
Fault identification of multi-feature boiler tube acoustic signal based on deep residual shrinkage network
-
摘要: 为了提高锅炉炉管声波信号故障识别的学习效果和识别精度,采用特征向量并行和拼接两种融合方式构成特征层,以及平均得分和最大值得分两种融合方式构建决策层等不同信息融合机制,提出基于深度残差收缩网络的多特征锅炉炉管声波信号故障识别方法。首先,考虑锅炉炉管上各声波传感器的差异性,分别计算声波信号谱特征一阶和二阶差分构建三通道特征集作为二维网络的输入特征向量;然后,在卷积神经网络和双向长短时记忆网络基础上引入注意力机制构建基线模型,并采用深度残差收缩网络对二维网络的通道权重进行优化分配,提高模型的故障识别精度。大量实验结果表明:采用特征向量并行融合方式构成特征层的信息融合机制是一种更有效的策略;本文模型的识别精度得到较大程度提高,与基线模型相比较,未加权平均召回率提高了4.32%。Abstract: To improve the learning effect and recognition accuracy in fault identification of boiler tube acoustic signals, different information fusion mechanisms were used in this study. Specifically, feature vector parallelism and splicing techniques are used to form the feature layer, while the decision layer is formed using average and maximum score approaches. A fault identification method of multifeature boiler tube acoustic signal based on a deep residual shrinkage network is proposed. First, the first-order and second-order differential characteristics of the acoustic signal spectrum were calculated separately, considering the variations of acoustic wave sensors on the boiler tube. This process constructs a three-channel feature set, which serves as the input feature vector of the two-dimensional network. Subsequently, an attentional mechanism is introduced to construct a baseline model using a combination of a convolutional neural network and a bidirectional short and long memory network. Additionally, a deep residual shrinkage network is used to optimize the allocation of channel weights within the two-dimensional network to improve the fault identification accuracy of the model. Extensive experimental results show that: it is a more effective strategy to construct the information fusion mechanism of the feature layer by using feature vector parallel fusion; compared with the baseline model, the unweighted average recall rate has increased by 4.32%, highlighting significant improvements in the recognition accuracy of the model presented in this paper.
-
锅炉炉管自动报警系统是当锅炉炉管在高温、高压状态下工作中发生泄露故障时,根据安装在锅炉炉管上的多个声波传感器检测到的声波信号判断锅炉炉管是否发生泄露故障[1]。目前,故障识别主要是依据声波信号的主要特征,包括声波韵律特征和声波谱特征[2]。
声波韵律特征包括声波基频特征和能量特征,按照其全局和局部特征,可以通过提取声波基频和能量的最大值、最小值、平均值及方差等构成高维声波特征集。声波谱特征包括线性频谱特征和倒谱特征,主要反映声波信号在频域上的差异。BOU⁃GHAZALE等[3-4]的研究表明,倒谱特征在识别声波信号特征上比线性频谱特征具有明显优势。Hsiao等[5-6]通过提取声波信号的基频、过零率、能量、梅尔频率倒谱系数(Mel-frequency cepstral coefficient,MFCC)等特征,并计算其方差、平均值、最大值、最小值、峰度、线性回归系数等构成高维声波特征集,然后采用深度循环神经网络(deep recurrent neural network, DRNN)模型在FAU-Aibo数据集的未加权平均召回率(unweighted average recall,UAR)提高了9.3%;Han等[7-8]通过声波能量、共振峰、谐波噪声比等特征构建16维声波信号特征向量,其中前9维为声波韵律特征,后7维为声波谱特征,提出了一种基于高斯核的非线性近端支持向量机模型;胡德生等[9-10]基于主辅网络特征融合方法,通过计算声波信号的平均过零率、基准频率、能量、以及MFCC等特征,在IEMO-CAP数据库上使未非加权平均精度(unweighted average precision, UAP)提高到73.1%。上述文献所述的模型均采用固定信息融合方法,将声波信号的不同特征输入到多个网络,因而声波信号特征利用率较低,造成模型的识别精确不高。本文充分利用声波信号的多特征性质,对多个声波特征采用不同融合策略进行信息融合,提高了信号特征利用效率,从而提升模型的识别精度。
近年来,卷积神经网络(convolutional neural network,CNN)和长短期记忆网络(long short-term memory,LSTM)以其较高的识别精度在声波信号特征识别领域得到了广泛的应用[11-16]。而近期的研究进一步表明,在双向长短期记忆(bidirectional long short-term memory,BLSTM)网络中引入注意力机制能更好地提高声波信号的识别精度[17-20]。其主要思路是:1)基于当前声波信号特征与其前后声波信号之间的相关性,采用BLSTM网络能够得到信号在时间上的依赖特征;2)基于炉管声波信号中泄漏故障信号与正常信号之间的信息特征差异,引入注意力机制,增加故障信号在特征模型中的权重。
