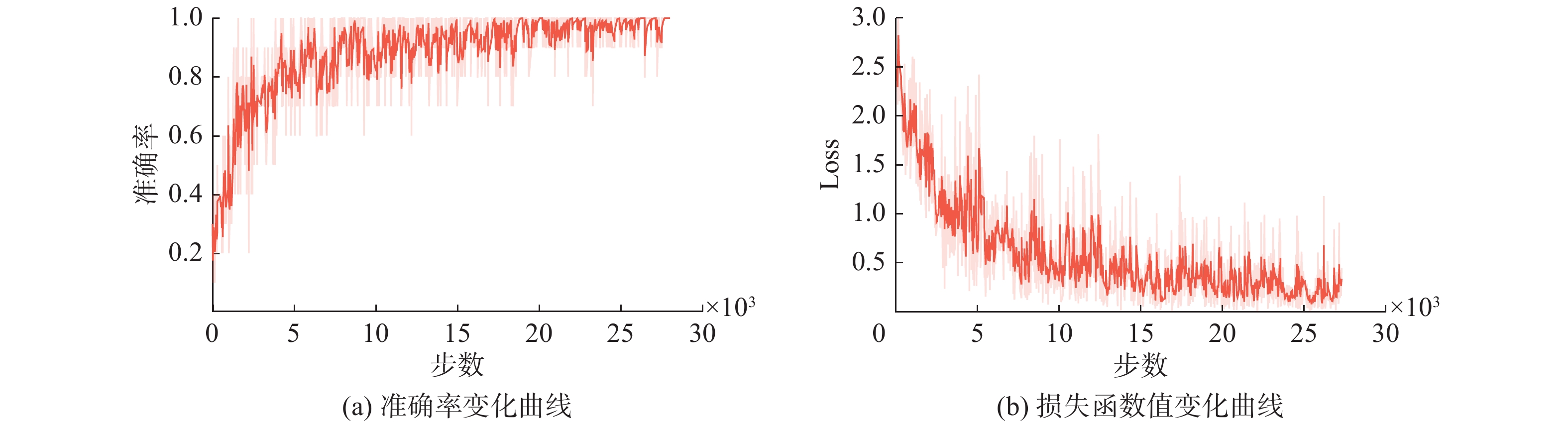 图 8 交互关系超图卷积模型训练准确率和损失函数值Fig. 8 Interactive relationship hypergraph convolution model training accuracy and loss function value下载:
全尺寸图片
图 8 交互关系超图卷积模型训练准确率和损失函数值Fig. 8 Interactive relationship hypergraph convolution model training accuracy and loss function value下载:
全尺寸图片
由图8可以看出,模型最终收敛趋于稳定,最终得到的最高识别率为97.36%。损失函数值为0.09188。为了进一步分析模型的性能,进行了对比试验。
5.3 对比分析
为了进一步验证该算法的有效性,将分2种情况对试验结果进行对比分析。首先验证双人交互连接强度的有效性,其次验证人体超图的有效性,以上试验在NTU RGB+D (Mutual)数据库下进行训练与测试。
5.3.1 验证双人交互连接强度的有效性
ST-GCN模型在NTU-RGB+D(Mutual)的CV基准上进行试验,加入双人交互关系矩阵后在同一环境下试验,对应的准确率和损失函数的变化曲线如图9所示,生成混淆矩阵分别如图10图11所示。
 图 9 交互关系图卷积模型训练准确率和损失函数值Fig. 9 Interactive relationship graph convolution model training accuracy and loss function value下载:
全尺寸图片
图 9 交互关系图卷积模型训练准确率和损失函数值Fig. 9 Interactive relationship graph convolution model training accuracy and loss function value下载:
全尺寸图片
 图 10 ST-GCN混淆矩阵Fig. 10 ST-GCN confusion matrix下载:
全尺寸图片
图 10 ST-GCN混淆矩阵Fig. 10 ST-GCN confusion matrix下载:
全尺寸图片
 图 11 引入交互关系混淆矩阵Fig. 11 ST-GCN(Interaction) confusion matrix下载:
全尺寸图片
图 11 引入交互关系混淆矩阵Fig. 11 ST-GCN(Interaction) confusion matrix下载:
全尺寸图片
从上面ST-GCN的混淆矩阵可以看出,在指、拍、推、打这几类上肢动作之间,如果不提取交互关系的情况下会出现大量混淆。这是由于ST-GCN单独提取每个人体特征,而不是同时提取两人的交互特征,在指、拍背、推、打这几类动作,都是一人不动,另一人抬起上肢,对于单独个体来说动作相似,因此容易混淆。加入双人交互关系后,以上几类容易混淆的交互动作分类出错情况明显减少,这些交互特性有助于更好地区分交互行为。证明了双人交互关系图有效地提取了交互信息特征,且交互关系图与ST-GCN模型是高度兼容的。
5.3.2 验证人体超图的有效性
在加入双人关系的基础上,加入人体超图结构,观察其对交互行为识别的贡献,对应的准确率和损失函数的变化曲线如图12所示。由图13的3个模型在11种交互动作上的准确率对比可以看出,加入交互连接强度关系后,有相似特性的上肢交互行为类别准确率得到大幅度提升,加入超图后的模型在每类交互动作识别中都有些提升,尤其在击打、踢、拥抱这些四肢运动幅度大的动作识别更准确,说明超图更有效表达个体运动特征,从而使交互行为识别准确率有所提升。
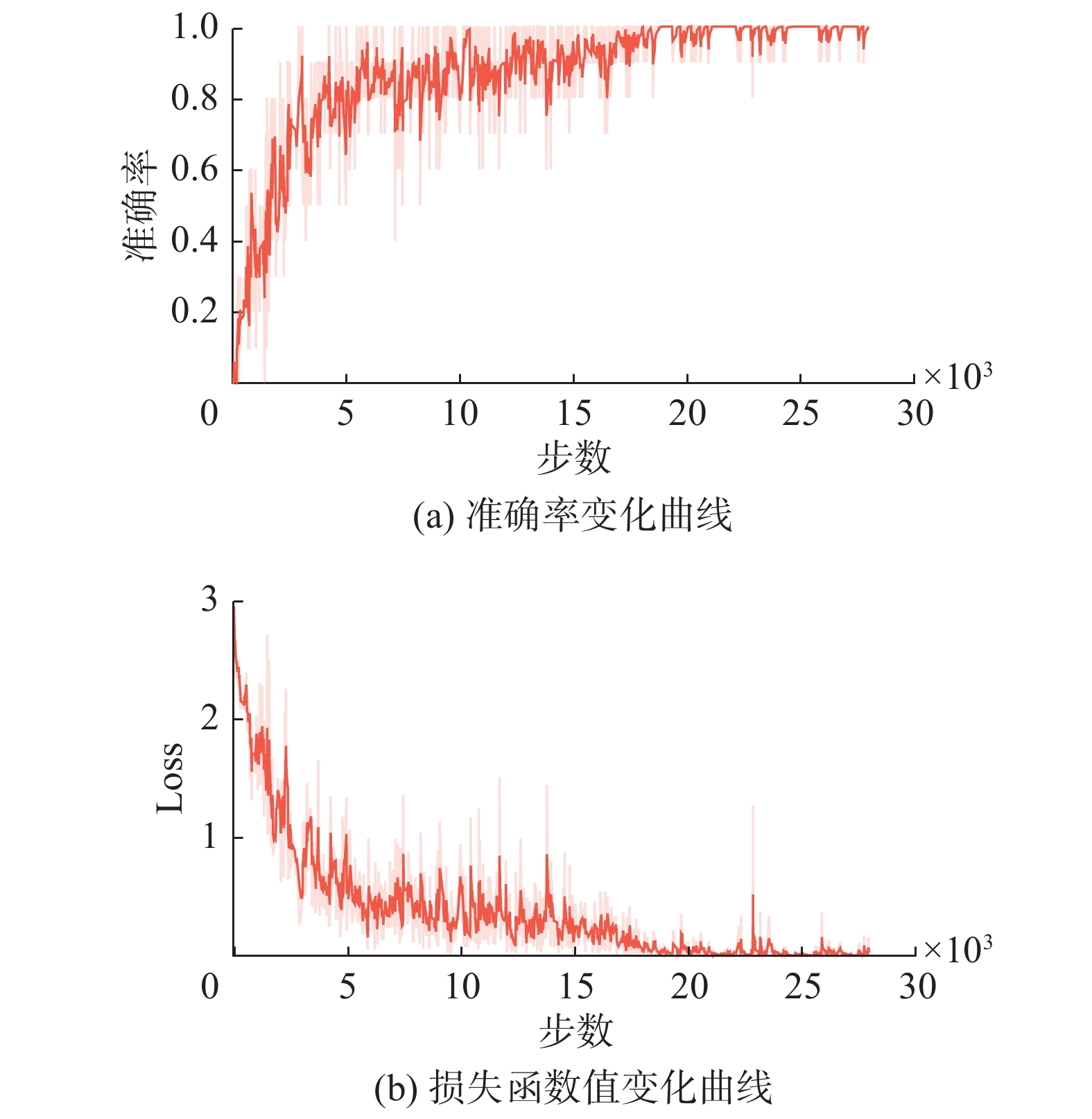 图 12 人体超图卷积模型训练准确率和损失函数值Fig. 12 Body hypergraph convolution model training accuracy and loss function value下载:
全尺寸图片
图 12 人体超图卷积模型训练准确率和损失函数值Fig. 12 Body hypergraph convolution model training accuracy and loss function value下载:
全尺寸图片
