
Intelligent generation and fine tuning of style based on the historical excellent layouts of digital newspapers
-
摘要: 在传统报纸印刷行业中,设计人员需要根据设计规则进行人工排版,其排版过程造价成本较高且耗时耗力。为提高排版效率,研究提出一种基于历史优秀版面的样式自动生成与微调方法。为了从数据中学习到报纸排版的风格,创建一个包含丰富的设计元素参数信息的电子报数据库,这些特征信息能够有效地反映报纸的布局。对于给定的新闻文章,首先根据历史优秀版面训练概率模型来推断电子报版面的样式,并结合固定约束和用户约束保证样式有效,同时构建美学设计原理的量化方法进一步实现样式微调。最后通过定性和定量评估,表明新方法可以生成满足视觉美观性、层次性和可读性的报纸。本文方法可为版面设计样式智能生成提供参考。Abstract: In traditional newspaper printing industry, designers need to manually typeset according to the design rules. The typesetting process is costly, time-consuming and labor-consuming. In order to improve the efficiency of typesetting, a method of automatic style generation and fine-tuning based on historical excellent layouts is proposed. In order to learn the style of newspaper typesetting from the data, an electronic newspaper database containing rich parameter information of design elements is created, which can effectively reflect the layout of newspapers. For a given news article, firstly, a probability model is trained according to the historical excellent layout to infer the layout style of the electronic newspaper, and the fixed constraints and user constraints are combined to ensure that the style is effective. At the same time, some aesthetic design principles are quantified to further realize style fine-tuning. Finally, through qualitative and quantitative evaluation, it shows that the new method can generate newspapers that meet the visual aesthetics, hierarchy and readability.This method can provide a reference for intelligent generation of layout design styles.
-
随着信息技术的飞速发展以及互联网的普及,人们每时每刻都在创造和传播着海量图文信息,其中,电子报纸就是一种以数字化形式进行大众传播信息的重要媒介。电子报纸中每个新闻块通常由标题、图片、正文和广告等设计元素组成,这些设计元素的样式影响着整个版面视觉呈现的美观程度以及新闻信息的可读性,如何将符合美学的设计原理合理有效地融入到报纸的版面设计中成为报纸排版的关键环节,这里用到的美学设计原理[1]众多,包括布局规划、视觉传达、图文平衡与对比、版面对齐与统一等大量专业知识,且报纸的制作周期较长且耗时耗力,故排版出美观优秀的电子报作品不管对业余用户还是对专业设计人员来说都是一件富有挑战的事。
现如今的报纸印刷行业大都使用排版软件进行人工电子报排版,排版软件主要为方正飞腾、Adobe InDesign、CorelDRAW等,这些软件提供了良好的用户排版交互界面和丰富的图文样式素材。然而,这些排版软件仍需人工进行设计排版,无法达到端到端的电子报自动生成效果。Flipboard[2]可以将一些社交媒体上的实时内容以杂志的形式整合在一个页面上供用户查看。近年来,一些研究人员在图文页面设计上也提出了一些有效可行的自动布局计算框架,如杂志封面、海报的自动生成[2-8],还有对单个设计元素进行建模求解,比如海报文字换行[9]、字体匹配[10]、图片色彩[11]等。
一张完整的新闻版面由全局布局结构和局部新闻面板样式组成,一个新闻面板中包含标题、图片、正文这些设计元素,样式参数则是用于描述设计元素的位置与大小。为了实现电子报的样式智能生成与微调,需要解决的主要问题有以下方面:1)数字报版面新闻篇数多,每篇新闻的重要程度不同,如何实现版面样式参数的差异化生成,达到数字报版面排版的高效信息传递。2)新闻版面内容丰富、图文内容无法简单地基于模板进行机械填充,如何实现兼顾内容完整性和美学要求的版面样式微调,达到数字报版面内容与设计风格的统一。
为了解决给定面板内图文样式问题,本文提出了一种基于历史优秀版面的样式智能生成和微调方法,即通过电子报数据集学习一个用于推断样式参数的概率模型。
综上所述,本文工作的主要贡献如下:1)设计了一个细粒度标签化的电子报数据集,其中包含丰富的设计元素语义信息,同时展示了如何构建从图像到tex代码的映射。2)引入了一个基于历史优秀版面的样式自动生成与微调方法,该方法学习了历史优秀报纸版面的设计风格,并且结合用户约束与设计原理实现样式微调,以产生高质量的样式设计。3)进一步地分析了排版结果并设计对比实验来证明本文方法的有效性。
1. 图形设计相关工作
1.1 基于设计规则的自动布局
在传统的平面设计工作中,工作人员通常会根据一些美学设计原理和先验知识进行图文排版,一些研究人员以此为切入点,在完整科学的美学体系中提取视觉布局的关键因素来量化表示图文的关系,从而达到自动化布局设计的目的。
在杂志海报设计上,Kuhna等[3]使用了基于自适应网格的布局[4]进行自动数字杂志生成,其自动排版方法主要基于图像重要度区域来识别限定文字范围。此外,Jahanian等[5]研究了正确设计一个良好的视觉文本布局的关键概念,介绍了设计元素、美学原则以及色彩方面的设计目的。O’Donovan等[6-7]通过优化一些视觉设计原则来定义对应的能量函数,从而实现单页平面设计的自动排版。Yang等[8]提出了一种将版式设计的所有关键要素整合在一起的计算框架,该计算框架实现了杂志封面的排版设计。以上方法在杂志封面、海报自动化布局设计中起着核心作用,然而报纸版面内容丰富,排版风格整齐统一,图文内容无法简单地通过设计规则详细地描述出来,本文方法从真实的报纸图像中学习其排版风格,具有可扩展性与泛化性。
1.2 基于数据驱动的自动布局
