
Automated generation method of digital newspaper layout
-
摘要: 报纸版面对新闻有一个价值排序合理且美观新颖的展示,让读者面对众多新闻,在短时间获取最具价值的讯息和浏览乐趣。然而,对于排版人员而言,手动制作美观易读的报纸版面布局需耗费大量时间成本。本文结合贝叶斯网络推断和约束规划技术,提出一种数字报版面布局自动生成方法。该方法首先基于历史版面数据驱动和专家经验对数字报版面的结构和属性建立推断模型,使得新生成的版面具有历史特定风格;然后利用推断结果建立混合整数约束规划模型计算版面布局,从而显著减少模型求解空间,提高布局质量。此外,推断模型提供多种可用候选结构为生成结果提供多样性,规划模型具有良好的对齐性能。为了训练和验证模型,本文构建并公开了一个中文版面数据集,包括详细版面新闻属性标签数据。用户研究结果表明版面布局自动生成方法的有效性。Abstract: Newspaper pages feature a reasonable and well-organized news layout, allowing readers to access the most valuable information and gain pleasure in a short span. However, for typesetters, generating this type of newspaper layout is time-consuming. A method for automatically generating digital newspaper layouts is proposed by combining the Bayesian network inference and constrained programming. An inference model for the structure and attribute of digital newspaper layout is established using historical layout data and expertise to endow newly generated layout with a historically specific style. Then, a mixed integer constraint programming model is proposed to compute the layout using the inference results. This approach aims to markedly reduce the solution space of the model and improve the layout quality. In addition, the inference model provides available candidate structures and generates varying results. The programming model also ensures that the layout has excellent alignment performance. A dataset with Chinese newspaper layouts is established to train and validate the model; it includes detailed news attribute label data. Research results exhibit the effectiveness of the automated layout generation method.
-
新闻报纸作为一种传统主流信息媒介,国家统计局报告2020年全国报纸出版种类1 810种,总印数达289.1亿份[1],仍值得重视。目前新闻报纸的排版大都由专业设计人员完成,一方面,通过微博、公众号等方式进行新闻发布,为获取时效性而舍弃了原有的美观排版;另一方面,通过人工编排报纸之后进行发布,虽然保留了版面的美观,时效性却大打折扣。因为整个设计流程对人工的依赖较高,尤其是对图片和文本进行排列组合,确定其相对位置以及样式规格以保证版面的可读性、信息性和美观性。这样通过人工手动排版报纸,会进行大量重复劳动,耗时费力,使得新闻出版效率低下。
近几年来,有许多专家学者对页面布局生成方法进行了研究[2]。例如生成杂志封面[3-5]、生成漫画布局[6-8]、广告图像布局[9-12]、他们更多考虑的是图形元素设计,通过图形传达信息与表达美感,信息性不足。例如:为科技论文自动生成科技海报[13],虽然考虑了图形和文本的信息性,但是页面内面板关联性较强,没有体现主次分明的层次感且多样性不足。例如:整数规划网格布局设计[14-16],很好地为用户提供合适且多样性的布局,然而布局元素既没有体现主次也没有存续以往的风格特征。一般来说,生成页面布局需要确定两部分内容: 1)整个页面的结构,这描绘了布局的骨架;2)每个排版元素的属性值,包括位置大小和内容,这确定了骨架的细节。文献[4,17-18]通过专家模板来确定布局结构,这能有效保证生成布局的性能,例如文献[4]利用专家模板并学习美学设计准则,将生成杂志封面转化为能量优化问题求解。文献[6,8,10-11,13]则通过数据驱动的方式学习布局特征:文献[13]使用概率图模型来推断元素属性,沿着二叉树递归搜索最佳分割位置,确定具体结构参数。文献[9]使用概率模型来推断成本函数,转而求解优化问题。文献[14-16]用数学约束来描述布局元素的大小位置,例如文献[14]用混合整数线性规划模型有效生成高质量布局。文献[19-23]将神经网络应用到页面布局生成领域,例如文献[19],提出一个基于内容感知的布局生成模型,用对抗生成网络模拟布局分布。这可以生成高质量的布局,但需要大量细粒度数据来训练模型且模型构建较为困难。据文献调研,现有方法并不能完美解决报纸排版问题。
针对于本文生成报纸版面问题,版面内新闻块以及新闻块内部的标题、文本、图片被视为排版元素,每个元素拥有位置大小和内容属性。版面结构数量众多而且排版元素的位置、大小、内容参数之间相互关联,基于数据驱动模型可以较好地学习元素内部联系却难以精确推断属性值,而规划模型可以基于目标精确求解但很难描述元素之间的内在联系且求解空间较大。要根据新闻内容特征对报纸进行编排,尤其是得到版面规范且美观,信息清晰有层次的报纸版面,仍然是一项具有挑战性的任务。
本文提出了一种融合学习与规划的数字报版面布局自动生成方法。通过历史版面数据集学习布局特征并结合模型推断属性构建混合整数约束规划模型,规划模型根据排版目标确定版面布局和排版元素属性值,最终生成报纸版面。本文的重点在于版面布局生成过程,分3个步骤实现:1)引入了二叉树结构来表示版面结构,并进一步设计最近邻方法来根据新闻属性来推断可用的版面结构,使其保持历史风格并确保生成多样性的版面;2)基于专家经验设计了贝叶斯网络并进行参数学习,对版面内新闻块属性建立推断模型,利用模型推断关键属性后验分布,减小后续模型变量搜索空间;3)利用二叉树结构构建版面结构混合整数约束规划模型,利用推断属性为新闻块属性设定合理区间,为版面设置约束和目标来生成整体协调、规范、美观的报纸版面。本文通过约束规划确定位置大小内容参数,不仅保证布局的对齐、不重叠、不溢出,还考虑了图文比例和矩形比例和留白等美学特性保证美观性,通过头条位置,不同新闻字号的特殊性等属性为新闻提供了层次感,而且部分属性基于模型预测生成,这保留了版面历史风格。
1. 数据集介绍