在锅炉炉管声波信号故障识别系统中,由于声波传感器之间输出的声波信号存在个体的差异性。为了降低个体差异对故障识别的影响,往往需要对各声波信号进行差分处理后再作为2D-CNN、3D-CNN网络的输入特征集,提升模型的识别精度。例如,Gao等[21]通过计算声音信号MFCC系数的一阶差分、二阶差分作为信号特征集输入到改进型3D-CNN-LSTM网络模型中,使网络模型的UAR在IEMCAP和EMO-DB数据库上分别达到了64.57%和83.15%。Sohaib等[22]通过计算声音信号的对数梅尔特征(Log-Mel)的一阶、二阶差分作为信号特征集输入到改进型2D-CNN-LSTM网络模型中,使网络模型基于发声源依赖实验和基于发声源独立实验的识别精确率在IEMOCAP数据库上分别达到90.02%和53.21%。Gupta等[23]通过计算语音信号Log-Mel的一阶、二阶差分构成3D-Log-Mel数据集输入到3D-CNN-LSTM网络模型,使语音信号识别平均准确率在IEMCAP和EMO-DB数据库上分别达到60.89%和86.07%。上述文献所述方法将信号进行差分处理后再输入到多通道卷积网络模型,但却没有对各通道的特征输入权重进行优化。声波信号的不同阶差分对信号的区分度显然是不相同的,输入到网络模型时应该合理分配各通道的权重,从而提升模型的识别精度。
深度残差收缩网络(deep residual shrinkage networks,DRSN)引入了注意力机制和软阈值函数。在内部将软阈值化作为非线性层,自适应地在特征学习过程滤除噪声信号,提高有用信号特征的学习效果,所以该模型适合给重要信号特征分配更大权重,而降低不重要信号特征的权重。本文引入DRSN对声波信号的输入权重进行优化分配,提高声波信号有效特征的输入权重,提高声波信号识别精度。
1. 锅炉炉管声波信号的有效特征
锅炉炉管在运行过程中最容易发生故障且故障后果最严重的4种泄露故障类型是发生在“四管”上的泄露故障,即再热器管、水冷壁管、省煤器管和过热器管[24]。用于故障识别的声波信号有效特征通常采用声波韵律特征和声波谱特征来描述。
1.1 声波信号韵律特征
1) 短时能量。不同类型的锅炉炉管声波信号的幅度值是不相同的。所以其声波信号的短时能量可以作为信号的特征之一;设某声波信号为
$ \{ x(n)\} $ ,定义加窗函数的平均短时能量为$$ \begin{array}{*{20}{c}} {{E_n} = \displaystyle\sum\limits_{i = 0}^{N - 1} {x(i)h(n - i)} = {x^2}(n)*h(n)} \\ {h(n) = \omega {{(n)}^2}} \end{array} $$ (1) 式中:
$ \omega (n) $ 为窗函数,可选矩形窗或汉明窗等;$ h(n) $ 为单位冲激响应;*为卷积。2) 短时平均幅度。声波信号短时能量主要用来描述信号的峰值幅度,而声波信号的单位时间内幅度值变化情况可用短时平均幅度值
$ {M_n} $ 来表示:$$ {M_n} = \sum\limits_{i = 0}^{N - 1} {\left| {{x_n}(i)} \right|} $$ (2) 3) 短时过零率。声波信号的短时过零率用来表示单位时间内声波信号穿越时间轴的次数,即
$$ {Z_n} = \frac{1}{2}\sum\limits_{i = 0}^{N - 1} {\left| {{{\rm{sgn}}} [{x_n}(i)] - {{\rm{sgn}}} [{x_n}(i - 1)]} \right|} $$ (3) 显然,锅炉炉管声波信号的高、低频部分具有较高和较低的短时过零率,可以用来表现声波信号的振动情况,所以能作为区分声波信号特征之一。
1.2 声波信号谱特征
声波信号的倒谱特征对信号特征的区分能力明显优于线性谱特征。倒谱特征常用MFCC、线性频率倒谱系数(linear frequency cepstral coefficient, LFCC)、线性预测倒谱系数(linear predictive cepstral coefficient, LPCC)来表示。
1) MFCC。MFCC可有效表征声波信号的共振情况。在声波信号故障识别领域,MFCC已经成为表征声波信号特征应用最广泛的参数[25]。声波信号的MFCC的计算过程如下:
①采用高频滤波器对声波信号进行预处理,滤除声波信号中的高频部分:
$$ {H_{\textit{z}}} = 1 - \mu {{\textit{z}}^{ - 1}} $$ (4) ②按照段长为25 ms、移动段长为10 ms对声波信号进行分段处理,并给各段声波信号加汉明窗;
③对各分段声波信号进行傅里叶变换,并计算各分段声波信号的能量分布:
$$ \begin{array}{*{20}{c}} {{X_a}(k) = \displaystyle\sum\limits_{i = 0}^{N - 1} {x(i){{\rm{e}}^{ - \tfrac{{j2 \text{π} k}}{N}}}} },&{0 \leqslant k \leqslant N} \end{array} $$ (5) ④采用梅尔尺度三角滤波器对能量谱作平滑处理:
$$ {H_m}(k) = \left\{ {\begin{split} & 0,\quad\quad {k < f(m - 1)} \\ & {\frac{{2(k - f(m - 1))}}{{(f(m + 1) - f(m - 1)(f(m) - f(m - 1)))}}},\quad{f(m - 1) \leqslant k < f(m)} \\ & {\frac{{2(f(m + 1) - k)}}{{(f(m + 1) - f(m - 1)(f(m) - f(m - 1)))}}},\quad{f(m) \leqslant k < f(m + 1)} \\ & 0,\quad\quad{k \geqslant f(m + 1)} \end{split}} \right. $$ (6) ⑤计算三角滤波器输出的对数能量,并对对数能量进行离散余弦变换,得到声波信号MFCC系数:
$$ \begin{array}{*{20}{c}} {s(m) = \ln\left(\displaystyle\sum\limits_{k = 0}^{N - 1} {{\left| {{X_a}(k)} \right|}^2}{H_m}(k)\right) },&{0 \leqslant m \leqslant M} \end{array} $$ (7) $$ \begin{array}{*{20}{c}} C(n) = \left(\displaystyle\sum\limits_{m = 0}^{N - 1} {s(m)\cos \left(\dfrac{{n{\text{π}} (m - 0.5)}}{M}\right)} \right),\;{n = 1,2, \cdots ,L} \end{array} $$ (8) 2) LFCC。LFCC计算过程与MFCC相同,只是其滤波器组的频率需要按照线性频率进行分布;