 图 13 比较3个模型在11种交互动作上的准确率Fig. 13 Accuracy of the three models on 11 kinds of interaction actions was compared下载:
全尺寸图片
图 13 比较3个模型在11种交互动作上的准确率Fig. 13 Accuracy of the three models on 11 kinds of interaction actions was compared下载:
全尺寸图片
比较这3种算法在NTU-RGB+D (Mutual) CV上的分数,如表1所示,与基线模型ST-GCN相比,加入双人交互图结构后识别准确率提高了4.61个百分点,加入交互图结构与超图结构后准确率比ST-GCN提高了6.34个百分点。试验结果证明了人体超图结构和双人交互图结构的有效性。
表 1 消融结果对比Table 1 Comparison of ablation results模型名称 双人交互 超图结构 识别结果/% ST- GCN × × 91.02 ST-GCN(Hypergraph) × √ 94.69 ST-GCN(Interaction) √ × 95.63 本研究算法 √ √ 97.36 5.4 与其他算法对比
为了验证所提出模型的有效性,将试验结果与基于关节点数据的其他方法在NTU RGB+D数据库下进行试验的结果对比,如表2所示。
由表2可以看出,用GCN处理关节点数据比文献[10]采用ST-LSTM的方法准确率有了大幅度的提高,说明加强对图结构的学习可以更有效地提取基于关节点的行为特征。文献[12-14,16]提出的双人交互行为识别算法均采用ST-GCN及改进的图结构算法,但未考虑多个非自然连接关节点间的信息交互问题以及双人之间的交互关系,导致准确率并没有明显突破。与以上算法相比,本研究提出的基于交互关系超图卷积模型的双人交互行为识别算法通过创新图结构实现多个非自然连接节点间信息交互,获得了最好的识别结果,验证了此模型的优越性。
6. 结束语
本研究提出基于交互关系超图卷积模型的双人交互行为识别算法,设计交互关系矩阵来表示交互关系图结构,结合几何特征表达2个人关节点的交互强度关系。设计以四肢为超边的超图拉普拉斯矩阵来表示人体超图结构,实现多个非自然连接关节间交互信息,强调了运动时的人体协调特征。通过多层时空卷积层来构建网络的主干,充分利用运动时人体关节间的空间和时间依赖性,发现关节点之间的潜在关系,从而更高效识别,同时证明了上述图结构与ST-GCN模型的兼容性。试验证明所提出的模型在双人交互识别方面表现出卓越的能力,在NTU的交互数据集上得到了令人满意的识别精度。
-
图 1 算法整体流程
Fig. 1 Overall flow of proposed algorithm
下载:
全尺寸图片
图 2 单人超图结构的创建
Fig. 2 Creation of single-player hypergraph structures
下载:
全尺寸图片
图 3 NTU数据集人体关节点
Fig. 3 NTU data set human node
下载:
全尺寸图片
图 4 双人交互关系结构的创建
Fig. 4 The creation of a two-person interactive relationship structure
下载:
全尺寸图片
图 5 ST-GCN网络结构
Fig. 5 ST-GCN network structure diagram
下载:
全尺寸图片
图 6 图结构嵌入时空图卷积结构
Fig. 6 Graph structure embedded space-time graph convolution
下载:
全尺寸图片
图 7 NTU RGB+D骨架数据示例
Fig. 7 NTU RGB+D skeleton data example
下载:
全尺寸图片
图 8 交互关系超图卷积模型训练准确率和损失函数值
Fig. 8 Interactive relationship hypergraph convolution model training accuracy and loss function value
下载:
全尺寸图片
图 9 交互关系图卷积模型训练准确率和损失函数值
Fig. 9 Interactive relationship graph convolution model training accuracy and loss function value
下载:
全尺寸图片
图 10 ST-GCN混淆矩阵