数据驱动方法[12-14]主要是通过给定数据学习其中包含的设计规则,预测设计元素的样式参数值。Damera-Venkata等[15]利用概率文档模型(probabilistic document model,PDM)来生成多页文档布局。Qiang等[16]推出了一个自动生成科技论文海报的计算框架,它参考PDM模型提出一个贝叶斯网络推理框架来整合一些设计原则,以此来推断每个面板的属性与图片的排列。You等[17]在自动合成广告中引入了捕捉训练图像风格的概率模型,该模型结合了图形元素特征来预测目标上下文中的设计性能。Zhang等[18]采用了布局风格学习、插值和迁移相结合的方法实现自动化的横幅设计。Lee等 [19]结合用户约束搭建了一个图像布局生成神经网络。以上这些方法更专注于对海报、广告等作品整体布局框架的设计,而不是根据报纸的排版风格设计新闻面板内部布局的关键特征。最近几年,生成对抗网络(generative adversarial network,GAN)也流行于图像生成领域[20-24],比如文本到图像的合成[25]和艺术文字logo布局设计[26],此外,文献[27-28]利用生成对抗网络学习出面向平面设计布局的生成模型。虽然GAN在杂志、海报设计上表现良好,但是相对以上平面设计而言,报纸有严格的区块划分,它对区块对齐、留白均匀有一定的约束要求。而GAN的可解释性、可调控性较差,且训练成本较高,故本文暂时不考虑使用GAN。本文方法受到了文献[17]的启发,即通过数据本身的分布特点建立样式参数的概率推断模型,与文献[17]不同的是,本文是对于多个新闻面板进行标题、图片、正文样式的选择,为了实现面板样式的差异化生成与内容完整性,文中结合面板分割的空间约束条件来推断样式参数的概率分布并保证内容填充均匀不溢出。
2. 电子报数据集
图1给出了创建电子报数据集的工作流程。
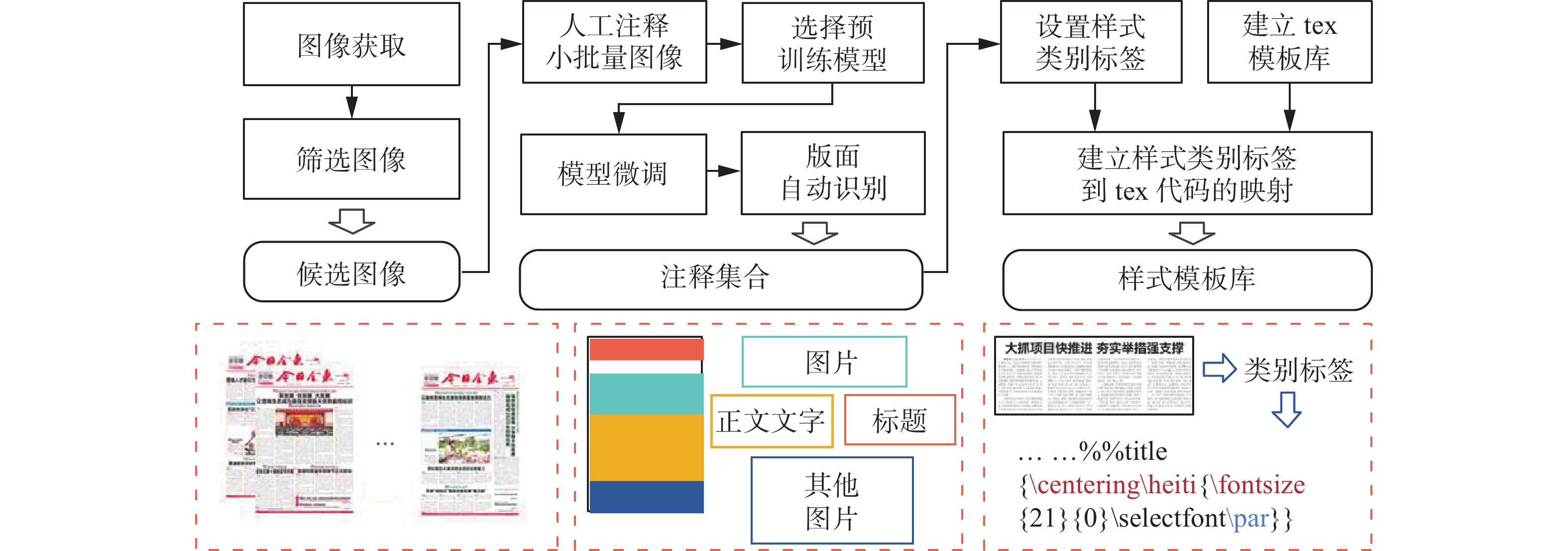 图 1 建立电子报数据集流程Fig. 1 Flow diagram for construction of the electronic newspaper dataset
图 1 建立电子报数据集流程Fig. 1 Flow diagram for construction of the electronic newspaper dataset 下载:
全尺寸图片
下载:
全尺寸图片
2.1 图像获取
为了完成电子报自动生成的任务,本文需要一个能够清楚描述报纸设计元素大小和位置的电子报数据集,然而现有的一些公开的杂志、海报等数据集[29]的布局风格与报纸相差较大,这就需要基于优秀的人工排版作品构建一个更加细粒度的电子报数据库。
本文从报刊数据库中选取了《今日金东》近一年的报纸数据,包括新闻版面图像以及对应的新闻内容原始素材。《今日金东》是人工高质量的排版作品,它包含丰富的符合大众审美的版面特征,它们的整体布局通常由规则的矩形排列组成,这有利于编写通用的tex模板并在LaTeX排版系统中编译实现,而对于那些不规则元素较多的版面,需要进行手动移除。在移除所有不规则布局图片后,得到了292张电子报图片、
1247 个新闻面板。由于报刊数据库中报纸风格统一,独立特征模型应用于样式微调可以保持每种报纸自身风格特征。2.2 手工注释与模型微调训练
本文借助百度开发的PPOCRLabe l工具[30]进行标注,每个元素都由一个矩形边界框标记。标签主要包含标题、文本、文章图片、报花图片4种类型。本文将标题元素与文本元素区分开来,因为标题元素在报纸设计中起着关键作用,将报花图片与文章图片分开来则是因为文章图片是属于固定的新闻内容,而报花图片则是报纸版面需求。其中,报花图片一般为广告、报头、报尾、启事、署名之类与新闻文章本身并无太大关系,主要用于填充留白,美化版面。总之,这些标签描述了电子报版面中各个设计元素的分布情况,可以从中分析出它们的大小与位置,为下文的概率模型的学习提供详细的特征数据。
本文为了统一注释规则并保证注释的质量,为标注者进行15 min的培训。由于图片数量过多,如果全部进行人工注释耗时耗力,因此首先标注了一小部分数据,图2给出了手动注释设计元素的一个例子,之后通过这些标注数据在PaddleDetection工具中训练了一个cascade_rcnn网络[31]来自动分割其他电子报版面。该网络的平均精度为0.814,由于目的是基于历史特征数据驱动获得粗略的布局特征范围,这种模糊匹配大大降低了网络误差的影响。同时,本文研究也邀请注释人员对识别结果进行评判,大家对最后的结果一致认同。
 图 2 电子报注释示例Fig. 2 Example of the electronic newspaper notes下载:
全尺寸图片
图 2 电子报注释示例Fig. 2 Example of the electronic newspaper notes下载:
全尺寸图片
该手工标注与模型微调训练的方法具有可扩展性,可以采用本文介绍的方法收集到更大规模的数据集,包括同一份报纸的年份更长的数据,或不同报纸的数据。基于大量历史优秀版面可以丰富数据集的特征信息,从而提高版面自动排版的质量。
2.3 建立图像到tex代码的映射
本文提出的电子报自动布局方法主要基于LaTeX排版系统进行文档生成,即根据系统推荐与用户需求自动生成对应的tex代码从而编译生成报纸文档的“外观”。需要根据图像特征制定新闻面板样式结构与tex语句的映射,建立图像到代码的映射模型。
为了建立映射模型,本文以单独的新闻面板为单位,根据版面识别模型获得的边界框坐标、大小信息得到标题、图片、正文的位置分布并以不同的类别标签来表示,3.1节对电子报样式种类进行了具体描述(比如horizontaltitle_nopic_nocol表示横标题无图不分栏的图文结构样式),由此为每个标签分配对应的tex模板代码,即制定一套图像特征到tex代码的映射规范来实现代码的自动生成,它可以根据模板种类生成模板代码,该映射模型的最大优势就是将电子报图像与tex代码连接起来,从而可以基于大量历史优秀版面数据,自动生成丰富的样式模板库。
3. 样式自动生成与微调方法
图3为本文计算方法框架。
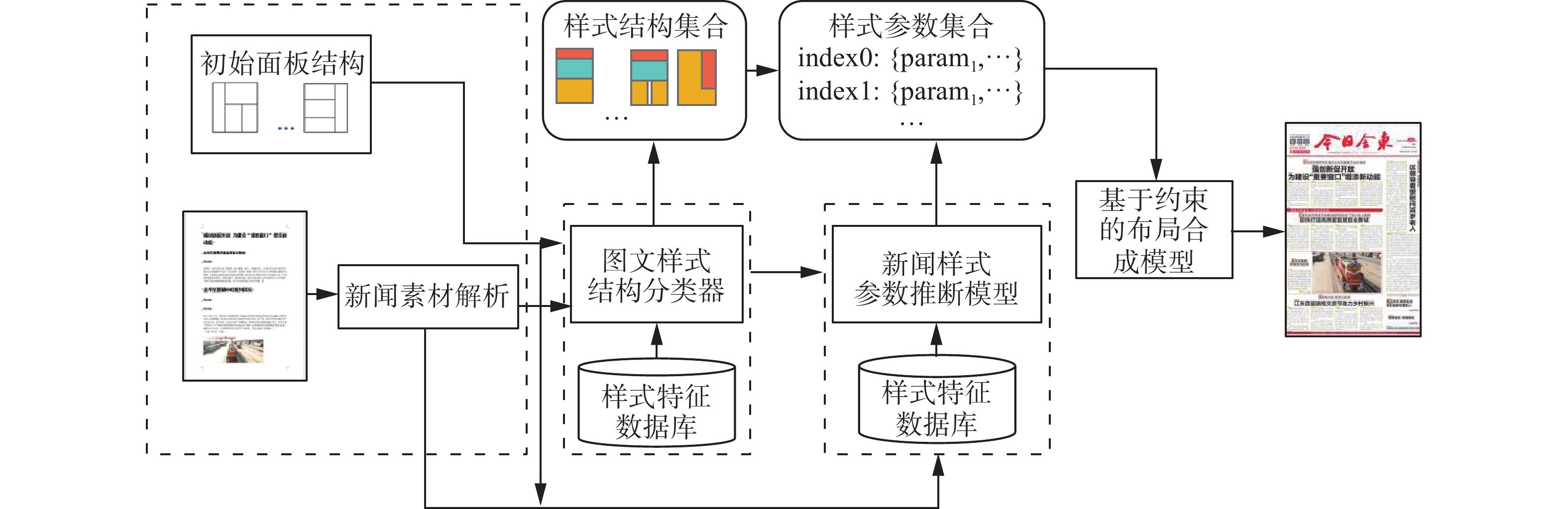 图 3 本文计算方法框架Fig. 3 Framework of our method下载:
全尺寸图片
图 3 本文计算方法框架Fig. 3 Framework of our method下载:
全尺寸图片
3.1 样式结构分类
对新闻页面元素进行结构化表达,把围绕某个主题的图文块抽象为矩形块,称为新闻面板。在学习获得样式参数之前,决定先将收集到的电子报图片作为参考标准,进一步提取出电子报单个新闻面板中所有设计元素的种类。
通过初步调查,本文收集了电子报常用的图文分布结构,电子报的图文结构分类可以理解为对标题、正文、图片这3个设计元素位置结构的划分,如图4所示。标题可以分为竖标题和横标题(图4(a)、4(b)),正文可以分为不分栏文章和分栏文章(图4(d)、4(f)),图片的划分相对于标题、正文来说较为复杂,在这里按照单个图片区域与正文文字的相对位置划分出了横向排列、纵向排列、内嵌型排列3大类。其中:1)横向排列又可以分为向上型横排和向下型横排,如图4(d)、4(e);2)纵向排列分为左右2种方向排列,如图4(b)、4(c);3)内嵌型排列多出现在分栏文章中,即在栏中插入图片,如图4(f)。