3) LPCC。LPCC采用线性预测分析方法获得声波信号的倒谱系数[26]。其计算过程如下:
①采用线性预测分析方法得到分段声波信号的全极点模型,即
$$ H({\textit{z}}) = \dfrac{G}{{1 - \displaystyle\sum\limits_{i = 1}^p {{a_i}{{\textit{z}}^{ - 1}}} }} $$ (9) ②声波信号的激励模型为
$$ U({\textit{z}}) = E({\textit{z}})G({\textit{z}}) = \dfrac{{{A_u}}}{{1 - {{\textit{z}}^{ - 1}}}} \cdot \dfrac{1}{{{{(1 - {{\rm{e}}^{ - c{T_{\textit{z}}} - 1}})}^2}}} $$ (10) ③模型的输入和输出关系可用表示为
$$ s(n){\text{ = }}\sum\limits_{k = 1}^p {{a_k}s(n - k) + Gu(n)} $$ (11) ④假设某段声波信号的第
$ n $ 个采样点的模型输出为$ \tilde s(n) $ ,且$ \tilde s(n) $ 能够用该段声波信号前面$ p $ 个模型输出线性表示,即$$ \tilde s(n) \approx {a_1}s(n - 1) + {a_2}s(n - 2) + \cdots + {a_p}s(n - p) $$ (12) 式中:
$ {a_1},{a_2}, \cdots ,{a_p} $ 为常数,称为线性预测系数。⑤从而,LPCC可表示为
$$ c(n) = \left\{ {\begin{split} & 0,\quad{n < 0} \\ &{\ln G},\quad{n = 0} \\ &{{a_n} + \displaystyle\sum\limits_{k = 1}^{n - 1} {\left(\dfrac{k}{n}\right)c(k){a_{n - k}}} },\quad{0 < n \leqslant p} \\ & {\displaystyle\sum\limits_{k = n - p}^{n - 1} {\left(\frac{k}{n}\right)c(k){a_{n - k}}} },\quad{n > p} \end{split}} \right. $$ (13) 2. 锅炉炉管声波信号识别模型构建
2.1 基线模型
在CNN和BLSTM网络模型基础上,引入注意力机制,通过增强有效声波信号的权重,降低无效声波信号的权重构建基线模型,如图1所示。
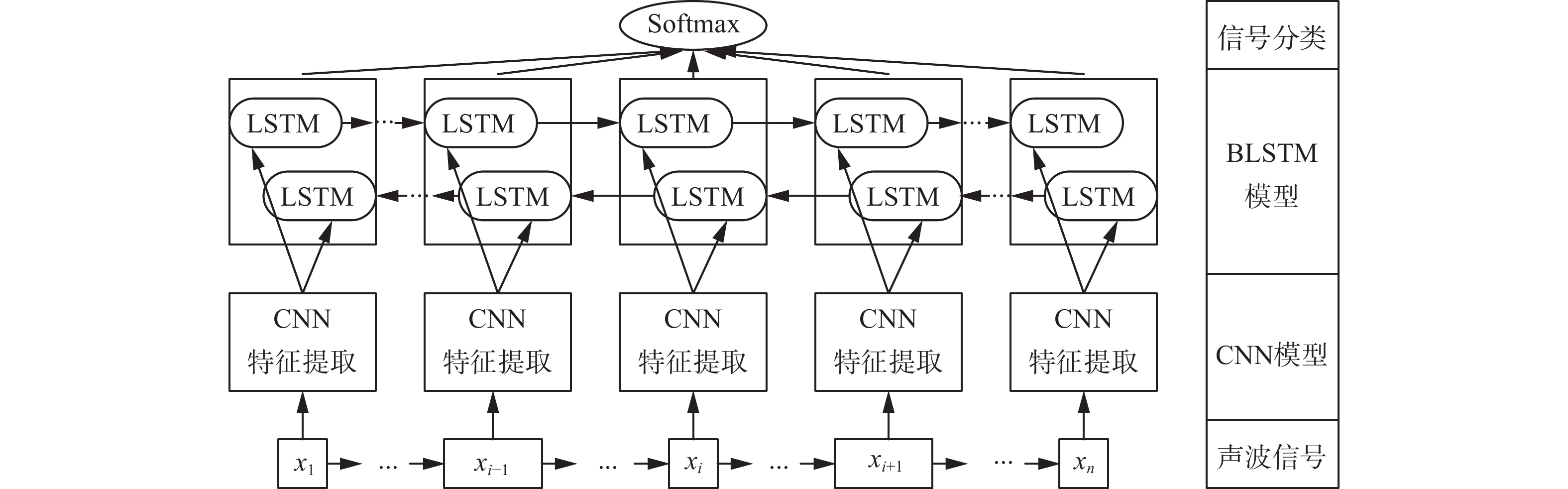 图 1 CNN-BLSTM 模型结构Fig. 1 Structure of CNN-BLSTM
图 1 CNN-BLSTM 模型结构Fig. 1 Structure of CNN-BLSTM 下载:
全尺寸图片
下载:
全尺寸图片
1) CNN模型。首先,将声波信号的韵律特征数据集作为1D-CNN网络的输入,1D-CNN网络设置2个卷积层,卷积核大小为5,数量定义为128,步长为1,激活函数采用ReLU。设置池化大小分别为5和3的两个池化层;然后,计算声波信号谱特征的一阶、二阶差分构成3个通道的数据集作为2D-CNN的输入;2D-CNN网络设置3个卷积层,卷积核大小分别为5×5、5×5、3×3,数量定义为128,步长为1,激活函数采用ReLU。设置池化大小为2×2的3个池化层;
2) BLSTM模型。当前声波信号的信号特征与其前、后声波信号的特征信息均相关。所以在处理声波信号序列时,需要采用两个独立的BLSTM网络从前、后两个方向分别对声波信号进行处理。所以,BLSTM网络在
$ t $ 时刻的隐藏状态输出结果为$$ {{\boldsymbol{h}}_t} = \left[ {{{{{\vec {\boldsymbol{h}}}}}_t};{{{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\leftarrow}$}}{{\boldsymbol{h}}} }}}_t}} \right] $$ (14) 式中:
${{{\vec {\boldsymbol{h}}}}_t} = \vec {\boldsymbol{L}} ({x_t}, {{\vec{\boldsymbol{h}}_{t - 1}}} )$ 表示BLSTM网络对前向信号进行处理在$ t $ 时刻的隐藏状态输出结果;${{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\leftarrow}$}}{{\boldsymbol{h}}} }}_t} = {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\leftarrow}$}}{{\boldsymbol{L}}} } ({x_t}, {{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\leftarrow}$}}{{\boldsymbol{h}}} }_{t - 1}}} )$ 表示BLSTM网络对后向信号进行处理在$ t $ 时刻的隐藏状态输出结果;符号$ \to 、\leftarrow $ 分别表示前向、后向。BLSTM网络的最终隐藏层输出可表示为
$$ {\boldsymbol{H}} = ({h_1},{h_2}, \cdots ,{h_t}) $$ (15) 式中:
$ {\boldsymbol{H}} \in {{\bf{R}}^{t \times d}} $ ;$ t $ 为声波信号的分段数;$ d $ 为BLSTM网络输出最终隐藏层的大小。3) 注意力机制。将BLSTM网络输出的最终隐藏层作为注意力机制的输入数据集。
$$ {e_i}{\text{ = tanh(}}{W_j}{h_i}{\text{ + }}{b_i}{\text{)}} $$ (16) $$ {a_i} = {{{\text{exp}}({e_i})}/{\sum\limits_t {{\text{exp}}({e_i})} }} $$ (17) $$ {h'_i} = {a_i}{h_i} $$ (18) 式中:
$ {a_i} $ 为注意力机制赋予给有效声波信号的权重;$ {h'_i} $ 为有效声波信号加权后的输出值。在CNN模型基础上构建引入了注意力机制的BLSTM网络。注意力机制的主要作用是合理分配输入通道的权重,对包含故障特征的声波信号分配较大的权重。锅炉炉管声波信号特征与炉内温度、炉管内压力、设备损耗、泄漏故障位置和程度等多种因素有关。注意力机制能够使模型更有效地提取声波信号本身特征及其耦合的炉管内压力信息、炉管老化程度、设备损耗特征等。并在很大程度上避免在机器学习中出现过拟合现象。