为了研究版面布局结构以及相关属性之间的联系,本文制作了一个报纸版面的数据集,该数据集包括171个报纸版面,共958篇新闻。这些报纸版面均选自2020年全年的《今日金东》,以保证样本之间的平衡性。利用PPOCRLabel[24]半自动化图形标注工具手动标注了50张版面的布局信息,并利用了PaddleDetection[24]目标检测项目进行训练,自动标注了剩下的新闻页面。对于每张报纸版面,我们标记了每个新闻块的大小和位置属性,以及新闻块内容属性,包括标题大小,正文大小图片元素的大小。此外,借助合作企业的数据库,得到对应新闻块的标题、副标题、正文内容及长度和新闻类型。
2. 版面布局生成方法
版面布局生成方法融合了机器学习和混合整数约束规划两种模型,通过学习模型推断版面结构和预测新闻元素属性,并用于构建规划模型。
如图1所示,框架主要包括4个部分的内容:1)信息提取,预处理用户提交的排版素材,获取新闻特征和用户设置;2)预测版面结构,在训练数据中学习最近邻模型来推断可用布局结构集合;3)预测新闻属性,在训练数据中学习概率图模型来推断头条新闻区块的宽度属性和新闻区块内图形元素的大小;4)求解规划模型,基于版面结构与特定元素的属性推断值构建模型,求解计算所有元素具体属性值。分别使用最近邻方法来预测版面结构集合和贝叶斯网络来预测新闻属性。最近邻方法训练时间快且准确度较高而基于专家经验设计的贝叶斯网络可以较好的描述元素属性之间的内部联系。
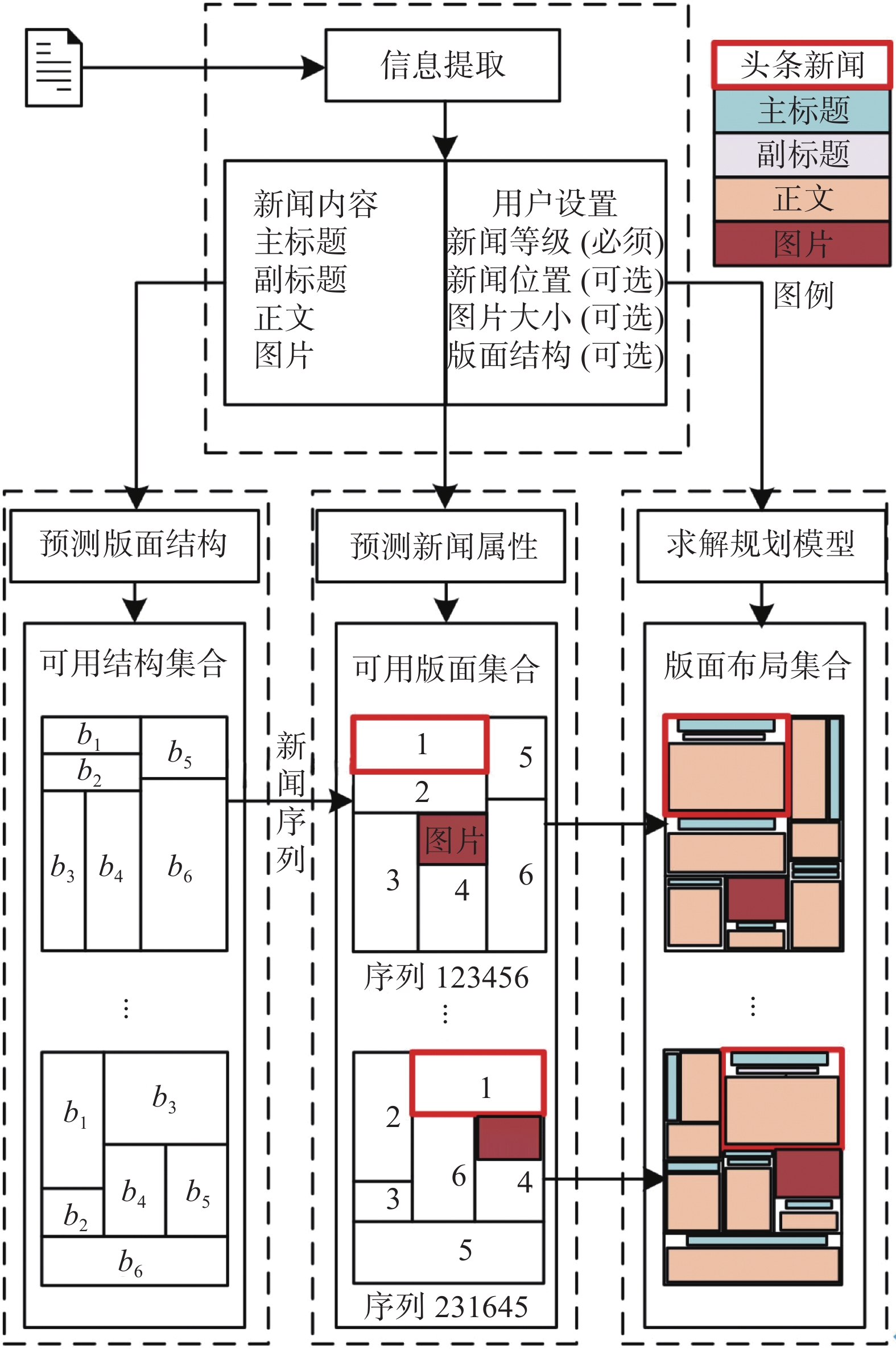 图 1 版面布局生成框架Fig. 1 Framework of generation of layout
图 1 版面布局生成框架Fig. 1 Framework of generation of layout 下载:
全尺寸图片
下载:
全尺寸图片
2.1 新闻属性介绍
数据集包括一组数字报版面和其相对应的版面结构,每个版面
$ {P}{} $ 拥有对应的版面结构$ {s} $ ,且版面由若干个新闻区块$ {b}{} $ 组成,每个版面都有且只有一个头条新闻区块。每个新闻区块拥有主标题、副标题、文本、图形4种元素,其中主标题和正文是必不可少的。对于包含$ {n}{} $ 个新闻区块的版面,每个新闻区块$ {{b}}_{{i}} $ 拥有如下属性:1)新闻区块相对版面宽度
$ {{w}}_{{i}} $ 和高度$ {{h}}_{{i}} $ ;2)新闻主标题字数
$ {a}_{i} $ ,主标题相对全版面字数${{a}}_{{i}}\text{}\text{=}{{}{a}}_{{i}}\text{}\Big/\text{}\displaystyle\sum _{{k}}{{a}}_{{k}}$ ;3)新闻副标题字数
$ {{f}}_{{i}} $ ,副标题相对全版面字数${{f}}_{{i}}\text{}\text{=}\text{}{{f}}_{{i}}\text{}\Big/\text{}\displaystyle\sum _{{k}}{{f}}_{{k}}$ ;4)新闻文本字数
$ {{t}}_{{i}} $ ,文本相对全版面文本字数${{t}}_{{i}}\text{}\text{=}\text{}{{t}}_{{i}}\text{}\Big/\text{}\displaystyle\sum _{{k}}{{t}}_{{k}}$ ;5)新闻图片数量
$ {{}\text{g}}_{{i}} $ ,版面图片总数${G=}\displaystyle\sum {{g}}_{{i}}$ ;6)新闻图形元素相对于版面的尺寸
$ {m}_{i} $ ,版面整体图片相对尺寸$M=\displaystyle\sum {m}_{i}$ ;7)新闻类型
$ {T}_{i} $ ,新闻类型分4种,头条、图片新闻(正文面积远少于图片面积)、有图新闻、无图新闻,$ {T}_{i}\in \left\{H,G,W,N\right\} $ 。2.2 版面结构推断
报纸版面结构集合需体现多样性,这不仅需要新闻样式之间组合多样,也要求版面拥有多样的结构以增加用户选择。本文提出最近邻方法来推断可用的版面结构集合。假设每个新闻区块为矩形,所有矩形边水平或垂直,不重叠,不溢出。递归二分结构包含了绝大部分报纸版面结构。为了描述版面结构,即矩形之间的关系。借鉴生成科技海报[13]和漫画布局[6]工作的思想,引入二叉树来表示报纸的布局,并作为报纸版面的结构类型。图2给出了二叉树表示版面布局结构。
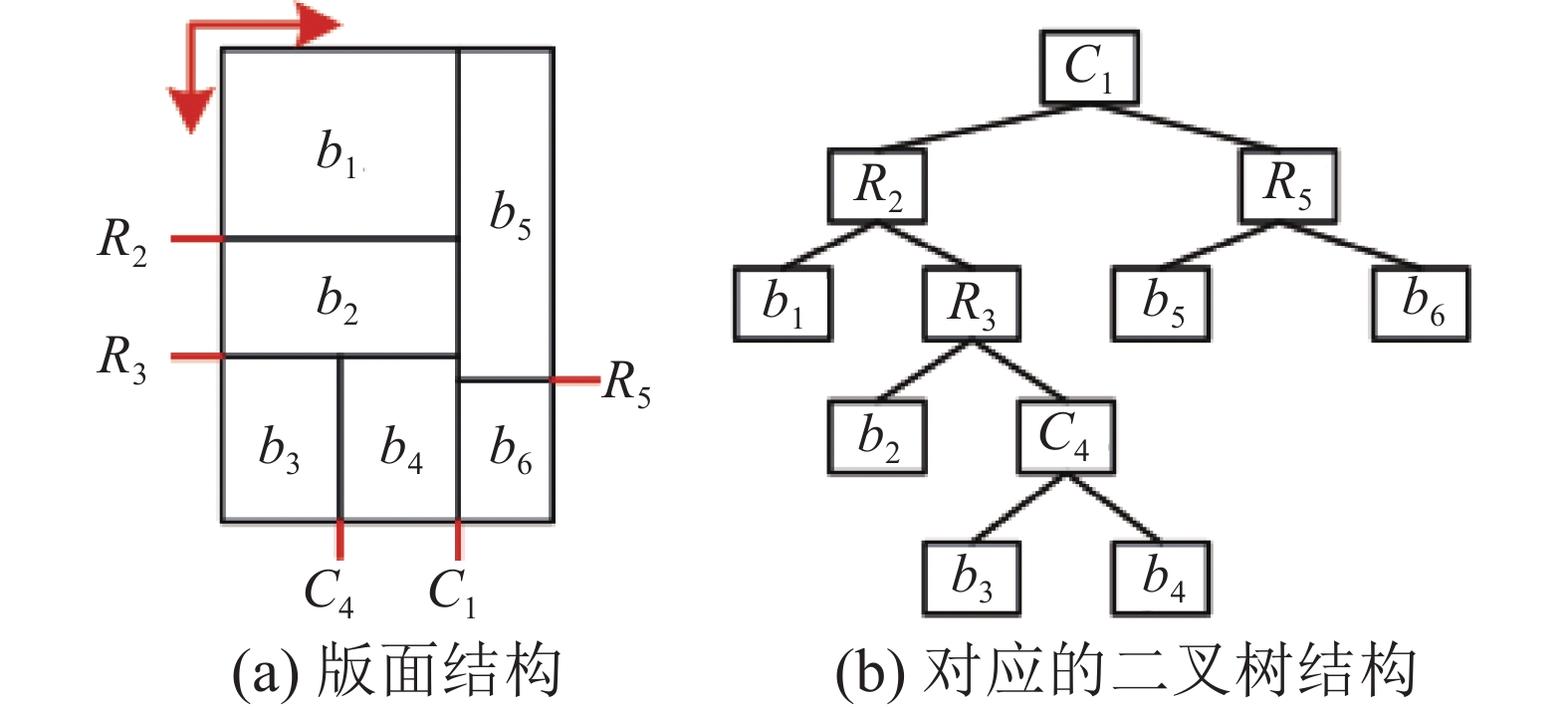 图 2 二叉树表示版面布局结构Fig. 2 Representing layout structure by binary tree下载:
全尺寸图片
图 2 二叉树表示版面布局结构Fig. 2 Representing layout structure by binary tree下载:
全尺寸图片
如图2所示,二叉树的叶子节点表示每个新闻区块,而非叶子节点包括两种类型,
$ C $ 类型节点表示将矩形纵向分割成水平两个子矩形,$ R $ 类型节点表示将矩形横向分割成竖直两个子矩形。为了避免结构重复,每一次横向分割都位于最上方,每一次纵向分割都位于最左方。所以新闻区块划分是按照从左到右,从上到下的顺序。在数据集中,使用二叉树先序遍历顺序表示结构类型。版面结构数量随着新闻块数量组合爆炸。将一个矩形划分成$ n $ 个小矩形,当$ n $ 取值1~9时,不同结构数量分别为1、 2、 6、 25、128、 758、5 014、36 194、 280 433[25]。然而其中充斥着无效结构(并不适合作为报纸版面结构,如图3(a)、图3(b)所示),常用的版面结构却不过几十种。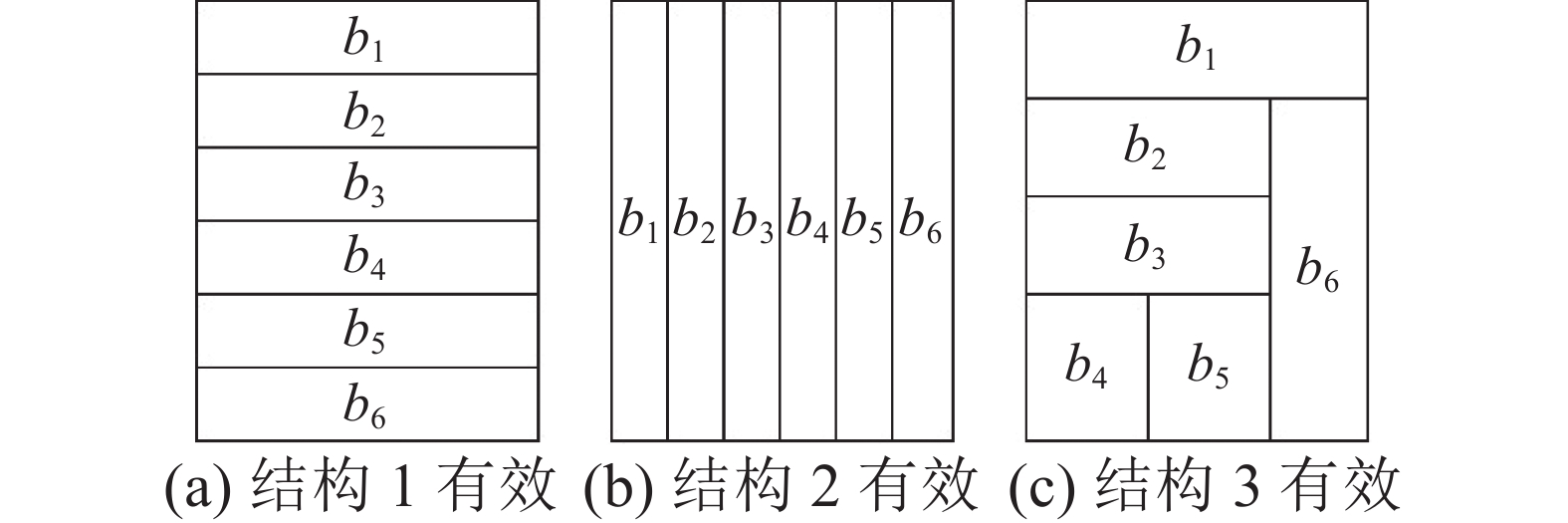 图 3 无效和有效的版面结构示例Fig. 3 Valid and invalid layout structures下载:
全尺寸图片
图 3 无效和有效的版面结构示例Fig. 3 Valid and invalid layout structures下载:
全尺寸图片
如图4所示,第3种结构类型在数据集中占42个版面,占数据集总版面数的24.56%。鉴于此,本文基于版面内容属性来确定版面结构,将版面结构预测视为分类问题,使用最近邻方法来实现。
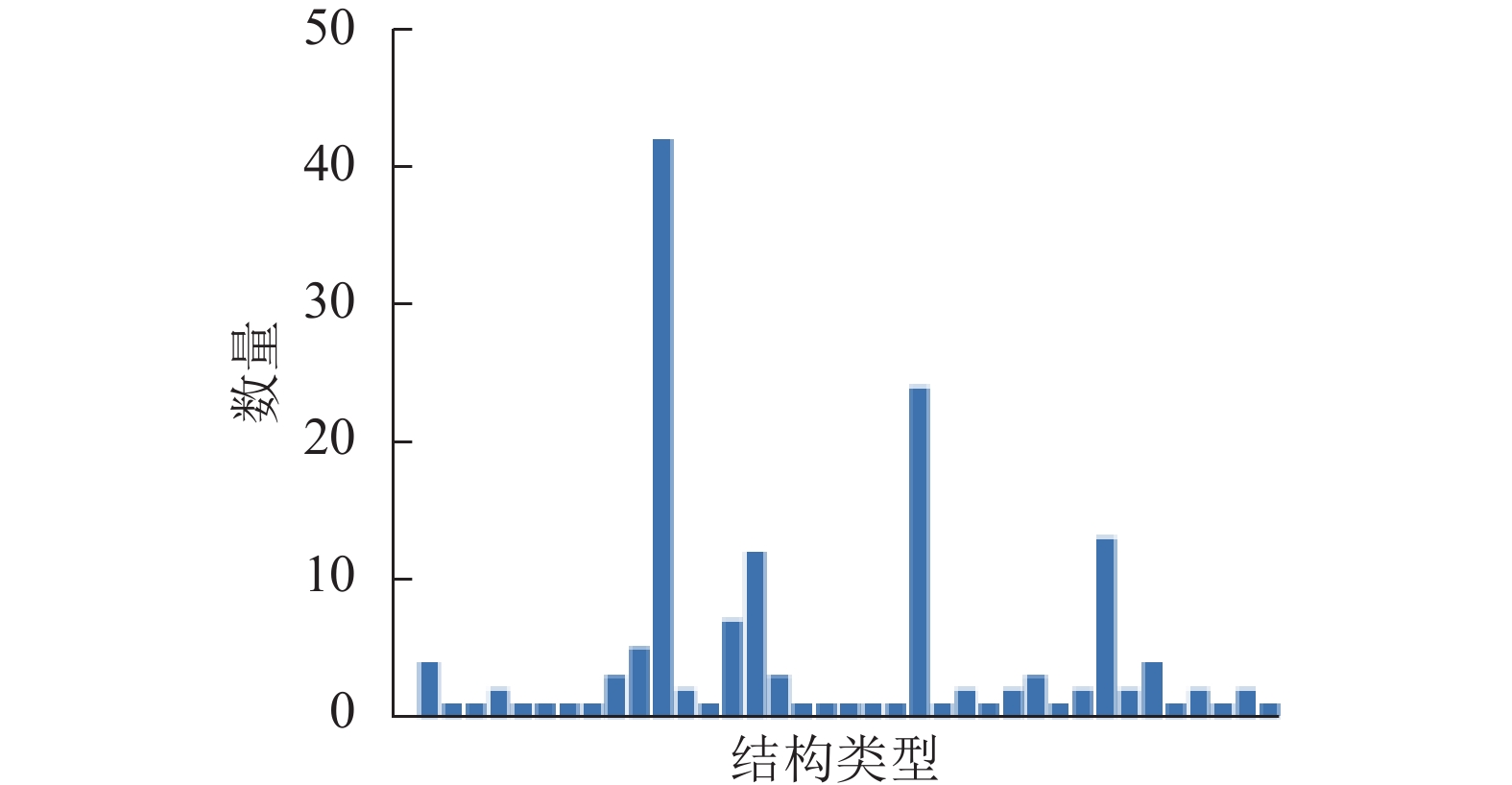 图 4 历史版面类型分布Fig. 4 Distribution of layout structures下载:
全尺寸图片
图 4 历史版面类型分布Fig. 4 Distribution of layout structures下载:
全尺寸图片
最近邻方法的实现步骤为
1)特征标准化:与相关排版专家交流发现,版面结构主要取决于每个新闻区块的尺寸,定义第
$ i $ 个新闻区块内容的相对尺寸$ {e}_{i} $ 为$$ {e}_{i}={\lambda }_{1}\cdot {a}_{i}+{\lambda }_{2}\cdot {f}_{i}+{\lambda }_{3}\cdot {t}_{i}+{\lambda }_{4}\cdot {g}_{i} $$ (1) 其中
$ {\lambda }_{1}、{\lambda }_{2}、{\lambda }_{3}、{\lambda }_{4} $ 分别为报纸版面中主标题、副标题、正文、图片的平均相对尺寸。对于一篇拥有$ n $ 篇新闻的版面$ {p}_{m} $ ,将该样本的特征向量$ {\boldsymbol{V}}_{m} $ 定义为$$ {\boldsymbol{V}}_{m}=\left[{e}_{{c}_{1}}{e}_{{c}_{2}}\cdots {e}_{{c}_{n}}\right] $$ (2) $$ {e}_{{c}_{j}}\leqslant {e}_{{c}_{j+1}},\forall j\in [2,n),j\in {N}^+ $$ (3) 其中