Fig. 10 ST-GCN confusion matrix
下载:
全尺寸图片
图 11 引入交互关系混淆矩阵
Fig. 11 ST-GCN(Interaction) confusion matrix
下载:
全尺寸图片
图 12 人体超图卷积模型训练准确率和损失函数值
Fig. 12 Body hypergraph convolution model training accuracy and loss function value
下载:
全尺寸图片
图 13 比较3个模型在11种交互动作上的准确率
Fig. 13 Accuracy of the three models on 11 kinds of interaction actions was compared
下载:
全尺寸图片
表 1 消融结果对比
Table 1 Comparison of ablation results
模型名称 双人交互 超图结构 识别结果/% ST- GCN × × 91.02 ST-GCN(Hypergraph) × √ 94.69 ST-GCN(Interaction) √ × 95.63 本研究算法 √ √ 97.36 -
[1] 吴联世, 夏利民, 罗大庸. 人的交互行为识别与理解研究综述[J]. 计算机应用与软件, 2011, 28(11): 60–63. doi: 10.3969/j.issn.1000-386X.2011.11.015 WU Lianshi, XIA Limin, LUO Dayong. Survey on human interactive behaviour recognition and comprehension[J]. Computer applications and software, 2011, 28(11): 60–63. doi: 10.3969/j.issn.1000-386X.2011.11.015 [2] WANG Pichao, LI Wanqing, OGUNBONA P, et al. RGB-D-based human motion recognition with deep learning: a survey[J]. Computer vision and image understanding, 2018, 171: 118–139. doi: 10.1016/j.cviu.2018.04.007 [3] BARADEL F, WOLF C, MILLE J, et al. Glimpse clouds: human activity recognition from unstructured feature points[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 469−478. [4] YUN K, HONORIO J, CHATTOPADHYAY D, et al. Two-person interaction detection using body-pose features and multiple instance learning[C]//2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Providence: IEEE, 2012: 28−35. [5] 姬晓飞, 谢旋, 任艳. 深度学习的双人交互行为识别与预测算法研究[J]. 智能系统学报, 2020, 15(3): 484–490. JI Xiaofei, XIE Xuan, REN Yan. Research on two-person interaction Recognition and Prediction Algorithm based on Deep Learning[J]. CAAI transactions on intelligent systems, 2020, 15(3): 484–490. [6] HUYNH-THE T, BANOS O, LE B V, et al. PAM-based flexible generative topic model for 3D interactive activity recognition[C]//2015 International Conference on Advanced Technologies for