2.2 信息融合
本文所述的信息融合是指综合不同模型的优势,达到不同模型间提优补缺的作用,主要包括特征层融合和决策层融合[27]。
特征层融合是指将原始样本分别输入到多个深度学习网络得到多个降维特征向量,由多个降维特征向量融合得到一个特征向量的方法,有特征向量并行和特征向量拼接两种方式。特征向量并行是将多个同维的特征向量进行叠加得到新的同维特征向量,新特征向量的维数没有增加,但却增加了每一维向量的特征信息;特征向量拼接是将多个同维度或不同维度的特征向量串联拼接而得到新的特征向量,新特征向量的维数增加,但每一维向量的特征信息量却没有增加。
决策层融合是指采用代数方法对多个模型网络的识别结果进行融合。多个模型网络的识别结果之间相互独立,识别结果一般用一个预测评分来表示,常见的决策层融合方式就是对多个预测评分求平均值、最大值等。
2.3 深度残差收缩网络
在深度残差网络中引用软阈值化作为非线性层。软阈值化的本质是通过设计合适的滤波器对信号噪声进行滤波。在深度残差网络基础上应用软阈值化构建DRSN,提高网络模型对含噪数据或复杂数据的学习效果和识别精度。用
$ {\boldsymbol{x}} $ 表示输入特征向量,用$ {\boldsymbol{y}} $ 表示输出特征向量,用${\boldsymbol{ \tau}} $ 表示一个正参数阈值,软阈值在网络模型中的作用可表示为$$ {\boldsymbol{y}}{{ = }}\left\{ {\begin{array}{*{20}{l}} {{\boldsymbol{x}} - {\boldsymbol{\tau}} },\quad{{\boldsymbol{x}} > {\boldsymbol{\tau}} } \\ 0,\quad{ - {\boldsymbol{\tau}} \leqslant {\boldsymbol{x}} \leqslant {\boldsymbol{\tau}} } \\ {{\boldsymbol{x}} + {\boldsymbol{\tau}} },\quad{{\boldsymbol{x}} < - {\boldsymbol{\tau}} } \end{array}} \right. $$ (19) 当软阈值的输出对输入的导数为1或0时,即
$$ \frac{{\partial {\boldsymbol{y}}}}{{\partial {\boldsymbol{x}}}}{\text{ = }}\left\{ {\begin{array}{*{20}{l}} 1,&{{\boldsymbol{x}} > {\boldsymbol{\tau}} } \\ 0,&{ - {\boldsymbol{\tau}} \leqslant {\boldsymbol{x}} \leqslant {\boldsymbol{\tau}} } \\ 1,&{{\boldsymbol{x}} < - {\boldsymbol{\tau}} } \end{array}} \right. $$ (20) 可有效防止信号经软阈值处理后出现梯度消失和爆炸等异常问题。
将多个具有不同通道阈值的残差收缩模块进行叠加构成DRSN,如图2所示。
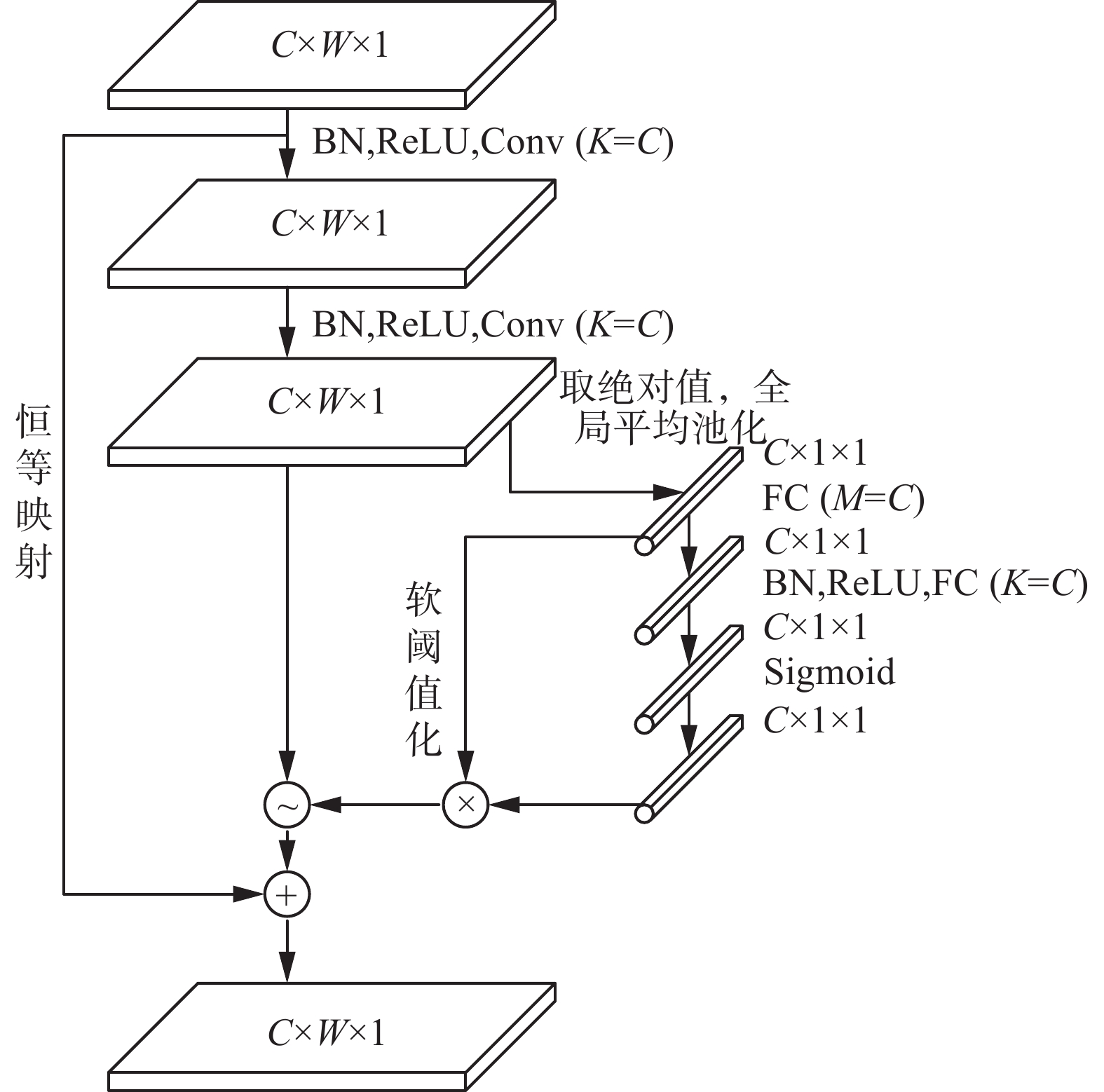 图 2 阈值独立型残差收缩模块Fig. 2 Residual shrinkage building unit with channel-wise thresholds下载:
全尺寸图片
图 2 阈值独立型残差收缩模块Fig. 2 Residual shrinkage building unit with channel-wise thresholds下载:
全尺寸图片
图2中的每个通道均对应一个独立阈值,所以构成DRSN的各残差收缩模块又称为阈值独立型残差收缩模块(residual shrinkage building unit with channel-wise thresholds,RSBU-CW)。通过对特征向量中每一个元素求绝对值,并利用全局平均池化方法将特征向量映射为一个一维向量作为一个两层全连接网络的输入,其中全连接网络的第二层神经元个数等于模型输入特征映射的特征通道个数,全连接网络的输入缩放在(0,1)之间,缩放参数表示为
$$ {\sigma _c}{\text{ = }}\frac{{\text{1}}}{{{\text{1 + }}{{\rm{e}}^{ - {{\textit{z}}_c}}}}} $$ (21) 式中:
${{\textit{z}}_c}$ 表示第$ c $ 通道的输出特征;$ {\sigma _c} $ 表示第$ c $ 通道的缩放参数。第
$ c $ 通道的阈值计算公式为$$ {\tau _c}{\text{ = }}{\sigma _c} \cdot {f_{{\rm{average}}}}\left| {{{\boldsymbol{X}}_{i,j,c}}} \right| $$ (22) 式中:
$ {{\boldsymbol{\tau}} _c} $ 表示第$ c $ 通道阈值;$ {{\boldsymbol{X}}_{i,j,c}} $ 表示特征向量$ {\boldsymbol{X}} $ 第$ c $ 通道下特征向量,坐标为$ (i,j) $ ;$ {f_{{\rm{average}}}} $ 表示求均值。由于各通道阈值由各样本自身的特征自适应确定,所以DRSN对含噪信号处理同样具有良好效果。当样本信号中的噪声较小时,经学习和训练后所得的阈值非常接近于0,从而使软阈值化对训练模型几乎不会造成不良影响。本文通过计算声波信号的谱特征,并经一阶差分和二阶差分后得到3个通道的特征数据集,在输入二维网络之前,利用DRSN得到各通道的输入权重。经上述方法处理后,每组声波信号的训练样本均能获得独立的通道权重,并根据各训练样本的信号特征对通道权重进行调整,从而得到具有独立通道权重的CNN,提升模型的识别效果。
2.4 DRSN多特征融合模型
锅炉炉管声波信号故障识别系统采用DRSN多特征融合模型(DRSN with multi-feature fusion, DRSN-MF)。该模型包含一个一维网络(1D-CNN-BLSTM-attention)和一个二维网络(2D-CNN-BLSTM-attention);两个网络分别都引入注意力机制和Dropout层。注意力机制的主要作用是通过提高有效声波信号的权重来提高声波信号故障识别效果;Dropout层的主要作用是有效缓解模型发生过拟合,提升模型的泛化能力,在一定程度上达到正则化的效果。二维网络比一维网络多了一个维度,模型利用这一维度实现样本数据的多通道输入。声波信号的韵律特征数据作为一维网络的输入;声波信号的谱特征作为二维网络的输入,在输入到二维网络前,首先计算声波信号谱特征的一阶和二阶差分,形成3通道特征数据集,再通过DRSN对二维网络的3个通道权重进行合理分配,最后再将特征数据集输入到二维网络。MFCC、LFCC和LPCC均采用这种方式输入数据。