${c}_{1},{c}_{2},\cdots {c}_{n}$ 为1,2,···,n的一个序列,并满足$ {e}_{{c}_{1}} $ 为头条相对尺寸。2)样本距离:使用欧氏距离作为样本距离,版面
$ {p}_{u} $ 和$ {p}_{v} $ 的距离$ d(u,v) $ 定义为$$ d(u,v)=\sqrt{({\boldsymbol{V}}_{{p}_{u}}-{\boldsymbol{V}}_{{p}_{v}})\cdot ({\boldsymbol{V}}_{{p}_{u}}-{\boldsymbol{V}}_{{p}_{v}}{)}^{{{\rm T}}}} $$ (4) 3)分类方式:由于同样的新闻内容根据排版的需求可能有多个结构选择,基于新闻内容匹配版面结构集合,本文将邻近的
$ k $ 个结构作为可用结构集合。2.3 头条宽度及图形尺寸推断
本文方法通过混合整数约束规划的方法来求解版面属性值。这主要包括两方面,一是新闻块位置坐标,二是新闻内容属性值,包括主标题字号、主标题样式(横竖)、正文栏数、图片尺寸以及各元素间距等。规划模型的解空间非常大,为保证多样性布局,对不同版面结构和新闻顺序排列组合,这将极大的增加求解空间。为了减小解空间,设计贝叶斯网络模型来推断头条新闻块的宽度和图片元素的尺寸。
头条新闻在版面中占据最重要的位置(通常位于版面最上方)。确定头条新闻的宽度后,很大程度影响着内容属性。头条新闻宽度主要受到头条内容和版面结构的影响。假设每个新闻区块之间内容都是相互独立的。头条宽度
$ w $ 主要取决于头条的主标题$ a $ 、副标题$ f $ 、文本$ t $ 、图片数量$ g $ 和版面结构$ s $ ,图5贝叶斯网络表示了头条宽度与内容之间的联系。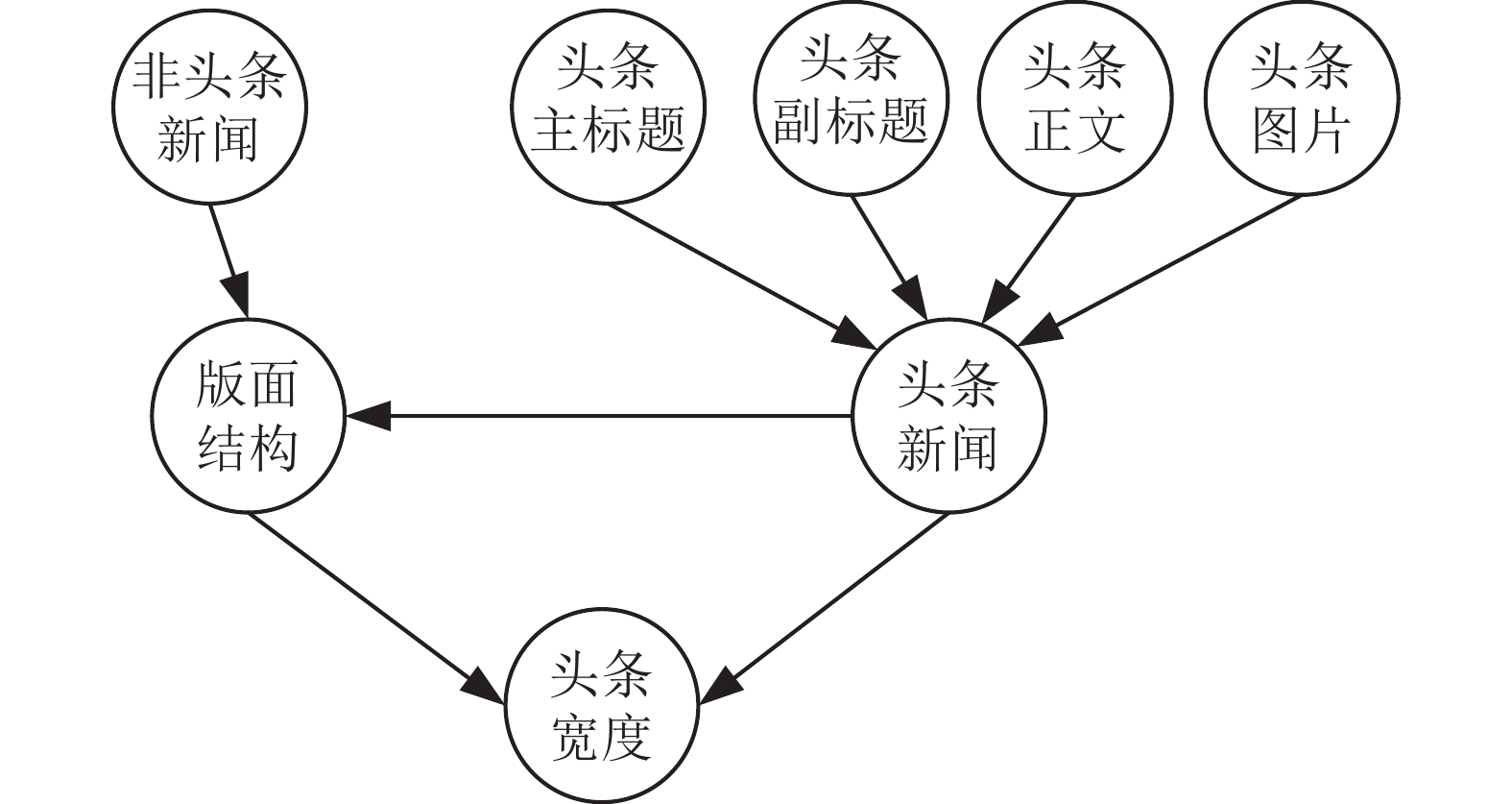 图 5 用于推断头条宽度的贝叶斯网络结构Fig. 5 Network structure to infer width of headline下载:
全尺寸图片
图 5 用于推断头条宽度的贝叶斯网络结构Fig. 5 Network structure to infer width of headline下载:
全尺寸图片
使用贝叶斯估计来学习模型参数的条件概率分布(conditional probability distribution,CPD),将头条新闻宽度推断作为最大后验假设问题(maximum posterior probability,MAP),定义如下:
$$ {w}^{*}=\mathrm{argmax}P\left(w\right|s,a,f,t,G) $$ (5) 图片元素是新闻块中重要的视觉元素,图片的大小直接影响版面的视觉传达。在后续规划模型中,图片大小与新闻块比例相关,通过变量乘积不等式来约束,求解空间大。本文设计贝叶斯网络来推断图片大小。图片的重要性与新闻类型相关,头条图片最为重要,其次为图片新闻。在贝叶斯网络中,新闻块的图片元素大小主要取决于新闻块的主标题、文本、图片数以及新闻类型。使用贝叶斯估计来学习模型参数的条件概率分布(CPD),将图片元素大小推断作为最大后验假设问题(MAP),定义如下:
$$ {m}^{*}=\mathrm{argmax}P\left(m\right|T,a,t,G) $$ (6) 如图6所示,版面风格导致新闻块变量集中的分布在几个区间内。各个变量需离散化表示,将预测宽度区间内的平均宽度作为推测宽度。预测元素大小区域平均值作为预测大小。
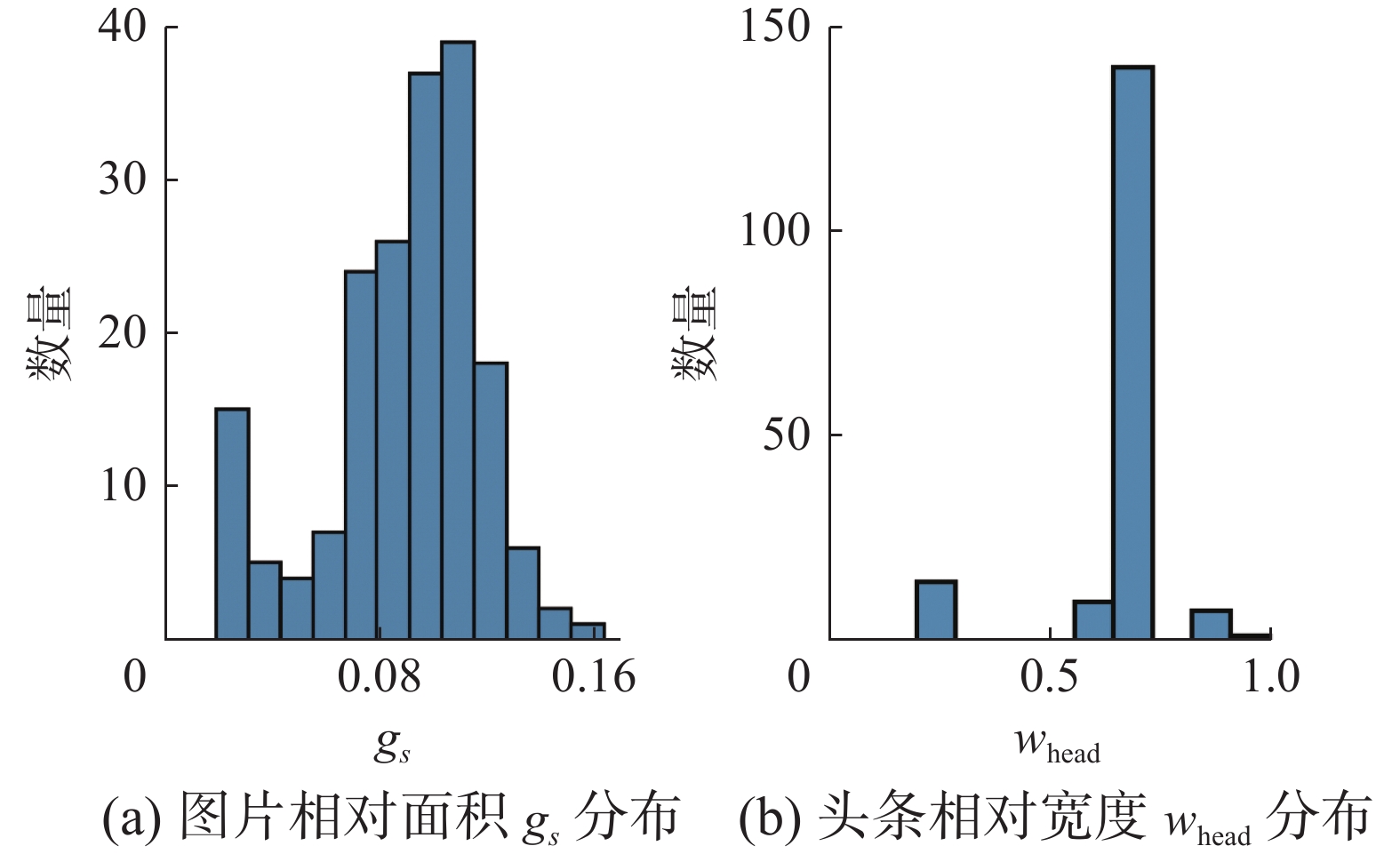 图 6 历史版面图片面积与头条宽度分布Fig. 6 Distribution of width of headline and size of graph下载:
全尺寸图片
图 6 历史版面图片面积与头条宽度分布Fig. 6 Distribution of width of headline and size of graph下载:
全尺寸图片
2.4 约束规划模型
本节设计混合整数约束规划模型用于生成报纸版面。模型约束通过结构二叉树、新闻内容、属性预测值来建立。基于属性预测,为关键属性值确定候选区间,减小求解空间突出版面特征。生成报纸版面的要求主要有3个:
1)每个新闻块矩形,对齐良好,布置在报纸版面上没有空洞且不会溢出版面。
2)新闻的图文比例合适、头条及各个新闻块符合报纸风格。
3)新闻块之间整体协调且各自之间清晰有差异主次分明。
2.4.1 版面结构约束
定义报纸版面平面坐标系,左上角为坐标系原点,
$ X $ 轴向右为正,$ Y $ 轴向下为正。为了描述每个新闻块$ {b}_{i} $ 的位置和大小,定义决策变量$ {x}_{i} $ 、$ {y}_{i} $ 、$ {w}_{i} $ 、$ {h}_{i} $ 。其中$ {x}_{i} $ 、$ {y}_{i} $ 表示新闻块$ {b}_{i} $ 左上顶点的坐标;$ {w}_{i} $ 、$ {h}_{i} $ 表示新闻块的宽度和高度。借助2.2节引入的二叉树结构来实现第一个目标,其中的叶子节点表示版面新闻块矩形,非叶子节点表示被划分矩形。定义中间变量$ {X}_{i} $ 、$ {Y}_{i} $ 、$ {W}_{i} $ 、$ {H}_{i} $ 分别表示非叶子节点矩形$ {B}_{i} $ 坐标和宽高,节点按照二叉树先序遍历顺序依次表示。如图7所示,根据非叶子节点的定义,每个非叶子节点矩形有横、竖(RC)两种划分方式。对于二叉树中任意非叶子节点,通过以下约束保证结构关系。
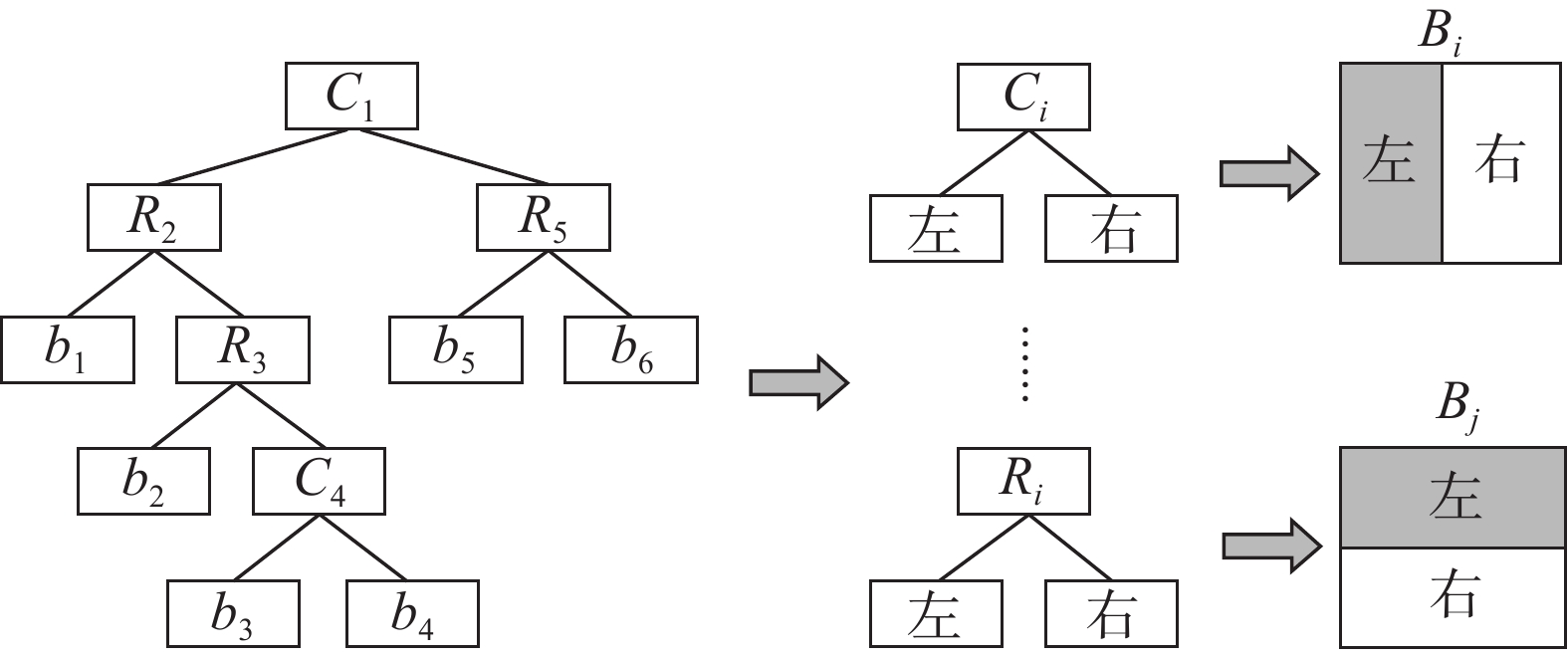 图 7 二叉树结构转化版面结构Fig. 7 Transform binary tree to layout structure下载:
全尺寸图片
图 7 二叉树结构转化版面结构Fig. 7 Transform binary tree to layout structure下载:
全尺寸图片
$$ {N}_{i}\cdot \left({w}_{\mathrm{l}\mathrm{e}\mathrm{f}\mathrm{t}}+{w}_{\mathrm{r}\mathrm{i}\mathrm{h}\mathrm{t}}-{W}_{i}\right)+\left(1-{N}_{i}\right)\cdot \left({h}_{\mathrm{l}\mathrm{e}\mathrm{f}\mathrm{t}}+{h}_{\mathrm{r}\mathrm{i}\mathrm{g}\mathrm{h}\mathrm{t}}-{H}_{i}\right)=0 $$ (7) $$ {N}_{i}\cdot ({h}_{\mathrm{l}\mathrm{e}\mathrm{f}\mathrm{t}}-{H}_{i})+(1-{N}_{i})\cdot ({w}_{\mathrm{l}\mathrm{e}\mathrm{f}\mathrm{t}}-{W}_{i})=0 $$ (8) $$ {N}_{i}\cdot ({h}_{\mathrm{r}\mathrm{i}\mathrm{g}\mathrm{h}\mathrm{t}}-{H}_{i})+(1-{N}_{i})\cdot ({w}_{\mathrm{r}\mathrm{i}\mathrm{g}\mathrm{h}\mathrm{t}}-{W}_{i})=0 $$ (9) $$ {x}_{\mathrm{l}\mathrm{e}\mathrm{f}\mathrm{t}}={X}_{i},{y}_{\mathrm{l}\mathrm{e}\mathrm{f}\mathrm{t}}={Y}_{i} $$ (10) $$ {x}_{\mathrm{r}\mathrm{i}\mathrm{g}\mathrm{h}\mathrm{t}}+{w}_{\mathrm{r}\mathrm{i}\mathrm{g}\mathrm{h}\mathrm{t}}={X}_{i}+{W}_{i},{y}_{\mathrm{l}\mathrm{e}\mathrm{f}\mathrm{t}}+{h}_{\mathrm{l}\mathrm{e}\mathrm{f}\mathrm{t}}={Y}_{i}+{H}_{i} $$ (11) $ \mathrm{式}\mathrm{中}:{x}_{\mathrm{l}\mathrm{e}\mathrm{f}\mathrm{t}} $ 、$ {y}_{\mathrm{l}\mathrm{e}\mathrm{f}\mathrm{t}} $ 、$ {w}_{\mathrm{l}\mathrm{e}\mathrm{f}\mathrm{t}} $ 、$ {h}_{\mathrm{l}\mathrm{e}\mathrm{f}\mathrm{t}} $ 、$ {x}_{\mathrm{r}\mathrm{i}\mathrm{g}\mathrm{h}\mathrm{t}} $ 、$ {y}_{\mathrm{r}\mathrm{i}\mathrm{g}\mathrm{h}\mathrm{t}} $ 、$ {w}_{\mathrm{r}\mathrm{i}\mathrm{g}\mathrm{h}\mathrm{t}} $ 、$ {h}_{\mathrm{r}\mathrm{i}\mathrm{g}\mathrm{h}\mathrm{t}} $ 分别表示第$ i $ 个非叶子节点矩形的左子代和右子代的位置和大小,$ {N}_{i} $ 表示节点类型,$ C $ 类型节点取值为1,$ R $ 类型取值0。每个矩形都会根据它的祖先节点来组织它的周边结构。2.4.2 内容约束以及基于推断进一步约束
每篇新闻的所有内容元素必须包含在相应矩形中。内容约束将新闻内容元素面积转化为占据矩形面积的高度,保证新闻内容高度不超过矩形高度,即留白高度大于等于0。具体样式微调优化参见项目相关文献[25]。为了保持矩形块内元素组织的合理性,主要考虑以下约束:
1)横竖标题样式
$ {t}_{{\mathrm{s}\mathrm{t}\mathrm{y}\mathrm{l}\mathrm{e}}_{i}} $ 取决于新闻块矩形的宽高比,通过数据集所有竖排标题的最小高宽比确定阈值。$$ {t}_{{\mathrm{s}\mathrm{t}\mathrm{y}\mathrm{l}\mathrm{e}}_{i}}=\left\{\begin{array}{l}1\text{\text{,}}{h}_{i}\geqslant {r}_{{\mathrm{s}\mathrm{t}\mathrm{y}\mathrm{l}\mathrm{e}}_{i}}\cdot {w}_{i}\\ 0\text{\text{,}}其他\end{array}\right. $$ (12) 2)为了获得具有历史图文比例风格和头条风格的版面,图片大小
$ {m}_{i} $ 和头条宽度$ {w}_{\mathrm{h}\mathrm{e}\mathrm{a}\mathrm{d}} $ 主要取决于基于2.3节的贝叶斯网络的预测值。其中$ {k}_{1}、{k}_{2} $ 为可放松的阈值。$$ (1-{k}_{1})\cdot {m}_{i}^{*}\leqslant {m}_{i}\leqslant (1+{k}_{1})\cdot {m}_{i}^{*} $$ (13) $$ (1-{k}_{2})\cdot {w}_{\mathrm{h}\mathrm{e}\mathrm{a}\mathrm{d}}^{*}\leqslant {w}_{\mathrm{h}\mathrm{e}\mathrm{a}\mathrm{d}}\leqslant (1+{k}_{2})\cdot {w}_{\mathrm{h}\mathrm{e}\mathrm{a}\mathrm{d}}^{*} $$ (14) 3)图片宽高比例变化不能太大以保持图片的清晰度,图片比例阈值主要依靠专家经验。
$$ (1-{k}_{3})\cdot {r}_{i}\cdot {o}_{i}\leqslant {q}_{i}\leqslant (1+{k}_{3})\cdot {r}_{i}\cdot {o}_{i} $$ (15) 式中:
$ o $ 、$ q $ 为图片宽度高度,$ r $ 为图片原始高宽比,$ {k}_{3} $ 为比例阈值。虽然该规划模型是非线性的,通过使用机器学习模型推断来减小求解空间,降低计算成本,同时得到具有风格特色的版面。2.4.3 整体布局与用户偏好
为了实现新闻块之间整体协调且主次分明。报纸版面中的新闻是有重要程度之分的,用户标注每篇新闻的等级(重要性)。设计以下指标来描述整体的布局状态。
1)新闻层次:新闻等级影响对应新闻块标题大小,更重要的新闻会拥有更大字号的标题。
2)新闻块留白:目标得到更少的新闻留白,尽量使得新闻填满整个版面。
3)新闻块矩形比例:对矩形比例合适的情况进行奖励,越接近黄金比例奖励越高。
如图8所示,图8(a)中新闻1等级更高,新闻块
$ {b}_{1} $ 中新闻相比新闻块$ {b}_{2} $ 中的拥有更大的标题字号;图8(b)中新闻块尽可能像$ {b}_{1} $ ,拥有更少的留白,而不是$ {b}_{2} $ ;图8(c)中新闻块矩形$ {b}_{1} $ 比例更接近黄金比例,模型对它的奖励大于$ {b}_{5} $ 的奖励,模型将会尝试寻找全局奖励最大的解。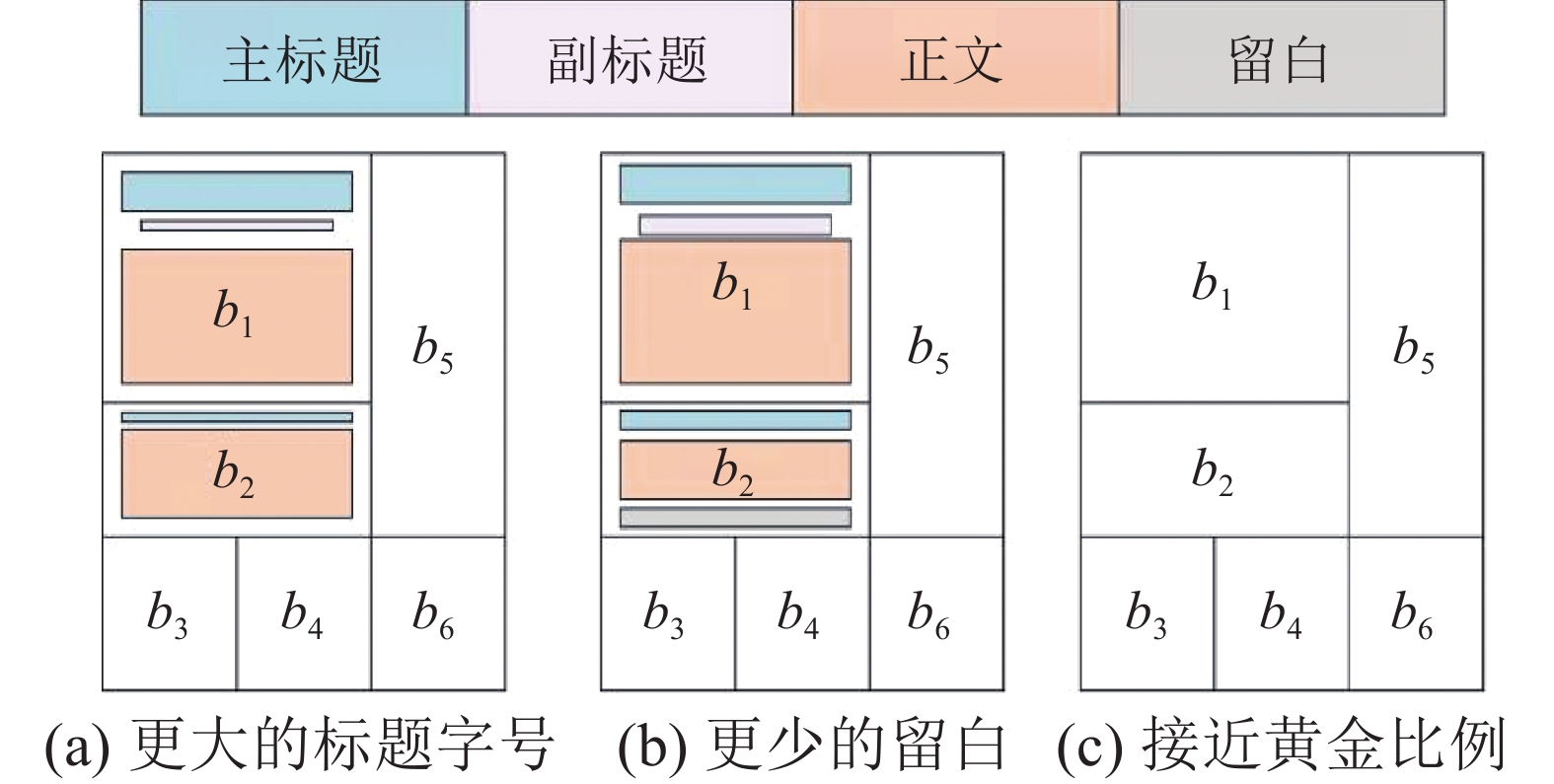 图 8 整体布局目标具体表现Fig. 8 Overall goals of generating layouts下载:
全尺寸图片
图 8 整体布局目标具体表现Fig. 8 Overall goals of generating layouts下载:
全尺寸图片
基于已定义的决策变量,可灵活实现用户指令。例如指定任意两篇新闻之间相对位置,新闻1必须放置在新闻2的正上方,可以根据新闻序列得到它们对应的新闻块
$ i $ 、$ j $ ,只需要增加约束:$ {y}_{i}+{h}_{i}\leqslant {y}_{j} $ 。同样,也可以指定新闻相对版面的位置。除此之外,可以具体指定某一篇新闻的字号大小、图片比例等属性。对于留白较大的区域,使用项目相关文献[26]的方法填充适当的报花。2.4.4 总结
算法1概述了生成版面的整个过程。步骤2)、3)根据新闻内容分别推断版面结构和图形元素的大小属性,步骤5)基于结构和内容推断头条宽度,步骤6)~11)根据不同的结构和新闻序列建立约束规划模型进行求解,步骤12)松弛对留白、头条、图片尺寸的约束来生成更多的解。
算法1 版面布局生成
输入 新闻内容articles与用户设置setting
1) 初始化版面集合
$ F=\left\{\right\} $ 2) 推断可用版面结构
$ S=\mathrm{k}\mathrm{n}\mathrm{n}\left(\mathrm{a}\mathrm{r}\mathrm{t}\mathrm{i}\mathrm{c}\mathrm{l}\mathrm{e}\mathrm{s}\right) $ 3) 推断版面内图片尺寸
$ m=\mathrm{b}\mathrm{y}\mathrm{s}\left(\mathrm{a}\mathrm{r}\mathrm{t}\mathrm{i}\mathrm{c}\mathrm{l}\mathrm{e}\mathrm{s}\right) $ 4) for s in S:
5) 推断头条宽度