 图 4 电子报样式示例Fig. 4 Examples of the electronic newspaper style下载:
全尺寸图片
图 4 电子报样式示例Fig. 4 Examples of the electronic newspaper style下载:
全尺寸图片
多个图片区域的样式则是以上3种类型排列组合形成。如果要对一篇文章的图文结构设置种类名称,可以根据标题、图片、正文的种类进行排列组合,获得对应的样式种类名称,比如图4(a)用verticalwraptitle_nopic_nocol表示。这里的每个下划线前的字母分别对应标题样式、图片位置、正文分栏情况的描述。
表 1 新闻版面参数Table 1 News layout parameters参数名称 描述 新闻面板位置($ \mathop p\nolimits_x $,$ \mathop p\nolimits_y $)及大小($ \mathop p\nolimits_w $,$ \mathop p\nolimits_h $) 新闻面板位置为新闻面板左下角坐标 标题方向$ \mathop t\nolimits_p $及大小$ \mathop t\nolimits_s $ 标题方向分为横标题和竖标题,大小为标题字号大小 图片位置$ \mathop g\nolimits_p $及大小($ \mathop g\nolimits_w $,$ \mathop g\nolimits_h $) 图片位置由离散变量定义 正文是否分栏$ i_c $及栏数$ \mathop c\nolimits_n $ 布尔值,表示正文分栏情况 表 2 新闻内容参数Table 2 News content parameters参数名称 描述 标题字数$ \mathop t\nolimits_n $、正文字数$ \mathop m\nolimits_n $ 单篇文章的主标题字数、正文字数 文字比例$ \mathop t\nolimits_r $ 单篇文章中字数占整个版面字数的比例 图片数量$ \mathop g\nolimits_n $ 单篇文章中图片的数量 3.2 样式参数概率推断模型
对于一张完整的报纸,可以根据新闻文章的不同将其抽象为由一组矩形块拼接组成的页面,本文研究聚焦于单个新闻块里所有样式参数的推断。在本节中使用历史优秀版面的特征数据学习了一个基于概率推断的样式参数模型,该模型描述了在各种因素影响下,各类样式参数的概率分布情况。其中初始布局数据可以任意指定,因为本文方法在最后版面生成时会进行布局结构的微调,用来保证结果的稳定性,故初始布局数据的设置没有严格限制。本文使用了本项目另一工作版面自动布局方法[32]获取布局数据的初始值,该方法生成的布局数据学习了历史数据报的拓扑结构,将它作为初始布局数据,即保留新闻面板的x轴位置
$ \mathop p\nolimits_x $ 和宽度$ \mathop p\nolimits_w $ ,之后通过调整新闻面板y轴位置$ \mathop p\nolimits_y $ 和高度$ \mathop p\nolimits_h $ 避免块间重叠。已知一个新闻面板的初始布局数据为
$ C_1 $ (即$ \mathop p\nolimits_x $ 、$ \mathop p\nolimits_y $ 、$ \mathop p\nolimits_w $ 、$ \mathop p\nolimits_h $ ),同时将第3.1节划分出的图文样式结构类别作为类别标签,训练一个基于朴素贝叶斯的样式结构分类器,当给定一组面板参数值后,该分类器可以预测图文结构,即获取标题、图片、正文这些设计元素的离散型属性,包含标题的位置$ \mathop t\nolimits_p $ 、图片的位置$ \mathop g\nolimits_p $ 、正文是否分栏$ i_c $ 这3种描述图文样式结构的离散变量。朴素贝叶斯分类器是一种经典、稳定的机器学习算法,对计算性能没有过高要求且分类效果表现良好,它主要是利用贝叶斯定理计算未知属性在已知条件下的条件概率。由此本文定义了对于一个面板Pi的样式结构Y的联合概率。
$$ P(Y|C_1)=\frac{P\left(C_1|Y\right)P\left(Y\right)}{P\left(C_1\right)} $$ 使用前面建立的样式特征数据库进行分类器的训练,这里采用了一个假设:已知条件
$ C_1 $ 中的特征是条件独立的,该假设足以完成最终的分类任务。在获得面板Pi内的样式结构后,将注意力转向每个面板内样式结构的参数设置。考虑到报纸的视觉美观程度以及信息可读性,需要合理安排每个面板内标题字号的大小
$ \mathop t\nolimits_s $ 、正文栏数$ \mathop c\nolimits_n $ 以及图片大小($ \mathop g\nolimits_w $ ,$ \mathop g\nolimits_h $ ),其中图片的宽度$ \mathop g\nolimits_w $ 和图文样式结构Y有很大的关系,因为在典型的新闻布局中,面板中图片的宽度跨越整数栏,通常都会有固定的宽度,故图片宽度不需要参数化,本文图片高度初始值按照原始图片的比例计算获得。但是对于后面样式微调时插入报花图片这种特殊情况,可以根据留白面积适当地伸缩图片高度以适应面板内的空间布局。为了估计标题字号
$ \mathop t\nolimits_s $ 、正文栏数$ \mathop c\nolimits_n $ 等参数的概率分布,采用核密度估计方法将栏数、标题字号的离散分布转化为连续分布。$$ \mathop f\nolimits_n (x) = \frac{1}{n}\sum\limits_{i = 1}^n {K\left(\frac{{x - \mathop x\nolimits_i }}{h}\right)} $$ $$ K(t) = \frac{1}{{\sqrt {2{\text{π }}} }}\mathop {\text{e}}\nolimits^{ - \tfrac{1}{2}\mathop t\nolimits^2 } $$ 式中:
$ x = (\mathop x\nolimits_1 ,\mathop x\nolimits_2 ,\cdots ,x_i ) $ ,这是样式参数值集合,$ \mathop x\nolimits_i \in [x - h,x + h] $ ,$ h $ 为带宽,这里使用网格搜索法寻找最优带宽,核函数$ K(t) $ 使用高斯核函数,因为高斯核函数的形状更适合描述本文样式特征数据库中变量的分布情况。栏式是组成报纸版面的基本形式,一般将常用的栏式称为基本栏。一张报纸的基本栏栏宽往往是统一的,但也允许略微改动,栏宽的长度通常以一栏中的单行字数表示,所以当对栏数进行估计时,本文把它转化为对于单行字数的条件概率计算:
$$ \mathop c\nolimits_w = \frac{{\mathop p\nolimits_w - \mathop c\nolimits_{{\rm{sep}}} (\mathop c\nolimits_n - 1)}}{{\mathop m\nolimits_s }} $$ $$ P(\mathop c\nolimits_n |\mathop p\nolimits_w ) = \mathop f\nolimits_n (\mathop c\nolimits_w ) $$ 式中:
$ \mathop c\nolimits_w $ 为一栏中的单行字数;$ \mathop p\nolimits_w $ 为面板宽度;$\mathop c\nolimits_{{\rm{sep}}}$ 为栏间距;$ \mathop m\nolimits_s $ 为正文字号,考虑到本文数据集中正文字号都是固定的,所以将正文字号看作全局变量,可以由用户预设定或系统默认值获得;$ \mathop c\nolimits_n $ 为栏数,其取值范围为[1,7],最后选择最大概率对应的栏数。标题是报纸样式布局中的一个重要的部分,影响标题变化的因素较多,选择面板属性{
$\mathop p\nolimits_x $ ,$\mathop p\nolimits_y $ ,$ \mathop p\nolimits_w $ ,$ \mathop p\nolimits_h $ }和新闻内容属性集合{$ \mathop t\nolimits_n $ ,$ \mathop m\nolimits_n $ ,$ \mathop t\nolimits_r $ ,$ \mathop g\nolimits_n $ }作为已知特征$ C_2 $ ,然后将标题字号$ \mathop t\nolimits_s $ 和样式结构类别$ Y $ 作为未知特征。为了获得相似特征面板下的标题字号分布情况,对于给定面板Pi的标题字号,首先根据已知条件C2使用k均值聚类(k=13)划分类别,之后再对聚类后的每个类中的标题字号$ \mathop t\nolimits_s $ 进行联合概率分布计算。$$ l = \arg \min \mathop {||{C_2}- \mathop \mu \nolimits_j ||}\nolimits_2 $$ $$ P(\mathop t\nolimits_s |l) = \mathop f\nolimits_n (\mathop t\nolimits_s |Y)P{\text{(}}Y|{C_1}{\text{)}} $$ 式中:
$ l $ 为该面板聚类后的类别号,$ \mathop \mu \nolimits_j $ 为第j个聚类中心(j=1,2,…,k),$ \mathop t\nolimits_s $ 为标题字号,$C_2$ 为已知条件,$ Y $ 为图文样式类别标签。最后采样高概率参数值获取图文样式结构、栏数、标题字号的候选集合。
3.3 基于约束的布局合成规划模型
前面都是关于报纸单个面板中样式参数候选集合的局部计算,而最后布局合成需要着眼于全局内容的组成,所以从样式候选集合中找到既满足布局结构约束又满足美学设计原理的样式参数至关重要,也将获取最优化样式参数的过程称为样式微调。为了解决这一问题提出了一个基于约束的布局合成规划模型,该模型需要设计约束条件和目标优化函数。
首先,给定一组描述报纸整体布局结构的数据(由
$ \mathop p\nolimits_x $ 、$ \mathop p\nolimits_y $ 、$ \mathop p\nolimits_w $ 、$ \mathop p\nolimits_h $ 组成且不包含报头信息),对这些数据进行分析并提炼出其中包含的布局约束,即将面板宽度$ \mathop p\nolimits_w $ 和$ \mathop p\nolimits_x $ 坐标作为硬约束,但不限制面板的高度$ \mathop p\nolimits_h $ 与$ \mathop p\nolimits_y $ 坐标,这些约束会以线性表达式的形式通过解析程序自动生成,图5给出了一个布局示例在坐标系中的位置表示,这里的长度度量单位为百分比。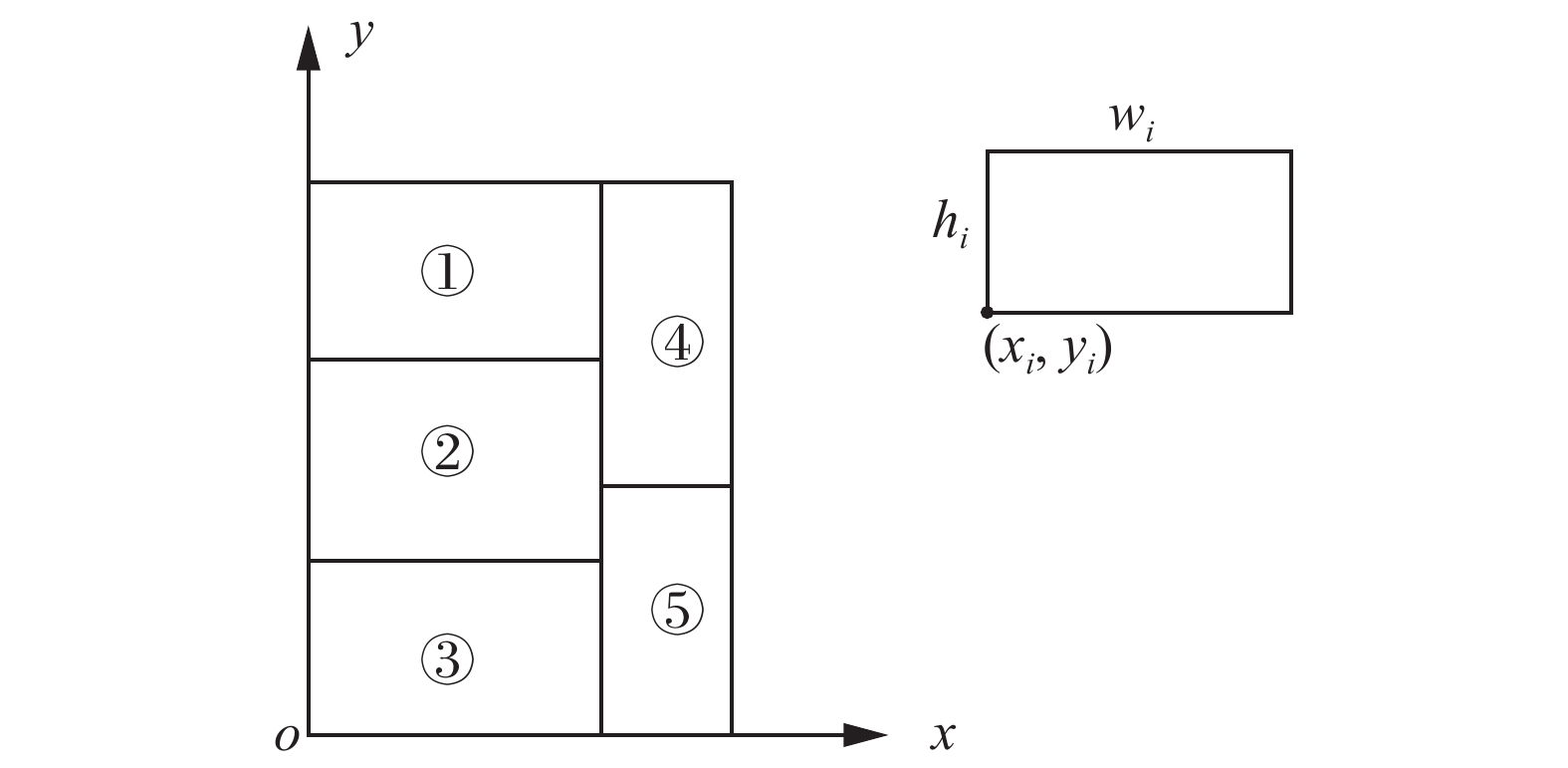 图 5 布局结构示例Fig. 5 Example of layout structure下载:
全尺寸图片
图 5 布局结构示例Fig. 5 Example of layout structure下载:
全尺寸图片
之后加入对标题的约束条件,很多时候人们对一张报纸版面的初始印象就来自各新闻块标题之间的大小关系,标题是否错落有致、层次分明影响着报纸的美观程度与可读性。文章权重表现了文章的重要性与层次性,所以需要根据文章权重对每个面板标题的大小进行有序排列。这里的文章权重可以通过用户自定义设置获取,也可以从每个面板标题字号聚类结果的平均值中推断获得,算法1总结了标题字号组合的计算过程。
算法1 标题字号组合
输入 每篇新闻内容参数值;
输出 res存放以面板为单位且按照权重顺序的字号排列组合的结果
1)初始化:res,temp为空数组
2)for each Pi in P do
3)归一化输入特征;
4)计算面板Pi特征到k个聚类中心的距离di;
5)ci←argmin(d1,d2,…,dk);
6)dict存储类别ci中的高概率参数值;
7)weights←sort by mean fontsize of dict;
8)call page_backtrack(0,dict,weights,res);
9)过程page_backtrack(index,dict,weights,res);
10)if temp按大小排序后与weights相同 then;
11) add temp to res;
12)for each index in dict;
13)add index to temp;
14)call page_backtrack(index+1,dict,weights,res);
15)delete index from temp;
每个面板的留白空间也是需要合理分配的,为了让版面留白均匀,对于留白过多的情况可以加入报花元素来填充留白区域。对于报花图片的选择,系统会根据留白大小推荐合适比例的报花进行插入。
在考虑好各个设计元素的限制条件后进行条件整合,与文献[33]中计算面板面积相似,为了防止面板内容溢出、留白面积过多以及留白不均匀的情况,需要计算参数候选集合中各个参数值经过排列组合后对应的面板内容面积,由此计算面板的留白面积,即给定一组面板面积
$\{{{\displaystyle S}}_{p_{1}},{{\displaystyle S}}_{p_{2}},\cdots, {{\displaystyle S}}_{p_{i}},\cdots,{{\displaystyle S}}_{p_{n}}\},i=1,2,\cdots,n$ ,一组面板内容的实际面积$\{{{\displaystyle S}}_{c_{1}},{{\displaystyle }}S_{c_{2}},\cdots,{{\displaystyle S}}_{c_{i}},\cdots,{{\displaystyle S}}_{c_{n}}\},i=1,2,\cdots,n$ ,这里需要设置面板面积大于面板内容面积的约束,面板留白面积$ \mathop S\nolimits_i^{'} $ 则定义为这两组面积的差值,同时,从报花库中选择出来的报花图片也需要根据实际的留白面积相应地调整其高度。由以上条件定义目标函数:
$$ \mathop f\nolimits^* = \min \left(\mathop \alpha \nolimits_1 \sum\limits_{i = 1}^n {\mathop \lambda \nolimits_i \mathop S\nolimits_i^{'} + } \mathop \alpha \nolimits_2 \max\left(\left|{{\mathop S\nolimits_{\text{i}}^{'} } \mathord{\left/ {\vphantom {{\mathop S\nolimits_{\text{i}}^{'} } {\mathop p\nolimits_{wi} }}} \right. } {\mathop p\nolimits_{wi} }} - \mathop g\nolimits_{hi} \right|\right)\right) $$ 式中:
$ \mathop \lambda \nolimits_i $ 为留白面积缩放因子,$ \mathop S\nolimits_i^{'} $ 为第i个面板的留白面积,$ \mathop p\nolimits_{wi} $ 是第i个面板的宽度,$ \mathop g\nolimits_{hi} $ 为该面板对应的报花图片高度,第1项$ \mathop \lambda \nolimits_i \mathop S\nolimits_i^{'} $ 定义为最小化额外留白面积,第2项用于衡量报花图片纵横比的伸缩变化程度,$\max|{{\mathop S\nolimits_i^{'} } \mathord{\left/ {\vphantom {{\mathop S\nolimits_i^{'} } {\mathop p\nolimits_{wi} }}} \right. } {\mathop p\nolimits_{wi} }} - \mathop g\nolimits_{hi} |$ 定义为对于一个报纸版面的所有面板中,其留白空间高度与报花图片初始高度之间的最大差值。根据先验知识可得留白面积一般会在页面底端,所以在底端面板的缩放因子$ \mathop \lambda \nolimits_i $ 普遍设置较小。设置好以上这些条件后,采用了谷歌开发的组合优化工具ortools进行约束优化问题的求解。最后选择使目标函数最小的一组样式参数进行布局合成,在布局合成过程中文中还使用美学规则或是先验知识进一步完善布局,比如重要性原则、对齐对称原则和留白原则等。
4. 实验结果
4.1 模型有效性评估
由于现有的相关研究中缺少可直接用于数字报样式生成和微调的可参照对比方法,故采用其他典型的分类模型和回归模型与本文方法进行对比实验,用来证明本文方法的有效性。
对于样式结构种类的推断,本文使用了新闻面板(
$ \mathop p\nolimits_x $ ,$ \mathop p\nolimits_y $ ,$ \mathop p\nolimits_w $ ,$ \mathop p\nolimits_h $ )特征作为已知条件,并选择了3种比较典型的概率分类模型进行学习。其中准确率(accuracy)A衡量了测试样本中模型推断结果的正确程度,它可以用于评估分类结果的有效性,准确率计算为$$ {{A}} = \sum\limits_{i = 1}^n {\frac{{H(y, y' )}}{n}} $$ $$ H(y,y')=\left\{\begin{array}{l}1,y=y'\\ 0,其他\end{array}\right. $$ 式中:
$ y $ 为原始面板的真实样式结构种类;$\mathop y\nolimits'$ 为由分类模型推断出来的样式结构种类;$ H(y, y' ) $ 为分类正确的结果赋值1,为分类错误的结果赋值0。表3详细地描述了训练集和测试集中标题、图片、正文的不同样式对应的数量,可以看到图片数据相对于标题、正文来说占比较少,这是因为通常一张完整的报纸版面中无图文章占比较多。由于图片类别数据不平衡,故本文分别训练了有图文章分类器与无图文章分类器,最后联合这些分类器进行分类。
表 3 数据集中各类样式数量Table 3 Quantity of various styles in our dataset数据集 标题 图片 正文 横标题 竖标题 横向分割 纵向分割 嵌入式 分栏 不分栏 训练集 697 113 105 84 66 470 340 测试集 376 61 49 66 32 275 162 表4给出了样式结构分类标签Y代表的3个离散参数在不同分类器上的准确率,说明了本文的电子报数据集在分类器上表现良好,在标题方向和分栏情况的推断上的分类效果尤其突出,但是对于图片位置的推断略有不足,尤其在图片的横向分割和嵌入式这2种预测上容易混淆,这种情况占错误样例的40%,这是因为在相似特征值的条件下,图片位置有多种情况可以满足排版要求。
表 4 样式参数分类结果Table 4 Result of style classification方法 标题方向 图片位置 分栏情况 朴素贝叶斯 0.98 0.83 0.95 多元逻辑回归 0.97 0.80 0.96 支持向量机 0.98 0.82 0.95 为了检验本文方法对于标题字号和栏数推断的有效性,这里引入了均方根误差(root mean square error,RMSE)指标计算在相同全局布局结构的条件下,本文方法与其他回归模型推断的标题字号、栏数与真实的标题字号、栏数的差距。其中,字号的单位为毫米,字号权重的均方根误差则表示推断出来的一个版面标题字号大小顺序的偏差程度。RMSE被定义为
$$ \mathop S\nolimits_{{\rm{RMSE}}} = \sum\limits_{i = 1}^n {\frac{{\mathop {(v - \mathop v\nolimits' )}\nolimits^2 }}{n}} $$ 式中:
$ v $ 为真实的变量大小,$\mathop v\nolimits'$ 为由本文模型推断出来的变量大小,n为新闻面板总数。表5列出了本文方法与其他回归模型推断样式参数的均方误差,可以看到本文方法虽然在栏数预测上略逊于其他方法,但在字号和字号权重推断上的误差值是明显低于其他方法的,这表明本文的算法对面板字号进行了有效的聚类,且通过概率模型可以更好地推断出字号的大小。同时,因为在一些参数获取上增加了用户约束,本文方法也适用于不同约束场景下标题字号的求解,由此增加了计算的灵活性。表 5 样式参数均方根误差Table 5 RSME of style方法 栏数 字号/mm 字号权重 本文方法 0.322 1.415 0.144 最近邻 0.531 3.840 0.577 支持向量机 0.259 2.981 0.288 贝叶斯网络 0.430 3.240 1.021 注:加黑为最优值。 在3.3节中详细描述了从高概率样式参数候选集合中找到既满足布局结构约束又满足美学设计原理的参数值的模型,该约束规划模型中的目标函数量化美学设计原理,代表了样式微调的方向,对于目标函数的两项微调因子的权重进行了进一步的探索。
图6(a)为还未进行样式微调时生成的结果,整体版面留白过多;图6(b)~6(d)给出了最后的布局合成约束规划模型中不同权重对应的目标函数生成的最终结果;图6(b)只考虑目标函数的第2项微调因子,即获取使插入的报花伸缩变化幅度最小的样式参数组合,可以看到该排版结果在视觉感官上呈现出的层次性较弱,并且右边的报花占据的视觉中心区域过多,总的来说,在图6(b)权重下的排版质量偏低。而图6 (c)只考虑最小化额外的留白空间,虽然在内容层次性上看比图6(b)表现好,但它却没有关注报花图片伸缩变化程度带来的排版质量的下降。图6(d)既考虑了额外留白空间又加入了对报花伸缩变化的惩罚项,可以看到最终的排版结果在不过分伸缩报花的同时也保证了样式微调的有效组合。