Communications. Ho Chi Minh City: IEEE, 2016: 117−122. [7] ZAREMBA W, SUTSKEVER I, VINYALS O. Recurrent neural network regularization[EB/OL]. (2014−09−18)[2022−01−01]. https://arxiv.org/abs/1409.2329.pdf. [8] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. [9] KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL].(2017−09−09)[2022−01−01]. https://arxiv.org/abs/1607.07043.pdf. [10] LIU Jun, SHAHROUDY A, XU Dong, et al. Spatio-temporal LSTM with trust gates for 3D human action recognition[EB/OL]. (2016−07−24)[2022−01−01]. https://arxiv.org/abs/1607.07043.pdf. [11] CHOUTAS V, WEINZAEPFEL P, REVAUD J, et al. PoTion: pose MoTion representation for action recognition[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7024−7033. [12] YAN Sijie, XIONG Yuanjun, LIN Dahua. Spatial temporal graph convolutional networks for skeleton-based action recognition[EB/OL]. (2018−01−25)[2022−01−01]. https://arxiv.org/abs/1801.07455. [13] CHENG Ke, ZHANG Yifan, HE Xiangyu, et al. Skeleton-based action recognition with shift graph convolutional network[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 180−189. [14] SONG Yifan, ZHANG Zhang, SHAN Caifeng, et al. Richly activated graph convolutional network for robust skeleton-based action recognition[J]. IEEE transactions on circuits and systems for video technology, 2021, 31(5): 1915–1925. doi: 10.1109/TCSVT.2020.3015051 [15] 刘云, 薛盼盼, 李辉, 等. 基于深度学习的关节点行为识别综述[J]. 电子与信息学报, 2021, 43(6): 1789–1802. doi: 10.11999/JEIT200267 LIU Yun, XUE Panpan, LI Hui, et al. A review of action recognition using joints based on deep learning[J]. Journal of electronics & information technology, 2021, 43(6): 1789–1802. doi: 10.11999/JEIT200267 [16] LI Maosen, CHEN Siheng, CHEN Xu, et al. Actional-structural graph convolutional networks for skeleton-based action recognition[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2020: 3590−3598. [17] 成科扬, 吴金霞, 王文杉, 等. 