$ {w}_{\mathrm{h}\mathrm{e}\mathrm{a}\mathrm{d}}=\mathrm{b}\mathrm{y}\mathrm{s}(\mathrm{a}\mathrm{r}\mathrm{t}\mathrm{i}\mathrm{c}\mathrm{l}\mathrm{e}\mathrm{s},s) $ 6)
$ \mathrm{w}\mathrm{h}\mathrm{i}\mathrm{l}\mathrm{e}\left|\right|F\left|\right| $ < 要求的版面数量:7)
$ \mathrm{f}\mathrm{o}\mathrm{r} $ 每个未使用的新闻序列$ \mathrm{s}\mathrm{e}\mathrm{q} $ :8) 建规划模型
$ {w}_{\mathrm{h}\mathrm{e}\mathrm{a}\mathrm{d}},m,s\to \mathrm{c}\mathrm{p}\mathrm{M}\mathrm{o}\mathrm{d}\mathrm{e}\mathrm{l} $ 9)
$ \mathrm{i}\mathrm{f}\mathrm{ }\mathrm{c}\mathrm{p}\mathrm{M}\mathrm{o}\mathrm{d}\mathrm{e}\mathrm{l} $ 求解出布局$ f $ :10) 布局添加到集合
$ F=F\bigcup f $ 11) 标记新闻序列
$ \mathrm{s}\mathrm{e}\mathrm{q} $ 已使用12) 放松留白,头条,图片约束阈值
输出 版面布局集合
$ F $ 3. 实验结果
利用历史优秀版面数据集对推断模型进行训练与验证。由于数据集较小,对于版面包含不同区块数量,采用交叉验证的方式进行模型训练与验证。训练集与测试集比例为4∶1。数据集包含4篇新闻的版面10个,5篇新闻的版面51个,6篇新闻的版面80个。
规划模型:融合了学习模型的预测约束,可以生成多样性的结果并延续历史风格。从过去一年里《今日金东》报纸中随机抽取报纸版面并提取其中包含的新闻内容,标记好每篇新闻的等级。对于性能定量分析;从计算时间和布局数量角度,分别在新闻内容特性方面对比分析了本文方法相较于纯规划模型(没有融合预测约束)的性能。
用户定性分析:我们邀请了5位没有经历过排版培训的在校学生作为排版新手。要求他们在学习了历史版面后,随机选择一篇版面新闻内容进行排版,力求版面的可读性、信息性与美观性。随后邀请10位用户进行评估,通过比较新手、专家(已出版版面)、规划算法和本文方法生成的版面布局在不同指标下的得分,来验证方法的有效性。为用户提供3个评价指标:1)可读性:单篇新闻的清晰度,主要体现在版面内部新闻之间界限、新闻内部元素之间界限的清晰性;2)信息性:在阅读报纸版面新闻时,能够轻松获取版面的重要信息;3)美观性:报纸版面的美学感受。
3.1 推断模型定量分析
最近邻分类方法在给定测试样本后,基于样本距离找出训练集中与之靠近的
$ k $ 个训练样本,并以样本间距离倒数加权“投票”方式得到合适的类别。由于同样的新闻内容根据排版的需求可能有多个结构选择,基于新闻内容得到合适的版面结构,与测试样本邻近的$ k $ 个样本的结构全部作为可用结构$ {S}^{*} $ ,而不是投票选出唯一的分类结果$ {s}^{*} $ ,显然$ {s}^{*}\in {S}^{*} $ 。$ k $ 值偏大会导致无效结构增多,并增加后续相应的计算压力;而k值偏小则会导致错失可行结构,使得最终版面的结构较为单一,减少多样性。准确率定义如下:$$ {{A}}_{\mathrm{c}}=\sum _{s\in {T}_{s}}I({s}_{\theta },{s}_{\beta })\bigg/\sum _{s\in {T}_{s}}1 $$ (16) $$ I({s}_{\theta },{s}_{\beta })=\left\{\begin{array}{l}1\text{,}\;\;s\in{s}_{\beta }\text{或}s=={s}_{\beta }\\ 0,\;\;其他\end{array}\right. $$ (17) 式中:
$ {s}_{\theta } $ 是数据集人工排版的版面原始结构,$ {s}_{\beta } $ 是推断结果。如图9所示,对k进行依次取值并在数据集上进行5折交叉验证,对比随机方法(随机选取一个版面)、本文方法和最近邻方法(选出唯一结构),并寻找最优k值提高推断准确率。
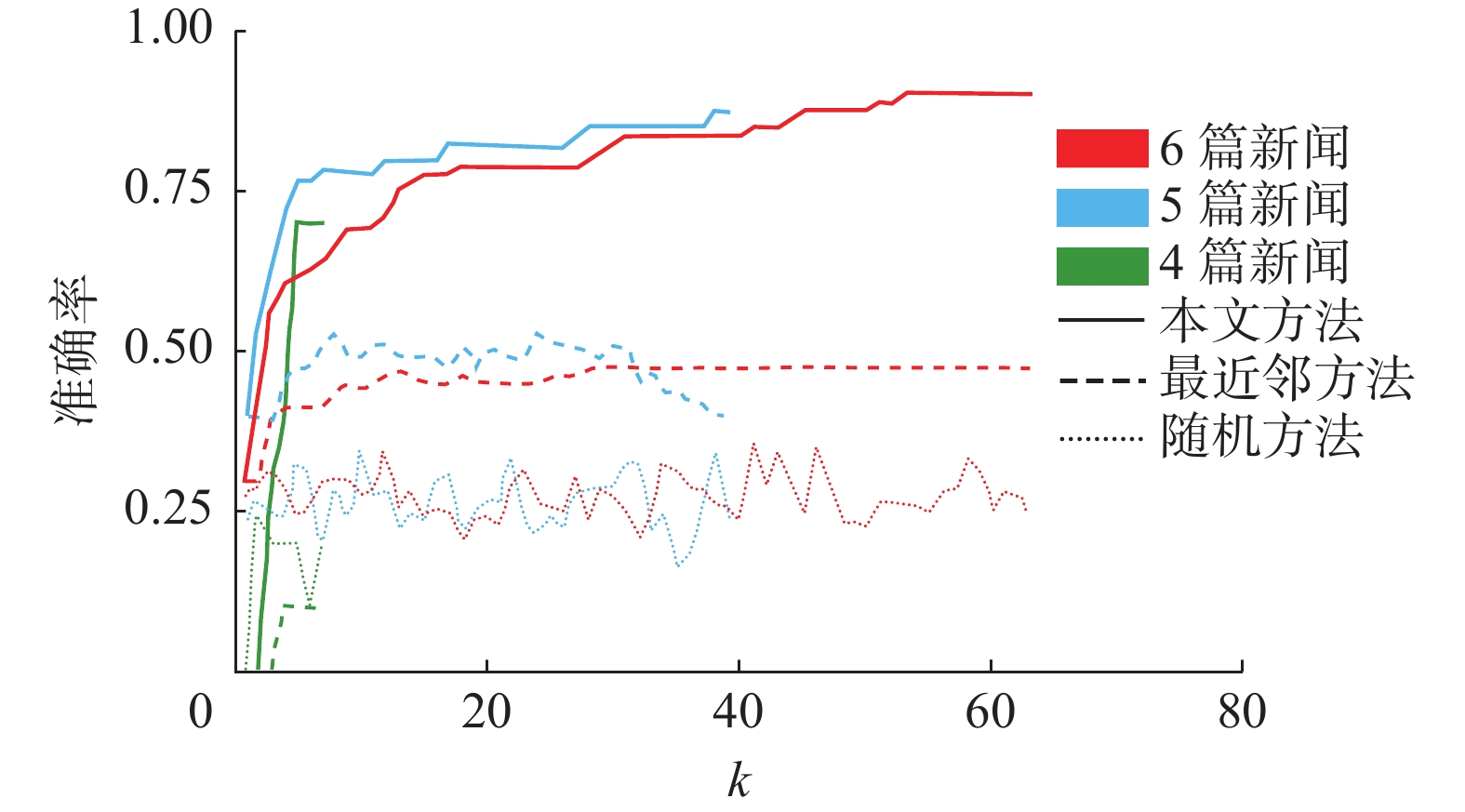 图 9 准确率随
图 9 准确率随$ k $ 值变化曲线Fig. 9 Curve of prediction accuracy with$ \mathit{k} $ value下载:
全尺寸图片
从图9可以看出,最近邻方法相比于随机选取方法,最近邻方法准确率优势明显。而本文方法选取最近的k个版面结构集合,准确率高于上述两种方法。更进一步,我们将预测结构中与原始结构相同个数c作为指标,比较了不同
$ k $ 值下的本文方法和随机选取k个版面方法的性能,如图10所示。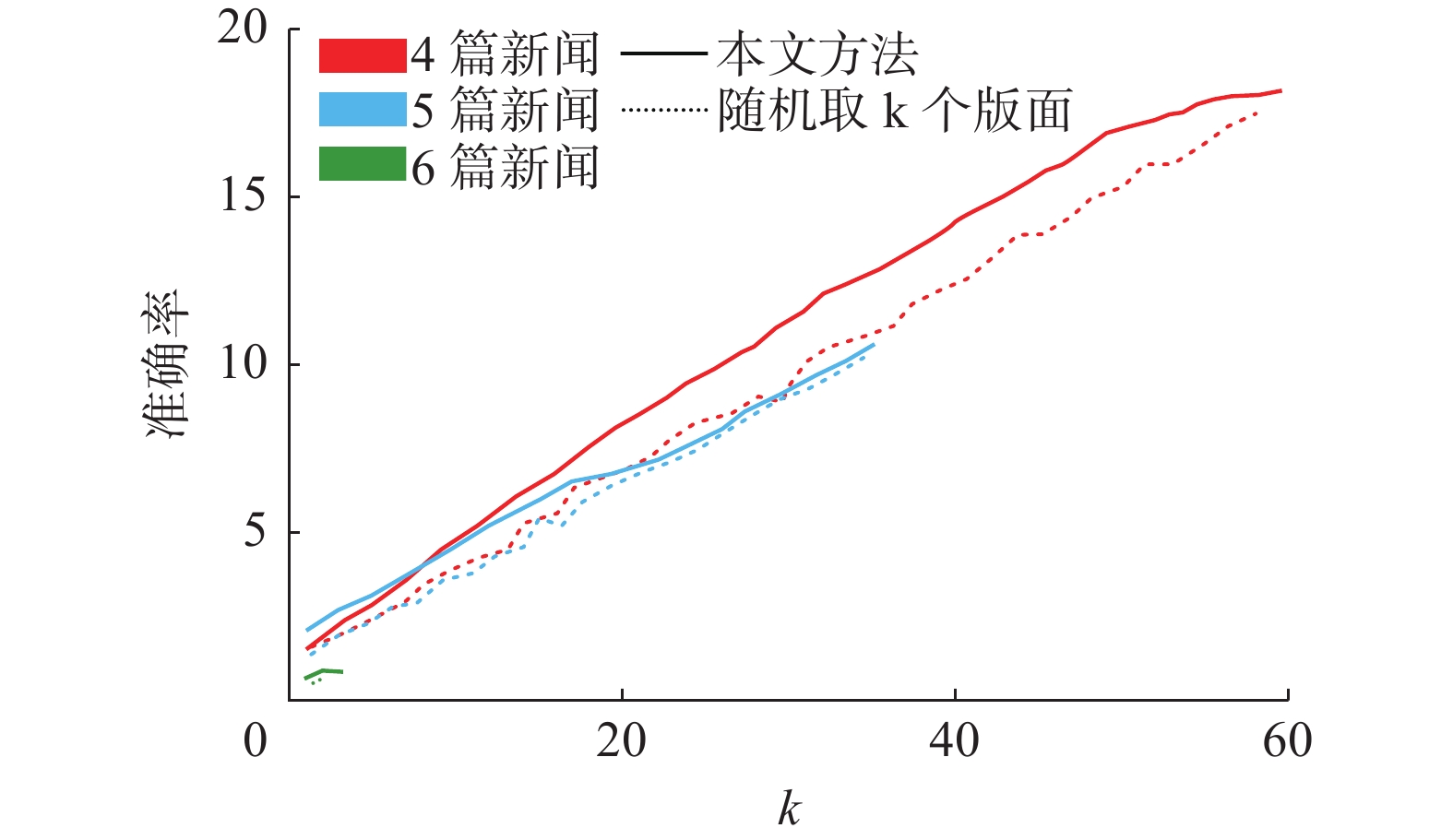 图 10 预测结构
图 10 预测结构$ c $ 值随$ k $ 值变化曲线Fig. 10 Curve of$ c $ value changes with$ \mathit{k} $ value下载:
全尺寸图片
本文方法推断的结构更接近原始结构:
$$ c=\sum _{s\in {T}_{s}}I({s}_{ {\theta }},{s}_{ {\beta }}) $$ (18) 此外,为了比较二者实际对排版结果的影响。对于包含6篇新闻的版面,选定k = 15,随机挑选了5个版面的内容,按照两种方法得到的结构进行排版。排版结果如表1所示,对于本文方法得到的结构集合,包含的结构数量更少,排版得到平均布局数量反而更多,排版时间更短,更加适合新闻内容。本文提出的推断版面结构最近邻方法可以提高排版效率。
表 1 不同预测结构排版结果Table 1 Results with different predicted structures方法 结构数量 布局数量 平均布局数量 时间/s 随机k个版面 6.0 40.0 6.7 62.34 本文方法 4.4 35.2 8.0 45.01 为了进行新闻属性推断,我们将头条宽度和图片尺寸同样作为分类问题。为其划分取值区间,将落入区间内的训练样本平均值作为预测值。采用准确率和相对误差ER来描述推断模型性能。
$$ E_{\mathrm{R}}=\frac{\left|\theta -\beta \right|}{\beta } $$ (19) 式中:
$ \theta $ 为预测值,$\, \beta $ 为原始版面值。得到的预测结果如表2所示。表 2 属性预测结果Table 2 Performance of attributes inference新闻/篇 头条宽度 图片尺寸 准确率 误差 准确率 误差 4 0.70 0.11 0.73 0.29 5 0.89 0.10 0.50 0.25 6 0.81 0.23 0.74 0.20 3.2 计算性能分析
本文推断模型分别利用scikit-learn[27]中最近邻分类模型和Pgmpy[28]中贝叶斯网络模型实现,规划模型使用Google开源的OR-Tools中CP-SAT作为约束规划的求解器[29],均使用Python3.8编写。实验配置为8核64位Intel(R) Core(TM) i7-4790 3.60 GHz CPU和8 GB RAM的计算机上进行。使用本文方法生成多组版面,每组版面拥有相同内容,每个版面均包含6篇新闻。