不同类型的特征数据集经过一维或二维深度学习网络后,其输出结果为对应的降维特征向量。在特征层融合中,降维特征向量采用并行和拼接方法进行信息融合后作为全连接层的输入,输出结果采用Softmax函数对声波信号进行识别,如图3(a)所示。在决策层融合中,降维特征数据集先通过全连接层,再采用Softmax函数得到各类降维特征的分类预测得分,最后采用求平均值和最大值的代数组合规则输出声波信号的识别结果,如图3(b)所示。
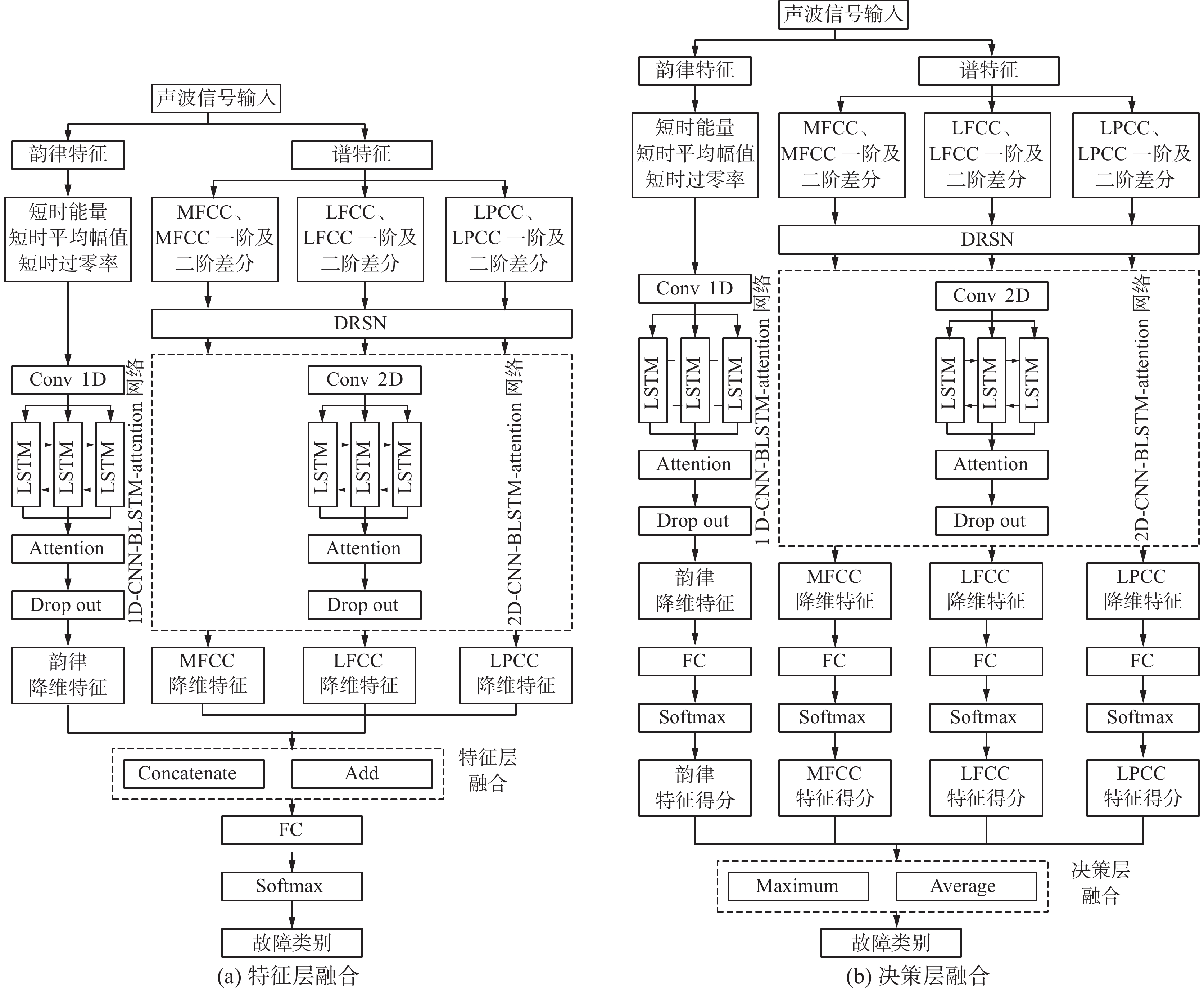 图 3 DRSN-MF结构图Fig. 3 DRSN-MF structure下载:
全尺寸图片
图 3 DRSN-MF结构图Fig. 3 DRSN-MF structure下载:
全尺寸图片
本文基于CNN模型在特征提取方面的优势和BLSTM在时间连续上的识别优势,将CNN和BLSTM进行融合得到CNN-BLSTM模型用于锅炉炉管声波信号故障识别,该模型能够提取丰富的信号特征,提高信号特征的利用效率,并对时间连续的行为动作具有较强的识别性,因此具有较高的信号识别率。
3. 模型实验及结果分析
3.1 锅炉炉管声波信号原始样本数据集
选择某典型锅炉炉管声波自动报警系统的历史数据作为本文的原始实验样本数据集。该样本数据集经过一定的数据筛选、排异处理,共12 600条数据,包括经多种类型、不同时段、多个声波传感器采样得到的再热器管、水冷壁管、省煤器管、过热器管泄漏故障数据,以及无泄露故障数据。数据集采样率为16 kHz,采用16 bit量化。
3.2 故障识别关键评价指标
锅炉炉管声波信号故障识别是一个典型的多分类任务,评价识别效果的主要指标有准确率、精确率、召回率和
$ {F_1} $ 值[28]。对于一个二分类模型,模型输入样本可以分为正样本和负样本;模型输出结果可分为4种情况:1) 真阳性$ {T_P} $ ,即预测结果和实际样本均为正样本;2) 假阳性$ {F_{\rm{P}}} $ ,即预测结果为正样本,实际样本为负样本;3) 真阴性$ {T_{\rm{N}}} $ ,即预测结果和实际样本均为负样本;4) 假阴性$ {F_{\rm{N}}} $ ,即预测结果为负样本,实际样本为正样本。1) 准确率。准确率为预测结果正确的数量与全部样本的比值:
$$ A = \frac{{{T_{\rm{P}}} + {T_{\rm{N}}}}}{{{T_{\rm{P}}} + {T_{\rm{N}}} + {F_{\rm{P}}} + {F_{\rm{N}}}}} $$ (23) 2) 精确率。精确率为真阳性样本数量与所有正样本数量的比值。
$$ R = \frac{{{T_{\rm{P}}}}}{{{T_{\rm{P}}} + {F_{\rm{N}}}}} $$ (24) 3) 召回率。召回率为真阳性样本数量与所有预测结果为正样本数量的比值。
$$ P = \frac{{{T_{\rm{P}}}}}{{{T_{\rm{P}}} + {F_{\rm{P}}}}} $$ (25) 4)
$ {F_1} $ 值。$ {F_1} $ 值为算数平均数除以几何平均数,且越大越好,本文的$ {F_1} $ 值就是精确值和召回率的调和均值。识别模型中,希望准确率和召回率都高,但是一般情况下,当准确率越高时、召回率就越低,反之依然。$ {F_1} $ 值的计算公式可表示为$$ {F_1} = 2 \times \frac{{P \times R}}{{P + R}} $$ (26) 多分类任务中,计算所有分类结果的精确率
$ R $ 和召回率$ P $ 可分别构成一个$ n $ 维向量$ {\boldsymbol{R}} $ 和$ {\boldsymbol{P}} $ ,即$$ {\boldsymbol{R}} = ({R_1},R_2, \cdots {R_i}, \cdots ,{R_n}) $$ (27) $$ {\boldsymbol{P}} = ({P_1},P_2, \cdots {P_i}, \cdots ,{P_n}) $$ (28) 式中:
$ n $ 表示多分类模型输出的分类类别数;$ {R_i} $ 、$ {P_i} $ 分别表示第$ i $ 个分类类别的精确率和召回率。对多分类模型输出分类类别的精确率求平均值就得到分类类别的UAP(
$ \hat R $ );对多分类模型输出分类类别的召回率求平均值就得到的分类类别的UAR($ \hat P $ ),即$$ \begin{array}{*{20}{c}} {\hat R = \displaystyle\sum\limits_{i = 1}^n {{R_i}} },&{\hat P = \displaystyle\sum\limits_{i = 1}^n {{P_i}} } \end{array} $$ (29) 3.3 模型参数设置
本文所有实验在搭载第12代Inter(R)Core(TM) i5-12500H标压处理器的HUAWEI MateBook 14 s上运行,基于TensorFlow构建深度学习框架。模型识别效果的评价指标采用UAR、UAP、准确率和
$ {F_1} $ 值。按照25 ms帧长和10 ms移动帧长的定义,将原始样本数据集的声波信号划分成200帧的声波段,训练样本数和测试样本数的比例为4∶1,所有实验结果取10次平均值以消除随机误差。设置模型的学习率为10−4,衰减率为10−6,学习最高迭代次数为150。3.4 实验结果及分析
1) 信息融合策略实验。
对声波信号的4种信息融合方式进行实验,实验结果如表1所示。
表 1 声波信号不同信息融合方式实验结果Table 1 Experimental results of different information fusion methods of acoustic signals% 融合策略 准确率 精确率 召回率 $ {F_1} $值 特征层融合(Concatenate) 81.47 80.78 80.21 81.34 特征层融合(Add) 84.95 85.20 85.11 84.79 决策层融合(Average) 80.03 81.23 80.06 80.12 决策层融合(Maximun) 64.25 70.26 63.42 66.18 从表1中数据可见,声波信号采用特征层融合策略比决策层融合的效果更好。这一实验结果表明,先将声波信号的特征进行整合,再进行分类的信号识别效果更好。另外表中数据还表明:信号在特征层融合时,采用并行方式的效果比拼接方式好;信号在决策层融合时,采用求平均值的效果比求最大值方式好,这主要是因为求最大值方式容易出现过拟合现象。
2) RSBU-CW模块数量设置实验。
多个RSBU-CW模块进行叠加构成DRSN,对构成模块的数量对模型的识别效果进行实验验证。模型的信息融合在特征层进行,各特征向量融合方法采用并行方式。当RSBU-CW模块数量分别为1、2、3时,模型的识别效果UAP分别为84.65%、81.37%、79.29%。由此可见,构成DRSN模型的RSBU-CW模块为1时,模型的识别效果就达到最佳状态。所以模型构建时,不必过多追求RSBU-CW模块的叠加数量,原因是DRSN模型的输入特征数据量较小,过多的RSBU-CW模块叠加反而容易造成DRSN模型过拟合,使其识别效果降低。
3) 模型训练过程实验。