 图 6 目标函数中不同微调因子权重(α1, α2)对应的布局结果Fig. 6 Layout results for weights(α1, α2) of different fine tuning factors in the objective function下载:
全尺寸图片
图 6 目标函数中不同微调因子权重(α1, α2)对应的布局结果Fig. 6 Layout results for weights(α1, α2) of different fine tuning factors in the objective function下载:
全尺寸图片
4.2 用户调研评估
本节采用用户研究来评估本文的实验结果与新手设计师、原版报纸之间的差距。邀请45名研究人员对这些报纸进行打分,其中15人为专业的报纸排版人员,15人有平时看报的习惯,15人平时较少看报。在调查问卷设计中,提供了9张电子报图片,其中3张使用本文的方法自动生成,3张为新手设计师生成,3张为原版报纸,同时设置了信息可读性、美观程度、层次性3个打分指标,打分程度分为不满意、不太满意、一般、较为满意和满意5种级别(这里以分数0、5、10、15和20代替)。当然,为了体现不同方法生成电子报的整体差异性,会提供相同的新闻素材进行生成比较。
图7为用户调查的最终统计结果,可以看到,与新手设计相比,本文方法在可读性、美观程度和层次性上明显要更加满足用户的视觉感官需求,且平均分数接近于“较为满意”这个选项。虽然本文方法还无法达到专业的电子报设计水平,但也可以成为设计人员的一个辅助工具,因为在正常的排版工作中,设计人员需要结合客户的各种需求、自身先验知识以及美学思想等各种主观性的判断进行设计,这些因素是无法正确估量的,所以还是要有一个用户交互的过程来充分满足多样性需求。
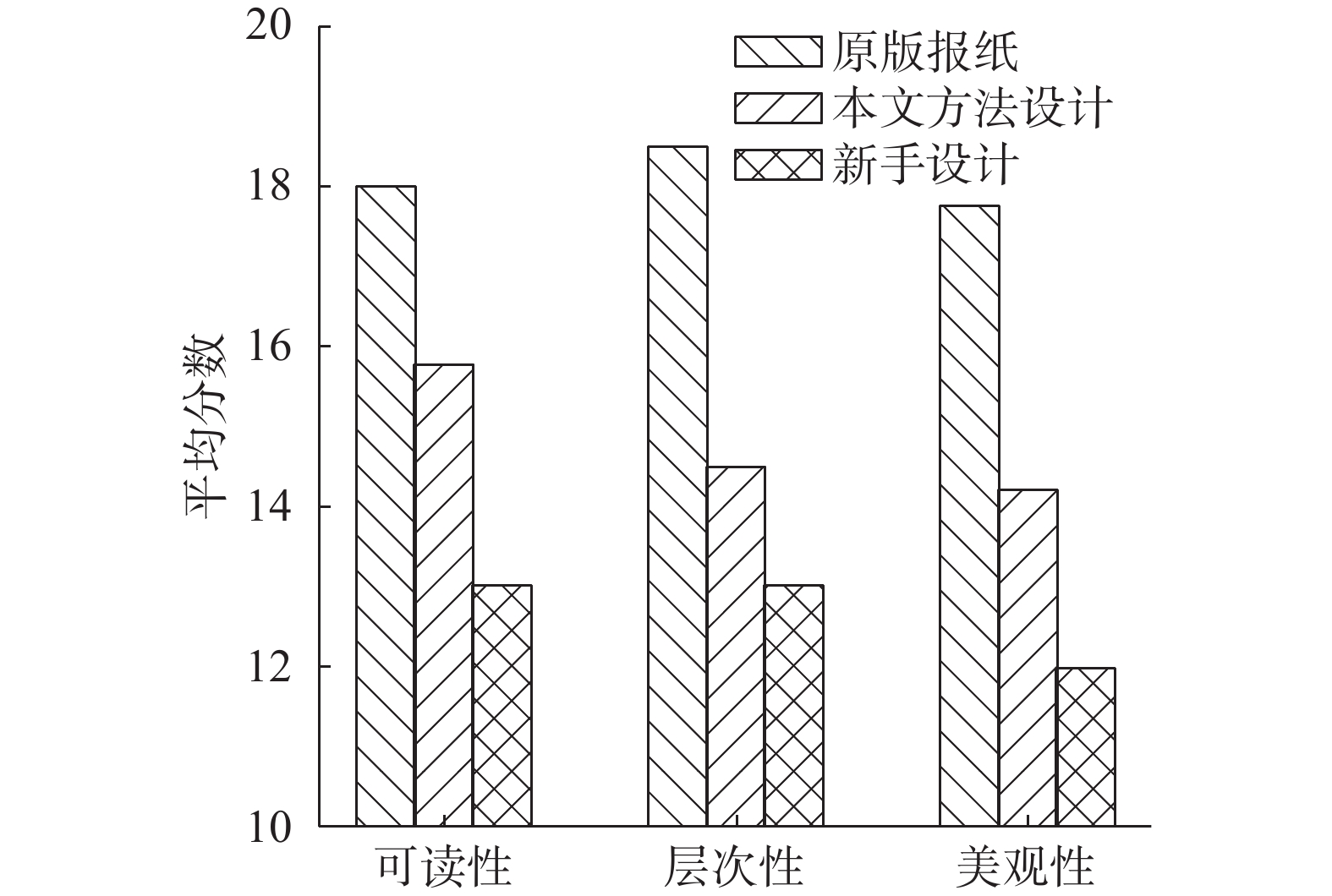 图 7 用户调查统计结果Fig. 7 User study of different posts下载:
全尺寸图片
图 7 用户调查统计结果Fig. 7 User study of different posts下载:
全尺寸图片
当然,本文也会根据同一新闻素材为用户提供多种布局选择。图8(a)~8(b)中第1张为报纸各版原图,其他由本文方法自动生成。
 图 8 不同素材生成的多种布局的电子报Fig. 8 Electronic newspapers with multiple layouts generated from the different materials下载:
全尺寸图片
图 8 不同素材生成的多种布局的电子报Fig. 8 Electronic newspapers with multiple layouts generated from the different materials下载:
全尺寸图片
5. 结束语
本文提出的方法可以作为一种辅助工具帮助报纸排版人员进行报纸的整体设计,该方法利用概率模型和约束规划模型可以生成有效的报纸版面的样式参数。本文方法的限制是它暂时只支持单页电子报的自动生成,然而报纸排版多由多个版面组成,在未来的工作中,将考虑发展多个版面电子报的自动化设计,以便支持报纸的自动批量生成。
-
图 1 建立电子报数据集流程
Fig. 1 Flow diagram for construction of the electronic newspaper dataset
下载:
全尺寸图片
图 2 电子报注释示例
Fig. 2 Example of the electronic newspaper notes
下载:
全尺寸图片
图 3 本文计算方法框架
Fig. 3 Framework of our method
下载:
全尺寸图片
图 4 电子报样式示例
Fig. 4 Examples of the electronic newspaper style
下载:
全尺寸图片
图 5 布局结构示例
Fig. 5 Example of layout structure
下载:
全尺寸图片
图 6 目标函数中不同微调因子权重(α1, α2)对应的布局结果
Fig. 6 Layout results for weights(α1, α2) of different fine tuning factors in the objective function
下载:
全尺寸图片
图 7 用户调查统计结果
Fig. 7 User study of different posts
下载:
全尺寸图片
图 8 不同素材生成的多种布局的电子报
Fig. 8 Electronic newspapers with multiple layouts generated from the different materials
下载:
全尺寸图片
表 1 新闻版面参数
Table 1 News layout parameters
参数名称 描述 新闻面板位置($ \mathop p\nolimits_x $,$ \mathop p\nolimits_y $)及大小($ \mathop p\nolimits_w $,$ \mathop p\nolimits_h $) 新闻面板位置为新闻面板左下角坐标 标题方向$ \mathop t\nolimits_p $及大小$ \mathop t\nolimits_s $ 标题方向分为横标题和竖标题,大小为标题字号大小 图片位置$ \mathop g\nolimits_p $及大小($ \mathop g\nolimits_w $,$ \mathop g\nolimits_h $) 图片位置由离散变量定义 正文是否分栏$ i_c $及栏数$ \mathop c\nolimits_n $ 布尔值,表示正文分栏情况 表 2 新闻内容参数
Table 2 News content parameters
参数名称 描述 标题字数$ \mathop t\nolimits_n $、正文字数$ \mathop m\nolimits_n $ 单篇文章的主标题字数、正文字数 文字比例$ \mathop t\nolimits_r $ 单篇文章中字数占整个版面字数的比例 图片数量$ \mathop g\nolimits_n $ 单篇文章中图片的数量 表 3 数据集中各类样式数量
Table 3 Quantity of various styles in our dataset
数据集 标题 图片 正文 横标题 竖标题 横向分割 纵向分割 嵌入式 分栏 不分栏 训练集 697 113 105 84 66 470 340 测试集 376 61 49 66 32 275 162 表 4 样式参数分类结果
Table 4 Result of style classification
方法 标题方向 图片位置 分栏情况 朴素贝叶斯 0.98 0.83 0.95 多元逻辑回归 0.97 0.80 0.96 支持向量机 0.98 0.82 0.95 表 5 样式参数均方根误差
Table 5 RSME of style
方法 栏数 字号/mm 字号权重 本文方法 0.322 1.415 0.144 最近邻 0.531 3.840 0.577 支持向量机 0.259 2.981 0.288 贝叶斯网络 0.430 3.240 1.021 注:加黑为最优值。 -