表3给出了每个步骤所需的平均时间。运行时间明显少于专业人员和新手制作报纸版面所花费的时间。本文方法平均4 s即可生成一个版面布局。
表 3 每个步骤的平均运行时间Table 3 Running time of each steps 排版步骤 平均时间 信息提取 0.06 预测版面结构 0.06 预测新闻属性 0.08 求解规划模型 3.64 在确定结构和新闻序列后,求解规划模型的时间性能会受到新闻内容的影响。本文考虑了版面中头条新闻尺寸
$ {s}_{\mathrm{h}\mathrm{e}\mathrm{a}\mathrm{d}} $ 、新闻总尺寸$ {s}_{\mathrm{p}} $ 、新闻尺寸标准差$ {D}_{\mathrm{p}} $ 和图片数量$ G $ 对模型性能产生的影响;另一方面,对学习到的新闻属性进行消融实验,即为规划模型融合不同的推断属性,分析其性能影响。新闻总尺寸$ {s}_{\mathrm{p}} $ 、新闻尺寸标准差$ {D}_{\mathrm{p}} $ 的计算方法为$$ {s}_{\mathrm{p}}=\sum _{{b}_{i}\in p}{s}_{i} $$ (20) $$ {D}_{\mathrm{p}}=\sqrt{\left(\sum ({s}_{i}-{s}_{\mathrm{p}}/n{)}^{2}\right)\big/n} $$ (21) 式中:
$ n $ 表示版面内新闻数量,相对尺寸通过式(1)计算。实验记录了新闻内容在相同版面结构和新闻序列下,规划模型和本文方法的求解时间和布局数量,所有版面新闻内容从数据库中按相应指标线性插值取出。图11、12给出了各种方法在不同新闻内容特征下的性能表现。
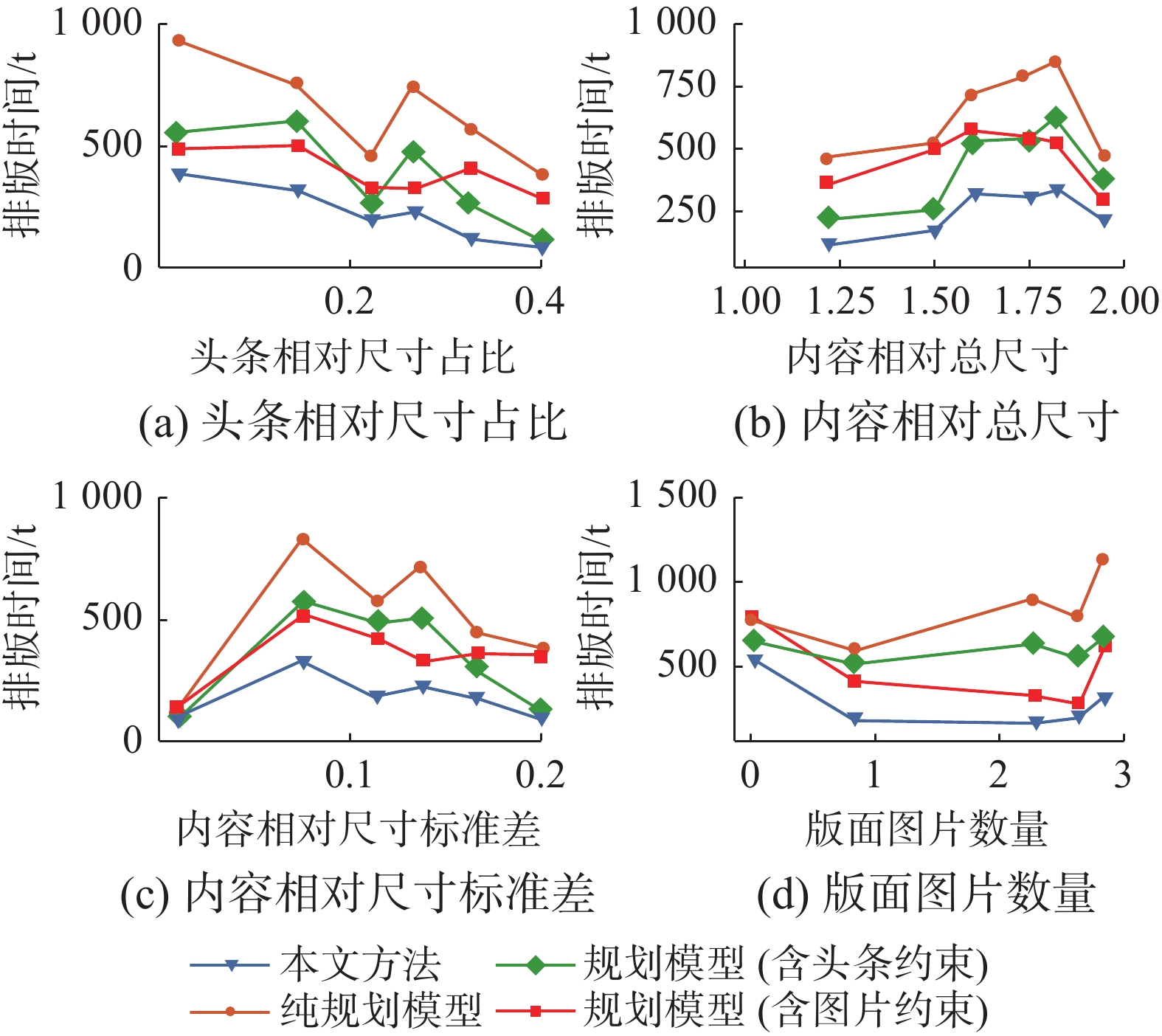 图 11 布局数量随版面内容特征变化曲线Fig. 11 Layout quantity change with content characteristics下载:
全尺寸图片
图 11 布局数量随版面内容特征变化曲线Fig. 11 Layout quantity change with content characteristics下载:
全尺寸图片
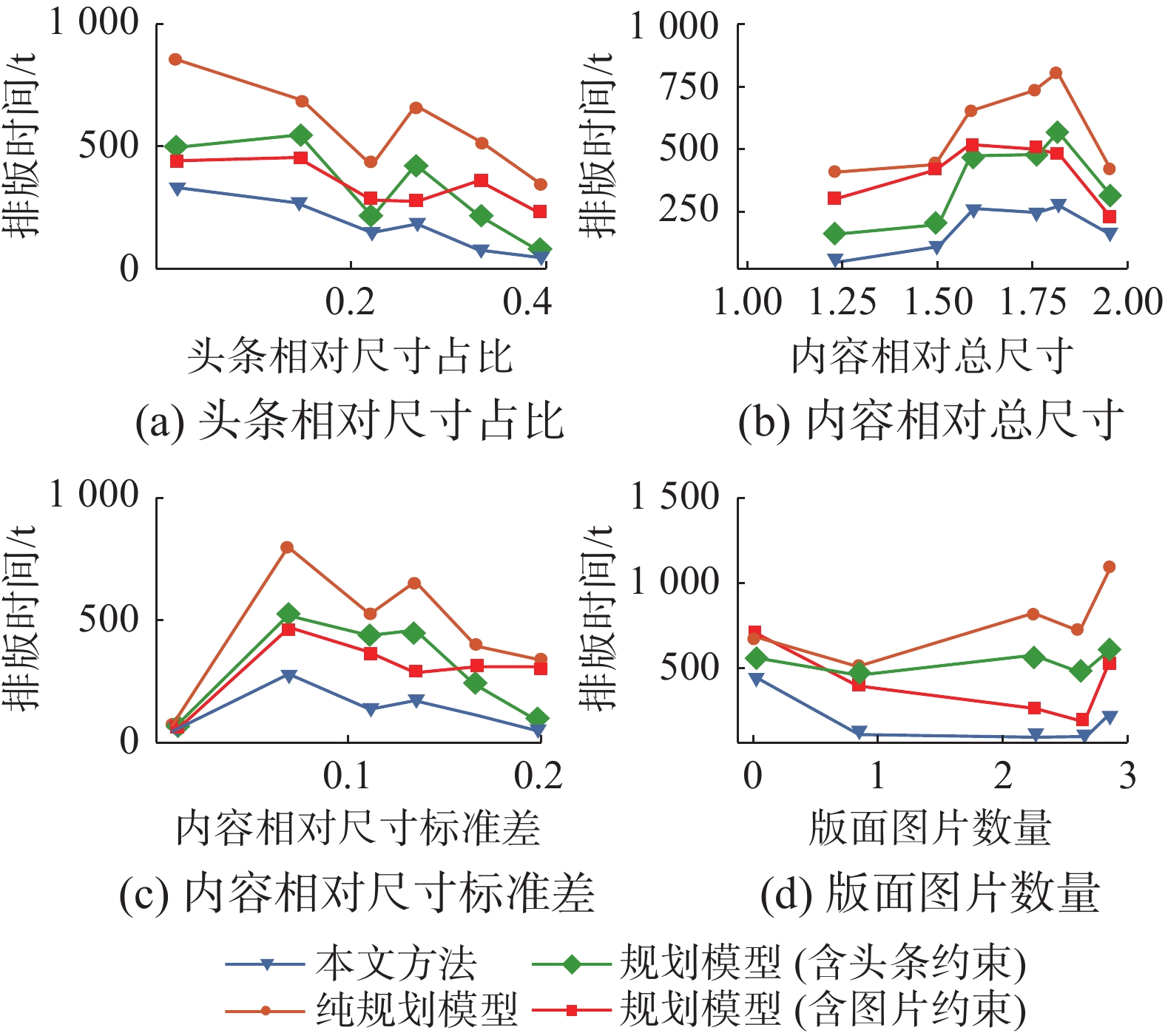 图 12 排版时间随版面内容特征变化曲线Fig. 12 Layout time change with content characteristics下载:
全尺寸图片
图 12 排版时间随版面内容特征变化曲线Fig. 12 Layout time change with content characteristics下载:
全尺寸图片
相较于纯规划模型,本文方法的总时间只有其10% ~ 40%。因为约束更少,纯规划模型可以生成更多的布局数量,本文生成布局数量(20 ~100)只有纯规划模型的一半不到。实验考虑到美观性和性能的平衡,只有对留白约束进行放松,没有对图片、头条相关约束进行放松。对于消融实验,当图片数量较少时,带有头条约束的模型与本文方法变化趋势高度相似,如图11、图12中(a)、(b)、(c)。而随着图片数量变化,如图11(d)。带有图片尺寸约束的模型与本文方法性能变化趋势相似。图片越多,图片尺寸对版面影响越大。
3.3 用户定性评估
我们邀请了10位在校学生作为用户,对不同方法生成的报纸版面的可读性、信息性和美观性进行评估。
每位用户会拿到包含同样内容而排版样式不同的5组版面,并要求对版面从0~10进行评分。每组版面布局都以随机顺序呈现给用户,部分版面布局结果如图13所示。
 图 13 布局结果示例Fig. 13 Results of generating layouts下载:
全尺寸图片
图 13 布局结果示例Fig. 13 Results of generating layouts下载:
全尺寸图片
由于,本文方法将产生多个版面布局,其目的在于供用户参考与选择,实验将记录每组版面不同指标下的最高分数和平均分数并最后按组进行平均,实验结果如表4所示。
表 4 用户评分结果Table 4 User study of different pages generated排版方式 可读性 信息性 美观性 整体分数 布局数量 平均分 最高分 平均分 最高分 平均分 最高分 平均分 最高分 专家 9.0 9.0 9.2 9.2 9.4 9.4 9.2 9.2 1 新手 8.4 8.4 7.8 7.8 8.0 8.0 8.3 8.3 1 纯规划方法 7.8 8.4 6.8 7.6 7.2 7.8 6.8 7.8 4 本文方法 8.4 8.6 8.4 8.8 8.0 8.6 8.0 8.8 4 关于可读性,本文方法、规划方法与新手生成的版面效果相当,略差于专家版面。可读性主要体现在新闻之间的清晰界限和新闻内部的聚合,对于模型和新手较为简单。关于信息性与美观性,本文方法优于规划方法和新手制作的版面,模型约束保证了元素对齐以及新闻层次、比例。对于新手而言,多个排版元素联合调整较为耗时。而纯规划的方法可能会导致图片尺寸过大或过小,影响美观性和信息性。整体上,本文方法优于新手制作的版面,可生成多种候选布局,以启发新的设计灵感。
对于相同的版面内容,纯规划模型生成的版面和本文方法生成的版面差别主要在于头条宽度和图片尺寸。纯规划过于追求矩形比例,缺少考虑头条和图片尺寸,从而导致整体布局的变化,如图13(d)。用本文方法生成的布局更符合历史版面风格。有趣的是,当新闻内容合适的时候,纯规划模型也有一定概率生成具有历史风格的版面,这表示专家一直在协调排版风格和整体布局比例。而本文方法也取得了排版风格和整体布局比例的平衡。
4. 结束语
本文提出了一种融合学习与规划的数字报版面布局生成方法。通过最近邻和贝叶斯网络方法推断布局结构和新闻属性,并基于学习模型的预测结果建立非线性整数规划模型,减小模型求解空间的同时,使得生成的版面布局直观、易读且带有历史风格。本文方法可生成多样性的版面布局,可为版面设计人员提供参考与选择。
目前,本文注重于排版元素内容类型和大小对布局的影响,没有考虑新闻文本、图片语义和布局之间的联系;对于文本字体类型和颜色的研究,以及如何将布局方法扩展到其他平面设计问题,都将在未来的工作中研究解决。
-
图 1 版面布局生成框架
Fig. 1 Framework of generation of layout
下载:
全尺寸图片
图 2 二叉树表示版面布局结构
Fig. 2 Representing layout structure by binary tree
下载:
全尺寸图片
图 3 无效和有效的版面结构示例
Fig. 3 Valid and invalid layout structures
下载:
全尺寸图片
图 4 历史版面类型分布
Fig. 4 Distribution of layout structures
下载:
全尺寸图片
图 5 用于推断头条宽度的贝叶斯网络结构
Fig. 5 Network structure to infer width of headline
下载:
全尺寸图片
图 6 历史版面图片面积与头条宽度分布
Fig. 6 Distribution of width of headline and size of graph
下载:
全尺寸图片
图 7 二叉树结构转化版面结构
Fig. 7 Transform binary tree to layout structure
下载:
全尺寸图片
图 8 整体布局目标具体表现
Fig. 8 Overall goals of generating layouts
下载:
全尺寸图片
图 9 准确率随
$ k $ 值变化曲线Fig. 9 Curve of prediction accuracy with
$ \mathit{k} $ value下载:
全尺寸图片