对模型的训练过程进行实验,设置模型的最大迭代次数为100次,并限定当模型连续40次迭代,其模型准确率没有提升时主动中断训练过程。得到的迭代次数−准确率变化曲线如图4所示。
 图 4 迭代次数变化时模型准确率变化曲线Fig. 4 Model accuracy curves when the number of iterations changes下载:
全尺寸图片
图 4 迭代次数变化时模型准确率变化曲线Fig. 4 Model accuracy curves when the number of iterations changes下载:
全尺寸图片
图4中的曲线表明,训练没有达到最大设定迭代次数训练就被中断,这是因为样本数据较少的缘故。同时,当训练次数达到50次左右时,模型就开始收敛,这个现象表明本文所构建的模型是实用且有效的。
4) 样本数据的混淆矩阵。
由学习框架得到原始样本数据的混淆矩阵如图5所示。从图5中数据可以看出,本文所构建的模型对再热器管、水冷壁管、省煤器管、过热器管泄漏故障,以及无泄露故障信号均有较高的召回率,这说明本文所构建的模型能够有效区分锅炉炉管是否发生泄漏故障,并能较好地区分泄漏故障的类型。
 图 5 原始样本的混淆矩阵Fig. 5 The confusion matrix of the original sample下载:
全尺寸图片
图 5 原始样本的混淆矩阵Fig. 5 The confusion matrix of the original sample下载:
全尺寸图片
5) 各类模型识别效果对比。
本文在CNN-BLSTM模型的基础上引入注意力机制作为基线模型,基线模型的信息融合在特征层采用特征向量并行融合方式。基线模型与本文所构建的DRSN-MF模型的识别效果如表2。
表 2 基线模型与DRSN-MF模型识别效果对比Table 2 Comparison of recognition effect between baseline model and DRSN-MF model% 模型 准确率 精确率 召回率 $ {F_1} $值 基线模型 80.42 80.96 80.51 80.49 DRSN-MF 85.05 84.38 84.83 84.61 如表2中数据所示,本文所构建的DRSN-MF模型在准确率、精确率、召回率和
$ {F_1} $ 值4个模型识别效果评价标准上均优于基线模型。为进一步验证本文引入DRSN,在特征层进行信息融合,以及采用特征向量并行方式的模型的优势,与其他文献中所述的基于CNN、LSTM及注意力机制所构建模型的识别效果进行比较的结果如表3所示。表3中的数据表明,DRSN能够有效提高基于CNN和LSTM深度学习的声波信号故障识别精度;同时,在特征层进行信息融合,以及采用特征向量并行方式能够提高模型的识别效果。
4. 结束语
本文在CNN-BLSTM模型的基础上引入注意力机制作为基线模型,构建了引入DRSN,在特征层进行信息融合,以及采用特征向量并行方式识别的模型,对锅炉炉管声波信号的故障进行识别。利用原始样本数据对本文所构建的DRSN-MF模型进行了大量的实验验证,并将本文模型与其他文献所述的模型进行对比,验证了本文构建模型的有效性,具有良好的推广价值和实用性能。
-
图 1 CNN-BLSTM 模型结构
Fig. 1 Structure of CNN-BLSTM
下载:
全尺寸图片
图 2 阈值独立型残差收缩模块
Fig. 2 Residual shrinkage building unit with channel-wise thresholds
下载:
全尺寸图片
图 3 DRSN-MF结构图
Fig. 3 DRSN-MF structure
下载:
全尺寸图片
图 4 迭代次数变化时模型准确率变化曲线
Fig. 4 Model accuracy curves when the number of iterations changes
下载:
全尺寸图片
图 5 原始样本的混淆矩阵
Fig. 5 The confusion matrix of the original sample
下载:
全尺寸图片
表 1 声波信号不同信息融合方式实验结果
Table 1 Experimental results of different information fusion methods of acoustic signals
% 融合策略 准确率 精确率 召回率 $ {F_1} $值 特征层融合(Concatenate) 81.47 80.78 80.21 81.34 特征层融合(Add) 84.95 85.20 85.11 84.79 决策层融合(Average) 80.03 81.23 80.06 80.12 决策层融合(Maximun) 64.25 70.26 63.42 66.18 表 2 基线模型与DRSN-MF模型识别效果对比
Table 2 Comparison of recognition effect between baseline model and DRSN-MF model
% 模型 准确率 精确率 召回率 $ {F_1} $值 基线模型 80.42 80.96 80.51 80.49 DRSN-MF 85.05 84.38 84.83 84.61 -
[1] 何俊松. 炉管泄漏自动报警装置的技术改造[J]. 广西电力, 2018, 41(1): 63–66. doi: 10.3969/j.issn.1671-8380.2018.01.018 HE Junsong. Technical modification of automatic warning system of boiler pipe leakage[J]. Guangxi electric power, 2018, 41(1): 63–66. doi: 10.3969/j.issn.1671-8380.2018.01.018 [2] OH H, JUNG J H, JEON B C, et al. Scalable and unsupervised feature engineering using vibration-imaging and deep learning for rotor system diagnosis[J]. IEEE transactions on industrial electronics, 2018, 65(4): 3539–3549. doi: 10.1109/TIE.2017.2752151 [3] BOU-GHAZALE S E, HANSEN J H L. A comparative study of traditional and newly proposed features for recognition of speech under stress[J]. IEEE transactions on speech and audio processing, 2000, 8(4): 429–442. doi: 10.1109/89.848224 [4] LAUKKA P, NEIBERG D, FORSELL M, et al. Expression of