[1] 李瑞. 基于新媒体的报纸版面设计探微[J]. 中国造纸, 2020, 39(5): 109–110. LI Rui. Exploration of newspaper layout design based on new media[J]. China paper, 2020, 39(5): 109–110. [2] YING C, FRTES F. Dynamic layout engine for a digital magazine[P]. U. S. Patent 9, 483, 444. 2016−11−1. [3] KUHNA M, KIVEA I, OITTINEN P. Semi-automated magazine layout using content-based image features[C]//Proceedings of the 20th ACM International Conference on Multimedia. New York: ACM, 2012: 379−388. [4] JACOBS C, LI W, SCHRIER E, et al. Adaptive grid-based document layout[J]. ACM transactions on graphics, 2003, 22(3): 838–847. [5] JAHANIAN A, LIU J, LIN Q, et al. Automatic design of colors for magazine covers[C]//Imaging and Printing in a Web 2.0 World IV. Burlingame: International Society for Optics and Photonics, 2013: 8664. [6] O’DONOVAN P, AGARWALA A. Learning layouts for single-page graphic designs[J]. IEEE transactions on visualization and computer graphics, 2014, 20(8): 1200–1213. doi: 10.1109/TVCG.2014.48 [7] O’DONOVAN P, AGARWALA A. Designscape: design with interactive layout suggestions[C]//Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems. Seoul: ACM, 2015: 1221–1224 [8] YANG Xuyong, MEI Tao, XU Yingqing, et al. Automatic generation of visual-textual presentation layout[J]. ACM transactions on multimedia computing, communications, and applications, 2016, 12(2): 1–22. [9] OTAO K, SATOH T. Text layout methods overlaid on images considering readability and balance[C]//Proceedings of the 18th International Conference on Advances in Mobile Computing & Multimedia. Chiang Mai: ACM, 2020: 219−223. [10] JIANG Shuhui, WANG Zhaowen, HERTZANN A, et al. Visual font pairing[J]. IEEE transactions on multimedia, 2019, 22(8): 2086–2097. [11] YOU Weitao, SUN Lingyun, YANG Zhiyun, et al. Automatic advertising image color design incorporating a visual color analyzer[J]. Journal of computer languages, 2019, 55: 100910. doi: 10.1016/j.cola.2019.100910 [12] FISCHE M, CAMGNA G, XU S, et al. Brassau: automatic generation of graphical user interfaces for virtual assistants[C]//Proceedings of the 20th International Conference on Human-computer Interaction with Mobile Devices and Services. Barcelona: HCI, 2018: 1−12. [13] BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877−1901. [14] BETRAEI T. Pix2code: generating code from a graphical user interface screenshot[C]//Proceedings of the ACM SIGCHI Symposium on Engineering Interactive Computing Systems. Paris: ACM, 2018: 1−6. [15] DAMERA-VENKATA N, BENTO J, O’BRIIEN-STRAIN E. Probabilistic document model for automated document composition[C]//The 11th ACM Symposium on Document Engineering. Mountain View: ACM, 2011: 3−12. [16] QIANG Yuting, FU Yanwei, YU Xiao, et al. Learning to generate posters of scientific papers by probabilistic graphical models[J]. Journal of computer science and technology, 2019, 34(1): 155–169. doi: 10.1007/s11390-019-1904-1 [17] YOU Weitao, JIANG Hao, YANG Zhiyuan, et al. Automatic synthesis of advertising images according to a specified style[J]. Frontiers of information technology & electronic engineering, 2020, 21(10): 1455–1466. [18] ZHANG Yunke, HU Kangkang, REN P, et al. Layout style modeling for automating banner design[C]//Proceedings of the on Thematic Workshops of ACM Multimedia. CA: ACM, 2017: 451−459. [19] LEE H Y, YANG W, JIANG L, et al. Neural design network: graphic layout generation with constraints[EB/OL]. (2019−12−19)[2022−04−06]. https://arxiv.org/abs/1912. 