图 10 预测结构
$ c $ 值随$ k $ 值变化曲线Fig. 10 Curve of
$ c $ value changes with$ \mathit{k} $ value下载:
全尺寸图片
图 11 布局数量随版面内容特征变化曲线
Fig. 11 Layout quantity change with content characteristics
下载:
全尺寸图片
图 12 排版时间随版面内容特征变化曲线
Fig. 12 Layout time change with content characteristics
下载:
全尺寸图片
图 13 布局结果示例
Fig. 13 Results of generating layouts
下载:
全尺寸图片
表 1 不同预测结构排版结果
Table 1 Results with different predicted structures
方法 结构数量 布局数量 平均布局数量 时间/s 随机k个版面 6.0 40.0 6.7 62.34 本文方法 4.4 35.2 8.0 45.01 表 2 属性预测结果
Table 2 Performance of attributes inference
新闻/篇 头条宽度 图片尺寸 准确率 误差 准确率 误差 4 0.70 0.11 0.73 0.29 5 0.89 0.10 0.50 0.25 6 0.81 0.23 0.74 0.20 表 3 每个步骤的平均运行时间
Table 3 Running time of each step
s 排版步骤 平均时间 信息提取 0.06 预测版面结构 0.06 预测新闻属性 0.08 求解规划模型 3.64 表 4 用户评分结果
Table 4 User study of different pages generated
排版方式 可读性 信息性 美观性 整体分数 布局数量 平均分 最高分 平均分 最高分 平均分 最高分 平均分 最高分 专家 9.0 9.0 9.2 9.2 9.4 9.4 9.2 9.2 1 新手 8.4 8.4 7.8 7.8 8.0 8.0 8.3 8.3 1 纯规划方法 7.8 8.4 6.8 7.6 7.2 7.8 6.8 7.8 4 本文方法 8.4 8.6 8.4 8.8 8.0 8.6 8.0 8.8 4 -
[1] 中华人民共和国国家统计局. 中国统计年鉴[M]. 北京: 中国统计出版社, 2021. [2] HURST N, LI W, MARRIOTT K. Review of automatic document formatting[C]//Proceedings of the 9th ACM symposium on Document engineering. Munich: ACM, 2009: 99–108. [3] JAHANIAN A, LIU J, LIN Qian, et al. Recommendation system for automatic design of magazine covers[C]//Proceedings of the 2013 International Conference on Intelligent User Interfaces. Santa Monica: ACM, 2013: 95–106. [4] YANG Xuyong, MEI Tao, XU Yingqing, et al. Automatic generation of visual-textual presentation layout[J]. ACM transactions on multimedia computing, communications, and applications, 12(2): 33. [5] PENG Yafang, CHOU T R. Automatic color palette design using color image and sentiment analysis[C]//2019 IEEE 4th International Conference on Cloud Computing and Big Data Analysis. Chengdu: IEEE, 2019: 389−392. [6] CAO Ying, CHAN A B, LAU R W H. Automatic stylistic manga layout[J]. ACM transactions on graphics, 31(6): 141. [7] JING Guangmei, HU Yongtao, GUO Yanwen, et al. Content-aware Video2Comics with manga-style layout[J]. IEEE transactions on multimedia, 2015, 17(12): 2122–2133. doi: 10.1109/TMM.2015.2474263 [8] YANG Xin, MA Zongliang, YU Letian, et al. Automatic comic generation with stylistic multi-page layouts and emotion-driven text balloon generation[J]. ACM transactions on multimedia computing, communications, and applications, 17(2): 55. [9] ZHANG Yunke, HU Kangkang, REN Peiran, et al. Layout style modeling for automating banner design[C]//Proceedings of the on Thematic Workshops of ACM Multimedia 2017. Mountain View: ACM, 2017: 451–459. [10] YOU Weitao, SUN Lingyun, YANG Zhiyuan, et al. Automatic advertising image color design incorporating a visual color analyzer[J]. Journal of computer languages, 2019, 55: 100910. doi: 10.1016/j.cola.2019.100910 [11] YOU Weitao, JIANG Hao, YANG Zhiyuan, et al. Automatic synthesis of advertising images according to a specified style[J]. Frontiers of information technology & electronic engineering, 2020, 21(10): 1455–1466. [12] GUO Shunan, JIN Zhuochen, SUN Fuling, et al. Vinci: an intelligent graphic design system for generating advertising posters[C]//Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. Yokohama: ACM, 2021: 1–17. [13] QIANG Yuting, FU Yanwei, YU Xiao, et al. Learning to generate posters of scientific papers by