affect in spontaneous speech: acoustic correlates and automatic detection of irritation and resignation[J]. Computer speech & language, 2011, 25(1): 84–104. [5] HSIAO P W, CHEN C P. Effective attention mechanism in dynamic models for speech emotion recognition[C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary: IEEE, 2018: 2526−2530. [6] LIU Ruonan, YANG Boyuan, ZIO E, et al. Artificial intelligence for fault diagnosis of rotating machinery: a review[J]. Mechanical systems and signal processing, 2018, 108: 33–47. doi: 10.1016/j.ymssp.2018.02.016 [7] HAN Zhiyan, WANG Jian. Speech emotion recognition based on Gaussian kernel nonlinear proximal support vector machine[C]//2017 Chinese Automation Congress. Jinan: IEEE, 2018: 2513−2516. [8] LI Yifan, LIANG Xihui, LIN Jianhui, et al. Train axle bearing fault detection using a feature selection scheme based multi-scale morphological filter[J]. Mechanical systems and signal processing, 2018, 101: 435–448. doi: 10.1016/j.ymssp.2017.09.007 [9] 胡德生, 张雪英, 张静, 等. 基于主辅网络特征融合的语音情感识别[J]. 太原理工大学学报, 2021, 52(5): 769–774. HU Desheng, ZHANG Xueying, ZHANG Jing, et al. Feature fusion based on main-auxiliary network for speech emotion recognition[J]. Journal of Taiyuan University of Technology, 2021, 52(5): 769–774. [10] KIM J, SAUROUS R A. Emotion recognition from human speech using temporal information and deep learning[C]//Proc Interspeech 2018. Hyderabad: ISCA, 2018: 937−940. [11] 胡康, 何思宇, 左敏, 等. 基于CNN-BLSTM的化妆品违法违规行为分类模型[J]. 智能系统学报, 2021, 16(6): 1151–1157. HU Kang, HE Siyu, ZUO Min, et al. Classification model for judging illegal and irregular behavior for cosmetics based on CNN-BLSTM[J]. CAAI transactions on intelligent systems, 2021, 16(6): 1151–1157. [12] 刘威, 王薪予, 刘光伟, 等. 融合关系特征的半监督图像分类方法研究[J]. 智能系统学报, 2022, 17(5): 886–899. LIU Wei, WANG Xinyu, LIU Guangwei, et al. Semi-supervised image classification method fused with relational features[J]. CAAI transactions on intelligent systems, 2022, 17(5): 886–899. [13] 苏丽, 孙雨鑫, 苑守正. 基于深度学习的实例分割研究综述[J]. 智能系统学报, 2022, 17(1): 16–31. SU Li, SUN Yuxin, YUAN Shouzheng. A survey of instance segmentation research based on deep learning[J]. CAAI transactions on intelligent systems, 2022, 17(1): 16–31. [14] 胡海华, 韩国军, 张孝谊. 基于卷积神经网络的闪存信道检测技术研究[J]. 智能系统学报, 2021, 16(6): 1090–1097. HU Haihua, HAN Guojun, ZHANG Xiaoyi. Research on flash memory channel detection technology based on convolutional neural network[J]. CAAI transactions on intelligent systems, 2021, 16(6): 1090–1097. [15] 潘国壮. 基于实时陆空通话情感识别的管制员疲劳状态快速监测研究[D]. 南京: 南京航空航天大学, 2020. PAN Guozhuang. Research on rapid monitoring of air traffic controller’s fatigue state based on real-time emotion recognition of land-air communication[D]. Nanjing: Nanjing University of Aeronautics and Astronautics, 2020. [16] FARHOUDI Z, SETAYESHI S. Fusion of deep learning features with mixture of brain emotional learning for audio-visual emotion recognition[J]. Speech communication, 2021, 127: 92–103. doi: 10.1016/j.specom.2020.12.001 [17] 李瑞航, 吴红兰, 孙有朝, 等. 基于深度残差收缩网络多特征融合语音情感识别[J]. 