09421. [20] TANG Yongchuan, HANG Jiangjie, YAO Mengting, et al. A review of design intelligence: progress, problems, and challenges[J]. Front inform technol electron, 2019, 20(12): 1595–1617. doi: 10.1631/FITEE.1900398 [21] LIU Steven, WANG Tongzhou, BAU David, et al. Diverse image generation via self-conditioned GANs[C]//IEEE/CFV Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 14274−14283. [22] DIVYA S, CAO Jiannong. Generative adversarial networks(GANs): challenges, solutions, and future directions[J]. ACM computing surveys, 2022, 54(3): 1−42. [23] ZHANG Han, XU Tao, LI Hongsheng, et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks[C]//2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 5908−5916. [24] HUANG Mengqi, MAO Zhendong, WANG Penghui , et al. DSE-GAN: dynamic semantic evolution generative adversarial network for text-to-image generation[EB/OL].(2022−09−03)[2022−09−06]. https://arxiv.org/abs/2209.01339. [25] QIAO Tingting, ZHANG Jing, XU Duanqing, et al. MirrorGAN: learning text-to-image generation by redescription[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019,1505−1514. [26] WANG Yizhi, PU Guo, LUO Wenhan, et al. Aesthetic text logo synthesis via content-aware layout inferring [C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 2426−2435. [27] LI Jianan, YANG Jimei, ZHANG Jianming, et al. Attribute-conditioned Layout GAN for automatic graphic design[J]. IEEE transactions on visualization and computer graphics, 2021, 27(10): 4039–4048. doi: 10.1109/TVCG.2020.2999335 [28] ZHENG Xinru, QIAO Xiaotian, CAO Ying, et al. Content-aware generative modeling of graphic design layouts[J]. ACM transactions on graphics, 2019, 38(4): 1–15. [29] ZHONG Xu, TANG Jianbin, YEES A J. PubLayNet: largest dataset ever for document layout analysis[C]//2019 International Conference on Document Analysis and Recognition. Sydney: IEEE, 2019: 1015−1022. [30] 马艳军, 于佃海, 吴甜, 等. 飞桨: 源于产业实践的开源深度学习平台[J]. 数据与计算发展前沿, 2019, 1(1): 105–115. MA Yanjun, YU Dianhai, WU Tian, et al. PaddlePaddle: an open-source deep learning platform from industrial practice[J]. Frontiers of data and computing, 2019, 1(1): 105–115. [31] CAI Z, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake: IEEE, 2018: 6154−6162. [32] 曾振宇, 程雨夏, 陶颖, 等. 数字报版面布局自动生成方法[J]. 智能系统学报, 2024, 19(3): 679–688. ZENG Zhenyu, CHENG Yuxia, TAO Ying, et al. Automatic generation method of digital newspaper layout[J]. CAAI transactions on intelligent systems, 2024, 19(3): 679–688. [33] 李治江, 崔广勋, 王嵩. 基于矩形Packing问题求解的页面自动排版方法[J]. 山东农业大学学报(自然科学版), 2016, 47(2): 264–268. LI Zhijiang, CUI Guangxun, WANG Song. Automatic page typesetting method based on rectangular packing problem[J]. Journal of Shandong Agricultural University(natural science edition), 2016, 47(2): 264–268.




















































