probabilistic graphical models[J]. Journal of computer science and technology, 2019, 34(1): 155–169. doi: 10.1007/s11390-019-1904-1 [14] DAYAMA N R, TODI K, SAARELAINEN T, et al. GRIDS: interactive layout design with integer programming[C]//Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems. Honolulu: ACM, 2020: 1–13. [15] OULASVIRTA A, DAYAMA N R, SHIRIPOUR M, et al. Combinatorial optimization of graphical user interface designs[J]. Proceedings of the IEEE, 2020, 108(3): 434–464. doi: 10.1109/JPROC.2020.2969687 [16] LAINE M, ZHANG Yu, SANTALA S, et al. Responsive and personalized web layouts with integer programming[J]. Proceedings of the ACM on Human-Computer Interaction, 2021, 5(EICS): 213. [17] JACOBS C, LI W, SCHRIER E, et al. Adaptive grid-based document layout[J]. ACM transactions on graphics, 22(3): 838−847. [18] DAMERA-VENKATA N, BENTO J, O’BRIEN-STRAIN E. Probabilistic document model for automated document composition[C]//Proceedings of the 11th ACM Symposium on Document Engineering. Mountain View: ACM, 2011: 3–12. [19] ZHENG Xinru, QIAO Xiaotian, CAO Ying, et al. Content-aware generative modeling of graphic design layouts[J]. ACM transactions on graphics, 38(4): 133. [20] ARROYO D M, POSTELS J, TOMBARI F. Variational transformer networks for layout generation[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 13637−13647. [21] TSENG H Y, LEE H Y, JIANG Lu, et al. RetrieveGAN: image synthesis via differentiable patch retrieval[C]//European Conference on Computer Vision. Cham: Springer, 2020: 242−257. [22] LI Jianan, YANG Jimei, ZHANG Jianming, et al. Attribute-conditioned layout GAN for automatic graphic design[J]. IEEE transactions on visualization and computer graphics, 2021, 27(10): 4039–4048. doi: 10.1109/TVCG.2020.2999335 [23] LEE H Y, JIANG Lu, ESSA I, et al. Neural design network: graphic layout generation with constraints[C]//European Conference on Computer Vision. Cham: Springer, 2020: 491−506. [24] MA Yanjun, YU Dianhai, WU Tian Wu, et al. PaddlePaddle: An open-source deep learning platform from industrial practice[J]. Frontiers of data and domputing, 2019, 1(1): 105–115. [25] CONANT J, MICHAELS T. On the number of tilings of a square by rectangles[J]. Annals of combinatorics, 2014, 18(1): 21–34. doi: 10.1007/s00026-013-0209-2 [26] 陶颖, 程雨夏, 曾振宇, 等. 基于数字报历史优秀版面的样式智能生成与微调[EB/OL]. (2022−07−14)[2022−07−14]. https://eprint.las.ac.cn/abs/202207.00113. TAO Ying, CHENG Yuxia, ZENG Zhenyu, et al. Intelligent generation and fine tuning of style based on the historical excellent layouts of digital newspapers[EB/OL]. (2022−07−14)[2022−07−14]. https://eprint.las.ac.cn/abs/202207.00113. [27] PEDREGOSA F, VAROQUAUX G, GRAMFORT A, et al. Scikit-learn: machine learning in python[J]. The journal of machine learning research, 2011, 12: 2825–2830. [28] ANKAN A, PANDA A. Pgmpy: probabilistic graphical models using Python[C]//Proceedings of the 14th Python in Science Conference. Austin: SciPy, 2015. [29] THIBAUT C, FREDERIC D, VINCENT F, et al. OR-Tools’ vehicle routing solver: a generic constraint-programming solver with heuristic search for routing problems[EB/OL]. (2023−03−06)[ 2023−03−06]. https://developers.google.com/optimization/.

















































































































