融合时空图卷积的多人交互行为识别[J]. 中国图象图形学报, 2021, 26(7): 1681–1691. doi: 10.11834/jig.200510 CHENG Keyang, WU Jinxia, WANG Wenshan, et al. Multi-person interaction action recognition based on spatio-temporal graph convolution[J]. Journal of image and graphics, 2021, 26(7): 1681–1691. doi: 10.11834/jig.200510 [18] WU Jianchao, WANG Limin, WANG Li, et al. Learning actor relation graphs for group activity recognition[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2020: 9956−9966. [19] CHEN Yuxin, ZHANG Ziqi, YUAN Chunfeng, et al. Channel-wise topology refinement graph convolution for skeleton-based action recognition[C]//2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2022: 13339−13348. [20] LEE J, LEE M, LEE D, et al. Hierarchically decomposed graph convolutional networks for skeleton-based action recognition[EB/OL]. (2022−12−25)[2023−01−01]. https://arxiv.org/abs/2208.10741.pdf. [21] ZHOU D, HUANG J, SCHÖLKOPF B. Learning with hypergraphs: clustering, classification, and embedding[C]//International on Neural Information Processing Systems. Vancouver MIT Press, 2006: 1601−1608. [22] ZHOU Dengyong, HUANG Jiayuan, SCHÖLKOPF B. Learning from labeled and unlabeled data on a directed graph[C]//Proceedings of the 22nd International Conference on Machine Learning. New York: ACM, 2005: 1036−1043. [23] YADATI N, NIMISHAKAVI M, YADAV P, et al. HyperGCN: a new method of training graph convolutional networks on hypergraphs[EB/OL]. (2018−09−07)[2022−01−01]. https://arxiv.org/abs/1809.02589.pdf. [24] SHAHROUDY A, LIU Jun, NG T T, et al. NTU RGB D: a large scale dataset for 3D human activity analysis[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1010−1019. [25] KE Qiuhong, AN Senjian, BENNAMOUN M, et al. SkeletonNet: mining deep part features for 3-D action recognition[J]. IEEE signal processing letters, 2017, 24(6): 731–735. doi: 10.1109/LSP.2017.2690339












