数据采集与处理, 2022, 37(3): 542–554. LI Ruihang, WU Honglan, SUN Youchao, et al. Speech emotion recognition base on multi-feature fusion of deep residual shrinkage network[J]. Journal of data acquisition and processing, 2022, 37(3): 542–554. [18] DANGOL R, ALSADOON A, PRASAD P W C, et al. Speech emotion recognition using convolutional neural network and long-short term memory[J]. Multimedia tools and applications, 2020, 79(43/44): 32917–32934. [19] 胡婷婷, 冯亚琴, 沈凌洁, 等. 基于注意力机制的LSTM语音情感主要特征选择[J]. 声学技术, 2019, 38(4): 414–421. HU Tingting, FENG Yaqin, SHEN Lingjie, et al. The salient feature selection by attention mechanism based LSTM in speech emotion recognition[J]. Technical acoustics, 2019, 38(4): 414–421. [20] 姜特, 陈志刚, 万永菁. 基于注意力机制的多任务3D CNN-BLSTM情感语音识别[J]. 华东理工大学学报(自然科学版), 2022, 48(4): 534–542. JIANG Te, CHEN Zhigang, WAN Yongjing. Multi-task learning 3D CNN-BLSTM with attention mechanism for speech emotion recognition[J]. Journal of East China University of Science and Technology(natural science edition), 2022, 48(4): 534–542. [21] GAO Zehai, MA Cunbao, SONG Dong, et al. Deep quantum inspired neural network with application to aircraft fuel system fault diagnosis[J]. Neurocomputing, 2017, 238: 13–23. doi: 10.1016/j.neucom.2017.01.032 [22] SOHAIB M, KIM C H, KIM J M. A hybrid feature model and deep-learning-based bearing fault diagnosis[J]. Sensors (Basel, Switzerland), 2017, 17(12): 2876. doi: 10.3390/s17122876 [23] GUPTA A, ANJUM, GUPTA S, et al. InstaCovNet-19: A deep learning classification model for the detection of COVID-19 patients using Chest X-ray[J]. Applied soft computing, 2020, 99: 1–13. [24] 陈捷, 陆云. 2016年度上海并网发电厂发电锅炉“四管”泄漏统计及案例分析[J]. 电力与能源, 2017, 38(2): 170–175. CHEN Jie, LU Yun. Statistics and case analysis of Shanghai grid plant power boiler four-tube leakages in 2016[J]. Power & energy, 2017, 38(2): 170–175. [25] WANG Tao, PEI Yu, XIAO Huiheng, et al. Detection of small gas leaks based on neural networks and D-S evidential theory using ultrasonics[J]. Insight-non-destructive testing and condition monitoring, 2014, 56(4): 189–194. doi: 10.1784/insi.2014.56.4.189 [26] 宁方立, 韩鹏程, 段爽, 等. 基于改进CNN的阀门泄漏超声信号识别方法[J]. 北京邮电大学学报, 2020, 43(3): 38–44. doi: 10.13190/j.jbupt.2019-127 NING Fangli, HAN Pengcheng, DUAN Shuang, et al. Identification method of valve leakage ultrasonic signal based on improved CNN[J]. Journal of Beijing University of Posts and Telecommunications, 2020, 43(3): 38–44. doi: 10.13190/j.jbupt.2019-127 [27] ZHAO Minghang, ZHONG Shisheng, FU Xuyun, et al. Deep residual shrinkage networks for fault diagnosis[J]. IEEE transactions on industrial informatics, 2020, 16(7): 4681–4690. doi: 10.1109/TII.2019.2943898 [28] 卢锦玲, 郭鲁豫. 基于改进深度残差收缩网络的电力系统暂态稳定评估[J]. 电工技术学报, 2021, 36(11): 2233–2244. doi: 10.19595/j.cnki.1000-6753.tces.200437 LU Jinling, GUO Luyu. Power system transient stability assessment based on improved deep residual shrinkage network[J]. Transactions of China electrotechnical society, 2021, 36(11): 2233–2244. doi: 10.19595/j.cnki.1000-6753.tces.200437






















































































